什么是 Token、Token 工厂与 Token 出海?从工程视角看懂 AI 新逻辑
从技术单位到商业单位,理解 AI 时代的新“硬通货”
最近两年,AI 行业里有一个词越来越高频:Token。
它最早更多出现在大模型 API 文档、计费页面和上下文窗口说明里,但到了 2025–2026 年,这个词已经明显从“模型内部术语”变成了“产业关键词”。英伟达近两年的公开表述里,反复把 token 作为 AI 的基础单位,并把 AI 基础设施的效率重点推进到 token throughput、token per watt、cost per token 等指标上。到了 GTC 2026,英伟达继续围绕 AI Factory 展开,强调固定功率预算下的 token 性能和更快的 time to token。
这背后其实说明了一件事:
AI 产业正在从“看有多少 GPU”,逐步转向“看能产出多少 Token”。
本文从技术博客的视角,把三个概念讲清楚:
- 什么是 Token
- 什么是 Token 工厂
- 什么是 Token 出海

一、什么是 Token?
1. Token 的定义
从技术上说,Token 是模型处理数据时使用的基本单位。
英伟达对 token 的官方解释是:token 是 AI 模型在训练和推理过程中处理的数据单元,用于支持预测、生成和推理。
对于大语言模型来说,模型并不是直接“看懂一整句话”,而是先把输入切分成更小的片段,再在这些片段上做 embedding、attention、预测下一个 token 等操作。
比如:
- 英文单词可能被拆成 1 个或多个 token
- 中文通常也不是严格“一字一 token”
- 标点、空格、数字也可能占用 token
- 在多模态模型里,图像、语音等内容也会被映射成模型可处理的 token 表达或等价序列
所以,Token 更像是模型内部的“计算颗粒度”,而不是自然语言里的字、词、句。
2. 为什么 Token 不是“字数”?
很多刚接触大模型的人,会把 token 简单理解成“字数”或者“单词数”。这个理解不准确。
原因在于,tokenization 取决于具体 tokenizer 和词表设计,不同模型的切分方式可能不同。同一句话,在不同模型里占用的 token 数也可能不一样。
因此,工程上更稳妥的说法是:
token 是模型内部使用的序列单位,不等于汉字数,也不等于单词数。
3. Token 为什么会变得这么重要?
因为它同时具备三层属性:
第一,它是信息单位。
模型训练和推理,本质上都发生在 token 序列上。
第二,它是算力消耗单位。
token 越多,通常意味着更多的显存占用、更多的 attention 计算、更长的推理链路。
第三,它是计费单位。
今天很多模型 API 已经按输入 token 和输出 token 计费,而不是简单按调用次数收费。
也就是说,Token 正在从一个纯技术概念,变成连接模型能力、算力成本和商业结算的统一单位。英伟达甚至直接把它称作 AI 的 “language and currency”。
二、从工程角度看,Token 为什么决定成本?
如果把大模型服务拆开看,企业真正关心的通常不是“参数量有多大”,而是下面这些问题:
- 响应快不快
- 并发能不能扛住
- 成本高不高
- 单位电力能产生多少有效输出
而这些问题,最后都能落到 token 指标上。
1. 常见指标有哪些?
推理系统里常见的几类指标包括:
- TTFT(Time to First Token):首个 token 返回时间
- TPOT(Time per Output Token):每个输出 token 的生成耗时
- TPS(Tokens Per Second):每秒输出 token 数
- Tokens per Watt:单位功耗下的 token 吞吐
- Cost per Million Tokens:每百万 token 的成本
英伟达在其关于推理经济学和 AI Factory 优化的公开内容里,已经明确把 time to first token、time per output token、tokens per second per watt、cost per token 作为关键衡量维度。
这意味着,模型服务的核心不只是“能不能跑”,而是“每度电、每台机器、每单位时间能不能更高效地产生 token”。
2. 一个简单的工程例子
假设两个推理集群:
- 集群 A:GPU 多,但调度一般、缓存利用差、功耗高
- 集群 B:GPU 数量略少,但 batch、KV cache、并发调度、模型编译优化做得更好
那么在同样电力预算下,B 完全可能产生更多 token,最终成本更低、收入更高。
所以在推理时代,真正重要的不只是“卡多不多”,而是:
卡能不能稳定转化成 token 产能。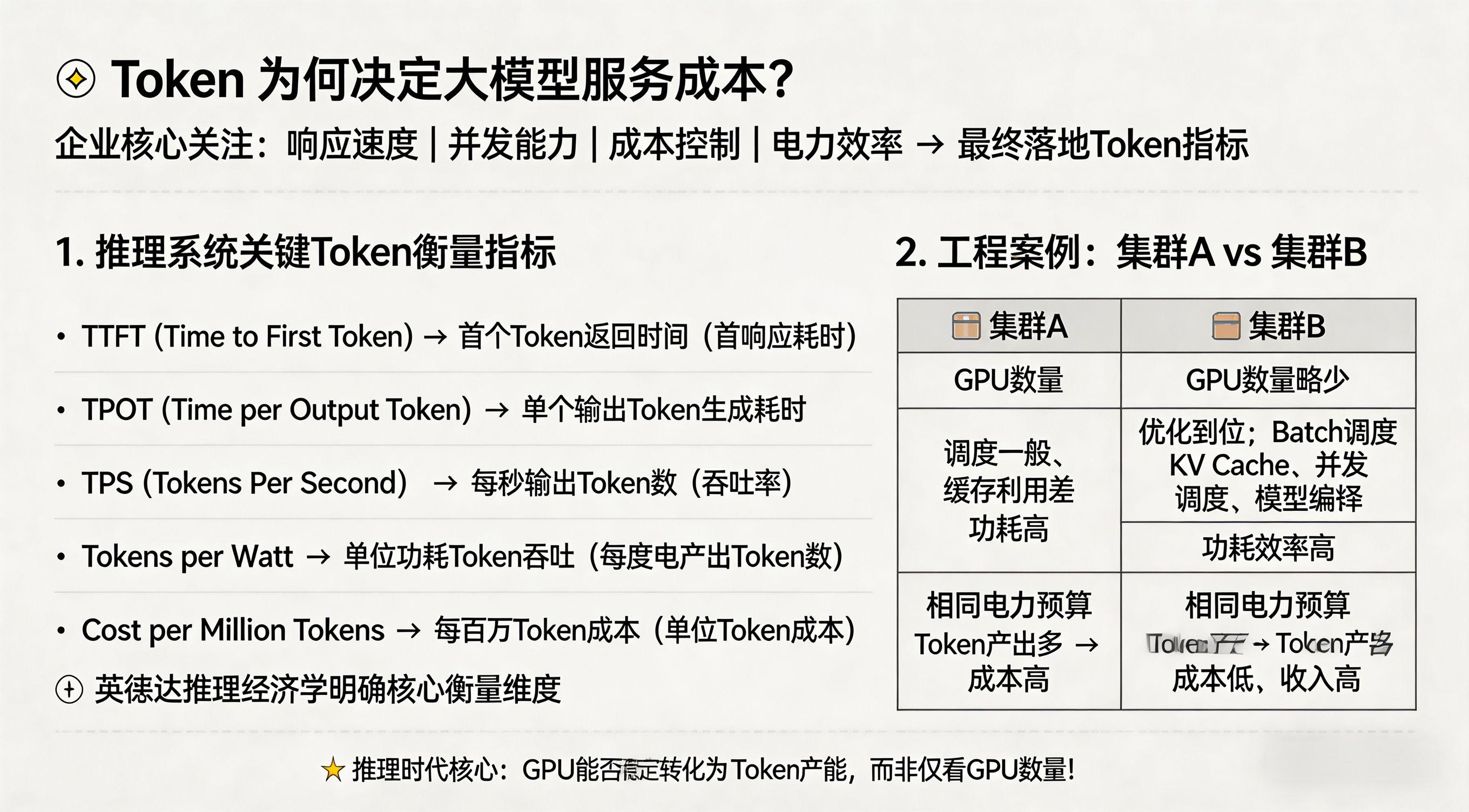
三、什么是 Token 工厂?
1. Token 工厂的本质
所谓 Token 工厂,可以把它理解成一个面向推理时代的智算中心模型:
输入的是电力、GPU、网络、存储、模型和调度系统,
输出的是稳定、可计量、可计费的 token 产能。
这和传统数据中心的思路不同。
英伟达在 AI Factory 的表述里提到,AI 工厂的“主要产物”不是传统 IT 意义上的通用计算,而是以 AI token throughput 衡量的智能产出。
这也是为什么现在越来越多厂商在讲:
- token throughput
- token per watt
- cost per token
- time to token
因为在推理业务里,这些指标比单纯的峰值 FLOPS 更接近真实商业结果。
2. 为什么智算中心会从“卖 GPU”走向“卖 Token”?
过去做算力租赁,逻辑比较简单:
- 卖裸金属
- 卖 GPU 时长
- 卖机柜和网络资源
但到了 AI 推理阶段,这种方式会越来越接近“卖原材料”。
真正更高附加值的,是把这些资源组织成一个高效推理系统,然后稳定输出 token 服务。
原因很简单:
客户最终买的不是 GPU 本身,而是结果。
比如客户要的可能是:
- 每秒多少 token
- 多快返回首字
- 每百万 token 多低成本
- 多高并发下仍稳定可用
于是,智算中心的竞争重点就发生了变化:
从“资源拥有量”
转向“资源转化率”。
3. Token 工厂的核心指标:每瓦 Token 吞吐量
英伟达在 Vera Rubin DSX AI Factory 参考设计中,明确提到要在固定电力预算下最大化 token performance per watt;其 DSX Max-Q 也是围绕固定功率约束下提升 token 性能而设计。
这说明一个事实:
未来的数据中心越来越受电力约束,而不是只受服务器数量约束。
所以“每瓦 token 吞吐量”会变成一个非常硬核的指标。因为它同时反映了:
- 硬件效率
- 系统调度效率
- 模型推理优化水平
- 散热与供电能力
- 业务经济性
换句话说:
过去拼的是“堆 GPU”;
未来拼的是“炼 Token”。
四、为什么 AI Agent 会放大 Token 消耗?
这是理解 Token 工厂很关键的一步。
早期的大模型应用,多数是简单问答:
用户输入一句,模型输出一段,调用链路比较短。
但 Agent 场景不一样。
一个 Agent 任务通常会包含:
- 任务理解
- 规划步骤
- 多轮思考
- 工具调用
- 检索外部信息
- 结构化输出
- 失败重试和自我修正
这意味着一次任务背后,往往不是“一次生成”,而是多轮 token 消耗叠加。
英伟达近年的公开表述里也反复强调,推理已经不只是简单生成,而是会随着 reasoning 和 agentic AI 的发展,带来更大的 token 需求。
所以从系统设计角度看,Agent 时代会把问题变成:
不是能不能提供模型调用,而是能不能承受大规模、持续增长的 token 生产压力。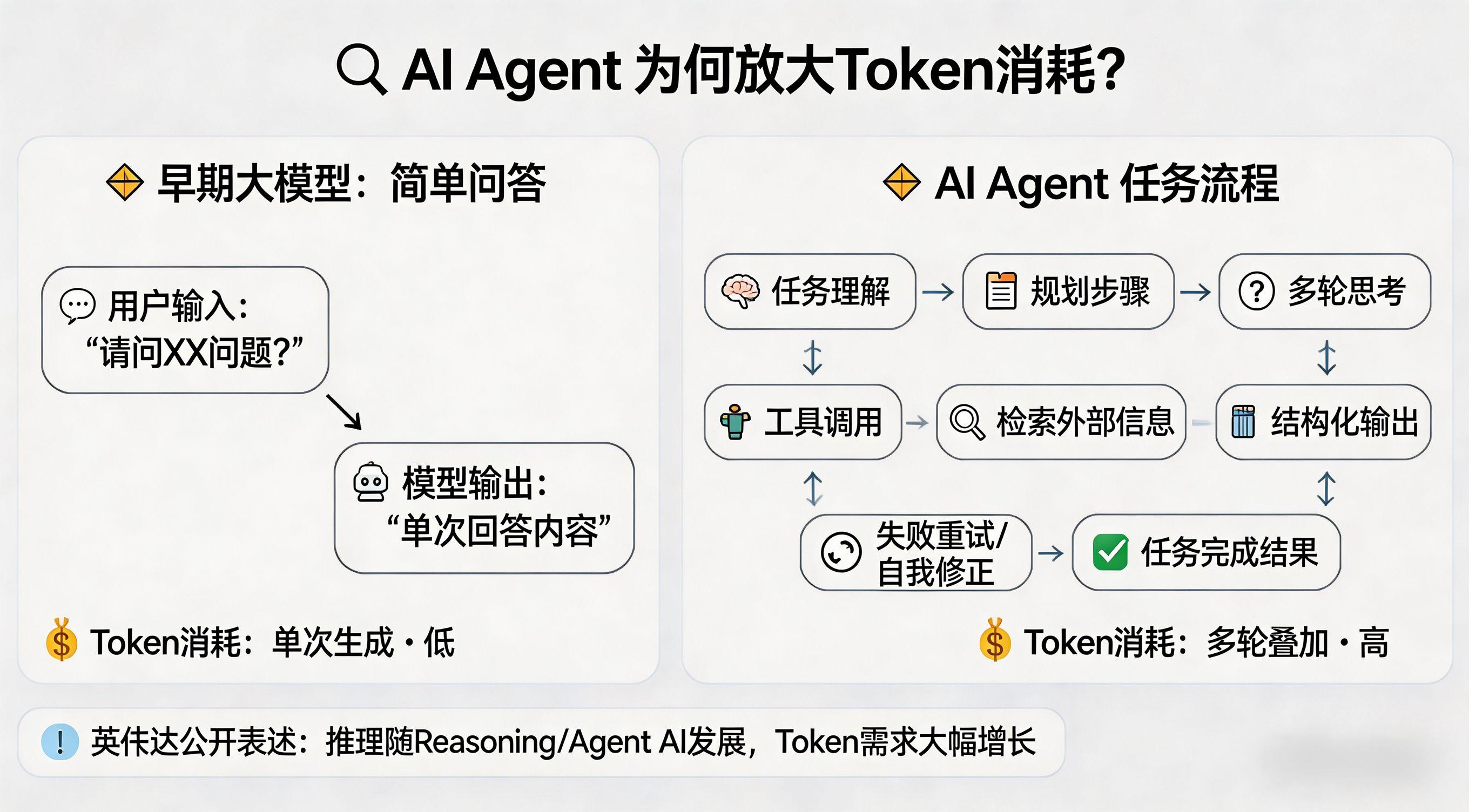
五、什么是 Token 出海?
1. 基本定义
所谓 Token 出海,可以理解为:
中国的大模型能力和推理能力,通过 API 或云服务形式交付给全球用户,并按 token 使用量收费。
它本质上是一种新的数字服务出口模式:
- 模型和算力可能部署在国内或中国厂商控制的节点
- 海外开发者通过 API 调用
- 商业结算围绕 token 发生
从产品视角看,这和传统 SaaS、云 API 类似;
但从产业视角看,它意味着:
出口的不再只是软件,也不再只是硬件,而是可计量的“智能服务”。
2. 为什么 Token 出海有现实基础?
因为全球模型生态已经高度 API 化。
开发者越来越习惯通过统一接口调用不同模型,并直接比较价格、上下文长度、稳定性和效果。OpenRouter 的公开页面和年度使用数据也说明,全球模型调用已经越来越以 token 使用量来衡量,而且中国模型在其平台上的份额在 2025 年下半年明显上升,一些周度区间曾接近总使用量的 30%。
这至少说明一件事:
国际市场已经存在按 token 购买模型能力的成熟消费习惯。
3. Token 出海比拼什么?
不是只比模型参数,而是比整套系统能力:
- 推理成本
- 电力和基础设施效率
- API 稳定性
- 上下文长度与延迟表现
- 多区域交付能力
- 合规和本地化能力
所以 Token 出海并不是“把模型放到国外平台上架”这么简单,背后拼的是算力、平台、工程化和运营体系。
六、为什么说 Token 是 AI 时代的新“硬通货”?
因为它第一次把三件事统一了:
- 技术侧:模型到底处理了多少内容
- 工程侧:系统到底消耗了多少资源
- 商业侧:服务到底创造了多少收入
这就是 Token 真正有意思的地方。
以前行业讨论 GPU、显存、带宽、FLOPS,这些都很重要,但它们更偏底层资源。
而 Token 更接近最终可交付的单位,因此更容易成为产业层的共同语言。
从这个意义上说,Token 不只是技术术语,而是 AI 时代很可能会长期存在的“价值计量单位”。
七、结语
如果把全文压缩成一句话,那就是:
Token 是模型的基本处理单位,Token 工厂是面向推理时代的高效产能组织方式,Token 出海则是这种产能走向全球市场的商业化路径。
所以未来 AI 产业真正的竞争,可能不再只是:
- 谁的 GPU 更多
- 谁的机房更大
- 谁的峰值算力更高
而是:
- 谁能更快地产生 token
- 谁能用更低功耗产生 token
- 谁能以更低成本交付 token
- 谁能把 token 变成全球化收入
这也解释了为什么最近两年,行业叙事正在从“算力”逐步转向“Token”。
因为真正值钱的,越来越不是硬件本身,
而是硬件背后持续产出的 Token 能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)