CrowdDiff:使用扩散模型的多假设人群密度估计(CVPR 2024)
1. 代码和数据集
1.1 代码地址:https:// dylran.github.io/crowddiff.github.io
1.2 数据集:JHU-Crowd++、ShanghaiTech A、 ShanghaiTech B、UCF-CC-50、UCF-QNRF和NWPU-Crowd六个公共数据集
2. 本文主要存在的问题
由于使用广泛的高斯核来创建地面真密度图,这种方法受到背景噪声积累和密度损失的影响。现有的方法在使用具有广泛核的地面真值密度图进行训练时表现不佳。扩散过程的中间时间步是有噪声的,扩散模型有随机性。
基于密度的方法更容易在最终结果中引入背景噪声,受到人群密度分布变化的影响;基于定位的方法需要人群密度启发式来设置提案。
尽管基于生成对抗网络 (GAN)的架构已被用于密度图预测[8,40,57],但这些方法仍然依赖于广泛的核大小,忽视了点监督的好处。由于模型学习了密度像素值的分布,因此保持密度像素值 的样本空间是有利的,而采用广义核只会阻碍它。
在生成模型中同时使用点监督和人群密度预测,在此之前还没有被深入研究过。基于密度的人群计数方法可能造成的密度损失。
3.文章提出的创新点
•我们将人群密度图生成表述为去噪扩散过程。CrowdDiff是第一个使用扩散模型进行人群计数的研究。
•我们提倡使用窄高斯核来简化学习过程,并促进高质量密度地图的生成,更接近地面真相。
•我们提出了一种机制来整合多个人群密度实现,以提高性能利用扩散模型的随机特性。
3.1 人群统计
我们将密度图的预测视为生成任务。
3.2 人群密度图生成的扩散模型
扩散模型是基于具有正向和反向过程的马尔可夫链定义的。我们的目标是通过扩散模型进行人群密度图生成。因此,我们的数据样本将是人群密度图 x0 ∈RH× W,其中H和W是高度和宽度维度。然而,我们并没有训练神经网络从xt 预测不同时间步长的x0 ,而是 根据人群图像(y)预测每个时间步长的xt 中的噪声量(λ -), 并应用反向扩散过程最终获得x0 。
我们使用中提出的混合损失(Lhybrid )函数 来训练去噪扩散网络。
![]()
其中Lvlb 为[36]中定义的原始变分下界,λvlb 为其权 重因子
3.3 CrowdDiff
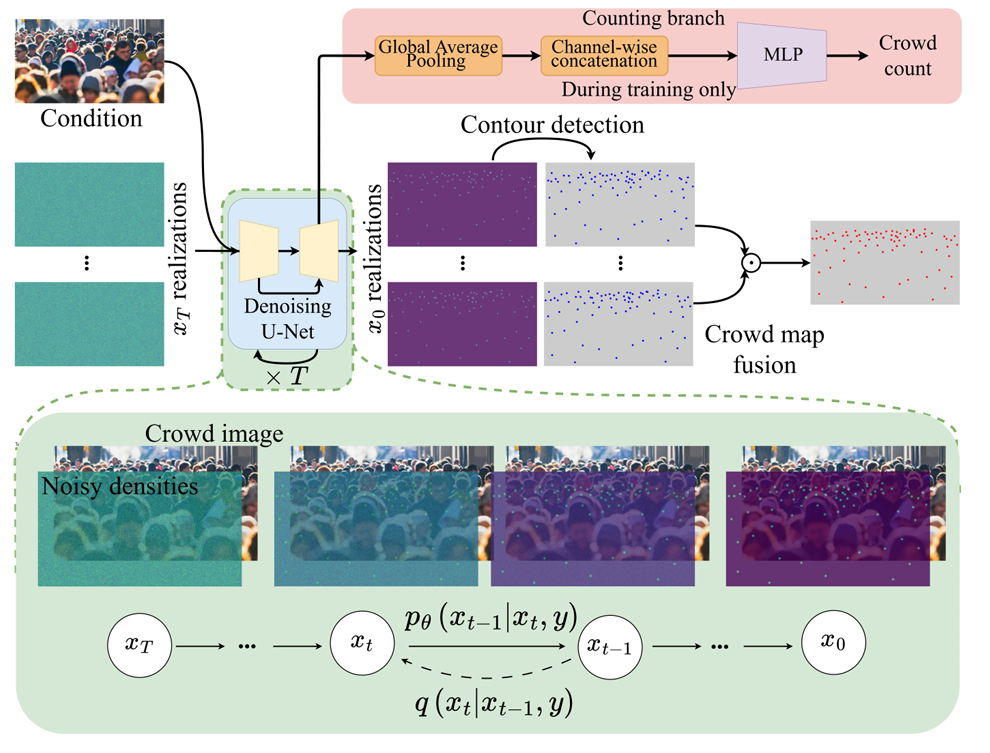
图2。整体人群计数管道。人群密度图是由人群图像的去噪扩散过程生成的。接下来,对得到的人群密度实现执行阈值分割,以创建人群地图。然后将人群地图融合成一个单一的人群地图。计数分支使用去 噪U-Net的编码器-解码器特征并行训练,并在推理过程中丢弃。
3.3.1 窄核
扩散过程需要一个密度图来学习人群密度的条件分布。人群密度图可以通过将点信息与预定义的高斯核进行卷积得到。
随着核的大小和方差的增加,高斯 核(值)的分布与得到的密度图之间的差异也会增加, 特别是对于拥塞场景。通过缩小高斯核的分布来避免,这有助于去噪网络,使像素值保持在预定义范围内。广义高 斯核的概率质量与得到的密度图之间的差异是显著的。这可能导致许多像素值被裁剪,从而在拥挤的 场景中造成信息的丢失。
前面提到的问题可以通过窄核来解决。窄内核为人群计数提供了一种替代路径,而无需对密度图值求和。人群计数可以通过简单地对可观察的核进行计数来获得。为此,我们对密度图执行阈值分割,并获得每个核的位置。然后,将人群计数计算为位置的总数。这提供了在生成的密度图中避免背景噪声的手段,并通过检测人群密度图中 的这些窄核来获得人群计数。
3.3.2 计数的联合学习
为了直接计算人群数,我们考虑了去噪U-Net的编解码器的中间 特征。我们将特定时间步长t的去噪网络的中间特征 集表示为Zt ={z1 t ,z2 t ,…, zdt},其中z* t 是解码器 对应特征级别上的表示向量。由于不同深度层的中 间表示的空间维度是不兼容的,因此对每个z* t 执行 全局平均池化,然后将它们连接起来构建单个特征 向量zt。 然后将其通过回归网络来估计各种噪声水平 下的人群计数。
对于采样对(x0 ,y),根据噪声调度,只 有密度图x0 被噪声扩散。因此,中间特征集Zt 中的 噪声电平将随时间步长而变化,扩散过程后期的 SNR将低于早期阶段。因此,我们利用中讨论的加 权方案计数回归网络训练过程中的第2.2节。我们利用L1 损失 如下:
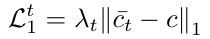
来测量给定时间步长t和给定采样对的预测(c¯t ))与基本 事实(c)之间的差异,其中λt 与Eq.(1)中使用的权重因子 相同。由于去噪模型的训练损失是所有时间步长和的 蒙特卡罗近似,因此训练损失可以写为:
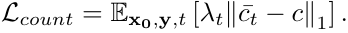
整体训练包括对去噪网络和回归分支的参数进行优化。 因此,总体训练目标如下:
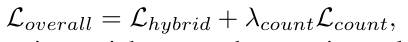
其中λcount 是计数任务的权重。
3.3.3 随机人群图融合
扩散模型的随机特性可以为相同的人群图像生成不同的人群密度图实现。因此,与传统的人群计数方法相反,使用扩散模型的计数性能可以通过多种实现来提高,这一点可以通过基于扩散模型的其他任务来证明。然而,与其将来自不同实现的单个计数平均,它们可以组合起来计算更改进的计数, 因为单个实现可以推断其他实现中不存在的人群密度。
为了结合密度图的不同实现,只有新的信息应该被转移到复合密度图中。为此,我们首先通过密度阈值法计算密度核的位置。一旦找到这些位置,就会为每个密度图构建一个点图,称为“人群图”。然后, 我们考虑不同实现的人群图之间的不相似性,为了衡量这一点,我们考虑结构相似性指数度量(SSIM)[53]。 我们为每个人群地图分配一个相似度分数,作为剩余人群地图实现的累积SSIM。然后,将这些映射按SSIM的升序排列, 然后再组合。此外,我们不要求地面真实位置组合不同的实现;它们是根据人群地图的相似度来组合的。
让我们考虑四张人群图。对于给定的人群图(源图), 我们将使用剩下的三个人群图中的每一个来测量SSIM, 并且这三个SSIM的总和将被分配为源图的相似性得分。 如果相似度得分是一张地图中最高的,那么它与剩余 的地图最相似,并且可能包含剩余地图中可用的大部 分点位置。因此,可以从最相似的地图中添加和添加 的新点是最少的。相反,相似度得分最低的人群地图 与其余地图的差异最大;因此,可以从这张地图中添加/ 添加的新点是最大的。因此,开始融合过程的最佳地 图是相似度得分最低的人群地图。同样地,我们将人 群地图按照相似度分数的升序进行排序进行组合。
在融合两个人群图时,有必要拒绝重复的点位置。 这是根据新点的位置与合并列表中的点进行比较来执行的。我们首先将人群地图和来自该实现的头部位置作为参考。接下来,我们定义每个人头位置的拒绝半径为:
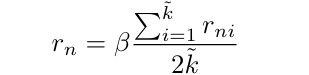
通过考虑固定范围内的k个最近的邻居。这里β是一个 比例因子,k ~是该范围内的总近邻。接下来,我们移 除参考图中落在拒绝半径内的下一个人群地图位置的 头部位置,如图4所示,其余位置添加到参考图中。这 个过程一直执行,直到所有的实现都用尽为止。
4.实验细节
在训练期间,我们使用第3.1节中描述 的窄核创建地面真值密度图。接下来,我们随机采样 一个时间步长t。然后,我们根据t处的方差采样一个高 斯噪声,并将其添加到地面真值图中,得到噪声图(xt )。 然后,我们将图像和xt 输入到去噪的U-Net(网络)中, 并预测添加到地面真值的噪声。因此,基于人群图像, 训练网络来预测xt 中的噪声。
在推理过程中,我们在时 间T时从N (0, I)处采样一个高斯噪声,用作初始噪声密 度图xT。 然后,网络将估计xT 中存在的噪声,并通过去 除该噪声,我们在时间T−1产生噪声密度图(xT−1 )。同 样,我们将重复这个过程,其中t−1处的噪声密度图xt− 1 是从噪声den-估计出来的时间t的密度图xt ,直到我们为图像生成密度图(x0 )。除 此之外,计数分支输出在推理过程中被丢弃。
扩散过程在推理期间使用1000个时间步长和DDIM采 样[44]。我们使用线性噪声调度,噪声方差范围从1× 10−3到0.02。
超参数值λcount设置为5×10−3,以匹配Lhybrid的值范 围。将γ和k值分别设置为0.5和1,以计算基于信噪比 的加权因子。对于[36]之后的λvlb ,我们采用原来的比 例因子1×10−3。对于人群地图融合,我们设置β等于0. 85,最大近邻为4。邻居搜索的半径被限制为图像尺 寸最小值的0.05。
除输入和输出层外,降噪网络的训练使用ImageNet预 训练的超分辨率[38]任务权值进行初始化。该网络训 练2次×10-5迭代,批处理大小为8,256张×256图像。 我们使用一个固定学习率为1×10−4的AdamW优化器, 并在[54]之后使用超过5个×10-3训练步骤的线性热身 计划。
5.结论和不足
我们提出了一种新的人群计数框架,其中密度图生成 被视为去噪扩散过程。新框架允许使用非常窄的密度 核,在人群密度图中可以更稳健地抑制噪声。因此, 我们在人群密度图上执行密度核检测,这比密度求和对噪声的免疫力更高。此外,由于生成模型的随机性, 与其他人群计数框架不同,所提出的方法可以通过多 种实现迭代地提高计数性能。此外,与现有的基于密 度的方法不同,我们提出的方法分配den头部位置的Sity核,不需要数据启发式,这是基于定位的 方法所要求的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)