Java 程序员的 AI 转型第六课:Spring AI 灵魂架构 Advisor 切面拦截与自定义实战
欢迎来到《Spring AI 零基础到实战》的第 6 节!
在前面的课程中,我们让 AI 拥有了人设,学会了看图,实现了JSON 映射和打字机流式输出。至此,你已经掌握了单次 AI 调用的所有基础。
但实际的 AI 应用开发中,工作流远比这复杂得多,我们会面临一系列复杂的工程问题:
- 可观测性:想在每次请求 AI 前后打印完整的日志,计算消耗了多少 Token。
- 记忆上下文:大模型没有记忆,需要在每次请求前,把前 10 轮的聊天记录拼接到提示词里。
- RAG 检索增强:遇到专业问题,需要先去本地知识库检索文档,再塞给大模型。
难道要把这些逻辑,硬编码散落到每一个 Controller 接口里吗?
Spring 团队给出了极其优雅的破局之道:不造反直觉的语法糖,回归 Java 开发者最熟悉的底层哲学——AOP(面向切面编程)! 本节我们将深入了解 Spring AI 的灵魂组件:ChatClient 与 Advisors,看看现代 AI 工作流到底该怎么写!
本节章节目标
- 认知重塑:理解为什么 Spring AI 抛弃复杂的管道语法,选择 AOP 模式。
- 源码解密:掌握
Advisor的核心接口定义、执行顺序控制以及请求/响应的载体结构。 - 手写实战:手写一个自定义的
SimpleLoggerAdvisor,同时兼容同步与流式调用的拦截。 - 官方武器库:全面了解 Spring AI 内置的开箱即用的顾问(记忆、RAG、风控、重读提示)。
Advisor 拦截器链的逻辑处理
在看源码之前,我们先通过下面的架构图,直观地感受一下:当在 ChatClient 中触发 .call() 时,请求是如何穿过层层 Advisor 拦截器,最终到达大模型的?
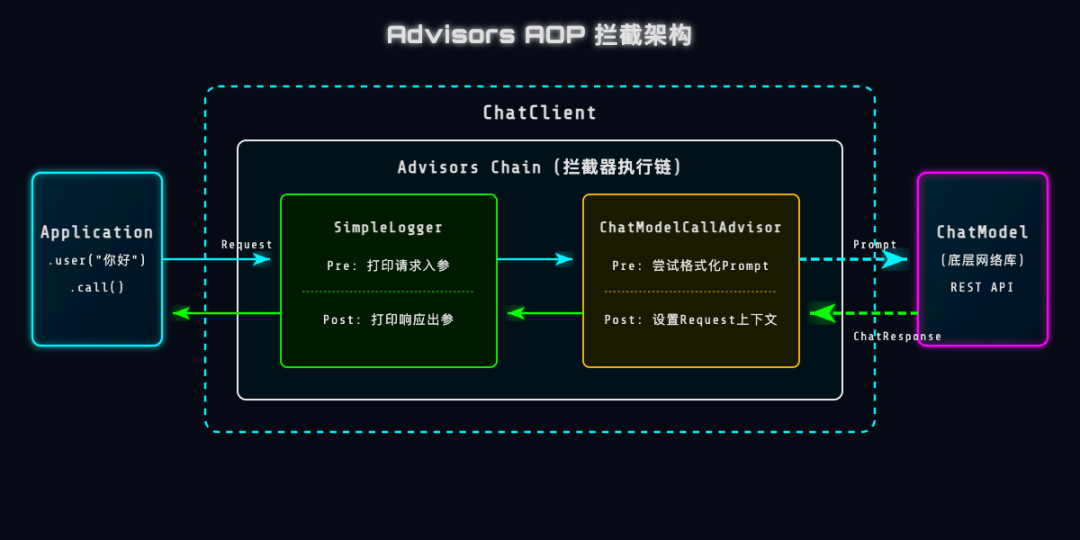
执行流程:
当执行 .call() 时,请求会被打包成 ChatClientRequest,依次穿过配置的 Advisor 链。每个 Advisor 都可以修改请求(上节课Java 程序员的 AI 转型第五课:让 AI 懂规矩!Spring AI 结构化输出 (DTO) 映射与 Flux 流式打字机极速响应就是采用 ChatModelCallAdvisor拦截处理结构化问题)。然后到达底层的 ChatModel 获取到 ChatClientResponse。接着,响应数据再原路返回穿过 Advisor 链,最终交到你手中。
Advisor 的执行采用了经典的责任链模式。通过 getOrder() 方法确定顺序:值越小,在发请求时(Pre-process)越先执行;而在处理响应时(Post-process)则越后执行。就像穿衣服和脱衣服的关系。
AOP 思想在 AI 调用中的投射
Advisor(顾问)是 Spring AI 的灵魂设计。它旨在解决 AI 交互中大量重复出现的模式(如维护历史、检索文档、过滤敏感词等)。
如果熟悉 Spring MVC 的 Interceptor,或者 Servlet 的 Filter,甚至 Spring 核心的 @Around 环绕通知,那么理解 Advisor 将毫无门槛。我们可以将 Spring AI 的架构完美映射到 AOP 的概念上:
| AOP 概念 | Spring Web 概念 | Spring AI 概念 | 作用说明 |
|---|---|---|---|
| Target (目标) | Controller 逻辑 |
ChatModel |
真正负责与 OpenAI 等大模型通信的底层客户端。 |
| Proxy (代理) | DispatcherServlet |
ChatClient |
开发者直接调用的入口,负责组装请求并触发拦截链。 |
| Advice (通知) | Filter/Interceptor |
Advisor |
核心! 拦截请求与响应,将非业务逻辑(记忆、日志、检索)解耦。 |
| Join Point | 接口被调用的瞬间 | call()/stream() |
触发大模型调用的动作。 |
Advisor 核心接口解构
要自定义一个 Advisor,我们需要了解它的基础骨架。
2.1 核心接口规范
- Advisor:所有顾问的基接口。它继承了 Spring 的 Ordered 接口,必须实现 getName() 和 getOrder()。
- getOrder():极其重要! 决定拦截器的执行顺序。值越小,在 Request 阶段越先执行,但在 Response 阶段越后处理响应。
- CallAdvisor:用于拦截 .call() 同步请求,核心方法是 adviseCall()。
- StreamAdvisor:用于拦截 .stream() 流式请求,核心方法是 adviseStream()。
2.2 数据传输载体 (DTO)
- ChatClientRequest:里面包含了即将发给大模型的 Prompt、系统指令、参数配置等。你可以随意修改它。
- ChatClientResponse:大模型返回的原始响应,包含文本内容和 Token 消耗等元数据。
- AdvisorContext:这是一个 Map,可以在不同的 Advisor 之间共享数据(比如传递对话 ID)。
一个日志拦截器案例
很多时候,我们发现 AI 回答得不好,可能是因为我们传给大模型的最终 Prompt 拼接错了。为了方便调试,我们来手写一个日志拦截器,它会在请求发出前打印参数,在结果返回后打印响应。
最佳实践:如果可以,Advisor 应该同时实现
CallAdvisor(拦截同步请求)和StreamAdvisor(拦截流式请求)。以确保在两种模式下都工作。
创建类 SimpleLoggerAdvisor:
import lombok.extern.slf4j.Slf4j;import org.springframework.ai.chat.client.ChatClientMessageAggregator;import org.springframework.ai.chat.client.ChatClientRequest;import org.springframework.ai.chat.client.ChatClientResponse;import org.springframework.ai.chat.client.advisor.api.CallAdvisor;import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;import org.springframework.ai.chat.client.advisor.api.StreamAdvisor;import org.springframework.ai.chat.client.advisor.api.StreamAdvisorChain;import reactor.core.publisher.Flux;/** * 自定义日志拦截器(顾问) */@Slf4jpublicclass SimpleLoggerAdvisor implements CallAdvisor, StreamAdvisor { @Override public String getName() { returnthis.getClass().getSimpleName(); } /** * 顺序控制:设为 0 表示优先级很高,最外层执行 */ @Override public int getOrder() { return0; } // ================= 拦截同步调用 (.call) ================= @Override public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) { // 请求大模型前:打印请求头和 Prompt logRequest(request); // 放行请求,交给链条中的下一个 Advisor 或底层 ChatModel ChatClientResponse response = chain.nextCall(request); // 拿到大模型结果后:打印返回信息 logResponse(response); return response; } // ================= 拦截流式调用 (.stream) ================= @Override public Flux<ChatClientResponse> adviseStream(ChatClientRequest request, StreamAdvisorChain chain) { // [Pre-process] 请求发出前打印 logRequest(request); // 放行流式请求 Flux<ChatClientResponse> responseFlux = chain.nextStream(request); // 注意:流式响应是一点点回来的。 // 我们使用 ChatClientMessageAggregator 将所有碎片段拼接完整后,再执行打印 returnnew ChatClientMessageAggregator() .aggregateChatClientResponse(responseFlux, this::logResponse); } // 内部打印方法 private void logRequest(ChatClientRequest request) { log.info("[发往大模型的请求]: {}", request); } private void logResponse(ChatClientResponse response) { log.info(" [大模型的完整响应]: {}", response); }}
如何将自定义 Advisor 挂载到 ChatClient?
非常简单,只需在 ChatClient 构建时,使用 .advisors() 挂载即可:
@Test void testOllamaClient() { String result = chatClient.prompt() .user("你好, 请介绍一下 Spring AI") // 挂载我们刚刚写的日志顾问 .advisors(new SimpleLoggerAdvisor()) .call() .content(); System.out.println("最终结果:" + result); }
运行测试,控制台可以看到拦截器打印出的完整请求报文和响应体!
[发往大模型的请求]: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='你好, 请介绍一下 Spring AI'....[大模型的完整响应]: ChatClientResponse[..., textContent=Spring AI 是一个由 Spring 官方团队推出的项目,旨在将人工智能能力....
Spring AI 内置的 Advisors
懂了 Advisor 的原理,我们不仅能自己写拦截器,更能无缝使用 Spring 团队为我们预置的强大内置库。日常业务中 90% 的高级 AI 需求,都可以直接使用。
1. 聊天记忆顾问 (Memory)
解决 AI 只有 7 秒记忆的问题。
MessageChatMemoryAdvisor:自动检索历史聊天记录,并以Message对象列表的形式追加到请求中。PromptChatMemoryAdvisor:将历史记录直接拼接成文本,塞到 System 提示词中。VectorStoreChatMemoryAdvisor:将会话历史存入向量数据库,对话时自动检索最相关的记忆片段。
2. 检索增强顾问 (RAG)
企业级私有知识库的核心!
QuestionAnswerAdvisor:结合向量数据库,将检索到的企业私有文档自动追加到 Prompt 中,实现外挂大脑。RetrievalAugmentationAdvisor:更高级的模块化 RAG 流程控制组件。
3. 推理增强顾问 (Reasoning)
ReReadingAdvisor:基于著名的 RE2 论文实现。它会自动让大模型把你的问题“重读一遍”,能显著提升大模型处理复杂逻辑题的准确率。
4. 内容安全顾问 (Safeguard)
SafeGuardAdvisor:在请求发送前和响应返回后,自动检测并过滤有害内容、敏感词,确保 AI 输出合规安全。
Advisor开发最佳实践
在使用或编写 Advisor 时,请牢记以下四点心法:
- 单一职责:每个顾问只干一件事(比如只记录日志,或只处理记忆),不要在一个 Advisor 里写几千行代码。
- 上下文共享:如果在多个 Advisor 之间需要传递数据(比如当前用户的 ID),请使用
ChatClientRequest.getAdviseContext(),它本质上是一个跨越整个拦截链的 Map。 - 兼容双模式:强烈建议同时实现
CallAdvisor和StreamAdvisor,以确保你的拦截逻辑在同步和打字机流式调用下都能生效。 - 严格控制顺序:通过认真规划
getOrder()的返回值,确保数据流的绝对正确。例如:内容过滤的 Advisor Order 必须尽量小(在外层拦截毒词),而 RAG 的 Advisor Order 稍微靠后(处理完最终的 Query 再去检索)
总结
Spring 团队运用高超的架构内功,使用经典的 AOP 拦截器模式,完美消解了 AI 提示词工程的复杂度。利用 Advisor,我们可以把日志、记忆、RAG 检索、内容过滤等非业务逻辑彻底解耦。
这不仅降低了 Java 开发者的学习成本,更让代码拥有了极强的扩展性。ChatClient 就像一个精密的主板,而所有的 Advisor 都是即插即用的显卡和内存条!
下节预告
理论武器已经装配完毕,接下来到了真刀真枪实战的时刻。
在通过代码调用 API 时,我们会发现 AI 天生就是个失忆症患者——它根本记不住你上一秒说了什么!
在下一节 第 7 节:《AI 失忆症克星!ChatMemory 对话历史管理与上下文实战》 中,我们将深入剖析大模型失忆的本质原因,并使用本节学到的 MessageChatMemoryAdvisor 结合各种内存与分布式存储方案,手把手教你打造一个拥有“长久记忆”的完美 AI 客服!
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)