(Arxiv-2026)Helios:真正的实时长视频生成模型
Helios:真正的实时长视频生成模型
paper title:Helios: Real Real-Time Long Video Generation Model
paper是PKU发布在Arxiv 2026的工作
Code:链接
Abstract
我们提出了 Helios,这是首个可在单张 NVIDIA H100 GPU 上以 19.5 FPS 运行、并支持分钟级生成、同时达到强基线质量水平的 14B 视频生成模型。我们在三个关键维度上取得了突破:
(1) 对长视频漂移具有鲁棒性,无需常用的抗漂移启发式方法,例如 self-forcing、error-banks 或关键帧采样;
(2) 实现实时生成,无需依赖标准加速技术,例如 KV-cache、稀疏/线性注意力或量化;
(3) 训练时无需并行或分片框架,从而能够在 80 GB GPU 显存内同时容纳最多四个 14B 模型,并实现图像扩散规模的 batch size。
具体而言,Helios 是一个 14B 的自回归扩散模型,采用统一的输入表示,天然支持 T2V、I2V 和 V2V 任务。为缓解长视频生成中的漂移问题,我们刻画了典型失效模式,并提出了简单但有效的训练策略,在训练过程中显式模拟漂移,同时从源头上消除重复运动。为了提升效率,我们对历史上下文和带噪上下文进行了大幅压缩,并减少了采样步数,从而使其计算成本可与 1.3B 视频生成模型相当,甚至更低。
此外,我们还提出了基础设施层面的优化,同时加速推理与训练并降低显存占用。大量实验表明,Helios 在短视频和长视频生成上都持续优于以往方法。我们计划开源代码、基础模型和蒸馏模型,以支持社区的进一步发展。
1 Introduction
14B 实时长视频生成模型可以比 1.3B 更便宜、更快,同时保持更强性能
—— Helios 团队
在过去一年里,扩散 Transformer 显著推动了视频生成的发展,并展现出作为世界模型的潜力。随着视频质量提升,各类应用对实时生成的需求也不断增加,同时对视频时长提出了更高要求——尤其是在游戏引擎和交互式生成场景中。然而,主流模型距离“实时且无限生成”仍相去甚远:它们通常只能生成 5 5 5– 10 10 10 秒的视频,而即便是这样短的片段,也可能需要数十分钟来合成。
实时无限视频生成旨在以交互速度生成时间连贯、高质量的长视频,但这一目标在很大程度上仍未解决。一些社区方法声称实现了实时无限生成;然而,这些方法通常依赖 1.3 B 1.3\text{B} 1.3B 模型。此类模型容量有限,难以表达复杂运动,并且经常导致高频细节模糊。Krea-RealTime-14B 虽然增大了模型规模,但整体上仍沿用了相同范式,在单张 H100 GPU 上也只能达到 6.7 6.7 6.7 FPS。此外,这些方法往往依赖训练即推理式 rollout(Self-Forcing)来缓解漂移,这会显著增加训练成本,并促使人们进行步数蒸馏。更关键的是,对漂移的鲁棒性与训练时使用的 rollout 长度紧密耦合:当训练仅限于 5 5 5 秒片段时,推理一旦超过 5 5 5 秒范围,往往就会出现严重漂移。最后,这些基于因果掩码的长视频生成方法从根本上改变了双向预训练模型的推理机制,并可能限制可达到的质量上限。
为应对这些挑战,我们提出了 Helios,这是一套用于实时长视频生成的 14 B 14\text{B} 14B 方案,在单张 H100 GPU 上可达到最高 19.5 19.5 19.5 FPS——甚至比一些 1.3 B 1.3\text{B} 1.3B 模型还要快。具体而言:
(1) 面向无限生成,我们将长视频生成表述为通过统一历史注入(Unified History Injection)的无限视频续写,并引入表征控制(Representation Control)和引导注意力(Guidance Attention),以高效地将历史上下文注入到带噪上下文中。这一设计避免了因果掩码的局限,同时保留双向推理能力,并在单一架构中统一了 T2V、I2V 和 V2V。
(2) 面向高质量生成,我们识别出三种典型漂移表现:位置漂移、颜色漂移和复原漂移。基于这一分析,我们提出了简单但有效的策略,在训练中显式模拟漂移,从而在不依赖 self-forcing 或 error-banks 的情况下实现无漂移长视频生成。此外,我们还解决了旋转位置编码(RoPE)的周期性结构与多头注意力之间的冲突,从源头上消除了重复运动。
(3) 面向实时生成,为了去除历史上下文和带噪上下文中的冗余,我们提出了多项长期记忆分块(Multi-Term Memory Patchification)和金字塔统一预测校正器(Pyramid Unified Predictor Corrector),显著减少输入到 DiT 中的 token 数量。我们进一步将流匹配从“全分辨率噪声到全分辨率数据”的单一路径,重构为多条“低分辨率噪声到多分辨率数据”的轨迹,从而将计算量降低到与图像扩散模型相当、甚至更低的水平。我们还提出了对抗式分层蒸馏(Adversarial Hierarchical Distillation),这是一种纯教师强制的方法,仅使用自回归模型本身作为教师,将采样步数从 50 50 50 步减少到 3 3 3 步。结合面向显存效率和吞吐量的基础设施级优化,这些进展共同推动系统迈向实时视频生成。据我们所知,Helios 是首个在单张 H100 GPU 上达到 19.5 19.5 19.5 FPS 的 14 B 14\text{B} 14B 视频生成模型,在保持相当质量的同时实现了 128 × 128\times 128× 加速。
最后,为了解决实时长视频生成领域缺乏全面开源基准的问题,我们构建了 HeliosBench,其中包含 240 240 240 个提示词,覆盖四种时长区间:极短( 81 81 81 帧)、短( 240 240 240 帧)、中( 720 720 720 帧)和长( 1440 1440 1440 帧)。部分案例展示及基准结果见图 1 1 1、图 2 2 2 和图 3 3 3。
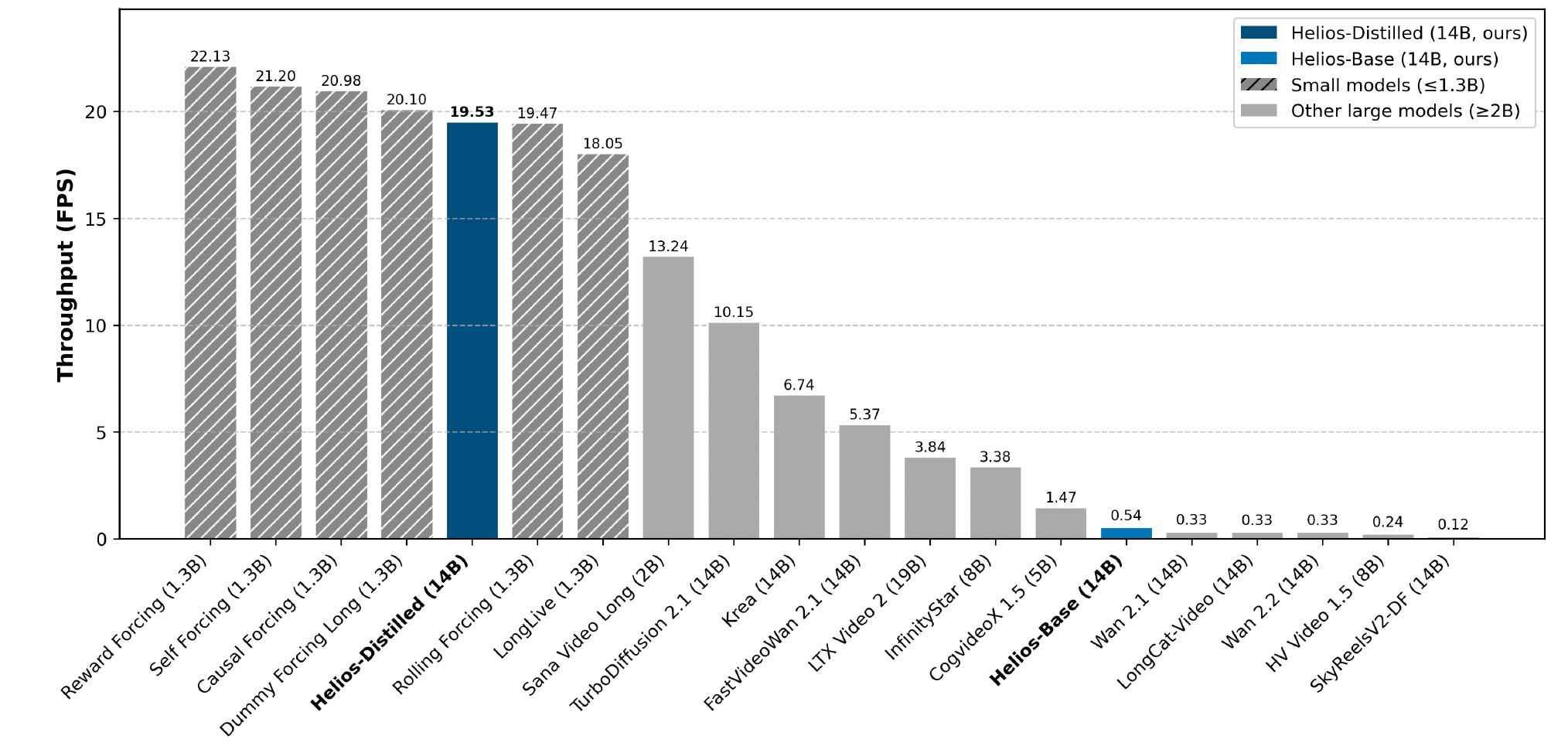
图1:在单张 H100 上,各种视频生成模型的端到端吞吐率(FPS)。结果是在相同分辨率下测得,并启用了所有官方加速技术,包括 FlashAttention、torch compile 和 KV-cache。Helios 相比同等规模的模型明显更快,并且达到了更小型蒸馏模型的速度水平。
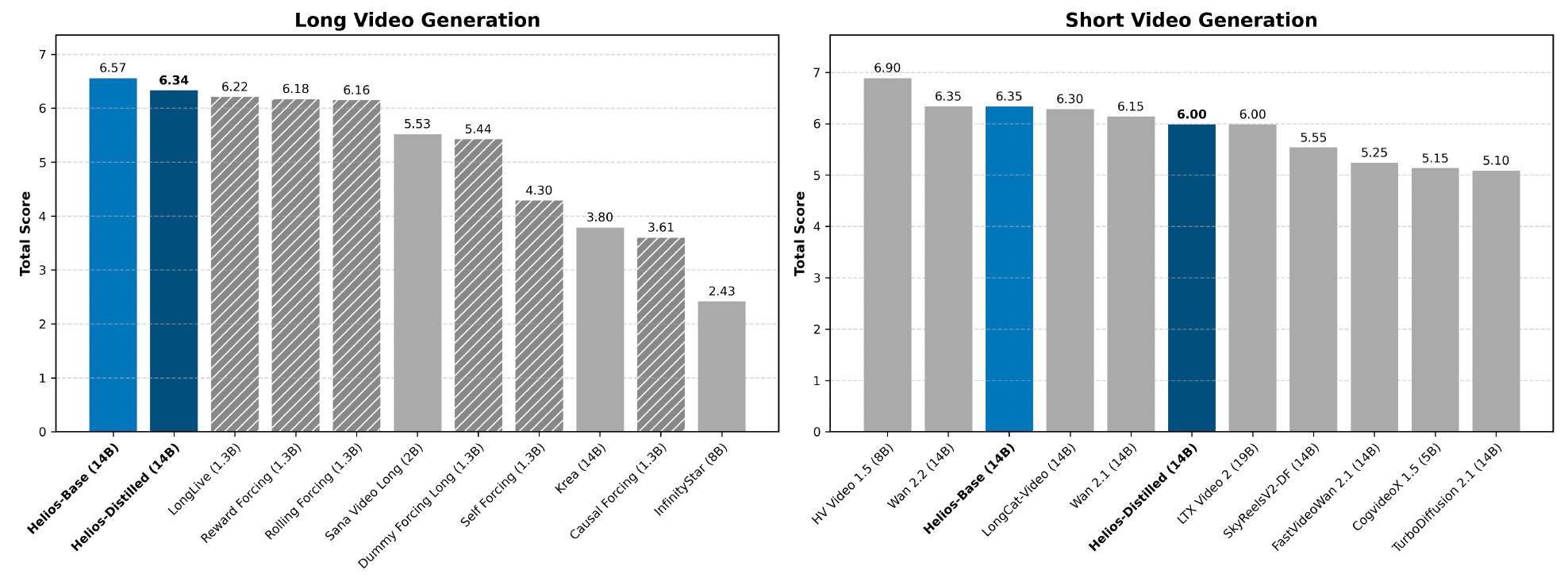
图2:Helios 及其对比方法的基准性能。无论是在短视频生成还是长视频生成任务中,Helios 都持续优于现有的蒸馏模型,同时其性能与基础模型相当。

图3:Helios 生成的无限视频展示。尽管其开销与 1.3 B 1.3\text{B} 1.3B 模型 [59, 60, 90, 100, 126] 相当,Helios 在视觉质量、文本对齐以及运动动态方面仍然表现出色。
我们的贡献可以概括如下:
• 在不使用常见抗漂移策略(例如 self-forcing、error-banks、关键帧采样或反向采样)的情况下,Helios 能够生成分钟级视频,并保持高质量和强时间连贯性。
• 在不使用标准加速技术(例如 KV-cache、因果掩码、稀疏/线性注意力、TinyVAE、渐进式噪声调度、隐藏状态缓存或量化)的情况下,Helios 在单张 H100 GPU 上实现了 14 B 14\text{B} 14B 视频生成模型端到端推理 19.5 19.5 19.5 FPS。
• 我们提出了一系列优化,同时提升训练与推理吞吐量并降低显存占用。这些改动使得在无需并行或分片基础设施的前提下训练 14 B 14\text{B} 14B 视频生成模型成为可能,并实现与图像模型相当的 batch size。
• 为解决实时长视频生成缺乏标准化基准的问题,我们发布了 HeliosBench。大量实验表明,Helios 在质量上显著优于现有方法,同时推理速度甚至超过一些 1.3 B 1.3\text{B} 1.3B 蒸馏模型。
2 Related Work
2.1 Long Video Generation
大多数视频生成模型仍然局限于短片段(通常为 5 5 5– 10 10 10 秒),而在不发生漂移的情况下扩展到更长时长仍然颇具挑战。早期方法如 FreeNoise [70] 和 FIFO-Diffusion [40] 采用了无需训练的噪声重调度。随后的方法,包括 Diffusion Forcing [7] 和 Rolling Diffusion [71],在训练期间对整个序列注入逐帧独立噪声,以模拟推理时上下文污染,从而通过自回归扩散 [77] 实现长视频合成。后续工作 [8, 84, 86] 又将这一范式扩展到更大规模的模型。FramePack [116] 训练了一个下一帧预测模型,并引入反向采样以减少漂移。Self-Forcing [34] 采用因果注意力 [107],并提出了一种训练即推理的 rollout 策略来提升质量。最近的进展还进一步探索了误差库机制 [28, 45, 69]、类 GPT 架构 [13, 18, 58]、关键帧采样 [33, 96, 124]、测试时训练 [14, 128] 以及多镜头生成 [6, 29, 37]。尽管取得了这些进展,这些方法往往仍会在超出训练时域后表现出明显漂移,或者依赖代价高昂的长视频微调,这限制了它们在长视频生成中的实际应用价值。
2.2 Real-Time Video Generation
长视频生成需要高效的架构与推理流水线。例如,使用 Wan2.1 14B [90] 时,在单张 NVIDIA A100 GPU 上生成一个 5 5 5 秒视频通常需要约 50 50 50 分钟才能达到可接受的质量。常见的加速方向包括并行化、蒸馏 [52, 61, 106]、线性注意力 [9, 82, 101] 或稀疏注意力 [46, 99, 114]、隐藏状态缓存 [10, 55, 64] 以及量化 [95, 113, 115]。现有的实时长视频系统大多基于蒸馏;例如,[11, 26, 59, 60, 100] 沿用了 CausVid [107] 的路线,并使用 DMD [105] 将采样步数从 50 50 50 步减少到 4 4 4 步,同时结合类似 Self-Forcing [34] 的 rollout 策略来缩小训练与推理之间的差距。然而,这些方法通常建立在相对较小的骨干模型之上(例如 Wan2.1 1.3B [90]),这限制了它们对复杂运动的建模能力以及对高频细节的保留能力。此外,尽管 Krea [67] 报告称在单张 NVIDIA B200 GPU 上可达到 11 11 11 FPS,但其在 H100 GPU 上的速度会下降到 6.7 6.7 6.7 FPS,且生成结果存在严重漂移,这对实时交互式生成而言仍然是一个突出问题。另有一些工作声称实现了实时,但实际上需要 8 8 8 张 GPU [23, 78, 83]。
3 Helios
(1)面向无限生成,我们提出了统一历史注入(Unified History Injection),将一个双向预训练模型 [90] 转化为自回归生成器,从而在统一框架下同时支持文生视频(T2V)、图生视频(I2V)和视频生视频(V2V)。
(2)面向高质量生成,我们提出了 Easy Anti-Drifting 来缓解漂移,从而在无需低效的 self-forcing [34] 或 error-bank [45] 的情况下,实现高质量的分钟级视频生成。
(3)面向实时生成,我们进一步提出了深度压缩流(Deep Compression Flow),同时减少视觉 token 数量和采样步数,从而使 14B 模型能够在单张 GPU 上实现实时生成。
3.1 Unified History Injection
在本节中,我们介绍如何将一个原本仅限于固定长度生成的双向模型,扩展为能够合成任意时长视频的模型。整体架构如图 4 4 4 所示。
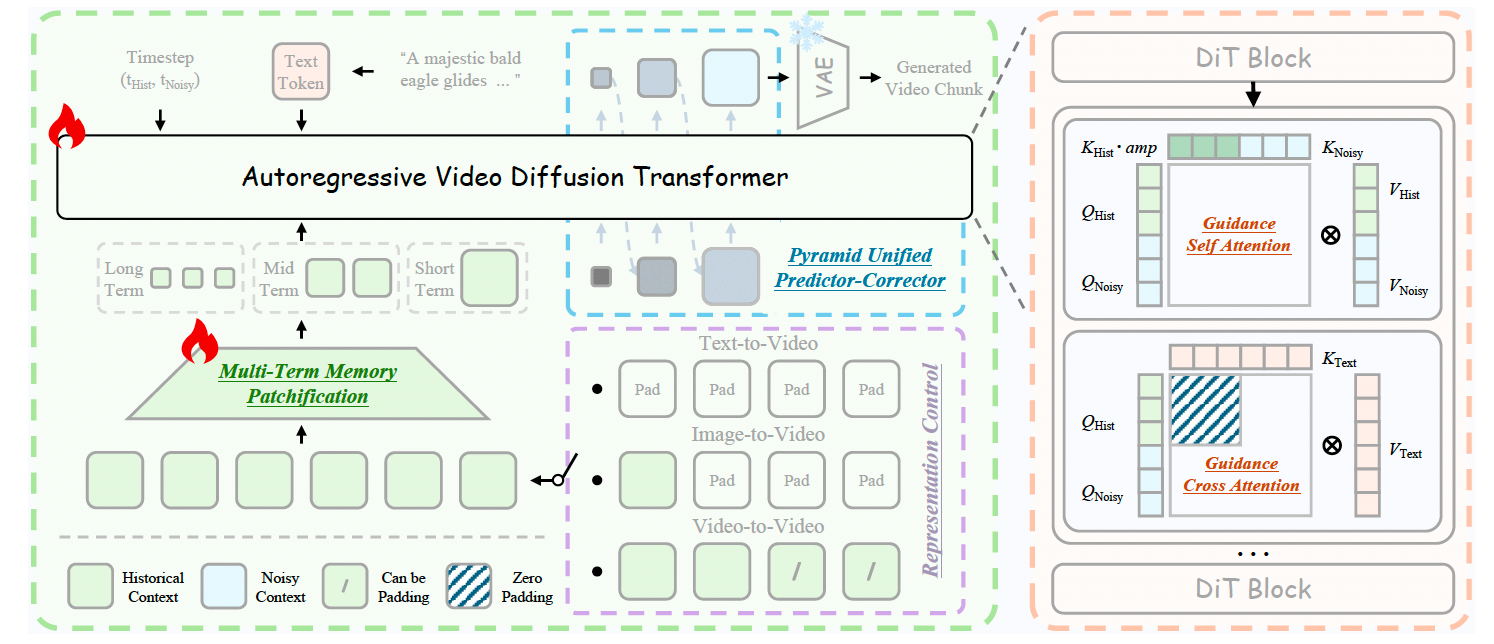
图4:Helios 的架构。Helios 是一个采用引导注意力模块(Guidance Attention blocks)构建的自回归视频扩散 Transformer。它通过多项长期记忆分块(Multi-Term Memory Patchification)和金字塔统一预测校正器(Pyramid Unified Predictor Corrector)对历史上下文和带噪上下文进行压缩,以降低计算开销,同时借助表征控制(Representation Control)在统一框架下整合文生视频(T2V)、图生视频(I2V)和视频生视频(V2V)任务。
3.1.1 Representation Control
以往工作通常通过将 diffusion forcing [7, 75] 与因果掩码 [107] 相结合,把双向模型转变为自回归生成器。然而,由此形成的逐帧噪声空间极其庞大,这会拖慢优化过程,并且往往需要进行步数蒸馏 [105, 106, 121]。这种方法之所以不理想,主要有两个原因:(i)推理过程与预训练模型的原始方式存在显著偏离,从而限制了可达到的性能;(ii)蒸馏模型会阻碍社区中的进一步开发。
我们通过表征控制(Representation Control)来解决这些问题,它将长视频生成表述为视频续写。如图 4 4 4 所示,输入由历史上下文 X H i s t ∈ R B × C × T H i s t × H × W X_{\mathrm{Hist}}\in\mathbb{R}^{B\times C\times T_{\mathrm{Hist}}\times H\times W} XHist∈RB×C×THist×H×W 和带噪上下文 X N o i s y ∈ R B × C × T N o i s y × H × W X_{\mathrm{Noisy}}\in\mathbb{R}^{B\times C\times T_{\mathrm{Noisy}}\times H\times W} XNoisy∈RB×C×TNoisy×H×W 的拼接组成,其中 B B B、 C C C、 T T T、 H H H 和 W W W 分别表示 batch size、通道数、帧数、高度和宽度。我们在训练和推理阶段都保持 T H i s t T_{\mathrm{Hist}} THist 和 T N o i s y T_{\mathrm{Noisy}} TNoisy 固定,并满足 T H i s t ≫ T N o i s y T_{\mathrm{Hist}}\gg T_{\mathrm{Noisy}} THist≫TNoisy。模型在以 X H i s t X_{\mathrm{Hist}} XHist 为条件的情况下对 X N o i s y X_{\mathrm{Noisy}} XNoisy 进行去噪,以生成时间上连贯的续写内容,从而实现任意长视频的生成。表征控制通过 X H i s t X_{\mathrm{Hist}} XHist 的表示形式实现任务的自动切换:如果 X H i s t X_{\mathrm{Hist}} XHist 全为零,则模型执行文生视频(T2V);如果只有最后一帧非零,则执行图生视频(I2V);否则执行视频生视频(V2V)。
3.1.2 Guidance Attention
历史上下文和带噪上下文具有不同的统计特性,因此应当区别对待。历史上下文包含已经与文本提示对齐的干净内容;它不应被去噪,也应当对 X N o i s y X_{\mathrm{Noisy}} XNoisy保持不敏感。相反,它的作用是引导 X N o i s y X_{\mathrm{Noisy}} XNoisy的去噪。我们通过两种方式显式地强化这种分离。首先,在整个去噪过程中,我们将 X H i s t X_{\mathrm{Hist}} XHist的时间步固定为 0 0 0,表示它始终保持干净且无噪声。其次,受[97, 123]启发,我们引入引导注意力(Guidance Attention),以增强历史上下文对未来帧生成的影响:
在自注意力层中,我们分别为带噪上下文和历史上下文计算 query、key 和 value 张量,分别记为 Q N o i s y , K N o i s y , V N o i s y Q_{\mathrm{Noisy}},K_{\mathrm{Noisy}},V_{\mathrm{Noisy}} QNoisy,KNoisy,VNoisy以及 Q H i s t , K H i s t , V H i s t Q_{\mathrm{Hist}},K_{\mathrm{Hist}},V_{\mathrm{Hist}} QHist,KHist,VHist。为了在保留有信息量的历史的同时抑制冗余或有害信号,我们引入按头的放大 token a m p amp amp 来调制历史 key。该设计会针对每个注意力头选择性地增强或减弱历史信息,从而鼓励模型聚焦于最具判别性的成分:
X S e l f = A t t e n t i o n ( [ Q N o i s y , Q H i s t ] , [ K N o i s y , K H i s t ⋅ a m p ] , [ V N o i s y , V H i s t ] ) X_{\mathrm{Self}}=\mathrm{Attention}([Q_{\mathrm{Noisy}},Q_{\mathrm{Hist}}],[K_{\mathrm{Noisy}},K_{\mathrm{Hist}}\cdot amp],[V_{\mathrm{Noisy}},V_{\mathrm{Hist}}]) XSelf=Attention([QNoisy,QHist],[KNoisy,KHist⋅amp],[VNoisy,VHist])
其中 [ ⋅ ] [\cdot] [⋅]表示拼接, ⋅ \cdot ⋅表示乘法。在交叉注意力中,我们将来自文本提示的语义信息注入模型。由于 X H i s t X_{\mathrm{Hist}} XHist已经整合了前面步骤中的语义信息,再次注入相同语义是冗余的。因此,我们只对 X N o i s y X_{\mathrm{Noisy}} XNoisy应用交叉注意力:
X C r o s s = A t t e n t i o n ( Q N o i s y , K T e x t , V T e x t ) X_{\mathrm{Cross}}=\mathrm{Attention}(Q_{\mathrm{Noisy}},K_{\mathrm{Text}},V_{\mathrm{Text}}) XCross=Attention(QNoisy,KText,VText)
其中 K T e x t K_{\mathrm{Text}} KText和 V T e x t V_{\mathrm{Text}} VText是编码后文本提示的 key 和 value 张量。
3.2 Easy Anti-Drifting
在本节中,我们总结了漂移的三种常见表现形式,如图 5 5 5 所示,并提出了一些简单但有效的技术,用于缓解长视频生成中的漂移和重复运动问题,而无需依赖 self-forcing [34]、error-bank [45] 或其他常用的抗漂移策略。

图5:长视频生成中三种具有代表性的漂移模式可视化。
3.2.1 Relative RoPE
漂移的一个主要来源是位置编码,我们将其称为位置漂移(Position Shift)。在实践中,扩散模型通常在推理时域与训练时域一致时表现最佳;一旦改变视频长度,模型就会暴露于未见过的时间位置,这会显著降低生成质量。现有长视频方法通常沿时间维使用绝对 RoPE。举例来说,生成一个 1440 1440 1440 帧视频时会使用索引 0 : 1399 0\!:\!1399 0:1399,而训练通常只限于短片段(例如 5 5 5 秒),因此即使采用了复杂的缓解方法,超出训练时域后的漂移仍然很可能发生。在更长视频上训练是一种直接但代价高昂的补救办法 [11, 59, 100]。
此外,绝对时间索引还可能导致生成过程反复跳回到早期位置,从而引起突兀的场景重置和周期性模式,我们将这种现象称为重复运动(repetitive motion)[12]。为了解决这些问题,我们提出了相对 RoPE(Relative RoPE)。无论目标视频长度是多少,我们都将 X H i s t X_{\mathrm{Hist}} XHist的时间索引范围约束为 0 : T H i s t 0\!:\!T_{\mathrm{Hist}} 0:THist,并将 X N o i s y X_{\mathrm{Noisy}} XNoisy分配到 T H i s t : T H i s t + T N o i s y T_{\mathrm{Hist}}\!:\!T_{\mathrm{Hist}}+T_{\mathrm{Noisy}} THist:THist+TNoisy。这种相对索引方式能够在任意长度下实现稳定生成,同时缓解 RoPE 周期性与多头注意力之间的相互作用,从源头上减少重复运动。
3.2.2 First-Frame Anchor

图6:正常视频与漂移视频在饱和度、审美评分和 RGB 统计量上的时间变化趋势。正常视频较为稳定,而漂移视频起初沿着相似轨迹变化,但随后会突然发生偏移,并持续处于不稳定状态。
漂移还常常表现为颜色漂移(Color Shift),并且随着生成视频变长而变得更加严重。为了刻画这一现象,我们通过跟踪随时间变化的饱和度、审美评分 [73] 以及 RGB 统计量(均值和方差),分析正常视频与发生漂移的视频。如图 6 6 6 所示,正常视频的统计量相对稳定,而漂移视频起初遵循相似的轨迹,但在某个时刻之后会发生剧烈偏移,并在此后持续不稳定。值得注意的是,漂移很少在生成开始阶段发生。受这一观察启发,我们在训练和推理过程中始终将第一帧保留在 X H i s t X_{\mathrm{Hist}} XHist中。作为一个全局视觉锚点,这一帧能够约束后续片段中的分布偏移,稳定随时间变化的统计量,并在自回归外推过程中有效缓解颜色漂移。
3.2.3 Frame-Aware Corrupt
漂移并不局限于颜色漂移;它也可能表现为图像复原伪影,例如模糊和噪声 [45]。我们将这一现象称为复原漂移(Restoration Shift)。这种偏移之所以出现,是因为模型在训练时使用的是干净视频,但在推理时却需要把自身并不完美的输出作为历史条件;因此,微小误差会随着时间不断累积并被放大。为了提升模型对不完美历史的鲁棒性,我们提出了逐帧感知扰动(Frame-Aware Corrupt),受 [7, 75] 启发,它在训练期间模拟真实的历史漂移。
具体来说,对于每一帧历史帧,我们独立采样以下扰动之一:
(i) 以概率 p c p_c pc,对帧曝光进行调整,调整幅度从 [ a min , a max ] [a_{\min},a_{\max}] [amin,amax]中均匀采样;
(ii) 以概率 p a p_a pa,添加噪声,噪声强度从 [ b min , b max ] [b_{\min},b_{\max}] [bmin,bmax]中均匀采样;
(iii) 以概率 p b p_b pb,先下采样再上采样,下采样因子从 [ c min , c max ] [c_{\min},c_{\max}] [cmin,cmax]中均匀采样;
(iv) 以概率 p d p_d pd,保持该潜变量为干净状态,
其中 p a + p b + p c + p d = 1 p_a+p_b+p_c+p_d=1 pa+pb+pc+pd=1。这些扰动是按帧独立采样的,因此包含 T H i s t T_{\mathrm{Hist}} THist帧的历史将产生 T H i s t T_{\mathrm{Hist}} THist个独立的损坏决策,这对于长视频稳定性至关重要。
3.3 Deep Compression Flow - From Token View
在本节中,我们从以 token 为中心的视角来介绍深度压缩流(Deep Compression Flow)。我们的目标是将一个 14B 视频生成模型在 token 层面的计算量降低到与 1.3B 模型相当的水平。
3.3.1 Multi-Term Memory Patchification
为了实现实时生成,我们通过多项长期记忆分块(Multi-Term Memory Patchification)来减少历史上下文 X H i s t X_{\mathrm{Hist}} XHist中的冗余。受先前工作 [25, 116, 125] 启发,我们利用了一个简单观察:在自回归视频生成中,对未来帧的预测主要依赖于时间上邻近的历史,以建模局部运动和短程连续性,而较远的历史主要提供粗粒度的全局上下文。
基于这一观察,我们采用了一个分层上下文窗口,将 X H i s t X_{\mathrm{Hist}} XHist划分为三部分——短期、中期和长期——分别包含 T 1 T_1 T1、 T 2 T_2 T2和 T 3 T_3 T3帧,其中 0 < T 1 < T 2 < T 3 0<T_1<T_2<T_3 0<T1<T2<T3。对于每一部分,我们施加一个独立的卷积核 ( p t ( i ) , p h ( i ) , p w ( i ) ) (p_t^{(i)},p_h^{(i)},p_w^{(i)}) (pt(i),ph(i),pw(i))来压缩时空 token,其中 i ∈ { 1 , 2 , 3 } i\in\{1,2,3\} i∈{1,2,3}表示这三部分。我们让压缩率随着时间距离增大而提高,例如, p t ( 1 ) < p t ( 2 ) < p t ( 3 ) p_t^{(1)}<p_t^{(2)}<p_t^{(3)} pt(1)<pt(2)<pt(3), p h ( 1 ) < p h ( 2 ) < p h ( 3 ) p_h^{(1)}<p_h^{(2)}<p_h^{(3)} ph(1)<ph(2)<ph(3),并且 p w ( 1 ) < p w ( 2 ) < p w ( 3 ) p_w^{(1)}<p_w^{(2)}<p_w^{(3)} pw(1)<pw(2)<pw(3)。经过分块后,token 数量变为:
L s h o r t = T 1 H W p t ( 1 ) p h ( 1 ) p w ( 1 ) , L m i d = T 2 H W p t ( 2 ) p h ( 2 ) p w ( 2 ) , L l o n g = T 3 H W p t ( 3 ) p h ( 3 ) p w ( 3 ) . L_{\mathrm{short}}=\frac{T_1HW}{p_t^{(1)}p_h^{(1)}p_w^{(1)}},\qquad L_{\mathrm{mid}}=\frac{T_2HW}{p_t^{(2)}p_h^{(2)}p_w^{(2)}},\qquad L_{\mathrm{long}}=\frac{T_3HW}{p_t^{(3)}p_h^{(3)}p_w^{(3)}}. Lshort=pt(1)ph(1)pw(1)T1HW,Lmid=pt(2)ph(2)pw(2)T2HW,Llong=pt(3)ph(3)pw(3)T3HW.
于是, X H i s t X_{\mathrm{Hist}} XHist中的 token 总数为:
L t o t a l = H W ( T 1 p t ( 1 ) p h ( 1 ) p w ( 1 ) + T 2 p t ( 2 ) p h ( 2 ) p w ( 2 ) + T 3 p t ( 3 ) p h ( 3 ) p w ( 3 ) ) . L_{\mathrm{total}}= HW\left( \frac{T_1}{p_t^{(1)}p_h^{(1)}p_w^{(1)}} + \frac{T_2}{p_t^{(2)}p_h^{(2)}p_w^{(2)}} + \frac{T_3}{p_t^{(3)}p_h^{(3)}p_w^{(3)}} \right). Ltotal=HW(pt(1)ph(1)pw(1)T1+pt(2)ph(2)pw(2)T2+pt(3)ph(3)pw(3)T3).
如图 7 7 7 所示,这一设计使得 L t o t a l L_{\mathrm{total}} Ltotal与目标视频长度无关,保持为常数。因此,在固定 token 预算下,模型能够保留显著更长的历史,同时降低训练和推理期间的计算成本与显存占用。在训练过程中,我们会随机将历史上下文中的一定比例置零,以模拟推理时的 T2V、I2V 和 V2V 场景。
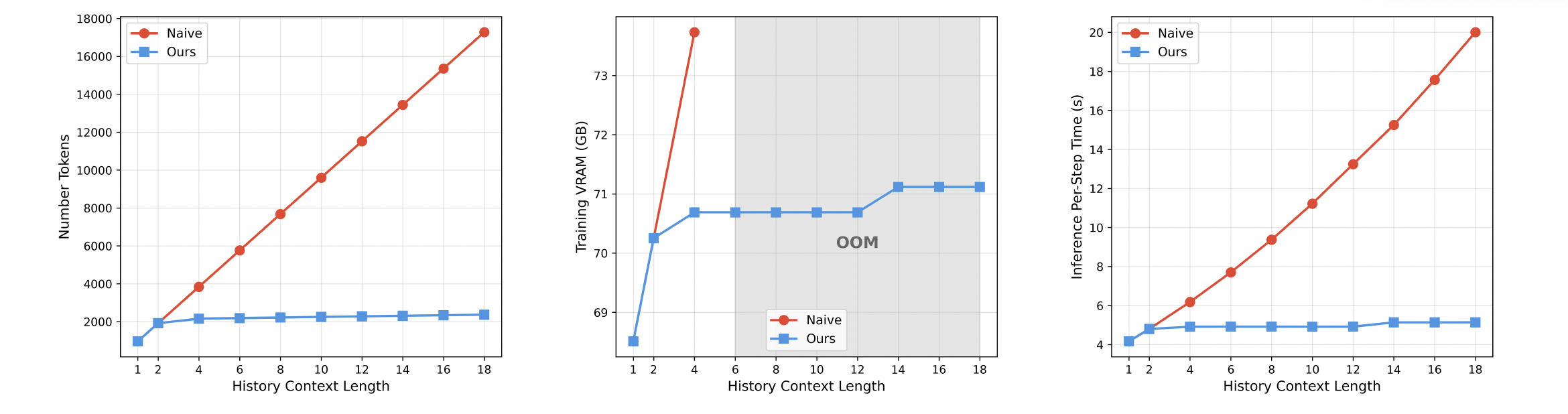
图7:利用多项长期记忆分块(Multi-Term Memory Patchification)实现开销降低。分层历史窗口采用逐步增大的卷积核,在扩展上下文长度的同时保持 token 预算恒定。
3.3.2 Pyramid Unified Predictor Corrector
为了减少带噪上下文 X N o i s y X_{\mathrm{Noisy}} XNoisy中的冗余,我们提出了金字塔统一预测校正器(Pyramid Unified Predictor Corrector),这是统一预测校正器(UniPC)采样器 [119] 的一个多尺度变体,如图 8 8 8 所示。受先前工作 [24, 38, 58, 87, 88] 启发,我们观察到,早期采样步骤主要受强噪声主导,因此主要决定全局结构(例如布局和颜色);而后期步骤则主要细化局部细节(例如边缘和纹理)。据此,我们采用由粗到细的调度方式:在早期阶段,我们在低分辨率潜空间中采样,并逐步过渡到全分辨率。具体而言,Helios 学习多尺度速度场,用以定义一个基于 ODE 的生成过程。我们从低分辨率高斯噪声 ϵ ∈ R B × C × T × h × w \epsilon\in\mathbb{R}^{B\times C\times T\times h\times w} ϵ∈RB×C×T×h×w出发,积分该 ODE,得到一条由粗到细的轨迹,并逐步上采样,最终得到全分辨率的干净样本 x 0 ∈ R B × C × T × H × W x_0\in\mathbb{R}^{B\times C\times T\times H\times W} x0∈RB×C×T×H×W,其中 h ≪ H h\ll H h≪H且 w ≪ W w\ll W w≪W。
训练。我们将生成过程划分为 K K K个空间分辨率逐步升高的阶段,其中第 k k k个阶段在分辨率 ( h k , w k ) (h^k,w^k) (hk,wk)下运行。为了学习从尺度 k − 1 k-1 k−1到尺度 k k k的直接传输方向,我们构造一条线性插值路径,作为这两个尺度之间的连续过渡:
x t k = ( 1 − λ t ) x k + λ t U p ( x k − 1 ) , x_t^k=(1-\lambda_t)x^k+\lambda_t\,\mathrm{Up}(x^{k-1}), xtk=(1−λt)xk+λtUp(xk−1),
其中 k ∈ { 1 , 2 , … , K } k\in\{1,2,\ldots,K\} k∈{1,2,…,K}, λ t ∈ [ 0 , 1 ] \lambda_t\in[0,1] λt∈[0,1]控制噪声水平。我们在各个阶段使用相同的 λ t \lambda_t λt调度,以保证跨尺度的流匹配保持一致。与 λ t \lambda_t λt相关联的时间步 T ∈ [ 0 , 1000 ] T\in[0,1000] T∈[0,1000]被划分为阶段边界 T 0 = 1000 > T 1 > ⋯ > T K = 0 T_0=1000>T_1>\cdots>T_K=0 T0=1000>T1>⋯>TK=0,因此第 k k k个阶段仅在区间 [ T k , T k − 1 ] [T_k,T_{k-1}] [Tk,Tk−1]上运行。对于边界条件,当 k = 1 k=1 k=1时,我们从噪声开始,即 U p ( x k − 1 ) = ϵ \mathrm{Up}(x^{k-1})=\epsilon Up(xk−1)=ϵ,其中 ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I);当 k = K k=K k=K时,我们恢复出全分辨率样本,即 x k = x 0 x^k=x_0 xk=x0。沿着这条线性路径,真实速度为常数:
v k = x k − U p ( x k − 1 ) . v^k=x^k-\mathrm{Up}(x^{k-1}). vk=xk−Up(xk−1).
我们将速度场参数化为 u θ k ( ⋅ ) u_\theta^k(\cdot) uθk(⋅),并最小化如下速度匹配目标:
L = E k , λ t , x t k , U p ( x k − 1 ) , y [ ∥ u θ k ( x t k , y , λ t , k ) − v k ∥ 2 2 ] , \mathcal{L}= \mathbb{E}_{k,\lambda_t,x_t^k,\mathrm{Up}(x^{k-1}),y} \left[ \left\| u_\theta^k(x_t^k,y,\lambda_t,k)-v^k \right\|_2^2 \right], L=Ek,λt,xtk,Up(xk−1),y[ uθk(xtk,y,λt,k)−vk 22],
其中 y y y表示条件输入。在实践中,我们设置 K = 3 K=3 K=3,以平衡质量和效率。
推理。类似地,我们将采样过程也划分为 K K K个阶段,并为每个阶段分配 ( N 1 , N 2 , … , N K ) (N_1,N_2,\ldots,N_K) (N1,N2,…,NK)个步骤,因此总步数为 N = ∑ k = 1 K N k N=\sum_{k=1}^K N_k N=∑k=1KNk。在第 k k k个阶段,我们在离散时间步 { t k n } n = 0 N k \{t_k^n\}_{n=0}^{N_k} {tkn}n=0Nk上采样,并按如下方式更新:
x t k n k = x t k n − 1 k + u θ k ( x t k n − 1 k , y , t k n − 1 ) ( t k n − t k n − 1 ) . x_{t_k^n}^k= x_{t_k^{n-1}}^k + u_\theta^k\!\left(x_{t_k^{n-1}}^k,y,t_k^{n-1}\right) \left(t_k^n-t_k^{n-1}\right). xtknk=xtkn−1k+uθk(xtkn−1k,y,tkn−1)(tkn−tkn−1).
当从阶段 k − 1 k-1 k−1过渡到阶段 k k k时,若直接对终止状态进行上采样,可能会引入伪影并破坏路径连续性。遵循 PyramidFlow [38],我们使用最近邻插值对终止状态进行上采样,然后对注入的噪声及其协方差进行校正,以维持跨尺度的一致分布。从计算角度看,单尺度、共 N N N步的推理开销为 O ( H W N ) \mathcal{O}(HWN) O(HWN)。相比之下,多尺度采样将步骤分布到多个阶段中,并在早期阶段处理更少的 token。在标准金字塔结构下(例如每个阶段都将分辨率减半),处理的 token 总数为:
( H × W + H 2 × W 2 + H 4 × W 4 + ⋯ + H 2 K − 1 × W 2 K − 1 ) × N K . \left( H\times W + \frac{H}{2}\times\frac{W}{2} + \frac{H}{4}\times\frac{W}{4} + \cdots+ \frac{H}{2^{K-1}}\times\frac{W}{2^{K-1}} \right)\times\frac{N}{K}. (H×W+2H×2W+4H×4W+⋯+2K−1H×2K−1W)×KN.
最后,UniPC [119] 会复用前几步的预测结果来校正当前更新。然而,由于预测张量在不同阶段之间的形状会发生变化,缓存的预测无法跨阶段过渡继续复用。因此,我们在每次阶段切换时重置状态缓冲区,并在新阶段内重新累积所需状态;从经验上看,这样既能保持采样稳定性,又能避免跨尺度校正伪影。
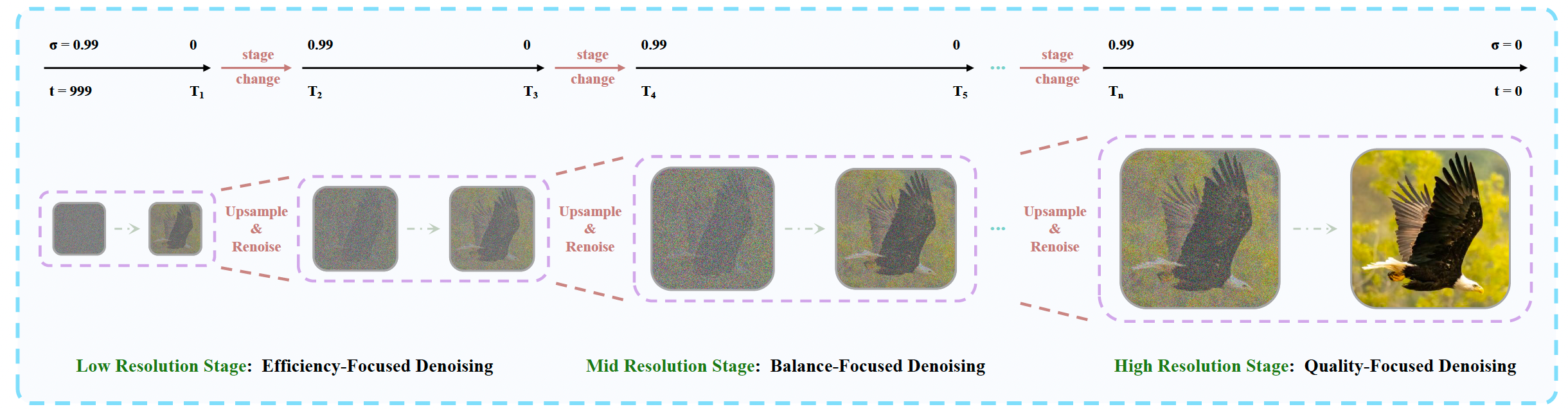
图8:金字塔统一预测校正器(Pyramid Unified Predictor Corrector)示意图。该过程由三个阶段组成:(i)低阶段侧重效率;(ii)中阶段平衡质量与效率;(iii)高阶段优先保证质量。
3.4 Deep Compression Flow - From Step View
3.4.1 Problem Formulation
步数蒸馏对于构建实时生成模型至关重要。在现有方法 [52, 61, 72, 121] 中,分布匹配蒸馏(Distribution Matching Distillation, DMD)[105] 已被广泛采用并相当成熟。在 DMD 中,我们首先采样噪声 ϵ \epsilon ϵ并将其输入一个少步数生成器 G θ G_\theta Gθ。利用 x 0 x_0 x0预测和反向模拟,生成器产生一个干净样本 x 0 x_0 x0。随后,我们采样一个噪声水平 λ τ ∼ U [ 0 , 1 ] \lambda_\tau\sim\mathcal{U}[0,1] λτ∼U[0,1],并对 x 0 x_0 x0加扰,得到带噪样本 x τ x_\tau xτ。接着,我们分别使用真实分数估计器 p r e a l p_{\mathrm{real}} preal和伪分数估计器 p f a k e p_{\mathrm{fake}} pfake对 x τ x_\tau xτ进行评估,得到分数 s r e a l s_{\mathrm{real}} sreal和 s f a k e s_{\mathrm{fake}} sfake。真实分数通过无分类器引导(classifier-free guidance)结合条件预测与无条件预测来计算,即 C F G ( s r e a l c o n d , s r e a l u n c o n d ) \mathrm{CFG}(s_{\mathrm{real}}^{\mathrm{cond}},s_{\mathrm{real}}^{\mathrm{uncond}}) CFG(srealcond,srealuncond);而伪分数只使用条件分支,即 s f a k e c o n d s_{\mathrm{fake}}^{\mathrm{cond}} sfakecond。二者之差定义了用于更新 G θ G_\theta Gθ的分布匹配梯度。此外,我们还在 x τ x_\tau xτ上使用流匹配损失 L F l o w \mathcal{L}_{\mathrm{Flow}} LFlow来训练 p f a k e p_{\mathrm{fake}} pfake,以提升稳定性。然而,Helios 改变了采样过程,因此标准流程无法直接适用。为此,我们提出了对抗式分层蒸馏(Adversarial Hierarchical Distillation),这是一个基于 DMD 的框架(见图 9 9 9),并包含以下改进。
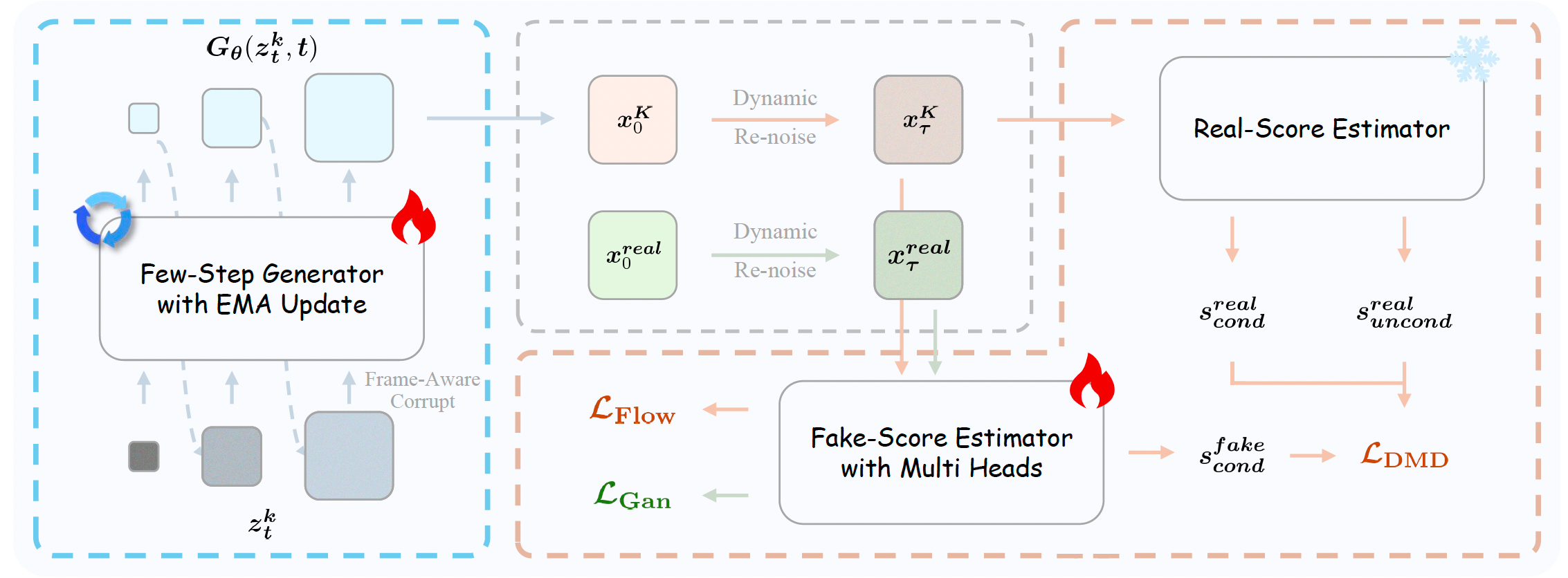
图9:对抗式分层蒸馏(Adversarial Hierarchical Distillation)的流程。该框架以 DMD [105] 为基础,并引入了若干改进,例如纯教师强制(Pure Teacher Forcing)、分阶段反向模拟(Staged Backward Simulation)、由粗到细学习(Coarse-to-Fine Learning)以及对抗式后训练(Adversarial Post-Training)。
3.4.2 Adversarial Hierarchical Distillation
采用自回归教师的纯教师强制。现有将 DMD 应用于实时长视频生成的方法 [11, 34, 59, 60, 100],通常在训练中完全舍弃真实数据。例如,Self-Forcing [34] 显式地将自回归模型的推理过程整合进训练流程:在生成当前片段时,使用先前生成的片段作为条件,以缩小训练—推理差距并缓解视频生成中的漂移。然而,我们观察到,这类方法对漂移的鲁棒性强烈依赖于训练期间 rollout 的片段数。具体而言,当训练中只 rollout 五个片段时,一旦推理阶段生成序列超过这一长度,模型就经常表现出严重的暴露偏差。受这一局限启发,后续研究采用了长 self-rollout 策略 [11, 59, 100],即在训练期间生成大量片段,对应的视频时长可达数十秒甚至数分钟,以增强长期稳定性。然而,这种方法带来了巨大的计算开销,使现有方法基本只能建立在约 1.3 B 1.3\text{B} 1.3B 参数规模的模型之上 [90]。为克服这一限制,我们在蒸馏阶段仅使用真实数据作为历史上下文,并且每个训练步只需生成单个片段,从而显著提升训练效率。此外,通过引入第 3.2 3.2 3.2 节提出的 Easy Anti-Drifting 机制,我们无需执行这种高成本 rollout,也能获得与长 self-rollout 策略相当的长视频抗漂移性能。更重要的是,我们选择 Helios-Base1 作为教师模型,因为它本身已经具备生成高质量长视频的能力;而现有方法通常依赖 Wan [90] 作为教师,而后者仅限于生成短视频。
分阶段反向模拟。DMD 在单一流轨迹上执行反向模拟以恢复 x 0 x_0 x0。与之相对,我们引入分阶段反向模拟(Staged Backward Simulation),将反向模拟分解为 K K K个阶段,生成中间估计 { x 0 k } k = 1 K \{x_{0}^{k}\}_{k=1}^{K} {x0k}k=1K;最终阶段的输出 x 0 K x_{0}^{K} x0K被用作 x 0 x_0 x0。在第 k k k个阶段,给定当前状态 x t k x_t^k xtk以及预测速度场 u θ k ( x t k , y , λ t , k ) u_\theta^k(x_t^k,y,\lambda_t,k) uθk(xtk,y,λt,k),我们将终止状态估计为
x 0 k = x t k − λ t ⋅ u θ k ( x t k , y , λ t , k ) , x_0^k=x_t^k-\lambda_t\cdot u_\theta^k(x_t^k,y,\lambda_t,k), x0k=xtk−λt⋅uθk(xtk,y,λt,k),
其中该更新可直接由式 5 5 5中的线性插值路径推出。随后,我们利用式 5 5 5重建 x t k x_t^k xtk,并通过式 10 10 10重新估计 x 0 k x_0^k x0k,重复这一过程直至阶段 k k k收敛。所得估计 x 0 k x_0^k x0k用于初始化阶段 ( k + 1 ) (k+1) (k+1)。经过 K K K个阶段后,我们得到 x 0 = x 0 K x_0=x_0^K x0=x0K。
由粗到细学习。相比 DMD,Helios 需要跨越 K K K个阶段和多条流轨迹传播梯度,这增加了优化难度,并且可能减慢收敛速度,尤其是在训练早期。因此,我们采用了三种课程学习式策略,逐步提高任务难度。
(1)分阶段 ODE 初始化(Staged ODE Init)。我们构建一个由 Helios-Mid 生成的 ODE 解对的紧凑数据集,并按照 [107] 用其进行初始化。不同于先前工作,我们的初始化是在 K K K个阶段上进行的。在每个阶段中,只需生成一个片段,而不是多个片段,并由一个自回归教师来引导该过程。
(2)动态重加噪(Dynamic Re-noise)。像标准 DMD 那样对噪声水平进行均匀采样,在层级式设定下并非最优,因为不同噪声区间对不同训练阶段的贡献不同。受 [5, 54] 启发,我们从 Beta 分布中采样时间步,其参数遵循余弦衰减调度:在训练早期集中于高噪声时间步以学习粗结构,随后逐渐趋于均匀,以强化中低噪声时间步上的细节精修。
对抗式后训练。DMD 通过匹配教师定义的分布,将一个多步教师蒸馏为少步学生;因此,学生会继承教师的偏置,并受限于教师的表达能力。为了缓解这一限制,受 Spark-Wan [48] 和 DMD2 [106] 启发,我们在蒸馏之外加入一个在真实数据上训练的额外 GAN 目标。这个辅助目标提供了独立于教师的监督,并能进一步提升样本质量。
具体而言,我们向 p f a k e p_{\mathrm{fake}} pfake添加多粒度分类分支 D D D,并将其分布在 DiT 的各层中。我们使用非饱和 GAN 目标来训练这些分支:
L D = E [ log D ( x τ r e a l , τ ) ] + E [ − log D ( x τ K , τ ) ] . \mathcal{L}_D=\mathbb{E}\big[\log D(x_\tau^{\mathrm{real}},\tau)\big]+\mathbb{E}\big[-\log D(x_\tau^K,\tau)\big]. LD=E[logD(xτreal,τ)]+E[−logD(xτK,τ)].
为了稳定判别器训练,我们引入一个近似的 R1 正则项(遵循 APT [53]):
L a R 1 = ∣ D ( x τ r e a l , τ ) − D ( N ( x τ r e a l , σ D I ) , τ ) ∣ 2 2 . \mathcal{L}_{aR1}= \left| D(x_\tau^{\mathrm{real}},\tau)-D(\mathcal{N}(x_\tau^{\mathrm{real}},\sigma_D\mathbf{I}),\tau) \right|_2^2. LaR1= D(xτreal,τ)−D(N(xτreal,σDI),τ) 22.
最终,完整的对抗目标定义为:
L D = E [ log D ( x τ r e a l , τ ) ] + E [ − log D ( x τ K , τ ) ] + λ D ⋅ E [ ∣ D ( x τ r e a l , τ ) − D ( N ( x τ r e a l , σ D I ) , τ ) ∣ 2 2 ] , \mathcal{L}_D= \mathbb{E}\big[\log D(x_\tau^{\mathrm{real}},\tau)\big] + \mathbb{E}\big[-\log D(x_\tau^K,\tau)\big] + \lambda_D\cdot \mathbb{E}\left[ \left| D(x_\tau^{\mathrm{real}},\tau)-D(\mathcal{N}(x_\tau^{\mathrm{real}},\sigma_D\mathbf{I}),\tau) \right|_2^2 \right], LD=E[logD(xτreal,τ)]+E[−logD(xτK,τ)]+λD⋅E[ D(xτreal,τ)−D(N(xτreal,σDI),τ) 22],
L G = E [ log D ( x τ K , τ ) ] . \mathcal{L}_G=\mathbb{E}\big[\log D(x_\tau^K,\tau)\big]. LG=E[logD(xτK,τ)].
在实践中,我们设 λ D = 100 \lambda_D=100 λD=100, σ D = 0.1 \sigma_D=0.1 σD=0.1。为了减少显存占用,我们向判别器输入的是从 x τ K x_\tau^K xτK中随机裁剪出的大小为 H ′ × W ′ H'\times W' H′×W′的区域,而不是完整分辨率样本,其中 H ′ = H 2 H'=\frac{H}{2} H′=2H, W ′ = W 2 W'=\frac{W}{2} W′=2W。
其他细节。我们从 Helios-Mid 初始化这个少步生成器,并从 Helios-Base 继承真实分数估计器和伪分数估计器,从而在训练中提供稳定且高保真的监督。
基于这一设计,对抗式分层蒸馏的目标为:
L G θ = L D M D + w G ⋅ L G , \mathcal{L}_{G_\theta}= \mathcal{L}_{\mathrm{DMD}} + w_G\cdot\mathcal{L}_G, LGθ=LDMD+wG⋅LG,
L p f a k e = L F l o w + w D ⋅ L D . \mathcal{L}_{p_{\mathrm{fake}}}= \mathcal{L}_{\mathrm{Flow}} + w_D\cdot\mathcal{L}_D. Lpfake=LFlow+wD⋅LD.
其中,我们设置 w G = 5 e − 2 w_G=5e-2 wG=5e−2、 w D = 1 e − 2 w_D=1e-2 wD=1e−2作为相应损失项的权重系数。我们遵循 CausVid [107],每更新 p f a k e p_{\mathrm{fake}} pfake五次,才更新一次 G θ G_\theta Gθ。
3.5 Other Techniques
在本节中,我们介绍几种无需训练、无需额外参数的推理技术。
自适应采样。图 6 6 6 表明,漂移通常伴随着 RGB 统计量(均值和方差)的显著偏移。由于潜空间是 RGB 空间的压缩表示,类似的分布偏移也会出现在潜变量统计量中。这启发了我们设计一种自适应抗漂移策略。设第 t t t 个生成潜变量片段的 RGB 均值和方差分别为 μ t \mu_t μt和 σ t 2 \sigma_t^2 σt2。在推理过程中,我们维护全局统计量(全局均值和方差),分别记为 μ ˉ t \bar{\mu}_t μˉt和 σ ˉ t 2 \bar{\sigma}_t^2 σˉt2,并通过指数滑动平均(EMA)进行更新:
μ ˉ t = ρ μ μ ˉ t − 1 + ( 1 − ρ μ ) μ t , \bar{\mu}_t=\rho_\mu \bar{\mu}_{t-1}+(1-\rho_\mu)\mu_t, μˉt=ρμμˉt−1+(1−ρμ)μt,
σ ˉ t 2 = ρ σ σ ˉ t − 1 2 + ( 1 − ρ σ ) σ t 2 , \bar{\sigma}_t^2=\rho_\sigma \bar{\sigma}_{t-1}^2+(1-\rho_\sigma)\sigma_t^2, σˉt2=ρσσˉt−12+(1−ρσ)σt2,
其中 ρ μ , ρ σ ∈ ( 0 , 1 ) \rho_\mu,\rho_\sigma\in(0,1) ρμ,ρσ∈(0,1)为平滑系数。当当前潜变量片段的统计量相对全局统计量的偏离超过预设阈值 δ μ \delta_\mu δμ和 δ σ \delta_\sigma δσ时:
∥ μ t − μ ˉ t ∥ 2 > δ μ 且 ∥ σ t 2 − σ ˉ t 2 ∥ 2 > δ σ , \|\mu_t-\bar{\mu}_t\|_2>\delta_\mu \quad\text{且}\quad \|\sigma_t^2-\bar{\sigma}_t^2\|_2>\delta_\sigma, ∥μt−μˉt∥2>δμ且∥σt2−σˉt2∥2>δσ,
我们就将当前片段视为出现了显著漂移。在生成下一个片段时,我们对历史上下文应用逐帧感知扰动(Frame-Aware Corrupt),以一种有针对性且无需训练的方式扰动这些发生漂移的帧。这种做法会隐式减少模型对有偏历史的依赖,并鼓励其更多依赖自身内在的生成先验,从而提升长视频的质量与稳定性。
交互式插值。长视频生成支持交互式编辑,用户可以动态修改提示词,这要求模型能够快速适应,同时不引入时间伪影。一个朴素的做法是突然切换到新的提示词嵌入;然而,这会引起瞬时的条件偏移,并且常常在编辑边界附近造成可见的不连续性(例如闪烁或语义突变)。遵循 Krea [67],我们改为采用提示词插值(prompt interpolation),在多个步骤中将条件从当前提示词逐渐过渡到目标提示词。这样能够使条件交接更加平滑,并提升感知上的时间连贯性。具体地,设当前提示词嵌入为 e ( 1 ) ∈ R ℓ T e x t × D \mathbf{e}^{(1)}\in\mathbb{R}^{\ell_{\mathrm{Text}}\times D} e(1)∈RℓText×D,目标提示词嵌入为 e ( 2 ) ∈ R ℓ T e x t × D \mathbf{e}^{(2)}\in\mathbb{R}^{\ell_{\mathrm{Text}}\times D} e(2)∈RℓText×D,其中 ℓ T e x t \ell_{\mathrm{Text}} ℓText表示文本长度, D D D表示隐藏维度。我们通过线性插值构造 M M M个中间条件 { e [ j ] } j = 0 M − 1 \{\mathbf{e}^{[j]}\}_{j=0}^{M-1} {e[j]}j=0M−1:
e [ j ] = ( 1 − λ j ) e ( 1 ) + λ j e ( 2 ) , λ j = j M − 1 , j = 0 , 1 , … , M − 1 , \mathbf{e}^{[j]}=(1-\lambda_j)\mathbf{e}^{(1)}+\lambda_j\mathbf{e}^{(2)}, \qquad \lambda_j=\frac{j}{M-1}, \qquad j=0,1,\ldots,M-1, e[j]=(1−λj)e(1)+λje(2),λj=M−1j,j=0,1,…,M−1,
其中 λ j ∈ [ 0 , 1 ] \lambda_j\in[0,1] λj∈[0,1]随 j j j线性增大,因此 e [ 0 ] = e ( 1 ) \mathbf{e}^{[0]}=\mathbf{e}^{(1)} e[0]=e(1), e [ M − 1 ] = e ( 2 ) \mathbf{e}^{[M-1]}=\mathbf{e}^{(2)} e[M−1]=e(2)。在生成过程中,我们按顺序输入这些嵌入,使条件在 M M M个步骤内逐步从 e ( 1 ) \mathbf{e}^{(1)} e(1)过渡到 e ( 2 ) \mathbf{e}^{(2)} e(2)。这种渐进式过渡可以缓解由条件突变引起的视觉和语义不连续问题。
4 Infrastructure
4.1 Workload Analysis
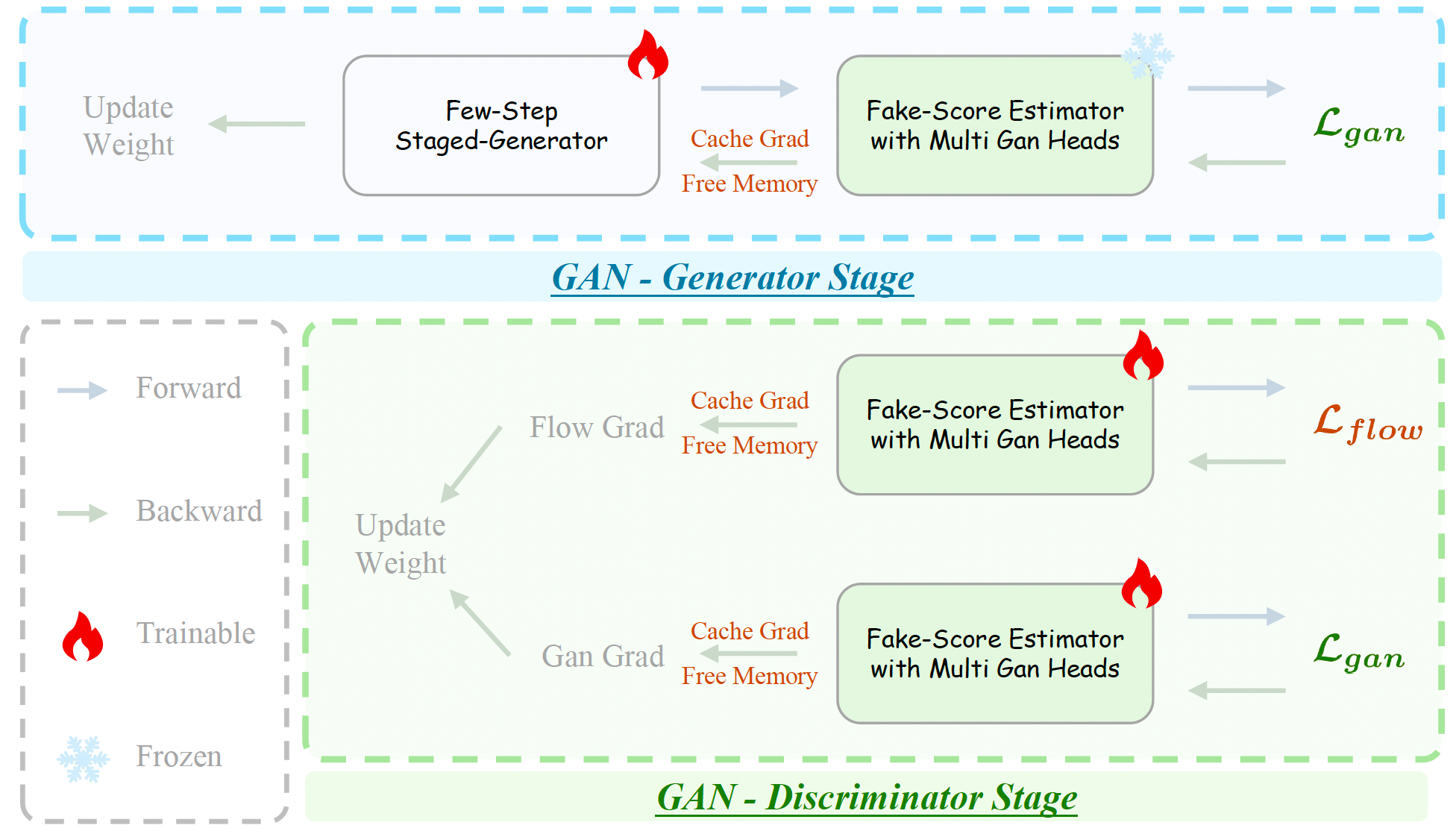
图10:用于 GAN 的 Cache Grad 执行流程。我们缓存判别器相对于输入的梯度,以解耦反向传播并尽早释放中间激活,从而显著降低峰值显存占用。
将基于 DiT 的视频生成器扩展到 14 B 14\text{B} 14B 参数规模,即使 batch size 为 1 1 1,也会带来难以承受的计算与显存开销。其主要瓶颈在于 3D 注意力在时间与空间 token 上具有二次复杂度。在实践中,要在单张 GPU 上训练这类模型,通常需要大量并行化(例如 CP、TP、SP)以及参数/激活分片(例如 FSDP、DeepSpeed)。
相比之下,Helios 提出了深度压缩流(Deep Compression Flow),同时压缩历史上下文和带噪上下文,从而使得前两个训练阶段能够在单张 GPU 上完成完整的前向与反向传播,而无需并行或分片。在多项长期记忆分块(Multi-Term Memory Patchification)中,我们设置
( p t ( 1 ) , p t ( 2 ) , p t ( 3 ) ) = ( 4 , 2 , 1 ) (p_t^{(1)},p_t^{(2)},p_t^{(3)})=(4,2,1) (pt(1),pt(2),pt(3))=(4,2,1),
( p h ( 1 ) , p h ( 2 ) , p h ( 3 ) ) = ( 8 , 4 , 2 ) (p_h^{(1)},p_h^{(2)},p_h^{(3)})=(8,4,2) (ph(1),ph(2),ph(3))=(8,4,2),
以及
( p w ( 1 ) , p w ( 2 ) , p w ( 3 ) ) = ( 8 , 4 , 2 ) (p_w^{(1)},p_w^{(2)},p_w^{(3)})=(8,4,2) (pw(1),pw(2),pw(3))=(8,4,2),
并取
( T 1 , T 2 , T 3 ) = ( 16 , 2 , 2 ) (T_1,T_2,T_3)=(16,2,2) (T1,T2,T3)=(16,2,2)。
这样可将历史上下文的 token 数量从 5 H W 5HW 5HW降低到 5 8 H W \frac{5}{8}HW 85HW(约为 8 × 8\times 8× 压缩)。结合金字塔统一预测校正器(Pyramid Unified Predictor Corrector, K = 3 K=3 K=3),带噪上下文的 token 数量则可从 N H W NHW NHW降到 7 16 N H W \frac{7}{16}NHW 167NHW(约为 2.29 × 2.29\times 2.29× 压缩)。
对于标准 DiT,单层复杂度大致为 O ( α B ℓ D 2 + β B ℓ 2 D ) \mathcal{O}(\alpha B\ell D^2+\beta B\ell^2D) O(αBℓD2+βBℓ2D),其中 α \alpha α和 β \beta β分别表示线性层和注意力的开销, ℓ \ell ℓ表示序列长度(其中 ℓ 2 \ell^2 ℓ2项主导自注意力计算)。整体复杂度因此缩放为 O ( L ( α B ℓ D 2 + β B ℓ 2 D ) ) \mathcal{O}(L(\alpha B\ell D^2+\beta B\ell^2D)) O(L(αBℓD2+βBℓ2D)),而激活显存则缩放为 O ( γ L B ℓ D ) \mathcal{O}(\gamma LB\ell D) O(γLBℓD),其中 γ \gamma γ依赖于具体实现。因此,历史上下文和带噪上下文中分别实现的 8 × 8\times 8× 与 2.29 × 2.29\times 2.29× token 压缩,对应大约 64 × 64\times 64× 和 5.2 × 5.2\times 5.2× 的注意力 FLOPs 降低,并且会线性降低激活与中间状态显存占用。
4.2 Memory Optimization
在前两个训练阶段中,GPU 只需要加载三个组件:VAE、文本编码器和 DiT。通过将 VAE 潜变量和文本嵌入卸载到磁盘,GPU 实际上只保留 DiT,从而使单 GPU 的 batch size 能够达到与图像扩散模型相当的规模。
在第三阶段中,内存需求显著增加:GPU 需要同时容纳四个 14B 模型(少步生成器、真实评分估计器、伪评分估计器以及 EMA 模型),以及多个 GAN 分支。在 80GB 显存预算下,即使仅用于推理,这一配置也可能超出容量,而训练由于需要存储激活和中间状态会进一步增加显存占用。因此,我们采用以下策略以在严格的内存约束下实现训练。
分片 EMA。指数滑动平均(EMA)通过平滑参数更新来稳定训练,通常以 FP32 存储以保证数值稳定性。一个朴素的实现会在每个 GPU 上复制完整的 FP32 EMA 副本,从而带来巨大的显存开销。参考 OpenSora-Plan [49],我们改为使用 ZeRO-3 在多个 GPU 之间对 EMA 参数进行分片,使每个设备仅存储 EMA 状态的一部分。对于一个在 Z Z Z 个 GPU 上分片的 14B 参数模型,每个设备大约存储 14 × 4 Z \frac{14\times4}{Z} Z14×4 GiB 的 EMA 参数。这消除了冗余副本并提升了内存效率。
异步显存释放。在第 3 阶段训练中,我们按顺序执行多个大模型:首先将噪声 z t z_t zt 输入到少步分阶段生成器中得到 x 0 staged x_0^{\text{staged}} x0staged,然后重新加噪,并通过真实评分估计器 p real p_{\text{real}} preal 和伪评分估计器 p fake p_{\text{fake}} pfake 对样本进行评估,以计算 L DMD L_{\text{DMD}} LDMD、 L GAN L_{\text{GAN}} LGAN 和 L Flow L_{\text{Flow}} LFlow。由于这些计算是串行执行的,在前向过程中任意时刻只需一个模型驻留在 GPU 上。
此外,在双时间尺度更新规则(TTUR)[105] 下,每次迭代只更新伪评分估计器 p fake p_{\text{fake}} pfake(通过 L Flow L_{\text{Flow}} LFlow 和 L GAN L_{\text{GAN}} LGAN)或少步生成器 G θ G_\theta Gθ(通过 L DMD L_{\text{DMD}} LDMD)。我们利用这一结构,将未使用的模型异步卸载到主机内存,将峰值显存限制在大约单个 14B 模型的水平。通过使用锁页主机内存、非阻塞数据传输以及精细的 CPU-GPU 调度,即使频繁进行数据传输,我们仍能保持接近纯 GPU 执行的吞吐量。
用于 GAN 的 Cache Grad。(1)更新生成器。标准自动微分需要在反向传播结束前保留少步生成器 G θ G_\theta Gθ 和伪评分估计器 p fake p_{\text{fake}} pfake 的所有激活,这会使后续计算 L DMD L_{\text{DMD}} LDMD 在内存受限情况下变得不可行。因此,我们通过在前向过程中缓存判别器相对于其输入的梯度,将伪评分估计器 p fake p_{\text{fake}} pfake 从默认的反向传播中解耦。具体而言,在其前向传播后我们立即释放估计器的中间激活,并在反向传播时复用缓存的输入梯度,从而避免保留完整计算图。这将峰值显存降低到单个 14B 模型的水平。
(2)更新伪评分估计器。我们将梯度累积与批处理执行相结合。首先在单独的一次前向/反向传播中计算 L Flow L_{\text{Flow}} LFlow,将其梯度累积到判别器中,并立即释放其激活。随后,我们将真实样本、生成样本和扰动样本(用于 L a R 1 L_{aR1} LaR1)拼接成一个 batch,并执行一次前向/反向传播以计算其余损失项。相比于同时计算所有损失,这种调度方式显著降低了峰值显存占用。
4.3 Efficiency Optimization
为了进一步加速训练和推理,我们用自定义实现替换了多个原生 PyTorch 操作,覆盖前向与反向传播,从而提升计算效率。
Flash 归一化。我们参考 [15, 32],使用 Triton 对 LayerNorm 和 RMSNorm 实现 kernel fusion。通过将均值和方差计算、归一化以及仿射变换合并到单个 kernel 中,我们最小化了内存流量,并利用了诸如 tl.math.rsqrt 等优化原语。为了减少内存占用,在反向传播中我们只缓存标量统计量(按行的 i n v _ v a r ∈ R B × ℓ inv\_var\in\mathbb{R}^{B\times \ell} inv_var∈RB×ℓ 和 μ ∈ R B × ℓ \mu\in\mathbb{R}^{B\times \ell} μ∈RB×ℓ),而不存储完整的归一化张量 z ∈ R B × ℓ × D z\in\mathbb{R}^{B\times \ell\times D} z∈RB×ℓ×D。这种方法将中间激活的内存复杂度从 O ( B ℓ D ) \mathcal{O}(B\ell D) O(BℓD) 降低到 O ( B ℓ ) \mathcal{O}(B\ell) O(Bℓ)。此外,我们采用混合精度策略:内部计算使用 FP32 以保证数值稳定性,而输入和输出保持其原始数据类型(例如 bfloat16)。最后,我们通过按行并行——即为每个 token 映射一个程序实例——以及合并式内存访问模式,最大化 GPU 带宽利用率。
Flash 旋转位置嵌入。我们使用 Triton 对旋转位置嵌入(RoPE)实现 kernel fusion 优化。通过将复数分解、旋转矩阵乘法以及结果重构合并到单个 GPU kernel 中,我们消除了 PyTorch 原生展平、分块和索引操作中固有的内存碎片与数据拷贝开销。具体来说,我们将输入 x ∈ R B × ℓ × H × D x\in\mathbb{R}^{B\times \ell\times H\times D} x∈RB×ℓ×H×D 展平为 R ( B ⋅ ℓ ⋅ H ) × D \mathbb{R}^{(B\cdot \ell\cdot H)\times D} R(B⋅ℓ⋅H)×D。我们通过为每个注意力头映射一个程序实例来实现并行执行,并采用交错内存访问,直接提取实部和虚部。旋转操作使用预先计算好的 cos \cos cos 和 sin \sin sin 值来完成:
o u t r e a l = x r e a l ⋅ cos − x i m a g ⋅ sin out_{\mathrm{real}}=x_{\mathrm{real}}\cdot \cos - x_{\mathrm{imag}}\cdot \sin outreal=xreal⋅cos−ximag⋅sin
以及
o u t i m a g = x r e a l ⋅ sin + x i m a g ⋅ cos out_{\mathrm{imag}}=x_{\mathrm{real}}\cdot \sin + x_{\mathrm{imag}}\cdot \cos outimag=xreal⋅sin+ximag⋅cos
计算结果会原地写回。对于反向传播,我们复用前向 kernel,只需将正弦分量取反( s i n n e g = − sin sin_{\mathrm{neg}}=-\sin sinneg=−sin)即可执行逆旋转。该策略避免了存储完整中间张量的需要,仅需保存 cos ∈ R B × ℓ × ( D / 2 ) \cos\in\mathbb{R}^{B\times \ell\times (D/2)} cos∈RB×ℓ×(D/2) 和 sin ∈ R B × ℓ × ( D / 2 ) \sin\in\mathbb{R}^{B\times \ell\times (D/2)} sin∈RB×ℓ×(D/2)。因此,我们将中间激活的内存复杂度从 O ( B ℓ H D ) \mathcal{O}(B\ell HD) O(BℓHD) 降低到 O ( B ℓ D ) \mathcal{O}(B\ell D) O(BℓD),其中 B B B、 ℓ \ell ℓ、 H H H 和 D D D 分别表示 batch size、序列长度、注意力头数和每个头的维度。
4.4 Other Techniques.
通过消除对因果掩码(causal masking)的需求,Helios 可以无缝集成诸如 FlashAttention [16, 17] 等高效注意力后端,从而实现更高的吞吐量和更低的延迟。
5 Experiments
5.1 Implementation Details
训练。我们从 Wan-2.1-T2V-14B [90] 初始化,并使用一个三阶段渐进式流程,在 0.8M 个时长 < 10 秒的视频片段上进行训练。Stage 1(Base)执行架构改造:我们引入 Unified History Injection、Easy Anti-Drifting 和 Multi-Term Memory Patchification,将双向预训练模型转换为自回归生成器。Stage 2(Mid)通过引入 Pyramid Unified Predictor Corrector 实现 token 压缩,大幅减少噪声 token 的数量,从而降低整体计算量。Stage 3(Distilled)采用 Adversarial Hierarchical Distillation,将采样步数从 50 减少到 3,并消除对无分类器引导(CFG)的需求。在整个训练过程中,我们对所有依赖时间步的操作应用动态偏移,使噪声调度与潜空间大小匹配。我们将分辨率限制为 384 × 640,并从每个视频中提取 109 帧片段。更多细节见表 1 和表 2。


推理。对于 Stage 1–2,我们采用 UniPC [119] 调度器,使用 50 个采样步,CFG scale 为 5.0,并使用 v-prediction。对于 Stage 2,我们用 CFG-Zero-Star [22] 替代标准 CFG。对于 Stage 3,我们采用 x 0 x_0 x0-prediction,使用 3 个采样步,并将 CFG scale 设为 1.0。
HeliosBench。由于目前没有针对实时长视频生成的开源基准,我们构建了 HeliosBench,一个包含 240 个由 Self-Forcing [34] 精炼的提示词测试集。我们评估四种时长等级:极短(81 帧)、短(240 帧)、中等(720 帧)和长(1440 帧)。在自动评估方面,现有基准与人类偏好的一致性较弱 [35, 36, 109, 120],但仍是当前最优选择。参考 [35, 109, 110],我们报告五个维度:(1)Aesthetic,由 LAION 美学预测器 [73] 评估;(2)Dynamic,使用 Farnebäck 算法 [110] 计算;(3)Motion Smoothness,由 RAFT [85] 评估;(4)Semantic,使用 ViCLIP [92] 衡量视频-文本对齐;(5)Naturalness,由 OpenS2V-Eval [110] 评估。此外,我们参考 [116] 在 Aesthetic、Motion Smoothness、Semantic 和 Naturalness 上量化漂移。由于这些指标噪声较大,且原始分数与人类感知相关性较弱,我们将每个指标根据其经验分布映射到 10 分制,以提升鲁棒性。为测量吞吐量(FPS),我们在默认帧长度下报告 384 × 640 分辨率的端到端速度,包括 VAE 和文本编码器的延迟。对于每个模型,我们启用其官方支持的加速技术(例如 FlashAttention、torch.compile、KV-cache 和 warm-up),以实现尽可能高的吞吐量。更多细节见附录 A。
对于基线模型,我们将 Helios 与一系列开源视频生成模型进行比较,包括:(1)基础模型:SANA Video [9]、CogVideoX [103]、Mochi [80]、HV Video [41, 93]、Wan [90]、LTX Video [30, 31]、Kandinsky [1]、StepVideo [63]、NOVA [18]、Pyramid Flow [38]、MAGI [86]、InfinityStar [58]、SkyReelsV2 [8] 和 LongCat-Video [84];以及(2)蒸馏模型:FastVideo [117]、TurboDiffusion [115]、CausVid [107]、Self-Forcing [34]、Rolling Forcing [59]、LongLive [100]、Infinite Forcing [39]、Reward Forcing [60]、Causal Forcing [126]、Dummy Forcing [26]、SANA Video Long [9] 和 Krea [67]。对于仅支持短视频生成的模型,我们通过将 240 个提示词匹配到各模型的默认长度来构建子集。为保证公平比较,我们将长视频模型的输出截断为前 81 帧。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)