Java 程序员的 AI 转型第七课:AI 失忆症克星!ChatMemory 对话历史管理与上下文实战
大家好,欢迎来到《Spring AI 零基础到实战》的第 7 节!
在上一节中,我们见识了现代 Spring AI 的灵魂——Advisor(顾问/切面拦截器)。有了这个高阶武器,我们终于可以向 AI 应用开发中最臭名昭著的难题开炮了:大模型的“7 秒钟失忆症”。
如果你现在用代码跟大模型聊天:
- 你问:“我叫张三,今年 6 岁。”
- AI 答:“你好,张三小朋友。”
- 你紧接着问:“我几岁了?”
- AI 答:“抱歉,我不知道你的年龄。”
为什么网页版的Deepseek/ChatGPT能记住上下文,而我们通过代码调用的 API 却是个“失忆症患者”?如果同时有 100 个用户在和你的 AI 客服聊天,怎么保证张三的记忆不会串线到李四那里?如果服务器重启,之前聊过的记忆还能找回来吗?
本节课,我们将利用上一节学过的 Advisor 机制,结合 Spring AI 强大的 ChatMemory 组件,为大模型装上多租户隔离与数据库持久化的长久记忆!
本节章节目标
- 认知破局:搞懂大语言模型(LLM)的无状态(Stateless)本质。
- 自动化记忆:掌握
MessageWindowChatMemory与MessageChatMemoryAdvisor,实现零代码侵入的上下文拼接。 - 多租户隔离:使用
ChatMemory.CONVERSATION_ID实现多用户会话的物理隔离。 - 记忆持久化:告别内存丢失,实战
JdbcChatMemoryRepository将对话记录永久存入 MySQL 数据库。
多租户记忆检索与装配引擎
在写代码之前,我们通过图来看一下当你同时服务多个用户时,Spring AI 底层的记忆切面是如何运转的:
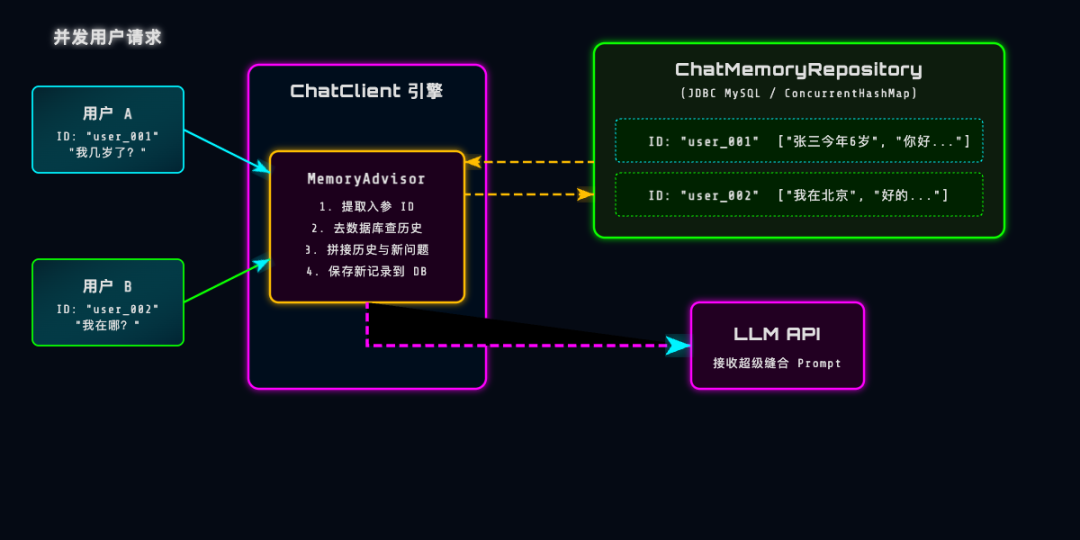
在这张图中,核心的秘密在于 ChatMemoryRepository。它就像一个巨大的文件柜:
- 抽屉(Key):就是我们传入的
conversationId(会话 ID,比如user_001)。 - 内容(Value):就是这个用户之前和 AI 聊过的所有记录(
List<Message>)。
每次收到用户的提问时,MemoryAdvisor 会根据请求中的 ID,自动去文件柜里拉出这个人的历史数据,彻底解放了开发者的双手!
大模型为什么会失忆?
在深入代码之前,我们必须纠正一个常见的思维误区:很多初学者以为,大模型是一个随时可以记忆数据的“机器人朋友”。
大模型(无论是 ChatGPT、DeepSeek 还是通义千问)在调用 API 时,本质上是一个极其无情的、无状态 (Stateless) 的数学函数:f(prompt) = response。
当你的 HTTP 请求发送过去时,它只认你这次发送的文本。一旦请求结束,你的数据就会在它的内存里被无情抹去。
**那网页版的 Deepseek 是怎么记住我刚才说的话的呢?**答案简单粗暴:它的前端网页或后端数据库,悄悄帮你把聊天记录全都存了下来。每次你发新消息时,系统会把“之前的聊天记录 + 你的新问题”揉成一个超级大的文本,整个打包发给大模型!
在 Spring AI 中,这些聊天记录被抽象为两个核心接口:
ChatMemory:负责管理策略(比如只保留最近的 10 条消息,防止记忆太长撑爆 Token)。ChatMemoryRepository:负责物理存储(存在内存里、还是存进 MySQL)。
引入 ChatMemory 与 Advisor
在不使用框架的 AI 开发时,我们一般会在 Java 里手动建一个 List<Message>,每次对话要自己的提问和 AI 的回答 add() 进去,极其繁琐。
在Spring AI框架中,我们可以利用 ChatClient 提供的流式 API 与 内置顾问 (Advisor) 直接省略着繁琐的操作,接下来我们便开始学习如何使用吧。
第一步:注册全局记忆组件
为了让系统拥有记忆能力,我们需要在 Spring 容器中注册一个 ChatMemory。最简单的方式是使用 MessageWindowChatMemory(滑动窗口记忆法, 会维护一个消息窗口,窗口大小不超过指定上限。当消息数量超过上限时,系统会删除较旧的消息,但会保留系统消息。默认窗口大小为 20 条消息。),它默认使用 InMemoryChatMemoryRepository(本质上就是一个 ConcurrentHashMap)把数据存在 JVM 内存里。
这一步我们完全可以不用自己做,当我们引入模型相关的starter的时候(如:spring-ai-starter-model-deepseek),Spring会自动帮我们向容器中注册ChatMemoryRepository 和 MessageWindowChatMemory,代码如下:
/** * 自动装配 * * 公众号:春风不晚 */@AutoConfiguration@ConditionalOnClass({ChatMemory.class, ChatMemoryRepository.class})public class ChatMemoryAutoConfiguration { @Bean @ConditionalOnMissingBean ChatMemoryRepository chatMemoryRepository() { return new InMemoryChatMemoryRepository(); } @Bean @ConditionalOnMissingBean ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) { return MessageWindowChatMemory.builder().chatMemoryRepository(chatMemoryRepository).build(); }}
@ConditionalOnMissingBean标注Bean,意味着我们可以自己在项目的配置文件中根据需要自行替换。
第二步:挂载 Memory Advisor
接下来,我们将这个全局的 chatMemory 组件,通过拦截器挂载到 ChatClient 上。
/** * 自动记忆 * * @author 公众号:春风不晚 */@RestControllerpublic class AutoMemoryController { private final ChatClient chatClient; // 构造器注入 Builder 和 ChatMemory public AutoMemoryController(ChatClient.Builder builder, ChatMemory chatMemory) { this.chatClient = builder // 为 ChatClient 挂载全局记忆拦截器 .defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()) .defaultSystem("你是一个贴心的私人助理,你需要努力记住用户的偏好。") .build(); } @GetMapping("/api/chat") public String chatWithMemory(@RequestParam String msg) { // 由于配置了 Advisor,每次 call() 前后都会自动读写 chatMemory! return chatClient.prompt() .user(msg) .call() .content(); }}
测试:
先访问 /api/chat?msg=我叫张三,我最喜欢吃火锅。

然后再访问 /api/chat?msg=我是谁,我喜欢吃什么?。

我们会发现 AI 终于不失忆了!
解决记忆“串线”问题
上面的代码虽然能用,但在真实的服务器上会导致灾难性后果。由于我们只注册了一个全局的 ChatMemory,如果张三和李四同时访问 /api/chat 接口,张三会看到李四的聊天记录!这就变成了大型精神分裂现场。
为了实现多租户(多用户)隔离,我们必须在每次请求时,通过 ChatMemory.CONVERSATION_ID 告诉 Advisor:当前这句话,属于哪个用户的抽屉?
我们可以稍微改造一下 Controller:
/** * @param userId 用户的唯一标识 (例如登录用户的 token 或 uuid) * @param msg 用户的新问题 */ @GetMapping("/api/chat/isolated") public String chatWithIsolatedMemory( @RequestParam String userId, @RequestParam String msg) { return chatClient.prompt() .user(msg) //在每次请求时,动态传入用户的专属会话 ID,取值见BaseChatMemoryAdvisor#getConversationId .advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId)) // 设置值在call()时,见:DefaultChatClientUtils#toChatClientRequest .call() .content(); }
测试:
1、访问:/api/chat/isolated?userId=zhangsan&msg=我叫张三

2、访问:/api/chat/isolated?userId=lisi&msg=我叫李四

3、交叉访问:/api/chat/isolated?userId=lisi&msg=你知道张三吗?

物理隔离完美生效!
从内存到 JDBC 数据库持久化
InMemoryChatMemory 把数据存在 JVM 的 ConcurrentHashMap 里。这意味着只要你的 Spring Boot 服务一重启,所有的历史记录都将丢失。这在生产环境中是绝对不可接受的。
Spring AI 提供了官方的 JDBC 存储方案,让我们几行代码就能把聊天记录持久化到 MySQL 或 PostgreSQL 中。
1. 引入 JDBC 依赖
在你的 pom.xml 中加入:
<!-- JDBC 记忆库官方 Starter --><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId></dependency><dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <scope>runtime</scope> <version>${mysql.version}</version></dependency>
2. 配置数据库连接
在 application.yml 中配置好 MySQL链接 和 memory的初始化策略:
spring: ai: chat: memory: repository: jdbc:# 初始化数据库,默认值是embedded,仅对嵌入式数据库自动创建表,如:H2、HSQL等嵌入式数据库 initialize-schema: always datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/springai?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowPublicKeyRetrieval=true&useSSL=false&allowMultiQueries=true username: root password: 123456
配置initialize-schema Spring AI 启动时会自动在库中创建名为:
spring_ai_chat_memory 的表,无需手动建表
3. 将 Memory 库切换为 Jdbc 驱动
package com.uka.springai.demo;import org.springframework.ai.chat.memory.ChatMemory;import org.springframework.ai.chat.memory.MessageWindowChatMemory;import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;import org.springframework.ai.chat.memory.repository.jdbc.MysqlChatMemoryRepositoryDialect;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.jdbc.core.JdbcTemplate;/** * JDBC 存储记忆 * * @author 公众号:春风不晚 */@Configurationpublic class AiMemoryConfig { @Bean public ChatMemory chatMemory(JdbcTemplate jdbcTemplate) { // 1. 构建基于 MySQL 语法的 JDBC 记忆库,手动创建repository,也可以通过@Bean 覆盖 JdbcChatMemoryRepository repository = JdbcChatMemoryRepository.builder() .jdbcTemplate(jdbcTemplate) // 设置mysql方言 .dialect(new MysqlChatMemoryRepositoryDialect()) .build(); // 2. 将此 Repository 注入到滑动窗口策略中 return MessageWindowChatMemory.builder() .chatMemoryRepository(repository) .build(); }}
再调用之前的 /api/chat/isolated 接口,所有的对话记录都将被永久地存入MySQL 数据库中。服务器断电重启,只要你传入相同的 userId,大模型就能精准回忆起之前的对话!
JDBC自动装配
上面我们给大家演示的是手动构建ChatMemory,由于我们引入的是spring-ai-starter-model-chat-memory-repository-jdbc,因此Spring 已经帮我们自动装配了了这个JdbcChatMemoryRepository,因此第3步替换的操作我们也可以选择忽略,Spring自动装配代码如下:
@AutoConfiguration( after = {JdbcTemplateAutoConfiguration.class}, // 在ChatMemoryAutoConfiguration之前执行,即可覆盖ChatMemoryAutoConfiguration中的内存存储 before = {ChatMemoryAutoConfiguration.class})@ConditionalOnClass({JdbcChatMemoryRepository.class, DataSource.class, JdbcTemplate.class})@EnableConfigurationProperties({JdbcChatMemoryRepositoryProperties.class})public class JdbcChatMemoryRepositoryAutoConfiguration { @Bean @ConditionalOnMissingBean JdbcChatMemoryRepository jdbcChatMemoryRepository(JdbcTemplate jdbcTemplate, DataSource dataSource) { // 根据数据库配置 获取数据库方言 JdbcChatMemoryRepositoryDialect dialect = JdbcChatMemoryRepositoryDialect.from(dataSource); return JdbcChatMemoryRepository.builder().jdbcTemplate(jdbcTemplate).dialect(dialect).build(); } // ....}
总结
在本节课中,我们终于赋予了 AI 长久且安全的记忆能力。 依托于 Spring AI 强大的 MessageChatMemoryAdvisor 切面机制,我们不仅彻底消灭了繁琐的“手动拼接历史”的代码,更运用了 CONVERSATION_ID 轻松实现了企业级的多租户物理隔离。
最后,通过引入 JdbcChatMemoryRepository,可以做到不修改任何代码,将记忆从内存平滑迁移到了 MySQL 关系型数据库中,达到了完全可直接上线的生产级别。
下节预告
随着用户和 AI 聊天的进行,虽然我们使用记忆能力记录了大量的上下文,这可能导致传递给大模型的 Prompt 越来越大。这不仅会导致 API 计费爆炸(Token 太贵),甚至会因为超出大模型的窗口限制而直接报错 OOM。
在 第 8 节:《告别 Token 刺客!Spring AI 记忆裁剪源码解密与 Token 级防溢出终极奥义》 中,我们将深入剖析 Token 的本质,并学习如何在 Spring AI 中精确计算和动态裁剪长文本,守住你的钱包和服务器的底线!
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)