让大模型写 Verilog,不靠一次猜对:EvolVE 用进化搜索改写 RTL 生成与优化
基于论文 EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization 的技术解读
让大模型写 Python,很多时候像让它顺着一条路往前推理。让大模型写 Verilog,问题马上变得尖锐。RTL 描述的不是一段顺序执行的程序,而是一组在时钟驱动下并行工作的硬件结构。一个信号晚一个周期、一个复位条件漏掉、一个组合路径没有收住,仿真结果就可能完全跑偏。
EvolVE 这篇论文抓住的正是这个矛盾。大语言模型有代码生成能力,却很难只凭一次回答稳定写出可综合、功能正确、PPA 表现还不错的 Verilog。作者没有选择继续堆模型参数或依赖更多专有训练数据,而是把 RTL 生成改造成一个可评估、可回退、可继续探索的搜索过程。模型负责提出候选设计,测试和综合工具负责给出反馈,搜索策略负责决定下一步往哪里走。
芯片设计卡住的地方,不在写几行代码
Verilog 在芯片设计里仍然重要,因为它给工程师留下了足够细的控制粒度。高层综合可以缩短开发周期,但很多性能敏感的模块最终还是要回到 RTL 层,仔细处理流水、状态机、存储访问、时序约束和面积开销。论文把前端 IC 设计的核心目标概括为功耗、性能、面积之间的平衡,也就是常说的 PPA。
手写 RTL 的成本高,不只是因为语法繁琐。真正难的是,硬件设计同时受到功能正确性、并行时序、可综合性和物理实现代价约束。软件里的一个循环,在硬件里可能对应展开的计算阵列、复用的数据通路、寄存器切分和控制状态。LLM 习惯沿着自然语言和顺序代码做下一 token 预测,这种能力和 Verilog 所需的周期级并发思维并不天然匹配。
过去两类工作试图补上这个缺口。一类是训练更懂 RTL 的专用模型,例如 RTLCoder、ScaleRTL、CodeV-R1 等,把 Verilog 数据和推理轨迹喂给模型。另一类是把 LLM 放进更复杂的代理流程,让不同角色处理分解、实现、测试、修复和优化。问题在于,高质量 Verilog 数据很有限,许多工业级设计不会开源;代理流程如果缺少可靠反馈,也容易在局部错误里反复打转。
EvolVE 的思路更接近硬件工程师的日常调试。先写一个版本,跑测试,看哪里错,再改一版。区别在于,它把这个循环系统化,把每个候选 Verilog 程序看成搜索树或进化链上的节点。节点里保存代码、得分和诊断反馈。只要评估器能判断哪个候选更接近目标,模型就不必一次写对,而可以在测试时计算预算内持续进化。
这也是论文没有把重心放在提示词技巧上的原因。对 Verilog 来说,一个更长的提示词也许能减少语法错误,却很难保证所有周期边界、握手协议和数据相关都正确。把问题放进搜索框架后,错误会被测试暴露出来,模型下一轮看到的是具体失败信号,而不是笼统的请改进代码。这个变化让 LLM 从单次生成器变成闭环系统里的一个变异算子。
EvolVE 把 Verilog 生成改造成搜索问题
论文给出的统一框架并不复杂。输入是自然语言规格和测试环境,LLM 先生成初始代码,评估器运行测试并给出分数和反馈。接下来,搜索策略从已有节点里选出父节点,让 LLM 基于父节点代码和反馈产生变异版本。新代码再交给评估器,得分更好的候选会进入归档。循环结束后,系统返回当前最优 Verilog。
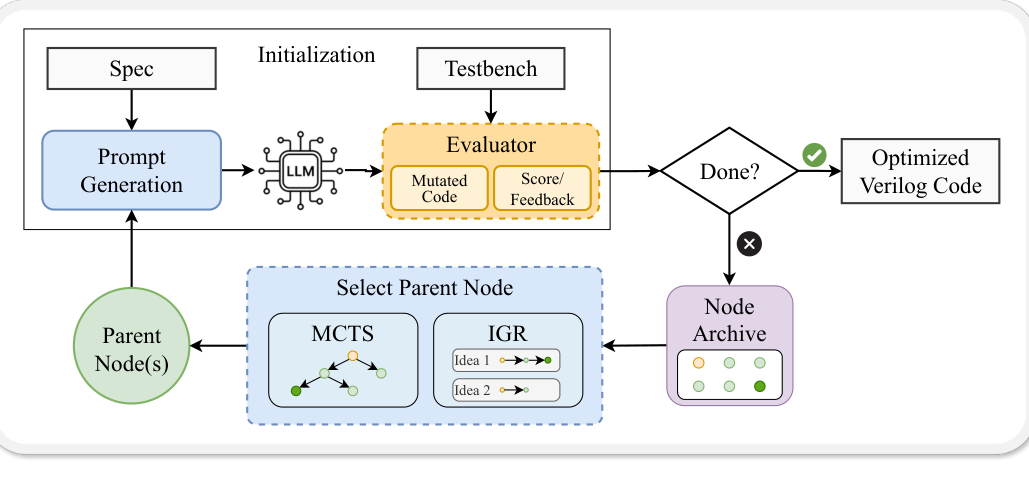
图 1:EvolVE 将规格、LLM 生成、测试反馈和节点归档放进同一个进化闭环。
来源:原论文 Figure 1。
生成任务和优化任务使用不同的评分方式。做功能生成时,分数主要来自测试通过率,编译或仿真失败会被打到很低。做 PPA 优化时,候选设计必须先通过全部测试,之后再比较面积和延迟的乘积。论文用面积乘延迟作为快速代理指标,因为开源工具 Yosys 和 Iverilog 的评估速度比 Synopsys VCS 和 Design Compiler 这类商业流程快超过 30 倍,而且面积改善通常和功耗改善有相关性。
这个设定很务实。真实 PPA 评估代价高,如果每一个候选版本都完整跑商业综合、时序和功耗分析,搜索很快就会被成本拖垮。EvolVE 先用较轻量的代理目标筛掉大量候选,再用商业工具做严谨验证。这样既让搜索跑得起来,也保留了与芯片实现相关的判断。
节点反馈也按任务变化。仿真失败时,反馈主要是错误信息。功能生成已经通过部分测试时,反馈会包含设计摘要,帮助模型理解当前实现的结构。PPA 优化时,反馈还会加入优化建议和设计摘要,让模型知道应该朝减少面积、缩短延迟或调整数据流的方向修改。搜索不是盲目随机改代码,而是每一步都把评估结果压回提示上下文。
框架里真正决定搜索风格的是两种策略:Idea-Guided Refinement 和 Monte Carlo Tree Search。论文简称它们为 IGR 和 MCTS。作者的结论很清晰,MCTS 更适合追求功能正确性,IGR 更适合 PPA 优化。
两条搜索路径:一条多起点,一条沿树深挖
IGR 的做法像同时开几条设计路线。LLM 先提出一组高层架构想法,必要时还能从相关论文里检索微架构知识。每个想法都生成一条独立 refinement 链,再沿着这条链做若干轮局部修改。它强调设计空间的广度,适合 PPA 优化这种不止修 bug 的任务。一个模块可能有多种数据流、多种缓冲策略、多种控制路径,早期的架构方向会明显影响后面的面积和延迟。
MCTS 的节奏更像沿着搜索树不断扩展有希望的分支。每个节点都保存访问次数和累计质量,算法用 UCT 规则在探索新分支和利用高分分支之间做权衡。叶子节点被选中后,LLM 根据该节点的代码和设计摘要生成新候选,评估分数再回传到祖先节点。对功能生成来说,这种策略很合适,因为很多 RTL 错误具有局部可修复性,沿着高分路径深挖,往往能把接近正确的代码推到完全通过。
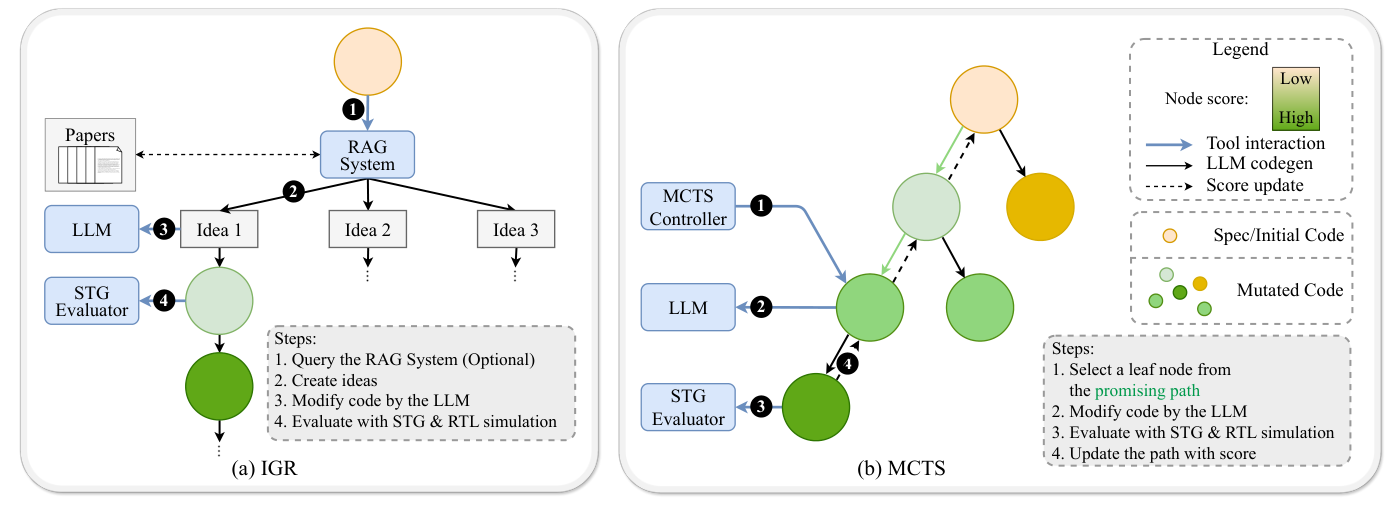
图 2:IGR 先生成多个设计想法再分别细化,MCTS 则在搜索树中选择高潜力节点继续扩展。
来源:原论文 Figure 2。
这两条路径背后的差别,正好对应硬件设计里的两类工作。调功能时,工程师常常围绕某个版本查波形、改状态机、补边界条件,MCTS 的利用能力会更强。做 PPA 时,工程师会比较完全不同的微架构,例如换数据复用方式、改缓冲层次、重排流水级,IGR 的多起点探索更容易跳出局部最优。
论文还强调了差分编辑。IGR 在每条 refinement 链里采用类似 Aider 的编辑方式,让模型基于已有代码做局部修改,而不是每次整文件重写。对于 RTL,这一点很关键。完整重写容易引入新的端口错误、时序错误和风格漂移;保留稳定代码状态,更接近工程师逐步 patch 的工作方式。
从搜索预算看,IGR 和 MCTS 也服务于不同问题。IGR 在论文实验中设置为 60 个初始想法,每个想法细化 5 步,总预算同样是 300 个节点。MCTS 则从根节点出发,每次扩展 3 个子节点,让高分路径获得更多访问机会。前者把预算摊到多个起点,后者把预算集中到可能正确的分支。这个差别解释了为什么作者在功能生成上偏向 MCTS,在优化任务上偏向 IGR。
STG 把测试从裁判变成导航
只有搜索策略还不够。搜索需要反馈,而且反馈不能太粗。许多 Verilog benchmark 只告诉模型通过或失败,测试激励也可能覆盖不足。一个候选设计也许只错了一个状态转移,另一个候选可能连复位都不对,如果二者都拿到失败,搜索策略就很难判断该保留谁。
EvolVE 引入 Structured Testbench Generation,简称 STG。它先解析待测模块端口,按命名规则把信号分成时钟复位、控制信号和数据通路。像 clk、rst、valid、ready 这些工业常见命名会被确定性识别,不需要再让 LLM 猜测端口语义。
测试激励的生成也分层处理。控制信号位宽不超过 8 时,STG 会穷举全部状态;位宽更大时,转为受约束随机采样,避免仿真爆炸。数据通路则加入零值、最大值、交替 bit 等边界样本,再配合随机采样。生成的 testbench 遵守 IEEE 2005 Verilog,可在 Icarus Verilog 和商业仿真器中运行。
关键变化在分数。STG 不只返回成败,而是按测试向量通过比例给出连续得分。这样一来,差一点正确的设计会被保留下来,明显错误的设计会被淘汰。对搜索算法来说,这相当于从黑白裁判变成带梯度的导航信号。
硬件验证里还有一个常见难点:时序对齐。组合逻辑和时序逻辑的错误不能混在一起看,否则模型很难判断是计算公式错了,还是寄存器更新晚了一拍。STG 在复位后、时钟边沿后短暂延迟等关键时刻触发检查,并把待测设计与 golden reference 做严格对齐。论文把这种细粒度正确率称为 functional gradient,它让搜索能够沿着部分正确的方向走,而不是反复丢弃所有失败版本。
功能生成:MCTS 让正确率继续爬升
论文在 VerilogEval v2、修订后的 Mod-VerilogEval v2 和 RTLLM v2 上评估功能生成能力。模型包括 Siliconmind-7B、GPT-OSS-120B、DeepSeek-R1-FP4,以及 API 访问的 Gemini-2.0-Flash。统一预算是 300 个计算节点,LLM temperature 设为 0.6,MCTS 扩展率为 3,探索常数为 1.4。
最强结果来自 DeepSeek-R1-FP4-MCTS。在原始 VerilogEval v2 上,它用 15 个节点就达到 94.2%,已经接近 VerilogCoder 使用 GPT-4-Turbo 和 100 节点报告的 94.2%。预算扩大到 300 节点后,DeepSeek-R1-FP4-MCTS 达到 98.1%,RTLLM v2 达到 92.0%。论文还显示,Siliconmind-7B 这类较小模型也能受益,VerilogEval v2 从基线首轮 82.1% 提升到 MCTS 300 节点下的 92.3%。
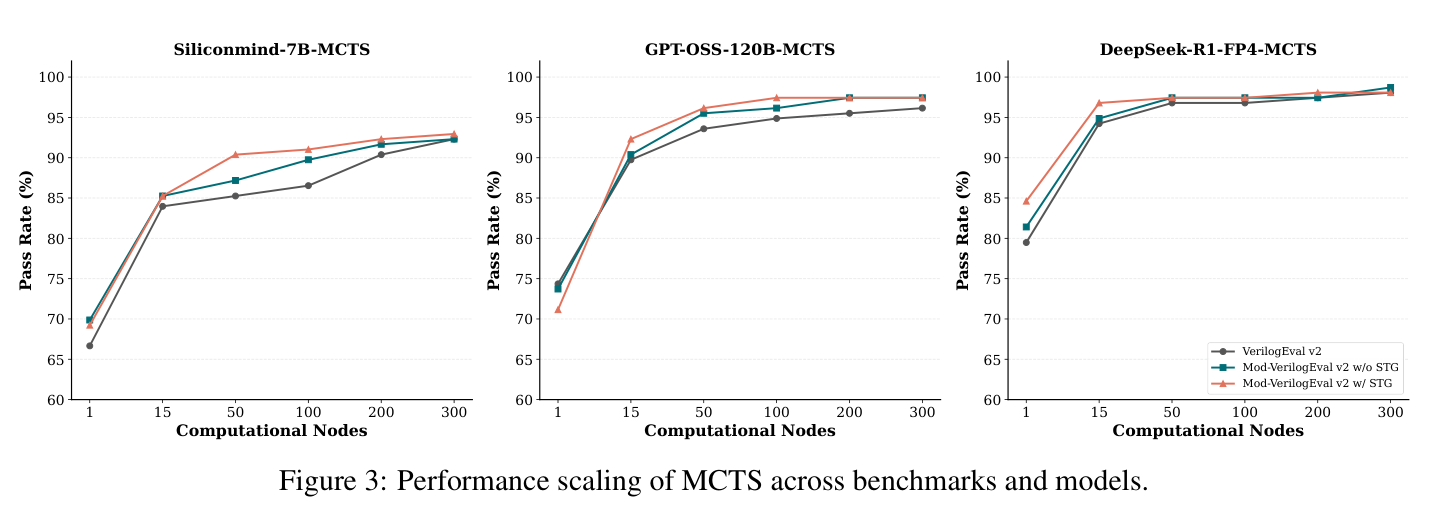
图 3:随着计算节点增加,MCTS 在多个模型和 benchmark 上继续提升通过率。
来源:原论文 Figure 3。
这些曲线说明 EvolVE 并不是简单地多抽样几次。对于强模型,搜索很快收敛。论文记录 DeepSeek-R1-FP4 在第一个节点就解决了 84.6% 的问题,平均只需 2.49 个节点。对于基础能力较弱的模型,搜索预算会被用在更难样本上,正确率随节点数继续上升。
STG 的作用体现在成本上。它在 300 节点上能保持接近的最终准确率,但收敛路径更短。以 DeepSeek-R1-FP4 为例,Mod-VerilogEval v2 上平均解题节点数从 4.78 降到 2.49,输出 token 从约 3.88 万降到 1.54 万。对实际部署来说,这种节省不只是账单问题,也意味着调试周转时间更短。
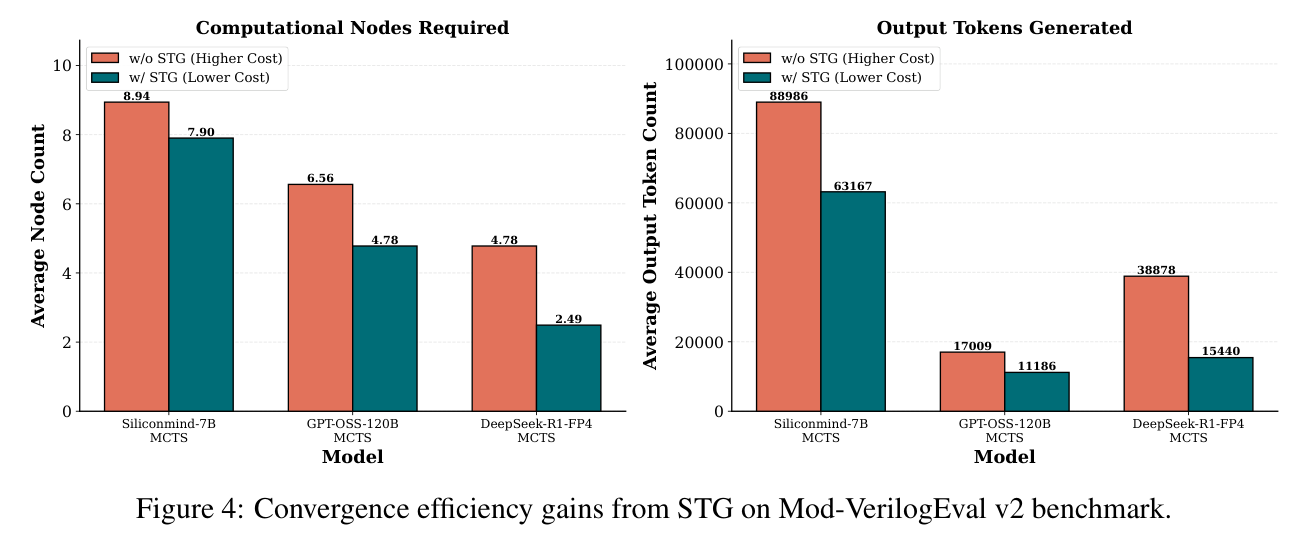
图 4:STG 明显降低平均节点数和输出 token,主要收益来自更细的测试反馈。
来源:原论文 Figure 4。
PPA 优化:IC-RTL 把问题拉近真实芯片设计
功能正确只是第一关。很多现有 benchmark 的模块较小,标准综合工具就能做掉不少优化,难以衡量 LLM 是否真的懂硬件结构。论文因此提出 IC-RTL benchmark,任务来自台湾大学集成电路设计竞赛和专家构造的复杂设计。它要求模型处理图像、矩阵、组合优化、编码和距离变换等更接近工程场景的 RTL。
IC-RTL 的意义在于,它把问题从能不能写出一个可运行模块,推进到能不能写出一个更像工程设计的模块。一个小型计数器或简单状态机,模型通过几轮修复就可能解决;但图像缓冲、矩阵阵列、Huffman 树和距离变换会把存储层次、控制复杂度、流水阻塞和数据相关同时摆到台面上。这样的任务更能区分语法熟练和架构优化能力。
IC-RTL 包含六类任务:LBP 需要在 128 × 128 灰度图上计算 3 × 3 局部纹理,核心是减少存储访问;GEMM 要设计脉动阵列矩阵乘法,关键是数据复用和同步;CONV 包含 3 × 3 卷积、偏置、ReLU 和 2 × 2 最大池化;JAM 要遍历 8 个工人和 8 个工作的 8! 种排列;HC 要在硬件里构造 Huffman 编码;DT 则要处理二值图像的前向和后向距离变换。
在 PPA 实验中,作者使用 DeepSeek-R1-FP4 加 IGR,并用 Synopsys Design Compiler 在 TSMC 180nm 工艺节点下综合验证。结果显示,EvolVE 在几类复杂结构上都有可观察收益。Q2_GEMM 延迟降低 12%,面积基本持平且功耗下降。Q4_JAM 面积降低 31%,功耗降低 26%,综合 PPA 改善 36%。Q5_HC 的峰值 PPA 改善达到 66%,主要来自排序网络和决策树结构的重组。整体几何平均 PPA 改善为 17%。
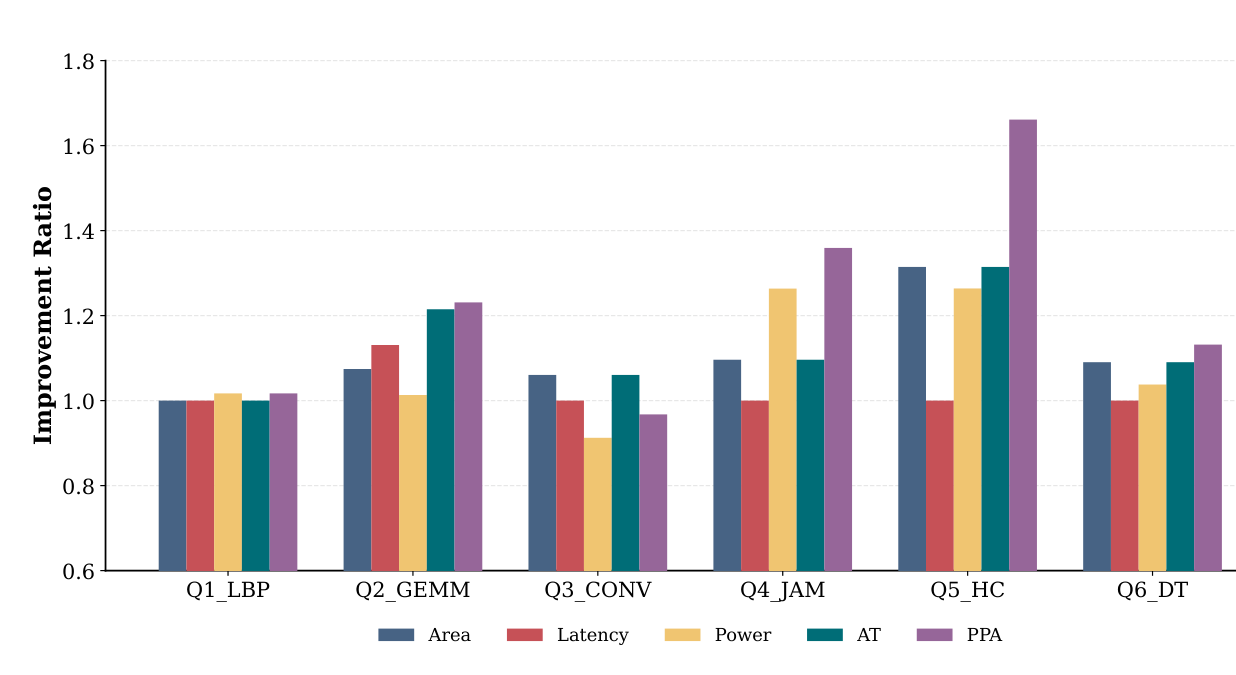
图 5:IC-RTL 上的 PPA 相对改进,Q5_HC 和 Q4_JAM 展现出最明显收益。
来源:原论文 Figure 5。
并非所有任务都会显著变好。Q1_LBP 的优化版本和人工基线几乎重合,面积和延迟差异在 1% 以内。论文把它解释为人工实现已经位于搜索空间的局部最优附近。Q3_CONV 则呈现面积和功耗的取舍,面积下降 6%,延迟保持不变,但功耗从 0.45 mW 升到 0.50 mW,抵消了一部分综合收益。
这个结果也提醒读者,进化搜索不是自动保证胜过专家。它更像把一批候选实现系统地摆到评估器面前,让工具和模型一起筛选。人工基线已经很强时,搜索可能只能找到近似解;设计空间包含复杂排序、控制和数据复用时,系统才更容易挖出人工实现之外的结构改进。
更有意思的是定向设计空间探索。以 Q5_HC 为例,如果提示模型优先减少面积,EvolVE 在 3ns 时钟下把面积从 2.39 × 10^4 微米平方降到 1.82 × 10^4 微米平方,延迟没有恶化。如果提示模型优先减少周期,它把执行时间从 429ns 降到 339ns,但面积从约 2.4 × 10^4 微米平方增加到约 2.9 × 10^4 微米平方。这说明系统能沿着不同约束找到不同 Pareto 点,而不是只吐出一个固定答案。
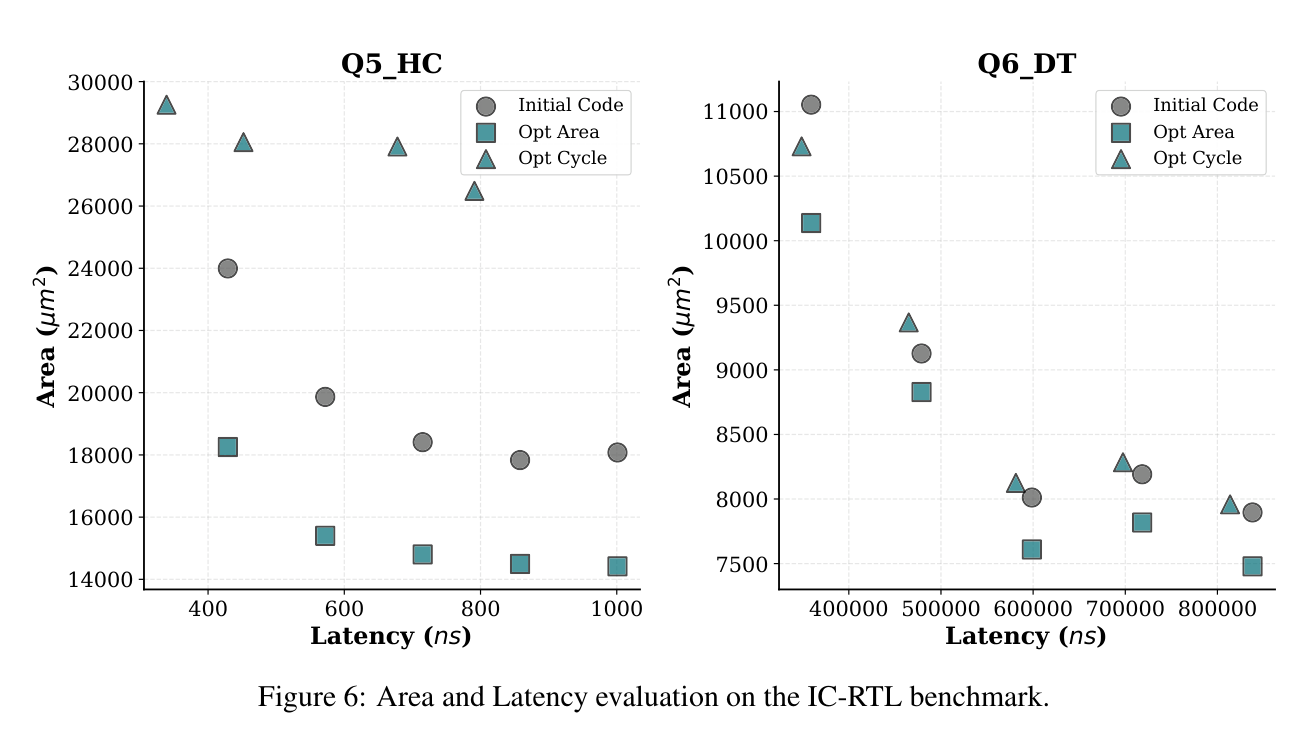
图 6:Q5_HC 和 Q6_DT 的面积延迟分布展示了面积优先与周期优先两种优化方向。
来源:原论文 Figure 6。
GEMM 案例显示它不只是修 bug
消融案例里的 GEMM 很能说明 EvolVE 的潜力。人工基线采用 output-stationary 脉动阵列,用 4 × 4 矩阵乘法分解可变尺寸矩阵,并设置输入和权重 reshape buffer 来配合数据流。EvolVE 在这个基础上先做微架构级 refinement,把 n × n 乘法所需的 2n − 1 行缓冲压到 n 行,依靠多路选择减少冗余数据暂存。
论文报告,在 4ns 时钟约束下,这轮优化把总延迟从 1448ns 降到 1280ns,面积从 339,266 微米平方降到 315,770 微米平方。更长的进化搜索又把结构从纯 output-stationary 推向 weight-output stationary hybrid,取消独立权重缓冲,改用直接权重插入和输入广播,延迟进一步降到 776ns。
这类变化已经超出普通语法修复。它涉及数据驻留策略、buffer 规模、PE 阵列间寄存器冗余和关键路径 retiming。对硬件工程师来说,这些才是 RTL 优化里真正耗时间的部分。EvolVE 证明的一点是,大模型在搜索和评估约束下,有机会从代码生成工具变成微架构探索助手。
这篇工作的边界在哪里
EvolVE 并没有把 RTL 自动化问题一次解决。论文也明确写到,STG 依赖可执行 golden reference,可能是 C 模型,也可能是 Verilog 参考实现。对全新 IP 来说,参考模型未必现成,验证本身仍然是高成本工作。
PPA 优化 benchmark 仍然稀缺。IC-RTL 往前走了一步,但离完整工业项目还有距离。真实芯片设计还会遇到跨模块约束、存储宏、时钟域、物理布局、DFT、IP 复用和签核流程。EvolVE 当前更像一个能在模块级 RTL 上运行的搜索框架,而不是完整替代设计团队的自动化平台。
还有一个现实问题是可解释性。论文里的 GEMM 案例展示了搜索发现的结构变化,读者能够看到 buffer 被压缩、权重流动方式被调整。但在更大设计里,系统生成的改动可能跨越多个 always 块和状态路径。工程团队如果要采用这类工具,还需要配套的差异解释、波形定位、约束追踪和人工审查流程。
实时 PPA 反馈也需要继续打磨。论文用面积延迟乘积作为快速代理目标,再用商业工具验证最终结果。这条路线合理,但代理目标和最终功耗、时序、面积之间总会存在偏差。未来如果能把更自动化的综合和时序反馈接入搜索闭环,系统对真实设计约束的敏感度会更高。
结语:大模型写 RTL 的关键不只是模型本身
EvolVE 的价值不只在于把某个 benchmark 分数刷高。它给 LLM 辅助芯片设计提供了一种更可靠的组织方式:模型不必被要求一次写出完美 RTL,而是可以在测试、评分、归档和搜索的闭环里逐步逼近可用设计。MCTS 负责把功能错误一点点修到正确,IGR 负责在更宽的架构空间里寻找 PPA 机会,STG 则把验证反馈变成搜索能够理解的连续信号。
对工程实践来说,这种方向比单纯期待更大的模型更有吸引力。Verilog 数据有限,工业设计又很难充分开放,靠训练集覆盖所有硬件模式并不现实。把模型、仿真器、综合工具和搜索算法组合起来,反而更贴近芯片设计的本质:写代码只是开始,评估和迭代才决定设计能否落地。
参考资料
图片部分改编自原论文 EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization,仅用于论文解读与学术交流。文中指标和实验结论均依据原论文内容整理,未对论文之外的数据作扩展推断。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)