用 AI Agent 监控南理工通知公告
一个 Python 爬虫 + AI Skill 的实践:让 Claude Code 和龙虾 OpenClaw 帮你盯着学校官网,再也不怕错过重要通知。
文章目录
痛点
学校的通知分散在多个部门网站上——研究生院、教务处、学生工作处、创新创业学院、国资处……每个网站的页面结构不同,有些还加了反爬。手动逐个检查既费时又容易遗漏。
能不能让 AI 帮我每天看一眼?
方案
写一个 Python 脚本 njust_monitor.py,一次性抓取 14 个网站最近 3 天的通知,输出标准 JSON。然后把它注册为 AI Agent 的 Skill——无论是 Claude Code 还是龙虾 OpenClaw,输入 /njust 就能看到结果。
用户输入: /njust
AI输出 :
教务处
- 2025-2026春季学期网络通识教育选修课学习通知 (2026-03-17) 链接
研究生院-首页通知公告
- 关于做好2026年春季学期课程安排的通知 (2026-03-16) 链接
监控范围
共覆盖 14 个页面,涵盖学校主要职能部门:
| # | 来源 | 域名 | 引擎 |
|---|---|---|---|
| 1 | 学校主页-通知公告 | www.njust.edu.cn | DrissionPage |
| 2-9 | 研究生院(通知/活动/培养/招生/学位/管理/导师/国际交流) | gs.njust.edu.cn | requests |
| 10 | 学生工作处 | dgxg.njust.edu.cn | DrissionPage |
| 11 | 创新创业学院 | eoe.njust.edu.cn | DrissionPage |
| 12 | 国资处 | gzc.njust.edu.cn | DrissionPage |
| 13 | 教务处 | jwc.njust.edu.cn | DrissionPage |
| 14 | 知识产权学院 | dicm.njust.edu.cn | DrissionPage |
依赖安装
pip install requests beautifulsoup4 DrissionPage
部署为Skill
这个脚本可以注册到两个 AI Agent 平台,各有优劣:
方式一:Claude Code 全局命令
目录结构:
**注:**在windows下,~/ 目录就是 C:\Users\用户名\,所有的/都替换为\
~/.claude/
└── commands/
└── njust.md # Skill 定义
└── my-scripts/
└── njust_monitor.py` # 脚本文件
脚本放在 ~/.claude/my-scripts/njust_monitor.py 或项目目录下均可。
njust.md 内容:
---
description: 监控南京理工大学各网站最近3天的通知公告
---
运行以下命令获取南京理工大学14个网站最近3天内发布的通知:
python -X utf8 C:\Users\ADMIN\.claude\my-scripts\njust_monitor.py
脚本 stdout 输出 JSON 数组,每条通知包含 title、url、date、source 字段。
请执行脚本,然后将结果按 source(来源)分组展示。
使用时在 Claude Code 中输入 /njust 即可。Claude 会执行脚本、解析 JSON、按来源分组渲染成 Markdown。
使用:
方式二:龙虾 OpenClaw Skill
目录结构:
~/.openclaw/workspace/skills/njust-notification-monitor/
├── SKILL.md # Skill 元数据 + 使用说明
└── scripts/
└── njust_monitor.py # 爬虫脚本
OpenClaw 的 Skill 系统会自动发现 SKILL.md,注册为可调用的技能。
使用:
接入飞书,并在HEARTBEAT.md 或者 cron 中设置定时任务:
也可在飞书中直接发送 /njust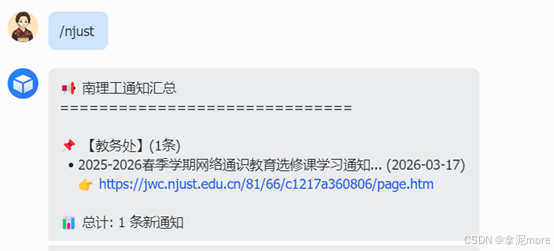
方式三:直接运行 python njust_monitor.py
添加监控网站
1、打开claude(在njust_monitor.py统一目录下)或者openclaw
2、发送指令:把这个网站也加入监控https://dgxg.njust.edu.cn/_t615/6509/list.htm
依赖安装
pip install requests beautifulsoup4 DrissionPage
局限与改进方向
- 速度:DrissionPage 需要启动浏览器,6 个反爬站点串行访问约需 30-40 秒。后续可考虑并发或复用 session。
- 稳定性:学校网站偶尔改版会导致解析器失效,需要定期维护 CSS 选择器。
- 覆盖范围:目前只覆盖了 14 个页面,后续可按需添加更多学院和部门。
- 定时推送:目前是按需触发,可以结合 cron 或 OpenClaw 心跳任务实现每日自动推送。
技术架构
双引擎爬虫
并非所有网站都能简单 requests.get() 拿到内容。南理工部分站点(主页、教务处、学生工作处等)部署了反爬机制,普通请求只会得到一个空壳页面。
因此脚本采用双引擎策略:
| 引擎 | 适用场景 | 技术栈 |
|---|---|---|
requests |
纯 HTML 页面(研究生院 8 个子站) | requests + BeautifulSoup |
DrissionPage |
反爬页面(主页、教务处等 6 个站点) | Chromium 无头浏览器 |
DrissionPage 会启动一个真实的 Chromium 浏览器实例,模拟用户访问行为(访问 → 等待 → 刷新 → 提取),绕过前端反爬脚本。
四种页面解析器
不同网站的 HTML 结构各异,脚本内置了 4 种解析器自动匹配:
PARSERS = {
"news_ul": parse_news_ul, # ul.news_ul li > a + span (研究生院)
"news_list": parse_news_list, # ul.news_list > div.xbtt-2 (学校主页)
"article_list": parse_article_list, # li.list_item > Article_Title (学工处/国资处)
"table": parse_table, # table tr > td a[title] (教务处/知产院)
}
输出格式
脚本 stdout 输出标准 JSON 数组,每条通知包含 4 个字段:
[
{
"title": "关于开展2026届本科毕业设计中期检查的通知",
"url": "https://jwc.njust.edu.cn/82/69/c1217a361065/page.htm",
"date": "2026-03-12",
"source": "教务处"
}
]
这种设计让脚本与展示层完全解耦——AI Agent 负责读取 JSON 并按来源分组渲染,脚本只管抓数据。
总结
这个项目的核心思路是:把重复的信息检索工作封装成脚本,再通过 AI Skill 机制让它「一句话可调用」。同一个 njust_monitor.py 脚本,既能在 Claude Code 里用 /njust 调用,也能在龙虾 OpenClaw 里作为 Skill 使用。
脚本负责抓数据,AI 负责展示——各干各的活,干净利落。
获取:
通过网盘分享的文件:njust-notification.zip
链接: https://pan.baidu.com/s/1cX16lWh9XfV1ek8cGzrRtw?pwd=p1q6
提取码: p1q6

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)