FedBN:基于局部批量归一化的非独立同分布特征上的联邦学习
FEDBN: 基于局部批量归一化的非独立同分布特征上的联邦学习
(FEDBN: FEDERATED LEARNING ON NON-IID FEATURES VIA LOCAL BATCH NORMALIZATION)
论文下载地址:https://arxiv.org/abs/2102.07623
摘要
新兴的联邦学习(FL)范式致力于在网络边缘实现深度模型的协同训练,而无需将原始数据集中聚合,从而提高了数据隐私性。在大多数情况下,对于联邦学习的设置,局部客户端之间的样本独立同分布 (iid)的假设并不成立。在这种设置下,神经网络的训练性能可能会根据数据分布发生显著变化,甚至损害训练的收敛性。之前的大部分工作都集中在标签分布的差异或客户端漂移上。与这些设置不同,我们解决的是联邦学习中的一个重要问题,例如,医学成像中不同的扫描仪/传感器,自动驾驶中不同的风景分布(高速公路与城市),即局部客户端存储的样本分布与其他客户端不同,我们将其表示为特征偏移非独立同分布 (feature shift non-iid)。在这项工作中,我们提出了一种有效的方法,在平均模型之前,使用局部批量归一化(local batch normalization)来缓解特征偏移。在大量的实验中,这种名为 FedBN 的方案不仅优于经典的 FedAvg,而且也优于针对非独立同分布数据的最先进方法(FedProx)。这些经验结果得到了收敛性分析的支持,该分析在一个简化设置中表明 FedBN 的收敛速度比 FedAvg 快。代码可在 https://github.com/med-air/FedBN 获取。
1 引言
联邦学习(FL)因涉及从分布式数据中学习的各种应用而受到欢迎。在 FL 中,云服务器(“服务器”)可以与分布式数据源(“客户端”)通信,而客户端则单独持有数据。FL 的一个主要挑战是客户端之间的训练数据统计异质性(Kairouz; Li)。研究表明,诸如 FedAvg(McMahan)等标准联邦方法并未特别针对非独立同分布(non-iid)数据进行设计,如果部署在 non-iid 样本上,其性能会显著下降甚至发散(Karimireddy; Li)。
最近的研究试图解决 FL 在 non-iid 数据上的问题。FedAvg 的大多数变体主要解决诸如跨客户端的稳定性、客户端漂移和异构标签分布等问题(Li; Karimireddy; Zhao)。相反,我们将重点放在特征空间中的偏移上,这在文献中尚未被探索。具体而言,我们认为本地数据在特征空间的分布方面存在偏差,并将这种场景识别为特征偏移。这种类型的 non-iid 数据是许多现实场景中的关键问题,通常出现在本地设备应对特征分布异质性负责的情况下。例如,在癌症诊断任务中,不同医院收集的医学放射图像具有均匀分布的标签(即,各医院治疗的癌症类型非常相似)。然而,由于医院使用的成像机器和协议不同(例如,不同的强度和对比度),图像的外观可能会有很大差异。在这个例子中,每个医院都是一个客户端,医院的目标是在不共享隐私敏感数据的情况下协同训练一个癌症检测模型。
在传统集中式训练的域自适应背景下,已经探索了处理具有特征偏移的 non-iid 数据。在这里,一种有效的实践方法是利用批量归一化 (Batch Normalization, BN) (Ioffe & Szegedy):最近的工作已提出将 BN 作为一种工具来减轻域自适应任务中的域偏移,并取得了令人满意的结果 (Li; Liu; Chang)。受此启发,本文提出在具有特征偏移的 FL 中应用 BN。为了说明这个想法,我们提出了一个玩具示例 (toy example) 来说明 BN 如何帮助协调局部特征分布。

图 1 说明:在包含和不含 BN 的情况下,两个客户端的本地数据集上的训练误差。其中 BN 协调了损失曲面。

图 2 说明:对于模型参数 w∈[0.001,12]w \in [0.001, 12]w∈[0.001,12] 和 BN 参数 γ∈[0.001,4]\gamma \in [0.001, 4]γ∈[0.001,4],一个客户端的误差曲面。平均化 (Averaging) 模型参数和 BN 参数会导致更差的解。
在 FL 玩具示例中对 BN 的观察: 我们考虑一个简单的非凸学习问题:我们生成数据 x,y∈Rx, y \in \mathbb{R}x,y∈R,其中 y=cos(wtruex)+ϵy = \cos(w_{true}x) + \epsilony=cos(wtruex)+ϵ,此处 x∈Rx \in \mathbb{R}x∈R 从高斯分布中独立同分布地抽取,ϵ\epsilonϵ 是零均值的高斯噪声;我们考虑模型形式为 fw(x)=cos(wx)f_w(x) = \cos(wx)fw(x)=cos(wx),模型参数 w∈Rw \in \mathbb{R}w∈R。本地数据在 xxx 的方差上存在偏差。首先,我们说明局部批量归一化能协调本地数据分布。我们考虑一种简化形式的 BN,它通过输入乘以 γ\gammaγ(即局部经验标准差)来归一化输入,并且考虑一个包含 2 个客户端的设置。如图 1 所示,两个客户端之间的局部平方损失差异非常大。因此,对模型进行平均并不会得到一个好模型。然而,当应用局部 BN 时,局部训练误差曲面变得相似,此时对模型进行平均可以是有益的。
为了进一步说明 BN 的影响,我们在图 2 中绘制了一个客户端针对模型参数 w∈Rw \in \mathbb{R}w∈R 和 BN 参数 γ∈R\gamma \in \mathbb{R}γ∈R 的误差曲面。该图显示,对于给定的最佳权重 w1∗w_1^*w1∗,改变 γ\gammaγ 会降低模型质量。同样,对于给定的最佳 BN 参数 γ1∗\gamma_1^*γ1∗,改变 www 会降低质量。特别是,平均模型 w‾=(w1∗+w2∗)/2\overline{w} = (w_1^* + w_2^*)/2w=(w1∗+w2∗)/2 和平均 BN 参数 γ‾=(γ1∗+γ2∗)/2\overline{\gamma} = (\gamma_1^* + \gamma_2^*)/2γ=(γ1∗+γ2∗)/2 具有很高的泛化误差。与此同时,带有局部 BN 参数 γ1∗\gamma_1^*γ1∗ 的平均模型 w‾\overline{w}w 表现非常好。
受上述见解和观察的启发,本文提出了一种用于解决 non-iid 训练数据的新型联邦学习方法,称为 FedBN。该方法在本地保持客户端的 BN 层进行更新(不进行通信),而在服务器端对其余层进行聚合。在实践中,我们只需使用 FedAvg 更新非 BN 层,而无需修改任何优化或聚合方案。这种方法需要调整的参数为零,需要极少的额外计算资源,并且可以轻松应用于 FL 中带有 BN 层的任意神经网络架构。除了在玩具示例中展示的优势外,我们还通过从理论上分析超参数化机制下 FedBN 的收敛性,展示了其在加速收敛方面的优势。此外,我们在一个基准数据集和三个真实世界数据集上进行了广泛的实验。与经典的 FedAvg 以及针对 non-iid 数据的当前最先进方法 (FedProx) 相比,我们新颖的方法 FedBN 在广泛的实验中证明了显著的实际改进。
2 相关工作
联邦学习中应对 Non-IID 挑战的技术: FL 中广为人知的聚合策略 FedAvg (McMahan) 往往在数据在本地客户端之间异构时遭受性能损失。解决 non-iid 问题的实证工作主要集中在标签分布偏斜上,在这种情况下,基于标签对“平坦的”现有数据集进行分区来形成 non-iid 数据集。FedProx (Li) 是一个最近的框架,它通过允许聚合部分信息并在 FedAvg 中添加近端项来解决异质性。Zhao 假设所有客户端之间共享数据的一个子集,从而泛化到手头的问题。FedMA (Wang) 提出了一种针对 non-iid 数据分区的聚合策略,以逐层的方式共享全局模型。然而,到目前为止,考虑由特征偏移引起的 non-iid 的尝试还很有限,而这在从不同设备收集的医疗数据和在各种嘈杂环境中收集的自然图像中是很常见的。最近,FedRobust (Reisizadeh) 假设数据遵循仿射分布偏移,并通过学习仿射变换来解决这个问题。当我们无法估计显式的仿射变换时,这会妨碍其泛化。与我们的工作同时进行的 SiloBN (Andreux) 凭经验表明,本地客户端保留一些不可训练的 BN 参数可以提高对数据异质性的鲁棒性,但没有提供该方法的理论分析。相反,FedBN 使所有 BN 参数严格保持本地化。 最近,提出了一种与解决 non-iid 问题正交的方法,该方法侧重于改进优化机制 (Reddi; Zhang)。
深度神经网络中的批量归一化: 批量归一化 (Ioffe & Szegedy) 是许多深度神经网络中不可或缺的组成部分,并在神经网络训练中展示了它的成功。相关文献揭示了批量归一化带来的许多好处。Santurkar 表明 BN 使优化景观变得非常平滑。Luo 研究了 BN 的显式正则化形式,从而提高了优化的鲁棒性。Morcos 认为 BN 隐式地抑制了对单一方向的依赖,从而提高了模型的泛化能力。Li 利用 BN 来解决域自适应问题。然而,在联邦学习的范围内,尤其是对于 non-iid 训练,BN 正在扮演什么角色,至今仍未被探索。
3 准备知识
联邦学习中的 Non-IID 数据: 我们将特征偏移的概念引入联邦学习中,作为客户端 non-iid 数据分布的一种新类别。到目前为止,根据 Kairouz; Hsieh 考虑的 non-iid 数据类别可以由每个客户端上特征 x\mathbf{x}x 和标签 yyy 之间的联合概率描述。我们可以将 Pi(x,y)P_i(\mathbf{x}, y)Pi(x,y) 重写为 Pi(y∣x)Pi(x)P_i(y|\mathbf{x})P_i(\mathbf{x})Pi(y∣x)Pi(x) 和 Pi(x∣y)Pi(y)P_i(\mathbf{x}|y)P_i(y)Pi(x∣y)Pi(y)。我们定义特征偏移为涵盖以下情况:1) 协变量偏移: 跨客户端的边缘分布 Pi(x)P_i(\mathbf{x})Pi(x) 发生变化,即使所有客户端的 Pi(y∣x)P_i(y|\mathbf{x})Pi(y∣x) 相同;以及 2) 概念偏移: 条件分布 Pi(x∣y)P_i(\mathbf{x}|y)Pi(x∣y) 跨客户端变化,而 P(y)P(y)P(y) 相同。
联邦平均 (FedAvg): 我们在 McMahan 引入的 FedAvg 之上建立我们的算法,这是最流行的现有策略,也是最容易实施的联邦学习策略,客户端协同地将本地训练的模型的更新发送到全局服务器。每个客户端在自己的本地数据上运行全局模型的一个本地副本。然后用局部客户端更新的平均值更新全局模型的权重,并将其部署回客户端。这是建立在以前的分布式学习工作之上的,不仅提供本地模型,而且还在每个设备上本地执行训练。因此,FedAvg 有可能使客户端(尤其是具有小数据集的客户端)能够协作学习一个共享的预测模型,同时将所有训练数据保留在本地。尽管 FedAvg 在经典的联邦学习任务中取得了成功,但它在大多数 non-iid 内容中存在收敛速度慢和准确率低的问题 (Li)。
4 带有局部批量归一化的联邦平均
4.1 提出的方法 - FEDBN
我们提出了一种高效且有效的学习策略,称为 FedBN。与 FedAvg 类似,FedBN 执行本地更新并平均本地模型。然而,FedBN 假设本地模型具有 BN 层,并将它们的参数从平均步骤中排除。 我们在附录 C 中给出了完整的算法。这种简单的修改在 non-iid 设置中带来了显著的经验改进。我们在一个简化的场景中对这些改进进行了解释,在其中我们表明 FedBN 在特征偏移下提高了收敛速度。
4.2 问题设置
我们假设 N∈NN \in \mathbb{N}N∈N 个客户端联合训练 T∈NT \in \mathbb{N}T∈N 个周期,并在进行了 E∈NE \in \mathbb{N}E∈N 次局部迭代后进行通信。因此,系统在 TTT 个周期内有 T/ET/ET/E 个通信轮次。为了简单起见,我们假设所有客户端针对回归任务具有 M∈NM \in \mathbb{N}M∈N 个训练样本(训练样本数量的差异可以通过加权平均来考虑 (McMahan)),即,每个客户端 i∈[N]i \in [N]i∈[N]([N]={1,…,N}[N] = \{1, \dots, N\}[N]={1,…,N})拥有训练样本 {(xji,yji)∈Rd×R:j∈[M]}\{(\mathbf{x}_j^i, y_j^i) \in \mathbb{R}^d \times \mathbb{R} : j \in [M]\}{(xji,yji)∈Rd×R:j∈[M]}。此外,我们假设一个通过梯度下降训练的带有 ReLU 激活函数的两层神经网络。设 vk∈Rd\mathbf{v}_k \in \mathbb{R}^dvk∈Rd 表示第一层的参数,其中 k∈[m]k \in [m]k∈[m],mmm 是隐藏层的宽度。设 ∥v∥S≜v⊤Sv\|\mathbf{v}\|_{\mathbf{S}} \triangleq \sqrt{\mathbf{v}^\top \mathbf{S} \mathbf{v}}∥v∥S≜v⊤Sv 表示给定正定矩阵 S\mathbf{S}S 诱导的向量范数。
我们在 FL 中考虑一种 non-iid 设置,其中局部特征分布不同——而不是标签分布不同(如 McMahan; Li 中所考虑的)。更准确地说,我们做出以下假设。
假设 4.1 (数据分布). 对于每个客户端 i∈[N]i \in [N]i∈[N],输入 xji\mathbf{x}_j^ixji 是居中的(Exi=0\mathbb{E}\mathbf{x}^i = \mathbf{0}Exi=0),其协方差矩阵为 Si=Exixi⊤\mathbf{S}_i = \mathbb{E}\mathbf{x}^i{\mathbf{x}^i}^\topSi=Exixi⊤,其中 Si\mathbf{S}_iSi 独立于标签 yyy,并且对于每个 i∈[N]i \in [N]i∈[N] 可能不同,例如,Si\mathbf{S}_iSi 不全为单位矩阵,并且对于每个索引对 p≠qp \neq qp=q,对所有 κ∈R∖{0}\kappa \in \mathbb{R} \setminus \{0\}κ∈R∖{0} 有 xp≠κ⋅xq\mathbf{x}_p \neq \kappa \cdot \mathbf{x}_qxp=κ⋅xq。
在假设 4.1 下,客户端 iii 第一层的归一化是 vk⊤xi∥vk∥Si\frac{\mathbf{v}_k^\top \mathbf{x}^i}{\|\mathbf{v}_k\|_{\mathbf{S}_i}}∥vk∥Sivk⊤xi。带有客户端指定的 BN 参数的 FedBN 训练一个模型 f∗:Rd→Rf^* : \mathbb{R}^d \to \mathbb{R}f∗:Rd→R,由 (V,γ,c)∈Rm×d×Rm×N×Rm(\mathbf{V}, \gamma, \mathbf{c}) \in \mathbb{R}^{m \times d} \times \mathbb{R}^{m \times N} \times \mathbb{R}^m(V,γ,c)∈Rm×d×Rm×N×Rm 参数化,即:
f∗(x;V,γ,c)=1m∑k=1mck∑i=1Nσ(γk,i⋅vk⊤x∥vk∥Si)⋅1{x∈client i} ,(1) f^*(\mathbf{x}; \mathbf{V}, \gamma, \mathbf{c}) = \frac{1}{\sqrt{m}} \sum_{k=1}^m c_k \sum_{i=1}^N \sigma\left( \gamma_{k,i} \cdot \frac{\mathbf{v}_k^\top \mathbf{x}}{\|\mathbf{v}_k\|_{\mathbf{S}_i}} \right) \cdot \mathbb{1}\{\mathbf{x} \in \text{client } i\} \ , \quad (1) f∗(x;V,γ,c)=m1k=1∑mcki=1∑Nσ(γk,i⋅∥vk∥Sivk⊤x)⋅1{x∈client i} ,(1)
其中 γ\gammaγ 是 BN 的缩放参数,σ(s)=max{s,0}\sigma(s) = \max\{s, 0\}σ(s)=max{s,0} 是 ReLU 激活函数,c\mathbf{c}c 是网络的顶层参数。在这里,我们省略了学习 BN 的偏移参数 1^11。
1^11 我们省略了中心化神经元以及学习 BN 的偏移参数以用于神经网络分析,因为假设 x\mathbf{x}x 是零均值的并且是两层网络设置 (Kohler; Salimans & Kingma)。
相反,FedAvg 训练的函数 f:Rd→Rf : \mathbb{R}^d \to \mathbb{R}f:Rd→R 是公式 1 的特例,其中对 ∀i∈[N]\forall i \in [N]∀i∈[N] 都有 γk,i=γk\gamma_{k,i} = \gamma_kγk,i=γk。我们在分析中对参数进行随机初始化 (Salimans & Kingma):
vk(0)∼N(0,α2I),ck∼U{−1,1},并且γk=γk,i=∥vk(0)∥2/α,(2) \mathbf{v}_k(0) \sim \mathcal{N}(0, \alpha^2\mathbf{I}), \quad c_k \sim U\{-1, 1\}, \quad \text{并且} \quad \gamma_k = \gamma_{k,i} = \|\mathbf{v}_k(0)\|_2 / \alpha, \quad (2) vk(0)∼N(0,α2I),ck∼U{−1,1},并且γk=γk,i=∥vk(0)∥2/α,(2)
其中 α2\alpha^2α2 控制了初始化时 vk\mathbf{v}_kvk 的大小。BN 参数 γk\gamma_kγk 和 γk,i\gamma_{k,i}γk,i 的初始化独立于 α\alphaα。网络 f∗(x;V,γ,c)f^*(\mathbf{x}; \mathbf{V}, \gamma, \mathbf{c})f∗(x;V,γ,c) 的参数是通过使用梯度下降最小化相对于平方损失的经验风险获得的:
L(f∗)=1NM∑i=1N∑j=1M(f∗(xji)−yji)2 .(3) L(f^*) = \frac{1}{NM} \sum_{i=1}^N \sum_{j=1}^M \left( f^*(\mathbf{x}_j^i) - y_j^i \right)^2 \ . \quad (3) L(f∗)=NM1i=1∑Nj=1∑M(f∗(xji)−yji)2 .(3)
4.3 收敛性分析
在这里,我们通过 Jacot 引入的神经正切核 (Neural Tangent Kernel, NTK) 来研究网络 FedAvg (fff) 和 FedBN (f∗f^*f∗) 预测的轨迹。最近的机器学习理论研究 (Arora; Du; Allen-Zhu; van den Brand; Dukler) 已经表明,对于有限宽度的超参数化网络,收敛速度由训练演化过程中诱导核的最小特征值控制。
为了简化追踪优化动态,我们考虑局部更新数量 E=1E=1E=1 的情况。我们可以将 NTK 分解为幅度分量 G(t)\mathbf{G}(t)G(t) 和方向分量 V(t)/α2\mathbf{V}(t)/\alpha^2V(t)/α2,遵循 Dukler:
dfdt=−Λ(t)(f(t)−y),其中Λ(t):=V(t)α2+G(t). \frac{df}{dt} = -\mathbf{\Lambda}(t)(f(t) - y), \quad \text{其中} \quad \mathbf{\Lambda}(t) := \frac{\mathbf{V}(t)}{\alpha^2} + \mathbf{G}(t). dtdf=−Λ(t)(f(t)−y),其中Λ(t):=α2V(t)+G(t).
V(t)\mathbf{V}(t)V(t) 和 G(t)\mathbf{G}(t)G(t) 的具体形式见附录 B.1。令 λmin(A)\lambda_{\min}(\mathbf{A})λmin(A) 表示矩阵 A\mathbf{A}A 的最小特征值。矩阵 V(t)\mathbf{V}(t)V(t) 和 G(t)\mathbf{G}(t)G(t) 是半正定的,因为它们可以被视为协方差矩阵。这给出了 λmin(Λ(t))≥max{λmin(V(t))/α2,λmin(G(t))}\lambda_{\min}(\mathbf{\Lambda}(t)) \ge \max\{\lambda_{\min}(\mathbf{V}(t))/\alpha^2, \lambda_{\min}(\mathbf{G}(t))\}λmin(Λ(t))≥max{λmin(V(t))/α2,λmin(G(t))}。根据 NTK,收敛速度由 λmin(Λ(t))\lambda_{\min}(\mathbf{\Lambda}(t))λmin(Λ(t)) 控制。那么,对于 α>1\alpha > 1α>1,收敛由 G(t)\mathbf{G}(t)G(t) 主导。令 Λ(t)\mathbf{\Lambda}(t)Λ(t) 和 Λ∗(t)\mathbf{\Lambda}^*(t)Λ∗(t) 表示 FedAvg 和 FedBN 的演化动态,令 G(t)\mathbf{G}(t)G(t) 和 G∗(t)\mathbf{G}^*(t)G∗(t) 表示 FedAvg 和 FedBN 演化动态中的幅度分量。对于收敛性分析,我们使用 Gram 矩阵的辅助版本,定义如下。
定义 4.2. 给定样本点 {xp}p=1NM\{\mathbf{x}_p\}_{p=1}^{NM}{xp}p=1NM,我们定义辅助 Gram 矩阵 G∞∈RNM×NM\mathbf{G}^\infty \in \mathbb{R}^{NM \times NM}G∞∈RNM×NM 和 G∗∞∈RNM×NM\mathbf{G}^{*\infty} \in \mathbb{R}^{NM \times NM}G∗∞∈RNM×NM 如下:
Gpq∞:=Ev∼N(0,α2I)σ(v⊤xp)σ(v⊤xq),(FedAvg)(4) \mathbf{G}_{pq}^\infty := \mathbb{E}_{\mathbf{v} \sim \mathcal{N}(0, \alpha^2\mathbf{I})} \sigma(\mathbf{v}^\top \mathbf{x}_p) \sigma(\mathbf{v}^\top \mathbf{x}_q), \quad (\text{FedAvg}) \quad (4) Gpq∞:=Ev∼N(0,α2I)σ(v⊤xp)σ(v⊤xq),(FedAvg)(4)
Gpq∗∞:=Ev∼N(0,α2I)σ(v⊤xp)σ(v⊤xq)1{ip=iq},(FedBN).(5) \mathbf{G}_{pq}^{*\infty} := \mathbb{E}_{\mathbf{v} \sim \mathcal{N}(0, \alpha^2\mathbf{I})} \sigma(\mathbf{v}^\top \mathbf{x}_p) \sigma(\mathbf{v}^\top \mathbf{x}_q) \mathbb{1}\{i_p = i_q\}, \quad (\text{FedBN}). \quad (5) Gpq∗∞:=Ev∼N(0,α2I)σ(v⊤xp)σ(v⊤xq)1{ip=iq},(FedBN).(5)
给定假设 4.1,我们使用 Dukler 中的关键结果来证明 G∞\mathbf{G}^\inftyG∞ 是正定的。进一步,我们证明了 G∗∞\mathbf{G}^{*\infty}G∗∞ 也是正定的。我们利用超参数化神经网络中 G(t)\mathbf{G}(t)G(t) 及其辅助版本之间的距离很小这一事实,使得 G(t)\mathbf{G}(t)G(t) 保持正定。
引理 4.3. 固定满足假设 4.1 的点 {xp}p=1NM\{\mathbf{x}_p\}_{p=1}^{NM}{xp}p=1NM。那么如同 (4) 和 (5) 中定义的 Gram 矩阵 G∞\mathbf{G}^\inftyG∞ 和 G∗∞\mathbf{G}^{*\infty}G∗∞ 都是严格正定的。令最小特征值为 λmin(G∞)=:μ0\lambda_{\min}(\mathbf{G}^\infty) =: \mu_0λmin(G∞)=:μ0 和 λmin(G∗∞)=:μ0∗\lambda_{\min}(\mathbf{G}^{*\infty}) =: \mu_0^*λmin(G∗∞)=:μ0∗,其中 μ0,μ0∗>0\mu_0, \mu_0^* > 0μ0,μ0∗>0。
证明概要: 主要思想遵循 Du; Dukler,即给定点 {xp}p=1NM\{\mathbf{x}_p\}_{p=1}^{NM}{xp}p=1NM,矩阵 G∞\mathbf{G}^\inftyG∞ 和 G∗∞\mathbf{G}^{*\infty}G∗∞ 可以显示为线性独立算子的协方差矩阵。附录 B.2 给出了证明的更多细节。
基于我们的公式,可以通过考虑非相同协方差矩阵,从 Dukler 推导出 FedAvg 的收敛速度 (定理 4.4)。我们在推论 4.5 中推导出了 FedBN 的收敛速度。我们比较 FedAvg 和 FedBN 收敛速度的关键结果体现在推论 4.6 中。
定理 4.4 (FedAvg 以 G\mathbf{G}G 为主导的收敛 (Dukler)). 假设网络 (4) 按照 (2) 进行初始化且 α>1\alpha > 1α>1,使用梯度下降进行训练,并且假设 4.1 成立。给定训练神经网络的损失函数是带有目标 yyy 且满足 ∥y∥∞=O(1)\|y\|_\infty = \mathcal{O}(1)∥y∥∞=O(1) 的平方损失。如果 m=Ω(max{N4M4log(NM/δ)/α4μ04,N2M2log(NM/δ)/μ02})m = \Omega \left( \max \{ N^4M^4\log(NM/\delta) / \alpha^4 \mu_0^4, N^2M^2\log(NM/\delta)/\mu_0^2 \} \right)m=Ω(max{N4M4log(NM/δ)/α4μ04,N2M2log(NM/δ)/μ02}),那么以 1−δ1 - \delta1−δ 的概率:
- 对于迭代 t=0,1,…t = 0, 1, \dotst=0,1,…,演化矩阵 Λ(t)\mathbf{\Lambda}(t)Λ(t) 满足 λmin(Λ(t))≥μ02\lambda_{\min}(\mathbf{\Lambda}(t)) \ge \frac{\mu_0}{2}λmin(Λ(t))≥2μ0。
- 使用步长 η=O(1∥Λ(t)∥)\eta = \mathcal{O}\left(\frac{1}{\|\mathbf{\Lambda}(t)\|}\right)η=O(∥Λ(t)∥1) 的梯度下降训练呈线性收敛:
∥f(t)−y∥22≤(1−ημ02)t∥f(0)−y∥22. \|f(t) - y\|_2^2 \le \left(1 - \frac{\eta \mu_0}{2}\right)^t \|f(0) - y\|_2^2. ∥f(t)−y∥22≤(1−2ημ0)t∥f(0)−y∥22.
遵循 Dukler 中的关键思想,我们在下文进一步表征了 FedBN 的收敛性。
推论 4.5 (FedBN 以 G\mathbf{G}G 为主导的收敛). 假设网络 (5) 且满足定理 4.4 中的所有其他条件。以 1−δ1-\delta1−δ 的概率,对于迭代 t=0,1,…t = 0, 1, \dotst=0,1,…,演化矩阵 Λ∗(t)\mathbf{\Lambda}^*(t)Λ∗(t) 满足 λmin(Λ∗(t))≥μ0∗2\lambda_{\min}(\mathbf{\Lambda}^*(t)) \ge \frac{\mu_0^*}{2}λmin(Λ∗(t))≥2μ0∗,并且使用步长 η=O(1∥Λ∗(t)∥)\eta = \mathcal{O}\left(\frac{1}{\|\mathbf{\Lambda}^*(t)\|}\right)η=O(∥Λ∗(t)∥1) 的梯度下降训练呈线性收敛:
∥f∗(t)−y∥22≤(1−ημ0∗2)t∥f∗(0)−y∥22. \|f^*(t) - y\|_2^2 \le \left(1 - \frac{\eta \mu_0^*}{2}\right)^t \|f^*(0) - y\|_2^2. ∥f∗(t)−y∥22≤(1−2ημ0∗)t∥f∗(0)−y∥22.
FedAvg (1−ημ0/21 - \eta \mu_0/21−ημ0/2) 和 FedBN (1−ημ0∗/21 - \eta \mu_0^*/21−ημ0∗/2) 收敛的指数因子分别由 G(t)\mathbf{G}(t)G(t) 和 G∗(t)\mathbf{G}^*(t)G∗(t) 的最小特征值控制。然后,我们可以通过比较 λmin(G∞)\lambda_{\min}(\mathbf{G}^\infty)λmin(G∞) 和 λmin(G∗∞)\lambda_{\min}(\mathbf{G}^{*\infty})λmin(G∗∞) 来分析 FedAvg 和 FedBN 的收敛性能。
推论 4.6 (FedAvg 和 FedBN 之间的收敛速度比较). 对于以 G\mathbf{G}G 为主导的收敛,FedBN 的收敛速度比 FedAvg 更快。
证明概要: 关键是要证明 λmin(G∞)≤λmin(G∗∞)\lambda_{\min}(\mathbf{G}^\infty) \le \lambda_{\min}(\mathbf{G}^{*\infty})λmin(G∞)≤λmin(G∗∞)。比较方程 (4) 和 (5),G∗∞\mathbf{G}^{*\infty}G∗∞ 取 G∞\mathbf{G}^\inftyG∞ 对角线上的 M×MM \times MM×M 分块矩阵。令 Gi∞\mathbf{G}_i^\inftyGi∞ 为 G∞\mathbf{G}^\inftyG∞ 对角线上的第 iii 个 M×MM \times MM×M 分块矩阵。由线性代数可知,λmin(Gi∞)≥λmin(G∞)\lambda_{\min}(\mathbf{G}_i^\infty) \ge \lambda_{\min}(\mathbf{G}^\infty)λmin(Gi∞)≥λmin(G∞) 对于 i∈[N]i \in [N]i∈[N] 成立。由于 G∗∞=diag(G1∞,…,GN∞)\mathbf{G}^{*\infty} = \text{diag}(\mathbf{G}_1^\infty, \dots, \mathbf{G}_N^\infty)G∗∞=diag(G1∞,…,GN∞),我们有 λmin(G∗∞)=mini∈[N]{λmin(Gi∞)}\lambda_{\min}(\mathbf{G}^{*\infty}) = \min_{i \in [N]}\{\lambda_{\min}(\mathbf{G}_i^\infty)\}λmin(G∗∞)=mini∈[N]{λmin(Gi∞)}。因此,我们得到结果 λmin(G∗∞)≥λmin(G∞)\lambda_{\min}(\mathbf{G}^{*\infty}) \ge \lambda_{\min}(\mathbf{G}^\infty)λmin(G∗∞)≥λmin(G∞)。
5 实验
在本节中,我们证明了当存在异构数据的跨客户端特征偏移时,使用局部 BN 参数是有益的。我们新颖的局部参数共享策略 FedBN 在特征偏移的 non-iid 数据集上实现了更鲁棒和更快的收敛,并且与替代方法相比获得了更好的模型性能。这一点在基准数据集和大型真实世界数据集上都得到了体现。
5.1 基准实验
设置: 我们使用包含来自不同域的特征偏移数据源的基准数字分类任务进行广泛的实证分析。不同域的数据具有异构的外观,但共享相同的标签和标签分布。具体来说,我们使用以下五个数据集:SVHN (Netzer), USPS (Hull), SynthDigits (Ganin & Lempitsky), MNIST-M (Ganin & Lempitsky) 和 MNIST (LeCun)。为了匹配第 4 节中的设置,我们通过随机抽样将这五个数据集的样本大小截断为其中最小的数字,导致每个数据集有 7438 个训练样本 2^22。在该基准数据集上的所有实验中,测试样本都被保留并保持一致。
2^22 这种数据预处理旨在严格控制非相关因素(例如,跨客户端的不平衡样本数量),以便实验结果能够更清楚地反映局部 BN 的效果。没有截断的结果报告在附录 E.2 中。
我们的分类模型是一个卷积神经网络,在每个特征提取层(即卷积层和全连接层)之后添加了 BN 层。该架构在附录 D.2 中有详细说明。
对于模型训练,我们使用交叉熵损失和学习率为 10−210^{-2}10−2 的 SGD 优化器。如果没有指定,我们对局部更新周期的默认设置为 E=1E = 1E=1,并且每个客户端数据量的默认设置为数据集原始大小的 10% 3^33。对于默认的 non-iid 设置,FL 系统包含五个客户端。每个客户端独占拥有从这五个数据集之一采样的数据。更多细节列在附录 D.2 中。
3^33 选择 10% 比例作为默认设置是基于 (i) 将其视为呈现我们方法总体功效的典型设置;(ii) 与文献相匹配,其中客户端大小通常在 100 到 1000 个数据点左右 (McMahan; Li; Hsu),这与我们 10% 的设置处于相似的规模(就样本数量的绝对值而言)。
概览: 在接下来的段落中,我们对所提出的 FedBN 方法的属性进行了全面调查,包括:(1) 收敛速度;(2) 相对于局部更新周期的选择的行为;(3) 在每个客户端具有不同数据量情况下的表现;(4) 不同异质性水平下的影响;(5) 与当前最先进方法 (FedProx (Li)) 以及两个基线 (FedAvg 和 SingleSet,即在每个客户端内训练一个单独的模型) 的比较。在附录 G 中,我们还提供了将包含未知域数据的新客户端纳入学习系统的经验结果。

图 3 说明:数字分类数据集上 FedBN 和 FedAvg 训练损失的收敛情况。FedBN 展现出更快和更鲁棒的收敛。
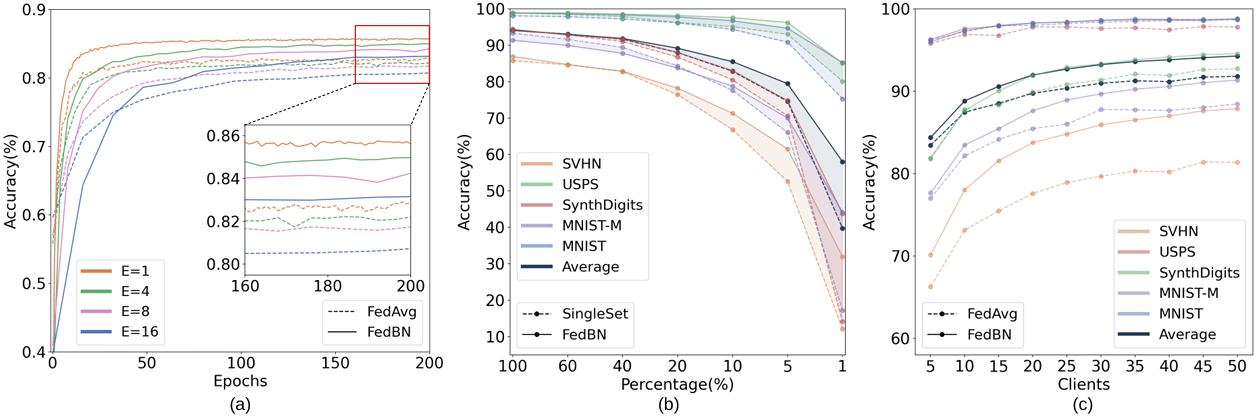
图 4 说明:分析实验结果:(a) 不同的局部更新周期下的分析。FedBN 在测试准确率上始终优于 FedAvg。(b) 在不同大小的局部客户端数据集上的模型表现。© 不同异质性水平下的测试准确率。
收敛速度: 我们分析了 FedBN 与 FedAvg 的训练损失曲线比较,如图 3 所示。FedBN 的损失比 FedAvg 下降得更快更平滑,表明 FedBN 的收敛速度更快。此外,与 FedAvg 相比,FedBN 在学习过程中表现出更平滑、更稳定的损失曲线。这些实验观察结果与推论 4.6 给出的结果一致。此外,我们在附录 E.1 中给出了关于不同局部更新周期 EEE 对 FedBN 和 FedAvg 收敛速度影响的更全面的比较。结果显示出与图 3 相似的模式。
局部更新周期分析: 以不同的频率进行聚合可能会影响学习行为。尽管我们的理论和其他实验的默认设置采用 E=1E=1E=1,但我们证明了 FedBN 在 E>1E > 1E>1 的情况下是有效的。在图 4 (a) 中,我们探索了 E=1,4,8,16E=1, 4, 8, 16E=1,4,8,16,并将 FedBN 与基线 FedAvg 进行了比较。正如预期的那样,图 4 (a) 暗示了对于 FedBN 和 FedAvg 来说,局部更新周期 EEE 和测试准确率之间存在反比关系。放大到最终的测试准确率,在不同的 EEE 下,FedBN 的准确率都稳定地超过了 FedAvg 的准确率。
局部数据集大小分析: 我们将每个客户端的数据量从其原始数据集大小的 100% 更改为 1%,以观察 FedBN 在每个客户端不同的数据容量下的行为。图 4 (b) 的结果展示了 FedBN 和 SingleSet 的准确率 4^44。当每个局部客户端仅被分配其原始数据量的 20% 时,测试准确率开始显著下降。从 FedBN 获得的提升幅度随着局部数据集大小的减小而增加。结果表明,FedBN 可以有效地从分布式数据的协同训练中受益,特别是当每个客户端只持有少量 non-iid 数据时。
4^44 附录 E.2 中提供了详细的统计数据和 FedAvg 的结果。
统计异质性的影响: 出现的一个显著问题是:在什么程度的特征偏移异质性下,FedBN 优于 FedAvg?为了回答这个问题,我们模拟了下面描述的具有不同异质性的联邦设置。我们将每个数据集划分为 10 个子集,每个客户端一个,具有相同数量的数据样本和相同的标签分布。我们将从相同数据集生成的客户端视为 iid 客户端,而将从不同数据集生成的客户端视为 non-iid 客户端。

表 1 说明:我们报告了来自 5 次试验运行的三个不同真实世界数据集的结果,格式为 平均值(标准差)。对于 Office-Caltech 10,A,C,D,WA, C, D, WA,C,D,W 是 Amazon, Caltech, DSLR 和 WebCam 的缩写;对于 DomainNet,C,I,P,Q,R,SC, I, P, Q, R, SC,I,P,Q,R,S 是 Clipart, Infograph, Painting, Quickdraw, Real 和 Sketch 的缩写。对于 ABIDE,我们列出了客户端(即医疗机构)的缩写。
我们首先将每个数据集中的一个客户端纳入 FL 系统。然后,我们同时从每个数据集中添加一个客户端,同时保持现有的客户端,重复 nnn 次,对于 n∈{1,…,9}n \in \{1, \dots, 9\}n∈{1,…,9} 5^55。对于每个设置,我们从头开始训练模型。更多的客户端对应于较少的异质性。我们在图 4 © 中展示了在不同异质性水平下的测试准确率,并包含了与为 iid FL 设计的 FedAvg 的比较。我们的 FedBN 在所有异质性水平下都实现了比 FedAvg 高得多的测试准确率。
5^55 也就是说,每次增加都包含五个 non-iid 客户端。

图 5 说明:基准实验上的表现。
与最先进方法的比较: 为了进一步验证我们的方法,我们将 FedBN 与目前最先进的 non-iid FL 方法之一 FedProx (Li) 进行了比较,该方法同样具有易于适配到当前实际 FL 框架的优势。我们还包括了基于 SingleSet 和 FedAvg 的训练作为基线。对于每种策略,我们将一个独立的测试数据集拆分给客户端,并报告在这些测试数据集上的准确率。我们使用不同的随机种子进行了 5 次重复实验。各个数据集上多次试验的平均准确率和标准差如图 5 6^66 所示。从结果中,我们可以得出以下观察结论:(1) FedBN 实现了最高准确率,始终优于最新技术和基线方法;(2) FedBN 在 SVHN(其图像外观与其他的截然不同,即呈现出更明显的特征偏移)上取得了最显著的提升;(3) FedBN 在多次运行中显示出较小的误差方差,表明其具备稳定性。
6^66 详细统计数据见附录 E.2。
5.2 真实世界数据集上的实验
为了更好地理解我们提出的算法如何在现实世界的特征偏移 non-iid 中发挥作用,我们广泛验证了 FedBN 与其他方法在三个真实世界数据集上的有效性:在不同的相机或环境中获取的图像 Office-Caltech10 (Gong) 上的图像分类;具有不同图像风格的 DomainNet (Peng) 上的图像分类;以及 ABIDE I (Di Martino) 上针对来自不同医疗机构的患者的神经系统疾病诊断任务 7^77。
7^77 有关数据集和训练过程的更多详细信息,请参见附录 D.3 和 D.4。
数据集和设置:
(1) 我们对来自 Office-Caltech10 的自然图像进行分类任务,该数据集包含组成 Office-31 (Saenko) (三个数据源) 和 Caltech-256 数据集 (一个数据源) (Griffin) 的四个数据源,这些图像是在使用不同的相机设备或在具有各种背景的不同真实环境中获取的。加入 FL 系统的每个客户端都被分配了来自四个数据源之一的数据。因此,客户端之间的数据是 non-iid 的。
(2) 我们的第二个数据集是 DomainNet,它包含来自六个不同数据源的自然图像:Clipart, Infograph, Painting, Quickdraw, Real, 和 Sketch。类似于 (1),每个客户端包含来自其中一个数据源的 iid 数据,但具有不同数据源的客户端具有不同的特征分布。
(3) 我们包括了来自 ABIDE I 的四个医疗机构 (NYU, USM, UM, UCLA;每个都被视为一个客户端),它们收集了使用不同成像设备和协议的脑功能图像。我们验证了一个医学应用:在自闭症谱系障碍患者和健康对照受试者之间进行二分类。
Office-Caltech10 包含十类对象。DomainNet 广泛包含 345 个对象类别,我们在实验中使用了最常见的十个类别来组成子数据集。我们的分类模型采用了 AlexNet (Krizhevsky) 架构,在每个卷积层和全连接层之后都添加了 BN。在输入网络之前,所有图像都被调整为 256×256×3256 \times 256 \times 3256×256×3。对于 ABIDE I,每个实例通过大脑连接组 (connectome) 计算被表示为一个 5995 维的向量。我们使用一个隐藏层大小为 16 的三层全连接神经网络作为分类器,在前两个全连接层之后带有两个 BN 层。与上述基准测试相同,我们对每个实验进行 5 次重复运行。
结果与分析: 实验结果以 平均值(标准差) 的形式显示在表 1 中。在 Office-Caltech10 上,FedBN 显著优于最先进的 FedProx 方法,并且与所有其他替代方法相比,平均准确率至少提高了 6%。在 DomainNet 上,FedBN 在大多数数据集上都取得了最高的准确率。有趣的是,我们发现替代的 FL 方法除了在 Quickdraw 上,取得了与 SingleSet 相当的结果,而 FedBN 优于它们 10% 以上。令人惊讶的是,对于上述两项任务,替代的 FL 策略在特征偏移 non-iid 数据集上是无效的,甚至比对大多数客户端使用单客户端数据进行训练还要糟糕。在 ABIDE I 中,FedBN 在三个客户端的平均测试准确率上均以不可忽视的优势胜出。这些结果令人鼓舞,并为将 FedBN 部署到医疗保健领域带来了希望,因为医疗领域的数据通常是有限的、孤立的,并且在特征上是异构的。
6 结论和讨论
这项工作提出了一种名为 FedBN 的新型联邦学习聚合方法,该方法保持局部的批量归一化参数与全局模型不同步,从而减轻了 non-IID 数据中的特征偏移。 我们为 FedBN 在超参数化神经网络范畴下的真实联邦设置中提供了收敛保证,同时还考虑了实际问题。在我们的实验中,我们对一套联邦数据集的评估表明,FedBN 可以显著改善 non-IID 数据集的收敛行为和模型性能。我们还展示了在将带有未知域数据的新客户端加入 FL 系统的场景下,FedBN 的有效性(见附录 G)。
FedBN 独立于通信和聚合策略,因此在实践中可以很容易地与不同的优化算法、通信方案和聚合技术结合起来。对此类组合进行理论分析是未来工作的一个有趣方向。
我们还注意到,由于 FedBN 只对 FedAvg 进行了轻量级修改,并且具有与其他策略结合的极大灵活性,这些优点使我们能够轻松地将 FedBN 集成到现有工具包/系统中,例如 Pysyft (Ryffel), Google TFF (Google), Flower (Beutel), dlplatform (Kamp & Adilova) 和 FedML (He) 8^88。
8^88 dlplatform 和 Flower 上的实现已可用,FedML 上的实现即将推出。
我们相信 FedBN 可以改善医疗保健 (Rieke) 和自动驾驶 (Kamp) 等广泛的应用。未来工作的一些有趣方向包括:分析本地数据中的哪些差异类型可以从 FedBN 中受益,并探索 FedBN 的局限性。此外,隐私是 FL 中的一个核心问题。FedBN 中不可见的 BN 参数应该会使对本地数据的攻击变得更具挑战性。量化 FedBN 在隐私保护方面的改进将会很有趣。
参考文献
见论文
附录
附录路线图: 附录的组织结构如下。我们在 A 节中列出了符号表。我们在 B 节中提供了收敛的理论证明。C 节中描述了 FedBN 的算法。D 节给出了实验设置的细节,E 节展示了基准数据集上的额外结果。我们在 F 节展示了合成数据上的实验。我们在 G 节证明了将 FedBN 泛化以在新的客户端上进行测试的能力。
A 符号表
表 2:论文中出现的符号。
| 符号 | 描述 |
|---|---|
| x\mathbf{x}x | 特征,x∈Rd\mathbf{x} \in \mathbb{R}^dx∈Rd |
| ddd | x\mathbf{x}x 的维度 |
| yyy | 标签,y∈Ry \in \mathbb{R}y∈R |
| P(⋅)P(\cdot)P(⋅) | 概率分布 |
| NNN | 客户端总数 |
| TTT | 训练的总周期 (epochs) 数 |
| EEE | FL 中的局部迭代次数 |
| MMM | 每个客户端中的训练样本数 |
| [N][N][N] | 集合,[N]={1,…,N}[N] = \{1, \dots, N\}[N]={1,…,N} |
| iii | 客户端指示符,i∈[N]i \in [N]i∈[N] |
| jjj | 每个客户端中样本的指示符,j∈[M]j \in [M]j∈[M] |
| (xji,yji)(\mathbf{x}_j^i, y_j^i)(xji,yji) | 客户端 iii 中的第 jjj 个训练样本 |
| mmm | 第一层的神经元数量 |
| kkk | 神经元指示符,k∈[m]k \in [m]k∈[m] |
| vk\mathbf{v}_kvk | 第一层中第 kkk 个神经元的参数 |
| ∣v∣S|\mathbf{v}|_{\mathbf{S}}∣v∣S | 向量范数,给定矩阵 S\mathbf{S}S,∣v∣S≜v⊤Sv|\mathbf{v}|_{\mathbf{S}} \triangleq \sqrt{\mathbf{v}^\top \mathbf{S} \mathbf{v}}∣v∣S≜v⊤Sv |
| Si\mathbf{S}_iSi | 客户端 iii 中特征的协方差矩阵,Si=Exixi⊤\mathbf{S}_i = \mathbb{E}\mathbf{x}^i{\mathbf{x}^i}^\topSi=Exixi⊤ |
| p,qp, qp,q | 样本指示符,p,q∈[NM]p, q \in [NM]p,q∈[NM] |
| fff | 带有 BN 的两层 ReLU 神经网络 |
| f∗f^*f∗ | 带有客户端指定 BN 参数的、带有 BN 的两层 ReLU 神经网络 |
| V\mathbf{V}V | 第一阶段神经元的参数,V∈Rm×d\mathbf{V} \in \mathbb{R}^{m \times d}V∈Rm×d |
| γ\gammaγ | BN 的缩放参数 |
| c\mathbf{c}c | 网络的顶层参数 |
| σ(⋅)\sigma(\cdot)σ(⋅) | ReLU 激活函数,σ(⋅)=max{⋅,0}\sigma(\cdot) = \max\{\cdot, 0\}σ(⋅)=max{⋅,0} |
| N(μ,Σ)\mathcal{N}(\boldsymbol{\mu}, \mathbf{\Sigma})N(μ,Σ) | 均值为 μ\boldsymbol{\mu}μ,协方差为 Σ\mathbf{\Sigma}Σ 的高斯分布 |
| U[−1,1]U[-1, 1]U[−1,1] | Rademacher 分布 |
| α\alphaα | 初始化时 vk\mathbf{v}_kvk 的方差 |
| L(f)L(f)L(f) | 网络 fff 使用平方损失的经验风险 |
| Λ(t)\mathbf{\Lambda}(t)Λ(t) | 周期 ttt 时 FedAvg 的演化动态 |
| V(t)\mathbf{V}(t)V(t) | 周期 ttt 时 FedAvg 关于 V\mathbf{V}V 的演化动态 |
| G(t)\mathbf{G}(t)G(t) | 周期 ttt 时 FedAvg 关于 γ\gammaγ 的演化动态 |
| Λ∗(t)\mathbf{\Lambda}^*(t)Λ∗(t) | 周期 ttt 时 FedBN 的演化动态 |
| V∗(t)\mathbf{V}^*(t)V∗(t) | 周期 ttt 时 FedBN 关于 V\mathbf{V}V 的演化动态 |
| G∗(t)\mathbf{G}^*(t)G∗(t) | 周期 ttt 时 FedBN 关于 γ\gammaγ 的演化动态 |
| λmin(A)\lambda_{\min}(A)λmin(A) | 矩阵 AAA 的最小特征值 |
| G∞\mathbf{G}^\inftyG∞ | G(t)\mathbf{G}(t)G(t) 的期望 |
| G∗∞\mathbf{G}^{*\infty}G∗∞ | G∗(t)\mathbf{G}^*(t)G∗(t) 的期望 |
B 收敛性证明
B.1 演化动态
在本节中,我们计算使用函数 fff 进行训练的演化动态 Λ(t)\mathbf{\Lambda}(t)Λ(t),以及使用 f∗f^*f∗ 进行训练的 Λ∗(t)\mathbf{\Lambda}^*(t)Λ∗(t)。由于参数使用梯度下降进行更新,参数的优化动态为
dvkdt=−∂L∂vk,dγkdt=−∂L∂γk. \frac{d\mathbf{v}_k}{dt} = -\frac{\partial L}{\partial \mathbf{v}_k}, \quad \frac{d\gamma_k}{dt} = -\frac{\partial L}{\partial \gamma_k}. dtdvk=−∂vk∂L,dtdγk=−∂γk∂L.
令 fp=f(xpip)f_p = f(\mathbf{x}_p^{i_p})fp=f(xpip)。然后,位点 ipi_pip 中第 ppp 个数据点的预测的动态为
∂fp∂t=∑k=1m∂fp∂vkdvkdt+∂fp∂γkdγkdt=−∑k=1m∂fp∂vk∂L∂vk⏟Tvp−∑k=1m∂fp∂γk∂L∂γk⏟Tγp. \frac{\partial f_p}{\partial t} = \sum_{k=1}^m \frac{\partial f_p}{\partial \mathbf{v}_k} \frac{d\mathbf{v}_k}{dt} + \frac{\partial f_p}{\partial \gamma_k} \frac{d\gamma_k}{dt} = - \underbrace{\sum_{k=1}^m \frac{\partial f_p}{\partial \mathbf{v}_k} \frac{\partial L}{\partial \mathbf{v}_k}}_{\mathbf{T}_v^p} - \underbrace{\sum_{k=1}^m \frac{\partial f_p}{\partial \gamma_k} \frac{\partial L}{\partial \gamma_k}}_{\mathbf{T}_\gamma^p}. ∂t∂fp=k=1∑m∂vk∂fpdtdvk+∂γk∂fpdtdγk=−Tvp
k=1∑m∂vk∂fp∂vk∂L−Tγp
k=1∑m∂γk∂fp∂γk∂L.
fpf_pfp 和 LLL 相对于 vk\mathbf{v}_kvk 和 γk\gamma_kγk 的梯度计算如下:
∂fp∂vk(t)=1mck⋅γk(t)∥vk(t)∥Sip⋅xpipvk(t)⊥1pk(t), \frac{\partial f_p}{\partial \mathbf{v}_k}(t) = \frac{1}{\sqrt{m}} \frac{c_k \cdot \gamma_k(t)}{\|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}} \cdot {\mathbf{x}_p^{i_p}}^{\mathbf{v}_k(t)^\perp} \mathbb{1}_{pk}(t), ∂vk∂fp(t)=m1∥vk(t)∥Sipck⋅γk(t)⋅xpipvk(t)⊥1pk(t),
∂L∂vk(t)=1m∑q=1NM(fq(t)−yq)ck⋅γk(t)∥vk(t)∥Siqxqiqvk(t)⊥1qk(t), \frac{\partial L}{\partial \mathbf{v}_k}(t) = \frac{1}{\sqrt{m}} \sum_{q=1}^{NM} (f_q(t) - y_q) \frac{c_k \cdot \gamma_k(t)}{\|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}} {\mathbf{x}_q^{i_q}}^{\mathbf{v}_k(t)^\perp} \mathbb{1}_{qk}(t), ∂vk∂L(t)=m1q=1∑NM(fq(t)−yq)∥vk(t)∥Siqck⋅γk(t)xqiqvk(t)⊥1qk(t),
∂fp∂γk(t)=1mck∥vk(t)∥Sipσ(vk(t)⊤xp), \frac{\partial f_p}{\partial \gamma_k}(t) = \frac{1}{\sqrt{m}} \frac{c_k}{\|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}} \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_p \right), ∂γk∂fp(t)=m1∥vk(t)∥Sipckσ(vk(t)⊤xp),
∂L∂γk(t)=1m∑q=1NM(fq(t)−yq)ck∥vk(t)∥Siqσ(vk(t)⊤xq), \frac{\partial L}{\partial \gamma_k}(t) = \frac{1}{\sqrt{m}} \sum_{q=1}^{NM} (f_q(t) - y_q) \frac{c_k}{\|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}} \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_q \right), ∂γk∂L(t)=m1q=1∑NM(fq(t)−yq)∥vk(t)∥Siqckσ(vk(t)⊤xq),
其中 fp=f(xpip)f_p = f(\mathbf{x}_p^{i_p})fp=f(xpip),xvk(t)⊥≜(I−Sipuu⊤∥u∥Sip2)x\mathbf{x}^{\mathbf{v}_k(t)^\perp} \triangleq (\mathbf{I} - \frac{\mathbf{S}_{i_p} \mathbf{u} \mathbf{u}^\top}{\|\mathbf{u}\|_{\mathbf{S}_{i_p}}^2})\mathbf{x}xvk(t)⊥≜(I−∥u∥Sip2Sipuu⊤)x,且 1pk(t)≜1{vk(t)⊤xp≥0}\mathbb{1}_{pk}(t) \triangleq \mathbb{1}_{\{\mathbf{v}_k(t)^\top \mathbf{x}_p \ge 0\}}1pk(t)≜1{vk(t)⊤xp≥0}。
我们将 Gram 矩阵 V(t)\mathbf{V}(t)V(t) 和 G(t)\mathbf{G}(t)G(t) 定义为
Vpq(t)=1m∑k=1m(αck⋅γk(t))2∥vk(t)∥Sip−1∥vk(t)∥Siq−1⟨xpipvk(t)⊥,xqiqvk(t)⊥⟩1pk(t)1qk(t),(6) \mathbf{V}_{pq}(t) = \frac{1}{m} \sum_{k=1}^m (\alpha c_k \cdot \gamma_k(t))^2 \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}^{-1} \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}^{-1} \left\langle {\mathbf{x}_p^{i_p}}^{\mathbf{v}_k(t)^\perp}, {\mathbf{x}_q^{i_q}}^{\mathbf{v}_k(t)^\perp} \right\rangle \mathbb{1}_{pk}(t)\mathbb{1}_{qk}(t), \quad (6) Vpq(t)=m1k=1∑m(αck⋅γk(t))2∥vk(t)∥Sip−1∥vk(t)∥Siq−1⟨xpipvk(t)⊥,xqiqvk(t)⊥⟩1pk(t)1qk(t),(6)
Gpq(t)=1m∑k=1mck2∥vk(t)∥Sip−1∥vk(t)∥Siq−1σ(vk(t)⊤xp)σ(vk(t)⊤xq).(7) \mathbf{G}_{pq}(t) = \frac{1}{m} \sum_{k=1}^m c_k^2 \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}^{-1} \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}^{-1} \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_p \right) \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_q \right). \quad (7) Gpq(t)=m1k=1∑mck2∥vk(t)∥Sip−1∥vk(t)∥Siq−1σ(vk(t)⊤xp)σ(vk(t)⊤xq).(7)
由此可得
Tvp(t)=∑q=1NMVpq(t)α2(fq(t)−yq),Tγp(t)=∑q=1NMGpq(t)(fq(t)−yq). \mathbf{T}_v^p(t) = \sum_{q=1}^{NM} \frac{\mathbf{V}_{pq}(t)}{\alpha^2} (f_q(t) - y_q), \quad \mathbf{T}_\gamma^p(t) = \sum_{q=1}^{NM} \mathbf{G}_{pq}(t) (f_q(t) - y_q). Tvp(t)=q=1∑NMα2Vpq(t)(fq(t)−yq),Tγp(t)=q=1∑NMGpq(t)(fq(t)−yq).
令 f=(f1,…,fn)⊤=(f(x1),…,f(xNM))⊤\mathbf{f} = (f_1, \dots, f_n)^\top = (f(\mathbf{x}_1), \dots, f(\mathbf{x}_{NM}))^\topf=(f1,…,fn)⊤=(f(x1),…,f(xNM))⊤。完整的演化动态由下式给出:
dfdt=−Λ(t)(f(t)−y),其中Λ(t):=V(t)α2+G(t). \frac{d\mathbf{f}}{dt} = -\mathbf{\Lambda}(t)(\mathbf{f}(t) - \mathbf{y}), \quad \text{其中} \quad \mathbf{\Lambda}(t) := \frac{\mathbf{V}(t)}{\alpha^2} + \mathbf{G}(t). dtdf=−Λ(t)(f(t)−y),其中Λ(t):=α2V(t)+G(t).
类似地,我们用 f∗f^*f∗ 为 FedBN 计算 Gram 矩阵 V∗(t)\mathbf{V}^*(t)V∗(t) 和 G∗(t)\mathbf{G}^*(t)G∗(t) 如下:
Vpq∗(t)=1m∑k=1m(αck)2γk,ip(t)γk,iq(t)∥vk(t)∥Sip−1∥vk(t)∥Siq−1⟨xpipvk(t)⊥,xqiqvk(t)⊥⟩1pk(t)1qk(t),(8) \mathbf{V}_{pq}^*(t) = \frac{1}{m} \sum_{k=1}^m (\alpha c_k)^2 \gamma_{k,i_p}(t) \gamma_{k,i_q}(t) \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}^{-1} \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}^{-1} \left\langle {\mathbf{x}_p^{i_p}}^{\mathbf{v}_k(t)^\perp}, {\mathbf{x}_q^{i_q}}^{\mathbf{v}_k(t)^\perp} \right\rangle \mathbb{1}_{pk}(t)\mathbb{1}_{qk}(t), \quad (8) Vpq∗(t)=m1k=1∑m(αck)2γk,ip(t)γk,iq(t)∥vk(t)∥Sip−1∥vk(t)∥Siq−1⟨xpipvk(t)⊥,xqiqvk(t)⊥⟩1pk(t)1qk(t),(8)
Gpq∗(t)=1m∑k=1mck2∥vk(t)∥Sip−1∥vk(t)∥Siq−1σ(vk(t)⊤xp)σ(vk(t)⊤xq)1{ip=iq}.(9) \mathbf{G}_{pq}^*(t) = \frac{1}{m} \sum_{k=1}^m c_k^2 \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_p}}^{-1} \|\mathbf{v}_k(t)\|_{\mathbf{S}_{i_q}}^{-1} \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_p \right) \sigma\left( \mathbf{v}_k(t)^\top \mathbf{x}_q \right) \mathbb{1}\{i_p = i_q\}. \quad (9) Gpq∗(t)=m1k=1∑mck2∥vk(t)∥Sip−1∥vk(t)∥Siq−1σ(vk(t)⊤xp)σ(vk(t)⊤xq)1{ip=iq}.(9)
因此,FedBN 的完整演化动态为
df∗dt=−Λ∗(t)(f∗(t)−y),其中Λ∗(t):=V∗(t)α2+G∗(t). \frac{d\mathbf{f}^*}{dt} = -\mathbf{\Lambda}^*(t)(\mathbf{f}^*(t) - \mathbf{y}), \quad \text{其中} \quad \mathbf{\Lambda}^*(t) := \frac{\mathbf{V}^*(t)}{\alpha^2} + \mathbf{G}^*(t). dtdf∗=−Λ∗(t)(f∗(t)−y),其中Λ∗(t):=α2V∗(t)+G∗(t).
B.2 引理 4.3 的证明
Dukler 证明了矩阵 G∞\mathbf{G}^\inftyG∞ 是严格正定的。在他们的证明中,G∞\mathbf{G}^\inftyG∞ 是定义为 ϕp(v):=σ(v⊤xp)\phi_p(\mathbf{v}) := \sigma(\mathbf{v}^\top \mathbf{x}_p)ϕp(v):=σ(v⊤xp) 的泛函在希尔伯特空间 V\mathcal{V}V(包含于 L2(N(0,α2I))L^2(\mathcal{N}(0, \alpha^2\mathbf{I}))L2(N(0,α2I)))上的协方差矩阵。G∗∞\mathbf{G}^{*\infty}G∗∞ 是严格正定的,通过证明 ϕ1,…,ϕNM\phi_1, \dots, \phi_{NM}ϕ1,…,ϕNM 线性无关,这等价于:
c1ϕ1+c2ϕ2+⋯+cNMϕNM=0 在 V 中(10) c_1 \phi_1 + c_2 \phi_2 + \dots + c_{NM} \phi_{NM} = 0 \text{ 在 } \mathcal{V} \text{ 中} \quad (10) c1ϕ1+c2ϕ2+⋯+cNMϕNM=0 在 V 中(10)
只有对于所有 ppp 有 cp=0c_p = 0cp=0 时才成立。
令 Gi∞\mathbf{G}_i^\inftyGi∞ 表示 G∞\mathbf{G}^\inftyG∞ 对角线上的第 iii 个 M×MM \times MM×M 分块矩阵。那么我们有:
G∗∞=diag(G1∞,…,GN∞). \mathbf{G}^{*\infty} = \text{diag}(\mathbf{G}_1^\infty, \dots, \mathbf{G}_N^\infty). G∗∞=diag(G1∞,…,GN∞).
要证明 G∗∞\mathbf{G}^{*\infty}G∗∞ 严格正定,我们将证明 Gi∞\mathbf{G}_i^\inftyGi∞ 是正定的。让我们定义
ϕj,i∗(v):=σ(v⊤xj)1{j∈site i},j=1,…,M. \phi_{j,i}^*(\mathbf{v}) := \sigma(\mathbf{v}^\top \mathbf{x}_j) \mathbb{1}\{j \in \text{site } i\}, \quad j = 1, \dots, M. ϕj,i∗(v):=σ(v⊤xj)1{j∈site i},j=1,…,M.
那么,我们将展示
c1ϕ1,i∗+c2ϕ2,i∗+⋯+cMϕM,i∗=0(11) c_1 \phi_{1,i}^* + c_2 \phi_{2,i}^* + \dots + c_M \phi_{M,i}^* = 0 \quad (11) c1ϕ1,i∗+c2ϕ2,i∗+⋯+cMϕM,i∗=0(11)
仅当 cj=0,∀j∈[M]c_j = 0, \forall j \in [M]cj=0,∀j∈[M] 时成立。假设存在不全为 0 的 c1,…,cMc_1, \dots, c_Mc1,…,cM 满足 (11)。设客户端 iii 的系数为 c1,…,cMc_1, \dots, c_Mc1,…,cM,其他客户端的系数为 0。那么,我们就有一系列系数满足 (10),这与 G∞\mathbf{G}^\inftyG∞ 严格正定相矛盾。这意味着 Gi∞\mathbf{G}_i^\inftyGi∞ 是严格正定的。也就是说,Gi∞\mathbf{G}_i^\inftyGi∞ 的特征值是正的。由于 G∗∞\mathbf{G}^{*\infty}G∗∞ 的特征值正好是 Gi∞\mathbf{G}_i^\inftyGi∞ 的特征值的并集,λmin(G∗∞)\lambda_{\min}(\mathbf{G}^{*\infty})λmin(G∗∞) 为正,因此,G∗∞\mathbf{G}^{*\infty}G∗∞ 是严格正定的。
B.3 推论 4.6 的证明
为了比较 E=1E=1E=1 时 FedAvg 和 FedBN 的收敛速度,我们比较了收敛速度中的指数因子,对于 FedAvg 和 FedBN 分别为 (1−ημ0/2)(1 - \eta \mu_0 / 2)(1−ημ0/2) 和 (1−ημ0∗/2)(1 - \eta \mu_0^* / 2)(1−ημ0∗/2)。然后,问题简化为比较 μ0=λmin(G∞)\mu_0 = \lambda_{\min}(\mathbf{G}^\infty)μ0=λmin(G∞) 和 μ0∗=λmin(G∗∞)\mu_0^* = \lambda_{\min}(\mathbf{G}^{*\infty})μ0∗=λmin(G∗∞)。比较方程 (7) 和 (9),G∗∞\mathbf{G}^{*\infty}G∗∞ 取 G∞\mathbf{G}^\inftyG∞ 对角线上的 M×MM \times MM×M 分块矩阵:
G∞=[G1∞G1,2∞…G1,N∞G1,2∞G2∞…G2,N∞⋮⋮⋱⋮G1,N∞G2,N∞…GN∞],G∗∞=[G1∞0…00G2∞…0⋮⋮⋱⋮00…GN∞], \mathbf{G}^\infty = \begin{bmatrix} \mathbf{G}_1^\infty & \mathbf{G}_{1,2}^\infty & \dots & \mathbf{G}_{1,N}^\infty \\ \mathbf{G}_{1,2}^\infty & \mathbf{G}_2^\infty & \dots & \mathbf{G}_{2,N}^\infty \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{G}_{1,N}^\infty & \mathbf{G}_{2,N}^\infty & \dots & \mathbf{G}_N^\infty \end{bmatrix}, \quad \mathbf{G}^{*\infty} = \begin{bmatrix} \mathbf{G}_1^\infty & 0 & \dots & 0 \\ 0 & \mathbf{G}_2^\infty & \dots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & \mathbf{G}_N^\infty \end{bmatrix}, G∞=
G1∞G1,2∞⋮G1,N∞G1,2∞G2∞⋮G2,N∞……⋱…G1,N∞G2,N∞⋮GN∞
,G∗∞=
G1∞0⋮00G2∞⋮0……⋱…00⋮GN∞
,
其中 Gi∞\mathbf{G}_i^\inftyGi∞ 是 G∞\mathbf{G}^\inftyG∞ 对角线上的第 iii 个 M×MM \times MM×M 分块矩阵。根据线性代数,
λmin(Gi∞)≥λmin(G∞),∀i∈[N]. \lambda_{\min}(\mathbf{G}_i^\infty) \ge \lambda_{\min}(\mathbf{G}^\infty), \quad \forall i \in [N]. λmin(Gi∞)≥λmin(G∞),∀i∈[N].
因为 G∗∞\mathbf{G}^{*\infty}G∗∞ 的特征值正是 Gi∞\mathbf{G}_i^\inftyGi∞ 特征值的并集,我们有
λmin(G∗∞)=mini∈[N]{λmin(Gi∞)}, \lambda_{\min}(\mathbf{G}^{*\infty}) = \min_{i \in [N]} \{\lambda_{\min}(\mathbf{G}_i^\infty)\}, λmin(G∗∞)=i∈[N]min{λmin(Gi∞)},
≥λmin(G∞). \ge \lambda_{\min}(\mathbf{G}^\infty). ≥λmin(G∞).
因此,(1−ημ0/2)≥(1−ημ0∗/2)(1 - \eta \mu_0 / 2) \ge (1 - \eta \mu_0^* / 2)(1−ημ0/2)≥(1−ημ0∗/2),我们可以得出结论:FedBN 的收敛速度快于 FedAvg。
C FEDBN 算法
我们用以下算法 1 描述了我们提出的 FedBN 的详细算法:
[算法 1]
算法 1: 使用 FedBN 的联邦学习
符号: 用户索引为 kkk,神经网络层索引为 lll,初始化的模型参数: w0,k(l)w_{0,k}^{(l)}w0,k(l),局部更新步长: EEE,以及总优化轮次 TTT。
1: for 每一轮 t=1,2,…,Tt = 1, 2, \dots, Tt=1,2,…,T do
2: for 每个用户 kkk 和 每一层 lll do
3: wt+1,k(l)←SGD(wt,k(l))w_{t+1,k}^{(l)} \leftarrow \text{SGD}(w_{t,k}^{(l)})wt+1,k(l)←SGD(wt,k(l))
4: end for
5: if mod(t,E)==0\text{mod}(t, E) == 0mod(t,E)==0 then
6: for 每个用户 kkk 和 每一层 lll do
7: if 层 lll 不是 BatchNorm (layer lll is not BatchNorm) then
8: wt+1,k(l)←1K∑k=1Kwt+1,k(l)w_{t+1,k}^{(l)} \leftarrow \frac{1}{K} \sum_{k=1}^K w_{t+1,k}^{(l)}wt+1,k(l)←K1∑k=1Kwt+1,k(l)
9: end if
10: end for
11: end if
12: end for
D 实验细节
D.1 基准数据集的可视化

图 6 说明:数据可视化。(a) 来自每个数据集(客户端)的示例。(b) 跨数据集的 non-iid 特征分布(针对每个数据集的随机 100 个样本)。
我们展示了五个基准数据集中的图像示例以及像素值直方图。它明显地呈现出异构的外观和偏移的分布。由这五个基准数据集组成的客户端被视为是 non-iid 的。
D.2 基准上的模型架构和训练细节
我们在本节中说明数字分类实验的模型架构和训练细节。
模型架构: 对于我们的基准实验,我们使用了一个六层卷积神经网络 (CNN),其细节列在表 3 中。
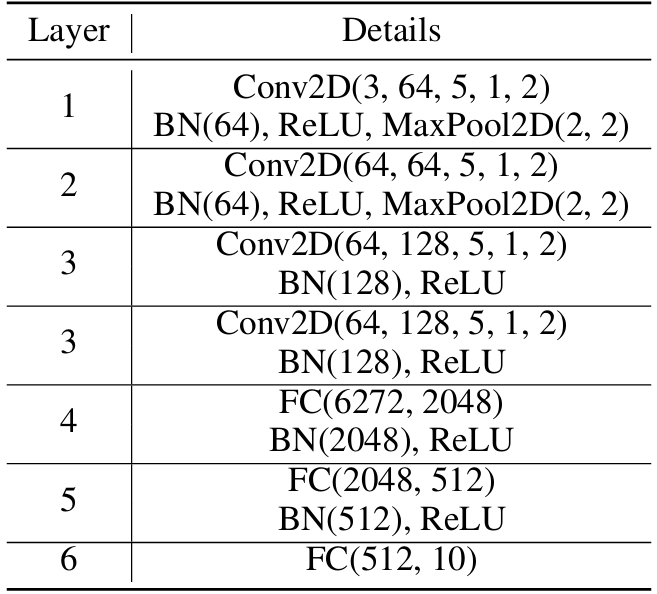
表 3 说明:基准实验的模型架构。对于卷积层 (Conv2D),我们列出了按输入和输出维度、核大小 (kernel size)、步长 (stride) 和填充 (padding) 顺序排列的参数。对于最大池化层 (MaxPool2D),我们列出了核 (kernel) 和步长 (stride)。对于全连接层 (FC),我们列出了输入和输出维度。对于批量归一化层 (BN),我们列出了通道维度。
训练细节: 我们给出了在 5.1 中进行的实验的详细设置:(1) 收敛速度 (表 4);(2) 局部更新周期分析 (表 5);(3) 局部数据集大小分析 (表 6);(4) 统计异质性的影响 (表 7) 和 (5) 与最新技术的比较 (表 8)。每个表描述了客户端数量、样本数和局部更新周期。
在训练过程中,我们使用学习率为 10−210^{-2}10−2 的 SGD 优化器和交叉熵损失,我们将批量大小设置为 32,训练周期 (epochs) 为 300。对于超参数 μ\muμ,我们通过基于 FedProx (Li) 默认设置的网格搜索找到了最佳值 μ=10−2\mu = 10^{-2}μ=10−2。
(表 4 至 表 8 为实验设置参数表,各列名称依次为 Datasets (数据集), SVHN, USPS, SynthDigits, MNIST-M, MNIST。各行名称包含 Number of clients (客户端数), Number of samples (样本数), Local update epochs (局部更新周期)。)




D.3 OFFICE-CALTECH10 和 DOMAINNET 图像分类任务的模型架构和训练细节
在本节中,我们提供了在 Office-Caltech10 (Gong) 和 DomainNet (Peng) 数据集上的模型和训练过程的细节。
模型架构: 对于这两个真实世界数据集 Office-Caltech10 和 DomainNet 数据上的图像分类任务,我们使用了调整后的 AlexNet,并在每个卷积层和全连接层(除最后一层外)之后添加了 BN 层,架构如表 9 所示。

表 9 说明:Office-Caltech10 和 DomainNet 实验的模型架构。详细符号解释同表 3,其中 AdaptiveAvgPool2D 指自适应平均池化层。
训练细节: Office-Caltech10 从 Office-31 和 Caltech-256 数据集 (Griffin) 中选择了 10 个常见对象。有四个不同的数据源,一个来自 Caltech-256,三个来自 Office-31,即 Amazon(从在线购物网站收集的图像),DSLR 和 Webcam(使用数码单反相机和网络摄像头在办公环境中捕获的图像)。
我们首先将两个数据集中的输入图像调整为 256×256×3256 \times 256 \times 3256×256×3,然后对于训练过程,我们使用交叉熵损失和学习率为 10−210^{-2}10−2 的 SGD 优化器,批量大小设置为 32,训练周期数为 300。在与 FedProx 进行比较时,我们将 μ\muμ 设置为 10−210^{-2}10−2,这是从默认设置中调整过来的。数据样本数根据最小的数据集保持相同的大小,即 Office-Caltech10 每个数据集使用 62 个训练样本,DomainNet 每个数据集使用 105 个训练样本。此外,为了简单起见,我们根据包含超过 345 个类别的 DomainNet 的数据量选择了前 10 个类别。
D.4 ABIDE 数据集和训练细节
在这里,我们描述了真实世界的医学数据集、预处理和训练细节。
数据集: 该研究使用了来自自闭症脑成像数据交换数据集 (ABIDE I 预处理,(Di Martino)) 的静息态 fMRI (rs-fMRI) 数据。ABIDE 是一个联盟,它为在科学界共享数据的目的,提供了宝贵的收集到的 rs-fMRI ASD(自闭症谱系障碍)和匹配对照数据。我们从具有用于连接组分析的可配置管道 (CPAC) 并在 Harvard-Oxford (HO) 图谱上进行分块的预处理 ABIDE 数据集中,下载了前四个最大站点(UM,NYU,USM,UCLA,被视为客户端)的感兴趣区域 (ROI) fMRI 序列。跳过缺少文件名的受试者,分别针对 UM, NYU, USM, UCLA 得到 88, 167, 52, 63 名受试者。由于缺乏足够的数据,我们使用了滑动窗口(窗口大小为 32,步长为 1)来截断 fMRI 的原始时间序列。四个站点的组成如表 10 所示。重叠截断(Overlapping Trunc)的数量即为客户端中的数据集大小。

表 10 说明:研究中使用的数据集的数据摘要。包含 Total Subject (总受试者), ASD Subject (ASD 患者), HC Subject (健康对照), ASD Percentage (ASD 占比), fMRI Frames (fMRI 帧数), Overlapping Trunc (重叠截断数)。
训练过程: 对于所有策略,我们将批量大小设置为 100。总训练局部周期 (epochs) 为 50,使用 SGD 优化器,学习率为 10−210^{-2}10−2。每个客户端的局部更新周期为 E=1E = 1E=1。我们通过网格搜索在 FedProx 中选择了最佳参数 μ=0.2\mu = 0.2μ=0.2。
E 基准数据集上的更多实验结果
E.1 FEDAVG 和 FEDBN 之间的收敛比较
在本节中,我们对不同的局部更新周期设置进行了额外的收敛分析实验:E=1,4,8,16E = 1, 4, 8, 16E=1,4,8,16。如图 7 所示,在 EEE 的不同值下,FedBN 的收敛速度均快于 FedAvg,这支持了我们在第 4 节中的理论分析和第 5 节中的实验结果。

图 7 说明:在不同局部更新频率下,随周期 (Epochs) 变化的训练损失 (Training loss)。
E.2 图 5 的详细统计数据
在图 5 中,我们比较了 FedBN 和替代方法在准确率方面的性能。我们在表 11 中显示了详细的准确率。
表 11 说明:以平均值(标准差)形式呈现的详细统计数据如图5所示。
E.3 FEDBN 与集中式训练的比较
为了更好地理解我们的正文中报告的数字的意义,我们将 FedBN 与集中式训练进行了比较,后者将所有训练数据汇集到一个中心。我们在表 12 中给出了每个数字数据集的测试准确率。FedBN,即带有特定数据 BN 层的联邦学习,可以实现与普通的 (vanilla) 集中式训练策略相当的性能。
表 12 说明:采用 5 次试验运行得出的均值(标准差)格式,呈现各测试集的测试准确率。
E.4 EEE 和 BBB 的不同组合
在本节中,我们展示了局部更新周期 EEE 和批量大小 BBB 的不同组合。具体来说,E∈{1,4,16}E \in \{1, 4, 16\}E∈{1,4,16} 和 B∈{10,50,∞}B \in \{10, 50, \infty\}B∈{10,50,∞},其中 ∞\infty∞ 表示全批量学习。遵循原始 FedAvg 论文 (McMahan) 中的设置,我们在表 13 中给出了 EEE 和 BBB 每个组合下 FedBN 和 FedAvg 之间的比较。结果很好地一致,表明 FedBN 能够持续优于 FedAvg,并且对批量大小的选择具有鲁棒性。此外,我们在图 8 中描绘了在 EEE 和 BBB 的不同组合下测试集准确率与局部周期 (epochs) 的关系。
表 13 说明:在默认非iid设置下的基准实验中,使用不同批次大小B和本地更新轮数E组合时的测试集准确率。
![**[图 8 翻译标注]**](https://i-blog.csdnimg.cn/direct/7f777f5b8deb4ee5a8e7ff901b7fb0fc.png#pic_center)
图 8 说明:对于 FedBN,使用不同局部更新周期 EEE 和批量大小 BBB 的测试集准确率曲线(5 个数据集的平均值)。
E.5 改变局部数据集大小实验的详细统计数据
考虑到把所有结果都放在一个图里(15 条线)可能会影响图的可读性,我们在我们的图 4 (b) 中排除了 FedAvg 的统计数据,那是关于局部数据集大小影响的我们方法的消融研究。在这里,我们在表 14 中列出了完整的结果。当局部客户端获得了大量数据时,SingleSet 可以成为最佳结果,这并不太令人惊讶。
表 14 说明:本地客户端在不同数据集规模下的模型性能。
E.6 在不等数据集大小上的训练
在我们的基准实验(第 5.1 节)中,我们将五个数据集的样本大小截断为它们的最小数量。此数据预处理旨在严格控制非相关因素(例如,跨客户端的不平衡样本数),以便实验发现可以更清楚地反映局部 BN 的效果。在这方面,截断数据集是一种使每个客户端具有相同数据点数量和相同局部更新步数的合理方法。也可以通过允许数据量较少的客户端重复采样(repeat sampling),将数据集保持在其原始大小(这是不平等的)。这样,所有客户端使用相同的批量大小和相同的每个 epoch 的局部迭代次数。我们分别在表 15 和表 16 中添加了具有 10% 和全部原始数据大小的这种设置的结果。可以观察到 FedBN 仍然始终优于其他方法。
表 15 说明:当客户端训练样本不均衡且仅使用10%的原始数据时,各客户端的测试准确率。每个客户端的训练样本数量标注在其名称下方。

表 16 说明:当客户端训练样本不均衡且使用全量数据时,各客户端的测试准确率。每个客户端的训练样本数量标注在其名称下方。
F 合成数据实验
设置: 我们从两对多高斯分布生成数据。对于第一对,样本 (x,0)(x, 0)(x,0) 和 (x,1)(x, 1)(x,1) 分别从 N(−1,Σ1)\mathcal{N}(-1, \mathbf{\Sigma}_1)N(−1,Σ1) 和 N(1,Σ1)\mathcal{N}(1, \mathbf{\Sigma}_1)N(1,Σ1) 中采样,协方差 Σ1∈R10×10\mathbf{\Sigma}_1 \in \mathbb{R}^{10 \times 10}Σ1∈R10×10。对于另一对,样本 (x~,0)(\tilde{x}, 0)(x~,0) 和 (x~,1)(\tilde{x}, 1)(x~,1) 分别从 N(−1,Σ2)\mathcal{N}(-1, \mathbf{\Sigma}_2)N(−1,Σ2) 和 N(1,Σ2)\mathcal{N}(1, \mathbf{\Sigma}_2)N(1,Σ2) 中采样,协方差 Σ2∈R10×10\mathbf{\Sigma}_2 \in \mathbb{R}^{10 \times 10}Σ2∈R10×10。具体来说,我们将协方差矩阵 Σ1\mathbf{\Sigma}_1Σ1 设计为对角单位矩阵,而 Σ2\mathbf{\Sigma}_2Σ2 与 Σ1\mathbf{\Sigma}_1Σ1 不同之处在于它的非对角线上有非零值。我们使用交叉熵损失和学习率为 1×10−51 \times 10^{-5}1×10−5 的 SGD 优化器训练了一个具有 100 个隐藏神经元的两层神经网络 600 步。表示 WkW_kWk 和 bkb_kbk 为神经元 kkk 的输入连接权重和偏置项。我们用 Wk∼N(0,α2I)W_k \sim \mathcal{N}(0, \alpha^2\mathbf{I})Wk∼N(0,α2I),bk∼N(0,α2)b_k \sim \mathcal{N}(0, \alpha^2)bk∼N(0,α2) 初始化模型参数,其中 α=10\alpha = 10α=10。
结果: 合成实验的目的是在一个受控设置下研究使用 FedBN 的行为。对于二分类,我们在 FedAvg 和 FedBN 上均实现了 100% 的准确率。图 9 显示了使用 FedAvg 和 FedBN 随着步数变化的训练损失曲线的比较,这表明 FedBN 获得了比 FedAvg 快得多的收敛速度。
![**[图 9 翻译标注]**](https://i-blog.csdnimg.cn/direct/470a70f41f994a8f948c5379352e47fa.png#pic_center)
图 9 说明:合成数据上的训练损失。(a) 客户端 1 中的数据从对角高斯生成;(b) 客户端 2 从对角高斯和全高斯的组合中生成。
G 迁移学习与在未知域客户端上的测试
在本节中,我们讨论 FedBN 的域外泛化,并证明以下两种场景的解决方案:1) 在训练期间将 FedBN 迁移到一个新的未知域客户端;2) 测试一个未知域客户端。
如果来自另一个域的新中心加入训练,我们可以将全局模型的非 BN 层参数迁移到这个新中心。这个新中心将计算其自身的均值和方差统计量,并学习相应的局部 BN 参数。
在联邦外部的一个具有未知统计量的新客户端上测试全局模型,需要允许在测试时访问局部 BN 参数(尽管在训练期间 BN 层不会在全局服务器上聚合)。这样一来,新客户端就可以使用在现有 FL 客户端处学到的所有可训练 BN 参数的平均值,并在其自己的数据上计算(均值、方差)。这样的解决方案也符合最近文献中的做法,例如 SiloBN (Andreux)。我们将这种针对 FedBN 的解决方案进行实验,并将其性能与 FedAvg 和 FedProx 进行了比较。具体而言,我们使用数字分类任务,并将 Morpho-MNIST (Castro) 中的两个未见过的数据集——Morpho-global 和 Morpho-local 作为两个新客户端。这些新客户端包含受到显著扰动的数字。具体来说,Morpho-global 包含 MNIST 数字的变细和变粗版本,而 Morpho-local 则通过膨胀和断裂来改变 MNIST。结果列于表 17。可以观察到,在如此具有挑战性的环境中,三种方法获得的结果大致具有可比性,而 FedBN 在整体平均准确率上表现出略高的性能。

表 17 说明:将全局模型泛化到未见域的客户端。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)