AI | token 的本质
注:本文为 “AI | token” 相关合辑。
英文引文,机翻未校。
中文引文,略作重排。
图片清晰度受引文原图所限。
未整理去重,如有内容异常,请看原文。
Explaining Tokens — the Language and Currency of AI
解析 Token —— AI 的语言与流通媒介
March 17, 2025 by Dave Salvator
Tokens are units of data processed by AI models during training and inference, enabling prediction, generation and reasoning.
Token 是 AI 模型在训练与推理阶段处理的数据单元,支撑模型完成预测、生成与推理任务。
Under the hood of every AI application are algorithms that churn through data in their own language, one based on a vocabulary of tokens.
每一款 AI 应用的底层均搭载算法,这些算法以自身语言处理数据,而该语言依托于由 token 构成的词汇表。
Tokens are tiny units of data that come from breaking down bigger chunks of information. AI models process tokens to learn the relationships between them and unlock capabilities including prediction, generation and reasoning. The faster tokens can be processed, the faster models can learn and respond.
Token 是将大规模信息拆分后形成的微型数据单元。AI 模型通过处理 token 学习单元间的关联关系,进而实现预测、生成与推理等功能。token 处理速度越快,模型学习与响应的效率越高。
AI factories — a new class of data centers designed to accelerate AI workloads — efficiently crunch through tokens, converting them from the language of AI to the currency of AI, which is intelligence.
AI 工厂是一类专为加速 AI 任务设计的新型数据中心,可高效处理 token,将其从 AI 的语言转化为 AI 的流通媒介,即智能。
With AI factories, enterprises can take advantage of the latest full-stack computing solutions to process more tokens at lower computational cost, creating additional value for customers. In one case, integrating software optimizations and adopting the latest generation NVIDIA GPUs reduced cost per token by 20x compared to unoptimized processes on previous-generation GPUs — delivering 25x more revenue in just four weeks.
依托 AI 工厂,企业可采用最新的全栈计算方案,以更低算力成本处理更多 token,为客户创造附加价值。某案例显示,结合软件优化方案并搭载新一代 NVIDIA GPU 后,单个 token 处理成本较上一代 GPU 未优化流程降低 20 倍,仅 4 周内营收提升 25 倍。
By efficiently processing tokens, AI factories are manufacturing intelligence — the most valuable asset in the new industrial revolution powered by AI.
AI 工厂通过高效处理 token 生产智能,而智能是 AI 驱动的新一轮工业革命中最具价值的资产。
What Is Tokenization?
什么是 Tokenization(分词)?
Whether a transformer AI model is processing text, images, audio clips, videos or another modality, it will translate the data into tokens. This process is known as tokenization.
无论 Transformer AI 模型处理文本、图像、音频片段、视频或其他模态数据,均会将数据转化为 token,该过程称为分词。
Efficient tokenization helps reduce the amount of computing power required for training and inference. There are numerous tokenization methods — and tokenizers tailored for specific data types and use cases can require a smaller vocabulary, meaning there are fewer tokens to process.
高效分词可降低训练与推理所需的算力消耗。分词方法种类繁多,针对特定数据类型与应用场景定制的分词器可采用更小的词汇表,即待处理的 token 数量更少。
For large language models (LLMs), short words may be represented with a single token, while longer words may be split into two or more tokens.
对于大语言模型,短单词可由单个 token 表示,长单词则可拆分为两个及以上 token。
The word darkness, for example, would be split into two tokens, “dark” and “ness,” with each token bearing a numerical representation, such as 217 217 217 and 655 655 655. The opposite word, brightness, would similarly be split into “bright” and “ness,” with corresponding numerical representations of 491 491 491 and 655 655 655.
以单词 darkness 为例,可拆分为 dark 与 ness 两个 token,各 token 对应数值标识,如 217 217 217 与 655 655 655。其反义词 brightness 同理拆分为 bright 与 ness,对应数值标识为 491 491 491 与 655 655 655。
In this example, the shared numerical value associated with “ness” can help the AI model understand that the words may have something in common. In other situations, a tokenizer may assign different numerical representations for the same word depending on its meaning in context.
该案例中,与 ness 关联的共用数值可帮助 AI 模型识别单词间的共性。其他场景下,分词器会依据同一单词在语境中的含义分配不同数值标识。
For example, the word “lie” could refer to a resting position or to saying something untruthful. During training, the model would learn the distinction between these two meanings and assign them different token numbers.
例如单词 lie 可表示躺卧姿态或虚假陈述,模型在训练过程中会学习两种含义的差异,并分配不同 token 编号。
For visual AI models that process images, video or sensor data, a tokenizer can help map visual inputs like pixels or voxels into a series of discrete tokens.
处理图像、视频或传感器数据的视觉 AI 模型中,分词器可将像素、体素等视觉输入映射为一系列离散 token。
Models that process audio may turn short clips into spectrograms — visual depictions of sound waves over time that can then be processed as images. Other audio applications may instead focus on capturing the meaning of a sound clip containing speech, and use another kind of tokenizer that captures semantic tokens, which represent language or context data instead of simply acoustic information.
处理音频的模型可将短片段转化为声谱图,即声波随时间变化的可视化形式,后续按图像方式处理。部分音频应用侧重提取语音片段的语义信息,采用另一类分词器获取语义 token,该类 token 表征语言或语境数据,而非单纯的声学信息。
How Are Tokens Used During AI Training?
Token 在 AI 训练阶段的应用方式
Training an AI model starts with the tokenization of the training dataset.
AI 模型训练以训练数据集的分词处理为起点。
Based on the size of the training data, the number of tokens can number in the billions or trillions — and, per the pretraining scaling law, the more tokens used for training, the better the quality of the AI model.
依据训练数据规模,token 总量可达数十亿至万亿级别。根据预训练缩放定律,训练所用 token 数量越多,AI 模型的效果越优。
As an AI model is pretrained, it’s tested by being shown a sample set of tokens and asked to predict the next token. Based on whether or not its prediction is correct, the model updates itself to improve its next guess. This process is repeated until the model learns from its mistakes and reaches a target level of accuracy, known as model convergence.
AI 模型预训练时,会接收一组 token 样本并预测下一个 token 以完成测试。模型依据预测结果的正误完成参数更新,优化后续预测。该过程重复执行,直至模型从误差中学习并达到目标精度,该状态称为模型收敛。
After pretraining, models are further improved by post-training, where they continue to learn on a subset of tokens relevant to the use case where they’ll be deployed. These could be tokens with domain-specific information for an application in law, medicine or business — or tokens that help tailor the model to a specific task, like reasoning, chat or translation. The goal is a model that generates the right tokens to deliver a correct response based on a user’s query — a skill better known as inference.
预训练完成后,模型通过后训练进一步优化,在与部署场景相关的 token 子集上持续学习。该类 token 可包含法律、医疗、商业等领域的专属信息,或适配推理、对话、翻译等特定任务。优化目标为使模型依据用户查询生成合适 token,输出正确响应,该能力即为推理。
How Are Tokens Used During AI Inference and Reasoning?
Token 在 AI 推理与思考阶段的应用方式
During inference, an AI receives a prompt — which, depending on the model, may be text, image, audio clip, video, sensor data or even gene sequence — that it translates into a series of tokens. The model processes these input tokens, generates its response as tokens and then translates it to the user’s expected format.
推理阶段,AI 接收提示词,依据模型类型不同,提示词可为文本、图像、音频片段、视频、传感器数据乃至基因序列,AI 会将其转化为一系列 token。模型处理输入 token 后以 token 形式生成响应,再转化为用户所需格式。
Input and output languages can be different, such as in a model that translates English to Japanese, or one that converts text prompts into images.
输入与输出语言可不同,例如实现英日翻译的模型,或将文本提示词转化为图像的模型。
To understand a complete prompt, AI models must be able to process multiple tokens at once. Many models have a specified limit, referred to as a context window — and different use cases require different context window sizes.
AI 模型需同时处理多个 token 以理解完整提示词。多数模型设有固定上限,称为上下文窗口,不同应用场景对应不同的上下文窗口尺寸。
A model that can process a few thousand tokens at once might be able to process a single high-resolution image or a few pages of text. With a context length of tens of thousands of tokens, another model might be able to summarize a whole novel or an hourlong podcast episode. Some models even provide context lengths of a million or more tokens, allowing users to input massive data sources for the AI to analyze.
单次可处理数千 token 的模型可完成单张高分辨率图像或数页文本的处理。上下文长度达数万 token 的模型可完成整本小说或一小时播客的摘要生成。部分模型的上下文长度超百万 token,支持用户输入大规模数据源供 AI 分析。
Reasoning AI models, the latest advancement in LLMs, can tackle more complex queries by treating tokens differently than before. Here, in addition to input and output tokens, the model generates a host of reasoning tokens over minutes or hours as it thinks about how to solve a given problem.
推理型 AI 模型是大语言模型的最新进展,通过改变 token 处理方式应对更复杂的查询。该类模型除输入与输出 token 外,会在数分钟至数小时内生成大量思考 token,以推导问题解决方案。
These reasoning tokens allow for better responses to complex questions, just like how a person can formulate a better answer given time to work through a problem. The corresponding increase in tokens per prompt can require over 100 × 100\times 100× more compute compared with a single inference pass on a traditional LLM — an example of test-time scaling, aka long thinking.
思考 token 可提升复杂问题的响应质量,如同人类通过思考形成更完善的答案。单条提示词对应的 token 数量增加后,算力需求较传统大语言模型单次推理提升超 100 倍,该现象属于测试时缩放,也称为深度思考。
How Do Tokens Drive AI Economics?
Token 如何驱动 AI 经济体系?
During pretraining and post-training, tokens equate to investment into intelligence, and during inference, they drive cost and revenue. So as AI applications proliferate, new principles of AI economics are emerging.
预训练与后训练阶段,token 对应智能研发的投入;推理阶段,token 决定成本与收益。随着 AI 应用普及,AI 经济的全新规则逐步形成。
AI factories are built to sustain high-volume inference, manufacturing intelligence for users by turning tokens into monetizable insights. That’s why a growing number of AI services are measuring the value of their products based on the number of tokens consumed and generated, offering pricing plans based on a model’s rates of token input and output.
AI 工厂支持大规模推理任务,将 token 转化为可变现的分析结论,为用户生产智能。因此越来越多的 AI 服务依据 token 消耗与生成数量衡量产品价值,并基于模型的 token 输入输出速率制定定价方案。
Some token pricing plans offer users a set number of tokens shared between input and output. Based on these token limits, a customer could use a short text prompt that uses just a few tokens for the input to generate a lengthy, AI-generated response that took thousands of tokens as the output. Or a user could spend the majority of their tokens on input, providing an AI model with a set of documents to summarize into a few bullet points.
部分 token 定价方案为用户提供输入与输出共用的固定 token 额度。用户可使用仅含少量 token 的短文本提示词作为输入,生成包含数千 token 的长文本 AI 响应;也可将大部分 token 额度用于输入,向模型提供多份文档并生成简短要点摘要。
To serve a high volume of concurrent users, some AI services also set token limits, the maximum number of tokens per minute generated for an individual user.
为支撑大规模并发用户,部分 AI 服务设置 token 限制,即单个用户每分钟可生成的 token 最大数量。
Tokens also define the user experience for AI services. Time to first token, the latency between a user submitting a prompt and the AI model starting to respond, and inter-token or token-to-token latency, the rate at which subsequent output tokens are generated, determine how an end user experiences the output of an AI application.
token 同样决定 AI 服务的用户体验。首 token 时间指用户提交提示词至模型开始响应的延迟,token 间延迟指后续输出 token 的生成速率,二者共同决定终端用户对 AI 应用输出的体验感受。
There are tradeoffs involved for each metric, and the right balance is dictated by use case.
各项指标间存在权衡关系,合理的平衡方案由应用场景决定。
For LLM-based chatbots, shortening the time to first token can help improve user engagement by maintaining a conversational pace without unnatural pauses. Optimizing inter-token latency can enable text generation models to match the reading speed of an average person, or video generation models to achieve a desired frame rate. For AI models engaging in long thinking and research, more emphasis is placed on generating high-quality tokens, even if it adds latency.
基于大语言模型的聊天机器人中,缩短首 token 时间可维持自然对话节奏、减少异常停顿,提升用户参与度。优化 token 间延迟可使文本生成模型匹配普通人阅读速度,或使视频生成模型达到目标帧率。执行深度思考与研究任务的 AI 模型更侧重生成高质量 token,即便会增加延迟。
Developers have to strike a balance between these metrics to deliver high-quality user experiences with optimal throughput, the number of tokens an AI factory can generate.
开发者需在各项指标间寻求平衡,在最优吞吐量(AI 工厂可生成的 token 数量)前提下提供优质用户体验。
To address these challenges, the NVIDIA AI platform offers a vast collection of software, microservices and blueprints alongside powerful accelerated computing infrastructure — a flexible, full-stack solution that enables enterprises to evolve, optimize and scale AI factories to generate the next wave of intelligence across industries.
为应对上述挑战,NVIDIA AI 平台提供丰富的软件、微服务、方案蓝图与高性能加速计算基础设施,构成灵活的全栈解决方案,助力企业迭代、优化与扩容 AI 工厂,推动各行业智能技术的新一轮发展。
Understanding how to optimize token usage across different tasks can help developers, enterprises and even end users reap the most value from their AI applications.
掌握不同任务下 token 用量的优化方法,可帮助开发者、企业乃至终端用户从 AI 应用中获取最大价值。
What is a token in AI and why is it so important?
AI 中的 token 是什么,为何其作用显著?
By Mirza Bahic published December 9, 2024
Find out how these tiny units make AI smart
探究这类微型单元如何赋予 AI 智能
In the world of artificial intelligence (AI), you may have come across the term “token” more times than you can count. If they mystify you, don’t worry - tokens aren’t as mysterious as they sound. In fact, they’re one of the most fundamental building blocks behind AI’s ability to process language. You can imagine tokens as the Lego pieces that help AI models construct worthwhile sentences, ideas, and interactions.
人工智能领域中,token 一词出现频率极高。若该概念令人困惑,无需担忧,token 并非如听起来那般晦涩。事实上,它是 AI 实现语言处理能力的基础组成单元之一。可将 token 类比为乐高积木,帮助 AI 模型构建合理语句、观点与交互内容。
Whether it’s a word, a punctuation mark, or even a snippet of sound in speech recognition, tokens are the tiny chunks that allow AI to understand and generate content. Ever used a tool like ChatGPT or wondered how machines summarize or translate text? Chances are, you’ve encountered tokens without even realizing it. They’re the behind-the-scenes crew that makes everything from text generation to sentiment analysis tick.
无论是单词、标点符号,还是语音识别中的音频片段,token 均为 AI 理解与生成内容的微型片段。使用 ChatGPT 等工具,或好奇机器如何完成文本摘要、翻译时,大概率已在无意识中接触 token。token 是支撑文本生成、情感分析等各类功能的底层核心单元。
In this guide, we’ll unravel the concept of tokens - how they’re used in natural language processing (NLP), why they’re so critical for AI, and how this seemingly small detail plays a huge role in making the best AI tools smarter.
本文将解析 token 概念,介绍其在自然语言处理中的应用、对 AI 的作用,以及该看似细微的要素如何推动优质 AI 工具性能提升。
So, get ready for a deep dive into the world of tokens, where we’ll cover everything from the fundamentals to the exciting ways they’re used.
接下来深入探究 token 领域,从基础原理到前沿应用逐一讲解。
What is a token in AI?
AI 中的 token 定义
Think of tokens as the tiny units of data that AI models use to break down and make sense of language. These can be words, characters, subwords, or even punctuation marks - anything that helps the model understand what’s going on.
token 是 AI 模型拆分并理解语言所用的微型数据单元,形式包括单词、字符、子词乃至标点符号,所有辅助模型理解信息的单元均属此类。
For instance, in a sentence like “AI is awesome,” each word might be a token. However, for trickier words, like “tokenization,” the model might break them into smaller chunks (subwords) to make them easier to process. This helps AI handle even the most complex or unusual terms without breaking a sweat.
例如句子 AI is awesome 中,每个单词可作为单个 token。对于 tokenization 这类复杂单词,模型会拆分为更小的子词片段以简化处理,使 AI 轻松应对复杂或生僻术语。
In a nutshell, tokens are the building blocks that let AI understand and generate language in a way that makes sense. Without them, AI would be lost in translation.
简言之,token 是 AI 合理理解与生成语言的基础单元,缺失 token 会导致 AI 无法完成语言处理任务。
Which types of tokens exist in AI?
AI 中的 token 类型
Depending on the task, these handy data units can take a whole variety of forms. Here’s a quick tour of the main types:
依据任务类型不同,token 呈现多种形式,主要类型如下:
- Word tokens - These are straightforward: each word is its own token. For instance, in “AI simplifies life,” the tokens are AI, simplifies, and life.
单词型 token:形式直观,每个单词为独立 token。例如句子 AI simplifies life 中,token 为 AI、simplifies、life。 - Subword tokens - Sometimes words get fancy, so they’re broken into smaller, meaningful pieces. For example, “unbreakable” might become un, break, and able. This helps AI deal with tricky words.
子词型 token:复杂单词会拆分为有意义的小片段,例如 unbreakable 可拆分为 un、break、able,辅助 AI 处理复杂词汇。 - Character tokens - Each character stands on its own. For “Hello,” the tokens are H, e, l, l, and o. This method is great for languages or data with no clear word boundaries.
字符型 token:单个字符为独立单元,例如 Hello 拆分为 H、e、l、l、o,适用于无明确单词边界的语言或数据。 - Punctuation tokens - Even punctuation marks get their moment in the spotlight! In “AI rocks!” the tokens include !, because AI knows punctuation matters.
标点型 token:标点符号为独立 token,例如句子 AI rocks! 中,! 属于 token,因 AI 需识别标点的语义作用。 - Special tokens - Think of these as AI’s backstage crew. Tokens like (beginning of sequence) or (unknown word) help models structure data and handle the unexpected.
- 特殊 token:作为 AI 辅助单元,如序列起始、未知单词等标识,帮助模型规整数据、处理未知信息。
Every token type pulls its weight, helping the system stay smart and adaptable.
各类 token 协同工作,提升系统的智能性与适配性。
What is tokenization in AI and how it works?
AI 中的分词定义与工作原理
Tokenization in NLP is all about splitting text into smaller parts, known as tokens - whether they’re words, subwords, or characters. It’s the starting point for teaching AI to grasp human language.
自然语言处理中的分词指将文本拆分为单词、子词或字符等 token 片段,是 AI 学习人类语言的初始步骤。
Here’s how it goes - when you feed text into a language model like GPT, the system splits it into smaller parts or tokens. Take the sentence “Tokenization is important” - it would be tokenized into “Tokenization,” “is,” and “important.” These tokens are then converted into numbers (vectors) that AI uses for processing.
工作流程为:向 GPT 等语言模型输入文本后,系统将其拆分为 token 片段。例如句子 Tokenization is important 会被拆分为 Tokenization、is、important,随后这些 token 转化为 AI 可处理的数值向量。
The magic of tokenization comes from its flexibility. For simple tasks, it can treat every word as its own token. But when things get trickier, like with unusual or invented words, it can split them into smaller parts (subwords). This way, the AI keeps things running smoothly, even with unfamiliar terms.
分词的优势在于灵活性。简单任务中可按单词拆分,遇到生僻或自创词汇时可拆分为子词,使 AI 稳定处理未知术语。
Modern models, like GPT-4, work with massive vocabularies - around 50,000 tokens. Every piece of input text is tokenized into this predefined vocabulary before being processed. This step is crucial because it helps the AI model standardize how it interprets and generates text, making everything flow as smoothly as possible.
GPT-4 等现代模型搭载约 5 万个 token 的大规模词汇表,输入文本需先按预设词汇表完成分词再处理。该步骤可规范模型的文本解读与生成逻辑,保障流程顺畅。
By chopping language into smaller pieces, tokenization gives AI everything it needs to handle language tasks with precision and speed. Without it, modern AI wouldn’t be able to work its magic.
分词将语言拆分为小片段,为 AI 高效精准完成语言任务提供支撑,是现代 AI 实现语言功能的必要前提。
Why are tokens important in AI?
token 在 AI 中作用显著的原因
Tokens are more than just building blocks - they’re what make AI tick. Without them, AI couldn’t process language, understand nuances, or generate meaningful responses. So, let’s break it down and see why tokens are so essential to AI’s success:
token 不仅是基础单元,更是 AI 运行的核心要素,缺失后 AI 无法处理语言、识别语义细节或生成有效响应。其作用体现在以下方面:
Breaking down language for AI
为 AI 拆分语言单元
When you type something into an AI model, like a chatbot, it doesn’t just take the whole sentence and run with it. Instead, it chops it up into bite-sized pieces called tokens. These tokens can be whole words, parts of words, or even single characters. Think of it as giving the AI smaller puzzle pieces to work with - it makes it much easier for the model to figure out what you’re trying to say and respond smartly.
向聊天机器人等 AI 模型输入文本时,模型不会直接处理整句,而是拆分为单词、子词或字符等 token 片段。如同为 AI 提供小型拼图碎片,便于模型理解语义并生成合理响应。
For example, if you typed, “Chatbots are helpful,” the AI would split it into three tokens: “Chatbots,” “are,” and “helpful.” Breaking it down like this helps the AI focus on each part of your sentence, making sure it gets what you’re saying and gives a spot-on response.
例如输入 Chatbots are helpful 后,AI 拆分为 Chatbots、are、helpful 三个 token,逐段解析语义,保障响应的准确性。
Understanding context and nuance
理解语境与语义细节
Tokens truly shine when advanced models like transformers step in. These models don’t just look at tokens individually - they analyze how the tokens relate to one another. This lets AI grasp the basic meaning of words as well as the subtleties and nuances behind them.
Transformer 等先进模型可充分发挥 token 的作用,模型不仅识别单个 token,还分析 token 间的关联关系,同时掌握单词基础含义与深层语义细节。
Imagine someone saying, “This is just perfect.” Are they thrilled, or is it a sarcastic remark about a not-so-perfect situation? Token relationships help AI understand these subtleties, enabling it to provide spot-on sentiment analysis, translations, or conversational replies.
例如语句 This is just perfect 可表达欣喜或反讽,token 间的关联帮助 AI 识别此类细节,完成精准的情感分析、翻译与对话回复。
Data representation through tokens
通过 token 完成数据表征
Once the text is tokenized, each token gets transformed into a numerical representation, also known as a vector, using something called embeddings. Since AI models only understand numbers (so, no room for raw text), this conversion lets them work with language in a way they can process. These numerical representations capture the meaning of each token, helping the AI do things like spotting patterns, sorting through text, or even creating new content.
文本分词后,每个 token 通过嵌入技术转化为数值向量。AI 模型仅识别数值信息,该转化过程使其可处理语言数据。数值向量承载 token 语义,辅助 AI 识别规律、筛选文本乃至生成全新内容。
Without tokenization, AI would struggle to make sense of the text you type. Tokens serve as the translator, converting language into a form that AI can process, making all its impressive tasks possible.
缺失分词步骤,AI 无法解读输入文本。token 充当翻译载体,将语言转化为 AI 可处理的形式,支撑各类复杂功能实现。
Tokens’ role in memory and computation
token 在存储与计算中的作用
Every AI model has a limit on how many tokens it can handle at once, and this is called the “context window.” You can think of it like the AI’s attention span - just like how we can only focus on a limited amount at a time. By understanding how tokens work within this window, developers can optimize how the AI processes information, making sure it stays sharp.
所有 AI 模型均设有单次处理 token 数量上限,即上下文窗口,可类比为 AI 的注意力范围。开发者依据窗口内 token 运行逻辑优化信息处理流程,保障模型性能。
If the input text becomes too long or complex, the model prioritizes the most important tokens, ensuring it can still deliver quick and accurate responses. This helps keep the AI running smoothly, even when dealing with large amounts of data.
输入文本过长或复杂时,模型优先处理关键 token,保障响应的速度与精度,使 AI 稳定处理大规模数据。
Optimizing AI models with token granularity
通过 token 粒度优化 AI 模型
One of the best things about tokens is how flexible they are. Developers can adjust the size of the tokens to fit different types of text, giving them more control over how the AI handles language. For example, using word-level tokens is perfect for tasks like translation or summarization, while breaking down text into smaller subwords helps the AI understand rare or newly coined words.
token 的灵活性体现在粒度可调,开发者可依据文本类型调整 token 尺寸,控制 AI 语言处理逻辑。翻译、摘要等任务适配单词级 token,子词拆分则帮助 AI 理解生僻或新词。
This adaptability lets AI models be fine-tuned for all sorts of applications, making them more accurate and efficient in whatever task they’re given.
该适配性使 AI 模型可针对各类应用微调,提升任务执行的精度与效率。
Enhancing flexibility through tokenized structures
通过分词结构提升灵活性
By breaking text into smaller, bite-sized chunks, AI can more easily navigate different languages, writing styles, and even brand-new words. This is especially helpful for multilingual models, as tokenization helps the AI juggle multiple languages without getting confused.
文本拆分为小片段后,AI 可轻松适配不同语言、写作风格与新词,多语言模型中该优势尤为突出,分词使 AI 稳定处理多语言信息。
Even better, tokenization lets the AI take on unfamiliar words with ease. If it encounters a new term, it can break it down into smaller parts, allowing the model to make sense of it and adapt quickly. So whether it’s tackling a tricky phrase or learning something new, tokenization helps AI stay sharp and on track.
分词还使 AI 轻松处理未知词汇,新词可拆分为小片段解析,快速完成适配。无论应对复杂语句还是学习新内容,分词均能保障 AI 稳定运行。
Making AI faster and smarter
提升 AI 运行速度与智能水平
Tokens are more than just building blocks - how they’re processed can make all the difference in how quickly and accurately AI responds. Tokenization breaks down language into digestible pieces, making it easier for AI to understand your input and generate the perfect response. Whether it’s conversation or storytelling, efficient tokenization helps AI stay quick and clever.
token 处理方式直接决定 AI 响应的速度与精度。分词将语言转化为易处理片段,简化输入解读与响应生成流程,高效分词使对话、文本创作等任务的 AI 运行更快速智能。
Cost-effective AI
实现 AI 应用的成本优化
Tokens are a big part of how AI stays cost-effective. The number of tokens processed by the model affects how much you pay - more tokens lead to higher costs. By using fewer tokens, you can get faster and more affordable results, but using too many can lead to slower processing and a higher price tag. Developers should be mindful of token use to get great results without blowing their budget.
token 是 AI 成本控制的关键要素,模型处理的 token 数量直接影响成本,token 越多成本越高。合理控制 token 用量可提升效率、降低支出,过量使用则会导致处理变慢、成本上升。开发者需管控 token 用量,在预算内实现优质效果。
Now that we’ve got a good grip on how tokens keep AI fast, smart, and efficient, let’s take a look at how tokens are actually used in the world of AI.
了解 token 对 AI 速度、智能性与效率的作用后,接下来探究其在 AI 领域的实际应用。
What are the applications of tokens in AI?
token 在 AI 领域的应用场景
Tokens help AI systems break down and understand language, powering everything from text generation to sentiment analysis. Let’s look at some ways tokens make AI so smart and useful.
token 帮助 AI 系统拆分并理解语言,支撑文本生成、情感分析等各类功能,具体应用如下:
AI-powered text generation and finishing touches
AI 文本生成与内容优化
In models like GPT or BERT, the text gets split into tokens - little chunks that help the AI make sense of the words. With these tokens, AI can predict what word or phrase comes next, creating everything from simple replies to full-on essays. The more seamlessly tokens are handled, the more natural and human-like the generated text becomes, whether it’s crafting blog posts, answering questions, or even writing stories.
GPT、BERT 等模型将文本拆分为 token 片段,辅助 AI 解析语义,预测后续单词或短语,生成简单回复至完整文章等内容。token 处理越流畅,生成的博客、问答、故事等文本越自然贴近人类表达。
AI breaks language barriers
AI 跨语言翻译
Ever used Google Translate? Well, that’s tokenization at work. When AI translates text from one language to another, it first breaks it down into tokens. These tokens help the AI understand the meaning behind each word or phrase, making sure the translation isn’t just literal but also contextually accurate.
谷歌翻译等工具依托分词技术实现功能。AI 翻译时先将文本拆分为 token,解析单词与短语的深层语义,保障翻译结果兼顾字面含义与语境准确性。
For example, translating from English to Japanese is more than just swapping words - it’s about capturing the right meaning. Tokens help AI navigate through these language quirks, so when you get your translation, it sounds natural and makes sense in the new language.
英日翻译并非单纯单词替换,需精准传递语义。token 帮助 AI 适配语言特性,使翻译结果在目标语言中自然通顺。
Analyzing and classifying feelings in text
文本情感分析与分类
Tokens are also pretty good at reading the emotional pulse of text. With sentiment analysis, AI looks at how text makes us feel - whether it’s a glowing product review, critical feedback, or a neutral remark. By breaking the text down into tokens, AI can figure out if a piece of text is positive, negative, or neutral in tone.
token 可辅助识别文本情感倾向,情感分析任务中 AI 依据 token 拆分结果判断文本为积极、消极或中性,适用于产品好评、负面反馈与中立评论等场景。
This is particularly helpful in marketing or customer service, where understanding how people feel about a product or service can shape future strategies. Tokens let AI pick up on subtle emotional cues in language, helping businesses act quickly on feedback or emerging trends.
该功能在营销与客服领域价值突出,AI 依据文本情感 cues 制定策略,快速响应用户反馈与市场趋势。
Now, let’s explore the quirks and challenges that keep tokenization interesting.
接下来探究分词技术的特点与面临的挑战。
Complexity and challenges in tokenization
分词的复杂性与挑战
While breaking down language into neat tokens might seem easy, there are some interesting bumps along the way. Let’s take a closer look at the challenges tokenization has to overcome.
语言分词看似简单,实际存在诸多难点,具体挑战如下:
Ambiguous words in language
语言中的歧义单词
Language loves to throw curveballs, and sometimes it’s downright ambiguous. Take the word “run” for instance - does it mean going for a jog, operating a software program, or managing a business? For tokenization, these kinds of words create a puzzle.
语言存在大量歧义现象,例如单词 run 可表示跑步、运行程序或管理业务,为分词带来解析难题。
The tokenizers have to figure out the context and split the word in a way that makes sense. Without seeing the bigger picture, the tokenizer might miss the mark and create confusion.
分词器需结合语境完成合理拆分,脱离整体语境易出现解析偏差,引发语义混淆。
Polysemy and the power of context
一词多义与语境依赖
Some words act like chameleons - they change their meaning depending on how they’re used. Think of the word “bank.” Is it a place where you keep your money, or is it the edge of a river? Tokenizers need to be on their toes, interpreting words based on the surrounding context. Otherwise, they risk misunderstanding the meaning, which can lead to some hilarious misinterpretations.
部分单词含义随语境变化,例如 bank 可表示银行或河岸。分词器需依据上下文解读词义,否则易出现滑稽的语义误判。
Understanding contractions and combos
缩写与复合词解析
Contractions like “can’t” or “won’t” can trip up tokenizers. These words combine multiple elements, and breaking them into smaller pieces might lead to confusion. Imagine trying to separate “don’t” into “do” and “n’t” - the meaning would be completely lost.
can’t、won’t 等缩写词易导致分词器出错,该类复合结构拆分后易丢失语义,例如 don’t 拆分为 do 与 n’t 后语义完全改变。
To maintain the smooth flow of a sentence, tokenizers need to be cautious with these word combos.
分词器需谨慎处理此类复合词,保障语句语义的完整性。
Recognizing people, places, and things
专有名词识别
Now, let’s talk about names - whether it’s a person’s name or a location, they’re treated as single units in language. But if the tokenizer breaks up a name like “Niagara Falls” or “Stephen King” into separate tokens, the meaning goes out the window.
人名、地名等专有名词在语言中为独立单元,若 Niagara Falls、Stephen King 等名称被拆分,会完全丢失原有语义。
Getting these right is crucial for AI tasks like recognizing specific entities, so misinterpretation could lead to some embarrassing errors.
专有名词解析准确对实体识别等 AI 任务至关重要,误拆分易引发明显错误。
Tackling out-of-vocabulary words
未登录词处理
What happens when a word is new to the tokenizer? Whether it’s a jargon term from a specific field or a brand-new slang word, if it’s not in the tokenizer’s vocabulary, it can be tough to process. The AI might stumble over rare words or completely miss their meaning.
分词器词汇表外的专业术语、新兴俚语等未登录词难以处理,AI 易出现识别障碍或语义误读。
It’s like trying to read a book in a language you’ve never seen before.
该场景如同阅读完全陌生语言的书籍,无法有效解读信息。
Dealing with punctuation and special characters
标点与特殊字符处理
Punctuation isn’t always as straightforward as we think. A single comma can completely change the meaning of a sentence. For instance, compare “Let’s eat, grandma” with “Let’s eat grandma.” The first invites grandma to join a meal, while the second sounds alarmingly like a call for cannibalism.
标点符号的作用并非一成不变,单个逗号可彻底改变语句语义。例如 Let’s eat, grandma 与 Let’s eat grandma 含义截然不同,前者为邀请祖母就餐,后者则存在语义歧义。
Some languages also use punctuation marks in unique ways, adding another layer of complexity. So, when tokenizers break text into tokens, they need to decide whether punctuation is part of a token or acts as a separator. Get it wrong, and the meaning can take a very confusing turn, especially in cases where context heavily depends on these tiny but crucial symbols.
部分语言的标点用法独特,进一步提升分词复杂度。分词器需判断标点为 token 组成部分或分隔符,误判会导致语义混乱,尤其在语境依赖标点的场景中问题更突出。
Handling multilingual world
多语言适配
Things get even trickier when tokenization has to deal with multiple languages, each with its structure and rules. Take Japanese, for example - tokenizing it is a whole different ball game compared to English. Tokenizers have to work overtime to make sense of these languages, so creating a tool that works across many of them means understanding the unique quirks of each one.
多语言分词难度显著提升,各语言具备独立结构与规则。例如日语分词逻辑与英语差异极大,通用分词工具需掌握各类语言的独特特性。
Tokenizing at a subword level
子词级分词
Thanks to subword tokenization, AI can tackle rare and unseen words like a pro. However, it can also be a bit tricky. Breaking down words into smaller parts increases the number of tokens to process, which can slow things down. Imagine turning “unicorns” into “uni,” “corn,” and “s.” Suddenly, a magical creature sounds like a farming term.
子词分词帮助 AI 处理生僻词与未知词,但也存在弊端。单词拆分后 token 总量增加,降低处理效率。例如 unicorns 拆分为 uni、corn、s 后,语义偏离原有含义。
Finding the sweet spot between efficiency and meaning is a real challenge here - too much breaking apart, and it might lose the context.
在处理效率与语义完整性间寻找平衡是子词分词的核心挑战,过度拆分易丢失语境信息。
Tackling noise and errors
噪声与错误数据处理
Typos, abbreviations, emojis, and special characters can confuse tokenizers. While it’s great to have tons of data, cleaning it up before tokenization is a must. But here’s the thing - no matter how thorough the cleanup, some noise just won’t go away, making tokenization feel like solving a puzzle with missing pieces.
拼写错误、缩写、表情符号与特殊字符易干扰分词器,大规模数据需先完成清洗再分词。但清洗流程无法完全消除噪声,使分词任务如同缺失碎片的拼图。
The trouble with token length limitations
token 长度限制问题
Now, let’s talk about token length. AI models have a max token limit, which means if the text is too long, it might get cut off or split in ways that mess with the meaning. This is especially tricky for long, complex sentences that need to be understood in full.
AI 模型设有 token 长度上限,文本过长时会被截断或不合理拆分,破坏语义完整性,对需完整解读的长难句影响尤为明显。
If the tokenizer isn’t careful, it could miss some important context, and that might make the AI’s response feel a little off.
分词器处理不当会丢失关键语境,导致 AI 响应出现偏差。
What does the future hold for tokenization?
分词技术的发展趋势
As AI systems become more powerful, tokenization techniques will evolve to meet the growing demand for efficiency, accuracy, and versatility. One major focus is speed - future tokenization methods aim to process tokens faster, helping AI models respond in real-time while managing even larger datasets. This scalability will allow AI to take on more complex tasks across a wide range of industries.
AI 系统性能持续提升,分词技术将向高效、精准、通用方向发展。核心优化方向为处理速度,未来分词方法可更快处理 token,支持模型实时响应与大规模数据处理,赋能各行业复杂 AI 任务。
Another promising area is context-aware tokenization, which aims to improve AI’s understanding of idioms, cultural nuances, and other linguistic quirks. By grasping these subtleties, tokenization will help AI produce more accurate and human-like responses, bridging the gap between machine processing and natural language.
语境感知分词是重要发展方向,可提升 AI 对习语、文化差异与语言特性的理解能力,使响应更精准贴近人类表达,缩小机器处理与自然语言的差距。
As expected, the future isn’t limited to text. Multimodal tokenization is set to expand AI’s capabilities by integrating diverse data types like images, videos, and audio. Imagine an AI that can seamlessly analyze a photo, extract key details, and generate a descriptive narrative - all powered by advanced tokenization. This innovation could transform fields such as education, healthcare, and entertainment with more holistic insights.
分词技术未来将突破文本范畴,多模态分词整合图像、视频、音频等数据类型,赋能 AI 完成图像解析、细节提取与文本描述等任务,为教育、医疗、娱乐等领域提供全面分析结论。
With blockchain’s rise, AI tokens could facilitate secure data sharing, automate smart contracts, and democratize access to AI tools. These tokens can transform industries like finance, healthcare, and supply chain management by boosting transparency, security, and operational efficiency.
区块链技术发展推动 AI token 应用,实现安全数据共享、智能合约自动化与 AI 工具普惠化,提升金融、医疗、供应链等领域的透明度、安全性与运行效率。
Quantum computing offers another game-changing potential. With its ability to process massive datasets and handle complex calculations at unprecedented speeds, quantum-powered AI could revolutionize tokenization, enhancing both speed and sophistication in AI models.
量子计算具备颠覆性潜力,其超高速大规模数据处理与复杂运算能力可革新分词技术,同步提升 AI 模型的运行速度与智能水平。
As AI pushes boundaries, tokenization will keep driving progress, ensuring technology becomes even more intelligent, accessible, and life-changing. The future looks bright and full of potential.
AI 技术持续突破边界,分词技术将持续推动行业发展,提升技术的智能性、普惠性与应用价值,未来发展前景广阔。
Navigating an ever-changing tokenization terrain
适应持续演进的分词技术体系
Navigating tokenization might seem like exploring a new digital frontier, but with the right tools and a bit of curiosity, it’s a journey that’s sure to pay off. As AI evolves, tokens are at the heart of this transformation, powering everything from chatbots and translations to predictive analytics and sentiment analysis.
分词技术领域如同全新数字疆域,借助合适工具与探索精神可实现显著价值。AI 发展进程中,token 是核心驱动要素,支撑聊天机器人、翻译、预测分析、情感分析等各类功能。
We’ve explored the fundamentals, challenges, and future directions of tokenization, showing how these small units are driving the next era of AI. So, whether you’re dealing with complex language models, scaling data, or integrating new technologies like blockchain and quantum computing, tokens are the key to unlocking it.
本文讲解了分词的基础原理、挑战与发展方向,展现该微型单元对 AI 新时代的驱动作用。无论是复杂语言模型、数据扩容,还是区块链、量子计算等新技术融合,token 均为核心解锁要素。
黄仁勋讲了两小时 token,中文世界终于有一个像样的译名了!
原创 拾柒年蝉 硬科普 2026 年 3 月 23 日 13:24 加拿大
一个字的翻译,关乎我们能不能真正理解 AI
前几天,英伟达创始人黄仁勋在 GTC 大会上发表主题演讲,讲了将近两个小时。
他提出了一个新词:“token 经济学”(token economics)。他说,AI 的价值,最终要用 token 来衡量——生产了多少 token,消耗了多少 token,token 的成本降到了多低。他甚至把英伟达的 GPU 集群称为"Token 工厂",意思是:我们造的不是芯片,我们造的是生产 token 的机器。
台下掌声雷动。但我相信,现场有相当一部分人,其实并没有真正听懂"token"是什么意思。
不怪他们。你注册一个 AI 产品,它会告诉你"赠送 100 万 token";你看 API 价格表,它写着"按输入输出 token 计费";你打开后台用量面板,又会看到 token usage、token limit、token cost 这些字样。这个词无处不在,却在中文世界里至今没有一个稳定的译法。有人叫它"令牌",有人叫它"词元",有人叫它"词符",更多人干脆放弃翻译,直接用英文。
这篇文章想做两件事:
第一,解释 token 到底是什么;
第二,提议一个我认为更好的中文译名——推量。
Token 是什么?
先说清楚 token 的本质。
AI 大模型处理文字,不是一个字一个字地读,也不是一个词一个词地读,而是把文本切成一个个更小的片段来处理,这个片段就叫 token。它既不能简单等于"一个字",也不能简单等于"一个词"——在中文里,一个 token 大约对应半个到一个汉字;在英文里,大约是四个字母,常见单词通常是一个 token,长词可能被拆成几个。
更重要的是,token 是大模型生成文字的最小单位,也是计费的基本单位。你问模型一个问题,它不是一口气把答案全部算出来,而是一个 token 接一个 token 地往外"推"——每次推出一个,再根据已有内容推下一个,如此循环,直到回答完毕。你有没有用过 AI 对话工具,看着回答一个字一个字地蹦出来?那个过程,就是模型在逐 token 生成。
过去,token 只是工程师后台看的东西。但现在,它正在迅速变成一种前台资源:你问一句,要消耗它;你让模型长篇输出,要消耗它;你开启深度模式、多轮对话,也要消耗它。普通人未必需要理解分词算法的内部机制,但越来越多人要面对一个现实:你在花的这种东西,到底叫什么?
现有译法,为什么都差点意思?
判断一个译名好不好,不能只看它"准不准确",更要看它能不能成为大众口语里的资源词汇——就像**“流量”**那样,让普通人一眼看出这是一种可用、可耗、可买、可比较的东西。
用这个标准来看,现有译法各有各的问题。
令牌——在技术圈里早有绑定含义:访问令牌、身份令牌、API 令牌,指的是认证凭证,和文本处理完全是两回事,容易混淆。更要命的是,"令牌"这个词太静态,像钥匙、像通行证,不像一种会被持续消耗、持续计费的资源。你很难自然地说:"这个月我用了 30 万令牌。"语法没问题,但说出口就是别扭。
词元——学术圈常用,相对准确,但太学院派,脱离大众口语。而且 token 未必对应完整的词,有时候只是词的一部分,叫"词元"容易产生误解。更根本的问题是,它没有资源感。没有人会说:"这个 app 每月送我 500 万词元。"这不是中文互联网会自然长出来的话。
不翻译,直接用 token——最常见,也最省事,但问题是:不译并不等于问题不存在。当一个词开始从开发者圈层进入大众产品场景,不译往往意味着理解门槛被转嫁给用户。长期接触"token 包"“token 额度”“token 消耗”,用户知道要花钱,但说不清自己到底在花什么。
语言不只是标签,它塑造认知。
为什么叫"推量"?
我想提议的译名,是推量。
原因有四个。
第一,音近。"推"的拼音是 tūi,和 token 同以字母 T 开头,发音上也有几分相近。好的译名往往兼顾音与义,"推量"在音上和 token 建立了联想,读者念出来时,那个呼应是自然的。
第二,义准。它抓住了 token 最核心的动作感。用户与模型交互时,最直观的感觉是:你发出一个问题,系统开始往外推答案;你让它扩写,它继续推;你开多轮对话,系统持续往前推进。大模型最可感知的运行方式,就是"推"。“推量"所表达的不是"token 在算法上是什么”,而是"用户在使用 AI 时到底在消耗什么"——推动模型持续生成的那种核心资源。
第三,类比强。“推量"的结构直接对应"流量”。移动互联网时代,普通人不需要理解 TCP/IP 协议,不需要理解手机如何上网,也会理解"流量"——因为这个词本身就传递了资源感、额度感、消费感。*“推量"同样是"动作+量"的结构,读者可以凭借对"流量"的直觉,迅速理解它的意思。过去你说"这个视频太费流量”,未来完全可以说**“这个模型太费推量”**。
第四,可扩展。“流量"催生了"流量池”“流量成本”“流量变现"一整套说法。“推量"同样可以自然扩展:推量成本、推量额度、推量套餐、推量工厂……黄仁勋说的"Token 工厂”,译成"推量工厂”,是不是顺口多了?
两套语言,并行不冲突
提出"推量",并不是要求工程师改口,也不是要取代学术术语。技术讨论里,token 可以继续叫 token;需要严谨对译的场合,"词元"也可以继续使用。
我主张的是一种分层翻译:后台术语保持专业,前台语言面向大众。开发者看的是 token、context window、input/output tokens;普通用户看到的则是推量、推量额度、推量消耗。两者并不冲突,反而彼此增益:前者保证精确,后者保证普及。
大模型不会永远只属于程序员和研究者。它会进入教育、办公、内容生产、日常搜索,进入每一个普通人都要面对的界面和账单。到那时,我们不能总是让用户在"会员"“次数”“字数”"token"之间迷迷糊糊地猜。我们需要一个更像这个时代中文的词。
也许再过几年,人们打开一个 AI 产品,不会再看到"赠送 100 万 token",而会看到一句更顺口的话:
本月赠送 100 万推量。
那时,中文世界才算真正把大模型时代的一项核心资源,翻译进了自己的日常生活。
老蝉后记:“推量”这个翻译完全是老蝉自己的原创,之前还没有看到有人这样翻译过,但不排除已经有人提出过,那就是心有灵犀了。希望“推量”这个词能在 AI 时代在中文世界流行起来。
从不 1V1 开会、不搞接班那一套,黄仁勋最新访谈:10 万个智能体造不出下一个英伟达、AGI 已实现、OpenClaw 就是 Token 时代的 iPhone
CSDN 2026年3月25日 16:44 江苏
来源 | Lex Fridman 整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
过去三十多年里,英伟达从一家做图形加速卡、甚至几度濒临破产的公司,到推出 CUDA 打开通用计算的大门,再到今天提出“AI 工厂”的概念,一路成长为全球首个市值突破 4 万亿美元的科技公司,几乎重塑了整个计算产业的底层形态。
而掌舵这家公司的,是黄仁勋——一个早年在餐厅打工洗盘子、清洁厕所,后来还差点成为了台积电 CEO 的科技领袖。
他自己曾多次坦言,如果一开始就知道这件事有多难,“可能根本不会做”。
那么问题来了——
- 当一家公司的产品,从一块 GPU,演变成一个由数十万芯片、网络、供电与冷却系统构成的“AI 工厂”时,这家公司究竟是如何被管理的?
- 当 AI 进入“拼算力”的阶段,真正的瓶颈到底是算法、数据,还是能源?
- 以及,在持续的高压决策与不确定性之中,一个人是如何支撑起这样一家公司?
近日,美国知名计算机科学家、人工智能研究员,同时也是热门播客主持人的 Lex Fridman,与黄仁勋进行了一场长达两个多小时的深度对谈。
两人从英伟达的发展历程聊起,延伸到中国、马斯克、程序员生态、AI 时代的“护城河”、太空数据中心,再到 NVIDIA 内部那种几乎“没有一对一会议、所有问题都公开讨论”的管理方式。在这家公司里,向黄仁勋直接汇报的对象多达 60 人。
期间,黄仁勋也给出了一系列观点鲜明的见解以及趋势判断:
- 英伟达是靠 GeForce 打下的江山,正是因为 GeForce,CUDA 才得以走进千家万户。
- 现在大概每六个月,就会出现一种新的 AI 模型架构。而系统架构和硬件架构,大概三年才迭代一次。所以你必须提前预判未来两三年可能会出现的技术方向。
- 有人愿意为每百万 token 支付 1000 美元的时代即将到来,这不是会不会发生的问题,而只是时间问题。
- OpenClaw 就是 Token 时代的 iPhone。
- 处理压力的方式,就是回到最本质的方式:推理
- 指望十万个智能体打造出另一个英伟达,可能性是零。
- 我觉得我们已经实现了 AGI。
- 以前全球只有 3000 万人能编程,现在这个门槛消失了,全世界 10 亿人都可以是“程序员”。
- 未来的数据中心,不应该再追求“100% 永久在线”。
- 不要因为智能的普及化、智能的商品化而感到焦虑。你反而应该为此倍受鼓舞。
至于个人,他的态度同样直接。他不信奉接班规划,而是「持续传递知识、赋能团队、提升身边每一个人的能力,因为我真正追求和期望的结果,是能工作到生命最后一刻。而且我希望能在工作中瞬间离去,不要有漫长的痛苦煎熬。」
这场对话,既是一次对英伟达过去路径的复盘,也是在试图回答一个更大的问题:当计算本身正在被重新定义时,一家公司要如何跟上,甚至提前押注未来。
YouTube 采访地址:https://youtube.com/watch?v=vif8NQcjVf0
以下是本次访谈的核心内容:
01 为什么要做“极致的协同设计”?
Lex Fridman:英伟达如今从过去专注于芯片级设计,进一步扩展到了机架级设计,你带领这家公司进入了一个全新的 AI 时代。
可以说,在很长一段时间里,英伟达的“成功之道”就是打造出最强的 GPU——而你们现在依然在这么做。但与此同时,你们的关注点已经扩展到了更极致的协同设计:不仅包括 GPU,还覆盖 CPU、内存、网络、存储、电力与散热、软件、整机机架、你们发布的 pod,甚至是整个数据中心。
那我们就来聊聊这种“极致协同设计”。在一个涉及如此多复杂组件和设计变量的系统中,最难的部分是什么?
黄仁勋:首先,之所以需要这种极致协同设计,是因为现在要解决的问题,已经无法被一台计算机、或者一块 GPU 单独加速解决了。
你面对的问题、所希望的系统性能提升,远远超过你增加的计算机数量。
假如你增加了 1 万台机器,但你希望性能提升一百万倍。
一旦进入这种规模,你就必须对算法进行重构:要把算法拆分、重新组织流水线,对数据进行分片,对模型进行分片。也就是说,你不仅仅是在“放大”问题规模,更是分散问题本身。而一旦这样做,几乎所有环节都会互相干扰。
这其实就是阿姆达尔定律(Amdahl’s Law)所描述的问题:整体加速比,取决于某一部分在总工作量中的占比。
举个例子,如果计算只占整个任务的 50%,那即便你把计算速度提升到“无限快”(比如一百万倍),整个系统的性能最多也只能提升两倍。这就意味着,你不仅要把计算本身做分布式,还得把整个处理流水线拆分开来。同时,你还要解决网络问题,因为所有这些计算机都需要互联。
在我们这个规模下的分布式计算中,CPU 是个问题,GPU 是个问题,网络也是个问题,交换还是个问题,把任务分配到这些机器上本身也是问题。
归根结底,这是一个极其复杂的计算机科学问题。所以我们必须把所有相关技术都调动起来,形成协同效应。否则的话,性能提升就只能是线性的,或者受限于摩尔定律,而大家也知道,由于登纳德缩放定律(Dennard scaling)的放缓,摩尔定律本身的推进速度其实已经明显减慢了。
02 直接管理的下属达 60 人,从来不 1V1 开会的黄仁勋是如何管理英伟达的?
Lex Fridman:这里面肯定存在各种取舍。而且你面对的是完全不同领域的协同:高带宽内存、网络、NVLink、网卡、光互连、铜缆、电源供给、散热……每一个方向都有世界级专家。那你是怎么把这些人拉到一起,共同讨论解决方案的?
黄仁勋:这就是为什么我的员工人数这么多的原因。
Lex Fridman:那具体是怎么运作的?你能不能讲讲专家和通才是怎么协作的?比如说,当你已经知道要把一整套复杂组件塞进一个机架里时,整个设计过程是怎样的?
黄仁勋:可以从三个问题进行解答。
第一:什么是“极致协同设计”?
本质上,我们是在对整个技术栈进行优化。从架构、芯片、系统,到系统软件、算法,再到应用,这是其中一层。第二层是你刚刚提到的,不只是 CPU、GPU、网络芯片、纵向扩展交换机、横向扩展交换机,还包括电力和散热,因为这些系统的功耗非常高。单台机器其实已经很高效,但规模一大,总能耗依然惊人。所以要解决的第一个问题,是“它是什么”。
第二:为什么要这样做?
这个我们刚刚也谈到了原因,你需要通过分布式,把性能提升做到远超简单堆机器的水平。
第三:怎么做到?
而这恰恰是英伟达这家公司最“神奇”的地方。要知道,你在设计一台计算机时,需要一个“操作系统”来管理它;同样,当你设计一家公司时,也应该先想清楚这家公司要生产什么。
我看过很多公司的组织架构图,它们几乎都长一个样,无外乎汉堡型组织结构图、扁平型组织结构图、汽车公司组织结构图。但在我看来,这一点都不合理。一家公司的目标,是成为一套能够产出成果的机制、体系与系统,而这份成果就是我们想要创造的产品。**公司的架构设计,也应当与它所处的外部环境相适应。**这几乎直接决定了你的组织该怎么设计。
现在公司里直接向我汇报的下属有 60 人。我基本上不会和他们 1V1 开会,因为那也不现实。
Lex Fridman:也就是说,你有 60 个直接下属。
黄仁勋:对,还不止。
Lex Fridman:而且这些人基本都有工程背景?
黄仁勋:几乎全部都是。有做内存的专家,有 CPU、光驱、GPU、架构、算法、设计……各个方向的专家都有。
Lex Fridman:所以你实际上一直在关注整个技术栈,而且不断围绕整个系统做深入讨论?
黄仁勋:是的。**而且我们的讨论从来不是一对一的,这也是我不做一对一会议的原因。我们会把问题摆出来,然后所有人一起上。**因为我们做的是“极致协同设计”,整个公司始终都在做这件事。
Lex Fridman:就算是在讨论某个具体模块,比如散热或者网络,所有人也都在旁听?
黄仁勋:对。
Lex Fridman:然后大家都可以插话,比如说:“这个方案在供电上不行”“这个对内存不友好”之类的?
黄仁勋:完全正确。当然,如果有人觉得这部分和自己无关,可以暂时不听。但团队里的每个人都知道什么时候该参与。如果本来是他们可以贡献的地方却没参与,我是会点名的。
Lex Fridman:就像你所说的,英伟达是一家会顺应环境做出调整的公司。
那么你认为,环境是从哪个节点开始发生变化,而公司又开始悄然做出转型的呢?从早期做游戏 GPU,逐渐转向深度学习,再到现在把自己定义为“AI 工厂”,这一转变是如何发生的?英伟达的业务是什么?
黄仁勋:这个过程其实可以系统性地一步步推演出来。
我们最初是一家做加速器的公司,但加速器的问题在于,它的应用场景太窄。它的优势是能针对特定任务做到极致优化,任何专精领域的产品都有这个优点。
但高度专业化的问题也很明显:市场覆盖面会变窄,不过这还不是最关键的。真正的问题在于,市场规模直接决定了你的研发能力,而研发能力最终又决定了你在计算领域能拥有的影响力和话语权。
所以,虽然我们起步时只是一家功能非常专一的加速器公司,但我们心里清楚,这只是第一步。
我们必须找到一条路,转向加速计算领域。可问题是,一旦成为通用计算公司,又会变得过于通用,反而削弱了专业优势。这两者本身就存在根本性的矛盾。我们在通用计算和专业专精之间,陷入了一种两难:计算能力做得越通用,专业优势就越弱;越是深耕专业领域,整体计算层面的拓展能力就越有限。
所以我刻意把这两个看似矛盾的方向结合在一起 —— 公司必须走出一条极其精准的道路,一步一步地扩大计算领域的布局,同时又不丢掉我们最核心的专业优势。
我们在加速之外迈出的第一步,是研发出可编程像素着色器。这是我们走向可编程化的起点,也是我们踏入计算领域的第一步。
第二步,我们在着色器中加入了 FP32 浮点运算单元。这次支持 IEEE 标准的 FP32 升级,是我们迈向计算领域的重大突破。也正是因为这一步,那些从事流处理器、数据流处理器研究的开发者们注意到了我们。
他们意识到:“突然间,这款算力极强的 GPU 居然兼容了 IEEE 标准,或许我们可以用上它。”
他们原本在 CPU 上编写的软件,现在有机会迁移到 GPU 上运行。这也推动我们在 FP32 的基础上搭建了 C 语言编程框架,也就是我们所说的 Cg 语言。
从 Cg 开始,我们一步步走到了 CUDA。
**而把 CUDA 搭载到 GeForce 显卡上,是一个无比艰难的战略决策。**这耗费了公司巨额利润,以当时的情况来看,我们根本承担不起这样的成本。但我们还是坚持这么做了,因为我们立志成为一家计算公司。
一家真正的计算公司,必须拥有自己的计算架构,而这套架构必须在我们所有的芯片产品中保持兼容。
Lex Fridman:能详细讲讲这个决定吗?当时明知道负担不起,为什么还要做?
黄仁勋:可以说,那是第一个关乎公司**“生死存亡”**的战略决策。
Lex Fridman:从结果来看,这可能是历史上最成功的公司决策之一。CUDA 成为了今天 AI 计算基础设施的核心。
黄仁勋:事实证明,这个决定是正确的。
起初我们创造了 CUDA,它大大拓宽了我们加速器所能支持的应用范围。但关键问题是,要怎么吸引开发者来用 CUDA?因为一个计算平台的生命力,完全在于开发者。
开发者不会因为一个平台能实现某个有趣的功能就慕名而来,他们选择一个平台,是因为它的用户基数足够大。毕竟开发者和所有人一样,都希望自己开发的软件能被更多人使用。
所以说,装机量才是一个架构最核心、最决定性的因素**。**哪怕这个架构饱受争议也没关系。
正如世界上没有任何一种架构受到的非议比 x86 更多,大家都说它设计不够优雅,但它恰恰成为了当今时代的主流架构。
尽管很多 RISC 架构设计精妙、理念先进,出自全球最顶尖的计算机科学家之手,最后却大多走向失败。所以这里我举了两个例子,一个设计优雅,一个甚至称不上美观,可最终活下来的是 x86。
原因就在于 —— 装机量定义架构,其他一切都是次要的。
当时市面上其实还有其他架构,CUDA 推出的时候,OpenCL 也在发展,还有好几种互相竞争的架构。但我们做对了一个关键决策:我们想明白了,最终决定成败的是装机量,而让一种全新计算架构走向世界的最好方式,就是把它装进用户最多的产品里。
那个时候,GeForce 已经大获成功。我们每年卖出数百万片 GeForce GPU。于是我们决定:把 CUDA 装进每一块 GeForce,装进每一台电脑,不管用户用不用。我们要以此为起点,慢慢积累起庞大的装机基础。
与此同时,我们开始想办法吸引开发者,我们走进大学、编写教材、开设课程,把 CUDA 推广到每一个角落。
当时 PC 还是最主要的计算载体,云计算还没出现。我们相当于把一台超级计算机,送到了每一位科研人员、每一位科学家、每一所工程院校、每一个学生的手中。我们相信,这样坚持下去,一定会发生了不起的事情。
但问题也随之而来:CUDA 大幅拉高了这款消费级 GPU 的成本,几乎耗尽了公司所有的毛利。
那时公司的市值大概在 60 亿到 80 亿美元之间。推出 CUDA 之后,我清楚这会带来巨额成本,但我们依然坚信这条路是对的。结果公司市值一度跌到只有 15 亿美元左右,我们在低谷徘徊了很久,才一点点慢慢爬回来。但我们始终没有放弃,坚持把 CUDA 搭载在 GeForce 上。
我常说,英伟达是靠 GeForce 打下的江山,正是因为 GeForce,CUDA 才得以走进千家万户。
科研人员、科学家们都是在 GeForce 上接触到 CUDA 的,他们中很多人本身就是游戏玩家,很多人习惯自己组装电脑。在大学实验室里,不少人也用 PC 配件搭建自己的计算集群。我们的故事,就是这样开始的。
Lex Fridman:然后,它就成了后来深度学习革命的基础。
黄仁勋:没错。
Lex Fridman:当时那个“生死时刻”,你还记得吗?彼时公司内部是怎么讨论的?
黄仁勋:我必须向董事会说清我们的战略意图,而管理团队也清楚,公司的毛利率会因此受到严重冲击。
试想一下这样的局面:让 GeForce 承担 CUDA 带来的额外成本,可游戏玩家既不领情,也不会为此多付钱。他们只会接受固定的价位,根本不会管你的成本是多少。
我们的成本直接上升了 50%,而当时公司的毛利率只有 35%。可想而知,这是一个多么艰难的决定。
但我们设想,未来这项技术可以应用到工作站和超级计算机上,或许在这些领域能够获得更高的利润空间。
基于这样的判断,我们才说服自己承担起这份代价。可即便如此,这一路还是走了整整十年。
Lex Fridman:但这些更多是跟董事会沟通、说服他们的过程,而我真正想问的是,在心态上,你是如何做到的?
英伟达一直在大胆押注未来,甚至可以说,不仅预判未来,更是在定义未来,尤其是现在。所以我其实是想向你请教这份智慧:作为一家企业,你究竟是如何做出这样的决策、完成这样跨越式选择的?
黄仁勋:首先,我的动力源于强烈的好奇心。在某个时刻,我构思的一套完整的逻辑会让我无比确信:这件事一定会发生,这样的未来一定会到来。我从心底里坚信这一点。
这中间固然会经历无数煎熬,但你必须坚守自己的判断。然后你会一步步推演实现路径,论证它为什么必然会出现。我们整个团队都是这么思考的,我和管理团队会花大量时间去反复推演、论证。
接下来这一点,大概算是一种领导能力。很多领导者的做法是:平时不动声色,自己默默研究,然后到了新一年,突然抛出一份宣言,推出全新计划。紧接着这边开始大规模裁员,那边大刀阔斧调整组织架构,再换个新使命、新 LOGO,诸如此类。
我们从来都不是这样,我也绝不会这么做。
当我接触到新事物,它开始改变我的想法时,我会立刻明确地告诉身边所有人:这个方向很重要,它会带来变革,会影响行业格局。我会一步一步地把逻辑讲清楚。
很多时候我其实已经下定决心,但我会抓住一切机会——外部信息、新的洞察、技术突破、工程进展、关键里程碑——用这些事实去逐步塑造大家的认知与信念。我几乎每天都在做这件事,对董事会、对管理团队、对全体员工,都是如此。
我一直在潜移默化地构建大家的共识,这样等到某天我说出“我们收购 mellanox 吧”,所有人都会觉得理所当然、势在必行。
当年我说出“各位,我们全力投入深度学习”的时候也是一样,我早已在公司各个部门埋下伏笔,一点点铺垫。大部分员工或多或少都听过相关的思考,所以当我正式宣布时,大家其实已经在不同层面上认同了。
在很多时候,我甚至希望员工们会说:“Jensen,你怎么才宣布?”事实上,我早就花了很长时间塑造大家的认知。这种领导方式,看上去像是后发制人,但其实是提前引导,直到宣布那一刻,所有人都能百分百认同。
而这正是你想要的效果——带着所有人一起前进。
不然的话,你突然宣布全力做深度学习,所有人都会一头雾水:“你在说什么?”
你突然说要全力投入某个方向,管理层、董事会、员工、客户都会一脸茫然:“这个想法是哪儿来的?”
他们只会觉得这太疯狂了。所以还有 GTC 大会的作用。回头看历年的主题演讲,我其实也在同步塑造行业伙伴的认知,再用他们的认同反过来影响我们自己的员工。
等到我正式宣布某项战略时,比如我们之前发布 Grok,其实我已经铺垫了整整两年半。你回头去看就会发现:天啊,他们两年半前就开始不断提及相关布局了。
我就是这样一步一步打好基础,等到正式宣布的那天,所有人都会觉得:“你怎么才官宣啊?”
Lex Fridman:但这不仅限于公司内部。你在塑造整个格局,整个全球创新的大格局。你把这些理念传播出去,其实就是在亲手创造现实。
黄仁勋:我们不造计算机,也不建云平台。说到底,我们是一家计算平台公司。
有意思的是,没人能直接“买走”我们的东西。我们做垂直设计、垂直整合,只为把产品做到最优,但随后我们会把整个平台全方位开放,让其他公司可以把它整合进自己的产品、服务、云平台、超算和 OEM 设备中。
所以奇妙的地方就在这里:如果我不能先说服他们,我就什么都做不成。
GTC 大会的大部分意义,就是在描绘一个未来。等到我们的产品真正就绪时,他们只会说:“你怎么才拿出来?”
03 训练的瓶颈不再是数据,而是算力
Lex Fridman:你一直以来都非常相信“规模法则”(广义上的 Scaling Laws)。那现在你依然这么看吗?
黄仁勋:是的,而且现在不止一个规模法则了,我们有好几个。
Lex Fridman:我记得你提到过四种:预训练、后训练、推理,以及智能体扩展。从长远和短期来看,有哪些问题是你最担心、甚至会让你睡不着觉的?
黄仁勋:我们不妨回头看看,曾经人们认为的那些瓶颈到底是什么。
一开始,大家都在讨论预训练的 Scaling Laws。当时大家普遍认为,我们拥有的高质量数据总量,会限制 AI 最终能达到的智能水平,这个 Scaling Laws 确实至关重要:模型越大,就需要对应更多的数据,才能训练出更聪明的 AI。这就是预训练阶段的逻辑。
后来 Ilya Sutskever 说了类似“我们已经没有数据了”、“预训练时代已经结束”这样的话,整个行业都陷入了恐慌,觉得人工智能走到头了。但事实显然并非如此。
我们还会持续扩大训练所用的数据规模,其中很大一部分将会是合成数据,这一点也曾让很多人困惑。大家没有意识到,甚至已经忘记了:我们人类彼此学习、相互传递信息所依靠的大部分知识,本质上都是“合成”的。它并非天然存在,而是由人创造出来的。我接收它、修改它、扩充它、重构它,再由别人继续使用。如今 AI 已经发展到这样的水平:它可以基于真实数据,进行增强、优化,并用合成方式生成海量的数据。
这部分后训练阶段的规模还在不断扩大。未来,人类原生数据在训练中的占比会越来越小,模型训练所使用的数据总量会持续扩张,直到我们不再受限于数据——训练的瓶颈不再是数据,而是算力。原因很简单:大部分数据都会是合成数据。
接下来就到了推理阶段。我还记得当时很多人跟我说:“推理?那很简单啊,难的是预训练。”大家都觉得那么庞大的系统都搞定了,推理肯定小菜一碟。
于是有人断言,推理芯片只会是小芯片,跟英伟达的芯片完全不一样,未来推理会是最大的市场,但门槛很低,会走向商品化,谁都能造自己的芯片。但对我来说,这种逻辑从一开始就站不住脚。
**因为推理就是思考,而思考从来都不简单。**思考远比单纯的阅读要难得多。
预训练本质上只是记忆与泛化,是从数据中寻找模式与关联,只是不断地“阅读”。而推理是思考、是逻辑推演、是解决问题,是面对从未见过的全新场景,把它拆解成可解决的问题,再通过第一性原理、过往经验,或是探索、试错、搜索来寻找答案。
整个推理阶段的缩放过程,本质上就是思考。它涉及推演、规划、搜索、决策……
这样的过程怎么可能只需要很少的算力?而我们在这一点上完全判断正确:推理阶段的算力需求是极其密集的。
那么问题来了,现在我们走到了推理与推理缩放的阶段,接下来还会有什么?
很明显,我们已经造出了智能体,一个拥有大语言模型的独立智能个体。在推理阶段,这个智能体可以自主开展研究、查询数据库、使用工具,而它最重要的能力之一,就是衍生出大量子智能体。
这意味着我们现在需要打造庞大的团队。对英伟达来说,通过招聘员工来扩大规模,远比只靠我一个人容易得多。
所以下一个 Scaling Law,就是 Agent Scaling Law。它相当于让 AI 实现自我复制,我们可以随心所欲地生成更多智能体。
我总结了四个 Scaling Law。随着智能体系统的应用,它们会产生更多数据、更多经验。其中一些成果会让我们觉得:“这太棒了,我们应该把它记住。”
这些数据会重新回流到预训练阶段,我们对其进行记忆与泛化,再通过后训练做精调与优化,接着在推理阶段进一步提升,最后由智能体系统推向整个行业。这样的循环会不断持续下去。
归根结底,智能的扩张最终只取决于一样东西——那就是算力。
Lex Fridman:但这里面有个难点,需要你提前预判:有些技术模块,必须用专门的硬件才能做到最优效果。所以你必须提前看清 AI 创新的未来方向。比如稀疏混合专家模型(MoE)就是一个典型例子。
而硬件不像软件,不能一周内就调整方向。这听起来非常困难、甚至有点太难做了,对吧?
黄仁勋:现在大概每六个月,就会出现一种新的 AI 模型架构。而系统架构和硬件架构,大概三年才迭代一次,所以你必须提前预判未来两三年可能会出现的技术方向。
要做到这一点,有几种方法。
首先,我们自己会开展内部研究,这也是我们布局基础研究和应用研究的原因之一。我们自主研发模型,亲身体验模型研发的全过程。这正是我前面说的“协同设计”的一部分。
其次,我们也是全球唯一一家与全世界所有 AI 企业都有合作的公司。在能力范围内,我们会尽力去了解行业从业者正在面临的各种挑战。
第三点是构建一个足够灵活的架构,能够适应变化、顺应潮流。比如 CUDA,它一方面是一个极其强大的加速平台,另一方面又非常灵活。这种“专用性”和“通用性”的平衡非常关键:既要足够专用,才能实现加速;又要足够通用,才能适应不断变化的算法。这也是 CUDA 能长期保持生命力的原因。
我们现在已经做到 CUDA 13.2,持续快速演进,以适配最新算法。举个例子,当“混合专家模型”(MoE)出现时,我们推出了 NVLink 72 代替了 NVLink 8。如今我们可以把一个 4 万亿、10 万亿参数的完整模型放在同一个计算域中,就像它只在一块 GPU 上运行一样。
大家可能没留意我这句话的分量,但如果你看看 Grace Blackwell 机架的架构就会发现,它从头到尾只专注一件事——处理大语言模型。
而仅仅一年之后,你再看 Vera Rubin 机架:它搭载了存储加速器,配备了名为 Vera 的全新超强 CPU,还集成了 Vera Rubin 芯片和 NVLink 72,专门用来运行大语言模型。
除此之外,它还新增了一种名为 Rock 的机架。
整套机架系统和上一代完全不同,里面集成了各类全新组件。原因在于:上一代架构是为运行稀疏混合专家大语言模型(MoE)的推理而设计的,而这一代,则是为智能体打造的——智能体需要频繁调用工具、进行复杂操作……
Lex Fridman:但这些设计,是在 Claude Code、Codex、OpenClaw 出现之前就完成的。也就是说,你们提前预判了未来?
黄仁勋:其实没那么复杂,你只要靠逻辑推演就能明白。
首先,你只需要去推理就行。不管未来怎么变,想要让大语言模型成为数字员工,它必须做什么?
它必须访问真实数据,也就是我们的文件系统。它必须会做研究,因为它不可能什么都知道。我也不想等到 AI 通晓过去、现在、未来一切知识之后,才让它发挥用处。所以很明显,它必须自己去做研究。
如果它想帮我,就必须使用我现有的工具。
很多人会说:“AI 会彻底颠覆软件行业,我们不再需要软件,不再需要工具了。”这很荒谬。
我们不妨做个思想实验,你只要坐着,喝杯威士忌,好好想一想,答案就会非常清晰。假设未来 10 年,我们造出了最厉害的智能体,比如人形机器人。
你觉得更可能的是实现下面哪种情况:
- 是这个机器人走进我家,使用我现有的工具完成工作?
- 还是它的手一会儿变成 10 磅重的锤子,一会儿变成手术刀,想烧水的时候就从手指发射微波?
- 还是它更可能直接用我家的微波炉?
它第一次用微波炉的时候,很可能也不会用。但没关系,它连着互联网,它可以阅读说明书,读完立刻就变成专家,然后正常使用微波炉。
我刚才描述的这些特点,其实几乎就是 OpenClaw 的全部设计理念。它会使用工具,会访问文件,会开展研究,拥有完整的 I/O 子系统。
当你这样一步步推演完,你就会意识到:天啊,这对未来计算的影响极其深远。
因为在我看来,我们相当于重新发明了计算机。
你可能会问,我们是什么时候开始思考这一切的?什么时候开始构思 OpenClaw 的?
如果你去看我在 GTC 大会上展示的 OpenClaw 架构图,你会发现,两年前我就已经画出来了。真的,两年前的 GTC 上,我讲的智能体系统,就和今天的 OpenClaw 完全一致。
当然,这中间需要很多条件成熟起来:
- 首先,Claude、GPT 这些模型必须达到相应的能力水平,它们的创新、突破与持续进步至关重要。
- 其次,必须有人做出一个足够健壮、足够完整的开源项目,让整个行业都能用起来。
我认为,OpenClaw 对于智能体系统的意义,就像当年 ChatGPT 对于生成式 AI 的意义一样。这绝对是一件划时代的大事。
Lex Fridman:确实,这是一个很特别的时刻。虽然不太清楚为什么它比 Claude Code、Codex 更出圈。
黄仁勋:因为普通用户也能用。
Lex Fridman:对,还有一部分原因是“氛围”和人本身的影响力。但与此同时,也有很多安全问题:这么强大的技术,如何在“有用”和“安全”之间找到平衡?
黄仁勋:我们第一时间就介入了,派了很多安全专家参与,并推出了 OpenShell,现在已经整合进 OpenClaw。
Lex Fridman:NVIDIA 还推出了 NemoClaw。
黄仁勋:对。
Lex Fridman:安装很简单,而且强调安全性。
黄仁勋:我们为你提供三项权限中的两项。智能体系统可以访问敏感信息,可以执行代码,也可以对外通信。我们只要在任意时刻开放其中两项功能,就能保证安全,而不会三项全部开放。
在这两项权限的基础上,我们还会根据企业授予你的权限提供访问控制,然后把它连接到这些企业已经在使用的策略引擎上。我们会尽最大努力帮助 OpenClaw 变得更加完善。
04 AI Scaling Law 面临的最大障碍
Lex Fridman:刚才你条理清晰地阐述了,我们过去曾遇到过许多自以为会成为瓶颈的障碍,但最终都一一克服了。但放眼未来,如今智能体显然会无处不在,你认为当下可能成为瓶颈的会是什么?很明显我们会需要算力,那么阻碍这种扩张的因素将会是什么?
黄仁勋:能源电力确实是个值得关注的问题,但并非唯一问题。这也是我们全力推进极致协同设计的原因,这样我们才能每年都把每瓦功耗每秒生成的 Token 数提升数个数量级。
过去十年里,摩尔定律让计算性能提升了大约一百倍,而我们通过扩展让计算性能提升了一百万倍。我们会通过极致协同设计继续保持这样的速度。能效、每瓦性能,会直接影响一家公司的营收,也会影响数据中心的收益。我们会把这一点做到极限,尽可能持续压低 token 成本。
我们的计算机价格在上涨,但 token 生成效率的提升速度要快得多,因此 token 成本一直在下降,几乎每年都会下降一个数量级。
Lex Fridman:关于电力这一点很有意思。所以应对功耗瓶颈的方法,是不断优化“每秒每瓦特生成的 Token 数”,让它变得越来越高效。当然,这里还有一个问题:我们该如何获取更多的电力供应?
黄仁勋:没错,我们也确实需要获取更多的电力。
05 供应链
Lex Fridman:这是一个极其复杂的话题。你曾谈论过小型模块化核反应堆,关于能源也有各种各样的设想。但关于 AI 供应链的瓶颈,比如 ASML 的 EUV 光刻机、台积电的 CoWoS 这样的先进封装技术,还有 SK 海力士的高带宽内存(HBM),这些问题会让你焦虑得睡不着觉吗?
黄仁勋:我们一直在为此努力,从未停歇。历史上从未有哪家公司能以我们这样的规模实现增长,同时还在不断加快增长速度,这一点令人难以置信,也很难被人们理解。
在整个 AI 计算领域,我们的市场份额还在持续提升。因此,上下游供应链对我们至关重要。
我花费大量时间与合作的各位 CEO 沟通,告诉他们哪些行业动态会推动增长持续甚至加速。这也是为什么我右手边坐着的,几乎是整个 IT 行业上游和整个基础设施行业下游的企业负责人。
GTC 现场有几百位 CEO,我认为从未有哪场主题演讲能吸引到数百位首席执行官到场。一方面,我向他们介绍我们当前的业务状况,分享近期的增长动力与行业趋势,同时也阐述我们未来的发展方向,让他们可以依据这些信息和行业动态来制定投资决策。我向他们传递信息的方式,和我对自己员工的沟通方式是一样的。
之后我还会亲自拜访他们,跟他们明确说:“你们要知道,这个季度、未来一年、接下来两年,行业会发生这些变化。”
你可以看看 DRAM 行业的那些企业负责人。过去全球最主流的 DRAM,是数据中心 CPU 用的 DDR 内存。大约三年前,我就说服了其中几位负责人,尽管当时 HBM 内存的应用还非常少,只有超级计算机会少量使用,但未来它一定会成为数据中心的主流内存。
一开始这听起来很荒唐,但有几位负责人相信了我,并决定投资研发和生产 HBM 内存。
还有一种内存用在数据中心里显得很特别,就是我们手机里使用的低功耗内存。我们希望他们对这种内存进行适配,用在数据中心的超级计算机上。他们当时的反应是:“给超级计算机用手机内存?”
然后我向他们解释了背后的原因。如今你再看这两种内存,LPDDR5 和 HBM4,市场规模大得惊人。相关企业都创下了历史最佳业绩,而这些都是有着四十五年发展历程的公司。所以说,这也是我工作的一部分,去传递判断、引导方向、激发行业的信心。
Lex Fridman:所以你不仅是在构思未来并激励英伟达的工程师,你还在亲手勾勒未来的供应链。你在和台积电、ASML 深度对话。
黄仁勋:贯穿上游和下游。还有像通用电气、Caterpillar 这些,它们算我们的下游。
Lex Fridman:没错,是一整个生态。但整个半导体行业涉及的工程技术极其艰难,供应链如此错综复杂,组件如此之多,想想都觉得有点后怕。但神奇的是,它居然运转得很好。
黄仁勋:没错,这背后就是深度科学。深厚的工程技术,顶尖的制造工艺,而且如今大部分制造环节都已经实现了机器人自动化。我们有几百家供应商,为我们拥有 130 万个零部件的机架提供技术支持。每个机架包含 130 万到 150 万个零部件,Vera Rubin 机架的供应商就有 200 家。
Lex Fridman:很有意思,你并没有把这些列为让你“彻夜难眠”的阻碍因素。
黄仁勋:因为我已经在做所有必要的准备工作来应对它了……
我能睡个安稳觉,是因为我已经把这些待办事项勾掉了。我会想:“好吧,让我们来推演一下,对我们来说什么才是重要的?”
因为我们把系统架构从你记得的最初的 DGX-1 升级到了 NVLink-72 机柜级计算——这意味着什么?对软件、对工程意味着什么?对我们的设计和测试方式意味着什么?对供应链又意味着什么?
其中一个变化是:我们将超级计算机的集成工作,从数据中心现场搬到了供应链的制造环节。
如果你要这么做,你就得意识到……假设你想建造一个拥有 50 吉瓦算力的超级计算机集群并让它们同步运行,而制造这 50 吉瓦的设备需要一周时间。那么在供应链端,每周测试这些超级计算机就需要 1 吉瓦的电力。所以,我需要供应链在发货前,就有足够的能力来增加电力供应,完成制造和测试。
NVLink-72 实际上是在供应链中就把超级计算机造好,然后每次以两三吨的重量整机架发货。过去都是零件分开运输,我们再在数据中心内部组装,但现在已经不可能这样做了,因为 NVLink-72 的集成度太高。
这就是一个典型的例子。
我需要亲自飞到供应链一线,去见我的合作伙伴,跟他们说:“你知道吗,我打算这么做……我们之前是这样制造 DGX 服务器的,以后我们要换一种方式。这种新方式会好得多,因为我们需要用它来做推理。”
推理市场正在到来,拐点即将出现,这会是一个巨大的市场。我首先向他们说明当前的形势,以及为什么这一切会发生,然后请他们每家都进行数十亿美元的资本投资。
因为他们信任我,而我也非常尊重他们。我给他们充分的机会向我提出疑问,花时间向大家解释,用逻辑进行推演。我会画图,用第一性原理一步步分析。每次和他们沟通结束之后,他们就清楚自己该做什么了。
Lex Fridman:看来很大程度上关乎人际关系和建立对未来的共识。但你真的不担心某些具体的瓶颈吗?比如 ASML 的 EUV 工具?或者台积电 CoWoS 封装的扩张速度?就像你说的,你们不只是在飞速增长,而是在加速增长。感觉供应链上的每个人都必须跟着加速,你有没有催促他们:“你们能不能扩产得再快点?”
黄仁勋:一直在催。
Lex Fridman:那你担心吗?
黄仁勋:不担心。因为我已经告诉了他们我的需求,他们也理解了,并且给了我承诺。我相信他们会做到的。
06 电力
Lex Fridman:很有意思,这一点很好。那我们不妨多聊聊“电力”这个问题。你对解决能源问题有什么期待?
黄仁勋:有一个我特别希望大家能关注的问题,也希望借这个机会把它讲清楚。现在的电网,其实是按“最极端情况”来设计的,还会留出一定冗余。但问题是,**99% 的时间里,我们根本达不到那个极端负载。**真正的“最坏情况”,通常只出现在冬天或夏天的几天,以及极端天气时。
绝大多数时间里,我们的用电大概只在峰值的 60% 左右。
也就是说,在 99% 的时间里,电网其实是“富余”的,有大量电力闲置在那里。但这些电力又必须随时待命,因为一旦出现极端情况,医院、基础设施、机场等关键系统必须优先供电。
所以我的问题是:我们能不能换一种方式?
比如,通过更合理的合同机制,以及更智能的数据中心和计算架构设计,让电网在需要保障社会关键基础设施时,数据中心可以主动“让出”一部分电力。
但这种情况其实非常少见。在极端情况下,我们可以用备用发电机顶上,或者把计算任务调度到别的地方,甚至可以让计算“降速运行”。比如,我们可以降低性能、减少功耗,让响应时间稍微变长一点。
所以我认为,**未来的数据中心,不应该再追求“100% 永久在线”。**现在的这些合同非常严格,反而给电网带来了巨大压力——因为电网必须不断扩容来满足这种要求。
但我真正想要的,其实只是利用那部分“本来就在闲置”的电力。
Lex Fridman:这个问题确实很少被讨论。那阻碍是什么?是监管,还是官僚体系?
黄仁勋:我觉得这是一个“三方问题”。
首先是最终客户。客户对数据中心提出了几乎“永不宕机”的要求,也就是说,他们追求的是“绝对完美”。为了实现这一点,你就需要备用发电机和电网一起提供“完美级”的保障。于是,每一方都在追求“六个 9”(99.9999% 可用性)。
但问题是,这些要求很多时候并没有被真正理解。很多企业的 CEO,可能根本不知道这些合同细节。我打算去和更多 CEO 聊这个问题。
现实情况是:合同是由下面的团队去谈的,双方谈判者都希望拿到“最优条件”。于是,云服务商(CSP)就会把同样的高要求传导给电力公司,要求它们也提供“六个 9”的可靠性。所以第一步,是让所有客户和 CEO 意识到,他们到底在要求什么。
第二步,是我们要建设“可优雅降级”的数据中心。如果电网说:“我们只能给你 80% 的电力”,我们应该能说:“没问题。”我们可以动态调度任务,保证数据不丢失,同时降低计算速率、减少能耗。服务质量会略有下降,但关键任务可以立即迁移到其他数据中心,继续保持 100% 可用。
Lex Fridman:这种“动态调度电力”的能力,从工程角度来看有多难?
黄仁勋:只要你能把问题定义清楚,就可以把它工程化解决。只要符合物理定律,我们就能做出来。
Lex Fridman:你刚才说的第三点是什么?
黄仁勋:第二点就是数据中心。第三点是我们需要电力公司也认识到这是一个机遇——不要只是说“要提升电网容量需要五年时间”,如果你们愿意提供这种级别保障的电力,我们下个月就能按这个价格给你们供应。
所以如果电力公司也能提供更多类型的电力交付承诺,我相信大家都知道该怎么利用。
但是目前电网的浪费实在太严重了,我们必须解决这个问题。
07 马斯克和他的 Colossus 超级计算机
Lex Fridman:你曾高度赞扬过 Elon Musk 和 xAI 在孟菲斯建设的 Colossus 超级计算机。他们在短短四个月内完成建设,现在规模已经达到 20 万块 GPU,而且还在快速增长。
对于整个行业来说,你觉得他的做法有哪些值得借鉴的地方?无论是工程方法,还是建设管理?
黄仁勋:首先,埃隆·马斯克深入钻研着众多不同领域,同时他也是一位非常出色的“系统级思考者”。
他能够跨越多个学科进行思考,而且他显然会推动事物向前,对一切提出质疑:
第一,这件事是否必要?
第二,必须要用这种方式完成吗?
第三,真的需要花费这么长时间吗?
他有能力对一切提出质疑,直到所有环节都精简到最必要的程度,再也无法删减,同时产品的核心功能依然保留。他是你能想象到的极致极简主义者,而且是在系统层面做到这一点。
另外我也很欣赏他的一点是,他始终亲临一线。
哪里有问题,他就会直接去到那里,然后说:“给我看看问题所在。”
当你把这些特质结合起来,就能打破很多固有的思维定式,比如“我们一直都是这么做的”、“我在等他们处理”之类的借口,每个人都有太多借口。
最后一点,当他自己以极高的紧迫感行动时,也会带动所有人都紧迫起来。
每家供应商都有很多客户和项目在推进,而他会通过实际行动,让自己成为所有人项目中的最高优先级。
Lex Fridman:我参加过一些类似的会议,看着很有意思。因为很少有人会不断追问:“这件事能不能更快?为什么一定要这么久?”而一旦你深入到实际流程,比如我记得有一次,他甚至在研究“机架里插线缆”这种具体操作,和一线工程师一起分析,看看怎么降低出错率。
当你从每一个细节去理解整个系统——从微观到宏观——你就能快速发现低效之处,并不断优化。
再加上你有能力直接拍板:“我们换一种完全不同的方式来做”,就可以去掉所有阻碍。
黄仁勋:没错,就是这样。
08 黄仁勋的工程哲学与领导力
Lex Fridman:在英伟达这种“极致系统协同设计”的方法论中,你是否看到了与埃隆·马斯克处理系统工程方式的相似之处?
黄仁勋:首先,协同设计本质上是一个终极的系统工程问题。我们正是从这个第一性原理出发来开展工作的。
我们做的另一件事,是一种理念,一种思维方式,也是我三十年前就开始采用的方法,我称之为「光速法则」。
光速法则不只是关于速度,它是我用来指代物理极限的简捷说法。我们所做的每一件事,都要和光速法则做对比:内存速度、运算速度、功耗、成本、时间、人力、制造周期……
当你在权衡延迟与吞吐量、成本与吞吐量、成本与容量时,所有这些维度都要用光速法则来检验,分别满足各类约束条件。而当你把它们综合考量时,就必须做出取舍——因为超低延迟的系统,和低成本、高吞吐量的系统,在架构上有着本质区别。
但你必须清楚:追求高吞吐量的系统,它的物理极限在哪里;追求低延迟的系统,它的物理极限又在哪里。只有这样,在设计整个系统时,你才能做出合理的权衡。
所以我要求所有人,在做任何事之前,都先思考第一性原理,思考一切事物的物理极限,并用这个极限来检验所有方案。
这是一种很好的思维框架。
我并不推崇另一种方法,那就是持续改进。持续改进的问题在于:你应该先以第一性原理和光速思维去设计产品,只受物理定律的限制,在此基础上再逐步优化。
但我不喜欢面对一个问题时,有人说:“现在这个流程需要 74 天,我们可以帮你做到 72 天。”
我宁愿把一切归零,然后说:“首先告诉我,为什么一开始需要 74 天?我们先看当下理论上最快能做到多少。如果从头完全重新设计,需要多久?”
很多时候结果会让你大吃一惊,可能只需要 6 天。剩下的 68 天,往往是各种合理的妥协、成本考量、流程折中等等。但至少你知道这些额外时间花在了哪里。
一旦你知道 6 天是可以实现的,那么从 74 天优化到 6 天的讨论,就会变得高效得多。
Lex Fridman:在面对如此复杂的系统时,“简洁性”有时会是一个好的引导准则吗?我是说,你发布的那个 Vera Rubin Pod 计算集群简直令人难以置信。它包含 7 种芯片类型、5 种定制机柜、40 个机柜、1.2 万亿亿个晶体管、近 2 万个英伟达裸片、超过 1100 颗 Rubin GPU、60 Exaflops 的算力,以及每秒 10 PB 的扩展带宽。而这仅仅是一个 Pod。
甚至仅仅是一个 NVL72 机柜,就塞进了 130 万个组件、1300 颗芯片,4000 个计算节点(Pods)都被挤进了一个 19 英寸宽的机柜里。
黄仁勋:Lex,为了让你有个直观的概念,我们每周可能需要生产大约 200 个这样的 Pod。
Lex Fridman:面对这么多不同的组件,我觉得“简洁”几乎是不可能的,但在设计过程中,这是否仍是你追求的一项指标?
黄仁勋:我最常说的一句话是:**“我们需要事物在必要时尽可能复杂,但在可能时尽可能简洁。”**所以问题在于,现有的这些复杂性全都是必要的吗?我们必须对此进行测试和挑战。除此之外,任何多余的复杂性都是多此一举。
Lex Fridman:但这依然近乎神迹。放眼整个半导体行业,英伟达目前所做的可以说是历史上最伟大的工程成就之一。这些系统真实地展现了工程学的奇迹。
黄仁勋: 这是世界上制造过的最复杂的计算机。
Lex Fridman:是的,那些工程团队……我不想挑起竞争,但我真的不知道该怎么比。如果工程界有奥林匹克竞赛,台积电当然很强,ASML 在各个尺度上也都极具统治力,但英伟达绝对是他们的劲敌。你们的团队太不可思议了。
黄仁勋:这么说吧,我们这里集结了每一个垂直领域的“奥运金牌得主”。
09 中国与“开发者大国”
Lex Fridman:还要让这些团队协同工作,并直接向你汇报。这太了不起了。你最近刚去了中国。中国在构建科技产业方面取得了惊人的成功,这让我很想请教你:在你看来,中国在过去 10 年里是如何做到建立起这么多世界级的公司、世界级的工程团队,以及这种能产出如此多优秀产品的技术生态系统的?
黄仁勋: 原因有很多。首先,让我们从一些事实开始:全球大约 50% 的 AI 研究人员是华人,而且他们中的大多数目前仍在中国。虽然我们这里(美国)也有很多,但中国依然保留着大量顶尖的研究人才。
其次,他们的科技产业崛起于一个精准的时机。在移动云计算时代,他们贡献力量的方式主要是软件。中国拥有极其出色的科学和数学教育背景,培养了一大批高素质的年轻人。他们的科技产业是在软件时代建立起来的,因此他们对现代软件非常熟悉。
此外,中国并不是一个单一的经济体。它拥有许多省份和城市,各地的市长都在互相竞争。这就是为什么中国有这么多电动汽车公司、这么多 AI 公司,以及你能想象到的任何领域的公司。这种内部的“疯狂竞争”筛选出了那些极其强大的幸存者。
他们还有一种社会文化:家庭第一,朋友第二,公司第三。因此,人们之间的交流非常频繁——他们本质上一直处于一种“全员开源”的状态。
正因此,他们对开源社区的贡献如此之大,是非常合理的。他们可能会想:“我们有什么好保密的?”我的工程师,他们的兄弟可能在另一家公司,朋友在第三家公司,大家都是同学——这就是所谓的“同学”概念。一旦是同学,就是一辈子的兄弟。因此,他们分享知识的速度极快。既然没必要把技术藏着掖着,不如直接放到开源社区。而开源社区反过来又放大并加速了创新进程。
所以,**优秀的人才、开源驱动的快速创新、深厚的友谊纽带,再加上残酷的竞争,这些因素共同促成了伟大成果的诞生。**中国是当今世界上创新最快的国家。我提到的这些都是基础:优秀的教育、望子成龙的父母、独特的文化。他们正好在技术呈指数级增长的时刻登场了。
Lex Fridman:从文化角度来看,当一名工程师是很酷的事情。这把你提到的所有因素都串联起来了。
黄仁勋:这是一个“开发者大国”(Builder Nation)。我们国家的领导人非常优秀,但大多是律师,他们的职责是维护法治、保护安全。而中国是从贫困中走出来的,所以他们的许多领导人本身就是极其出色的工程师,拥有最聪明的头脑。
Lex Fridman:稍微岔开一下,既然提到了开源,我得提到我一直支持的 Perplexity,我知道你也是它的老用户。
也要感谢你们发布了开源的 Nemotron 3 Super,现在大家可以在 Perplexity 里用它来查资料。这是一个拥有 1200 亿参数的开源权重混合专家模型(MoE)。你对开源的愿景是什么?你提到了中国的 DeepSeek、MiniMax 等公司在推动开源 AI 运动,而英伟达也在引领近乎 SOTA(最前沿)水平的开源大模型。
黄仁勋:首先,如果我们想成为一家伟大的 AI 计算公司,就必须理解 AI 模型是如何演进的。
我喜欢 Nemotron 3 的一点是,它不只是纯粹的 Transformer 模型,还结合了 SSM(状态空间模型)。我们在早期开发了条件 GAN(生成对抗网络),一步步演化到了扩散模型(Diffusion)。
我们在模型架构和不同领域进行的这些基础研究,让我们能够洞察:什么样的计算系统能更好地服务于未来的模型。这就是我们“极致协同设计”战略的一部分。
其次,我们认识到:一方面,我们希望有世界级的模型作为产品,它们应当是闭源私有的;但另一方面,我们也希望 AI 能普及到每一个行业、每一个国家、每一个研究者和学生手中。如果一切都是闭源的,就很难在此基础上进行研究和创新。
开源是许多行业加入 AI 革命的根本前提。英伟达拥有足够的规模、技术和动力,去持续构建这些 AI 模型。通过开源,我们可以激活每一个研究者和每一个国家。
还有第三个原因:AI 不仅仅是语言。这些 AI 可能会调用在其他模态数据上训练的模型,比如生物学、化学、物理定律、流体力学或热力学。这些东西并不完全具备语言结构。
我们不造车,但我们想确保每家车企都能用上伟大的模型;我们不研发药物,但我希望确保像礼来(Lilly)这样的公司拥有世界上最好的生物 AI 系统。这就是为什么我们要参与 AI 协同设计,并让所有人都能进入这个世界。
10 曾差点成为了台积电的 CEO
Lex Fridman:这真的太不可思议了。你和台积电关系密切。所以我必须问问,台积电的工程团队和他们所做的顶尖工程工作,也让这家公司成为了传奇。你如何看待台积电的企业文化与做事方式,能解释他们为什么能在半导体领域取得如此独一无二、无人能及的成功吗?
黄仁勋:首先,外界对台积电最深的误解就是,以为他们只靠技术立足。好像他们只是拥有优秀的晶体管,一旦别人做出更好的晶体管,游戏就结束了。当然,我所说的技术不只是晶体管,还包括金属互连系统、封装技术、3D封装、硅光子技术等等所有相关技术。正是这些技术让台积电与众不同。
但他们真正厉害的,**是统筹全球数百家企业动态需求的能力。**这些需求时刻都在变化:产能上调、下调、延后、提前,不同客户之间来回调整,晶圆开始生产、暂停生产、紧急投产……整个世界的格局一直在变,需求复杂多变,而他们却能运营着高吞吐量、高良率、低成本、优质客户服务的工厂。他们非常信守承诺。
因为他们明白自己是在帮助你运营公司,所以只要承诺了晶圆交付时间,就一定会如期交货,让你可以正常运转自己的业务。可以说,他们的制造体系简直是奇迹。
第二点是他们的文化,这种文化一方面聚焦技术,不断推动技术进步;另一方面又以客户服务为导向。很多公司擅长客户服务,却没有顶尖的技术实力,无法走在技术前沿。
也有很多公司身处技术最前沿,却不是客户服务做得最好的。而台积电 somehow 在两者之间取得了平衡,并且在两方面都做到了世界一流。
第三点,也是我最看重的,是他们建立起了一种叫做信任的无形资产。我愿意把公司的命运托付给他们,这一点至关重要。
Lex Fridman:说到信任,你们之间建立了非常紧密的关系,这种信任是基于多年的表现积累而来,同时也包含着人与人之间的情谊。
黄仁勋:三十年了,我们和他们合作的业务规模高达数百上千亿美元,却没有一纸合同,这真的很了不起。
Lex Fridman:太惊人了。对了,还有这样一个传闻:2013 年,台积电创始人张忠谋曾邀请你担任台积电 CEO,而你回答说自己已经有工作了。这个故事是真的吗?
黄仁勋:是真的。我没有草率拒绝,而是深感荣幸。
我当时和现在都清楚,台积电是人类历史上最重要的公司之一。张忠谋是业界最受尊敬的管理者之一,也是我人生中的挚友。他能发出邀请,我既谦卑又荣幸。
但我手头的工作同样意义重大,我心里清楚英伟达未来会走向何方,能带来怎样的影响力,这是非常重要的事业,也是我独有的责任,必须由我来实现。所以我拒绝了,不****是因为这份邀请不够重磅,这是一份难以想象的邀约,但我实在无法接受。
Lex Fridman:我认为英伟达和台积电都是人类文明史上最伟大的两家公司。运营其中任何一家,都必定是极度复杂的事业,需要……你必须全身心投入。不止CEO层面,每个层级的每个人都必须真正全力以赴。
黄仁勋:是的,毫无疑问。
Lex Fridman:才能完成如此复杂的事业。
黄仁勋:而现在,我可以同时帮助两家公司。
11 英伟达的护城河
Lex Fridman:现在英伟达已经是全球市值最高的公司了。我必须问一个问题:用科技行业的话来说,你们最大的“护城河”是什么?也就是你们抵御竞争的核心优势。
黄仁勋:对我们来说,最重要的一点,就是我们计算平台的“装机量”。而今天最核心的,是 CUDA 的装机量。
当然,20 年前我们还没有装机量。那时候如果有人做一个 GUDA 或 TUDA,其实也没什么区别。关键在于,这从来不只是技术问题。
技术本身当然很重要,也很有前瞻性。但真正关键的是,公司是否长期投入、坚持推进,并不断扩大它的影响力。CUDA 的成功,不是三个人做出来的,而是 4.3 万人一起做出来的。
还有数百万开发者,他们相信我们,信任我们会不断把 CUDA 从 1 做到 2、3,一直到 13。他们愿意把自己的软件,甚至是“庞大的软件”,迁移到 CUDA 上。所以,“装机量”即庞大的用户群体是我们最重要的优势。
当你把这个装机量,再叠加上我们的执行速度,而且是在如此复杂的系统规模下,就会形成一个非常强的壁垒。
历史上从来没有哪家公司构建过这么复杂的系统,更不用说每年迭代一次了。这种执行速度,加上装机量,在开发者眼中意味着:如果我支持 CUDA,半年之后,它可能就会变得好 10 倍。
不仅如此,如果我基于 CUDA 进行开发,就能触达数亿用户和设备。我们覆盖了所有云平台、所有计算机企业、所有行业和所有国家。所以如果我开发一个开源工具包,并且首先基于 CUDA 发布,就能同时获得这两方面的优势。
同时,我完全相信英伟达会一直保留 CUDA,对其进行维护和升级,并且持续优化相关库,只要公司还在运营。这一点是完全可以信赖的,而这最后一点,就是信任。
把这些因素综合起来,如果我是一名开发者,我会优先选择 CUDA,主要基于 CUDA 开发。归根结底,我认为这是我们最核心的优势,甚至是我们首要的核心优势。
我们的第二项优势是生态系统。我们将这个极其复杂的系统进行了垂直整合,同时又横向融入到每一家企业的计算设备中。我们接入了谷歌云、亚马逊云、微软 Azure,目前也在大力拓展 AWS。我们还和 CoreWeave、Nscale 这类新兴公司合作,为礼来等企业提供超级计算机,也覆盖各类企业级设备。我们还深入到无线基站的边缘场景,可以说布局非常广泛。一套架构应用在所有这些不同的系统中。我们还覆盖了汽车、机器人、卫星以及太空领域。
正是这样一套统一的架构,搭配如此广泛的生态系统,基本上覆盖了全球所有行业。
Lex Fridman:那随着 AI 工厂的出现,CUDA 的装机量会如何演化?未来的英伟达,会不会完全变成一家“AI 工厂公司”?
黄仁勋:对我们来说,计算的基本单元曾经是 GPU,后来变成了整机,再后来变成了集群,而现在,它是一整座 AI 工厂。
过去,当我看到一台计算机,看到英伟达打造的产品时,我脑海里浮现的是芯片的样子。当我发布新一代产品时,比如“各位,今天我们发布 Ampere 架构”,我会拿起那颗芯片。那是我当时对自己所做产品的认知模式。
而现在,我不会再这样了。拿起芯片的样子固然很美好。但也只是美好而已。它不再是我对工作的认知模式了。
我现在的认知模式,是一个吉瓦级的巨型设施,有发电设备接入电网,有冷却系统,有规模惊人的网络架构。
上万人参与现场部署,数百名网络工程师驻守,数千名工程师在幕后支持它启动。你也知道,启动这样一座工厂,并不是有人说一句“开机了”就完事,而是需要数千人共同协作才能完成。
Lex Fridman:所以在你的思维里,当你思考一个计算单元时,实际上——你晚上躺在床上想的,已经是一整批机架、一个个算力集群,而不是单独的芯片了。
黄仁勋:是整个基础设施。而且我希望自己的下一次认知升级是,在思考建造计算机的时候,能站在全球规模的层面。那会是下一个跃迁。
12 太空中的 AI 数据中心
Lex Fridman:那你怎么看 Elon Musk 提到的“在太空做计算”?这可能有助于解决能源扩展的问题。
黄仁勋:散热可不容易。
Lex Fridman:确实,工程难度很大。不过英伟达似乎也在考虑这个方向?
黄仁勋:没错,我们已经做到了。英伟达 GPU 是首批进入太空的 GPU。我之前都没特意意识到这一点,还挺有意思的……我本该正式宣布一下的。
我们已经踏入太空了。真该给我们的 GPU 穿上小小的宇航服,那里是处理大量影像数据的理想场所。
那些卫星搭载着超高分辨率成像系统,现在正持续不断地扫描地球。人们需要能够覆盖全球、连续不间断的厘米级成像,这样就能实现万物的实时遥测。
你不可能把所有数据都传回地球,那可是 PB 级别的海量数据。必须在边缘端直接运行 AI,把不需要的、已经见过的、没有变化的数据全部过滤掉,只保留有用信息。所以 AI 必须在边缘端完成处理。
显然,如果把设备放在极地轨道,还能实现全天候太阳能供电。但在太空里,没有热传导,也没有热对流。周围基本上只有辐射。不过太空空间很大,我想,我们到时候直接装上巨大的散热板就好了。
Lex Fridman:你觉得这个方向有多现实?是 5 年、10 年,还是 20 年?
黄仁勋:其实我这个人要务实得多。我会先去找接下来一波又一波的机会在哪里,同时也在布局太空领域。我会派工程师去攻克相关难题,我们也已经开始行动了。
我们学到了很多东西:如何应对辐射?如何应对性能衰减?如何持续检测和验证故障?如何做冗余设计?如何实现优雅降级等等。
我们还可以展开很多探索,比如软件方面:在太空中,软件该如何设计?如何考虑冗余和性能问题?
要让计算机就算不会坏掉,也只是变慢而已。我们可以提前开展大量工程探索。但与此同时,我最优先的事情还是——消除浪费。地球上已经有那么多闲置电力,我希望尽快把它用起来。
Lex Fridman:确实,地球上还有很多“低垂的果实”可以利用。
13 英伟达的市值会达到 10 万亿美元吗?
Lex Fridman:你觉得英伟达有可能达到 10 万亿美元市值吗?或者说,在什么样的未来世界里,这件事会变成现实?
黄仁勋:我认为英伟达的增长极有可能实现,在我看来甚至是必然的。我来解释一下原因。
我们是有史以来规模最大的计算机公司,单是这一点就足以让人发问:为什么?答案主要有两方面,两个根本性的技术原因。
**首先,计算模式已经从过去的检索型、文件检索系统转变了形态。**在过去,几乎所有内容都是文件形式,我们预先编写、录制、制作内容,再发布到网络或存入文件,然后通过推荐系统、智能筛选为你调取所需信息。计算机在很大程度上就是一套人类预先记录、再进行文件检索的系统。
而现在,人工智能计算机具备了场景感知能力,必须实时处理并生成 token,计算模式从检索型转向了生成型。新时代的计算需要远超以往的处理能力,过去我们依赖大量存储,而现在需要的是海量运算。这是第一个核心变化,我们从根本上改变了计算的形态与实现方式。
唯一能让这一趋势逆转的可能,只有这种全新计算模式失效。也就是基于场景关联、态势感知,在生成信息前依托全新洞察的计算密集型模式失去效用。在过去十几年深耕深度学习的过程中,只要有任何一刻我认定这条路走不通、是死胡同,或是无法规模化、无法适配多种模态与应用场景,我的看法都会截然不同。但过去五年给我的信心,远超此前十年的总和。
第二个核心逻辑是,过去的计算机以存储为主,本质上更像仓库,仓库很难创造高额收益;**而我们现在打造的是工厂,工厂的价值直接和企业营收挂钩。**计算机由此完成了双重蜕变,不仅计算方式改变,存在的意义也彻底不同,它不再只是计算设备,而是创造营收的生产工厂。
如今我们看到,这些工厂不仅能生产用户需要的内容与产品,这些产出还对各类用户有着极高的价值,token 也开始像 iPhone 一样分层,有免费 token、高端 token,还有介于两者之间的多个层级。
智能本身其实是可规模化的产品,面向专业领域的高阶智能 token,用户愿意为之付费。有人愿意为每百万 token 支付 1000 美元的时代即将到来,这不是会不会发生的问题,而只是时间问题。
由此可见,这些工厂生产的产品具备真实价值,能够创造营收与利润。接下来的问题就是,全球需要多少座这样的工厂,需要多少 token,社会愿意为这些 token 支付多少成本。如果生产力得到大幅提升,全球经济又会发生怎样的变化?我们会研发出全新药物、产品与服务吗?
综合这些因素,我坚信全球 GDP 的增长会加速,也坚信用于计算的 GDP 占比会达到过去的一百倍。因为计算机不再是存储单元,而是生产力单元。从这个角度回看英伟达的业务定位,以及我们能在全新经济格局与产业中占据的位置,我认为公司的规模还会大幅扩张。
剩下的问题就是,英伟达在不久的将来能否实现三万亿美元营收?
**答案当然是肯定的,因为这一目标不受物理条件限制,在我看来没有任何因素能阻碍这一目标的实现。**而且英伟达的供应链由 200 家企业共同分担压力,我们依托生态伙伴实现规模化扩张,唯一需要考虑的就是能源供应,而我们必然能解决能源问题。
所以综合来看,营收数字只是一个数字而已。我还记得英伟达首次突破十亿美元营收时,有位 CEO 告诉我,从理论上讲,无晶圆厂的半导体公司不可能超过十亿美元规模,我就不赘述他的理由了,这一说法显然不合逻辑,事实也早已推翻了这个论断。后来又有人说,因为其他企业的限制,我们的规模不可能超过 250 亿美元,还有人给出各种看似合理的限制理由。
这些都不是基于第一性原理的思考,判断的核心其实很简单:我们创造的产品是什么,我们能开拓的市场空间有多大。
英伟达并非靠抢占现有市场份额发展,我刚才谈到的大部分领域,目前都还不存在,这也是最难让外界理解的地方。如果英伟达只是一家市值百亿美元、试图抢夺同行份额的企业,股东很容易就能估算出增长空间,只要拿下 10% 的份额就能实现相应扩张。但人们很难想象我们的上限,因为我们没有现成的市场份额可以抢夺。
所以我认为,世界面临的挑战之一,是对未来的想象力。而我有足够的时间,我会持续用逻辑推演未来,不断向外界传递这些理念,每一届 GTC 大会都会让这些构想越来越贴近现实。
会有越来越多的人认同这个方向,总有一天我们会实现目标,而我百分之百确定,我们终将抵达那里。
Lex Fridman:没错,“Token 工厂”这个视角非常有洞察力。通过“每秒每瓦特生成的 Token 数”来衡量,每个 Token 都有其实际价值。这是真正的产品。既然 AI 可以解决这么多潜在问题,基于第一性原理,很容易想象未来我们需要指数级增长的 Token 工厂。
黄仁勋:是的。而且让我特别兴奋的是,「Token 界的 iPhone」已经出现了。
Lex Fridman:你把它称作什么?等等,你是说 OpenClaw 就是那个 iPhone?
黄仁勋:没错。
Lex Fridman:这很有意思。
黄仁勋:泛指智能体。Token 领域的 iPhone 来了。它是历史上增长最快的应用,增长曲线一路直线飙升,完全是狂飙的状态。
Lex Fridman:这足以说明很多问题。
黄仁勋:毫无疑问,OpenClaw 就是 Token 时代的 iPhone。
Lex Fridman:从去年 12 月左右开始,是不是有一件真正特别的事情发生了?人们开始真正意识到 Claude Code、Codex 还有 OpenClaw 的力量。我有点不好意思承认,这次来这里的机场里,我第一次在公开场合做了这样一件事——我所谓的编程,只是对着笔记本电脑说话而已。
黄仁勋:对,就是这样。
Lex Fridman:我觉得挺尴尬的,因为我表现得就像在跟人类同事聊天。我不确定未来每个人都对着自己的 AI 说话会是什么样,但这种办事效率真的太高了。
黄仁勋:更有可能的情况是,你的 AI 会一直“骚扰”你。因为它办事太快了,它会不断向你汇报:“这事儿办完了,下一步你想让我做什么?”我觉得大多数人还没意识到,未来跟你聊天、发消息最频繁的“人”,其实是你的这些智能助手。
14 当一家万亿美元市值公司的 CEO,所承受的压力
Lex Fridman:这是一个令人难以置信的未来。我读到你曾提到,你的成功很大程度上来自于你比任何人都更努力、也能承受比任何人更多的痛苦。
我们可以列出很多这背后涉及的内容:失败、我们刚才讨论的成本与工程问题、人性层面的挑战、不确定性、责任、疲惫、尴尬,还有你提到过的那些公司几乎濒临崩溃的时刻,以及巨大的压力。
现在,作为这家公司——全球经济体和各国都在围绕它制定战略、规划财政投入、设计 AI 基础设施——的 CEO,你是如何承受这种程度的压力的?在这么多国家和人依赖你的情况下,你从哪里获得力量?
黄仁勋:我非常清楚,英伟达的成功对美国来说意义重大。我们创造了巨额税收,确立了国家在科技领域的领导地位。
而科技领导力,对于国家安全至关重要——不仅仅是某一个方面,而是国家安全的各个层面。
当一个国家更加繁荣时,我们就能更好地制定国内政策,改善社会福利。
我们正在推动美国的再工业化,创造大量就业机会,让制造业回流美国,涵盖芯片、计算机,当然还有这些“AI 工厂”。
我非常清楚这一点。
而且我也很清楚一件事——有很多普通投资者、教师、警察等人,因为某种原因投资了 NVIDIA,或者通过媒体关注买入股票,现在成了百万富翁。
这是一个真实存在的现象。
我也清楚,NVIDIA 在整个生态系统中处于一个非常核心的位置——上游和下游都有大量合作伙伴依赖我们。
所以,我处理压力的方式,就是回到最本质的方式:推理。
我会不断问自己:我们在做什么?这会带来什么影响?它会如何影响他人?无论是正面收益,还是对供应链带来的负担。
然后我会问自己:那我接下来要怎么做?
我会把问题拆解开,逐步分解,把复杂局面变成一个个我可以实际处理的小问题。
接下来我唯一要做的就是:有没有去做?有没有交给合适的人去做?
如果你意识到应该做,但既没做,也没让别人去做,那就别抱怨了。
所以我对自己是非常严格的。
但与此同时,我会把问题拆解,这样我就不会陷入恐慌。我可以安心睡觉,因为我已经列出了需要做的事情,并确保所有可能带来风险的问题都已经被传达给合适的人。
如果某件事可能威胁到公司、合作伙伴或行业,我都会确保有人知道,并且是能够采取行动的人。
我已经把压力释放出去,或者已经在解决问题。那接下来还能做什么呢?
Lex Fridman:在你整个构建 NVIDIA 的过程中,经历了如此多高强度的挑战,你有没有经历过心理上的低谷?
黄仁勋:当然有,而且是经常性的。
Lex Fridman:你是通过不断拆解问题来应对的吗?
黄仁勋:还有一点,Lex,是“遗忘”。
你也知道,人工智能学习中最重要的特质之一,就是系统性遗忘。你需要知道什么时候该放下一些事情,不能把所有东西都记住,不能背负一切,也不该带着所有负担前行。我会很快地拆解问题,理性分析问题,然后和身边的人一起分担压力。当我把事情告诉所有人时,本质上就是在分担这份重担。
要尽可能快地去做。让你焦虑的事情,一定要说给别人听,不要自己闷在心里。当然也不要吓到别人,把问题拆成更小的部分,带动大家、激励大家一起去解决。但核心的一点还是遗忘。很多时候你必须对自己强硬一点,告诉自己别再纠结抱怨,振作起来继续前进,然后起床投入新的一天。另一部分原因是,你会被下一个目标、下一个未来、下一个机会吸引,告诉自己过去的已经过去了,接下来该做什么?我觉得你在优秀的运动员身上也能看到这一点,他们只关心下一分,上一分已经成为过去,无论尴尬还是挫折都不再回头。
因为我的很多工作都是公开进行的。我经常会说一些在当时看来合理或者有趣的话,大部分时候只是因为我自己觉得有趣。事后回想起来,可能就没那么好笑了……
Lex Fridman:确实,我懂这种感觉。你基本上是让自己被未来吸引,忘掉过去,继续前进。
黄仁勋:是的。
Lex Fridman:你曾说过一句很有名的话:如果你当初知道构建英伟达会这么难——甚至比你想象的难一百万倍——你可能就不会做这件事了。
黄仁勋:没错。其实我想表达的是,拥有一颗孩童般的内心,是一种不可思议的强大力量。我每次面对新事物的时候,常常会对自己说:这能有多难呢?你就用这样的心态给自己打气,这能有多难?尽管从来没人做到过,尽管这件事看起来无比庞大,要投入数千亿美元,要耗费无数资源,但你还是会想,没错,可它到底能有多难呢?
你必须让自己进入这样的心态。不要提前去预想所有的细节、所有的挫折、所有的艰难困苦和所有的失望。你不必提前知道这些。你应该带着全新的期待投入一段新的旅程,相信一切都会顺利、都会很棒、都会充满乐趣。而当你真正身处其中时,你需要耐力,需要毅力,这样当挫折真正到来时——那些让你意外的打击、失望、尴尬乃至屈辱——你才能扛过去。
你不能被这些打倒,这时候你要开启另一面,那就是忘掉这一切,继续前进,不停向前。只要我对未来的判断、对未来终将实现的理由没有发生实质性的改变,那么我就有理由相信,最终的结果也不会改变。我预想中的未来依然会到来,既然它一定会到来,我就会继续追寻。
我坚信这一点。这其实是结合了两三种人类的特质:以全新的心态投入经历的能力、忘记挫折的能力、相信自己的能力,坚守自己的信念并保持真诚。同时你也在不断地重新评估。
我认为这样几种特质的结合,对于培养韧性至关重要。我很幸运,过往的人生经历让我拥有了这几项特质。我始终充满好奇,始终在学习,向身边每一个人学习。我始终保持谦逊,常常会想,他们做得真好,太出色了,我想知道他们是如何思考的,他们是如何做到的。我会在心里模仿每一个人,从很多方面来说,我几乎在效仿所有我关注的人。你会对自己观察到并敬佩的一切抱有共情,然后不断地从中学习。
Lex Fridman:你现在是世界上最富有、最成功的人之一。这会不会让你更难保持谦逊?是否会让你更难接受他人的观点,或者更难承认自己可能是错的?
黄仁勋:很意外——不会,反而相反。因为我大量的工作是公开进行的,所以当我犯错时,几乎所有人都能看到。
而当我出错的时候——当我判断失误或者事情没有按照预期发展时,我在公开场合说的大部分话都是经过深思熟虑的,因为这些话会影响到其他人,我必须对此保持谨慎和周全。
但在会议内部进行逻辑推演时,很多结果都可能出现变数,可这从来不会阻止我去思考分析。
我的管理和领导方式,就是在众人面前不断地推演论证。就算是和你交谈时,你也能看到我一步步梳理问题的过程。我希望你能理解我的想法,不是因为我单方面告诉你结论,而是因为我对自己要表达的内容保持谦逊,会把得出结论的思考过程展现给你,然后由你自己判断最终是否认同我的观点。
我整天在会议上都是这样做的,面对所有员工,我都会经常说:“让我告诉你我的看法”,然后完整地梳理我的思路。这让每个人都有机会打断我,说出“我不认同这一部分”。
通过梳理思路并让大家参与探讨的好处在于,人们不必否定你的最终结论,他们可以对你的推理环节提出不同看法,从而引导我从不同角度思考,我们再一起继续推演。
这就像是一种集体探索路径的方式,效果非常好。
Lex Fridman:我能感受到,你在解释问题的时候,是在实时思考的,而且保持开放。这种状态很难长期维持,尤其是在经历了这么多成功和痛苦之后。
黄仁勋:是的,关键在于你要能承受“尴尬”。
Lex Fridman:没错,“容忍尴尬”是很重要的一点。能够在众人面前承认自己错了,并从中成长,这在人性层面是非常困难的。
黄仁勋:对。不过你知道,我第一份工作是清洁厕所。
15 关于电子游戏的看法
Lex Fridman:很高兴你始终保持着当年在 Denny’s 餐厅打工时的那种奋斗精神。那段旅程真的很美。让我们聊聊电子游戏吧,我是个资深玩家,我得感谢英伟达多年来提供的卓越图形技术。
黄仁勋:顺便说一下,GeForce 直到今天依然是我们最核心的市场战略。人们在青少年时期通过游戏认识英伟达,等他们上了大学,就已经深深刻下了英伟达的印记。起初他们只是玩《使命召唤》或《堡垒之夜》,后来他们开始学习使用 CUDA,再后来他们在 Blender、达索系统(Dassault)或 Autodesk 里进行专业创作。
Lex Fridman:没错,我和朋友提到要采访你时,他的第一反应就是:“噢,他们做游戏显卡特别厉害。”虽然英伟达远不止于此,但它确实给无数人带来了快乐。最近关于 DLSS 5 有一些争议,你能解释一下吗?有些玩家担心 AI 的介入会让游戏画面看起来充满“AI 废料感(AI Slop)”。
黄仁勋:我完全理解这种顾虑,因为我自己也不喜欢那种千篇一律的 AI 废料感。现在的 AI 生成内容确实容易陷入审美疲劳。但 DLSS 5 的初衷并非如此。
我之前展示过一些例子,DLSS 5 是由 3D 物理信息引导和约束的。它以物理真实的数据为基础,这意味着艺术家的原始几何构型决定了骨架,我们对每一帧的几何结构都保持绝对忠诚。它受纹理和艺术风格的约束,只是增强画面,并不会篡改艺术家的意图。
甚至在未来,由于系统是开放的,你可以训练自己的模型甚至通过提示词来控制风格。比如你想要“卡通渲染”或者某种特定风格。这一切都是为了给艺术家提供生成式 AI 的工具,让他们创造出更美、且符合自己风格的作品。我想玩家们的误解可能是:我们是在游戏渲染完成后进行这种“后期处理”。事实并非如此,DLSS 是与美术流程深度融合的。
Lex Fridman:我觉得人类对人脸非常敏感。而我们正处在一个很美好的时代,人们开始对粗糙劣质的 AI 内容变得敏感起来。这就像一面镜子,让我们意识到,我们真正追求的其实是不完美。我们追求的有时并非完美的画面效果,这也让我们明白,在自己创造的世界里,究竟什么才是真正打动我们的东西。这一点很美好。只要这些工具能帮助我们打造属于自己的世界——
黄仁勋:没错,的确是这样。这只是又一种工具而已,人们也希望生成式模型能创造出与照片写实风格截然不同的效果,这一点它也能做到。所以它仅仅是一款新工具而已。
我想游戏玩家们可能也会发现,过去几年里我们为游戏开发者提供了皮肤着色器技术。很多游戏中的皮肤着色器都包含了次表面散射效果,让皮肤看起来更真实自然。整个行业,游戏开发者们都在寻找越来越多的工具来表达自己的艺术创作理念,而AI只是其中一种,最终如何使用由他们自己决定。
Lex Fridman:问一个不太常规的问题,你认为史上最伟大、最具影响力的游戏是什么?从英伟达的角度来看也可以。
黄仁勋:《毁灭战士》。
Lex Fridman:毫无疑问是《毁灭战士》,它开启了 3D 游戏的时代。
黄仁勋:我会说是《毁灭战士》,从艺术、文化影响力与产业交叉的角度来看,它把个人电脑变成了游戏设备,这是一个非常重要的时刻。当然在这之前已经有飞行模拟类软件,但它们都没有《毁灭战士》这样的普及度,是它推动整个行业把个人电脑从办公自动化工具,变成了适合家庭和游戏玩家使用的设备。所以《毁灭战士》在这方面影响深远。如果从真正的游戏技术角度来说,我会选《VR战士》。我们和这两款作品的团队都是很好的朋友。
Lex Fridman:近些年也有很多出色的游戏,比如《赛博朋克 2077》,它有着非常优秀的 GPU 加速画面效果。
黄仁勋:全光线追踪。
Lex Fridman:没错,全光线追踪。另外我个人特别喜欢《上古卷轴5:天际》,虽然它发布已经很久了,但玩家们一直在推出各种模组。
黄仁勋:我们很喜欢模组生态。
Lex Fridman:玩家们用模组创造出全新的内容,简直就像另一款游戏,也让我可以一遍又一遍重玩。它让你意识到,你能以全新的方式,重新体验自己早已热爱的世界。
黄仁勋:没错。
Lex Fridman:我经常这么做,我最喜欢的事情之一就是在天际省的世界里漫步。
黄仁勋:我们开发了一款叫做 RTX Mod 的工具,这是一个模组制作工具。
Lex Fridman:太棒了。
黄仁勋:它能让玩家社区把最新的技术注入到老游戏当中。
16 AGI 什么时候到来?
Lex Fridman:你曾说过关于 AGI 的时间线,取决于你如何定义通用人工智能。那我就来问问你对可能时间线的看法。我们不妨用一个听起来有些夸张的定义:一套 AI 系统能够基本胜任你的工作——也就是创立、发展并运营一家成功的科技公司,市值超过……
黄仁勋:是像样的公司,还是随便一家?
Lex Fridman:不,必须是市值超过十亿美元的公司。你清楚要完成所有这些环节有多难。那么我们距离这一天还有多远?我们说的是像 OpenClaw 这样的系统,能够完成所有极度复杂的工作:首先是创新,然后是寻找客户、完成销售、进行管理,组建由智能体和人类构成的团队,等等。这会是五年、十年、十五年,还是二十年之后的事?
黄仁勋:我认为现在就已经实现了。我觉得我们已经实现了 AGI。
Lex Fridman:你认为真的可以让一套这样的 AI 系统来运营一家公司吗?
黄仁勋:有可能,原因是这样的。你说的是十亿美元,而且没说要永久维持下去。举个例子,完全有可能出现这样的情况:Claude 创建了一项网络服务,或是一个有趣的小应用,突然之间有几十亿人愿意花五十美分使用它,然后不久后又停止运营了。在互联网时代,我们见过大量这类公司,而当时大多数网站的复杂程度,都不会超过如今 OpenClaw 所能生成的内容。
Lex Fridman:有意思,实现病毒式传播并将其变现。
黄仁勋:没错。只是我现在还不知道具体会是什么形式,但换作当年,我也无法预测出那些互联网公司的出现,不是吗?
17 编程的未来:未来程序员会有 10 亿人
Lex Fridman:你的这个观点会让很多人兴奋。
黄仁勋:没错。
Lex Fridman:大家会想,你这话是什么意思?难道我只要启动一个智能体就能赚大钱吗?
黄仁勋:事实上,这种事现在已经在发生了。你也知道,去中国的话会看到,很多人在教自己的 Claude 出去找工作、做任务、赚钱。我一点都不会觉得奇怪,如果突然出现某个社交类产品,有人打造出一个非常可爱的虚拟网红,或者类似电子宠物那样的社交应用,一夜之间爆火。很多这类应用会火上几个月,然后慢慢淡出。但指望十万个这样的智能体打造出另一个英伟达,可能性是零。
另外有一点我必须强调,也希望大家都能明白,很多人确实在担心自己的工作。我想提醒他们,你工作的目的,和你完成工作所用的任务与工具,是相关的,但并不是一回事。
我已经做了 33 年的工作,我是全球任职时间最长的科技行业 CEO,马上 34 年了。过去 34 年里,我工作所用的工具一直在不断变化,有些时候两三年里就会发生巨大的改变。
我想让每个人都听到一个真实的故事:当年计算机科学家和 AI 研究者最先预言会消失的职业,是放射科医生。
因为计算机视觉会达到超越人类的水平,而它确实做到了。计算机视觉在 2019、2020 年左右就已经超越人类了,可能稍晚一点,2020 年。
距离计算机视觉超越人类已经过去很久了。当时的预测是,放射科医生会消失,因为阅读影像片子这件事会交给 AI,人类再也不需要了。
他们说对了一半,计算机视觉的确完全超越了人类。现在所有的放射科平台和工具都是由 AI 驱动的,但是放射科医生的数量反而增加了。
问题来了,为什么?
如今全球甚至还出现了放射科医生短缺的情况。那些危言耸听的言论太过了,吓到了很多人,让他们不敢进入这个对社会至关重要的行业,这其实造成了伤害。
那为什么预言是错的?
原因在于,放射科医生的使命,是诊断疾病,帮助患者和医生做出诊断。因为现在我们可以更快地阅片,就能检查更多影像,诊断更精准,让患者更快入院,接诊更多病人。医院的收入变高了,病人变多了,就需要更多放射科医生。
其实这件事的逻辑显而易见。英伟达的软件工程师数量也会增加,而不是减少。
原因同样是,软件工程师的工作目标,和他们写代码这项具体任务,相关但不等同。我需要我的工程师解决问题,我并不在乎他们写了多少行代码。他们工作的本质目的没有改变。解决问题、团队协作、定位问题、评估结果、寻找新的问题、创新、串联思路,这些东西永远不会消失。
Lex Fridman:你觉得有没有可能……就算拿编程来说,你认为全世界程序员的数量可能会增加,而不是减少吗?
黄仁勋:是的。原因是这样的。编程的定义是什么?我认为,就今天而言,编程的定义其实就是提出需求说明,如果你希望更具指导性一些,你甚至可以给它一个你想要编写的软件架构。
那么问题是,有多少人能做到这件事?描述出需求说明,让计算机去明白要构建什么。能有多少人?以前全球只有 3000 万人能编程,现在这个门槛消失了,全世界 10 亿人都可以是“程序员”。
未来的每一个木匠都会是程序员,只不过拥有 AI 的木匠同时也是建筑师。他们能为客户创造的价值直接提升了,他们的技艺水平也得到了巨大的提升。
我相信每一个会计,同时也会是你的财务分析师,也是你的财务顾问。所以所有这些职业的层次都被拉高了。如果我是一个木匠,看到 AI,我会特别兴奋。如果我是水管工,我能为客户提供的服务也会迎来巨大的提升。
Lex Fridman:而现在这些程序员和软件工程师,我觉得他们正处在最前沿,能凭直觉理解如何用自然语言和智能体沟通,从而设计出最好的软件。
黄仁勋:没错,正是这样。
Lex Fridman:所以长远来看两者会融合,但我认为学习编程依然有价值,比如学习什么是编程语言,传统的编程方式,编程语言的优秀实践,大型软件系统的设计原则。这些对于大型软件系统的编程语言依然重要吗?
黄仁勋:就像你在对观众说的,我认为提出需求说明的目标,以及其中的艺术性,取决于你要解决什么问题。当我在为公司制定战略、规划方向和我们应该做的事情时,我会描述到足够具体的程度,让大家明白方向并且可以执行。具体到他们能够行动,但我会刻意保留一些不明确的地方,这样才能让 43000 名优秀的员工把它做得比我想象的更好。
所以当我和工程师、和其他人合作时,我会想清楚我要解决什么问题,我在和谁合作。需求说明的细致程度、架构定义的程度都与此相关。每个人都需要学会自己想在编程的哪个层次上定位。编写需求说明就是编程。你可以选择定义得非常具体,因为你追求一个非常明确的结果。你也可以选择在某个领域更偏向探索,于是你可以不把需求写得太细,从而和 AI 来回迭代,甚至突破自己的创造力边界。这种在不同层次之间把握分寸的艺术,就是未来的编程。
Lex Fridman:但我们跳出编程来看,我觉得很多人担心自己的工作是理所当然的,他们对工作充满焦虑,尤其是白领群体。我觉得我们都不知道该如何面对自动化和新技术到来时必然出现的动荡时代。我只是觉得,首先,我们都需要有同情心,有责任感去体会那些失去工作的个人和家庭真实承受的痛苦。我认为每当出现像人工智能这样具有变革性的技术时,一定会伴随很多痛苦,而我不知道该如何化解这种痛苦。
希望随着工具的发展,能为这些人创造更多同类工作的机会,让他们变得更高效,也希望工作能变得更有乐趣,就像编程领域一样。我必须说,我现在编程变得特别开心,从来没有这么开心过。所以希望 AI 能自动化掉工作中枯燥的部分,让人类负责有创造力的部分。但即便如此,依然会有很多痛苦和煎熬。
黄仁勋:这是我面对焦虑的第一个建议,其实我们刚才也聊到过。对未来的巨大焦虑,对压力的巨大焦虑,对不确定性的巨大焦虑,我首先会把它拆解开来,然后告诉自己,有些事情你可以做点什么,有些事情你无能为力。但对于那些你能改变的事情,我们理性分析,然后去行动。
如果我们今天要招聘一个应届毕业生,有两个人选,一个完全不懂 AI,一个精通使用 AI,我一定会选精通 AI 的那个。不管是会计、市场营销、供应链、客服、销售、业务拓展、律师,我都会雇用擅长使用 AI 的人。所以我建议每一个大学生,每一位老师都应该鼓励学生去使用 AI。每个大学生毕业时都应该成为 AI 的使用者。每个人,不管你是木匠还是电工,都去用 AI,看看它如何改变你的工作,提升你自己。
如果我是农民,我一定会用 AI。如果我是药剂师,我也会用 AI。我想看看它如何提升我的工作,让我成为革新这个行业的人。这是我会做的第一件事。然后我也会帮助他们。技术确实会取代很多任务,实现自动化。如果你的工作就是这些任务本身,那你很可能会受到冲击。如果你的工作目标包含了你自身,而不仅仅是某些任务,那么你就必须去学习如何用 AI 自动化这些任务。在这两者之间还有很多不同的层次。
Lex Fridman:顺便说一句,AI 聊天机器人最棒的地方在于,你可以把问题拆解开来。当你感到焦虑时,你可以通过和它对话把问题理清。我最近就深有体会——你能用它梳理生活里的各种问题,真的特别神奇,而且我指的不是心理治疗那种,而是非常实际的问题。比如直接说:“我很担心我的工作,我需要掌握哪些技能?我该一步步做什么?我该怎么更好地使用 AI?”
你刚才说的所有这些,你都可以直接去问它,它会给你一份逐条清晰的计划。它简直就是绝佳的人生教练,真的。
黄仁勋:就算你说“我不会用 AI”,AI 也会说:“没关系,我来教你。”
19 “不要因为智能的普及化、智能的商品化而感到焦虑”
Lex Fridman:你认为,人性与人类意识中,是否存在某些从根本上无法被计算的东西?或许是某种无论芯片多么强大,都永远无法复制的存在?
黄仁勋:我不知道芯片会不会感到紧张。当然,那些会引发焦虑、紧张或其他情绪的条件,我相信 AI 都能够识别并理解。但我不认为我的芯片会亲身感受到这些情绪。
因此,那些焦虑、那种感受、那种兴奋感…… 所有这些情绪,都会体现在人类的表现之中。比如,有人能展现出极其惊人的表现,像运动员那样;也有人只是普通水平,甚至低于普通水平。同样的环境下,不同的人会呈现出完全不同的结果、不同的表现,形成这样一整个完整的区间。
我不认为我们所构建的任何东西,会出现这样的情况:两台不同的计算机在完全相同的情境输入下,它们会有不同的表现。当然,它们可能会产生不同的统计结果,但那并不是因为它们感受不同。
Lex Fridman:没错,就是这种主观感受……我们人类所拥有的主观感受,真的有着无比特别的意义。
就像我跟你说过的,和你对话时我其实相当紧张。还有希望、恐惧、焦虑,以及生命本身,生命的丰富与厚重。世间万物何其美妙。我们爱得多么深沉,心碎时又多么痛楚;我们对死亡满怀畏惧,挚爱之人离去时又承受着巨大的悲痛。
所有这一切,完整的一切。我知道,很难想象 AI——一个计算设备——能够拥有这样的感受。
但关于这一切,还有太多奥秘等待我们去揭开,所以我愿意接受一切惊喜。在过去几个月、几年里,我已经收获了太多意外。
模型规模的拓展,能够在智能领域创造出不可思议的奇迹。亲眼见证这一切的发生,实在太过奇妙。所以,我始终敞开胸怀,等待惊喜的到来。
黄仁勋:这真的很重要,我们需要弄清楚什么是智能。你知道的,我们常常使用这个词,但它并不神秘。智能是有意义的。
它是一个系统,包含感知、理解、推理和计划的能力。而这种反馈循环,正是智能的本质。智能并不是一个等同于人性的词语,我认为这两者必须区分开。我们有两个词来表示这两个概念。
我并不对智能抱有过高的幻想,也不对它过度浪漫化。智能是…你听过我说过的,**我其实认为智能是一种商品。**我周围有很多聪明的人,他们在各自的领域里都是顶尖的。
但我在这个圈子里依然有我的位置。这其实挺有意思的。他们比我受过更好的教育,上的大学也比我好。在他们各自的领域里,他们的造诣都比我更深,所有人都是如此。
我手下有 60 位这样的人。对我而言,他们个个都是超人。可不知为何,却是我坐在中间,统筹着这 60 个人。
所以你会不禁自问……我这样一个普通人,凭什么能置身于这群超人之间,统领全局?
这就是我想说的重点。我的观点是,**智能是一种功能性的东西。**但人性并非由功能来定义,它的内涵要宏大得多。
我们的人生阅历、承受痛苦的能力、我们的决心,这些都与“智能”是不同的概念。
所以,如果我只能让观众明白一件事,那就是:长久以来,我们已经把“智能”这个词捧到了一个过高的地位。
Lex Fridman:我们真正应该抬高的词是人性。
黄仁勋: 品格,人性。
Lex Fridman:所有这些东西。
黄仁勋:所有这些品质——同理心、慷慨,以及你刚才提到的一切,我都相信它们是超人般的力量。
而如今,智能将会变得商品化。我们之前也聊到,过去最重要的是教育。即便过去人们总说最重要的是教育,你在学校里收获的也远不止知识本身。
但遗憾的是,我们的社会把一切都归结到了一个词上,可人生绝不是一个词就能概括的。
我想告诉你,从我自身的经历来看,即便我的智商水平不如身边所有人,也丝毫改变不了我最为成功的事实。
我希望借此能激励所有人:不要因为智能的普及化、智能的商品化而感到焦虑。你反而应该为此倍受鼓舞。
Lex Fridman:没错。我认为人工智能会让我们更加赞颂人类本身。当然,要以人为本,人类至上。我觉得让这个世界如此精彩的,永远是人类。而人工智能只是一个非凡的工具,它让我们能够更强大。
黄仁勋: 没错。
19 谈及生死:没想过英伟达的接班问题
Lex Fridman:英伟达的成功以及像我刚刚提到的无数人们的生活,都依赖于你。但你只是一个普通人,和我们所有人一样,终有一死。你有思考过死亡这个话题吗?你害怕死亡吗?
黄仁勋:我真的不想死。我现在的生活很美好,拥有一个幸福的家庭,也有一份非常重要的工作。这并非是我一个人独特的经历,更是全人类的独特体验。我正在经历的,是人类文明史上仅此一次的体验。
英伟达是历史上影响力最为深远的科技公司之一。我们正在从事至关重要的工作,我对此极为重视。当然,其中也包括一些实际问题,比如我们该如何考虑接班规划?
而我一直以来的观点众所周知 —— 我并不信奉接班规划。
我这么说的原因不是因为我会永生不死。而是因为如果你一直担心继任规划,还为此焦虑不已,那你应该怎么做呢?
那就把所有问题归结到最根本层面。
如果你关心公司未来的走向,关心你之后的未来,那么今天最重要的事情就是尽可能频繁、持续地传递知识、信息、见解、技能和经验。
这就是为什么我总是不断地和团队交流。每一次会议都是一次思想碰撞的会议。我在公司内外的每一分每一秒,都是在尽量快地传递知识。
我学到的任何东西,从来不会在我的桌子上停留超过一秒钟,我会马上把这些信息、知识传递出去。在我还没完全学会之前,我就已经叫别人去学习了。“赶快学这个,这太酷了,你一定要了解。”
所以,**我一直****在不断传递知识、赋能他人,提高周围每个人的能力,**因为我真正追求和期望的结果,是能工作到生命最后一刻。而且我希望能在工作中瞬间离去,不要有漫长的痛苦煎熬。
Lex Fridman:作为你的一名粉丝,考虑到你对文明的巨大积极影响,当然,我希望你能继续前进。还有能够看着英伟达的创新真是太有意思,你们的创新速度真是让人惊叹。
我本人也是工程学的忠实拥趸。英伟达一直在持续开展着数不胜数、令人惊叹的工程研发工作。看着这一切发生,本身就是一种乐趣。这是对人类的赞颂,是对伟大建设者的赞颂,也是对卓越工程技术的赞颂。所以,它有着非同寻常的意义。我希望你和英伟达能继续走下去。
对于我们当下所经历的这一切,对于人类、对于人类的未来,是什么给了你希望?当你放眼长远,深入思考未来,展望 10 年、20 年、50 年乃至 100 年后,是什么让你心怀希望?
黄仁勋:我一直深信人类的善良、慷慨、悲悯之心与内在潜能。我对此始终抱有极大的信心,有时甚至过于乐观,也因此被人利用过,但这从未改变我的想法。
我始终相信,人性本善,人们愿意帮助他人。而事实也一再证明我是对的,甚至常常超出我的预期。因此我对人类的潜能充满绝对信心。
在我看来,如今一切皆有可能的现状,以及基于我们当下所做之事推断出的未来走向,就是让我满怀希望的源泉。
当前我们有很多问题要解决,很多事情要建造,很多好事要做,这些现在都在我们的掌握之中,而且都在我有生之年就能实现。面对这一切,你根本不可能不心怀浪漫与憧憬。你懂我的意思吧?
Lex Fridman:生活在这样一个激动人心的时代真是太棒了!
黄仁勋:面对这一切,你怎么能不心怀浪漫与憧憬呢?我们完全有理由期待,疾病终将被终结、污染问题会得到大幅改善、未来人类真的能够实现光速旅行。当然,不是长途,而是短途旅行。
有人会问我要如何实现。首先,很快我就会把一个人形机器人送上宇宙飞船,就是我研发的这款人形机器人。我们会尽快将它发射升空,它还会在飞行过程中不断迭代升级。
等到时机成熟,我所有的意识早就已经——你知道,我人生中太多东西都已经上传到互联网上了。把我所有的收件箱、我做过的每一件事、我说过的每一句话都提取出来。这些信息都被收集起来,正在塑造属于我的人工智能。
等到那一刻来临,我们就会以光速把它发送出去,追上我的机器人。
Lex Fridman:太棒了。对我来说,这更多是应用方面的思考,但从我的角度来看,那些谜题,真的是太多了……充满了令人着迷的科学问题。
黄仁勋:了解生物机器指日可待。这不是 10 年后的事,可能是 5 年之内。
Lex Fridman:然后是你们的生物机器,人类的思维以及突破物理学、理论物理。这真是令人兴奋。
黄仁勋:解释意识问题,那将是一个伟大的成就。
Lex Fridman:这一切都在我们的掌握之中。Jensen,非常感谢你这些年来所做的一切。感谢你为世界做的贡献,感谢你做为一个人所展现出来的一切。我能感受到你是个伟大的人,祝愿你今年一切顺利,我迫不及待想看到你接下来做的事情,再次感谢你今天的对话。
黄仁勋:谢谢你,Lex。我度过了愉快的时光。如果能再说一句话的话,我也要感谢你做的所有采访,感谢你对采访对象的深度、尊重以及你为揭示这些令人惊叹的人物所做的研究。我非常享受你采访过的每一个人。作为一个创新者,能创造出这种长形式的内容,真是太不可思议了,虽然它也很简洁,然而却依然充满吸引力。总之,感谢你所做的一切。
科普:AI 里的 token 到底是个啥玩意?
一口 Linux 2026 年 3 月 18 日 16:45 西藏
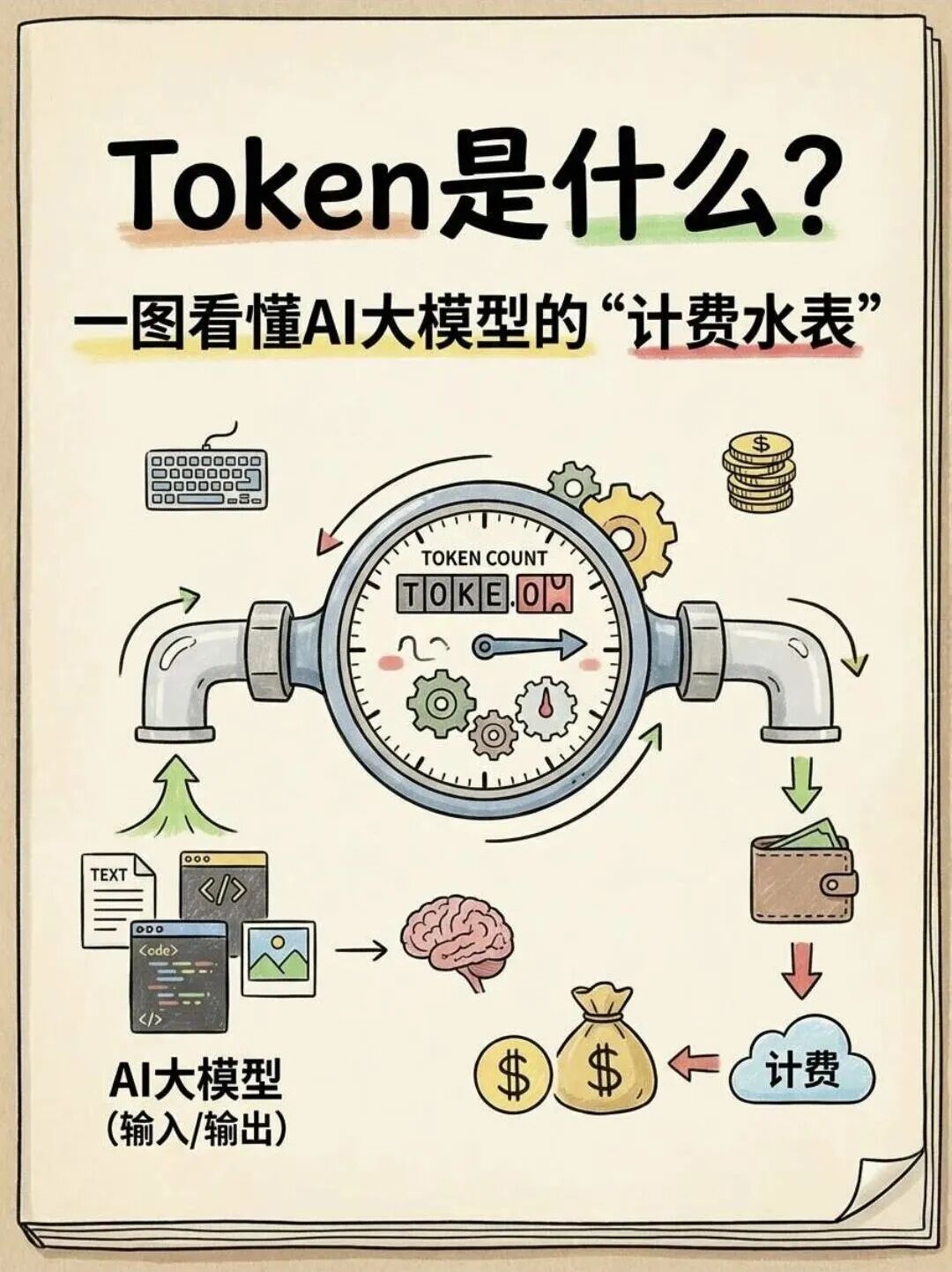
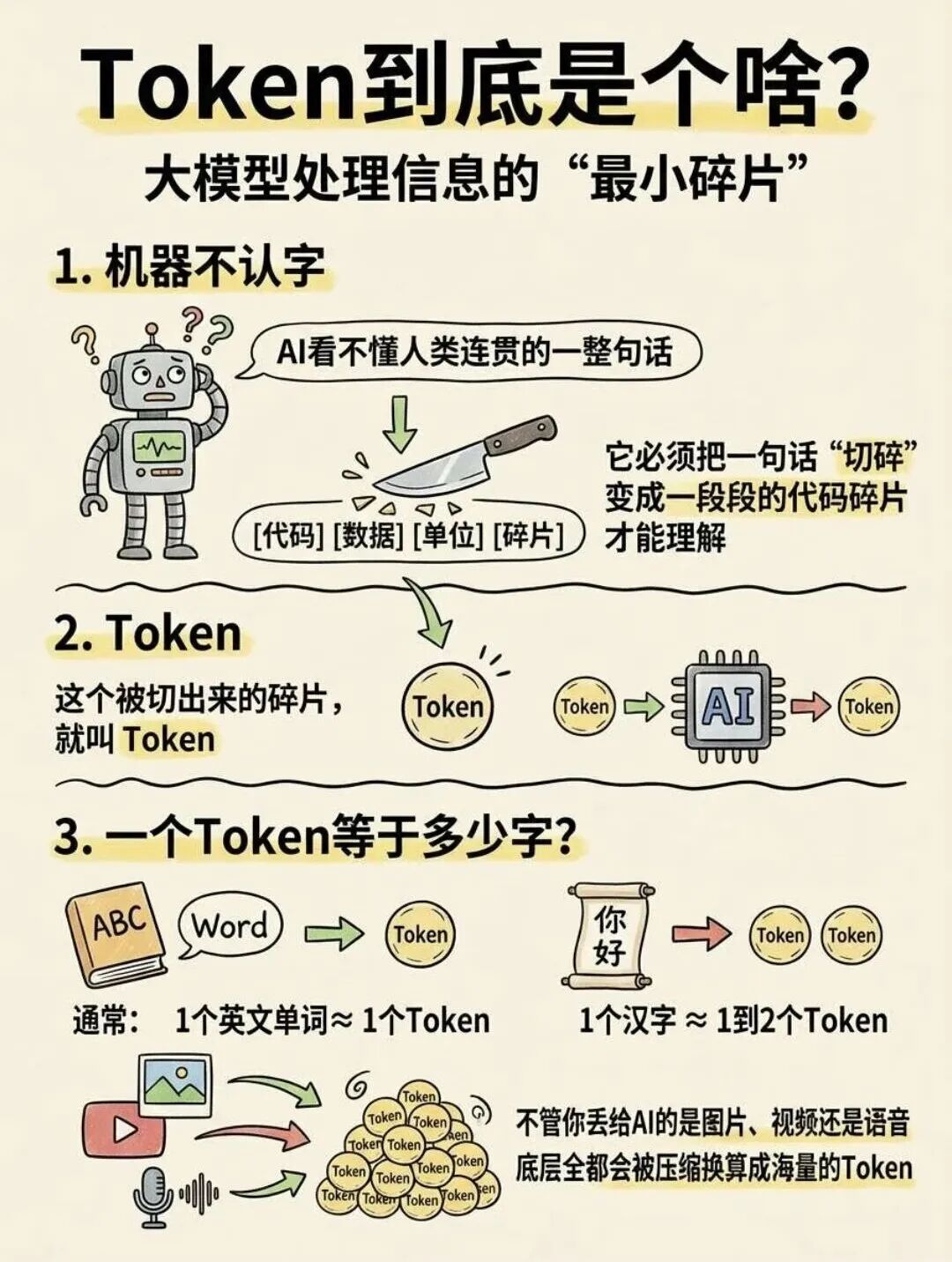
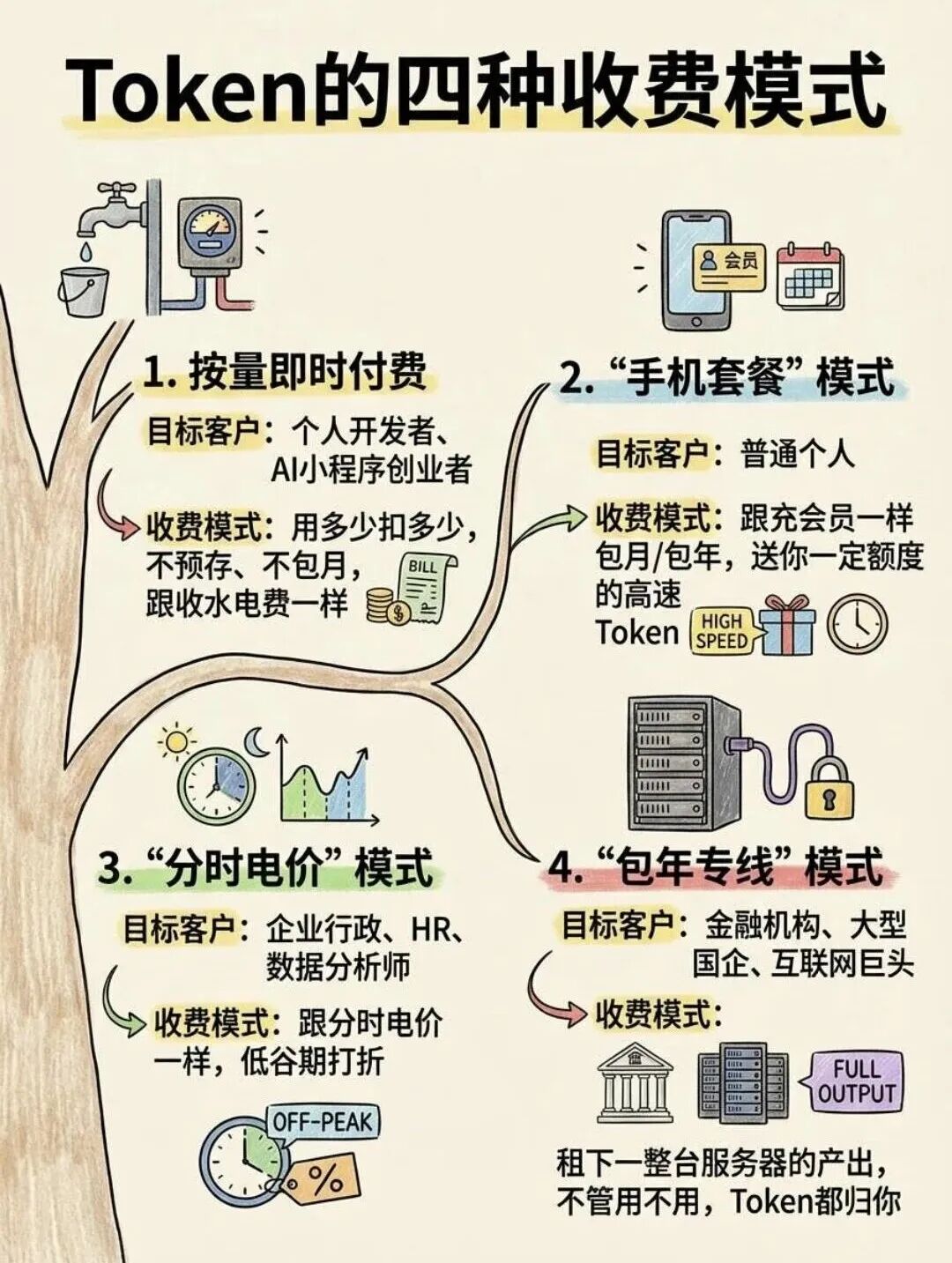
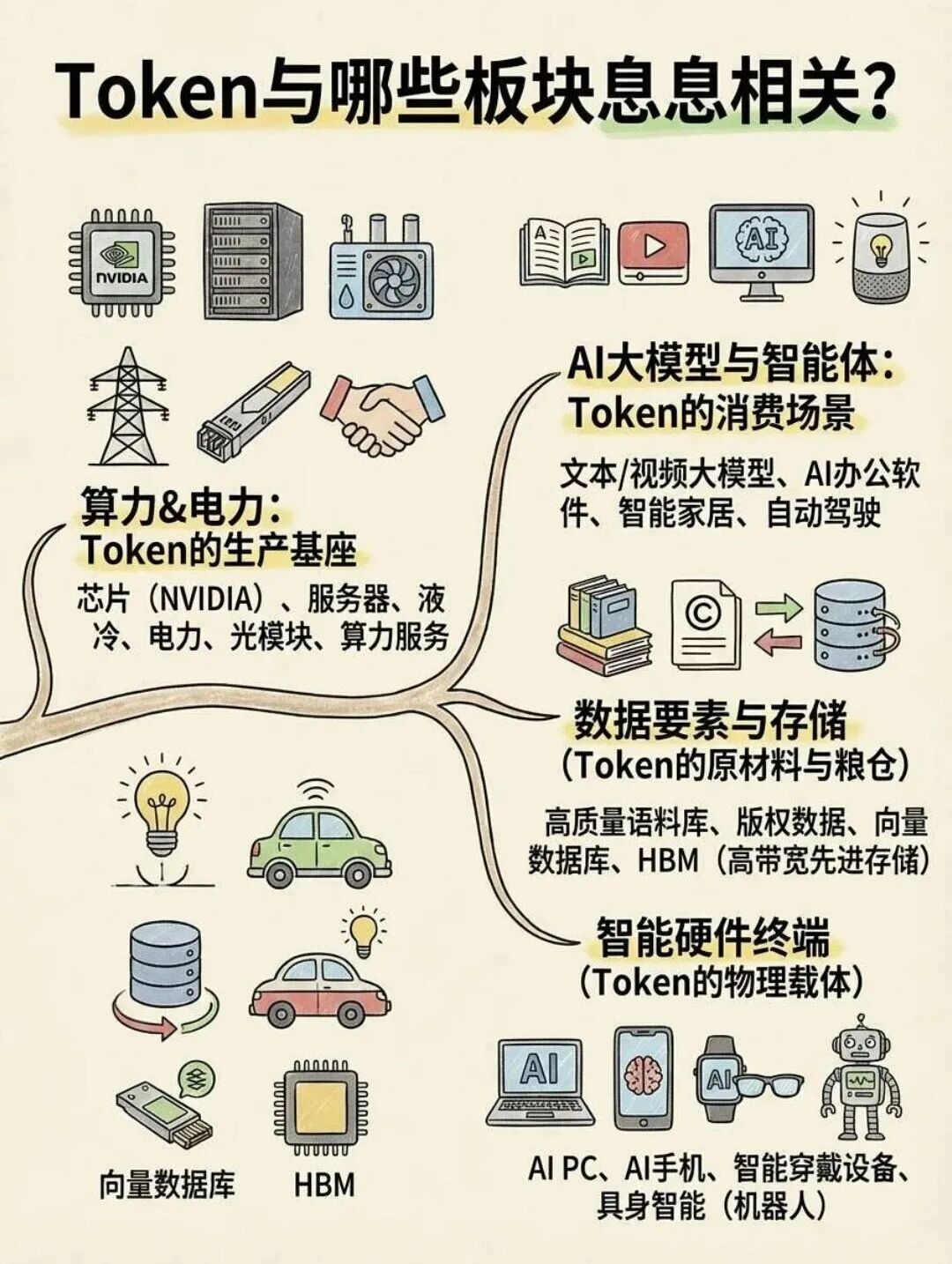
这最后一张被 CSDN 误伤不显示几次了。

end
全世界的聪明人,都该请大卫·休谟喝一杯
孤独大脑 2026 年 1 月 28 日 21:37 广东,
读他的书,仿佛置身于延绵的山海间。我不禁感慨,仅凭娓娓道来的文字,他竟能洞悉宇宙间最深处的秘密。
休谟说,人类的感官无法观测到所谓的“因果力”。例如台球撞击:
运动的 A 球撞向静止的 B 球。我们的感官捕捉到–A 在移动、两球接触、B 开始移动。
因为这些现象总是“恒常联结”,大脑便自动脑补出一根看不见的因果线,认为 A“导致”了 B 的运动。
休谟指出,你从未真正“看见”那股名为“因果”的力量,它本质上只是时间的先后、空间的邻接,以及相似性。
正如《三体》中的“农场主假设”:如果因果只是某种偶然的重复,那么我们引以为傲的科学大厦,可能只是建立在脆弱幻觉之上的沙堡。
休谟通过对因果的颠覆,引出了著名的“归纳法危机”:
所有的经验科学(包括物理学、经济学、甚至成功学)都建立在归纳法之上。既然归纳法在逻辑上无法自我证明,那么所有的科学定律本质上都是某种“高概率的猜想”。
此前,科学的任务是寻找绝对必然的自然规律。但休谟指出,你无论观测到多少次 A→B,也推不出下一次 A 必然导致 B。
这一思想启发了爱因斯坦。他坦言,阅读休谟关于因果和感知的批判,对他推翻“绝对时空观”至关重要。随后,波尔和海森堡的量子力学更是印证了休谟的预言:自然界底层不是绝对因果,而是概率波。
如今的大语言模型,本质上就是“超级休谟机”:通过海量的“恒常联结”数据,去预测下一个 Token 出现的概率。
休谟的思想,还顺着波普尔、索罗斯,再到塔勒布,成为《黑天鹅》理论的灵魂。
休谟宣称“理性是激情的奴隶”,这预判了现代经济学对“理性人”假设的抛弃。卡尼曼与塞勒的理论核心都在于:人类的决策深受情绪、直觉和习惯的影响,而非纯粹的逻辑计算。
休谟甚至附送了解药——习惯是人生的伟大指南。在不确定的世界里,既然逻辑无法提供绝对担保,我们就依靠感官经验与演化形成的直觉生活。
他深深影响了亚当·斯密,并预表了海耶克的“自发秩序”理论。
仅通过内省,休谟就发现了“自我”是一种幻觉。所谓的“自我”不过是“不同感知的束丛或集合…并处于永恒的流动和运动之中”。他还提出了类似于镜像神经元的“共情”机制。
我最晚领会的是休谟的“实然-应然问题”,即所谓“休谟断头台”:你不能因为自己对朋友两肋插刀,就认为他应该对你死心塌地。
在这不确定的世界里,我们该如何安放理性?休谟是这方面最好的老师。
Reference
- Explaining Tokens — the Language and Currency of AI | NVIDIA Blog
https://blogs.nvidia.com/blog/ai-tokens-explained/ - Explaining Tokens — the Language and Currency of AI | NVIDIA Blog
https://blogs.nvidia.com/blog/ai-tokens-explained/ - 黄仁勋讲了两小时 token,中文世界终于有一个像样的译名了!
https://mp.weixin.qq.com/s/jPupWpLvdBepWS7UptCKpA - 从不 1V1 开会、不搞接班那一套,黄仁勋最新访谈:10 万个智能体造不出下一个英伟达、AGI 已实现、OpenClaw就是Token时代的iPhone
https://mp.weixin.qq.com/s/tg7auPQ9iQ1qyimQrznJPQ - 科普:AI 里的 token 到底是个啥玩意?
https://mp.weixin.qq.com/s/yEvF-NvrvaF0PvR6n7t0yw - 全世界的聪明人,都该请大卫·休谟喝一杯
https://mp.weixin.qq.com/s/NciLkWaCIho8nCYTbDkj0A

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)