给OpenClaw装上「长期记忆」:Mind Lab发布MindClaw,用LoRA RL让AI Agent真正记住你
OpenClaw让Agent火了一把,但它有个致命问题:记不住你。Mind Lab的MindClaw想解决这件事。
OpenClaw的出现,让更多人开始把AI理解为一个能行动、能积累、能进化的系统,而不只是一个一次性的问答引擎。
但用过一段时间后,很多人发现了一个问题:它的「成长」其实是假的。
技能越攒越多,Prompt越来越长,检索越来越复杂——但Agent并没有真正变得更稳定。它只是在越来越依赖「在正确的时刻找到正确的文本」。
刚刚,Mind Lab发布了最新研究博客MindClaw,并开放了Preview体验。MindClaw的目标很明确:用LoRA RL把OpenClaw的「外挂记忆」变成「参数化记忆」,让Agent真正记住你。
Prompt空间的成长,迟早会撞墙
OpenClaw目前的成长主要发生在Prompt空间:技能被生成后存储在上下文中,记忆通过检索被塞回上下文。
在冷启动阶段,这套方案效果出奇地好。系统感觉很自适应、很个性化,甚至比底座模型本身的表现还要强。
但一个主要通过在Prompt空间积累更多技能和记忆来成长的系统,同时也在积累更多噪声。
Mind Lab指出了两个反复出现的失败模式:
第一个是技能漂移。 系统收集了大量实际上不起作用的技能。有些方向正确但操作模糊,有些冗余,有些从未被触发,有些仅仅因为是更强的模型生成的所以「看起来」合理。
第二个是检索依赖。 模型并不真正「拥有」这些技能。它能否在正确的时刻找到正确的技能,取决于检索质量、Prompt布局、上下文预算和模型的瞬时状态。
这不是参数化记忆,这是靠重新塞入来维持的记忆。
Mind Lab在此前关于Context Learning的研究中就提出过同样的关切:上下文可以改善当前轨迹,但如果这些增益从未被内化到参数中,它们就不会变成持久的能力。它们始终是外部支撑,而承载它们的负担只会越来越重。
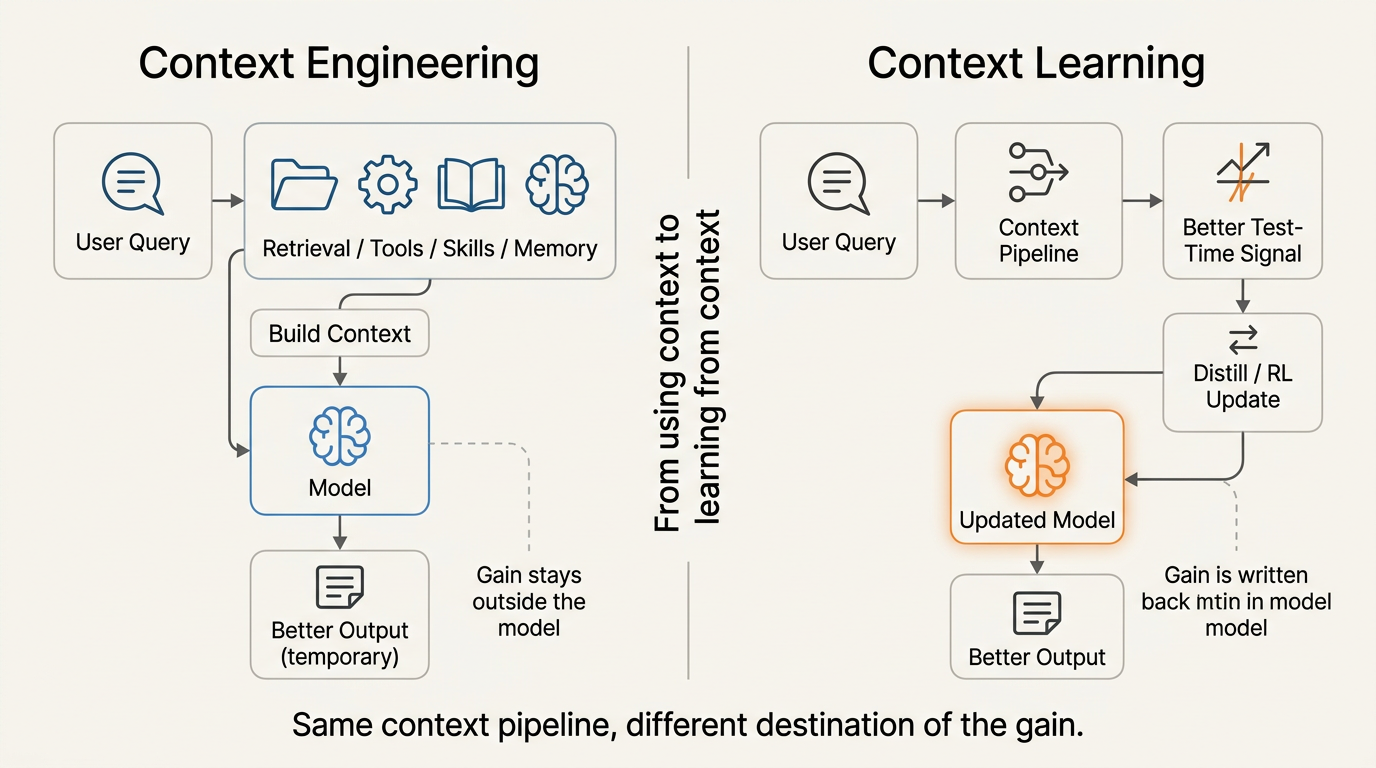
个人Agent终究需要参数化记忆
Mind Lab的核心论点很直接:一个真正的个人Agent,最终需要参数化记忆。
如果一个Agent真的适配了你的工作方式,它不应该在每一条重要轨迹上都从零开始重建你的偏好、工作流和决策习惯。检索仍然重要,但检索应该是补充性的,不应该承担长期个性化的全部重量。
Mind Lab用一句话区分了两种路径:
Context Engineering帮助模型在「这一轮」做得更好。
Context Learning帮助模型在「未来每一轮」变得更好。
前者改善局部表现,后者创造积累。
MindClaw:两层架构,一个目标
MindClaw是Mind Lab对这个方向的当前实现。目标很直接:让OpenClaw风格的经验积累,不再只是一个不断膨胀的上下文窗口。
MindClaw由两层组成:
Agent层:MetaClaw
MetaClaw为已部署的Agent提供了一个实用的学习循环:在线对话收集、技能注入、失败后技能进化、RL样本收集。它是连接日常使用和结构化学习循环的Agent层。
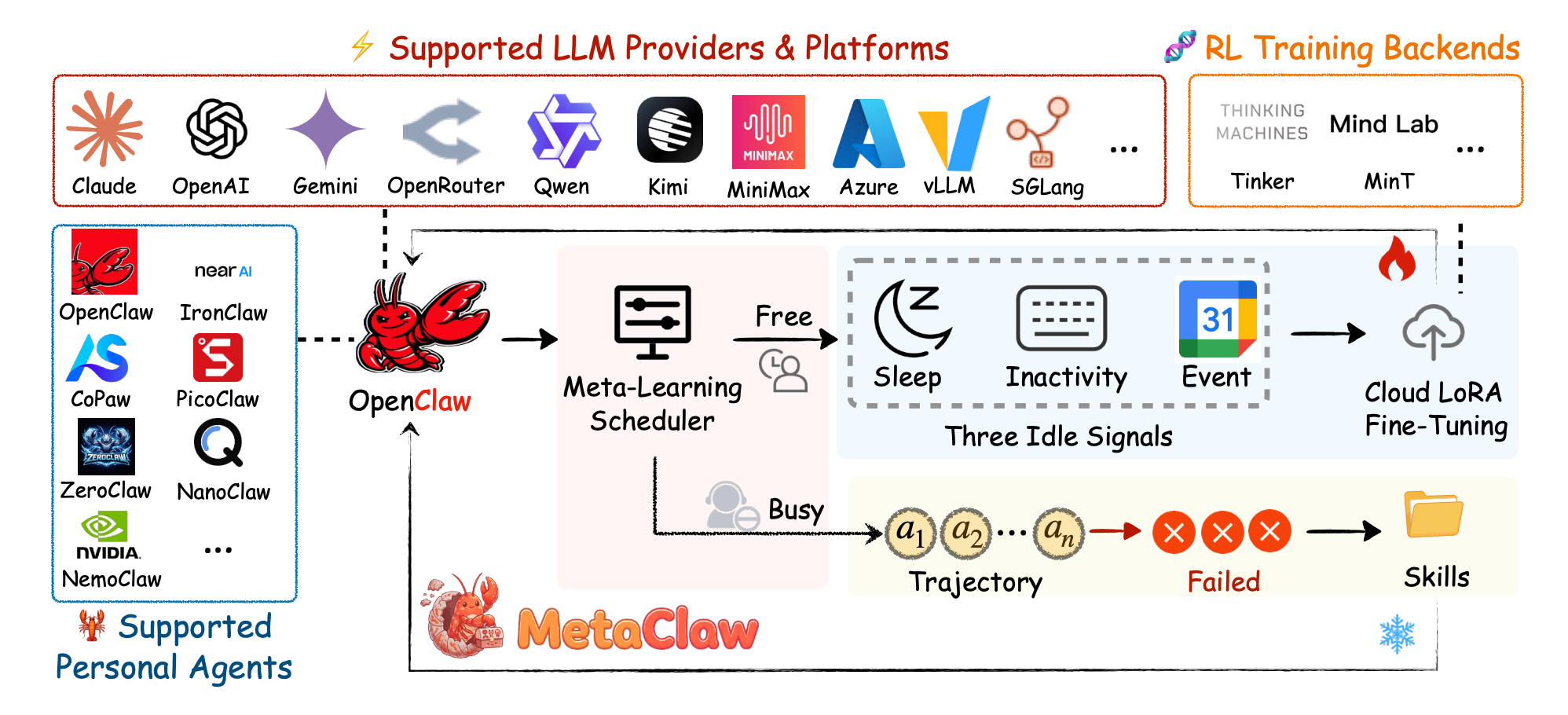
基础设施层:MinT
当目标从「把更多技能塞进上下文」转变为「把技能内化进参数」,瓶颈就不再只是Agent框架了——它变成了基础设施问题。
你需要一个系统,能把实时经验转化为稳定的LoRA RL更新。你需要管理训练状态、连接rollout和优化、从故障中恢复、并在真实产品约束下保持循环可用。
这正是MinT被构建来解决的问题。
Mind Lab在介绍MinT时的核心论点是:很多团队已经拥有最有价值的资产——真实经验。 他们有产品轨迹、领域工作流、反复出现的用户行为和只在实践中才会暴露的失败模式。他们往往缺少的,是一种把这些经验转化为稳定模型改进的实际方法。
没有这种基础设施,经验只是一条日志,不会变成智能。
Mind Lab真正想弥合的差距
Mind Lab关心的差距很简单:
系统可以不断生成更多技能,但模型可能仍然没有学会如何可靠地使用它们。
如果这个差距持续存在,系统就会滑向一种「伪进化」:技能库越来越大,Prompt越来越长,检索越来越复杂。但Agent并没有变得相应地更稳定——它只是变得更依赖在正确的时刻找到正确的外部文本。
这就是为什么Mind Lab不太关心「生产更多技能」,而更关心提高有用技能被实际学习、实际触发、逐步内化的概率。
结合元学习的视角,画面变得更清晰:
快时间尺度上:系统可以继续生成和优化技能
慢时间尺度上:高价值技能应该通过LoRA RL被写入参数
对用户来说,区别是具体的。如果技能只存在于上下文中,体验往往是:系统「有时候」记得用它们。如果有用的技能逐渐被写入参数,体验就不同了:系统变得更一致、更个性化,不再需要一遍又一遍地从Prompt空间重建同样的能力。
为什么是LoRA RL?
原因很实际:经济性。
如果长期记忆需要全参数训练——这条路不会变成产品。
如果长期记忆只依赖检索和上下文填充——内部噪声只会不断增长。
LoRA RL提供了中间路径:更低的训练成本、更快的更新速度、可行的持续改进循环,而结果住在参数里,不只是外部文本中。
Mind Lab认为,LoRA RL不仅仅是一种更便宜的后训练方法。它改变了长期个性化的可行性边界。 只有当参数更新在操作上变得足够轻量,Personal OpenClaw才不再只是一个一次性配置的把戏。
从这个角度看,MindClaw的重点不是添加更多技能,而是让高价值技能变成参数化记忆。
完整的拼图
Mind Lab在博客中给出了MindClaw的完整架构逻辑:
| 组件 | 角色 | 解决什么问题 |
| MetaClaw | Agent层学习循环 | 连接日常使用与结构化经验收集 |
| MinT | RL基础设施 | 让参数级适配在实际产品中可持续运行 |
| LoRA RL | 桥梁 | 把反复出现的经验转化为持久能力 |
Mind Lab的观点是:一个个人Agent不能永远停留在上下文层。它必须逐步获得参数化记忆,更稳定地适配你的工作,并以一种能够随时间复利积累的形式积累经验。
Mind Lab是谁?
Mind Lab是一家由95后青年科学家组成的AI研究团队,致力于构建体验智能(Experiential Intelligence)——能从真实经验中持续学习的AI系统。
此前,Mind Lab已发布后训练平台MinT、完成业界首个1T LoRA-RL、修复了MoE强化学习中的Router Replay R3关键Bug,并提出了从Context Engineering到Context Learning的范式转变。MindClaw是这一系列研究的最新落地。
本文核心贡献者:Lucian Li、Qihan Liu、Song Cao、Ruijian Ye、Andrew Chen、Pony Ma。
写在最后
OpenClaw证明了Agent可以积累经验。MindClaw要回答的下一个问题是:积累的经验能不能真正变成模型的一部分?
这不只是技术问题,更是产品问题。当你的AI助手真的记住了你——不是靠每次重新检索,而是靠参数里写着你的偏好——那才是个人Agent真正成立的时刻。
MindClaw的Preview已经开放体验,感兴趣的可以直接试用。
博客原文:https://macaron.im/mindlab/research/mindclaw-fine-tuning-openclaw-for-personalized-long-term-memory
参考链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)