11、LangChain 组件:Short-term Memory(短期记忆)
详细介绍短期记忆的核心概念、使用方法、生产环境配置及高级技巧,助力 AI Agent 实现对话上下文管理。
一、概述
记忆是 AI Agent 记住历史交互信息的核心组件,短期记忆(Short-term memory)用于在单个对话线程中保存历史交互,支持 Agent 跨多轮对话保持上下文一致性。
核心特点:
- 线程隔离:不同对话线程的记忆相互独立(通过
thread_id区分) - 上下文管理:解决 LLM 上下文窗口限制问题
- 状态持久化:通过 Checkpointer 存储对话状态,支持断点续聊
- 与长期记忆的区别:短期记忆仅作用于单个线程,跨会话需使用 Long-term memory
关键挑战:
- 长对话可能超出 LLM 上下文窗口,导致信息丢失或报错
- 冗余历史信息会降低 LLM 响应速度、增加成本并影响准确性
二、快速使用
通过指定 checkpointer 为 Agent 添加短期记忆,默认使用内存存储(仅适用于开发环境)。
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 创建带短期记忆的 Agent
agent = create_agent(
"gpt-5", # 替换为实际使用的模型(如 gpt-4o、claude-3 等)
tools=[get_user_info], # 替换为自定义工具列表
checkpointer=InMemorySaver(), # 内存级 Checkpointer(开发环境用)
)
# 发起带线程 ID 的对话(同一 thread_id 共享上下文)
agent.invoke(
{"messages": [{"role": "user", "content": "Hi! My name is Bob."}]},
{"configurable": {"thread_id": "conversation-1"}}, # 对话线程唯一标识
)
三、生产环境配置
生产环境需使用数据库-backed 的 Checkpointer,支持 Postgres、SQLite、Azure Cosmos DB 等,以下以 Postgres 为例:
1. 安装依赖
pip install langgraph-checkpoint-postgres
2. 配置 Postgres Checkpointer
from langchain.agents import create_agent
from langgraph.checkpoint.postgres import PostgresSaver
# 数据库连接 URI(替换为实际配置)
DB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
# 初始化 Checkpointer 并自动创建数据表
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 自动创建所需数据表
agent = create_agent(
"gpt-5",
tools=[get_user_info],
checkpointer=checkpointer, # 生产环境 Checkpointer
)
其他数据库支持:LangChain Checkpointer 官方列表
四、自定义 Agent 记忆
默认使用 AgentState 管理对话历史(messages 字段),可通过继承 AgentState 扩展自定义字段(如用户 ID、偏好设置等)。
from langchain.agents import create_agent, AgentState
from langgraph.checkpoint.memory import InMemorySaver
# 自定义状态 schema(扩展记忆字段)
class CustomAgentState(AgentState):
user_id: str # 用户唯一标识
preferences: dict # 用户偏好(如主题、语言等)
# 创建带自定义记忆的 Agent
agent = create_agent(
"gpt-5",
tools=[get_user_info],
state_schema=CustomAgentState, # 指定自定义状态
checkpointer=InMemorySaver(),
)
# 调用时传入自定义状态字段
result = agent.invoke(
{
"messages": [{"role": "user", "content": "Hello"}],
"user_id": "user_123",
"preferences": {"theme": "dark", "language": "en"}
},
{"configurable": {"thread_id": "conversation-1"}}
)
五、常见记忆管理模式
为解决长对话上下文窗口溢出问题,LangChain 支持三种核心记忆管理策略:
5.1 截断消息(Trim messages)
保留最近的 N 条消息,删除早期冗余内容,适用于对历史细节要求不高的场景。
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from typing import Any
# 定义模型调用前的消息截断中间件
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""保留最后 3-4 条消息(含系统消息),适配上下文窗口"""
messages = state["messages"]
if len(messages) :
return None # 消息数量较少,无需截断
# 保留第一条消息(通常是系统提示)+ 最近的 3-4 条交互
first_msg = messages[0]
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), # 清除原有消息
*new_messages # 添加筛选后的消息
]
}
# 注册中间件
agent = create_agent(
"gpt-5-nano",
tools=[],
middleware=[trim_messages], # 绑定截断中间件
checkpointer=InMemorySaver(),
)
# 测试多轮对话(即使超过 3 轮也能记住关键信息)
config = {"configurable": {"thread_id": "conversation-1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
# 输出结果:AI 能记住用户名 Bob
final_response["messages"][-1].pretty_print()
5.2 删除消息(Delete messages)
永久删除指定消息或全部消息,适用于需要清理敏感信息或无效交互的场景。
5.2.1 删除指定消息
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
def delete_early_messages(state: AgentState):
"""删除最早的 2 条消息"""
messages = state["messages"]
if len(messages) > 2:
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
return None
5.2.2 清空所有消息
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langchain.messages import RemoveMessage
def clear_all_messages(state: AgentState):
"""清空全部对话历史"""
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}
5.2.3 模型调用后自动清理
from langchain.agents.middleware import after_model
@after_model
def delete_old_messages(state: AgentState, runtime: Runtime) -> dict | None:
"""对话超过 2 轮后,自动删除最早的 2 条消息"""
messages = state["messages"]
if len(messages) > 2:
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
return None
# 绑定清理中间件
agent = create_agent(
"gpt-5-nano",
tools=[],
middleware=[delete_old_messages],
checkpointer=InMemorySaver(),
)
5.3 总结消息(Summarize messages)
通过 LLM 总结早期对话内容,用摘要替代原始消息,兼顾上下文完整性和窗口限制。
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
# 初始化总结中间件
checkpointer = InMemorySaver()
agent = create_agent(
model="gpt-4.1",
tools=[],
middleware=[
SummarizationMiddleware(
model="gpt-4.1-mini", # 用于生成摘要的轻量模型
trigger=("tokens", 4000), # 令牌数超过 4000 时触发总结
keep=("messages", 20) # 保留最近 20 条原始消息
)
],
checkpointer=checkpointer,
)
# 测试长对话(即使多轮交互也能记住核心信息)
config = {"configurable": {"thread_id": "conversation-1"}}
agent.invoke({"messages": "hi, my name is bob"}, config)
agent.invoke({"messages": "write a short poem about cats"}, config)
agent.invoke({"messages": "now do the same but for dogs"}, config)
final_response = agent.invoke({"messages": "what's my name?"}, config)
# 输出结果:AI 通过摘要记住用户名 Bob
final_response["messages"][-1].pretty_print()
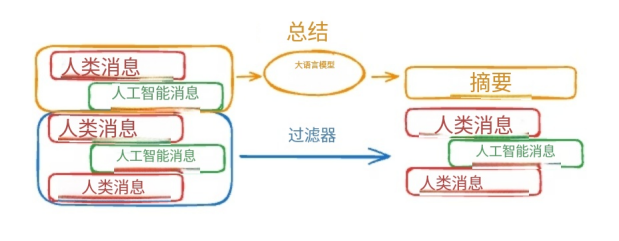
六、访问和修改记忆
6.1 工具中操作记忆
6.1.1 读取短期记忆
通过 ToolRuntime 访问 Agent 状态(隐藏参数,不暴露给 LLM):
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
# 自定义状态(含 user_id 字段)
class CustomState(AgentState):
user_id: str
# 工具中读取状态
@tool
def get_user_info(runtime: ToolRuntime) -> str:
"""根据 user_id 查询用户信息"""
user_id = runtime.state["user_id"] # 读取状态中的 user_id
return "User is John Smith" if user_id == "user_123" else "Unknown user"
# 初始化 Agent
agent = create_agent(
model="gpt-5-nano",
tools=[get_user_info],
state_schema=CustomState,
)
# 调用工具(传入 user_id)
result = agent.invoke({
"messages": "look up user information",
"user_id": "user_123"
})
print(result["messages"][-1].content) # 输出:User is John Smith
6.1.2 写入短期记忆
工具中通过 Command 直接更新 Agent 状态:
from langchain.tools import tool, ToolRuntime
from langchain_core.runnables import RunnableConfig
from langchain.messages import ToolMessage
from langchain.agents import create_agent, AgentState
from langgraph.types import Command
from pydantic import BaseModel
# 自定义状态(含 user_name 字段)
class CustomState(AgentState):
user_name: str
# 自定义上下文(传入 user_id)
class CustomContext(BaseModel):
user_id: str
# 工具中更新状态
@tool
def update_user_info(
runtime: ToolRuntime[CustomContext, CustomState],
) -> Command:
"""查询并更新用户姓名到状态中"""
user_id = runtime.context.user_id
name = "John Smith" if user_id == "user_123" else "Unknown user"
return Command(update={
"user_name": name, # 更新 user_name 字段
"messages": [ToolMessage(
"Successfully looked up user information",
tool_call_id=runtime.tool_call_id
)]
})
# 初始化 Agent
agent = create_agent(
model="gpt-5-nano",
tools=[update_user_info],
state_schema=CustomState,
context_schema=CustomContext,
)
# 调用工具并更新状态
agent.invoke(
{"messages": [{"role": "user", "content": "update user info"}]},
context=CustomContext(user_id="user_123"),
)
6.2 动态 Prompt 中使用记忆
通过中间件动态生成 Prompt,融入状态信息:
from langchain.agents import create_agent
from typing import TypedDict
from langchain.agents.middleware import dynamic_prompt, ModelRequest
# 自定义上下文
class CustomContext(TypedDict):
user_name: str
# 示例工具
def get_weather(city: str) -> str:
"""查询城市天气"""
return f"The weather in {city} is always sunny!"
# 动态生成系统提示(融入用户名)
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
user_name = request.runtime.context["user_name"]
return f"You are a helpful assistant. Address the user as {user_name}."
# 初始化 Agent
agent = create_agent(
model="gpt-5-nano",
tools=[get_weather],
middleware=[dynamic_system_prompt],
context_schema=CustomContext,
)
# 调用(传入用户名)
result = agent.invoke(
{"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
context=CustomContext(user_name="John Smith"),
)
# 输出结果:AI 会以 "Hi John Smith" 开头回应
for msg in result["messages"]:
msg.pretty_print()
6.3 模型调用前处理记忆(Before model)
在 LLM 调用前修改状态(如截断、过滤消息),示例见 5.1 截断消息。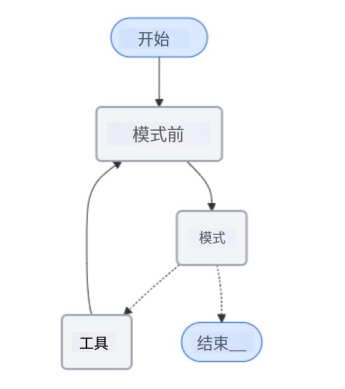
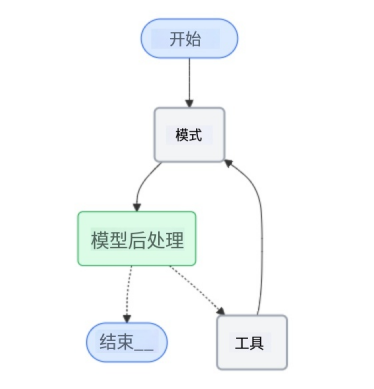
6.4 模型调用后处理记忆(After model)
在 LLM 响应后清理或更新状态(如删除敏感信息):
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.runtime import Runtime
# 定义模型调用后的消息过滤中间件
@after_model
def validate_response(state: AgentState, runtime: Runtime) -> dict | None:
"""删除包含敏感词的响应消息"""
STOP_WORDS = ["password", "secret", "token"]
last_message = state["messages"][-1]
if any(word in last_message.content.lower() for word in STOP_WORDS):
return {"messages": [RemoveMessage(id=last_message.id)]} # 删除敏感消息
return None
# 绑定中间件
agent = create_agent(
model="gpt-5-nano",
tools=[],
middleware=[validate_response],
checkpointer=InMemorySaver(),
)
参考链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)