agent的常见模式和适用的场景(anthropic博客精简版)
原文链接:https://claude.com/blog/common-workflow-patterns-for-ai-agents-and-when-to-use-them
主流的agent形式一共有下面几种:
-
顺序sequential
-
并行parallel
-
评估 evaluator-optimizer
| 模式 | 解决的问题 | 适用场景 | 权衡/代价 | 收益 |
|---|---|---|---|---|
| 顺序模式 (Sequential) | 任务之间存在依赖关系:步骤 B 需要步骤 A 的输出。 | 多阶段流程、数据流水线、“草稿-审核-润色”循环。 | 增加延迟:每个步骤都必须等待前一个步骤完成。 | 可以让每个 Agent 专注于单一任务,从而提高准确性。 |
| 并行模式 (Parallel) | 任务相互独立,但逐个执行速度太慢。 | 多维度评估、代码审查、大规模文档分析。 | 成本更高:产生多个并发 API 调用,且需要设计聚合策略。 | 能够加快完成速度,并在工程团队之间实现关注点分离。 |
| 评估器-优化器 (Evaluator-optimizer) | 初始草稿的质量不够理想,无法直接使用。 | 技术文档撰写、客户沟通、针对特定标准的代码生成。 | 消耗大量 Token:成倍增加 Token 使用量并延长了迭代时间。 | 通过结构化的反馈循环,能够生成质量更高的输出结果。 |
顺序
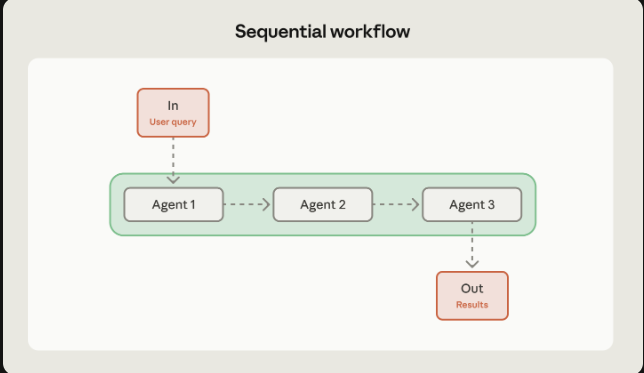
什么时候使用?
当任务可以被自然分解的为有明确依赖的各个阶段的时候
-
Multi-stage processes where each step depends on the previous output 多步骤过程,并且每个步骤都依赖前一个步骤
-
Data transformation pipelines where each stage adds specific value 每一个阶段都贡献加载的数据转换流程
-
Tasks that can’t be parallelized due to inherent dependencies 由于内在依赖关系,无法并行化的任务
-
terative improvement cycles like draft-review-polish cycles 像草稿-审稿-润色周期这样的迭代改进周期
Pro tip: First try your pipeline as a single agent, where the steps are just part of the prompt. If that’s good enough, you’ve solved the problem without additional complexity. Only split into a multi-step workflow when a single agent can’t handle it reliably.
并行
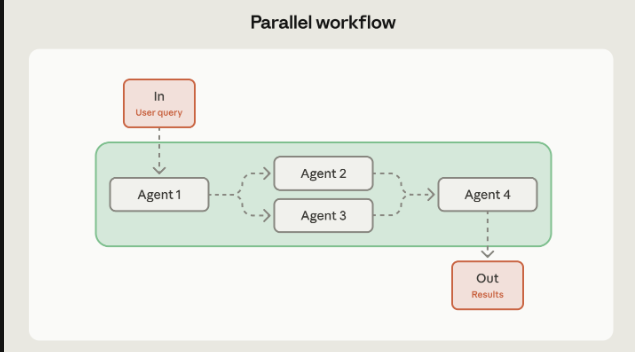
什么时候使用?
一个任务可以拆成多个独立的子任务,或者说需要对同一个问题有多个视角的时候,因为他可以实现关注点的分离。单独的agent去处理评判一件事情往往比在一次事情中兼顾所有事情来的高效
-
Sectioning approaches where different agents handle different aspects (like one processing queries while another screens for safety issues)分段方法,不同agent负责不同方面(比如一个处理查询,另一个负责安全问题筛查)
-
Evaluation scenarios where each agent assesses different quality dimensions评估场景中,每个agent评估不同的质量维度
-
Voting patterns where multiple agents analyze the same content and you aggregate their assessments 投票模式是多个代理分析同一内容,然后你汇总他们的评估
什么时候不该使用?
-
当agent需要累积上下文的时候或者需要建立在每一个agent的工作上的时候,不需要使用并行
-
资源限制或者api并发效率低下的情况下
-
缺乏明确的策略去处理不同agent矛盾的返回结果的时候
-
聚合的结果过于复杂降低输出质量的时候
例子:
-
Automating evaluations (each agent checks different quality metrics) or code review (multiple agents examine different vulnerability categories)自动化评估(每个智能体检查不同的质量指标)或代码审查(多个智能体检查不同的漏洞类别)
-
Document analysis is another strong use case: parallelize extraction of key themes, sentiment analysis, and factual verification, then combine the insights 文档分析是另一个强有力的应用场景:并行提取关键主题、情感分析和事实验证,然后将洞见结合起来
建议
首先尝试将你的任务链作为一个“单 Agent”来运行,即将所有步骤直接写在提示词(Prompt)中。如果效果已经达标,那么你就在不增加额外复杂度的前提下解决了问题。只有当单 Agent 无法可靠地处理任务时,才考虑将其拆分为多步骤的工作流。
评估器-优化器工作流程
Evaluator-optimizer workflows pair two agents in an iterative cycle: one generates content, another evaluates it against specific criteria, and the generator refines based on that feedback. This continues until the output meets your quality threshold or hits a maximum iteration count.
评估器-优化器工作流程将两个 agent 在迭代循环中配对:一个生成内容,另一个根据特定标准评估内容,生成器根据反馈进行优化。这个过程会一直持续直到达到你的质量阈值或达到最大迭代次数。
The key insight is that generation and evaluation are different cognitive tasks. Separating them lets each agent specialize—the generator focuses on producing content, the evaluator focuses on applying consistent quality criteria.
关键见解是生成和评估是不同的认知任务。将他们分开,让每个代理各自专精——生成器专注于内容制作,评估者专注于应用一致的质量标准。
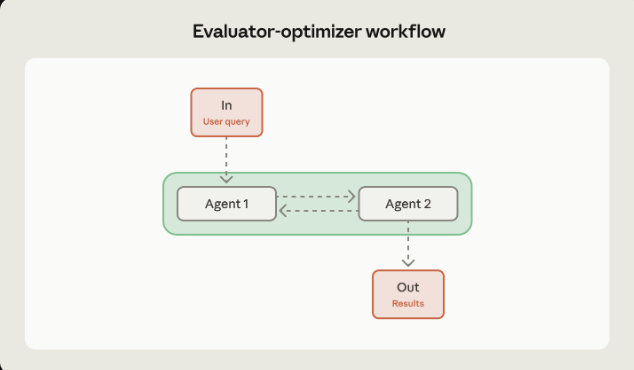
什么时候用:
当你有明确的且可衡量的质量标准,并且首次尝试和最后的结果之间差异足够显著来弥补token的消耗的时候
具体场景:
-
Code generation with specific requirements (security standards, performance benchmarks, style guidelines) 具有具体要求的代码生成(安全标准、性能基准、风格指南)
-
Professional communications where tone and precision matter 专业沟通中,语气和精准度至关重要
-
Any scenario where first-draft quality consistently falls short of requirements任何首稿质量持续未达要求的情形
什么时候不该使用?
当首次尝试的质量已经能满足需求时,请跳过“评估器-优化器”工作流——否则你是在不必要的迭代中白白浪费 Token。不要在以下场景使用此模式:需要即时响应的实时应用;基础分类等简单的常规任务;或者评估标准过于主观、AI 评估器无法保持一致判断的场景。如果存在确定性的工具(如检查代码风格的 Linter),请优先使用它们。此外,当资源预算的限制超过了质量提升带来的收益时,也应避免此模式。
例子
-
Generating API documentation (generator writes docs, evaluator checks for completeness, clarity, and accuracy against the codebase) 生成 API 文档(生成器撰写文档,评估器对照代码库检查其完整性、清晰度及准确性)。
-
Creating customer communications (generator drafts email, evaluator assesses tone and policy compliance)创建客户沟通内容(生成器起草邮件,评估器评估语气是否合适以及是否符合公司政策)
-
Producing SQL queries (generator writes query, evaluator checks for efficiency and security issues)生成 SQL 查询(生成器编写查询语句,评估器检查是否存在效率问题或安全性漏洞)。
建议
在开始迭代之前,请务必设定明确的停止标准。定义最大迭代次数和具体的质量阈值。如果没有这些“护栏”,你可能会陷入高昂的循环陷阱——评估器不断挑剔微小的瑕疵,生成器不断进行微调,但实际上输出质量在停止迭代很久之前就已经进入了平台期。要懂得什么时候“够好就行”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)