【Azure 架构师学习笔记 】- Azure AI(22) -AI知识库Agent平台(1)- 项目启动及基础搭建
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(21) - Azure Agent进阶优化
前言
接下来打算用几篇文章来演示一个知识库Agent平台的搭建。把它当成一个“项目”来做。
一、整体规划
- 项目总内容:围绕企业级AI知识库Agent平台核心功能,分8步完成基础搭建与RAG核心落地。 全程优先使用免费工具/系统自带工具。
- 8步计划及当前进度:
- 第1步:项目初始化与需求拆解(当前进度:正在推进)
- 第2步:文档处理模块升级(从单文件到批量+标准化,复用免费工具)
- 第3步:RAG核心——文档分块策略
- 第4步:向量嵌入与向量数据库实操(Milvus,开源免费,搭配免费可视化工具)
- 第5步:RAG闭环实现(检索+生成+幻觉优化,用免费工具调试)
- 第6步:混合检索(向量+关键词)优化检索效果(基于免费工具扩展)
- 第7步:多轮问答与记忆系统升级(无需付费LLM,可适配开源免费模型)
- 第8步:项目复盘与优化(架构思维培养,用免费工具整理复盘报告)
- 当前所处步骤:第1步 项目初始化与需求拆解(核心目标:完成项目初始化全流程,包括需求拆解、基础架构设计、开发环境搭建,衔接已有Azure OpenAI配置;)
二、第1步:项目初始化与需求拆解
一、讲解
第一天核心目标:完成「项目初始化全流程」,包括需求拆解、基础架构设计、开发环境搭建,无需额外找资料,跟着步骤走即可完成;全程优先使用系统自带工具、开源免费工具,无需付费,耗时1.5-2小时。
(一)需求拆解:企业级AI知识库Agent平台
需求拆解是架构师的核心能力,不能只列功能,要区分「功能需求」和「非功能需求」,同时结合已有的技术储备,避免冗余开发;可借助系统自带的记事本/备忘录(Windows记事本、Mac备忘录)或免费工具(如Notion、飞书文档)整理需求,无需复杂工具,简单记录即可。
- 功能需求:
- 文档批量上传:复用前面Word/PDF/TXT读取能力,新增Excel读取,支持文件夹批量上传,无需手动单个处理;后续实操可用系统自带的文件管理器辅助批量筛选文件。
- 文档分块:解决长文档语义丢失问题,为后续向量存储做准备;可借助免费工具(如Notepad++)模拟分块逻辑。
- 向量存储:将分块后的文本转换为向量,存入Milvus(向量库,开源免费),实现精准检索;Milvus可免费部署。
- 智能检索:先实现基础向量检索,后续升级为混合检索(向量+关键词),适配实际检索场景;检索调试可用免费工具(如Postman免费版)辅助。
- 多轮问答:对话记忆能力,实现上下文关联,无需用户重复提问;若暂无Azure OpenAI,可替换为开源免费LLM(如Llama 3、Qwen)。
- 总结导出:支持将问答结果、文档总结导出为Excel/TXT,贴合办公场景需求;导出功能用Python自带库实现。
- 非功能需求:
- 高可用:避免单点故障(如LLM调用失败、向量库崩溃),后续通过Docker/K8s实现(Docker免费,K8s开源免费)。
- 高并发:支持多用户同时上传、检索,后续通过批量处理、缓存优化实现;缓存可用Python自带的缓存库。
- 低延迟:检索+生成响应时间控制在1-2秒内,后续通过推理优化、索引优化实现;索引优化用Milvus自带功能。
- 可监控:能实时查看LLM调用状态、检索效果、系统报错,后续通过LLMOps实现(用开源免费工具Prometheus+Grafana)。
- 可扩展:支持后续添加权限管理、多租户、多Agent协作等功能,架构设计时预留扩展空间;扩展逻辑可用免费绘图工具绘制,方便后续对接。
- 成本可控:优化LLM调用Token消耗、向量库存储成本,后续通过缓存、量化实现。
(二)项目架构设计
架构设计无需复杂,重点是「模块化拆分」(高内聚、低耦合),让每个模块职责清晰,后续可独立扩展,同时衔接已有的技术能力;架构图优先使用免费/自带工具绘制,推荐3种免费方案。
- 免费绘图工具推荐(3种方案,均免费、易操作,适配新手):
- 方案1:系统自带工具(零成本,无需安装)—— Windows用「画图3D」,Mac用「预览」自带的绘图功能。
- 方案2:开源免费工具(功能完善)—— DrawIO(浏览器在线使用,支持导出PNG、PDF,架构师常用),官网:https://app.diagrams.net/,无需注册即可使用。
- 方案3:办公软件自带功能(复用性强)—— WPS/Office自带的「SmartArt」或「绘图」功能,简单拖拽模块,即可快速绘制模块化架构图,适合习惯用办公软件的同学。
- 核心架构图:
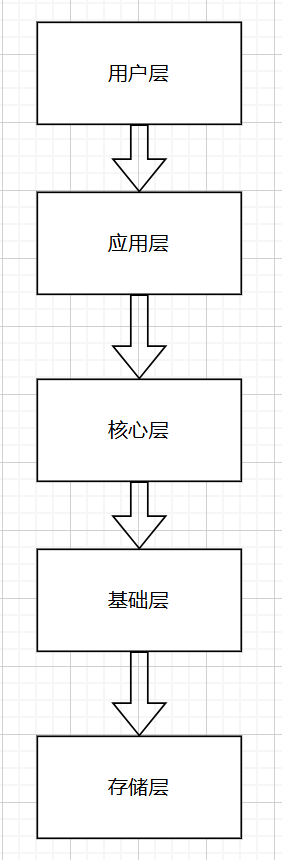
核心架构(分层清晰,用免费工具拖拽模块即可绘制,标注每个层的核心职责):
用户层 → 应用层 → 核心层 → 基础层 → 存储层
- 用户层:简化版Web界面。
- 应用层:封装用户交互逻辑(文件上传入口、问答输入框、结果展示、导出功能);用Python自带库实现。
- 核心层:3个核心模块(文档处理模块、RAG模块、Agent模块),每个模块独立封装,可单独优化;模块逻辑用如DrawIO绘制模块依赖图。
- 基础层:Python、Azure OpenAI(可替换为开源免费LLM:Llama 3、Qwen)、LangChain(开源免费)。
- 存储层:Milvus(开源免费,向量存储)、本地文件存储、配置文件存储(本地文件)。
- 架构图绘制步骤(以DrawIO为例):
-
第一步:打开DrawIO官网(https://app.diagrams.net/),无需注册,直接点击「开始绘制」,选择「空白绘图」。
-
第二步:在左侧「形状」栏,选择「矩形」,拖拽5个矩形到画布,分别命名为「用户层」「应用层」「核心层」「基础层」「存储层」,按从上到下的顺序排列。
-
第三步:用左侧「连接线」工具,连接5个层(用户层→应用层→核心层→基础层→存储层),标注箭头方向,体现层级依赖关系。
-
第四步:绘制完成后,点击顶部「文件」→「导出为」,选择PNG格式,保存到项目根目录,后续可插入文档或面试时展示。
- 核心模块职责:
- 文档处理模块:负责文件读取、批量处理、格式标准化、文档分块(复用文件处理能力,用Python自带库+免费工具辅助)。
- RAG模块:负责向量嵌入、向量检索、检索+生成闭环、幻觉优化(基于Milvus开源免费向量库)。
- Agent模块:负责多轮问答、记忆管理、工具调用(可适配开源免费LLM,降低成本)。
(三)开发环境搭建
复用已有的Python环境、Azure配置(若暂无,可后续替换为开源免费LLM),重点新增Milvus向量库安装,全程标注常见报错及解决方案,确保一次性成功;所有工具均为免费/开源,无需付费。
- 环境前提(确认你已具备,无需重复安装,均为免费工具/组件):
- Python 3.9-3.11(推荐3.10,开源免费,官网可直接下载,避免版本过高导致依赖包报错)。
- 已配置Azure OpenAI(若暂无,可先跳过,后续用开源免费LLM替换),拥有Endpoint、API Key、部署名(GPT-4、text-embedding-3-large)。
- 已安装基础依赖包:openpyxl(Excel读取,开源免费)、PyPDF2(PDF读取,开源免费)、python-docx(Word读取,开源免费)、requests(API调用,Python自带,免费)。
- 新增依赖包安装:
# 核心依赖(LangChain:简化Agent/RAG开发,开源免费;pymilvus:Milvus客户端,开源免费)
pip install langchain==0.1.10 pymilvus==2.4.4
# 辅助依赖(日志、配置文件解析,均开源免费)
pip install python-dotenv loguru
# 后续文档处理、检索辅助依赖(提前安装,避免后续重复操作,均开源免费)
pip install whoosh sentence-transformers
- Milvus向量库安装(两种方式,选一种即可,推荐方式1,简单易操作,开源免费):
方式1:Docker Compose安装(推荐,无需配置复杂环境,适合新手;Docker免费,Milvus开源免费)
- 第一步:安装Docker和Docker Compose(已安装可跳过)
- Windows:安装Docker Desktop(官网下载,免费版足够用,勾选“Use WSL 2 instead of Hyper-V”),安装完成后启动Docker。
- Mac:安装Docker Desktop(官网下载,免费版足够用),启动后在偏好设置中开启Docker Compose。
- 第二步:创建Milvus配置文件(docker-compose.yml),用系统自带的记事本(Windows)、文本编辑(Mac)或免费工具(Notepad++)编写。
- 创建根目录命名:enterprise-ai-knowledge-agent(企业级AI知识库Agent平台)
- 新建一个文件夹(命名为milvus),在文件夹中创建文件docker-compose.yml,复制以下内容(直接复制,无需修改):
version: '3.5'
services:
etcd:
image: quay.io/coreos/etcd:v3.5.5
container_name: milvus-etcd
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379
minio:
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
container_name: milvus-minio
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/data
command: minio server /data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
milvus:
image: milvusdb/milvus:v2.4.4
container_name: milvus-standalone
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- etcd
- minio
- 第三步:启动Milvus
- 确保docker服务启动。
- cmd 进入milvus文件夹,执行命令:docker-compose up -d
- 启动成功后,执行命令:docker ps,能看到3个容器(milvus-etcd、milvus-minio、milvus-standalone),状态为started即可。

方式2:本地安装(适合有一定环境配置经验的,略复杂,不推荐第一天尝试;)
- 常见报错及解决方案:
- 报错1:Docker启动失败(Windows)→ 解决方案:开启WSL 2,重启Docker,若仍失败,卸载Docker重新安装,勾选WSL 2选项。
- 报错2:Milvus容器启动后立即退出 → 解决方案:检查端口19530、9091是否被占用,执行命令(Windows):netstat -ano | findstr “19530”,找到占用进程并结束,再重启Milvus;同时注意,若访问http://127.0.0.1:2379 或 http://0.0.0.0:2379 提示“invalid link”,属于正常现象,该地址为Milvus内部依赖(etcd)的访问地址,无需手动访问,只需确认Milvus容器正常运行即可。
- 报错3:pip安装依赖包失败 → 解决方案:更换镜像源,执行命令:pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple;若访问该镜像源提示“link fetch error”,可更换为其他免费镜像源(如阿里云:https://mirrors.aliyun.com/pypi/simple/),均为免费可用。
- 报错4:Azure配置无法连接 → 解决方案:检查Endpoint、API Key是否正确,确认部署名与代码中一致,检查网络是否能访问Azure服务;若访问Azure Endpoint(如https://xxx.openai.azure.com/)提示“link dead”,需确认Endpoint地址是否正确、网络是否通畅,若暂无Azure,可后续替换为开源免费LLM(如Llama 3)。
- 环境验证(第一天收尾,确保所有环境正常,用免费工具辅助验证):
编写简单测试代码,验证Python环境、Azure OpenAI(或开源LLM)、Milvus是否能正常连接,代码直接复制粘贴即可运行;验证过程中可使用系统自带的命令行、免费的代码编辑器(如VS Code免费版、Notepad++)编写代码。
二、实操实践
实操核心:搭建规范的项目目录、整合配置文件、验证环境,确保第一天就能完成项目初始化;所有实操工具均为免费/自带,无需额外付费。
(一)项目目录搭建
目录结构决定项目的可扩展性,避免后续代码混乱,严格按照以下结构创建,每个文件夹的作用已标注,无需额外新增文件夹;创建目录用系统自带的文件管理器(Windows资源管理器)。
- 新建项目根目录(命名规范):
根目录命名:enterprise-ai-knowledge-agent(企业级AI知识库Agent平台) - 新建子文件夹及文件(逐一创建,不要遗漏):
enterprise-ai-knowledge-agent/ # 根目录
├── config/ # 配置文件(Azure、向量库、数据库)
│ ├── init.py # 空文件,标记为Python包
│ └── config.yaml # 配置文件,存储所有配置信息(核心)
├── core/ # 核心模块(RAG、Agent、文档处理)
│ ├── init.py
│ ├── rag/ # RAG模块(后续实现)
│ │ └── init.py
│ ├── agent/ # Agent模块(后续实现)
│ │ └── init.py
│ └── document/ # 文档处理模块(后续实现)
│ └── init.py
├── llm/ # LLM调用(Azure OpenAI、开源免费LLM)
│ ├── init.py
│ └── azure_llm.py # Azure OpenAI调用封装(可替换为开源LLM)
├── storage/ # 存储模块(向量库、文件存储)
│ ├── init.py
│ └── milvus_client.py # Milvus客户端封装
├── utils/ # 工具类(容错、日志、通用函数)
│ ├── init.py
│ └── logger.py # 日志工具
├── app/ # 应用层(简化版Web界面)
│ ├── init.py
│ └── app.py # 基础Web界面(Flask开源免费)
├── llmops/ # LLMOps模块(后续升级,用开源免费工具)
│ └── init.py
├── main.py # 项目入口(验证环境)
└── requirements.txt # 依赖包清单(第一天生成)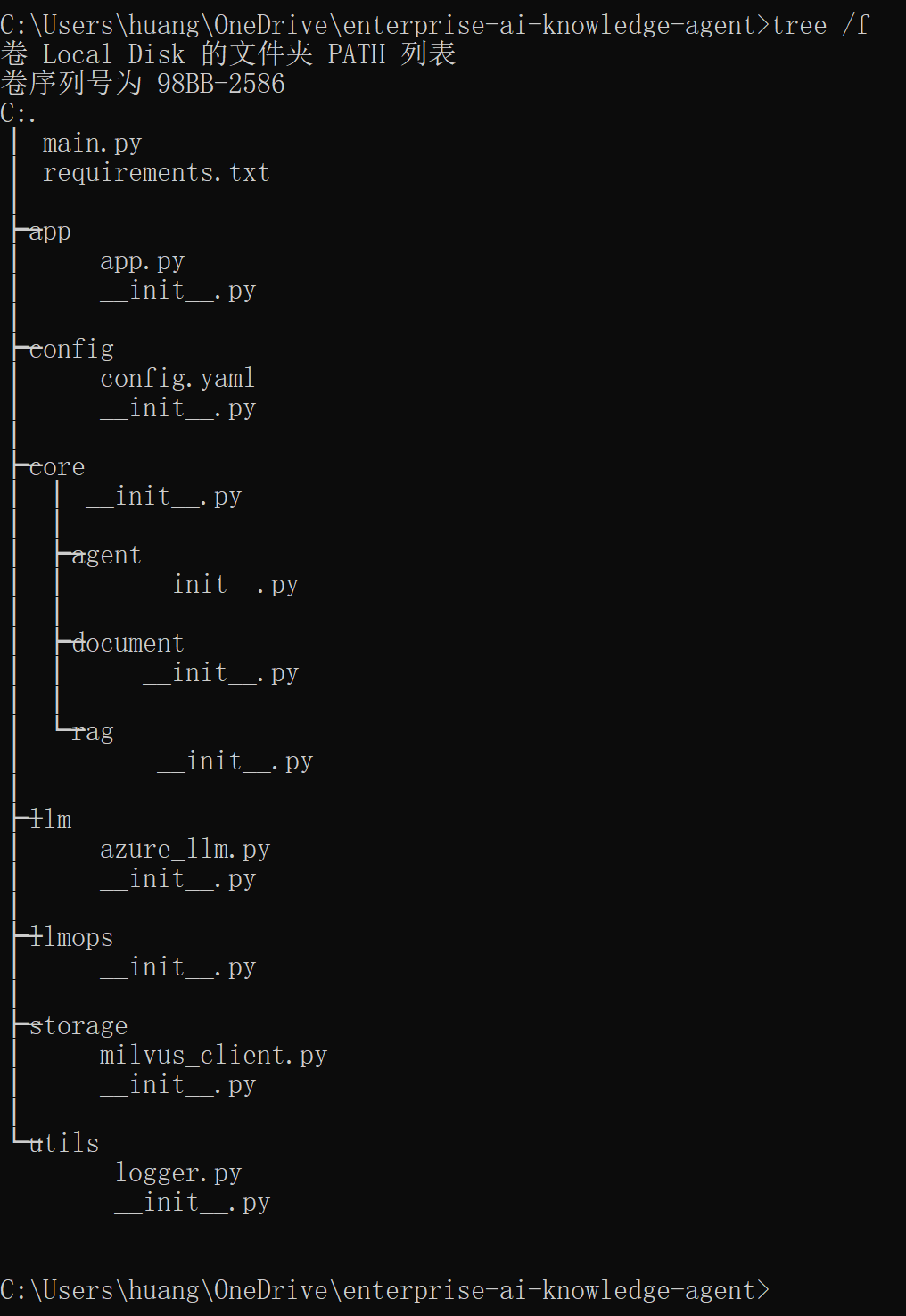
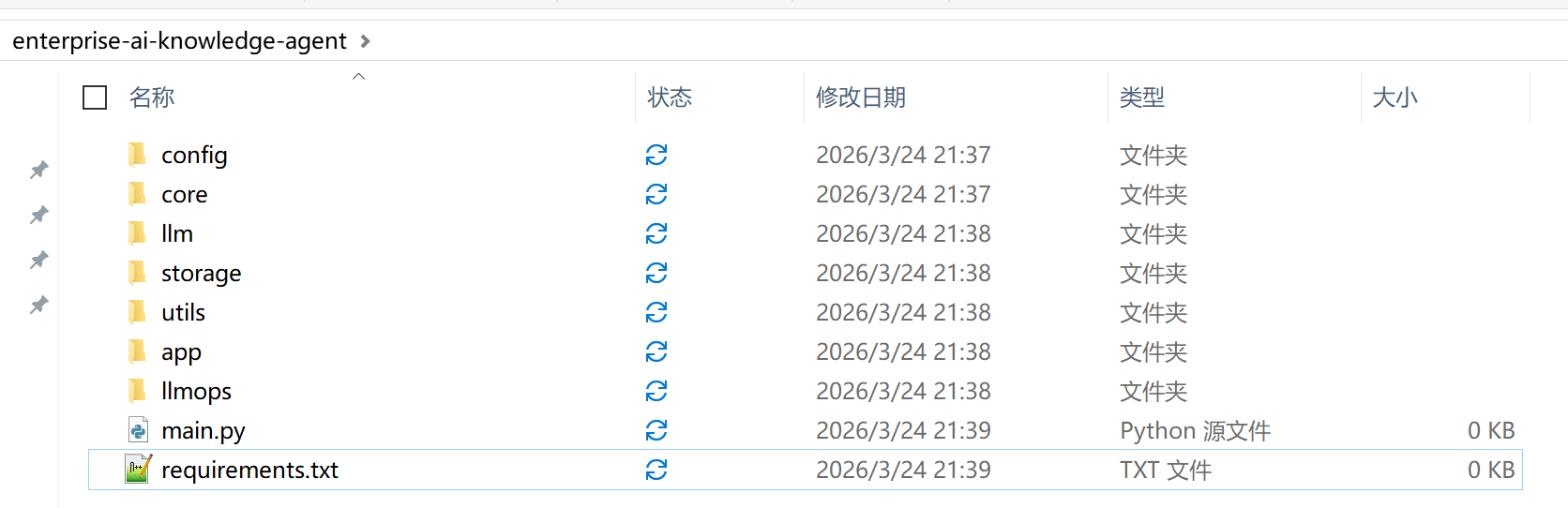
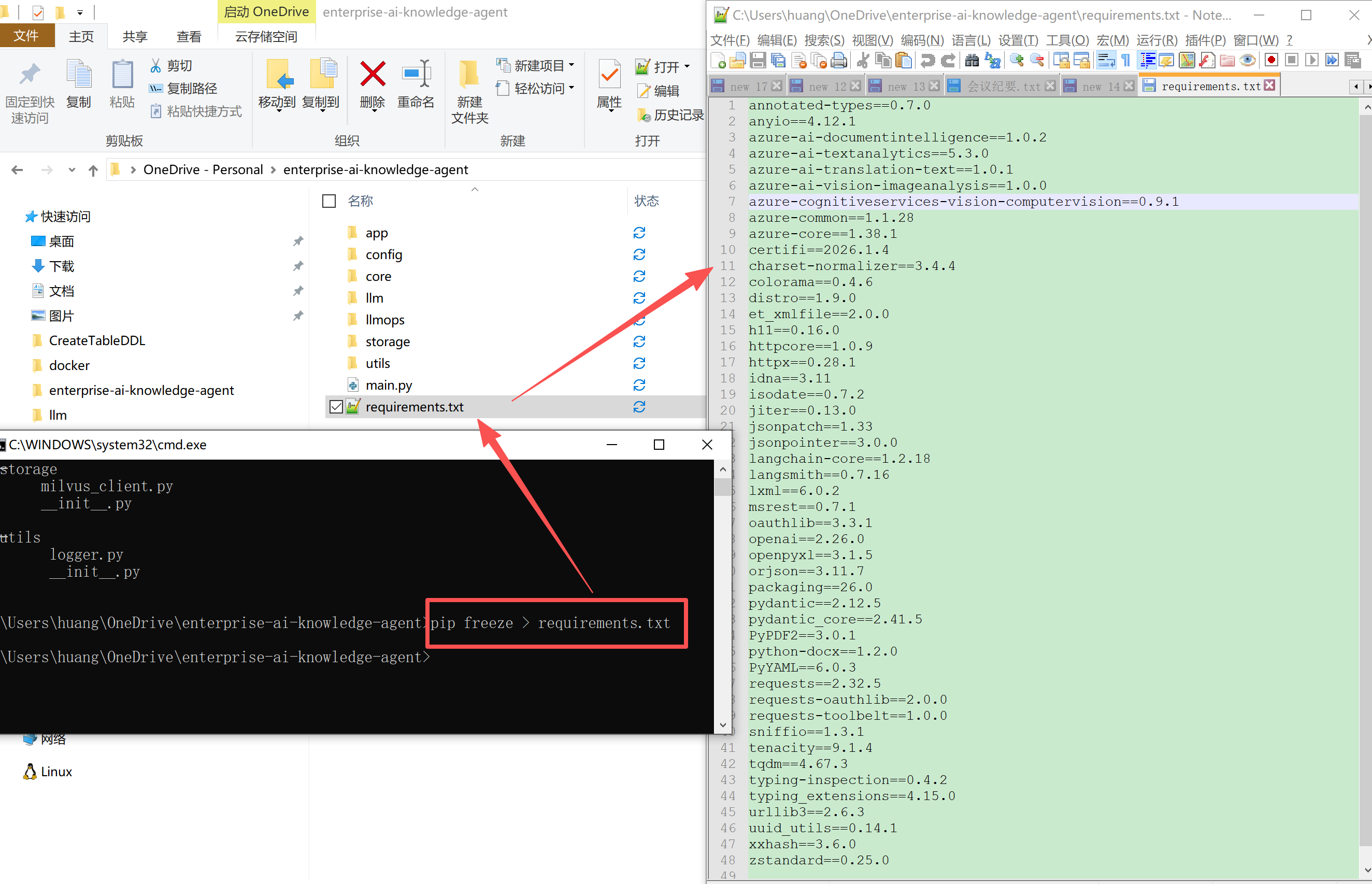
- 生成requirements.txt(后续部署、复用方便,用系统自带命令行执行):
打开命令行,进入项目根目录,执行命令:pip freeze > requirements.txt,生成依赖包清单,后续重新部署时可直接执行pip install -r requirements.txt安装所有依赖;命令行是系统自带工具,无需额外安装。
(二)配置文件整合
将Azure OpenAI、Milvus的配置集中管理,实现一键加载,避免后续代码中硬编码;配置文件用系统自带的记事本(Windows)、文本编辑(Mac)或免费工具(Notepad++)编写。
- 编辑config/config.yaml文件(复制以下内容,替换为你的实际配置):
# Azure OpenAI 配置(替换为你的实际信息;若暂无,可后续替换为开源免费LLM)
azure:
openai:
endpoint: "你的Azure OpenAI Endpoint" # 例:https://xxx.openai.azure.com/(若提示link dead,检查地址正确性)
api_key: "你的Azure API Key"
deployment_name_gpt4: "你的GPT-4部署名" # 例:gpt-4
deployment_name_embedding: "你的Embedding部署名" # 例:text-embedding-3-large
api_version: "2024-02-15-preview" # 固定版本,无需修改
# Milvus 配置(默认无需修改,若修改过Milvus端口,对应调整)
milvus:
host: "localhost"
port: 19530
collection_name: "enterprise_knowledge_base" # 向量库集合名,后续存储向量用
vector_dim: 1536 # 与Embedding模型维度一致(text-embedding-3-large为1536)
# 项目基础配置
project:
file_upload_path: "./uploads" # 上传文件存储路径
log_path: "./logs" # 日志存储路径
similarity_threshold: 0.7 # 检索相似度阈值(后续用)
- 配置文件加载封装(编写utils/init.py,实现一键加载配置,用免费代码编辑器编写):
import yaml
import os
def load_config(config_path: str = "./config/config.yaml") -> dict:
"""
加载配置文件
:param config_path: 配置文件路径
:return: 配置字典
"""
if not os.path.exists(config_path):
raise FileNotFoundError(f"配置文件不存在:{config_path}")
with open(config_path, "r", encoding="utf-8") as f:
config = yaml.safe_load(f)
return config
# 全局配置,后续其他模块可直接导入使用
CONFIG = load_config()
(三)核心工具封装(第一天简化实现,后续逐步优化)
封装Azure OpenAI调用、Milvus客户端、日志工具,避免重复编码,贴合“复用、模块化”思维;所有封装依赖均为开源免费。
- 日志工具(utils/logger.py):简化实现,方便后续调试、排查问题,用开源免费库loguru实现)
from loguru import logger
import os
from utils import CONFIG
# 创建日志目录
log_path = CONFIG["project"]["log_path"]
if not os.path.exists(log_path):
os.makedirs(log_path)
# 配置日志:输出到文件+控制台,按天分割
logger.add(
os.path.join(log_path, "app_{time:YYYY-MM-DD}.log"),
rotation="00:00", # 每天分割日志
retention="7 days", # 保留7天日志
compression="zip", # 压缩过期日志
encoding="utf-8"
)
# 简化日志调用,后续直接从utils导入logger即可
logger.info("日志工具初始化完成")
- Azure OpenAI调用封装(llm/azure_llm.py,复用你已学的调用逻辑;若暂无Azure,可替换为开源免费LLM)
from openai import AzureOpenAI
from utils import CONFIG
from utils.logger import logger
class AzureLLMClient:
def __init__(self):
"""初始化Azure OpenAI客户端;若暂无Azure,可替换为Llama 3等开源免费LLM"""
self.client = AzureOpenAI(
azure_endpoint=CONFIG["azure"]["openai"]["endpoint"],
api_key=CONFIG["azure"]["openai"]["api_key"],
api_version=CONFIG["azure"]["openai"]["api_version"]
)
self.gpt4_deployment = CONFIG["azure"]["openai"]["deployment_name_gpt4"]
self.embedding_deployment = CONFIG["azure"]["openai"]["deployment_name_embedding"]
logger.info("Azure OpenAI客户端初始化完成;若提示link dead,检查Endpoint地址和网络")
def get_embedding(self, text: str) -> list:
"""
获取文本的Embedding向量
:param text: 输入文本
:return: 向量列表
"""
try:
response = self.client.embeddings.create(
input=text,
model=self.embedding_deployment
)
return response.data[0].embedding
except Exception as e:
logger.error(f"获取Embedding失败:{str(e)};若Azure无法连接,可后续替换为开源免费Embedding模型")
raise e
def chat_completion(self, prompt: str) -> str:
"""
GPT-4对话生成
:param prompt: 提示词
:return: 生成的回答
"""
try:
response = self.client.chat.completions.create(
model=self.gpt4_deployment,
messages=[{"role": "user", "content": prompt}],
temperature=0.7 # 温度参数,后续可优化
)
return response.choices[0].message.content
except Exception as e:
logger.error(f"GPT-4调用失败:{str(e)};若Azure无法连接,可后续替换为Llama 3等开源免费LLM")
raise e
# 全局客户端,后续其他模块可直接导入使用
AZURE_LLM_CLIENT = AzureLLMClient()
- Milvus客户端封装(storage/milvus_client.py,第一天简化实现,能连接即可;Milvus开源免费)
from pymilvus import MilvusClient, CollectionSchema, FieldSchema, DataType
from utils import CONFIG
from utils.logger import logger
class MilvusStorage:
def __init__(self):
"""初始化Milvus客户端,创建集合(若不存在);Milvus开源免费,无需付费授权"""
self.client = MilvusClient(
uri=f"http://{CONFIG['milvus']['host']}:{CONFIG['milvus']['port']}"
)
self.collection_name = CONFIG["milvus"]["collection_name"]
self.vector_dim = CONFIG["milvus"]["vector_dim"]
# 检查集合是否存在,不存在则创建
self._create_collection_if_not_exist()
logger.info("Milvus客户端初始化完成;无需访问http://127.0.0.1:2379,容器正常运行即可")
def _create_collection_if_not_exist(self):
"""创建Milvus集合(若不存在)"""
if not self.client.has_collection(collection_name=self.collection_name):
# 定义集合字段:id(主键)、text(分块文本)、vector(向量)、doc_name(文档名称)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=self.vector_dim),
FieldSchema(name="doc_name", dtype=DataType.VARCHAR, max_length=255)
]
schema = CollectionSchema(fields=fields, description="企业级AI知识库向量集合")
self.client.create_collection(collection_name=self.collection_name, schema=schema)
logger.info(f"Milvus集合 {self.collection_name} 创建完成")
else:
logger.info(f"Milvus集合 {self.collection_name} 已存在")
# 全局客户端,后续其他模块可直接导入使用
MILVUS_CLIENT = MilvusStorage()
(四)项目入口实现(main.py,第一天核心验证,运行即完成初始化)
from utils.logger import logger
from llm.azure_llm import AZURE_LLM_CLIENT
from storage.milvus_client import MILVUS_CLIENT
from utils import CONFIG
def main():
"""项目入口,验证环境是否正常;用系统自带命令行运行"""
logger.info("="*50)
logger.info("企业级AI知识库Agent平台 - 第一天环境验证")
logger.info("="*50)
# 1. 验证配置加载
logger.info("1. 验证配置加载...")
try:
logger.info(f"Azure Endpoint:{CONFIG['azure']['openai']['endpoint'][:20]}...(若提示link dead,检查地址和网络)")
logger.info(f"Milvus 地址:{CONFIG['milvus']['host']}:{CONFIG['milvus']['port']}(无需访问http://127.0.0.1:2379)")
logger.info("配置加载成功")
except Exception as e:
logger.error(f"配置加载失败 ❌:{str(e)}")
return
# 2. 验证Azure OpenAI调用(若暂无Azure,可跳过,后续替换为开源免费LLM)
logger.info("\n2. 验证Azure OpenAI调用...")
try:
# 测试Embedding调用
test_text = "AI架构师必备技能"
embedding = AZURE_LLM_CLIENT.get_embedding(test_text)
logger.info(f"Embedding生成成功,向量维度:{len(embedding)}")
# 测试GPT-4调用
test_prompt = "简要介绍AI知识库Agent平台的核心功能"
response = AZURE_LLM_CLIENT.chat_completion(test_prompt)
logger.info(f"GPT-4调用成功,回答:{response[:50]}...")
logger.info("Azure OpenAI调用成功 ✅")
except Exception as e:
logger.error(f"Azure OpenAI调用失败 ❌:{str(e)};可后续替换为Llama 3等开源免费LLM")
return
# 3. 验证Milvus连接
try:
logger.info("3. 验证Milvus连接...")
MILVUS_CLIENT.client.list_collections()
logger.info("Milvus连接成功 :服务正常运行")
except Exception as e:
logger.error(f"Milvus连接失败 ❌:{str(e)}")
return
logger.info("\n" + "="*50)
logger.info("第一天环境验证全部通过!项目初始化完成 ")
logger.info("后续将逐步实现文档处理、RAG等核心模块")
if __name__ == "__main__":
main()
整体调用: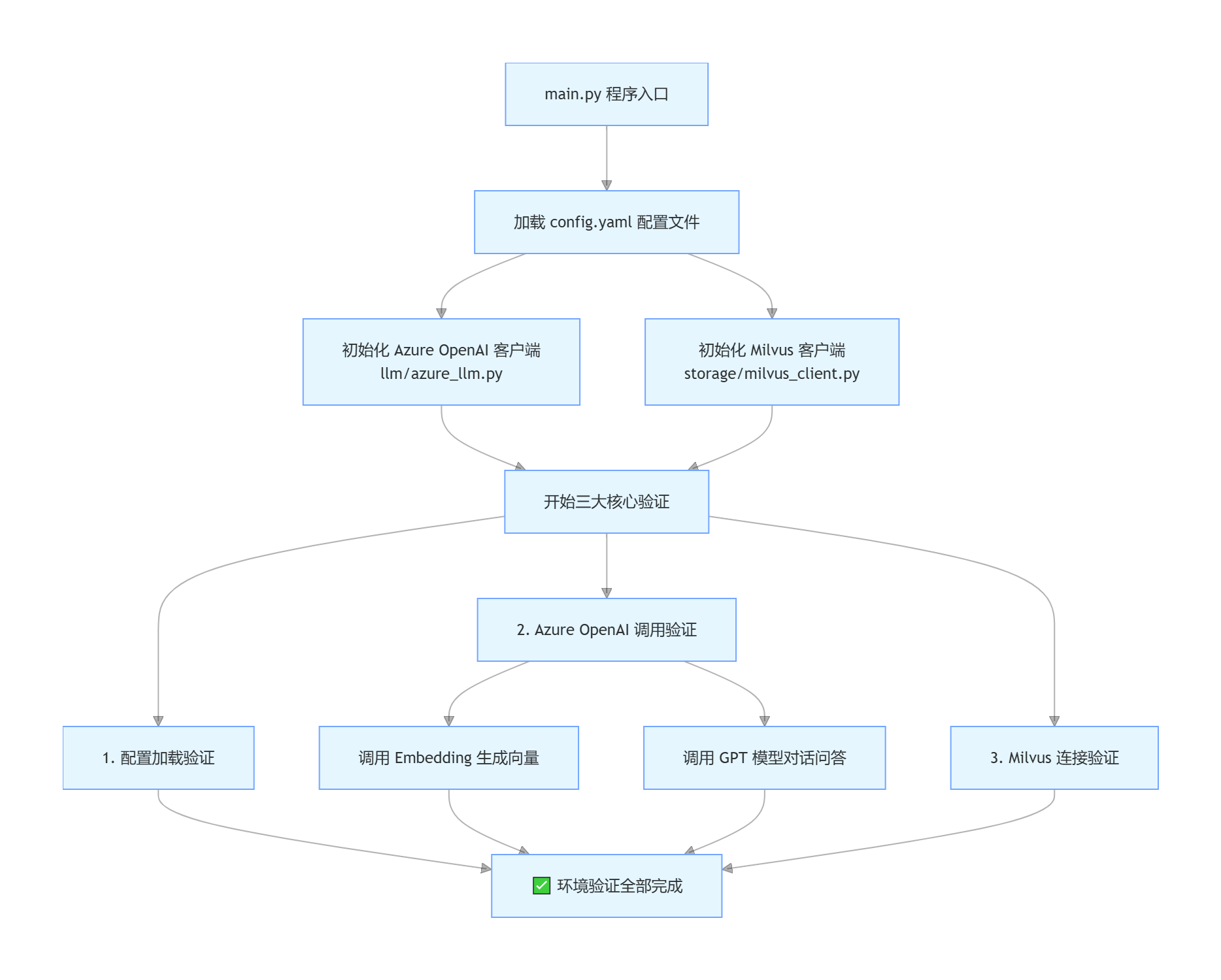
(五)环境验证(第一天收尾,确保所有功能正常,用免费工具辅助)
- 运行main.py:打开系统自带命令行,进入项目根目录,执行命令:python main.py;。
- 验证结果:若控制台输出“第一天环境验证全部通过!项目初始化完成”,且无报错,说明第一天实操全部完成。
- 常见问题排查(结合用户提供的报错信息,补充免费解决方案):
- 若提示“找不到模块”:检查目录结构是否正确,确保每个文件夹都有__init__.py文件,运行时确保当前目录是项目根目录;用系统自带文件管理器检查目录,免费工具(Notepad++)查看文件内容。
- 若Azure调用失败/提示“link dead”:检查config.yaml中的Azure Endpoint是否正确,确认API Key未过期,网络能访问Azure服务;若暂无Azure,可后续替换为开源免费LLM(如Llama 3),无需付费。
- 若Milvus调用失败/访问http://127.0.0.1:2379 提示“invalid link”:检查Milvus容器是否正常运行(docker ps查看),确保host和port与配置一致;该地址为Milvus内部依赖地址,无需手动访问,容器正常即可。
- 若pip安装依赖提示“link fetch error”:更换免费镜像源(如阿里云、豆瓣镜像源),执行命令:pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/。
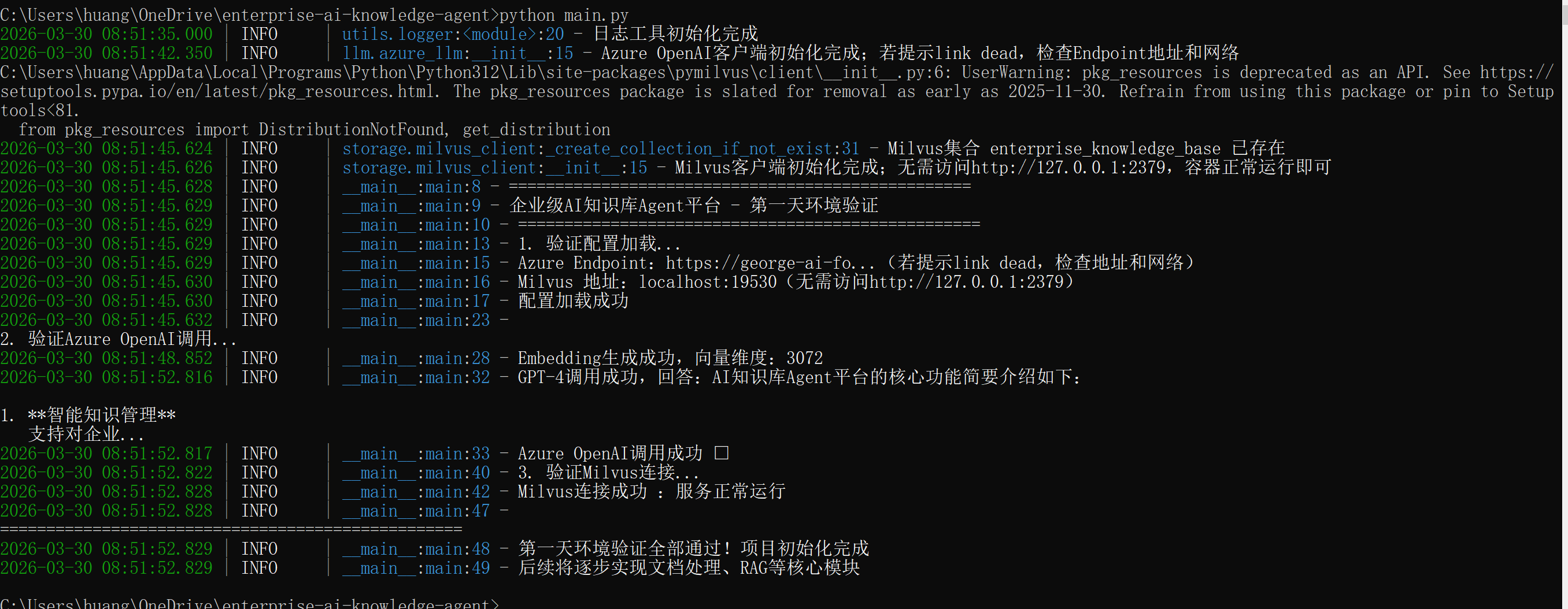
- 配置加载成功:Endpoint、Milvus 地址都正确加载
- Azure OpenAI 调用成功:Embedding 生成成功(维度 3072,和 text-embedding-3-large 完全匹配),GPT-4 调用成功,返回了完整回答。
- Milvus 连接成功:服务正常运行,集合已存在
验证已经覆盖了所有核心依赖:
- Python 环境与依赖:pymilvus、openai 等库正常导入
- 配置文件:yaml 解析无误,敏感信息正确
- Azure OpenAI 服务:Embedding + Chat 双接口可用
- Milvus 向量数据库:容器运行正常,客户端连接成功
小结
第一天核心是「项目初始化」,重点不在于实现复杂功能,而在于搭建规范的架构、完成环境验证,同时培养架构思维;
- 掌握企业级AI项目的需求拆解方法:能区分功能需求与非功能需求,结合自身技术储备拆解需求,避免冗余开发,可借助系统自带工具、免费工具整理需求。
- 理解模块化架构设计思路:将项目拆分为核心层、基础层、存储层等,每个模块独立封装,实现“高内聚、低耦合”,能用工具(如DrawIO)绘制架构图,为后续扩展打下基础。
- 完成开发环境全流程搭建:熟练安装Milvus向量库(Docker方式),整合Azure OpenAI配置(可替换为开源免费LLM),解决常见环境报错(如invalid link、link fetch error),具备环境部署能力,且全程无额外成本。
- 掌握配置文件集中管理、工具类封装的技巧:避免硬编码,提升代码复用性和可维护性,贴合架构师编码规范;用免费工具编写配置文件、代码,降低实操成本。
- 实现环境验证闭环:能通过代码验证各模块是否正常工作,培养故障排查思维;借助系统自带命令行排查问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)