【Agent学习】Day01
读研快1年了,感觉除了年龄和焦虑与日俱增,专业学习方面一无所长。咨询师兄之后,决定先自己动手开始学习Agent的搭建,特发此博客记录个人的学习经过。
第一步:用OPEN AI写hello world
注册一个OPEN AI的key,我选择的是国内的Open AI代理网站,大家可以自行选择。
注册后,点击“快速开始”会显示个人自动生成的Key,免费额度是20次
然后创建一个.env的文件用于配置API,之后使用主代码中的函数加载该文件,防止信息直接在主代码中被泄露
OPENAI_API_KEY="sk-xxx(个人申请的Key)"
OPENAI_BASE_URL="https://api.fe8.cn/v1"现在在终端下载OpenAI的相关库(在这里我遇到了一个小问题,我自己的python包存在损坏,所以连接了组内的服务器进行下载)
pip install python-dotenv openai下载成功后创建openai_test.py的python文件,开始实现写hello world的功能
# 加载openai的库
from openai import OpenAI
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
client = OpenAI()
# 我是用户方提问服务方内容为“你是谁”
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{
"role": "user",
"content": "你是谁?"
}
],
)
# 打印openai返回的信息
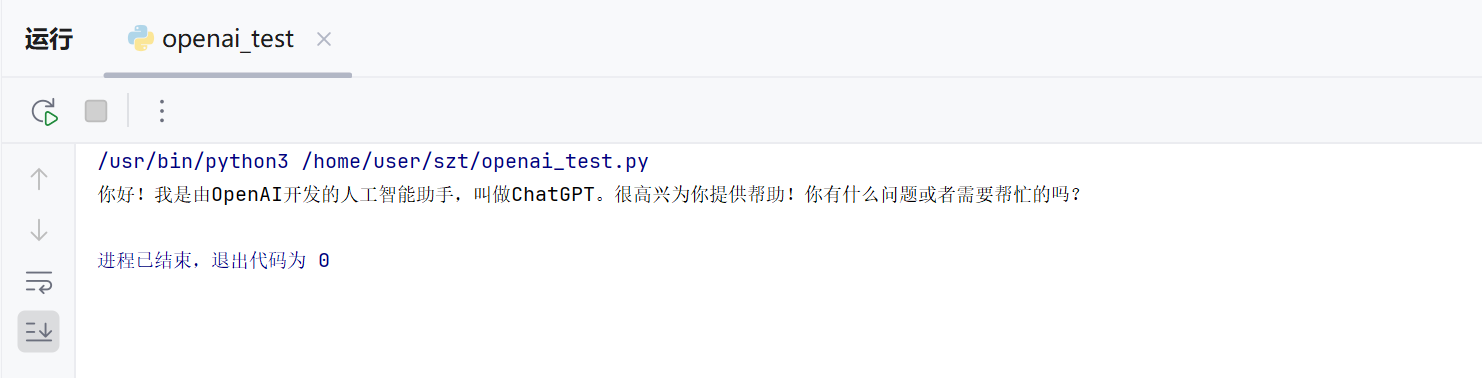
print(response.choices[0].message.content)运行后显示结果:
第二步:了解提示词工程
在openai_test.py代码中出现了一个函数:chat.completions.create()
该函数包含了以下参数:
model:指定使用哪个模型
message:传入大模型的prompt,prompt中有3种角色
- system:系统指令,用于初始化GPT的行为、规定GPT的角色和后续的行为模式
- user:用户输入的信息
- assistant:机器回复,由API根据system和user的消息自动生成
temperature:参数值越小,模型就会返回一个越确定的结果。当需要模型应用于更具有创意性的场景中,可以适当调高参数值使其返回一个更随机的结果
top_k:与temperature一起称为核采样技术,用于控制模型返回结果的真实性
max_token:控制了输入和输出的总token上限

第三步:LangChain的学习
3. 1学习LangChain的框架
LangChain是一个面向大模型的开发框架,共有4层框架,从下到上分别为:
- LangChain的Python和JavaScript库
- 模型I/O封装
- Retrieval数据连接与向量检索封装
- Chain实现系列顺序功能的组合
- Memory上下文的管理能力封装
- Callbacks过程回调函数
- Tools调用外部功能的函数
- Toolkits操作某软件的一组工具集
- Templates:易于部署的参考体系结构
- LangServe:用于将LangChain部署为REST API的库
- LangSmith:开发人员平台
现在开始实现第一个LangChain程序
3.1.1 环境安装(二选一)
pip install langchainconda install langchain -c conda-forge(pip和conda均是用于安装的工具,pip适用于大部分库、conda适用于难以安装的库,可以将pip理解为淘宝,conda理解为京东)
LangChain封装了对于大模型的调用接口,所以我们可以选择使用自己喜欢的大模型用LangChain调用,此处我们选择OpenAI的API调用大模型
pip install -U langchain-openai3.1.2 通过LangChian的接口调用OpenAI对话
import os
#加载.env到环境变量
from dotenv import load_dotenv,find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
response = llm.invoke("你是谁")
print(response.content)
#输出结果:你好!我是ChatGPT,一个由OpenAI开发的人工智能语言模型。我可以帮助回答问题、提供信息、写作建议、翻译语言等等。你有什么需要帮助的吗?3.1.3 通过LangChian实现多轮对话封装
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
from langchain_core.messages import (
AIMessage,#等价于OPENAI接口中的assistant role
HumanMessage,#等价于OPENAI接口中的user role
SystemMessage#等价于OPENAI接口中的system role
)
messages = [
SystemMessage(content="你是[同学小张]的个人助理。你叫[小明]"),
HumanMessage(content="我叫[同学小张]"),
AIMessage(content="好的老板,你有什么吩咐?"),
HumanMessage(content="我是谁")
]
response = llm.invoke(messages)
print(response.content)
#输出的结果:你是同学小张。有什么需要小明帮忙的吗?3.2 学习LangChain的输入输出模块
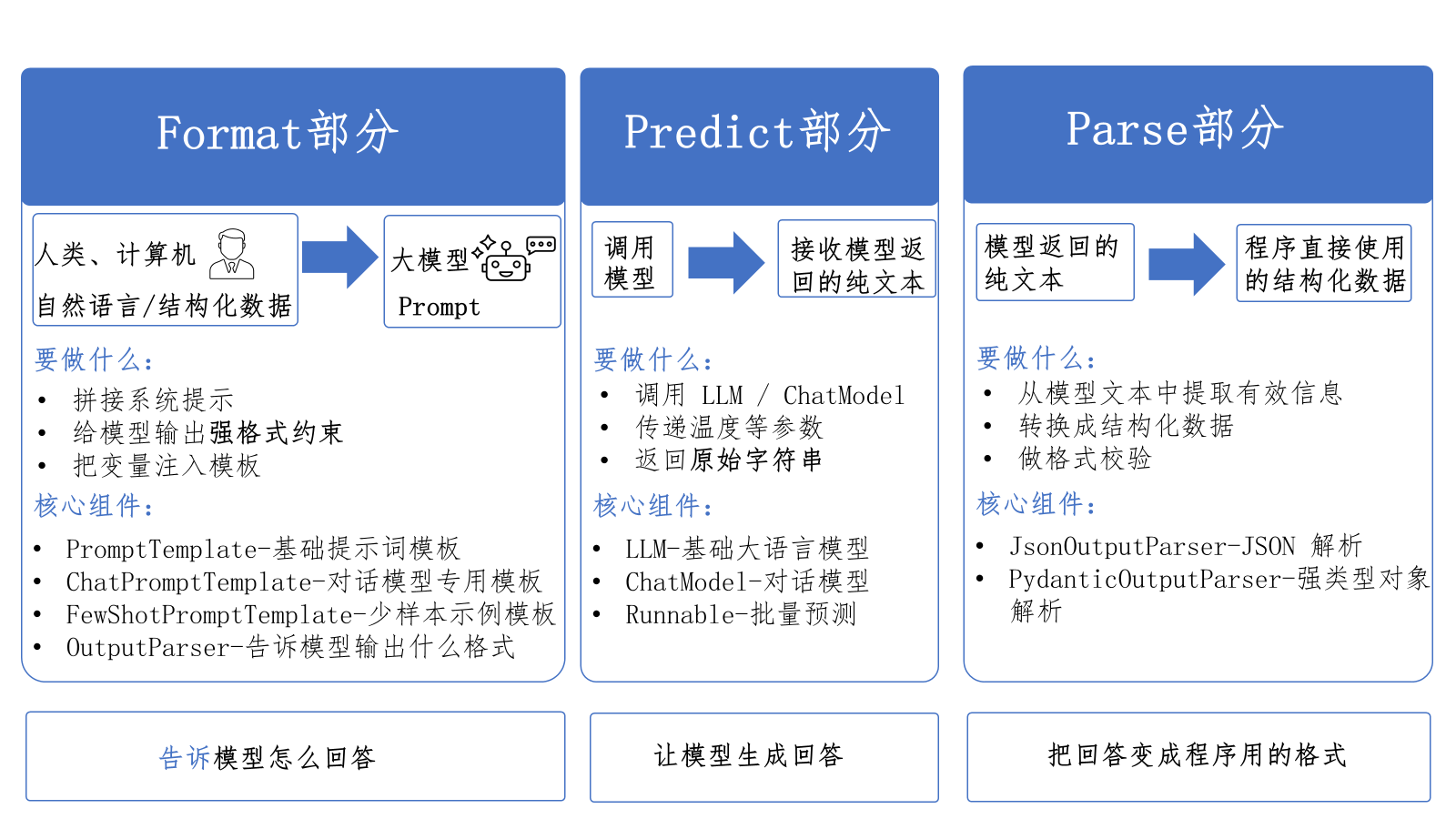
3.2.1 Format部分:Prompt模版封装
PromptTemplate:创建一个字符串类型的Prompt
#01:实现langchain的I/O模块
#01-1:实现Format部分:组装用户输入和Prompt模板,作为大模型的输入
#01-1-1:ChatPromptTemplate:创建一个字符串型的Prompt
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
from langchain_core.prompts import ChatPromptTemplate
prompt_template ="""
我的名字叫【{name}】,我的个人介绍是【{description}】。
请根据我的名字和介绍,帮我想一段有吸引力的自我介绍的句子,以此来吸引读者关注和点赞我的账号。
"""
template = ChatPromptTemplate.from_template(prompt_template)
print(template.input_variables)
#输出结果:['description', 'name']
prompt = template.format(name="小申",description="喜欢睡觉,曾经蝉联1135宿舍午睡冠军")
print(prompt)
#输出结果:Human:
#我的名字叫【小申】,我的个人介绍是【喜欢睡觉,曾经蝉联1135宿舍午睡冠军】。
#请根据我的名字和介绍,帮我想一段有吸引力的自我介绍的句子,以此来吸引读者关注和点赞我的账号。
response = llm.invoke(prompt)
print(response.content)
#输出结果:大家好,我是小申,一个热爱睡觉的资深睡神!曾经蝉联1135宿舍午睡冠军,实力证明:睡觉也是一门高级艺术。如果你和我一样,喜欢用睡眠充电,
#那就关注我吧,一起分享高质量睡眠的小秘密!
ChatPromptTemplate:创建一个Message数组类型的Prompt
#01-1-2:ChatPromptTemplate:创建一个Message数组型的Prompt
from langchain_core.prompts import SystemMessagePromptTemplate,HumanMessagePromptTemplate
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是【{name}】的个人助手,你需要根据用户输入,来替用户生成一段有吸引力的自我介绍的句子,以此来吸引读者关注和点赞用户的账号。"),
HumanMessagePromptTemplate.from_template("{description}")
]
)
prompt = template.format(name="小申",description="喜欢睡觉,曾经蝉联1135宿舍午睡冠军")
print(prompt)
response = llm.invoke(prompt)
print(response.content)
3.2.2 Predict部分:大模型接口封装
LangChain对大模型有两种封装:llm和chat_model
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAI
llm = OpenAI()
chat_model = ChatOpenAI()
from langchain.schema import HumanMessage
text = "What would be a good company name for a company that makes colorful socks?"
messages = [HumanMessage(content=text)]
llm.invoke(text)
# >> Feetful of Fun
chat_model.invoke(messages)
# >> AIMessage(content="Socks O'Color")3.2.3 Parse部分:输出结果校验的封装
#01-2:实现langchain的Parse模块
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
from pydantic import BaseModel, Field, validator
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
def output_parse_test():
# 数据结构
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# 解析器
parser = PydanticOutputParser(pydantic_object=Joke)
# 提示词
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt_str = prompt.format(query="Tell me a joke.")
response = llm.invoke(prompt_str)
try:
parser_result = parser.parse(response.content)
print("解析成功:")
print(parser_result)
except Exception as e:
print("解析结果:")
print(response.content)
output_parse_test()总结:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)