一堂课带你走进生成式人工智能的原理
一、前言
相信大家在日常的学习生活中,或多或少都使用过 OpenAI 的 ChatGPT、Google 的 Gemini 或 Anthropic 的 Claude 等人工智能平台。这些工具确实为我们带来了极大的便利,大幅提升了工作与学习的效率。本文的主要目标是带大家揭开这些生成式人工智能的神秘面纱,对它们背后的运行原理建立一个基本的认识。
二、初识生成式 AI
无论是 ChatGPT、Gemini 还是 Claude,它们提供给用户的最基础功能看似极其简单:你输入一段文字(比如一个问题),它就会给你返回一段文字回复。虽然“输入-输出”的形式简单,但它却能帮你完成许多复杂的任务,比如编辑短信、制定计划甚至辅导作业。
随着技术的演进,目前的 AI 平台已经不再局限于纯文本,它们还能接收和输出语音、图片、文档等多种形式的信号。在这里,我们先从最基础的“文本到文本”讲起,文章后半部分也会揭秘模型是如何跨界处理语音和图像的。
三、核心原理:文字接龙
(一)运行过程
ChatGPT、Gemini 和 Claude 本质上都是语言模型。
那么,语言模型究竟是什么? 简单来说,它是一种经过专门训练、能够理解和生成人类语言的人工智能系统。当你输入一段文字时,它会顺着你的语境继续往下说——这其实就是一场高级的文字接龙游戏。模型的核心任务就是猜测:在你提供的这段话后面,最应该接哪个字。
举个例子:
-
当你输入:“人工智”
-
大模型很有可能会接着输出:“能”
-
当你输入:“今天是周末,我很”
-
大模型或许会接着输出:“开心”
怎么样,是不是和文字接龙游戏很像。
在这场文字接龙游戏中,有两个非常重要的基本概念:
- 它的输出(也就是它接的字)有一个名字叫做Token,翻译成中文叫做词元。
- 而我们给模型的输入(也就是给模型的这些话),也有一个名字,叫做Prompt,翻译成中文叫做提示词。
(二)运行机制:模型是如何完成接龙的?
好,那问题来了,模型是如何完成文字接龙这个游戏的?
为了更清晰地说明,我们再来看一个完整的问答过程:
当我们输入:
水的沸点是多少?
我们想要模型回答的并且模型也会回答的是:
水的沸点是100摄氏度。
我们拆解一下这个过程:
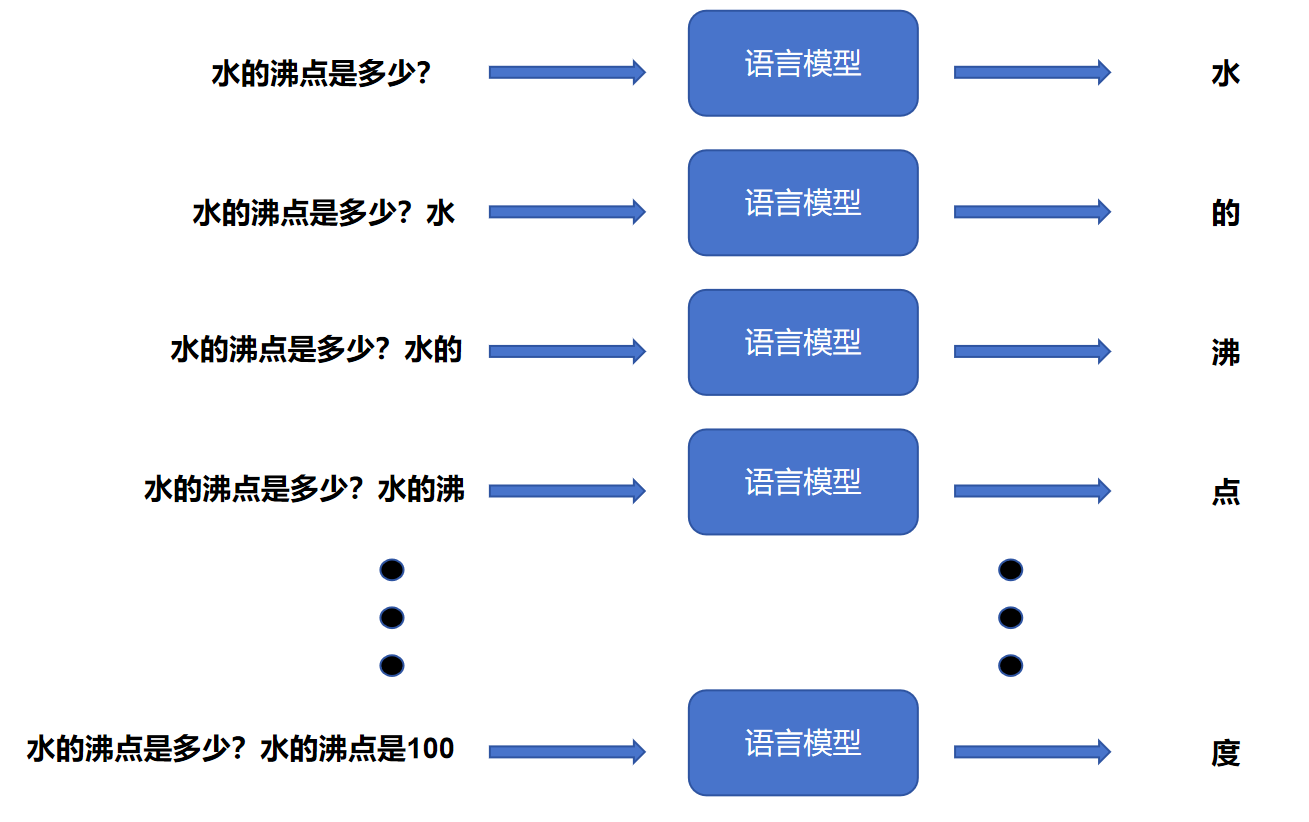
我们将这个过程拆解开来,模型其实是这样一步步工作的:
-
逐字预测: 模型首先根据输入“水的沸点是多少?”,计算出下一个字大概率是“水”。
-
循环迭代: 接着,它将新生成的“水”字拼接到原问题后,把“水的沸点是多少?水”作为新的输入,再次预测下一个字,大概率得出“的”。
-
不断重复: 如此往复,每次都把刚刚生成的 Token 加入已知条件中,重新计算下一个 Token。
(三)了解了基本流程后,你可能会产生以下几个疑问:
1. 模型是怎么决定要接哪个字的?

表中左侧所有的Token的集合,叫做Vocabulary(字典)
这依赖于概率分布与字典 (Vocabulary)。字典包含了模型能够输出的所有可能的 Token。每次接字时,模型会根据前面的上下文,为字典里的每一个 Token 计算出一个概率分数。它通常会大概率选择得分最高的那个 Token,但这其中也会引入一定的随机性,这就解释了为什么对于同一个问题,模型每次的回答可能都不完全一样。
2. 模型怎么知道什么时候该停止?
在模型的词典中,存在一个特殊的 Token——通常被称为 [END] 或 [EOS] (End of Sequence)。当模型预测并输出这个特殊符号时,接龙游戏就会宣告结束,模型停止生成。
3. 模型是如何计算出这些概率的?
你可以把模型想象成一个极其复杂的数学函数。我们输入的文字是自变量 $X$,经过这个函数的运算,输出的就是下一个 Token 的概率分布 。
就像最简单的函数 包含参数
和
一样,大模型这个复杂函数也包含了海量的参数 (Parameters)。目前主流的大模型,参数量达到百亿级别已是常态,十亿级别只能算是“小模型”。
而要想模型的效果好,参数多是一方面,参数还要合适,那么怎么得到合适的参数呢?这就需要训练了,你可以这样来理解:大模型也要经过学习大量的资料,才能掌握那么多知识。参数调整的过程,其实就是大模型学习(训练)的过程,不断使得参数变得尽量最优。
4. 这么多参数是怎么定下来的?(关于训练)
谈到训练,那么大模型训练所需的数据是什么呢?
一方面,可以是从网络上爬下来的语料;另一方面,可以是工作人员专门制作的标注资料;还有就是使用者的反馈了。

模型必须要通过学习海量的数据,才能掌握规律并优化这些参数。这个调整参数的过程就是大模型的训练过程,可以简单分为三个阶段:
-
Pre-train (预训练): 投喂海量未标注的网络语料,让模型掌握基础的语言规律和通用知识。
-
Fine-tune (微调): 使用少量高质量、人工标注的数据进行专项训练,让模型学会如何更好地回答问题。
-
RLHF (基于人类反馈的强化学习): 根据使用者的真实反馈来调整模型。比如给出两个答案让测试员挑选,模型会根据选择结果自我修正,提高优质答案的生成概率。
5.模型为什么会回答问题呢?当我们输入“水的沸点是多少?”时,模型为什么不会接“你知道吗?”这句话接上去也很合理呀。
原因可能是你的输入其实不一定是模型看到的Prompt,
有可能当你输入:
水的沸点是多少?
你的输入会变成:
使用者问:水的沸点是多少?AI回答:
不过对于一个闭源的大模型平台,它是如何修改你的输入来生成Prompt的你并不知道。还有一个观察,你问“今天是周几?”按理说后面接任何星期的概率都该差不多,但是模型往往会准备回复你正确的答案。这也暗示有可能,你的输入改为Prompt时,可能已经添加了今天的时间,以及你的相关资料。这样就有足够的Prompt,来确保接下来模型回答问题,并且不会胡说。确保足够的Prompt就是Context Engineering。
6.模型怎么做到多轮对话的呢?
如果你理解模型如何解下一个字的原理,这个问题也很好理解。那就是,在一个对话框中,模型会将你当前的输入以及之前你们之间的对话记录都作为输入。这样,模型相当于在你们之前对话的基础上,来回答你接下来的问题。
(四)走向多模态:模型是如何看图和听声音的?
既然模型的核心工作机制是“序列接龙”,那它又是如何处理图像和音频的呢?道理其实是相通的。
对于图像而言,最直观的想法是让模型一个像素、一个像素地去预测。而视频,本质上就是连续播放的多张图片。
同理,对于音频,声音是由连续的采样点组成的,模型只需要预测下一个采样点,不断循环,就能合成一段语音。
然而在实际工程中,逐个预测像素或采样点的计算量极其庞大,因此业界通常不会采用这种最原始的方法。
-
图像的处理: 往往会将一整张图片切割成一个个小方块(例如 16x16 的 Patches),然后将这些图像块编码成类似于文字的 Token,输入给大模型。模型预测出下一个图像 Token,最后再解码还原成图片。
-
音频的处理: 同样也是将一段连续的音频切分成一个个音频片段(Frames),编码为 Token 后进行序列预测。
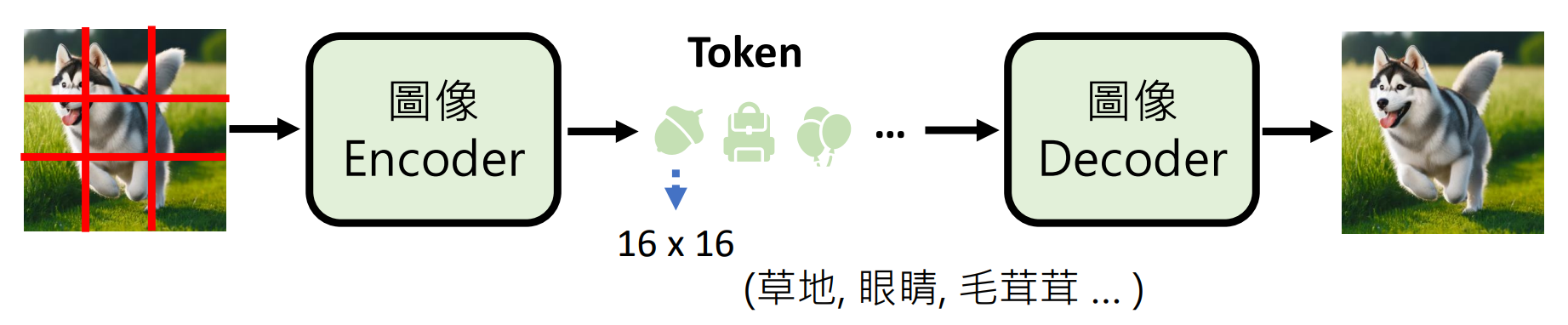

四、总结
发现了吗?生成式人工智能虽然看似神通广大,但其核心逻辑却极具规律性。模型所处理的,往往都是有结构的对象。
生成式人工智能的基本原理,就是让机器学会产生复杂的、有结构的物件。
-
复杂的: 意味着它能够组合出无穷无尽的可能性。
-
有结构的: 意味着哪怕再宏大的文章、再精美的图片,都可以被拆解为有限的基本单位。
在 AI 的世界里,这些基本单位,统称为 Token。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)