从零开始学知识图谱|大模型知识库构建实战教程
知识图谱行业价值、大模型知识库痛点、图谱赋能意义
2026年,大模型已经无处不在,但“幻觉”(hallucination)仍是企业落地的最大杀手:金融风控、医疗问诊、客服机器人动辄编造事实,直接导致合规风险和信任崩盘。
知识图谱(Knowledge Graph) 的核心价值正是结构化知识:把碎片化数据变成“实体-关系-属性”的三元组网络,让大模型“先查图谱再回答”。
- 行业价值:支持复杂多跳推理、知识溯源、实时更新,广泛用于推荐系统、智能搜索、企业大脑。
- 大模型痛点:纯向量RAG召回率低、无法处理逻辑关系;知识图谱+大模型(GraphRAG)可将准确率提升40%以上。
- 图谱赋能意义:把大模型从“概率生成器”变成“可信知识引擎”,真正实现企业级私有化落地。
核心知识点:知识图谱不是“又一个数据库”,而是大模型的长期记忆和推理大脑。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可
模块一:底层原理精讲(实体/关系/属性核心概念、知识表示、图存储逻辑、知识推理)
1.1 实体/关系/属性核心概念
- 实体(Entity):现实世界中的“东西”,如“唐宇迪”“知识图谱”“Neo4j”。
- 关系(Relation):实体间的连接,如“唐宇迪 教授 知识图谱”。
- 属性(Attribute):实体的描述信息,如“唐宇迪 年龄 35”。
通俗原理:知识用**三元组(h, r, t)**表示(head实体-关系-tail实体),无数三元组组成图谱。
图文示意:典型知识图谱实体-关系网络(供应链示例)。
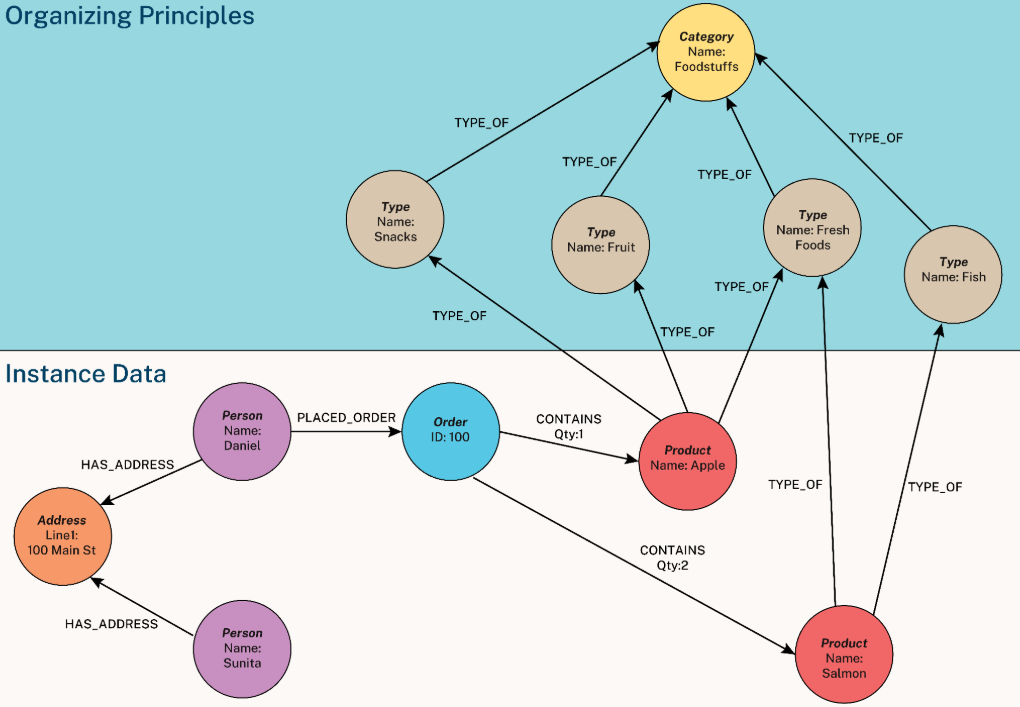
必记要点:实体必须唯一(用唯一ID或URI),关系有方向,属性可多值。
1.2 知识表示
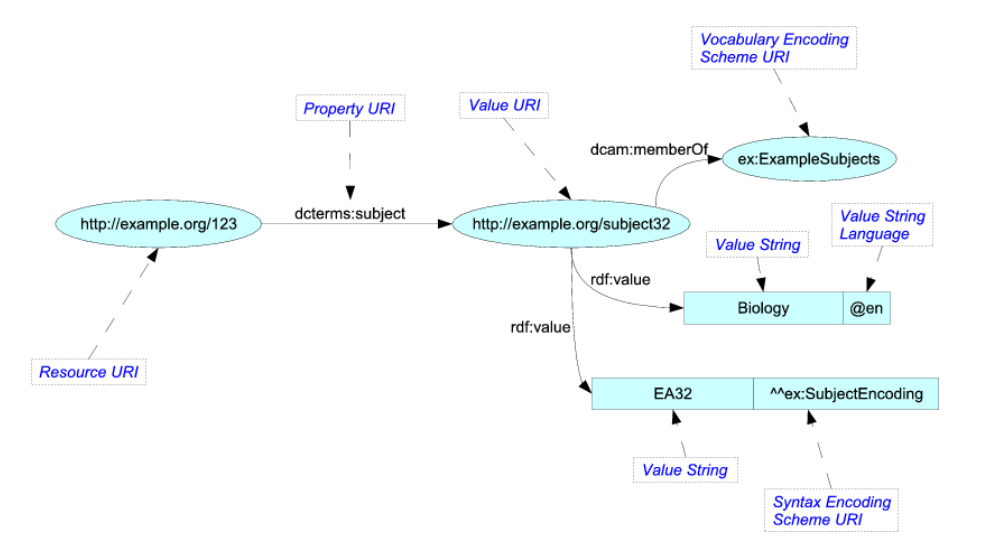
早期用RDF(Resource Description Framework)三元组,现在主流是属性图(Property Graph):节点和边都可以带属性,更灵活。
图文示意:RDF vs Property Graph对比。
1.3 图存储逻辑
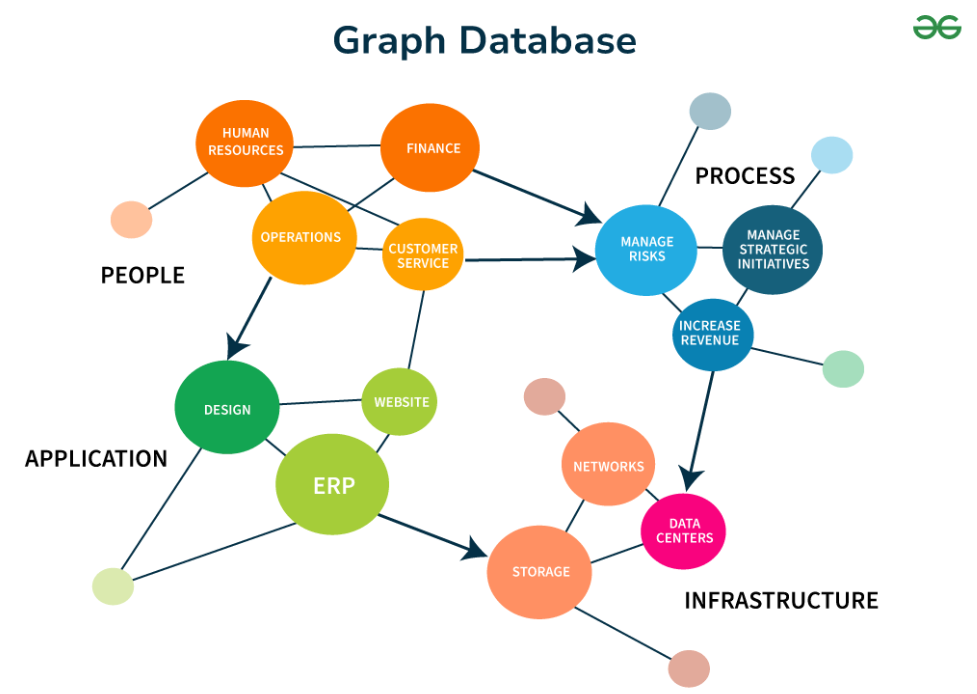
图数据库以“节点-关系-属性”原生存储,支持毫秒级多跳查询,远优于关系型数据库。
图文示意:Neo4j图存储结构。
1.4 知识推理
原理:通过图遍历(Path)、规则(Rule)和嵌入(Embedding)推导出隐含知识,如“如果A是B的父亲,B是C的父亲,则A是C的祖父”。
图文示意:知识推理示例(多跳路径)。
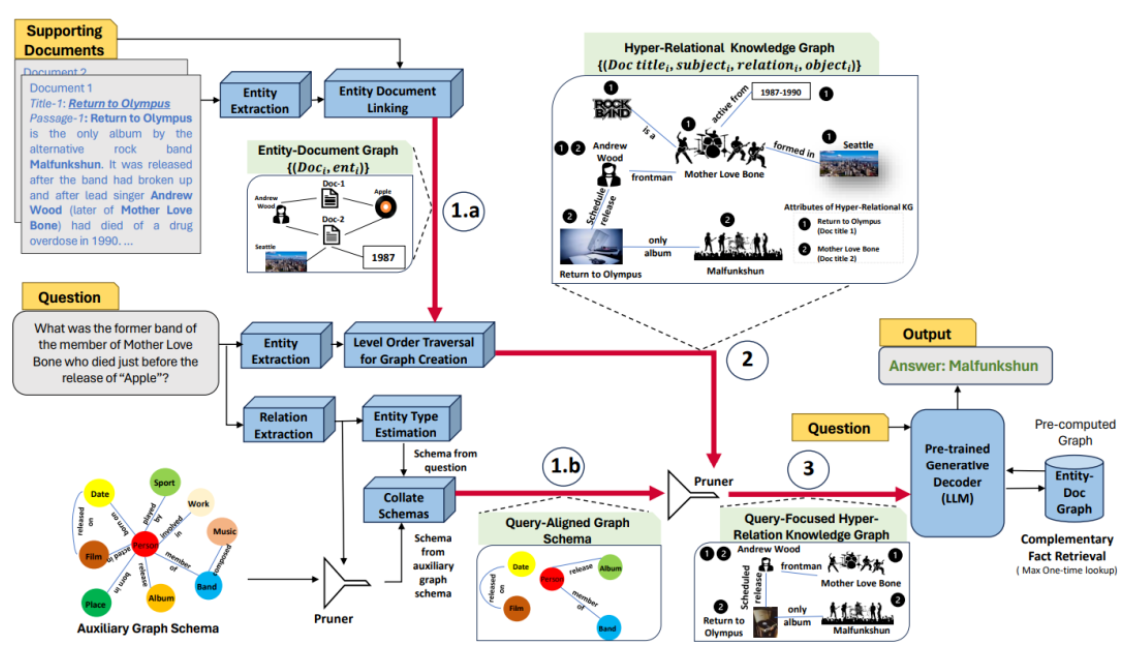
核心知识点:推理让知识图谱“活”起来,是大模型RAG的灵魂。
模块二:技术栈选型解析(图数据库对比、抽取工具、大模型对接方案)
2.1 图数据库对比(2026最新)
| 数据库 | 模型 | 查询语言 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|---|
| Neo4j | Property Graph | Cypher | 生态最完善、可视化强 | 社区版规模有限 | 企业主力、学习首选 |
| TigerGraph | Distributed | GSQL | 分布式分析极强 | 学习曲线陡 | 大规模实时推荐 |
| JanusGraph | Property Graph | Gremlin | 开源免费、多后端 | 部署稍复杂 | 成本敏感项目 |
| NebulaGraph | Distributed | nGQL | 高性能、存储分离 | 生态较新 | 海量数据 |
选型原则(必记):零基础首选Neo4j,Cypher语法像SQL,上手最快。
2.2 抽取工具
- 传统:spaCy + StanfordNLP(规则+统计)
- 大模型时代:LLM Prompt + LangChain/LlamaIndex(零样本抽取,精度更高)
2.3 大模型对接方案
主流:GraphRAG(Neo4j官方)+ LangChain/LlamaIndex。
图文示意:LLM + 知识图谱RAG全流程。
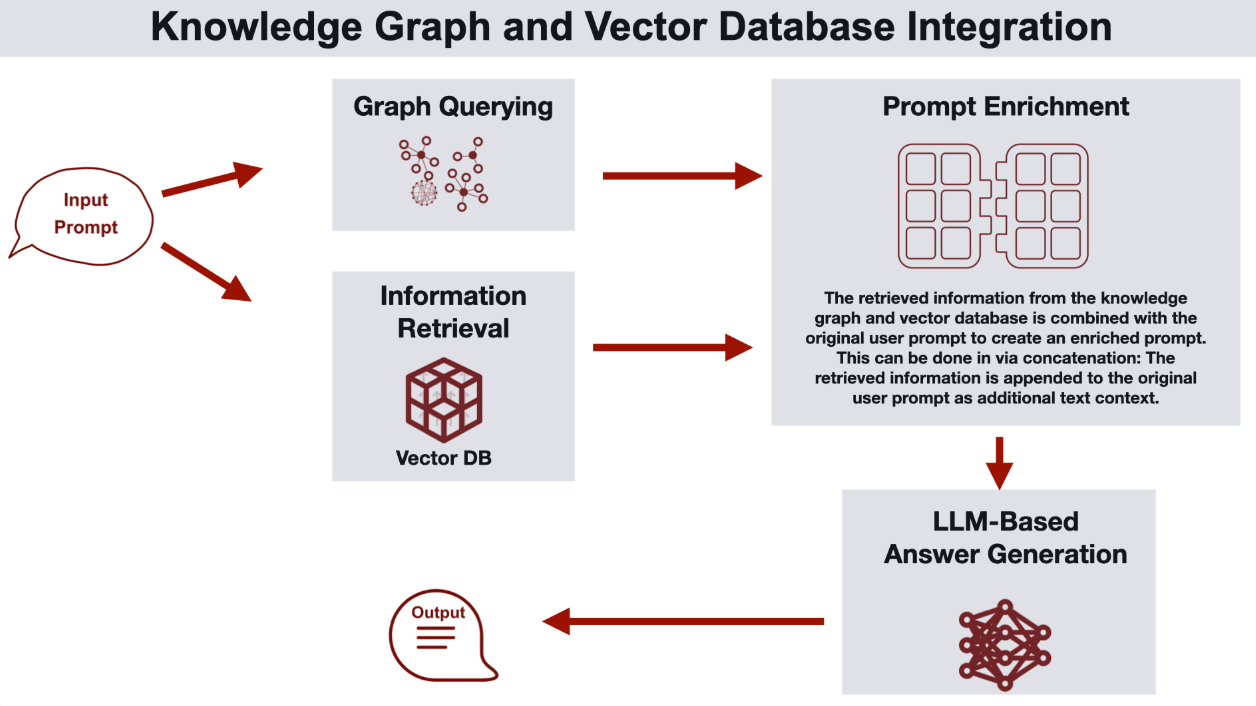
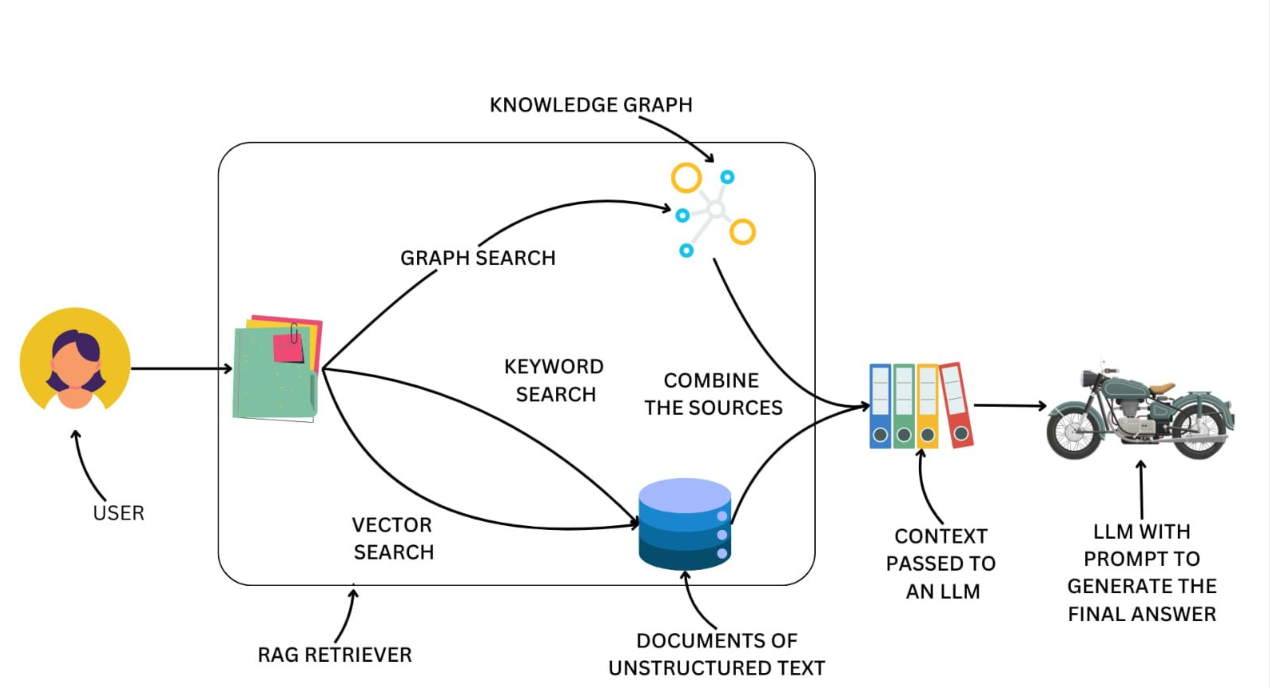
核心知识点:大模型负责“抽取+推理”,图数据库负责“存储+查询”,二者结合才是王道。
模块三:知识库全流程构建(数据清洗、知识抽取、图谱融合、入库存储)
3.1 数据清洗
用Pandas + 正则清洗PDF/Excel/网页数据,去重、标准化。
3.2 知识抽取(LLM + Prompt)
核心代码(LangChain + OpenAI,逐行解析):
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = PromptTemplate(
input_variables=["text"],
template="""从以下文本中抽取实体、关系和属性,以JSON格式输出:
实体: [实体1, 实体2...]
关系: [(实体1, 关系, 实体2), ...]
属性: {实体: {属性名: 值, ...}}
文本: {text}"""
)
chain = LLMChain(llm=llm, prompt=prompt)
text = "唐宇迪是资深AI讲师,专注知识图谱研发。"
result = chain.run(text)
print(result) # 输出JSON三元组
必记要点:Prompt中必须要求“唯一实体ID”和“置信度”,避免幻觉。
3.3 图谱融合(Entity Linking)
相同实体(如“唐宇迪”在多处出现)合并成一个节点,用模糊匹配 + LLM判断。
3.4 入库存储(Neo4j Cypher)
完整代码(py2neo或官方driver):
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
def create_graph(tx, entity1, relation, entity2, props):
tx.run("""
MERGE (a:Entity {name: $e1})
MERGE (b:Entity {name: $e2})
MERGE (a)-[r:RELATION {type: $rel}]->(b)
SET r += $props
""", e1=entity1, e2=entity2, rel=relation, props=props)
with driver.session() as session:
session.execute_write(create_graph, "唐宇迪", "专注", "知识图谱", {"since": 2023})
图文示意:完整构建流水线。
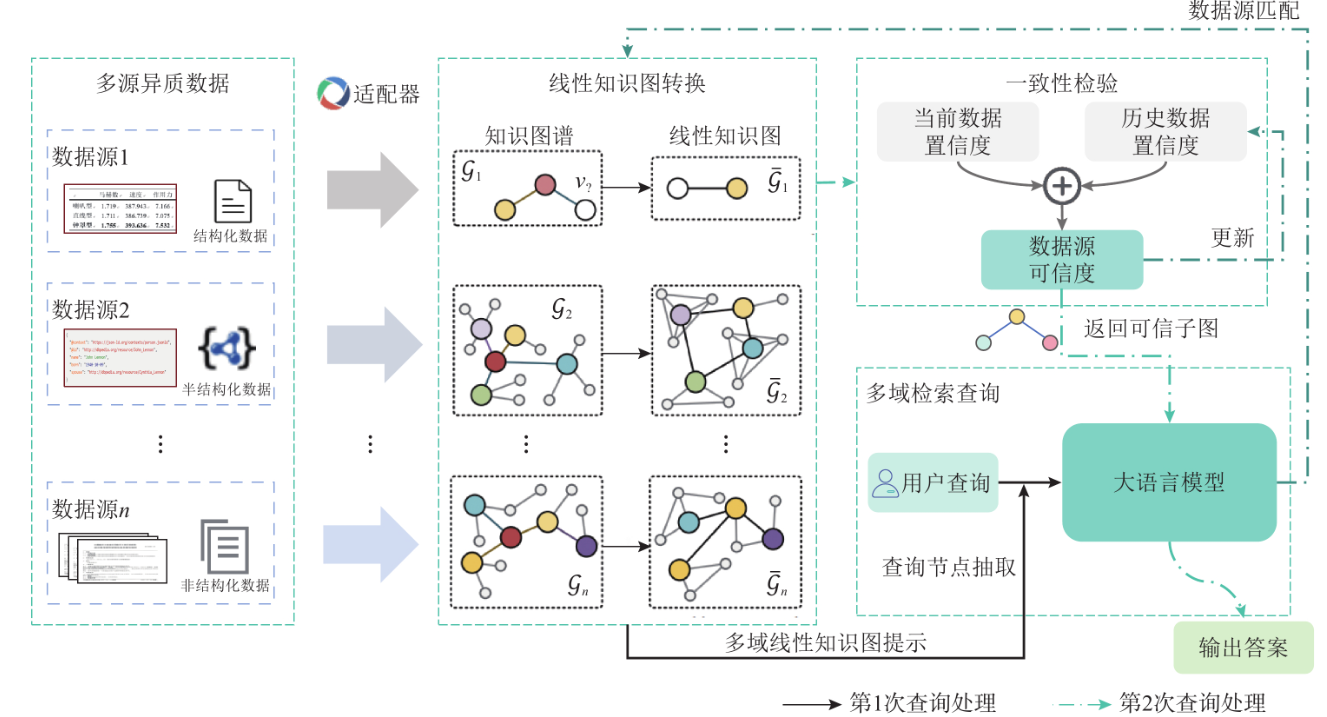
模块四:大模型对接+优化调试+避坑经验+进阶路线
4.1 大模型对接(GraphRAG)
用Cypher查询图谱结果 + LLM生成自然语言答案。
代码示例(LangChain + Neo4j):
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
graph = Neo4jGraph(url="bolt://localhost:7687", username="neo4j", password="password")
chain = GraphCypherQAChain.from_llm(llm=llm, graph=graph, verbose=True)
print(chain.run("唐宇迪专注什么领域?"))
4.2 优化调试
- 索引:创建实体唯一索引加速查询。
- 向量索引:结合向量搜索实现混合检索。
- 监控:Neo4j Browser + APOC插件可视化。
4.3 Top 10避坑经验(血泪史)
- 实体不唯一 → 出现重复节点,用MERGE而非CREATE。
- 关系方向错 → 画图先确认方向。
- Prompt不加JSON格式 → LLM输出乱套。
- 大模型温度设太高 → 抽取幻觉严重,设0.0。
- 不做融合 → 图谱碎片化。
- Cypher不加LIMIT → 查询爆炸。
- 忘记事务 → 数据不一致。
- 向量嵌入模型不匹配 → 检索失效。
- 生产不加权限控制 → 安全漏洞。
- 不监控查询耗时 → 慢查询拖垮系统。
4.4 进阶路线(规划师视角,3个月速成)
- 第1个月:掌握Neo4j Cypher + 手动构建小型图谱。
- 第2个月:LLM抽取 + GraphRAG完整系统。
- 第3个月:图谱融合 + 多源数据 + 推理应用。
- 6个月后:Graph Neural Network + 动态知识更新 + 企业级私有化。
- 12个月目标:构建公司级知识大脑,成为“知识图谱与大模型专家”。
对于需要系统学习 需要我们规划答疑和就业指导的朋友 可以扫码了解详情

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)