AI人工智能-大模型训练-第十三周(小白)
一、核心痛点:为什么大模型训练这么难
我们可以把大模型比作“一栋超级大房子”,训练模型就是“装修这栋房子”
- 效率问题:装修材料(训练数据)太多,一个人搬材料、刷墙、铺地板,要花好几年(对应数据量大,单GPU训练耗时)
- 显存问题:房子太大(模型参数多),你的工具车(GPU显存)装不下整栋房子的装修材料和工具(对应模型参数、中间计算记过超出GPU显存,直接报错)
其实后面的所有方法,本质上都是“怎么让装修又快又能装下”——要么“多找人分工”(并行训练),要么“精简材料占用空间”(混合精度,ZeRO),要么“不重新装修,只局部改造”(REFT微调)
二、并行训练:多GPU“分工干活”(解决效率+显存问题)
并行训练就是“找多个工人一起装修”,但分工方式不同,对应三种核心并行策略
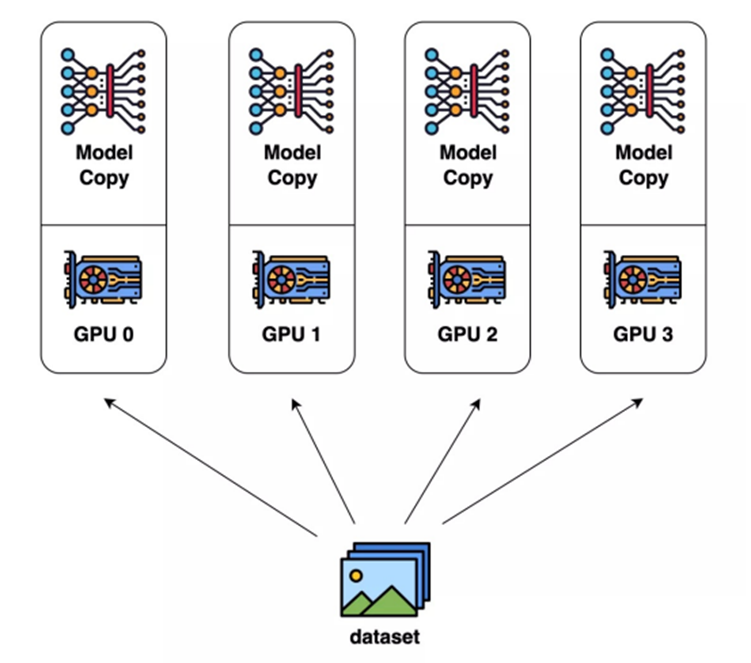
1.数据并行(DP):“多人干同样的话,最后汇总”
- 核心逻辑:把“装修材料”(训练数据)分成多份,每个GPU(工人)拿一份材料,同时用完整的模型(整栋房子的装修方案)计算梯度;计算完后,所有人把梯度汇总(比如你算的梯度是0.1,我算的是0.2.汇总后是0.3),再用汇总后的梯度统一更新模型参数
- 类比:3个工人同时刷同一栋房子的3个房间,每个人都有完成的“刷墙流程”(模型),刷完后一起商量“下次怎么刷更快”(统一更参数)
关键特点:
- 优点:简单易操作,不用改模型结构,训练速度随 GPU 数量线性提升;
- 缺点:要求单块 GPU 能装下完整模型(显存够大)—— 如果房子太大(模型参数太多),一个工人的工具车装不下完整装修方案,就没法用。
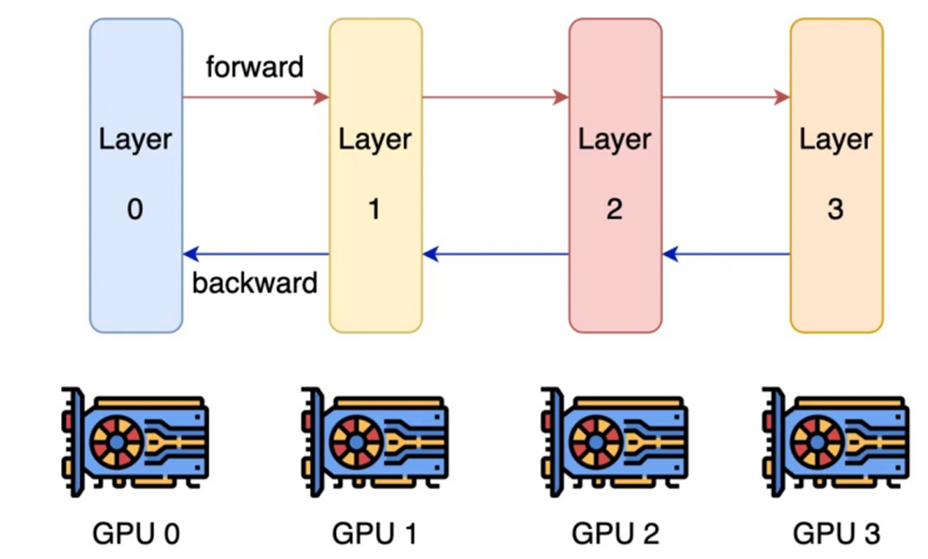
2.模型并行(PP):“多人干不同的活,按流程来”
- 核心逻辑:把“模型”(装修方案)拆成不同部分,每个GPU只负责其中一部分。比如Transformer的第1-2层给GPU0,第3-4层给GPU1,第5-6层给GPU2;前向传播时,数据按“GPU0->GPU1->GPU2”的顺序计算,反向传播时按“GPU2->GPU1->GPU0”的顺序回传梯度
- 类比:装修时,工人A只负责刷墙,工人B只负责铺地板,工人C只负责装家电,按流程接力干活,最后完成整栋房子装修
关键特点:
- 优点:解决“单GPU装不下完成模型的问题”(比如模型有100层,拆给10个GPU,每个GPU只装10层)
- 缺点:GPU之间要频繁传数据(比如工人A刷完墙,要告诉工人B可以铺地板了),通讯时间长,效率比数据并行略低
3.张量并行(TP):把一个活拆成小块,每人干一块
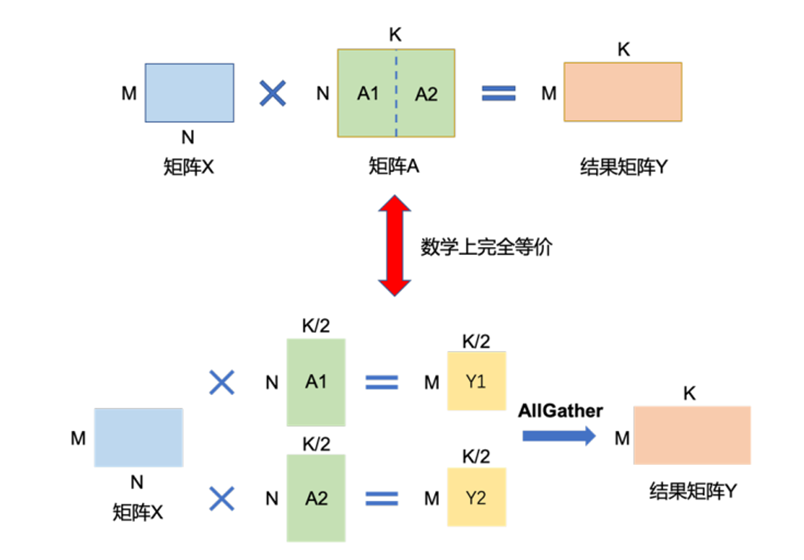
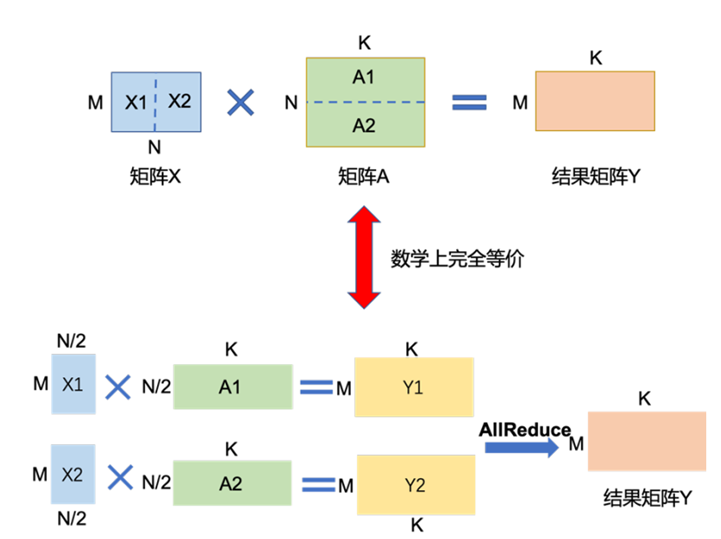
- 核心逻辑:比模型并行更细粒度的拆分——不拆“模型层”,而是拆“层力的张量(矩阵)”。比如一个大矩阵运算(深度学习力的核心运算),拆成两个小矩阵,两个GPU分别算小矩阵的结果,最后合并成完成结果(数学上完全等价)
- 类比:要搬一块100斤的石头(大矩阵),一个人搬不动,拆成两块50斤的,两个人分别搬,到目的地再拼回一块
- 针对Transformer的优化:Transformer的“多头注意力”(比如16个注意力头),可以让每个GPU负责1-2个注意力头的计算,不用拆分矩阵,效率更高
关键特点:
- 优点:显存占用最低(拆的最细),能训练超大模型
- 缺点:GPU之间通讯最频繁(比如两个小矩阵之间要合并),需要告诉网络支持,否则回变慢
4.混合并行:多种分工结合,取长补短
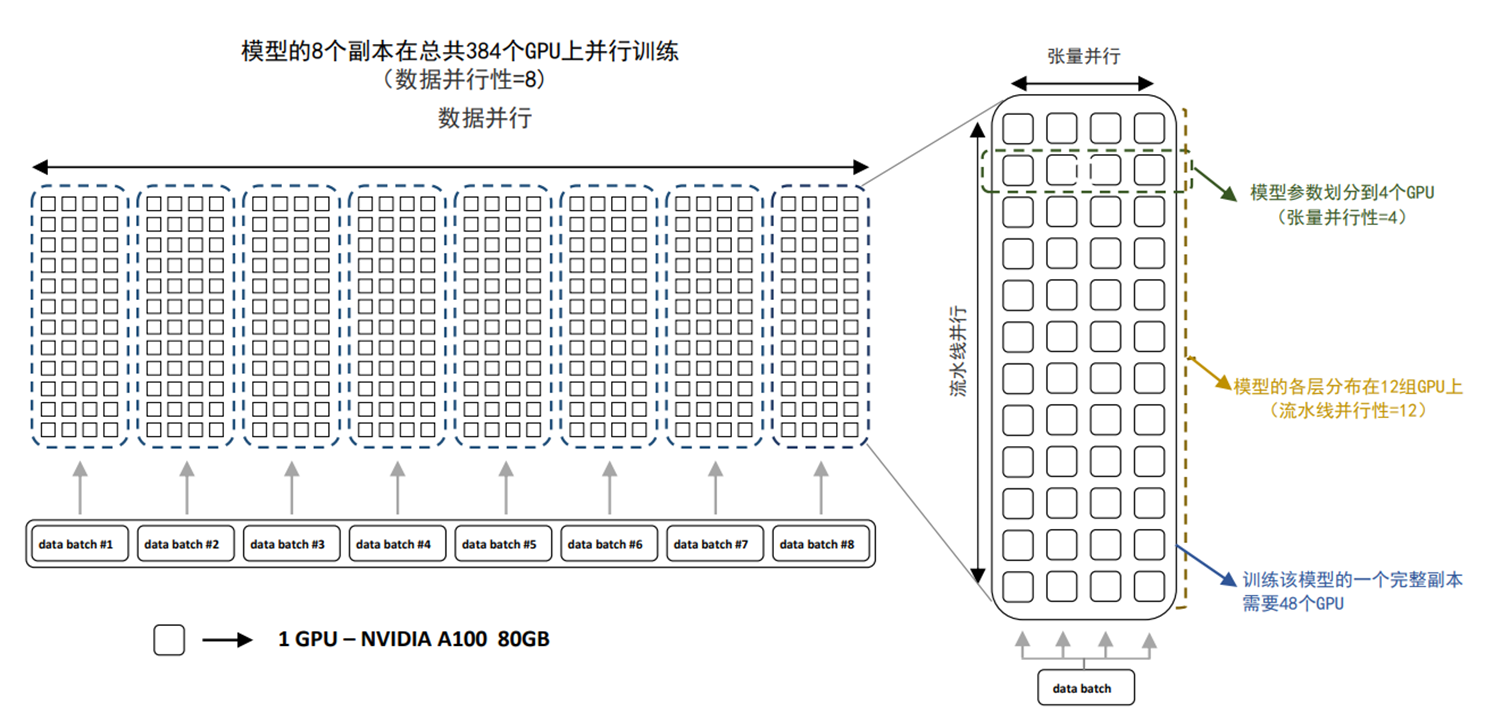
比如BLOOM模型(1760亿参数)的训练,就是把“数据并行+模型并行+张量并行”结合起来
- 先按数据并行拆分训练数据(多人干同样的活)
- 每个数据组里,按模型并行拆分模型层(没人干不同的活)
- 每个层里,按张量并行拆分矩阵(拆小块)
- 类比:装修公司派10个团队(数据并行),每个团队里有3个工人(模型并行:刷墙、铺地板、装家电),每个工人再找助手拆分工序(张量并行:比如刷墙拆成“刷底漆,刷面漆”),最大化效率和容量
三、混合精度训练:精简数据占用空间,不丢关键信息
深度学习训练时,数据用“浮点数”存储和计算,浮点数的“精度”(记录数字的详细程度)和“占用空间”成反比——精度越高,占显存越多。混合精度训练就是“大部分用低精度省空间,关键步骤用高精度保效果”
1.三种常用浮点数:FP32、FP16、BF16
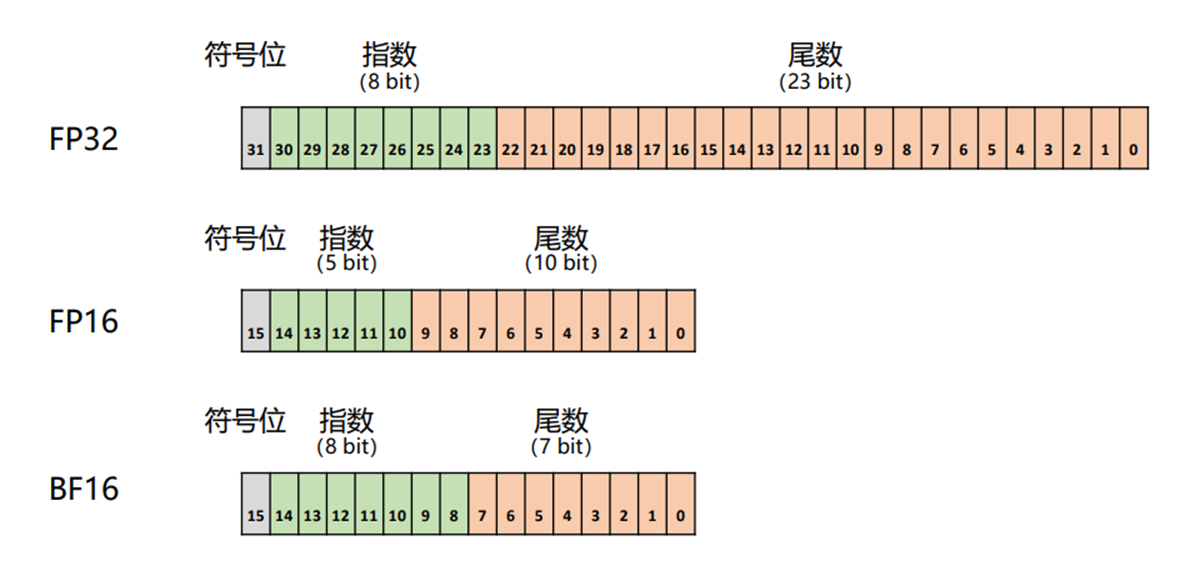
我们用 “记录身高” 类比,帮你理解三者区别:
| 类型 | 比特数(占用空间) | 精度(记录详细程度) | 类比场景 | 适用场景 |
|---|---|---|---|---|
| FP32 | 32bit(4 字节) | 最高(尾数 23bit) | 用卷尺精确测量(保留小数点后 3 位) | 小模型训练、需要高精度的场景 |
| FP16 | 16bit(2 字节) | 中等(尾数 10bit) | 用直尺测量(保留小数点后 1 位) | 大模型训练的大部分步骤 |
| BF16 | 16bit(2 字节) | 中等(尾数 7bit) | 用手比划(保留整数位,误差略大) | 对精度要求不高、追求速度的场景 |
补充:浮点数的 “指数位” 决定 “能表示的数字范围”(比如能不能表示 10^38 这么大的数),“尾数位” 决定 “精度”(比如能不能区分 1.0001 和 1.0002)。FP32 指数位 8bit、尾数位 23bit,所以既能表示超大数,又能精确到小数;FP16 指数位 5bit、尾数位 10bit,范围小但精度够日常计算;BF16 指数位 8bit(和 FP32 一样,能表示超大数)、尾数位 7bit(精度略低),适合大模型(参数多,需要表示大范围数字)。
2.为什么会有精度损失
比如十进制的0.2,转成二进制是无限循环小数(0.001100110011...),但浮点数的尾数位是有限的(比如FP16只有10bit),只能截断保留,导致“实际存储的数字和真实值有微小差异”——这就是精度损失。但大模型训练时,这种微小差异不会影响最终效果,反而能省一半显存。
3.混合精度训练的核心逻辑
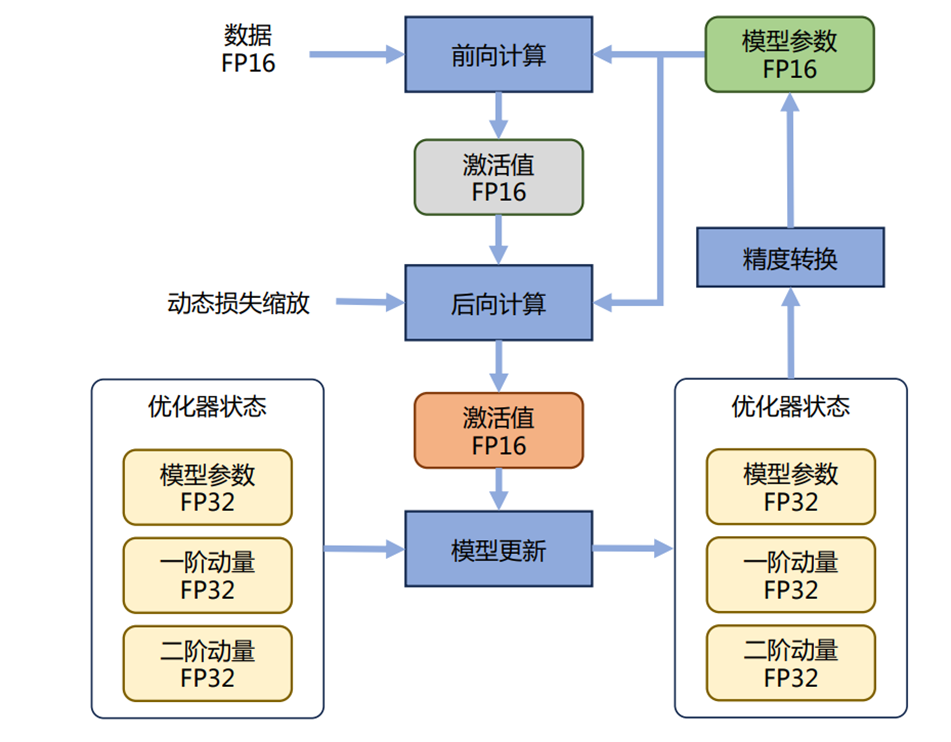
- 大部分计算FP16/BF16(省显存、提速度)
- 关键参数(比如模型权重、梯度)用FP32备份(避免精度损失累积)
- 反向传播时,用FP16计算梯度,再转成FP32更新备份的权重,最后更新后的权重在转成FP16用于下一轮训练
- 类比:平时记笔记用简写(FP16),关键公式用完整写法备份(FP32),既省时间又不丢失关键信息
四、ZeRO优化:拆分模型组件,彻底释放显存
ZeRO(零冗余优化器)是微软Deepspeed框架的核心功能,本质是“把模型的三个核心组件(参数、梯度、优化器状态)拆到多个GPU甚至CPU上”,让每个GPU只存一部分,彻底解决“显存不够”的问题
我们先明确模型训练时GPU要存的3样东西:
- 参数(W):模型的权重(比如Transformer的注意力层权重)
- 梯度(dW):反向传播计算出的“该怎么更新权重”
- 优化器状态(比如Adam的m,v):优化器需要记录的历史信息(比如之前的梯度平均值)
ZeRO的四个阶段(从“不拆分”到“全拆分”)
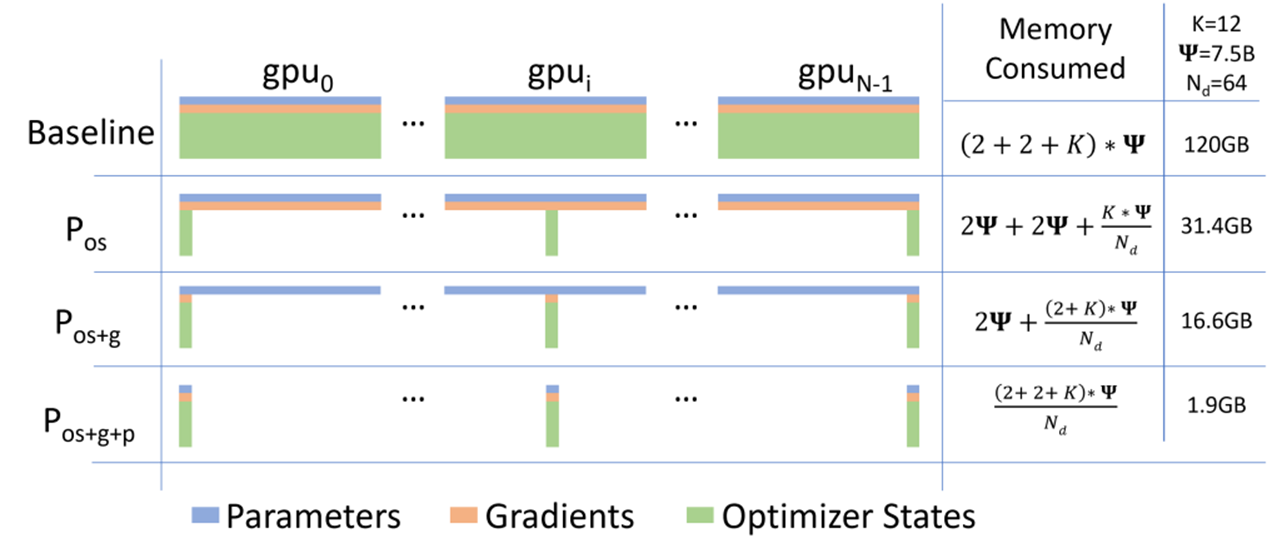
用 “分蛋糕” 类比,蛋糕就是 “3 样组件的总显存占用”:
| 阶段 | 拆分内容 | 类比场景 | 显存效率(能训练的模型大小) | 训练速度 |
|---|---|---|---|---|
| Stage0 | 不拆分(所有 GPU 存完整组件) | 所有人都拿一整块蛋糕(和普通训练一样) | 最低(只能练小模型) | 最快 |
| Stage1 | 拆分优化器状态 | 蛋糕切成 N 块,每人拿一块优化器状态(参数和梯度还是完整的) | 提升(能练中等模型) | 略慢 |
| Stage2 | 拆分优化器状态 + 梯度 | 蛋糕切成更小的块,每人拿一块优化器状态 + 一块梯度(参数完整) | 再提升 | 较慢 |
| Stage3 | 拆分参数 + 梯度 + 优化器状态 | 蛋糕拆成最小块,每人只拿一小块参数、一小块梯度、一小块优化器状态 | 最高(能练千亿参数模型) | 最慢 |
ZeRO-offload:把部分蛋糕放到CPU的盘子里
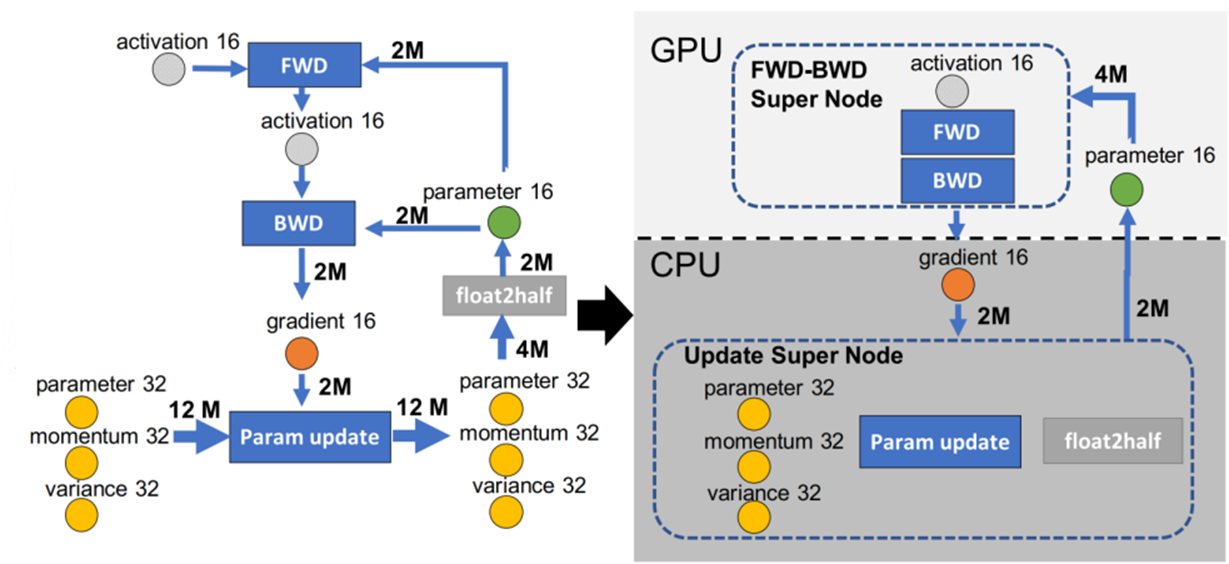
如果GPU显存还不够,ZeRO-offload会把“优化器状态”放到CPU内存里(CPU内存比GPU显存大得多),GPU只负责计算,需要时再从CPU调数据——相当于“工人只带工具干活,材料存放在旁边的仓库(CPU内存)”,进一步释放GPU显存,但会因为CPU和GPU之间传数据,速度再慢一点。
核心结论:
- 追求速度:选Stage0/Stage1(适合中小模型)
- 追求大模型:选Stage2/stage3+offload(适合千亿参数模型)
- 速度和显存的权衡:Stage2是最常用的折中方案
五、PEFT微调:不重新装修,只局部改造(降低微调成本)
我们知道微调的核心是 “用少量数据更新预训练模型的参数”,但大模型(比如 11B 参数)微调时,要更新所有参数,显存占用大、耗时久 ——PEFT(参数高效微调)就是 “只更新模型的一小部分参数,让模型适配新任务”,相当于 “装修房子时,不重新拆墙砌墙,只换窗帘、刷墙面局部,既省钱又省时间”。
下面有5中核心PEFT方法,重点说“怎么局部改造”
1.Prompt Tuning:给模型加“专属提示词模板”
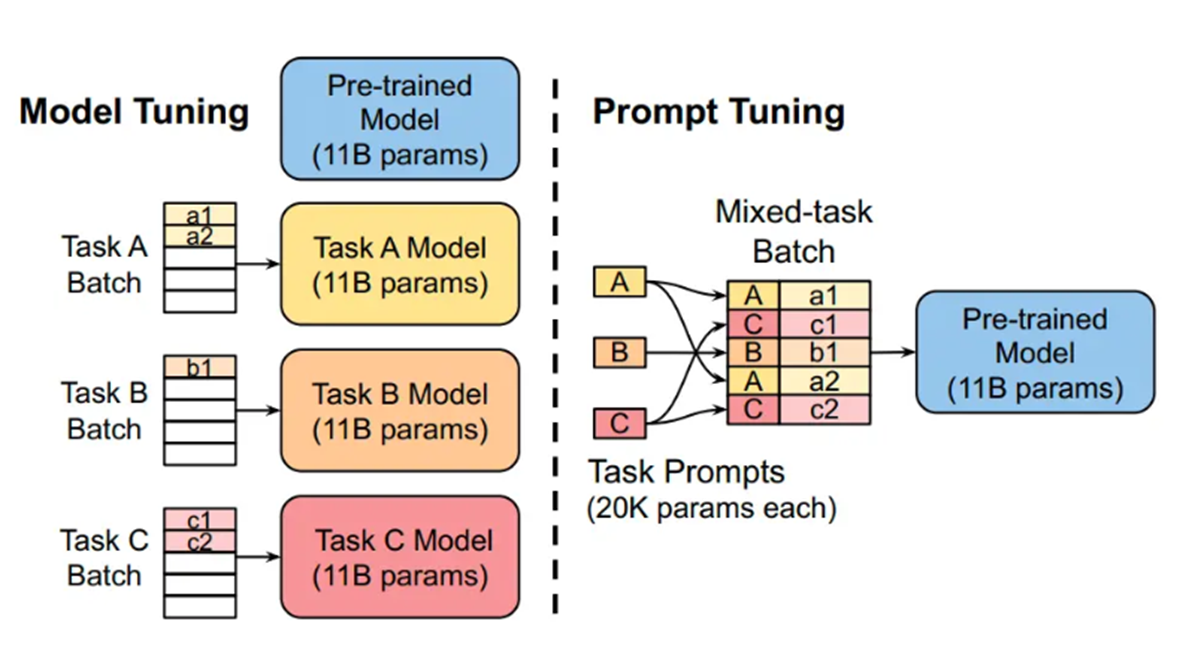
- 核心逻辑:预训练模型的参数完全冻结(不改动),针对每个任务(比如文本分类、生成),训练一个 “专属提示词嵌入层”(比如 20K 参数,比 11B 参数少太多),相当于 “给模型贴一个‘任务标签’,告诉它‘现在要做什么任务’”。
- 类比:你有一辆通用汽车(预训练模型),要用来拉货(任务 A),就加一个 “货箱附件”(提示词嵌入层);要用来载客(任务 B),就加一个 “座椅附件”,不用改汽车本身。
- 优点:每个任务只需要训练少量参数(20K 左右),多个任务可以共享同一个预训练模型,存储成本极低。
2.Prefix-tuning:给模型加“前缀引导层”
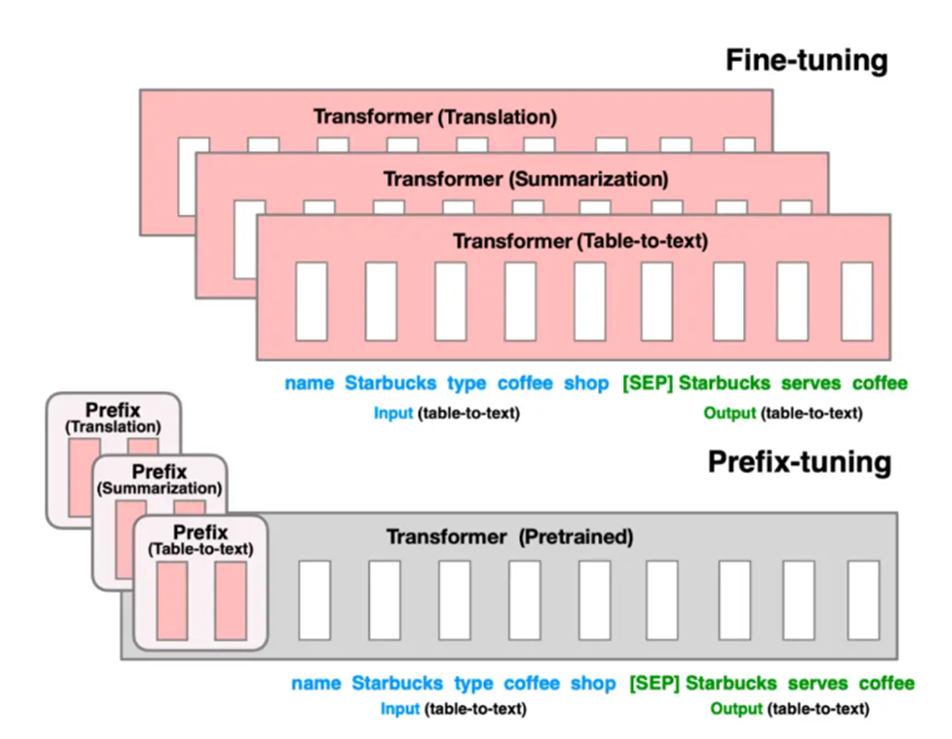
- 核心逻辑:和 Prompt Tuning 类似,但提示词不是 “一个标签”,而是 “一串可学习的前缀向量”,插在输入文本的前面,引导模型生成符合任务要求的输出。
- 比如任务是 “写诗歌”,就训练一个 “诗歌风格前缀”(比如向量 [0.1, 0.3, ...]),输入文本前加上这个前缀,模型就知道要按诗歌风格生成。
- 区别:Prompt Tuning 的提示词是 “任务级”(比如 “分类”“生成”),Prefix-tuning 是 “风格 / 场景级”(比如 “诗歌”“科普”),更灵活。
3.P-tuning&P-tuning v2:给模型加“分层提示”
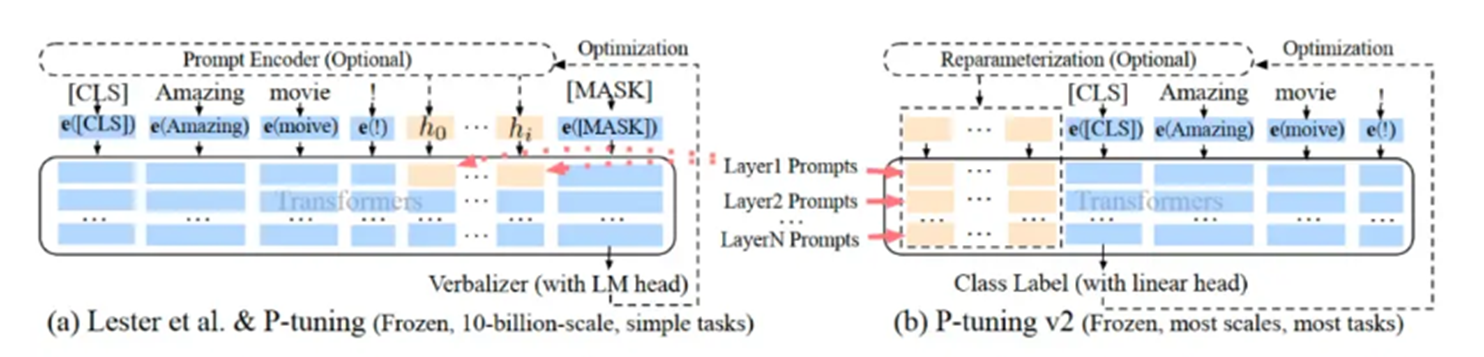
- P-tuning:把提示词嵌入到模型的中间层(不是只在输入层),比如在 Transformer 的第 2 层、第 5 层都加提示词,引导模型的中间计算过程。
- P-tuning v2:更进一步,在模型的所有层都加 “分层提示”,并且可以用 “提示编码器” 优化提示词,适配更多任务(比如文本分类、问答、生成),是更通用的版本。
- 类比:装修时,不仅在门口贴 “风格标签”,还在每个房间都放 “风格摆件”,让整个房子的风格更统一。
4.Adapter:给模型加“小插件层”
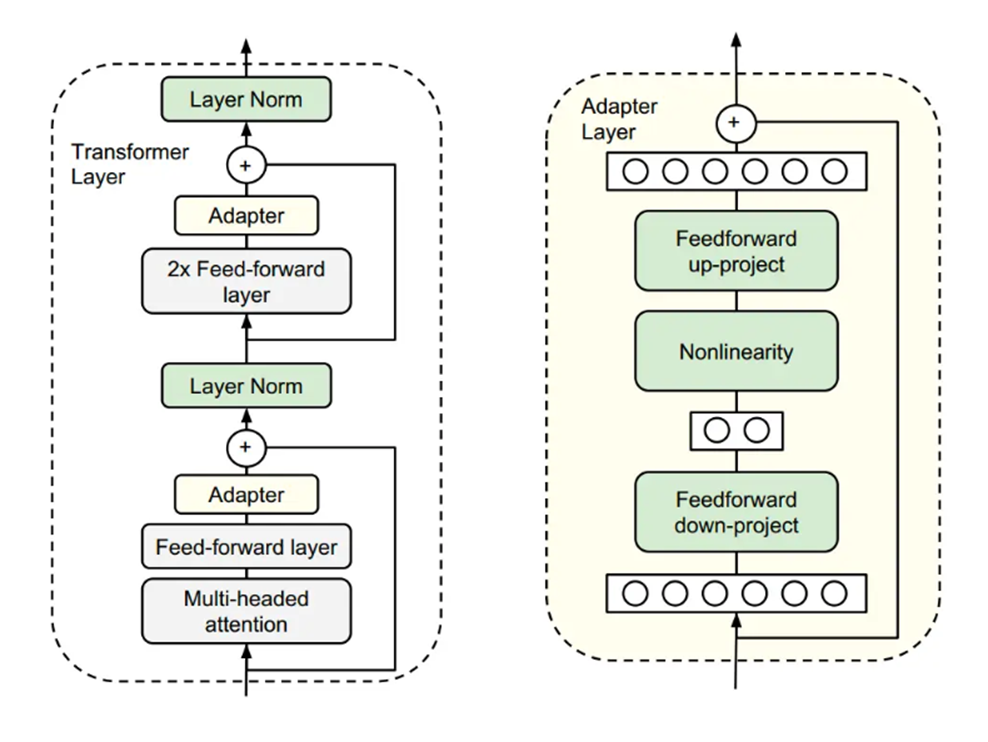
- 核心逻辑:在 Transformer 的每一层(比如注意力层、MLP 层)中间,插入一个 “小的 Adapter 层”(比如由两个小矩阵组成),只训练这个 Adapter 层的参数,模型原有参数冻结。
- 比如 Transformer 的 MLP 层是 “大工厂”,Adapter 层是 “工厂里的小机器”,只改小机器的运行方式,不改动大工厂的核心结构。
- 优点:插件式设计,可灵活增减,适配不同任务,但参数比 Prompt Tuning 略多(每个 Adapter 层几千到几万参数)。
5.LoRA:给模型的关键层 加“低秩矩阵插件”(最常用)
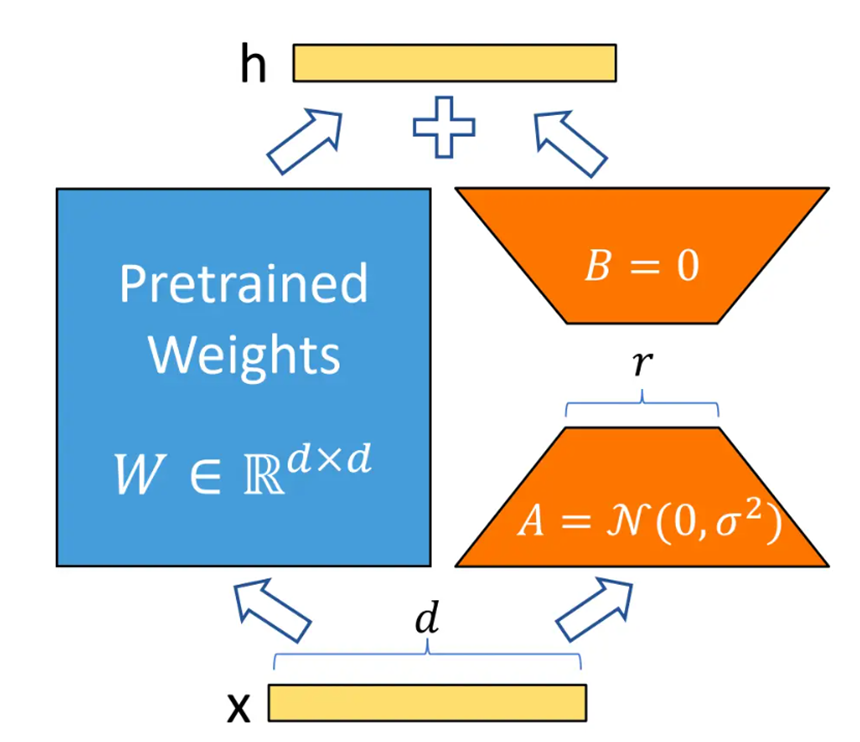
- 核心逻辑:大模型的核心是 “大矩阵运算”(比如注意力层的 QKV 矩阵),LoRA 不改动这个大矩阵,而是在旁边加两个 “小矩阵”(低秩矩阵),训练时只更新这两个小矩阵的参数,大矩阵参数冻结。
- 数学逻辑:两个小矩阵相乘,结果等价于 “大矩阵的一个微小修改”,但参数数量只有大矩阵的几百分之一(比如大矩阵是 1024×1024=100 万参数,小矩阵是 1024×16 + 16×1024=3.2 万参数)。
- 类比:你的手机(大模型)拍照效果一般,不用换手机,只装一个 “拍照插件 APP”(小矩阵),就能提升拍照效果,插件还能随时卸载。
- 优点:参数最少、训练最快、效果最好,是目前大模型微调的首选方法(比如 ChatGLM、Llama 系列微调都常用 LoRA)。
六、总结:大模型训练的“解决方案逻辑链”
- 先解决 “装得下”:模型太大装不下 GPU,用「模型并行 / 张量并行」拆分模型,再用「混合精度 + ZeRO」精简显存占用;
- 再解决 “练得快”:数据太多练得慢,用「数据并行 / 混合并行」提升效率;
- 最后解决 “微调省成本”:预训练模型微调太贵,用「PEFT(优先 LoRA)」只更少量参数,适配新任务。
整个流程就像 “装修超级大房子”:先想办法把房子拆成小块(并行),让工具车装得下;再精简材料包装(混合精度),多放些材料;最后局部改造(PEFT),不用重新装修 —— 既高效又省钱,这就是大模型大规模训练的核心逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)