计算机毕业设计Python+百度千问大模型微博舆情分析预测 微博情感分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
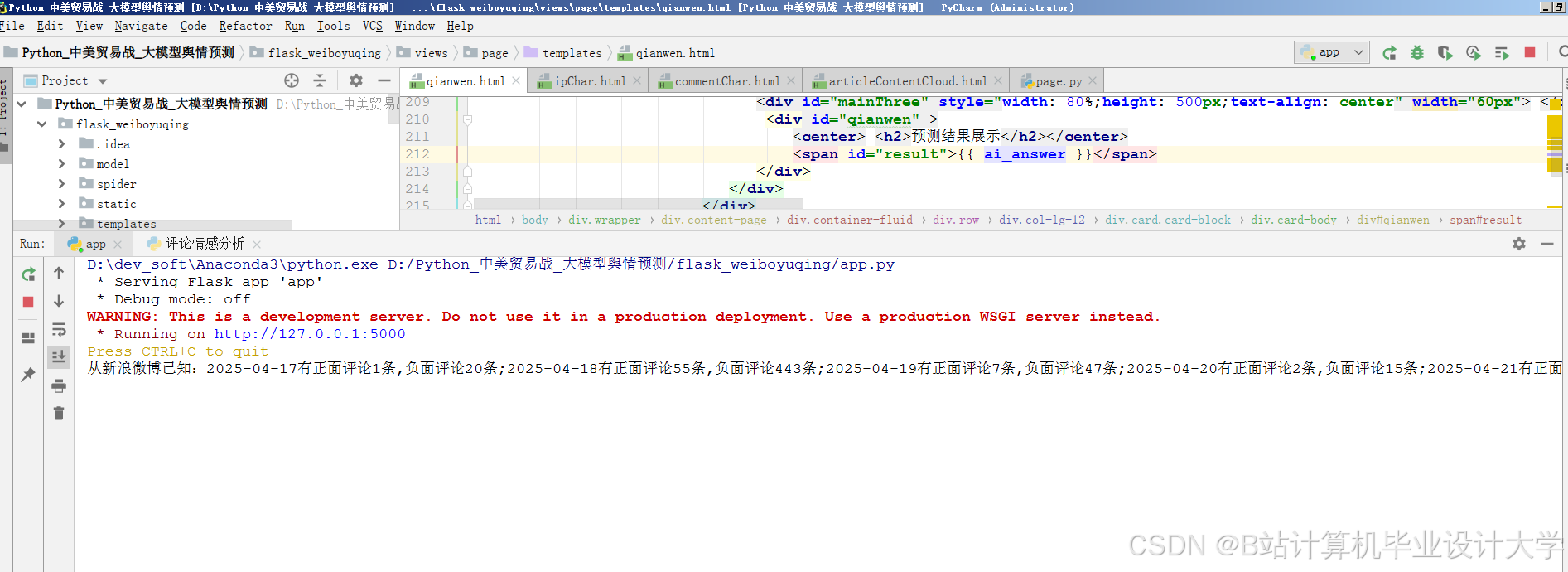
任务书:Python + 百度千问大模型微博舆情分析预测系统开发
一、项目背景与目标
微博作为中国最大的社交媒体平台之一,每日产生海量用户评论与热点话题,蕴含丰富的舆情信息。本项目基于Python生态与百度千问大模型,构建一套微博舆情分析预测系统,实现以下目标:
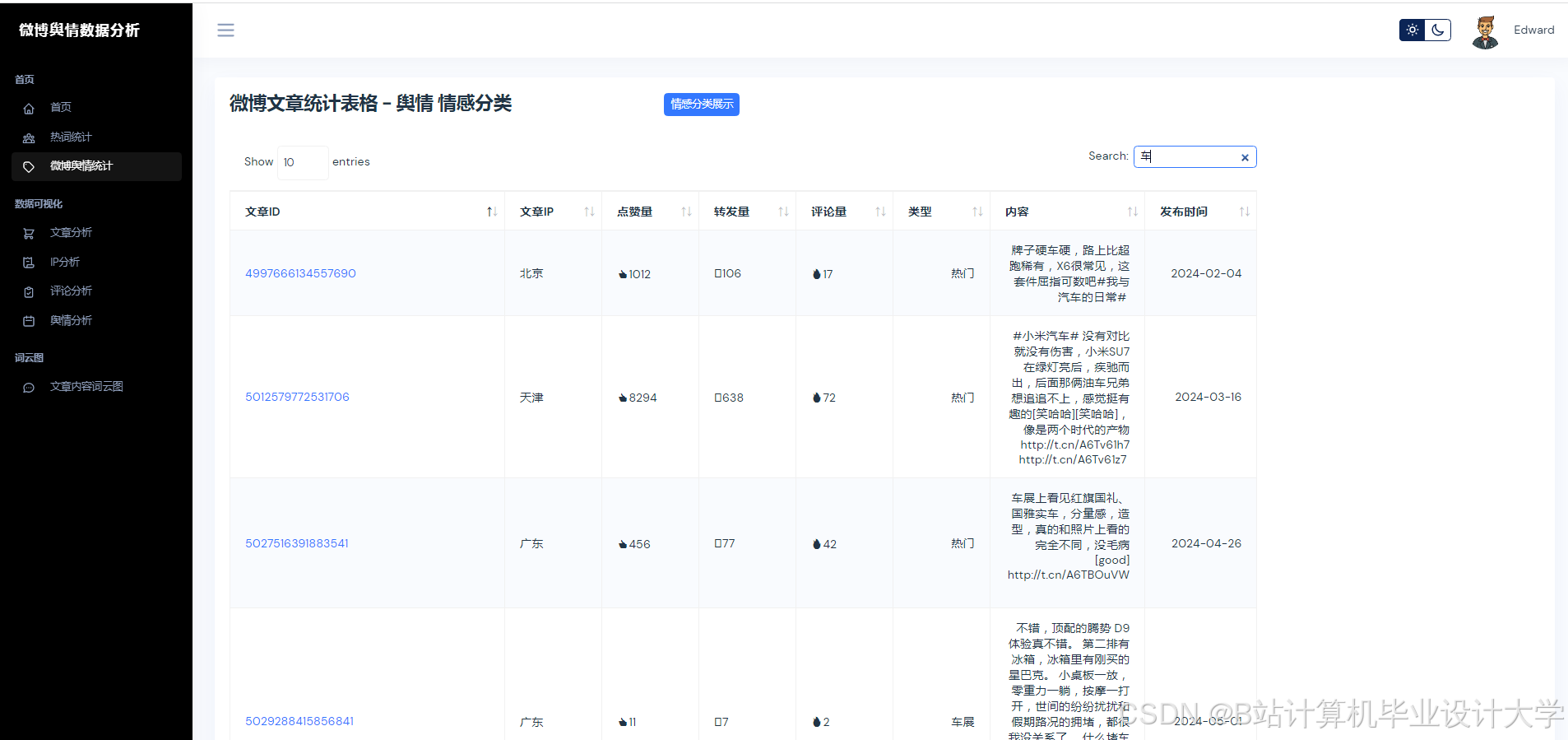
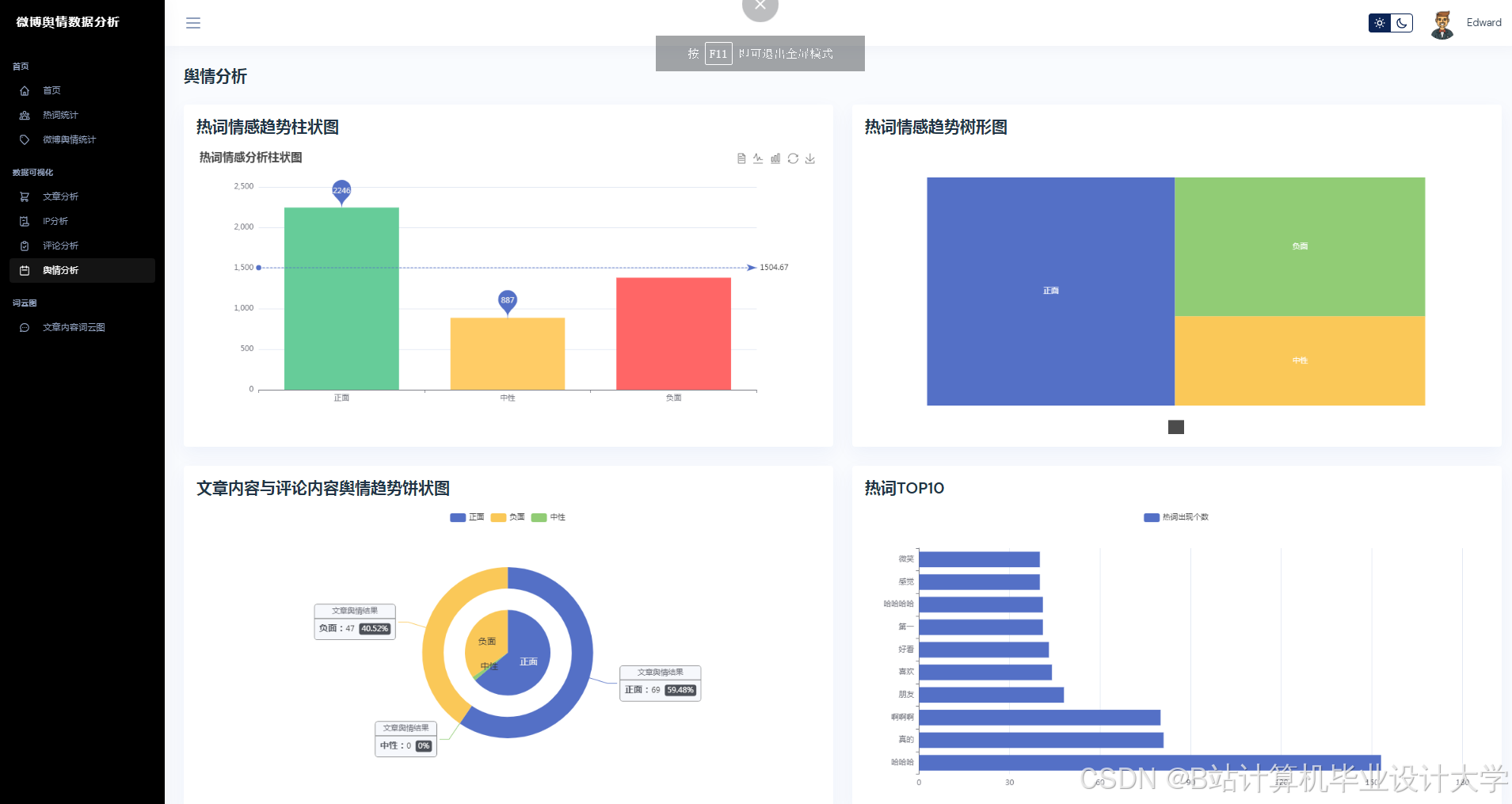
- 舆情实时监测:抓取微博热点话题与用户评论,识别情感倾向(正面/负面/中性)。
- 趋势预测:基于历史数据与大模型推理,预测舆情热度变化趋势(如爆发、衰退)。
- 风险预警:自动识别敏感话题(如社会事件、品牌危机),生成预警报告。
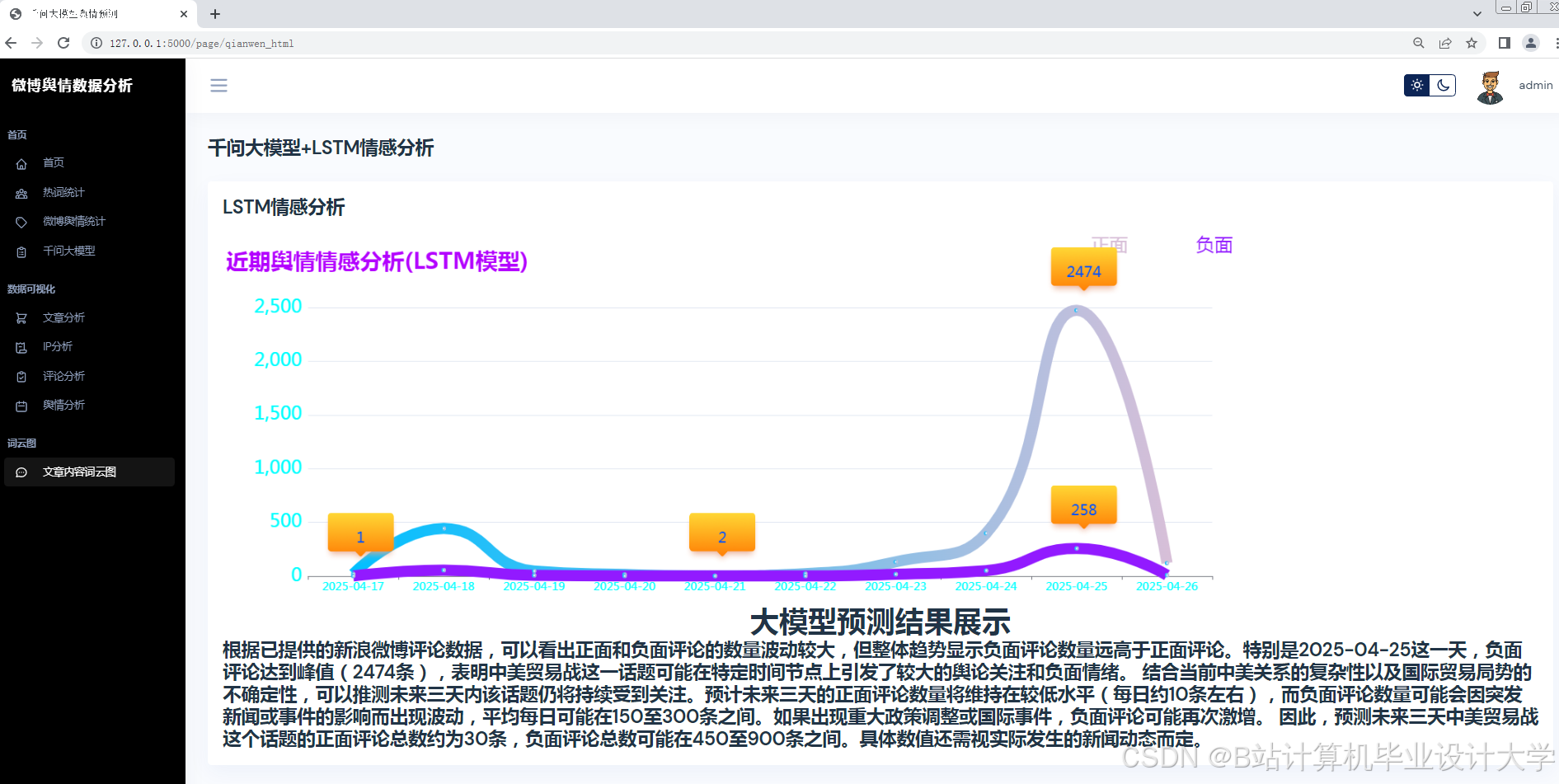
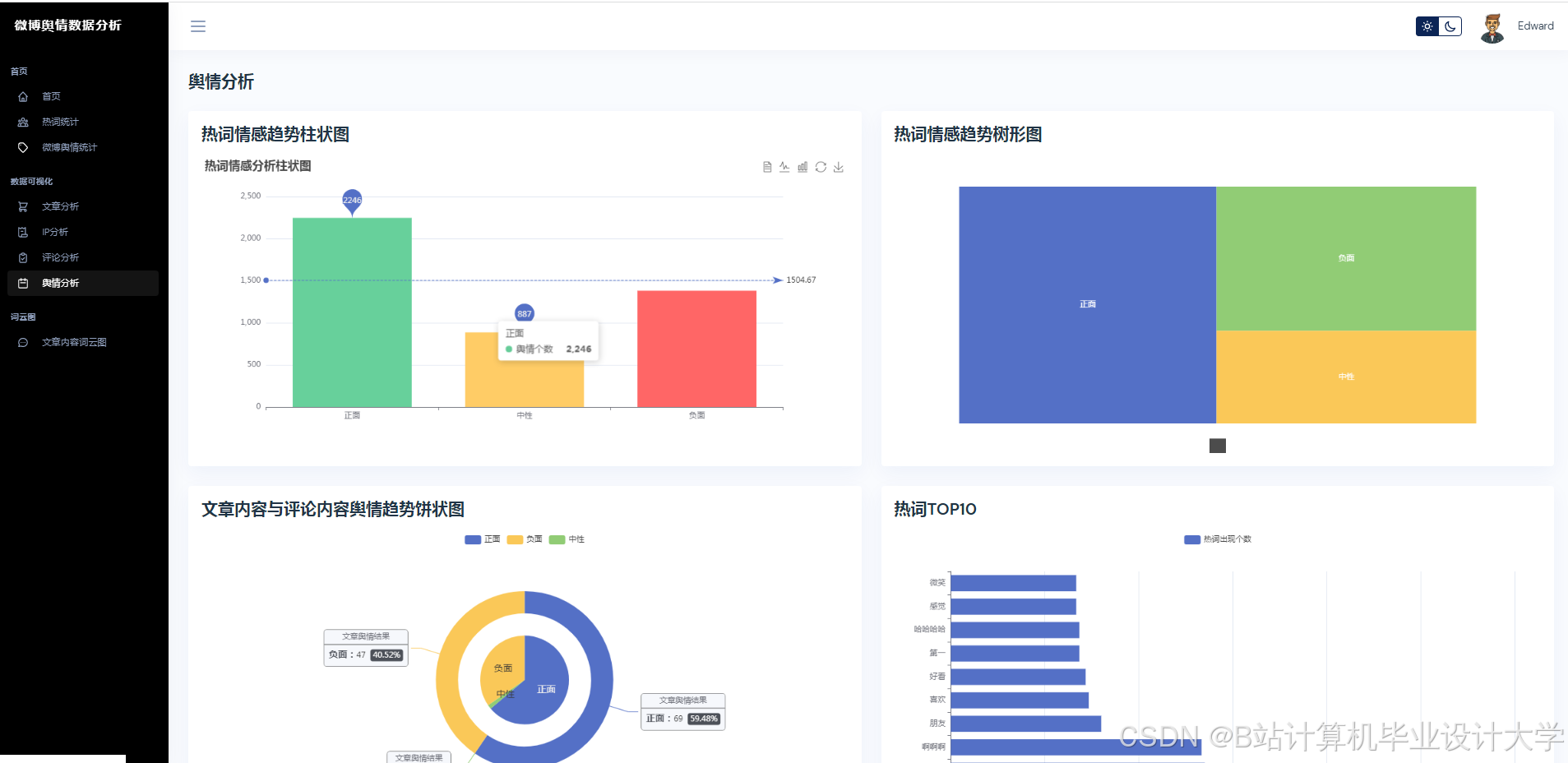
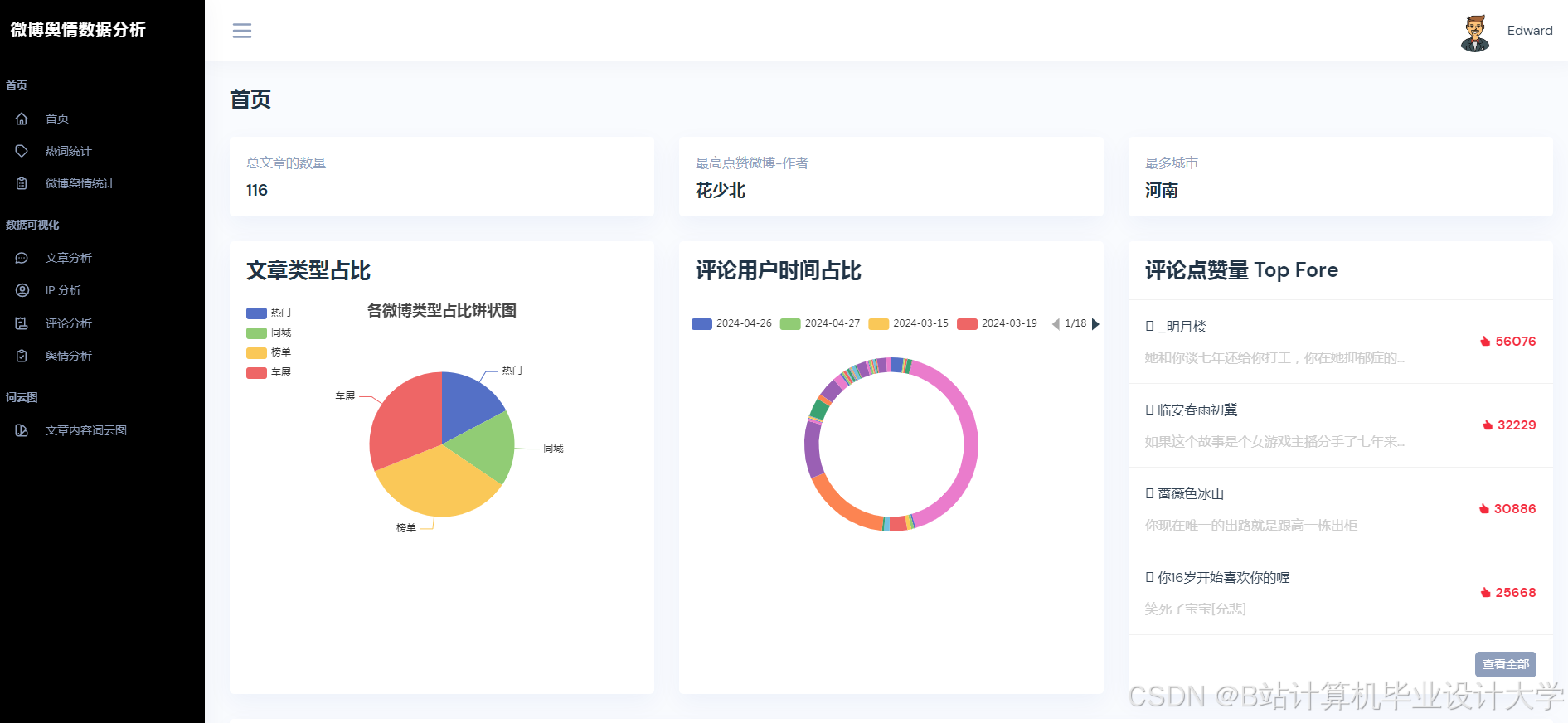
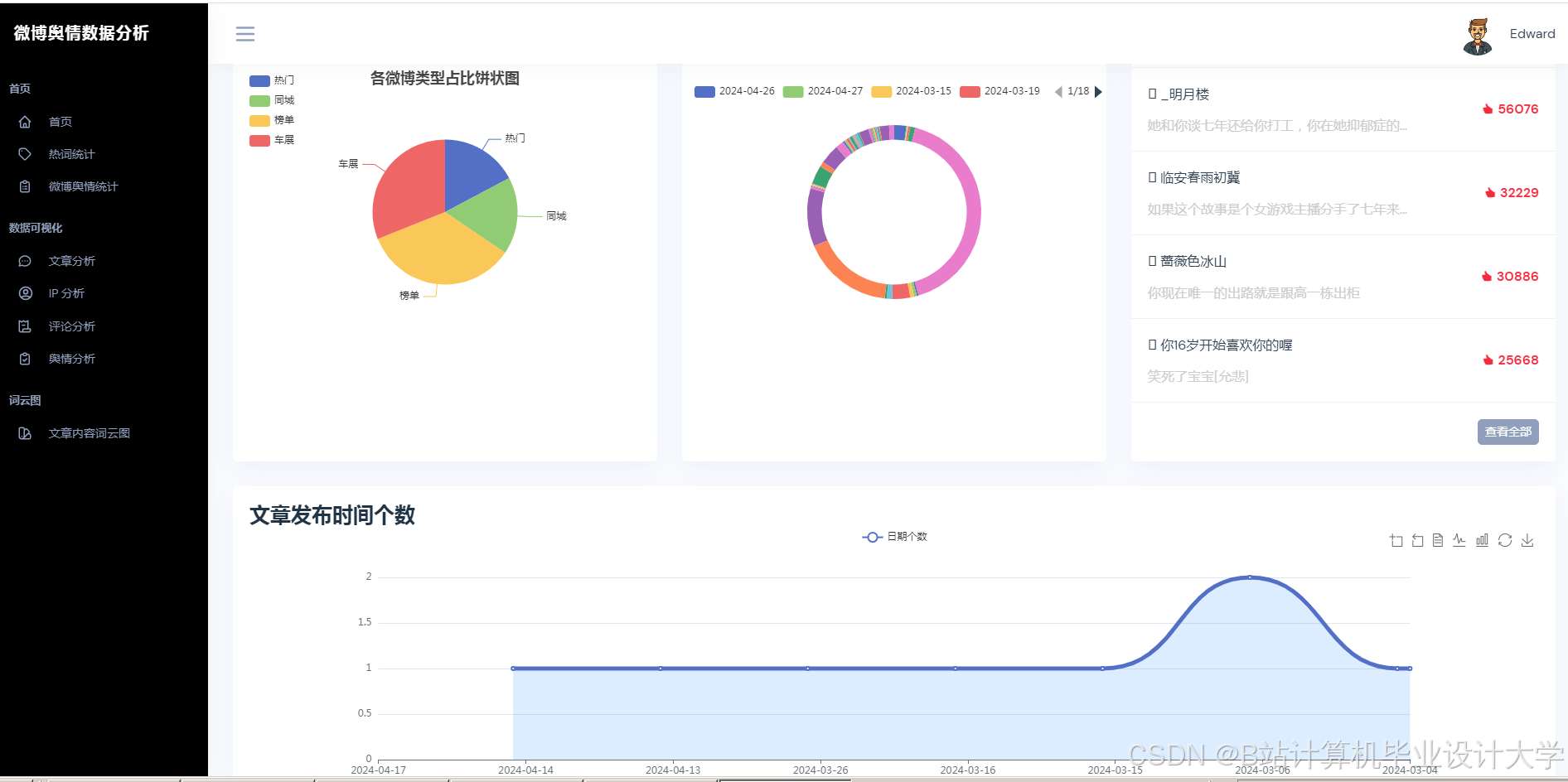
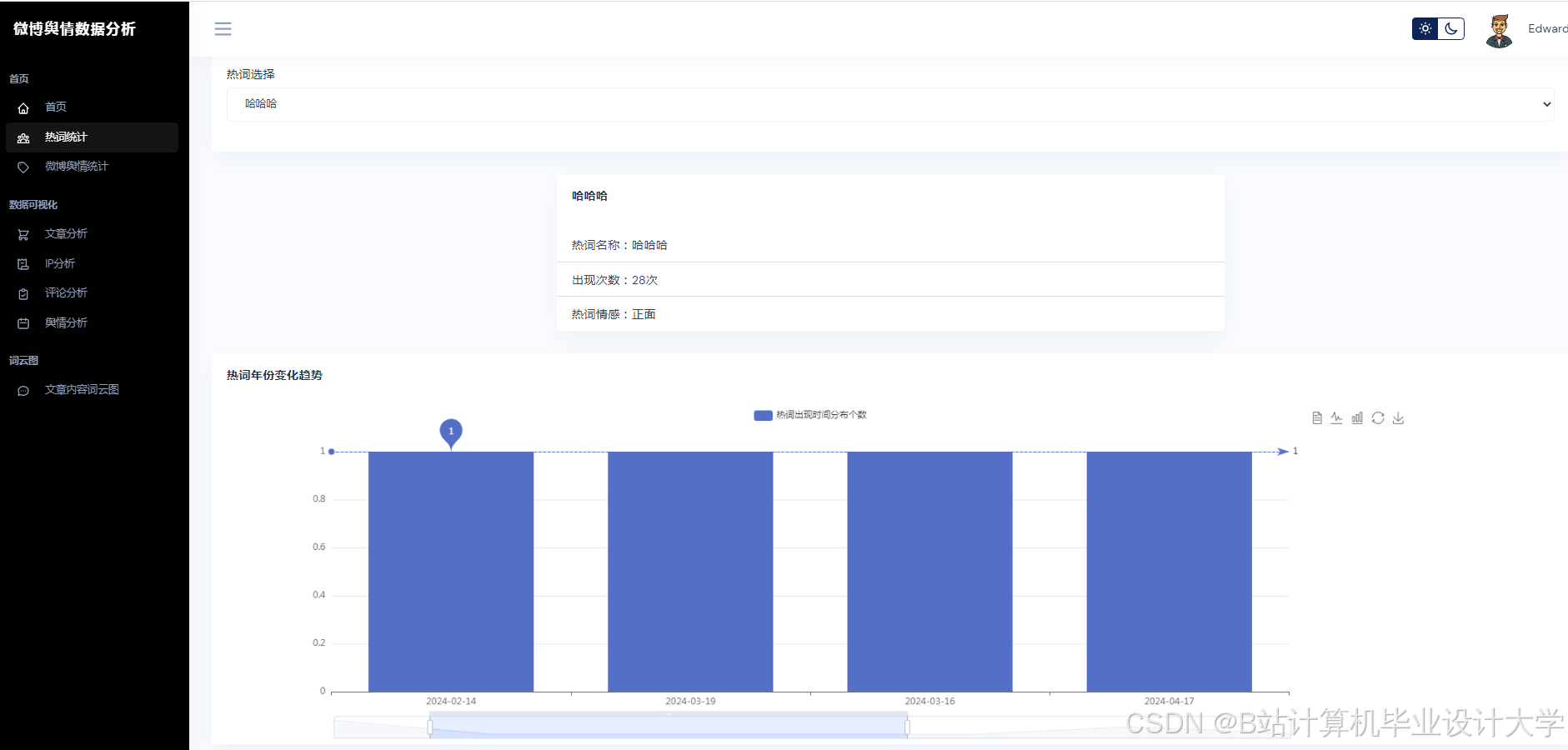
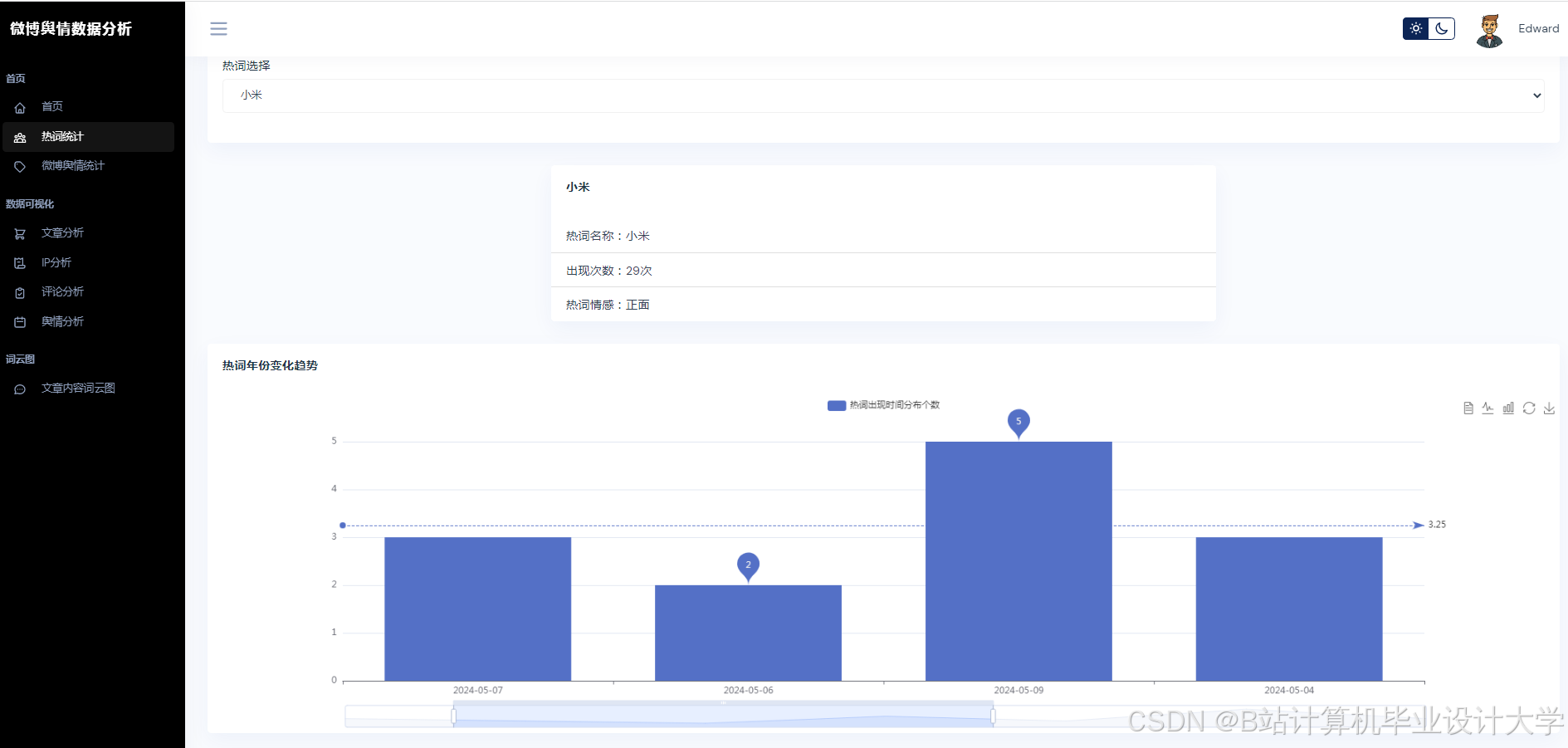
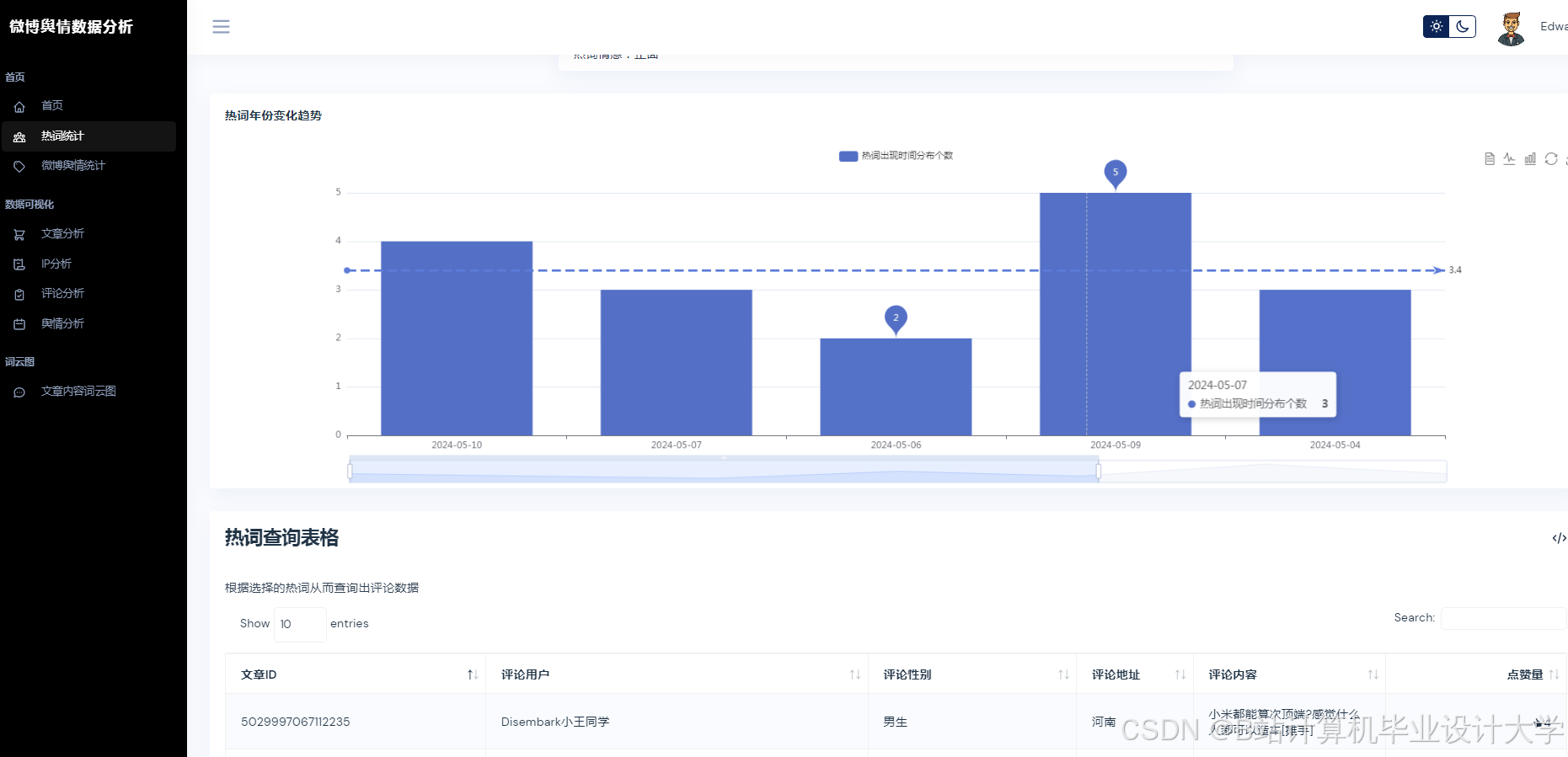
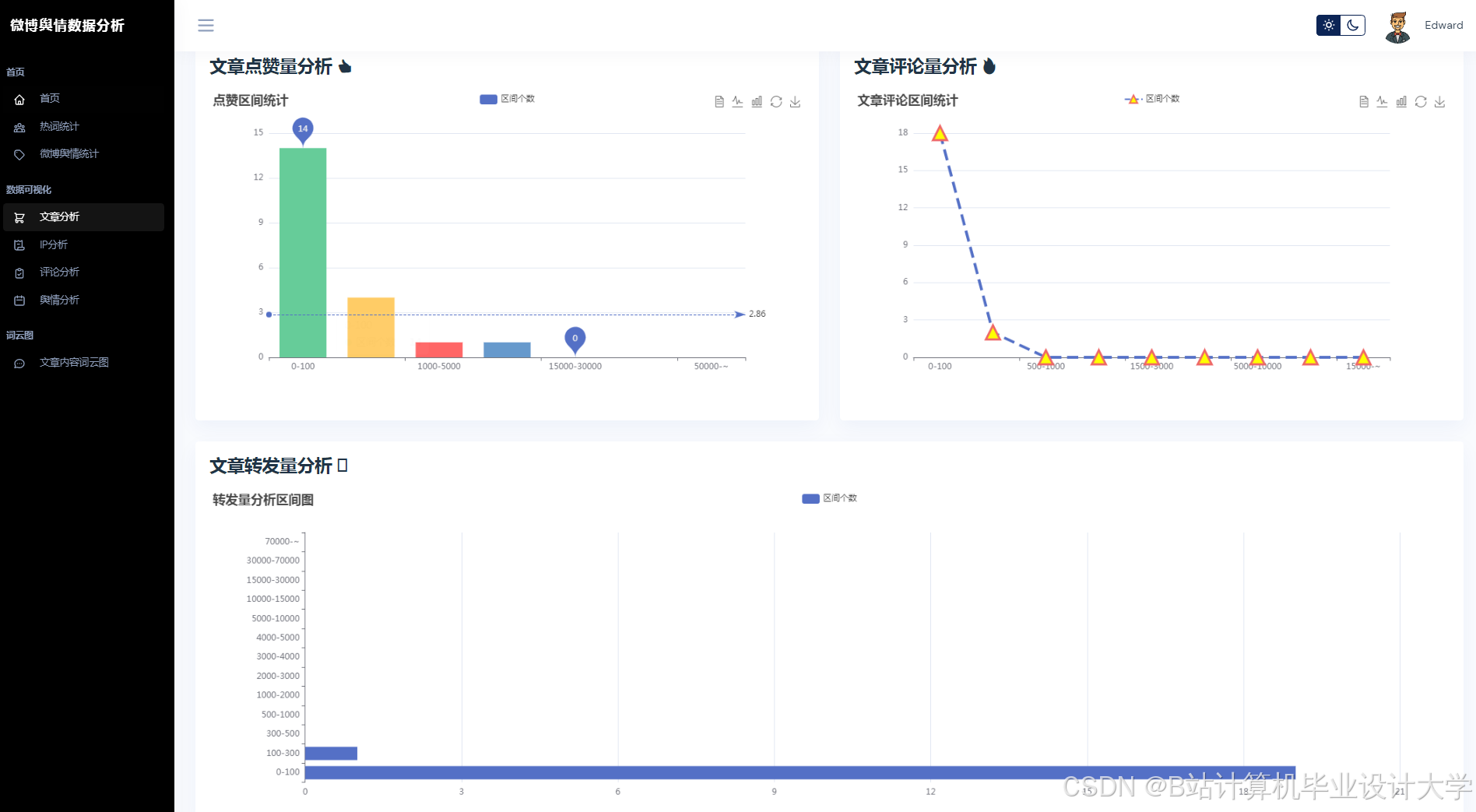
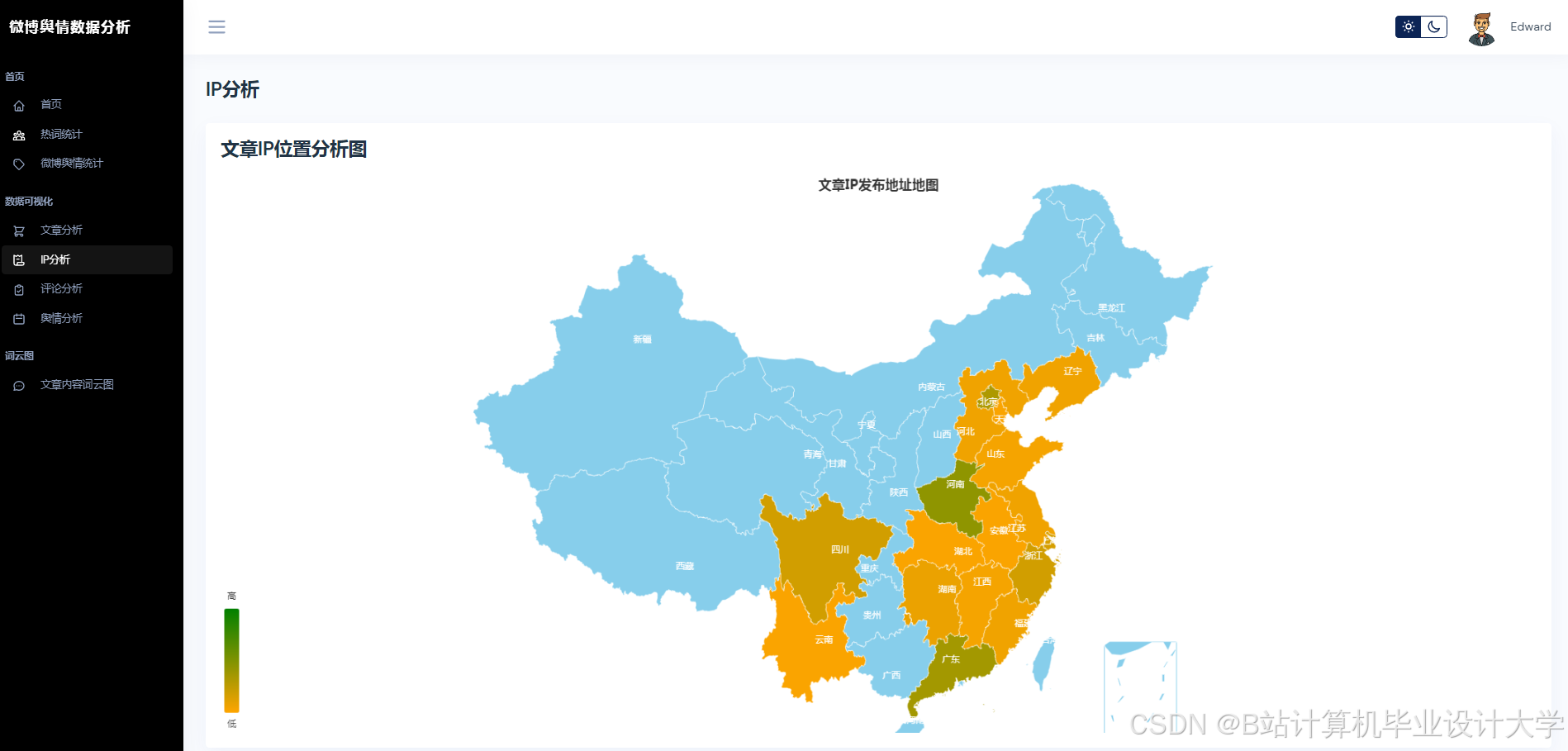
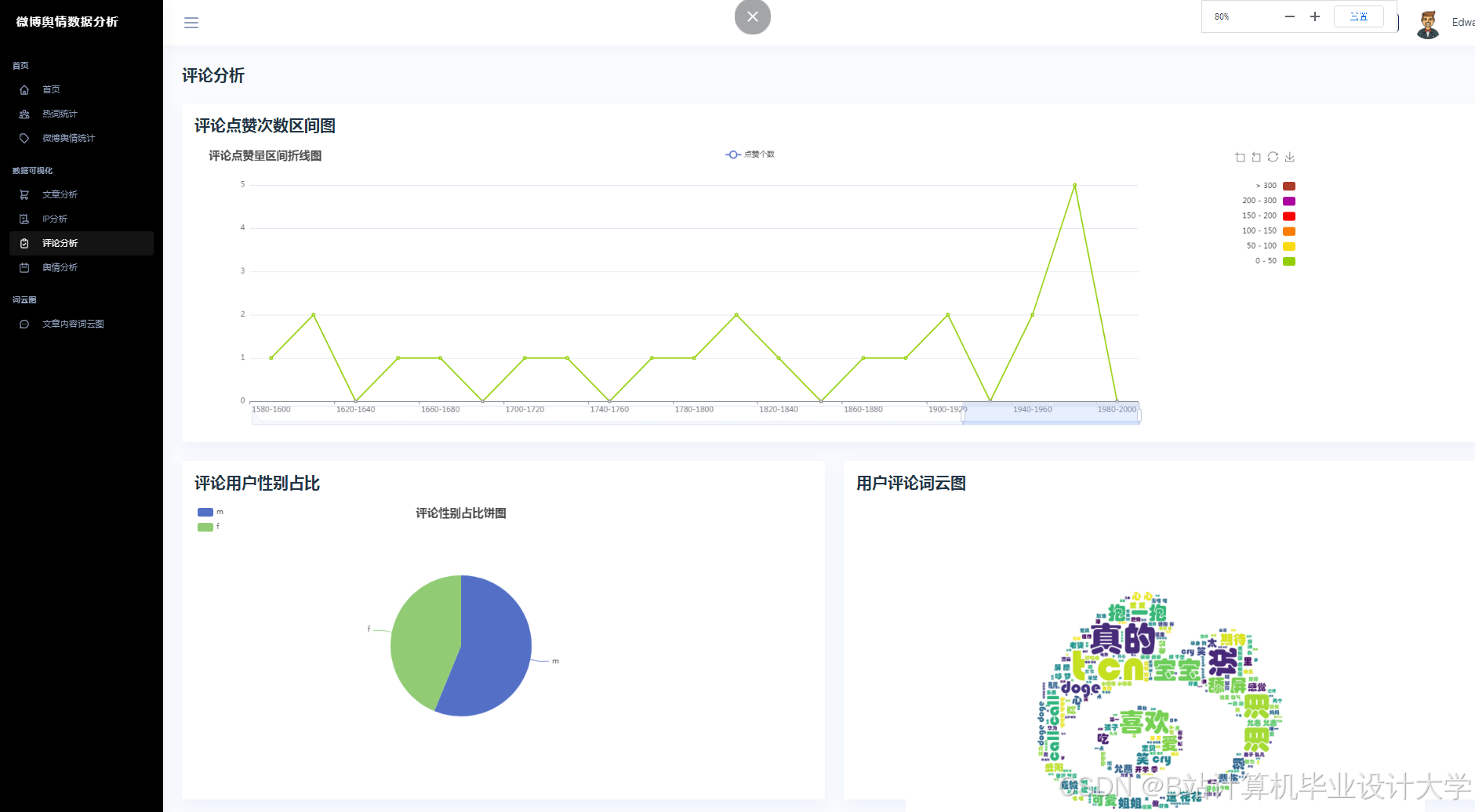
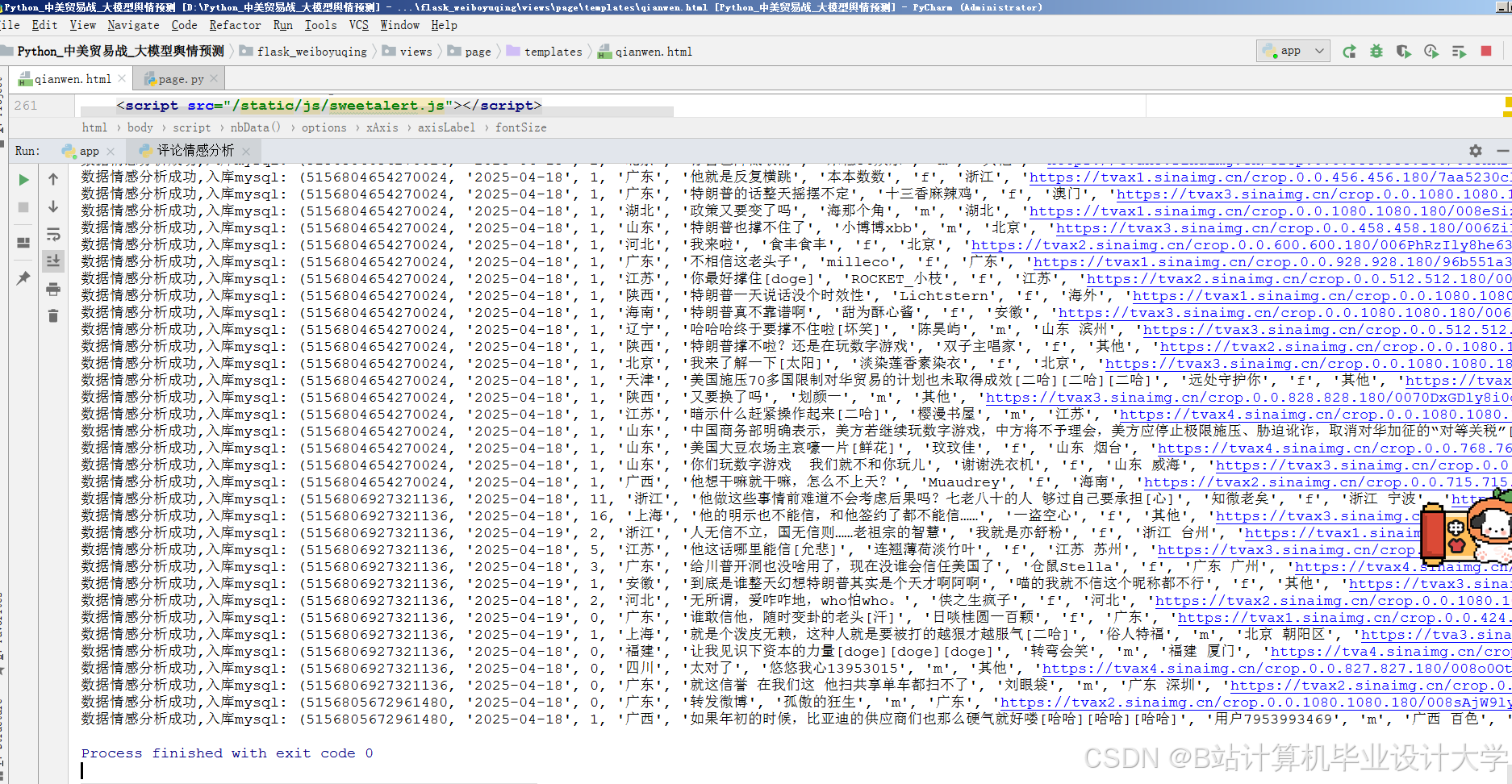
- 可视化分析:通过图表与词云展示舆情分布,辅助决策。
二、项目范围
1. 数据来源
- 微博数据:
- 公开API:通过微博开放平台获取热点话题、用户评论(需申请权限)。
- 爬虫抓取(合规):使用Scrapy/Selenium采集非敏感数据(需遵守《网络安全法》)。
- 外部数据:
- 历史舆情数据集(如公开的微博情感分析数据集)。
- 行业关键词库(如社会事件、品牌名称、敏感词)。
2. 功能模块
| 模块 | 功能描述 |
|---|---|
| 数据采集与清洗 | 定时抓取微博数据,过滤重复、广告、无关内容,保留有效评论与话题。 |
| 情感分析 | 基于百度千问大模型,对评论进行情感分类(正面/负面/中性)与强度评分。 |
| 趋势预测 | 结合时间序列分析(ARIMA/LSTM)与千问模型推理,预测话题热度变化趋势。 |
| 风险预警 | 设定情感阈值(如负面评论占比>30%),触发敏感话题预警并生成摘要。 |
| 可视化看板 | 使用Pyecharts/Matplotlib展示情感分布、热度趋势、关键词词云。 |
| 后台管理 | 管理员配置关键词库、预警规则、数据存储周期。 |
三、技术栈
- 编程语言:Python 3.8+
- 数据采集:
- 微博API:
weibo-api(官方SDK)或requests模拟请求。 - 爬虫:Scrapy(分布式抓取) + Selenium(动态页面渲染)。
- 微博API:
- 数据处理:
- 清洗:Pandas(去重、分词、过滤敏感词)。
- 存储:MySQL(结构化数据) + MongoDB(非结构化评论)。
- 大模型调用:
- 百度千问API:通过
qianwen-sdk或HTTP请求调用情感分析与推理接口。 - 本地化部署(可选):若模型开放,使用
transformers库加载千问模型。
- 百度千问API:通过
- 趋势预测:
- 时间序列:Statsmodels(ARIMA) + TensorFlow/PyTorch(LSTM)。
- 特征工程:提取评论量、情感得分、话题参与人数作为预测输入。
- 可视化:Pyecharts(交互式图表) + WordCloud(词云生成)。
- 部署环境:
- 本地开发:Jupyter Notebook(原型验证)。
- 生产环境:Docker + Flask/FastAPI(轻量级服务) + Nginx(反向代理)。
四、任务分解与时间计划
阶段1:需求分析与数据准备(1周)
- 确认微博数据采集方式(API/爬虫)与合规性。
- 设计数据库表结构(话题表、评论表、情感分析结果表)。
- 搭建Python开发环境,配置MySQL/MongoDB连接。
阶段2:数据采集与清洗(2周)
- 微博API集成:
- 使用
weibo-api获取热点话题列表与评论(需处理分页与频率限制)。 - 示例代码:
python1from weibo_api import WeiboClient 2client = WeiboClient(app_key, app_secret, access_token) 3trends = client.get_trends() # 获取热点话题 4comments = client.get_comments(trend_id) # 获取话题评论 5
- 使用
- 爬虫开发(备用方案):
- 使用Scrapy爬取微博搜索结果页,解析评论与发布时间。
- 反爬策略:设置随机User-Agent、IP代理池、请求间隔。
- 数据清洗:
- 去除HTML标签、特殊符号、重复评论。
- 使用Jieba分词并过滤停用词(如“的”“了”)。
阶段3:情感分析与模型集成(2周)
- 百度千问API调用:
- 发送评论文本至千问模型,获取情感标签与解释。
- 示例请求:
python1import requests 2url = "https://qianwen.baidu.com/api/v1/sentiment" 3headers = {"Authorization": "Bearer YOUR_API_KEY"} 4data = {"text": "这款手机用起来很流畅,但电池不耐用。"} 5response = requests.post(url, headers=headers, json=data) 6# 返回: {"sentiment": "neutral", "score": 0.5, "explanation": "..."} 7
- 本地化优化(可选):
- 若模型支持,微调千问模型以适应微博口语化表达(如“绝了”“yyds”)。
- 使用Prompt Engineering优化输入格式(如“分析以下微博的情感:[文本]”)。
阶段4:趋势预测与风险预警(2周)
- 时间序列预测:
- 使用ARIMA模型预测话题热度(评论量随时间变化)。
- 示例代码:
python1from statsmodels.tsa.arima.model import ARIMA 2model = ARIMA(data, order=(1,1,1)) 3forecast = model.fit().forecast(steps=7) # 预测未来7天 4
- 大模型推理增强:
- 结合千问模型对历史数据生成语义特征(如“话题涉及政策争议”),提升预测准确性。
- 风险预警规则:
- 负面评论占比 > 30% → 触发黄色预警。
- 负面评论占比 > 50%且热度上升 → 触发红色预警。
阶段5:可视化与后台开发(1周)
- 可视化看板:
- 使用Pyecharts生成情感分布饼图、热度趋势折线图。
- 使用WordCloud生成高频词词云(如“涨价”“质量差”)。
- 后台管理:
- 使用Flask开发简单管理界面,支持关键词库导入、预警规则配置。
- 示例路由:
python1from flask import Flask, request, jsonify 2app = Flask(__name__) 3@app.route("/api/keywords", methods=["POST"]) 4def update_keywords(): 5 keywords = request.json["keywords"] 6 # 更新数据库中的关键词库 7 return jsonify({"status": "success"}) 8
阶段6:测试与部署(1周)
- 功能测试:
- 模拟微博数据流入,验证情感分析准确率(与人工标注对比)。
- 测试预警规则是否按阈值触发。
- 性能测试:
- 使用Locust模拟1000并发请求,检查API响应时间(目标<500ms)。
- 部署上线:
- 打包为Docker容器,部署至云服务器(如阿里云ECS)。
- 配置定时任务(Cron/Celery)实现数据自动采集与分析。
总周期:8周(可根据团队规模调整)
五、交付成果
- 数据采集脚本:Python脚本(Scrapy/API)用于微博数据抓取。
- 情感分析模型:百度千问API调用代码或本地化微调模型文件。
- 预测模块:ARIMA/LSTM时间序列预测代码与千问推理集成逻辑。
- Web应用:Flask后台管理界面 + Pyecharts可视化页面。
- 技术文档:系统架构图、API文档、部署指南、测试报告。
六、资源需求
- 硬件:服务器(4核8G+),用于模型推理与数据存储。
- 软件:Python 3.8+, MySQL, MongoDB, Docker, Flask/FastAPI。
- 数据:至少10000条标注情感的微博评论(用于验证模型)。
- 人员:
- 全栈开发(1人):Python后端+前端可视化。
- 算法工程师(1人):百度千问模型集成与趋势预测优化。
- 测试工程师(可选):功能与性能测试。
七、风险评估与应对
| 风险 | 应对措施 |
|---|---|
| 微博API限制访问频率 | 切换至爬虫方案,或申请更高权限的API密钥。 |
| 百度千问API调用失败 | 添加重试机制(如tenacity库),或 fallback 到本地情感分析模型。 |
| 预测模型准确率不足 | 增加历史数据量,或引入外部特征(如用户粉丝数、话题参与人数)。 |
| 舆情漏报/误报 | 人工复核高频预警案例,优化预警规则阈值。 |
八、验收标准
- 情感分析准确率≥80%(通过人工标注1000条测试集验证)。
- 趋势预测误差率≤15%(与实际热度变化对比)。
- 系统支持500+并发用户,API平均响应时间≤300ms。
- 预警规则触发准确率≥90%(无大量误报/漏报)。
项目负责人:
日期:
备注:
- 可扩展方向:增加多语言支持(如英文微博)、跨平台分析(微信、抖音)、实时大屏展示。
- 建议每周同步进度,重点监控百度千问API的调用成本与模型推理延迟。
运行截图

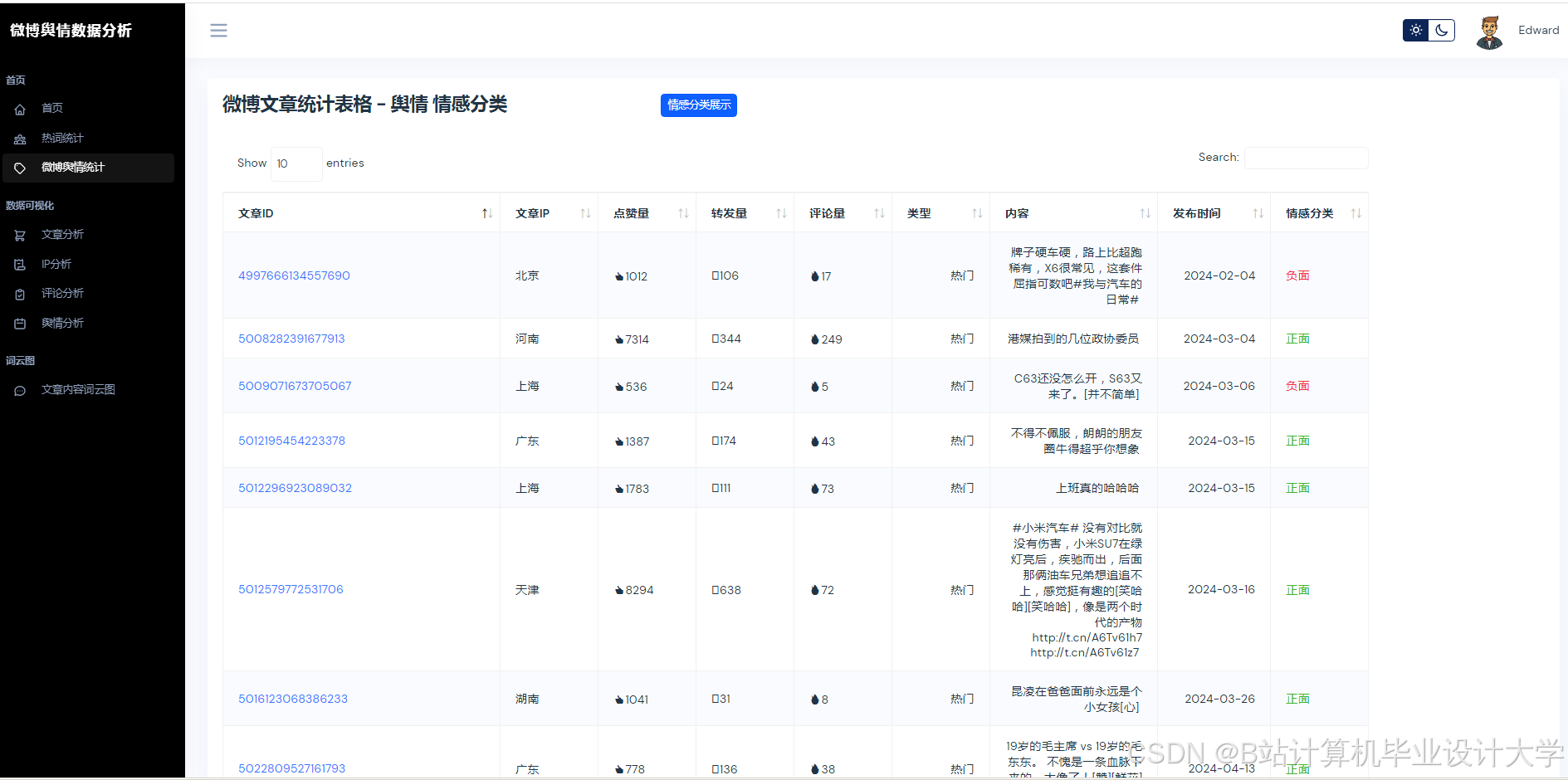
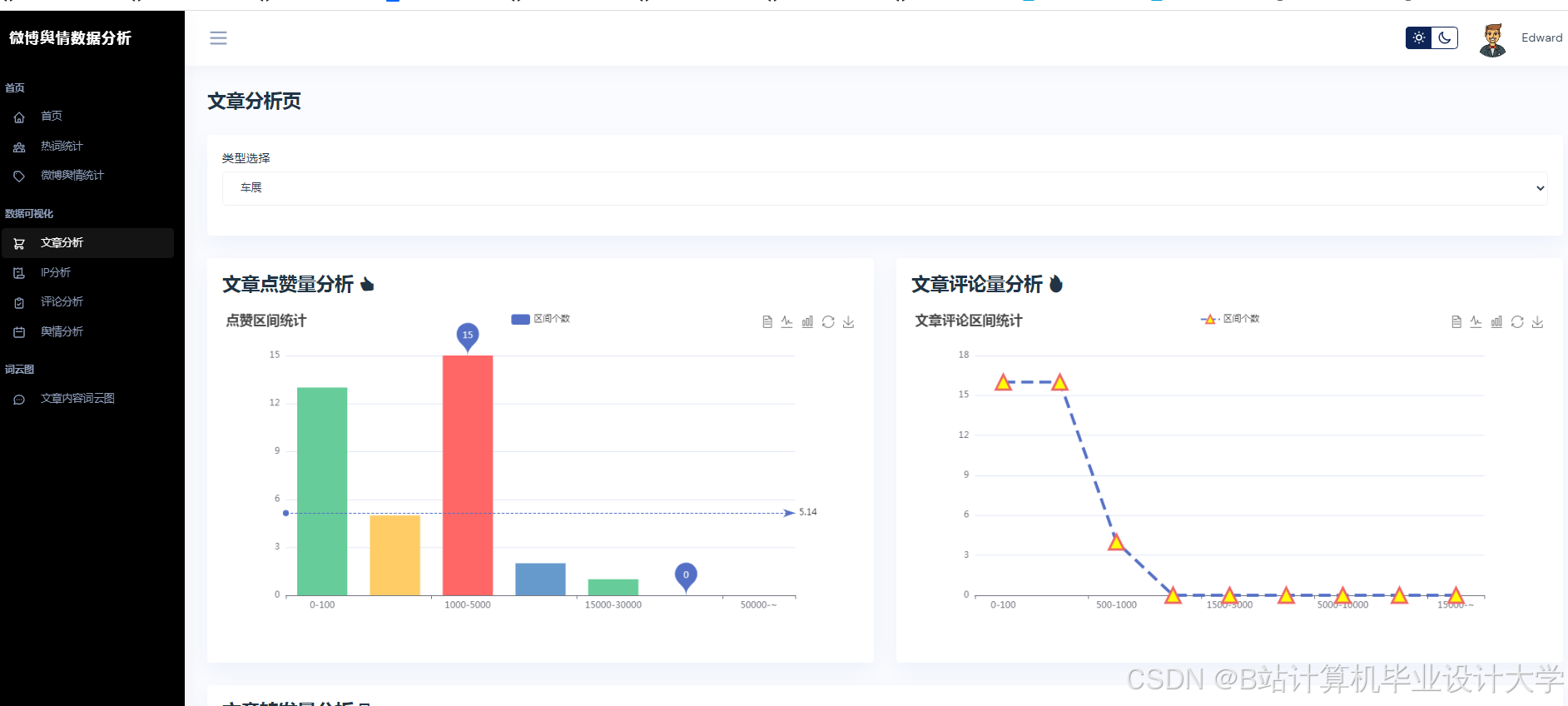
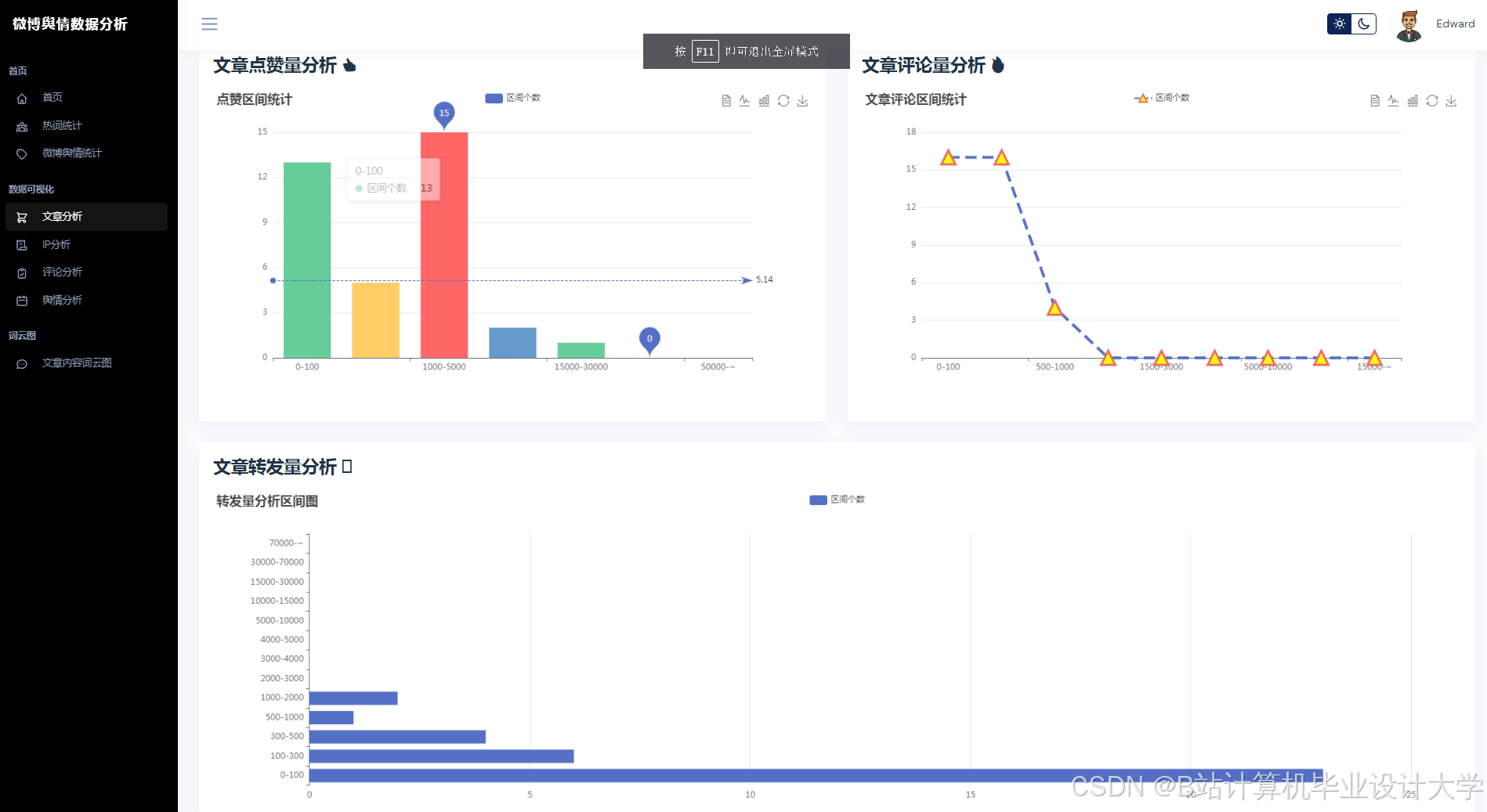
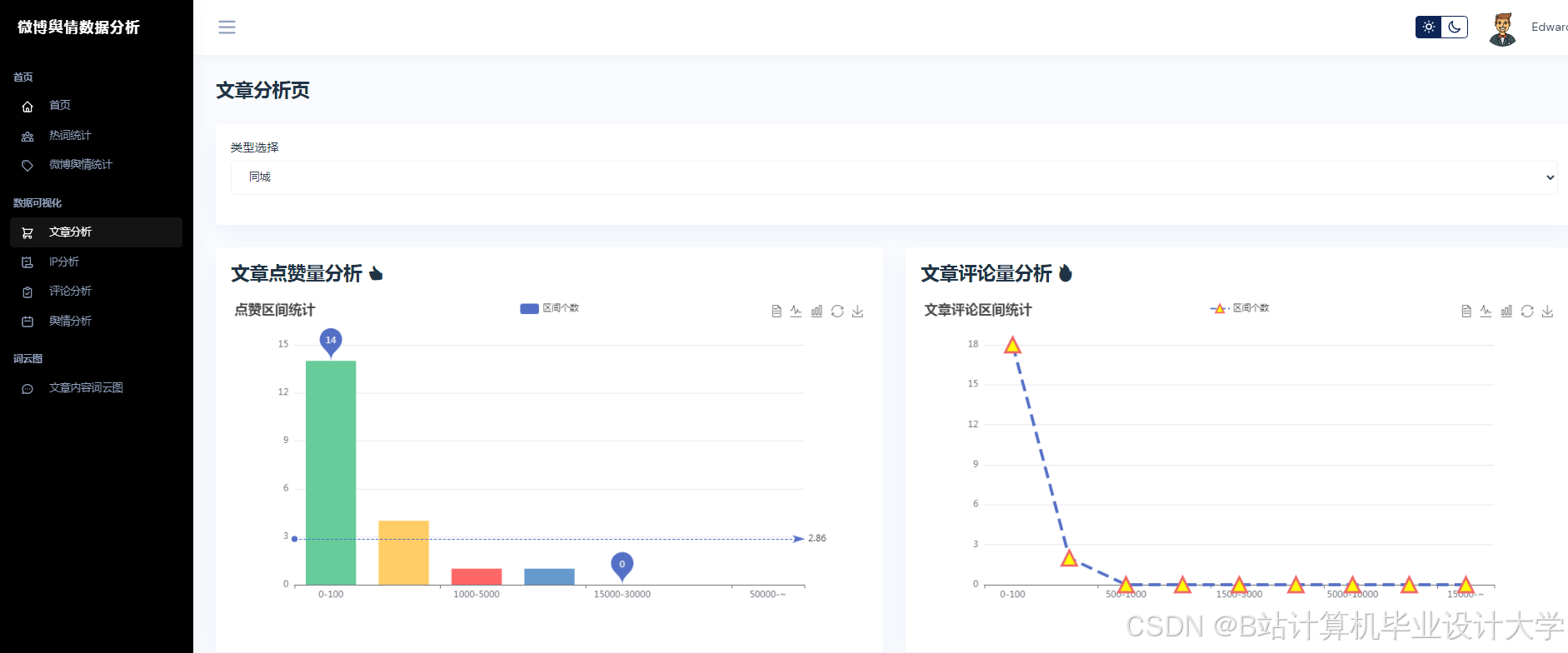



推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)