ChatGPT等大语言模型的训练过程:从Pre-train到RLHF的深度解析
通过前面的文章介绍,大家可能已经知道大语言模型的训练过程包括3个阶段,分别是Pre-train、SFT和RLHF。
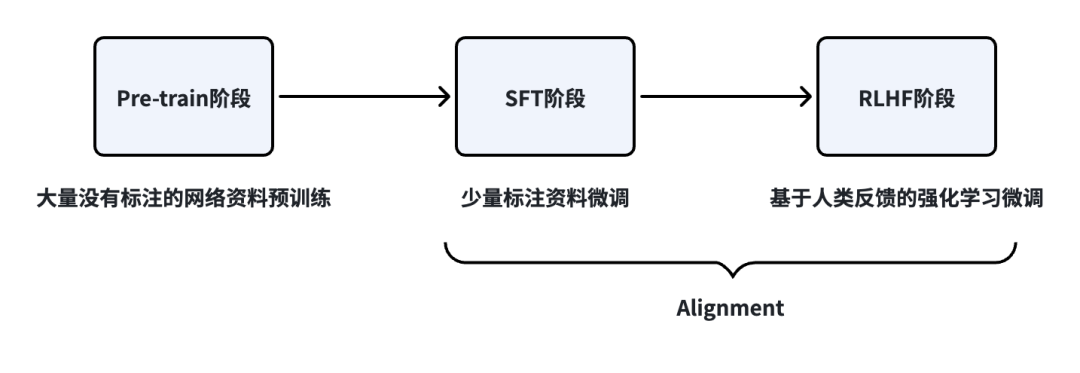
- Pre-train阶段:即预训练,是相对Post-Training而言的;
- SFT阶段:即Supervised Fine-Tuning,监督微调;
- RLHF阶段:即Reinforcement Learning with human Feedback,是基于人类反馈的强化学习。
其中,Pre-train是大语言模型训练的起点,让模型获得了语言能力和知识,接下来的SFT和RLHF阶段统称为Alignment(对齐),用于调整大语言模型的行为,使其输出更加符合人类的需求和偏好。
具体来说,在Pre-train阶段,模型在海量未经人工标注的文本数据上,基于自监督学习Self-Supervised Learning的方式通过任务Next-Token Prediction学习语言的统计规律,并在这一过程中获得对语言结构、语义关系以及大量事实知识的表示能力;第二阶段SFT基于少量人类标注的资料进行微调,人类标注者为各种问题提供高质量的参考回答,使模型学会按照人类期望的方式进行回复;最后第三阶段RLHF基于人类的反馈进行强化学习微调,使其更倾向于生成符合人类偏好的回答。
整个训练过程可以类比于我们学习知识的过程:
- Pre-train阶段就像是我们的自学阶段,我们通过阅读大量的书籍和资料逐渐掌握知识规律;
- SFT阶段就像是在学校上课,老师会提供教学和解题思路,教我们遇到各类题目时应该如何回答;
- RLHF则类似课后练习和参加考试,通过实践检验并不断扩展自身的能力。
因为大语言模型训练的本质就是教模型如何进行『文字接龙』,所以虽然整个训练过程包括三个阶段,但是它们的核心目的都是让大语言模型可以正确的做『文字接龙』。在整个训练过程中,模型的结构是不变的,底层都是基于Decoder-Only的Transformer架构,但是各个阶段所使用的训练数据和训练方法却大不相同。就拿训练方法来说,在Pre-train阶段,整个训练过程实现就是我们在第一篇文章[机器学习/深度学习基本概念简介]中介绍的机器学习三部曲,但是在第二阶段SFT和第三阶段RLHF其模型的结构已经确定,所以训练的第一步不是要寻找一个『函数』,而是需要确定模型要微调的参数(层)并冻结其他参数(层),其训练过程如下:
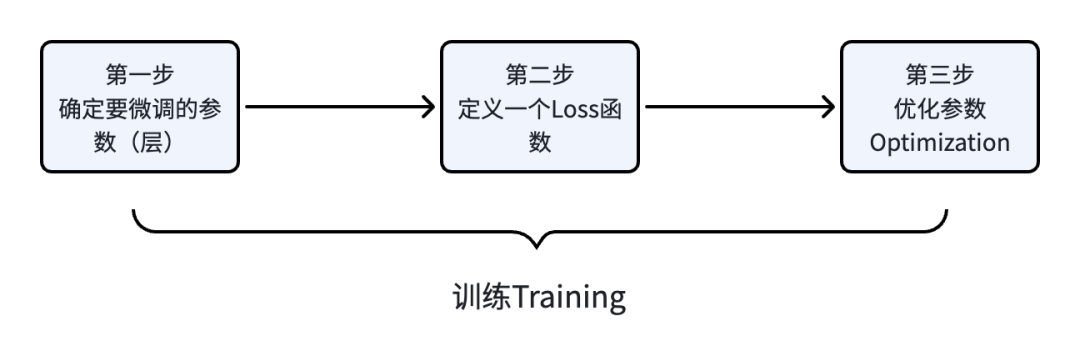
通常我们将Pre-train训练的模型叫做Base Model(基础模型),基于Base Model之上进行SFT微调,微调后的模型叫做SFT Model(SFT模型),一般的RLHF会基于SFT Model之上再进行强化学习训练。
下面我们就对这三个阶段依次进行详细介绍。
一、Pre-train Stage
数据预处理阶段
在第二篇文章[生成式人工智能的基本原理])中已经提到,要让模型能够做『文字接龙』至少需要两方面的知识:语言知识和世界知识;
- 语言知识:通过学习语言知识,大语言模型可以掌握人类语言的文法;
- 世界知识:本质上就是要让大模型理解物理世界。
那我们如何获得用于大语言模型训练的数据呢?这就依赖于前置的数据预处理阶段。
数据预处理阶段的目标是:从互联网获取大量公开可访问的文本数据,然后经历多个步骤对这些文本数据进行处理以得到数量巨大、质量较高、内容多样性很强的大语言模型预训练数据集。
要构造这样的训练集,通常有两种选择:
- 自行爬取,像OpenAI或Anthropic(以及其他公司)基本都是自建大规模数据集;
- 使用公共的已爬取网页仓库,例如CommonCrawl维护的网页库;
如果你想要深入了解数据预处理这个过程,可以参考Hugging Face发布的训练集FineWeb Recipe。
FineWeb是HuggingFace公开的一套用于大语言模型LLM预训练的高质量文本训练集,使用CommonCrawl作为起点,并对原始网页文本数据进行多个步骤的清洗和过滤,包括:URL过滤、文本提取、语言过滤、数据去重等阶段,整个数据预处理过程如下图所示:
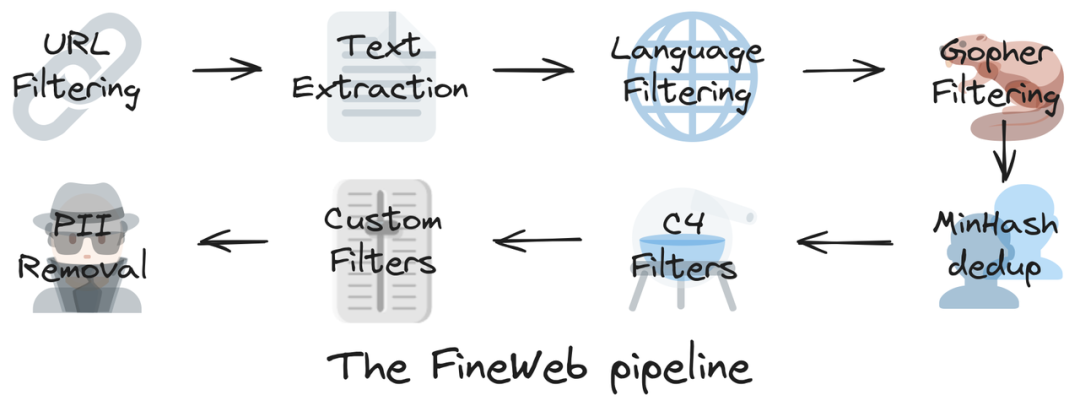
目前FineWeb是能够实现大语言模型最高性能的开放数据集,大家如果对其感兴趣可以看下以下Blog:https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
那大语言模型预训练到底需要多少数据呢?
以FineWeb数据集为例,最终的数据规模是44TB,从占用磁盘空间来看可能没有想象中那么大,但是却包含了大约15T的高质量文本Token。那15T Token是什么概念?我们以一个形象的比喻来告诉你。
假设一张A4纸正常可以排版300~500个单词,对应就是大约500个Token,如果一张A4纸的厚度大约是0.1毫米,那么将15T Token打印出来,其厚度大概是3000公里,如果一个人1秒可以读一页,那么大概需要1000年才能读完这些资料。
接下来看下主流开源大语言模型在Pre-train阶段到底需要多少训练数据集?
- The Llama 3 Herd of Models

- DeepSeek-V3 Technical Report

上面两张图截取自Llama3和DeepSeek V3的论文,从图中可以看到Llama3的预训练使用了15T规模的多语言Token,同样DeepSeek V3也使用了14.8T多样化的高质量Token,所以现在大家知道了如果要Pre-train一个大语言模型大概需要15T的Token。但是训练数据是不是越多越好呢?
在回答这个问题之前,我们需要先了解下Scaling Law。那具体什么是Scaling Law呢?
在人工智能领域,Scaling Law是指在大语言模型LLM的训练过程中,模型性能(以Loss衡量)与算力(Compute)、参数量(Parameters)和数据量(Tokens)三者之间存在的一种确定的、可预测的数学关系。
简而言之,它揭示了『大力出奇迹』背后的科学规律,只要按比例增加这三个要素,模型的性能就会稳步提升,可以将Scaling Law理解为人工智能领域的摩尔定律。
Scaling Law最早是由OpenAI在2020年发表的论文 Scaling Laws for Neural Language Models 中提出,指出Loss与大语言模型的规模之间呈现幂律(Power Law)关系:
- 非饱和性:只要在对数坐标轴上观察,随着规模增加,Loss的下降几乎是直线的,且目前尚未看到性能提升的上限;
- 独立性:如果算力、参数或数据中某一个因素遇到瓶颈,单纯增加其他因素对性能的提升会迅速边际递减。
从上述观点可以看到,在2020年初(LLM发展早期)由于当时认为可训练的算力和数据是足够的,参数量相比算力和数据量更重要,所以业界的尝试方向是不断扩大模型参数以训练一个更大的语言模型。
随后在2022年,DeepMind发表的论文 Training Compute-Optimal Large Language Models 对Scaling Law做了进一步的完善。在论文中指出在给定算力的情况下,当前大部分大语言模型的训练明显存在问题:在训练数据量不变的情况下,如果重点继续放在参数规模上意义不大,对于计算最优的训练,模型规模和训练数据量应同比例的增加,即模型规模每增加一倍,训练数据量也应增加一倍。
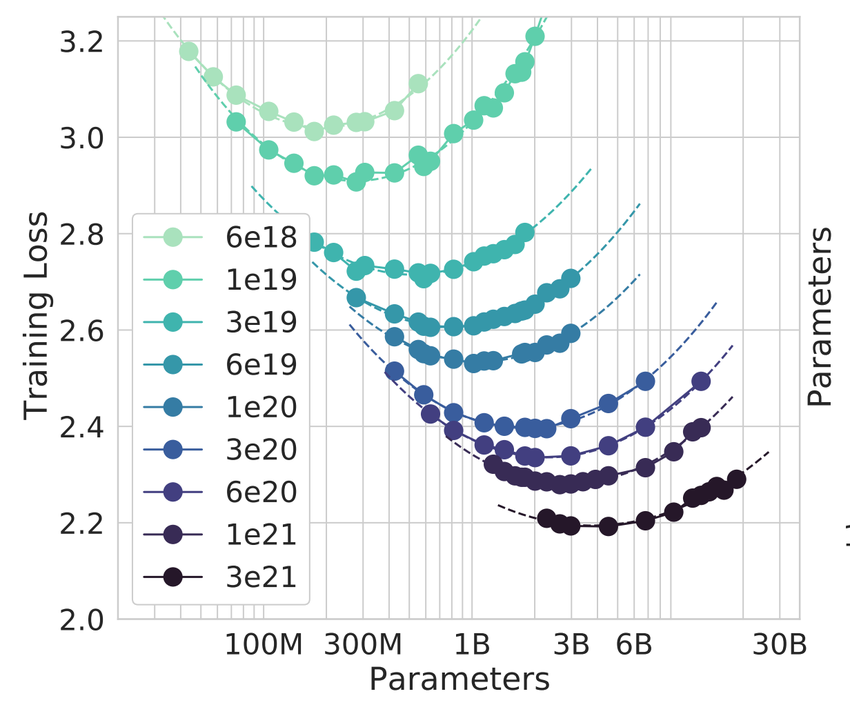
For various model sizes, we choose the number of training tokens such that the final FLOPs is an constant. The cosine cycle length is set to match the target FLOP count. We find a clear valley in loss, meaning that for a given FLOP budget there is an optimal model to train.
对于不同规模的模型,我们选择相应的训练Token数量,使得最终的FLOPs(浮点运算次数)保持为一个常数。余弦学习率调度(cosine)的周期长度也被设置为与目标FLOPs数量相匹配。我们在损失(loss)曲线上观察到一个明显的“谷底”,这意味着在给定的 FLOPs 预算下,存在一个最优的模型规模。
Scaling Law的意义在于:AI研究可以『工程化的预测模型的能力』。
- 性能预测:通过在小规模模型上进行实验,可以精准预测训练一个大语言模型最终能达到多低的Loss,从而避免浪费昂贵的算力;
- 资源预测:在有限的算力下,应该选择训练一个『大而糙』的模型,还是一个『小而精』的模型。
目前对于基于Transformer架构的大语言模型,一个公认的经验法则是:每个Token在训练时所需要的算力大约是模型参数量的6倍,计算公式如下:
其中,C(Compute)是训练所需的算力(单位:FLOPs),N(Parameters)是模型的参数量,D(Data)是训练数据的Token数。
在了解了Scaling Law之后,我们再回答上面的问题『大语言模型训练时是不是数据量越大越好呢?』
答案是需要综合考虑算力、数据和模型参数三个方面的因素:一个参数比较大的模型,通常需要大量的数据,也需要消耗大量的算力;但是在实践中,往往算力是有限的,那么在固定算力的情况下,为了得到一个性能更好的模型往往需要在特定大小的模型上基于特定大小的数据进行预训练。
近两年,我们也会听到关于Scaling Law正在失效的讨论,主要有以下几个因素:
数据瓶颈出现:在论文 Will we run out of data? Limits of LLM scaling based on human-generated data 中提出,预计2028年前后我们会用尽网络上的所有公开数据,意味着用于训练大模型的文本数据是有限的,数据瓶颈导致了继续扩大参数规模变得无意义,这个现象也被称作数据墙(Data Wall)。
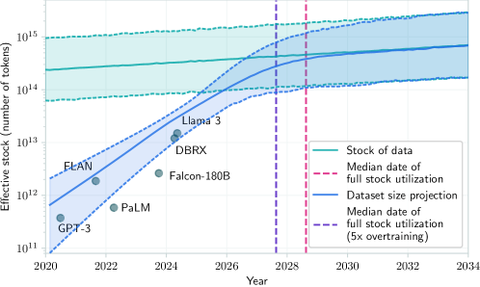
边际效用递减:增加算力、参数带来的Loss下降在对数坐标轴上开始放缓,企业需要评估这样的投入产出比是否值得。
Tokenization和Training阶段
具体到Pre-train的详细过程在第四篇[从零动手实现GPT]中已经详细介绍过,这里就不在赘述了,大家可以跳转进行阅读。
这里再补充几个可视化网站,帮助大家对这部分内容进行更好的理解:
Tokenizer可视化:
https://tiktokenizer.vercel.app/
LLM可视化:
https://bbycroft.net/llm
The “psychology(心理学)” of a base model
最后的部分引用Karpathy大神的『The “psychology” of a base model』,从心理学的角度来看下Base Model到底是什么?
-
It is a token-level internet document simulator;
-
It “dreams” internet documents,can also recite some training documents verbatim from memory (“regurgitation”),The parameters of the model are kind of like a lossy zip file of the internet;
=> a lot of useful world knowledge is stored in the parameters of the network
-
It is stochastic / probabilistic - you’re going to get something else each time you run;
-
You can already use it for applications (e.g. translation) by being clever with your prompts;
-
e.g. English:Chinese translator app by constructing a “few-shot” prompt and leveraging “in-context learning” ability;
-
e.g. an Assistant that answers questions using a prompt that looks like a conversation;
-
But we can do better…
让我们一条一条来看:
It is a token-level internet document simulator;
Base Model本质上是一个Token模拟器,它的能力就是模拟互联网文本中的Token统计分布。换句话说,它可以生成类似互联网文本的内容,但是它本身还不是一个『Assistant』。
It “dreams” internet documents,can also recite some training documents verbatim from memory (“regurgitation”),The parameters of the model are kind of like a lossy zip file of the internet;
Base Model可以看作是互联网的压缩,但是是『有损』压缩,模型参数是对互联网内容的一种『压缩表示』,模型只记住了文本的统计规律,而不是完整信息。
It is stochastic / probabilistic - you’re going to get something else each time you run;
同样的输入,每次输出可能不同,模型预测的是下一个Token的概率分布,并从分布中采样来确定下一个Token;
You can already use it for applications (e.g. translation) by being clever with your prompts;
但是通过巧妙的Prompt设计,Base Model仍然可以用来执行任务。
事实也确实如此,在ChatGPT之前的2020年OpenAI就发布了GPT-3,模型最大参数为175B,但是该Base Model还是没有办法很好的回答问题,只能预测出一些看似延续问题的答案。正如Karpathy最后提到的,But we can do better,接下来就进入SFT和RLHF的阶段,来看下Base Model这块璞玉,是如何被精雕细琢后爆发出强大的力量的?
二、SFT Stage
通过上面对Pre-train阶段的介绍,我们知道Base Model本身并不是一个『Assistant』,它并不能按照我们期望的方式正确的回答问题,那怎么办?这个时候就需要对Base Model进行Post-training,那如何实现Post-training呢?
一种方法就是基于人类标注的对话数据来对Base Model进行监督微调,标注示例如下所示:

这个方法最早是在2022年OpenAI发布的论文InstructGPT:Training language models to follow instructions with human feedback 中提出,该方法就是Supervised Fine-Tuning(SFT),又叫做Instruct Fine-Tuning。
一般的,SFT后的Model在命名上会加上Instruct或者Chat的字样,比如Llama 3.1 405B Instruct。
这里需要明确下,真正人工标注的用于SFT的训练语料是需要符合大语言模型的Conversation Protocol/Format,也就是我们在第二篇生成式人工智能的基本原理中提到的Chat Template,上述的示例只是为了方便我们理解。例如用于GPT-4 SFT微调的真实标注语料如下图所示:
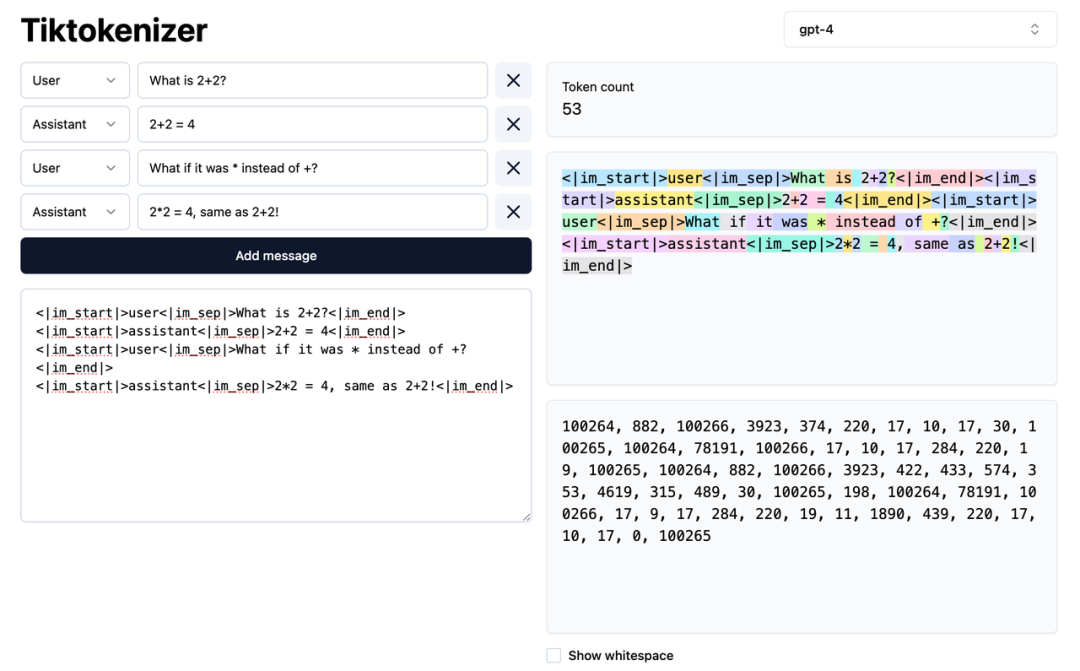
接下来我们可以看下InstructGPT论文中对SFT的关键描述:
We first hired a team of 40 contractors to label our data, based on their performance on a screening test (see Section 3.4 and Appendix B.1 for more details). We then collect a dataset of human-written demonstrations of the desired output behavior on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train our supervised learning baselines.
我们首先根据筛选测试的表现,聘用了 40 名外包标注人员来标注数据。随后,我们收集了一批由人类撰写的示范数据,这些数据展示了提示词(主要为英文的)输入下,期望得到的输出行为。这些提示词一部分来自提交到 OpenAI API 的用户输入,另一部分由标注人员自行编写。我们利用这些数据基于监督学习来训练基础模型。
Labelers significantly prefer InstructGPT outputs over outputs from GPT-3. On our test set, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having over 100x fewer parameters. These models have the same architecture, and differ only by the fact that InstructGPT is fine-tuned on our human data. This result holds true even when we add a few-shot prompt to GPT-3 to make it better at following instructions.
标注人员明显更偏好 InstructGPT 的输出,而不是 GPT-3 的输出。在我们的测试集中,尽管参数规模小了超过 100 倍(13 亿参数 vs. 1750 亿参数),13 亿参数的 InstructGPT 模型生成的结果仍然比 1750 亿参数的 GPT-3 更受欢迎。这些模型具有相同的架构,唯一的区别在于 InstructGPT 在我们的人类标注数据上进行了微调。即使我们为 GPT-3 添加了少样本提示以提升其遵循指令的能力,这一结果依然成立。
SFT微调的过程如下图所示:
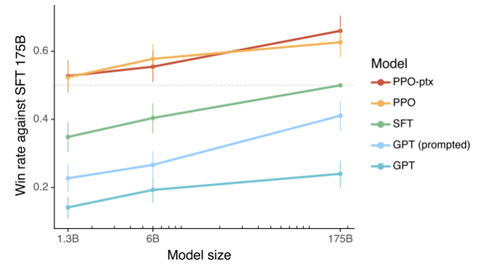
从论文的结论中可以清晰的看到,经过SFT微调后的1.3B的InstructGPT在用户评估中其性能要优于175B的GPT-3模型,尽管InstructGPT模型参数数量比GPT-3的参数数量少100倍,如下图所示:
因为SFT微调的训练数据是需要人类进行标注的,那到底需要多少笔资料呢?
针对这个问题,其实有很多的研究都表明,SFT微调所需资料数量可能远远小于大家的认知,只需要一万笔左右高质量的资料即可,以下是节选自Llama2的论文:
Llama 2: Open Foundation and Fine-Tuned Chat Models

通过以上内容,我们可以看到SFT只需要少量的人工标注的资料就可以激发出Base Model模型的潜能。
那到底SFT做了什么?为什么在少量的人类标注的资料上对Base Model进行微调后,模型就可以输出符合人类期望的答案呢?
有很多的论文研究表明:其实SFT微调的过程并没有给模型带来本质的变化,SFT并不能给大语言模型更多新的知识,它只是改变了模型的输出风格,在行为统计上尽可能的去模仿训练标注资料,使其风格保持一致。我们可以结合下面的论文进行说明:
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
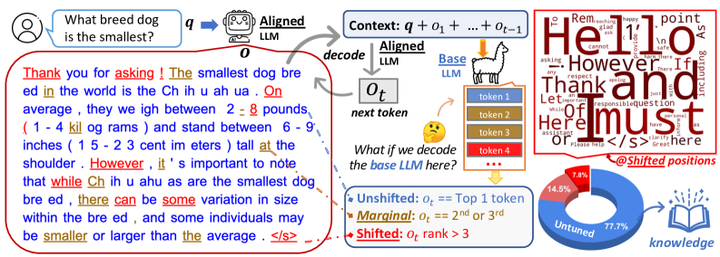
Analyzing alignment with token distribution shift. An aligned LLM (llama-2-chat) receives a query 𝐪 and outputs a response 𝐨. To analyze the effect of alignment tuning, we decode the untuned version (llama-2-base) at each position t. Next, we categorize all tokens in 𝐨 into three groups based on t’s rank in the list of tokens sorted by probability from the base LLM. On average, 77.7% of tokens are also ranked top 1 by the base LLM ( unshifted positions), and 92.2% are within the top 3 (+ marginal). Common tokens at shifted positions are displayed at the top-right and are mostly stylistic, constituting discourse markers. In contrast, knowledge-intensive tokens are predominantly found in unshifted positions.
分析对齐过程中 token 分布的变化。一个经过对齐的语言模型(llama-2-chat)接收一个查询 𝐪,并生成响应 𝐨。为了分析对齐调优的影响,我们在每一个位置t 上,用未对齐版本(llama-2-base)进行解码。接着,我们根据每个位置上的 token 在基础模型按概率排序的 token 列表中的排名,将响应 𝐨 中的所有 token 分为三类。平均来看,77.7% 的 token 在基础模型中同样排名第 1(即未偏移(unshifted)位置),92.2% 的 token 排在前三(即包含边际偏移(marginal))。在发生偏移(shifted)的位置中,常见的 token 多为风格性用语,主要构成话语标记(discourse markers)。相比之下,知识密集型 token主要集中在未偏移的位置。
该论文对基础模型Llama2和微调后的Llama2-chat进行对比测试,将预测的下一个Token划分为Unshifted、Marginal和Shifted三类,从结论可以看到只有大约7%的Token预测的rank发生了Shifted偏移,而且这些Token如右上角所示,基本都是一些mostly stylistic, constituting discourse markers(主要是“风格层面”的,构成“话语标记”,意思是这些内容更多是“说话方式”的体现,而不是“信息本身”,它们属于话语标记)。
然后作者在更多的模型上进行实验,基本都得到了相同的结论:
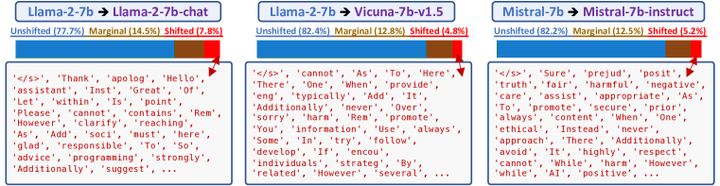
可是如果Shifted的Token的占比这么少,为什么Base Model和SFT之后的Model输出往往会天差地别呢?其实根本的原因还是回到大语言模型的本质就是在做『文字接龙』,真是一步错步步错,虽然只是连接词一个Token的改变,但是文字接龙的结果确是完全不同。
那你接下来可能会想:即使SFT微调的训练数据只需要一万笔左右,但是也都是需要人工进行标注的,为了得到高质量的标注数据,需要针对每一个Instruct指令,都需要相应的专家给出示范答案,那有没有办法可以解决这个问题呢?
答案就是知识蒸馏Knowledge Distillation,整体流程如下所示:

知识蒸馏的本质是用一个更『强』的模型扮演『标注人员和专家』给出答案,再用这些高质量的数据来SFT微调一个新的模型。基于知识蒸馏的方法确实可以有效的微调大语言模型,而且成本很低。目前有很多论文都在宣称他们只花费了不到100美元就可以训练出一个性能还不错的大语言模型,比如:Alpaca、S1等,其本质上都是基于一个开源的Base Model之上,使用ChatGPT或者Gemini的知识通过蒸馏的方式微调出来的模型。
那进一步知识蒸馏过程中『准备Instruct指令』这个步骤是不是也可以省去呢?
近期确实有很多论文研究在尝试这种范式:只需要从网络上随便找一些句子,将句子的前半部分当作Instruct指令给到教师模型(比如ChatGPT)来生成答案,再通过这些数据来微调我们自己的模型,这种方式叫做Non-Instructional Fine-Tuning。更进一步,有人提出当前大部分的SFT都是Instruct Fine tunning,需要准备一个问题和一个答案,那是不是可以完全不用准备问题和答案指令对,直接将教师模型的任意生成的内容作为SFT的训练资料来微调模型,这个方法叫做Response Fine-Tunning,论文结果证明该方法同样有效,居然效果和Instruct Fine-Tuning的性能差不多。
SFT的本质到底是什么?
SFT的本质,是让大语言模型学习人类偏好的回答方式。当我们与一个经过SFT训练的模型对话时,可以将其理解为一个统计意义上的人类标注人员模拟器。模型的回答并不是实时搜索或推理后得到的结果,而是基于训练过程中学到的概率分布,对在类似问题下人类通常如何回答的一种模仿。
以『推荐北京最值得参观的五个地标』为例,模型的输出并不是来自一次真实的检索与筛选过程,而更像是对大量相关语料中常见模式的组合与重构。它会综合预训练阶段获得的世界知识,以及SFT阶段学到的表达偏好,生成一个『看起来合理且符合人类习惯』的答案。这种生成过程本质上是概率驱动的,而非事实校验驱动的,所以当模型缺乏足够知识或模式支持时,也可能生成看似合理但不完全准确的内容。
所以,SFT并不是让模型学会“如何得到答案”,而是让模型学会“什么样的答案更像人类认为的好答案”。
The “psychology(心理学)” of a sft model
以下内容同样借鉴Karpathy大神的观点,我们来看看在SFT微调这种训练过程下,LLM会产生哪些认知行为?
- 幻觉(Hallucination)
首先就是『幻觉』问题:即模型会编造信息,这在早期的LLM是非常严重的问题,现在已经有所改善,但是仍然存在,那么幻觉是如何产生的?
假设SFT训练集中有以下对话:

在训练数据中,当人类标注人员提供答案时,他们要么本来就知道答案,要么会借助工具比如去网上搜索,然后给出一个『自信且确定的答案』。但是问题就在这里,假设现在你的提问是:『Who is Orson Kovats?』,Orson Kovats是一个随便构造的名字,这个时候其实模型很可能也并不知道这个人是谁,但是模型可能并不会像人类一样回答:『我不知道。』,因为在训练集中类似『Who is xxx?』这样的问题总是有答案,所以模型会模仿这种模式并自信的给出答案,于是就产生了『幻觉』。那如何解决幻觉的问题呢?
缓解措施 #1:
使用不断向模型提问的方式来发现模型不知道的知识,并将其添加到训练数据集后对模型进行微调,使模型在不知道的情况下拒绝回答。例如:

缓解措施 #2:
如同我们在不知道的情况下会使用搜索工具一样,同样可以对训练集进行扩充让模型学会如何使用工具,这个能力就是我们经常听到的Function Calling,也是Agent底层依赖的基础能力,我们会在下一篇文章中详细介绍。

- 模糊记忆 & 工作记忆
模糊记忆可以理解为Pre-train在参数中压缩的知识记忆,可以理解为很久以前读过的内容;工作记忆指对话过程中上下文窗口里的知识,是模型可以直接访问的内容。
当我们使用LLM对内容进行总结或者摘要时,更好的做法是把对应的内容直接放到上下文中,这样模型就不需要去回忆。
- 模型没有自我意识!
当我们使用LLM的时候,很多人会下意识的问:『你是谁?』、『谁创造了你?』等这样的问题,在早些时候很多模型的回答可能会出现是OpenAI。
这里要强调的是其实这样的问题没有太大意义,因为模型的本质就是做文字接龙,基于Pre-train的知识来预测下一个Token,可能在Pre-train的时候互联网上就是存在了大量有关ChatGPT的内容,所以模型会输出OpenAI。当然如果此时你问任何一个模型这样的问题,大概率都不会出现这个尴尬的答案。可以通过以下方法解决这个问题:
方法一:在SFT训练集中加入这样的对话,硬编码让模型知道它是谁。
方法二:在System Prompt中添加模型自我认知相关的信息。
- 模型如何思考?
一个重要的事实是:模型只能从左向右的生成Token,意味着每生成一个Token,模型只进行一次前向计算,因此,每个Token的计算量是有限的,所以模型是不能在一个Token计算中完成一个复杂的推理。举个例子:

如上两个标注示例,虽然答案都是正确的,但是我们认为第二个示例会更好,因为整个推理被分布到了多个Token计算中,这个过程就是CoT(Chain of Thought)。
所以如果有些任务要求模型只输出一个Token,对于稍微复杂的问题可能模型就没办法给出正确答案,因为整个计算量超过了单个Token的能力,那么更好的办法就是使用Tool工具,比如可以使用代码编程来计算。
所以我们要知道的是:模型是需要通过Token进行思考的,所以不要依赖LLM去做类似心算、内部推理以及复杂计算的事情,而应该尽量把问题拆解并使用工具解决问题,这也是构建Agent的思想。
- 模型为什么不擅长做计数?
有个经典的问题:strawberry中有几个r?在早期,这个问题很多大语言模型都没办法回答正确,即使在今天,虽然ChatGPT回答的结论是对的,但是过程中还是有些问题,如下图所示:
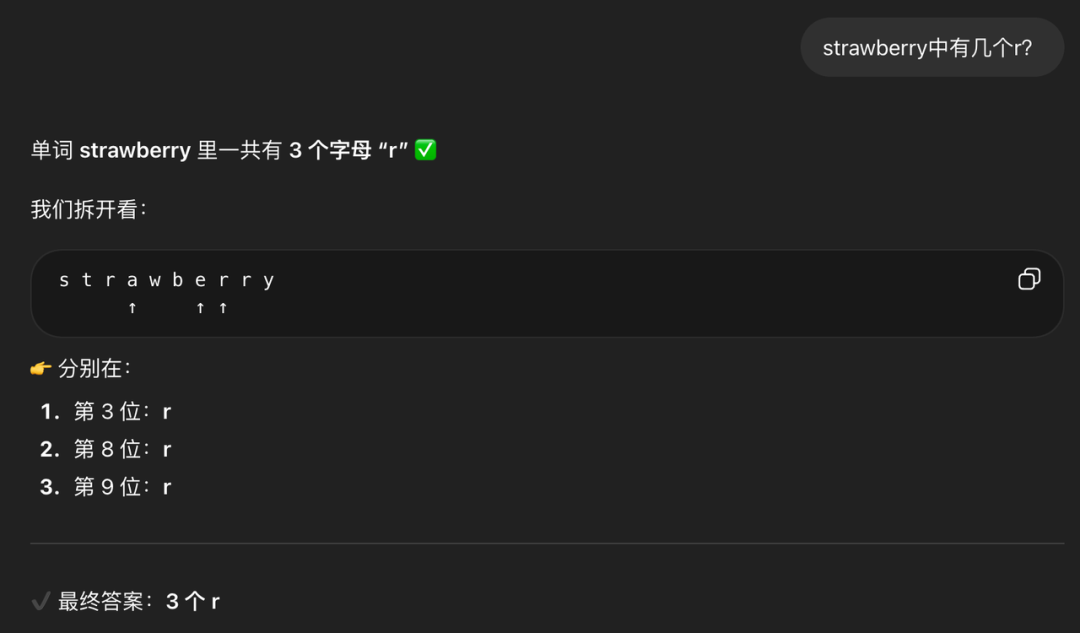
那为什么会出现这样的结果呢?这类问题看似很简单,但是当我们问『strawberry中有几个r?』时,模型看到的并不是strawberry这个单词,而是对应的Token,还记得我们一直强调的大语言模型其实在做的是『Token接龙』,然后我们要求模型根据这些Token去数有多少个『r』,本身对于LLM来说就是一件很难的事情,所以对于像单词拼写、字母操作以及字符计数等问题推荐的做法还是通过调用工具基于代码编程来解决。
到这里我们已经介绍了大语言模型训练的前两个阶段:
- Pre-train(预训练):基于互联网的文本数据,得到Base Model,它的本质是一个『互联网文档模拟器』;
- SFT(Supervised Fine-Tuning):基于人类标注的对话数据,得到SFT Model,它的本质是一个『统计意义上的人类标注人员模拟器』,让大语言模型学习人类偏好的回答方式。
下面我们来介绍第三个阶段RLHF基于人类反馈的强化学习。
三、RLHF Stage
也许你曾经也好奇过大语言模型的强化学习RL训练是如何运作的?RLHF到底是什么?为什么大语言模型的训练过程中要先进行SFT然后再进行RLHF,我们是不是可以跳过SFT直接进行RL训练呢?下面我们开始介绍大语言模型训练的第三个阶段:强化学习阶段,通过下面的介绍相信你会对RLHF会有更深入的理解。
在开始之前我们先来看下什么是强化学习?
强化学习(Reinforcement Learning,RL)的核心思想是通过试错学习(Trial-and-error Learning)与奖励反馈(Reward model)来学习最优决策策略,其本质就是在不确定环境中,通过与环境交互、利用奖励信号,不断更新策略,从而最大化长期收益。
强化学习RL的基本框架如下图所示:
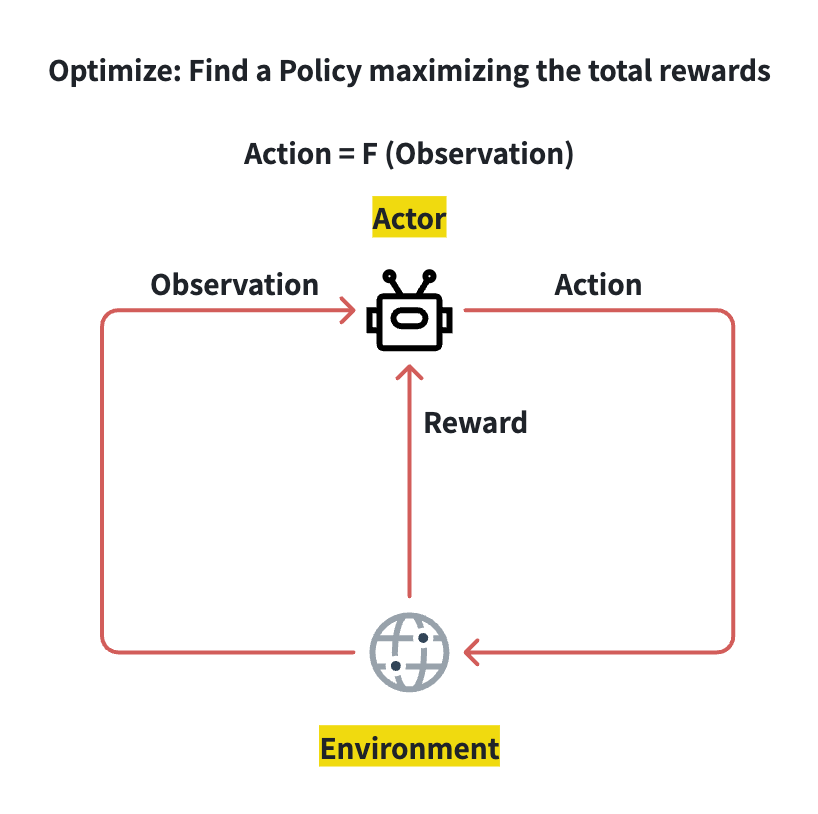
强化学习RL中有两个核心角色:Actor(即我们要训练的Model)和Environment(Actor所处的环境),整个过程是一个不断循环的过程:
- Actor会不断的观察当前的状态(Observation)并决定下一个动作(Action);
- Environment基于当前的动作(Action)更新状态并返回奖励(Reward)。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献153条内容
已为社区贡献153条内容

所有评论(0)