Meta AI的多模态生成式推荐系统 MSC-GRec 的大模型级量化与落地实践
一、导语(Lead)
本文将深度解读由 Meta AI 和苏黎世联邦理工学院(ETH Zurich)联合提出的最新生成式推荐模型 MSC-GRec(Multimodal Semantic and Collaborative Generative Recommender)。
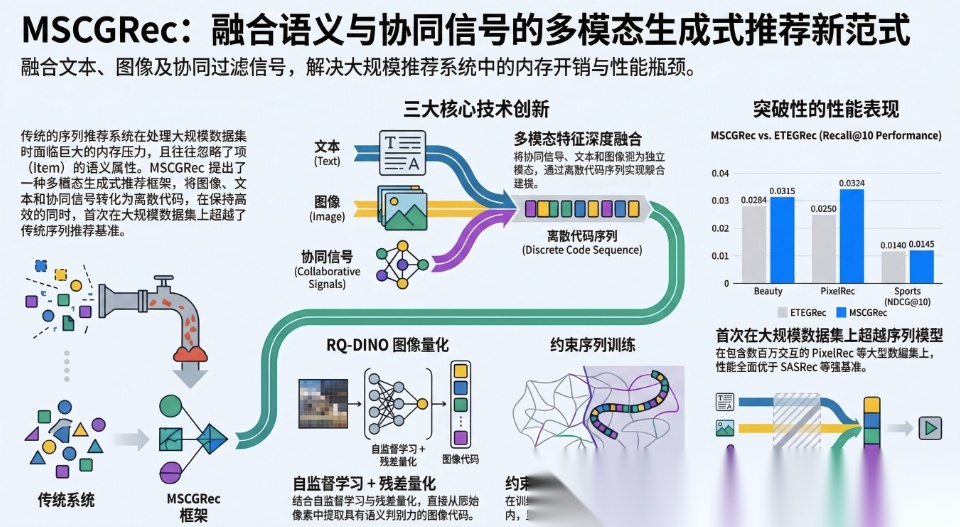
在处理海量商品库时,传统的序列推荐系统面临着巨大的内存开销(Embedding 词表爆炸)。而现有的“生成式推荐(Generative Recommendation)”虽然通过生成离散语义代码(Semantic Codes)解决了内存问题,但在大库上的推荐精度却始终无法超越传统模型。
MSC-GRec 通过三大核心创新打破了这一僵局:将协同过滤信号作为独立模态融入大语言模型范式、提出基于 DINO 框架的图像自监督量化学习(RQ-DINO),以及引入约束序列学习(Constrained Training)机制。它在三个超大规模真实数据集上全面击败了传统序列推荐和现有生成式方法,标志着生成式推荐真正具备了在工业级海量数据上落地的统治力。
二、研究背景:为什么要解决这个问题?
在深入理解 MSC-GRec 之前,我们需要先剖析推荐系统过去十年面临的底层架构演进,以及当前业界遭遇的“内存墙”与“语义墙”两大核心痛点。只有理解了这些痛点,我们才能明白为什么生成式推荐(Generative Recommendation)被视为下一代推荐范式,以及为什么它在落地时又困难重重。
1. 当前领域面临的核心问题:ID 范式的“内存墙”与“语义墙”
传统的推荐系统(尤其是以 SASRec 为代表的序列推荐模型)本质上遵循着一种基于 ID 的匹配范式(ID-based Paradigm)。系统会为数据库中的每一个商品(Item)分配一个独一无二的原子 ID(如 Item_9527),并为每个 ID 学习一个高维的稠密向量(Embedding)。在推理时,模型根据用户的历史点击序列计算出一个 User Embedding,然后在庞大的 Item Embedding 表中进行近似最近邻检索(ANN Search)或者点积打分。
这种范式在过去非常有效,但在当今动辄数以亿计的商品库面前,暴露出两个致命的局限:
- • 内存墙(Memory Wall)瓶颈:每一个商品都需要在内存中维护一个浮点数向量。如果库里有 10 亿个商品,一个维度为 256 的 FP32 Embedding 表将占用惊人的数百 GB 显存。这导致工业界不得不花费极其高昂的硬件成本来维护这些巨大的 Embedding 表,且极大限制了模型的扩展能力。
- • 语义墙(Semantic Wall)与冷启动难题:孤立的 ID 本身不包含任何物理世界的语义信息。模型完全依靠用户交互的“共现频率(Co-occurrence)”来学习向量(即协同过滤信号)。这意味着,如果一个新商品刚刚上架(零交互),它的 Embedding 就是随机初始化的,模型根本不知道它到底是一部手机还是一把牙刷,导致严重的冷启动问题。
通俗类比:传统的 ID 推荐就像一个完全不识字但记忆力极强的图书管理员。他只记得“借过编号 A001 书的人,通常也会借 B002”,但他完全不知道 A001 是一本《科幻小说》,B002 是一本《太空歌剧》。一旦进来一本新书(新 ID),他就彻底懵了。
2. 生成式推荐(Generative Recommendation)的崛起与局限
为了打破上述双墙,业界近年来受大语言模型(LLM)的启发,提出了一种颠覆性的范式:生成式推荐(Generative Recommendation)。
其核心思想是:抛弃原子 ID 和巨大的 Embedding 表,将每个商品表示为一段简短、包含语义的离散代码序列(Discrete Semantic Codes)。例如,通过残差量化(RQ)技术,将一本《哈利波特》的文本描述量化为代码序列 。其中 24 可能代表“图书”,156 代表“奇幻”,92 代表“魔法学校”。
这样,推荐任务就从“在海量向量库中做点积检索”变成了类似 ChatGPT 的 Next-token Prediction(生成下一个词)。模型通过阅读用户历史浏览的代码序列,直接逐个 Token 地生成下一个推荐商品的代码。
生成式推荐带来了显而易见的优势:
- 极度省内存:不再需要存储亿级别商品的 Embedding 表。模型只需要记住一个极小的词表(例如 256 个 Token),商品表示由这 256 个 Token 组合而成,内存需求呈指数级断崖式下降。
- 天生具备语义和泛化能力:由于代码是基于商品文本/图像生成的,相似的商品会共享前缀代码。新商品只要有文本描述,就能被量化为相似的代码,从而完美解决冷启动。
然而,理想很丰满,现实却很骨感。 现有的生成式推荐模型(如基于文本的 TIGER)在小规模数据集上表现惊艳,但在面临真实的海量商品库时,其推荐精度却始终无法超越传统的序列模型(如 SASRec)。
3. 为什么这个问题一直没有被很好解决?
生成式推荐在大库上“水土不服”的根本原因在于现有的研究陷入了两个误区:
- • 只重语义,抛弃了协同过滤信号(Collaborative Signals):
现有的生成式模型大多只依赖文本或图像来生成代码。但是,推荐系统与纯 NLP/CV 任务不同。在商业场景中,“经常被一起购买”的属性(协同过滤)往往比“长得相似”或“描述相似”更具决定性。 比如,用户买完“手机”后往往需要买“手机壳”,这两者在文本或图像上毫无相似之处,纯语义模型很难将它们联系起来;而传统的 ID 模型却能通过共现轻易捕捉这种关系。现有方法(如 LETTER 或 CoST)试图通过复杂的对比损失函数强行对齐语义与协同信号,但这往往导致模型在训练时顾此失彼,难以达到最优。 - • 模态单一且量化方式粗糙:
真实世界是多模态的。现有的方法大多只盯着文本(Text),如果遇到缺乏文本描述的场景(如纯视频、纯图像流),模型就抓瞎了。此外,直接使用预训练好的图像编码器(如 CLIP)提取特征再进行量化,往往会保留大量对推荐无用的背景高频细节,而不是提取“这件衣服是什么风格”这种高层语义。
综上所述,当前推荐系统领域迫切需要一种**既能享受生成式框架带来的“内存红利”和“语义泛化能力”,又能完美融合“协同过滤信号”和“多模态特征”**的工业级大模型解决方案。这就是 MSC-GRec 诞生的时代背景。
三、核心研究问题
1. 论文试图解决的核心问题是什么?
论文试图解决的核心问题是:如何设计一个多模态生成式推荐框架,在不增加内存开销和推理延迟的前提下,将协同过滤信号和多模态语义信号(文本、图像)深度融合,从而在海量商品数据集上全面超越传统基于 ID 的序列推荐模型。
深入拆解这个任务:
- • 输入是什么:用户的历史交互商品序列。每个商品具备多种模态信息(如商品标题文本、商品缩略图,以及它在历史序列模型中的协同过滤表示)。
- • 输出是什么:系统预测出的下一个最符合用户兴趣的商品。在生成式范式下,输出具体表现为一段属于该预测商品的离散多层级代码序列(Discrete Semantic Code Sequence)。
- • 为什么这个问题很难:
- 异构信息的融合冲突:文本、图像和协同过滤信号处于完全不同的表示空间。如何在一个自回归(Autoregressive)生成的框架内,优雅地融合这些信息而不引起模态间的梯度冲突?
- 图像量化的低效性:推荐系统关注的是图像背后的“用户偏好语义”,而不是图像的“像素重建”。传统的图像离散化方法(如 VQ-VAE,基于重建误差)在此处完全不适用。
- 捷径学习(Shortcut Learning)与词表爆炸:随着商品库扩大,理论上可能的代码组合数量呈指数级增长。但现实中,只有一小部分代码组合真正对应着真实的商品。自回归模型在训练时,往往会消耗大量算力去“死记硬背”哪些代码组合是合法的、哪些是非法的,而不是去专注学习“用户到底喜欢什么”。这会导致严重的过拟合和性能饱和。
2. 创新:作者提出了什么新的方法、模型或技术?
为了攻克上述难题,Meta AI 的研究团队提出了 MSC-GRec (Multimodal Semantic and Collaborative Generative Recommender)。其核心创新可以归纳为“一个框架、两把尖刀”:
A. 方法的整体思路与模型结构
MSC-GRec 彻底摒弃了“试图把所有模态压进同一个代码本”的做法。相反,它采用了一种**“异构输入,独立量化,统一处理,单模态解码”的创新架构。
在输入端,模型将商品的文本、图像、以及传统序列模型(如 SASRec)学习到的 Item Embedding**,分别独立进行残差量化(Residual Quantization, RQ),得到各自模态的层级代码序列。模型将这些不同模态的代码拼接在一起作为输入。这就巧妙地将“协同过滤信号”视作了一种额外的“语言模态”注入了模型。
B. 核心创新点 1:基于 DINO 的图像自监督量化学习 (RQ-DINO)
以往处理图像模态时,要么使用重建损失(VQ-VAE)导致失去语义,要么直接量化冻结的 CLIP 向量导致域偏移(Domain Shift)。
MSC-GRec 创造性地将残差量化(RQ)直接嵌入到当前最先进的计算机视觉自监督学习框架 DINO(Self-Distillation with No Labels) 之中。在教师-学生自蒸馏的训练中,模型强制对学生网络(Student)的中间表征进行残差量化,然后用量化后的特征去逼近教师网络(Teacher)的稠密输出。这使得网络在没有标签的情况下,自发地学习出既满足层级量化要求、又高度浓缩了高级语义的图像离散代码。
C. 核心创新点 2:约束序列学习 (Constrained Sequence Learning)
为了解决大模型在海量商品前产生的“捷径学习(死记硬背)”现象,作者提出了一种极其优雅的训练策略调整。
在计算 Softmax 交叉熵损失时,传统的生成式大模型会将当前 Token 候选与整个词表(比如 256 个 Token)进行归一化。但在 MSC-GRec 中,作者利用已知商品的离散代码构建了一棵前缀树(Prefix Tree / Trie)。在训练的每一步,Softmax 的分母仅在当前路径下合法的子节点(Permissible Codes)中进行求和。
这不仅没有任何额外的计算开销(树可以预先计算好),而且彻底阻断了模型去记忆无效代码路径的企图,强制大模型将所有的参数容量都用于对“真实商品”进行精确排序。
3. 比较:论文与哪些现有方法进行了比较?
论文在严格的学术基准下,与当今工业界和学术界两大阵营的最强 Baseline 进行了全面对比:
- • 序列推荐阵营(Sequential Recommendation):
- • SASRec:引入自注意力机制的序列推荐基石模型,目前在大规模稀疏数据集上依然是最强且最稳定的 Baseline 之一。
- • BERT4Rec、GRU4Rec、Caser、FDSA:涵盖了双向 Transformer、RNN、CNN 和特征增强的各个方向的经典方法。
- • 其特点:检索精度极高(特别是 SASRec),协同信号捕捉极其敏锐,但致命弱点是必须依赖庞大的 Item Embedding 表,缺乏跨商品语义共享能力。
- • 生成式推荐阵营(Generative Recommendation):
- • TIGER:谷歌提出的生成式推荐鼻祖级框架,基于文本语义进行残差量化。
- • LETTER & CoST:试图在生成式框架中引入对比学习,以对齐语义与协同信号。
- • ETE-GRec:将序列编码器和商品分词器进行端到端联合循环优化的最新模型。
- • MQL4GRec:处理多模态生成式推荐的最先进方法。
- • 其特点:内存极低,具备语义理解能力,但在海量商品数据上的排序能力长期被 SASRec 等传统模型压制。
MSC-GRec 与它们的核心差异:
它首次通过“模态融合”的方式,不借助复杂的对比损失对齐函数,直接将 SASRec 的稠密输出量化为“协同词汇”,让大模型去阅读。相比于纯文本的 TIGER,它懂协同过滤;相比于纯协同过滤的 SASRec,它拥有多模态语义和极低的内存占用;相比于 LETTER 等对比学习方案,它更加端到端且避免了多目标优化的梯度打架。
4. 核心理论假设
作者提出 MSC-GRec 架构底层的核心理论假设主要有两个:
- “协同过滤与语义特征是正交且互补的模态”假设:
作者认为,商品的长相(图像)、名字(文本)与它在商业生态中的位置(协同信号),是描述该商品的三种完全不同的“语言(Languages)”。试图用一个一维的代码序列强行融合它们(例如 Early Fusion 或 Contrastive Loss)会损失大量信息。
理论解释:如果将它们作为平行的独立模态输入序列模型(Transformer),强大的自注意力机制天生就具备在上下文(Context)中寻找跨模态关联特征的能力。让大模型自己去判断何时该用“图像相似度”推荐,何时该用“协同共现率”推荐,远胜于人工设计对齐损失。 - “受限解空间提升泛化能力”假设 (Constrained Space Hypothesis):
传统的序列生成将推荐问题视作在绝对无约束的空间中游荡。但实际的商品库是封闭且固定的。
直觉上的理解:就像参加一场选择题考试,如果你知道只有 A、B、C 是有效选项(虽然答题卡上印着 A 到 Z),你就不应该把脑力浪费在考虑“这题选 Z 会不会扣分”上。通过在训练阶段引入前缀树约束(Constrained Training),直接将模型的解空间从“理论宇宙”压缩到“现实商品库”,模型就能将所有的表征容量集中在区分 A、B、C 究竟谁更优上,从而带来排序性能的巨大飞跃。
四、研究方法(Methodology)
本节我们将深入解构 MSC-GRec 的系统架构,看看它是如何一步步将多模态数据转化为推荐决策的。
4.1 整体方法框架
MSC-GRec 的整体工作流分为**离线量化(Offline Quantization)和在线序列学习(Online Sequence Learning)**两个宏观阶段(详见论文图 1):
- 独立模态的分词与量化(Tokenization):
系统获取所有商品的基础信息。
- • 文本模态:使用预训练的 LLM(如 LLAMA)提取商品文本的稠密向量(Text Embedding)。
- • 图像模态:使用本文独创的 RQ-DINO 框架直接从像素级别提取并量化图像特征。
- • 协同过滤模态:在历史日志上离线训练一个标准的 SASRec 模型,提取出其学到的 Item Embedding。
随后,利用残差量化(RQ)技术,将这三个稠密向量分别转化为长度为 的离散代码序列。并在每种模态的末尾添加一个独特的防碰撞代码(Collision Code),确保没有任何两个商品拥有完全相同的代码。
- 多模态组合与历史序列构建:
对于每个商品 ,它现在由三种模态的代码序列拼接而成:。
将用户历史点击的商品按时间顺序排列,就构成了一个极其丰富的多模态词元序列作为大模型的输入(Encoder Input)。 - 预测与受限解码(Prediction & Decoding):
使用基于 T5 架构的 Encoder-Decoder 大模型。Encoder 负责阅读用户的多模态历史。Decoder 负责生成下一个预测商品。
关键设计:为了保持极高的推理效率,解码端(Decoder)并不需要生成所有模态的代码。系统指定单一的优势模态(通常是协同代码)作为 Target 进行自回归预测。在推理阶段,使用受限集束搜索(Constrained Beam Search)在预构建的商品前缀树上游走,最终锁定用户最可能点击的商品。
4.2 关键技术模块详解
接下来,我们深挖 MSC-GRec 能够拉开性能差距的三个核心技术组件。
模块一:基于 DINO 的图像自监督量化 (RQ-DINO)
传统的生成式推荐多半使用 VQ-VAE 来量化图像。VQ-VAE 包含一个 Encoder 和一个 Decoder,训练目标是让 Decoder 能把量化后的代码重新还原成原始图像像素。
这在推荐系统中是灾难性的:因为重建像素会逼迫模型把宝贵的离散代码容量浪费在记录背景颜色、光影细节等无关信息上,而忽略了“这件商品属于哪种款式”的语义特征。
作者摒弃了重建目标,巧妙地借用了 DINO 框架(一种先进的视觉自监督蒸馏技术)。
DINO 包含两个网络:学生网络(Student )和教师网络(Teacher )。教师的参数是学生参数的历史指数移动平均(EMA)。训练目标是让学生输出的概率分布逼近教师的概率分布:
其中 ,交叉熵 用于拉近两者的表征。
RQ-DINO 的魔改:
作者在学生网络计算出特征 后,强制在其上插入一层**残差量化(RQ)**模块,得到量化后的近似特征 。然后再送入分类头去逼近教师网络:
这个看似微小的改动意义极其深远:由于没有了像素重建损失,且 DINO 天生致力于提取全局级的高级语义(如物体的轮廓、类别、风格),模型被强制在保留高级语义的前提下,自发地寻找到最优的离散化层级结构。这一模块直接拔高了图像特征在推荐中的含金量。
模块二:约束序列训练 (Constrained Training)
我们再来细看前文提到的解决“捷径学习”的约束训练机制。
在标准的自回归生成(如 GPT 系列)中,预测第 个层级代码时的损失函数是全局 Softmax:
其中 是整个词表, 是正确代码的 Logit。模型为了降低损失,不仅需要提高正确代码的得分,还要压低所有错误代码的得分。
但在推荐系统中,大量代码组合在现实中是“空”的(即没有任何商品被分配给这段代码组合)。如果在训练时让模型去压低这些“空”组合的得分,本质上是在浪费模型的拟合能力去记忆数据库结构,也就是所谓的“捷径学习(Shortcut Learning)”。
约束 Softmax:
作者预先构建了一棵包含所有真实商品代码路径的前缀树 。给定已经生成的前缀代码序列 ,我们可以查树得到当前节点所有合法的孩子节点集合(Permissible Next Codes),记作 。
训练时的损失函数被严格修改为:
公式分母中的求和范围从“整个词表 ”剧减为了“仅限合法的孩子节点”。这种对解空间的硬约束,使得模型不再去记忆哪些代码不存在,而是全心全意对真正存在的商品候选项进行精确的打分排序,这也是 MSC-GRec 能够斩获极高 Recall@1 的秘密武器。
模块三:层级与模态感知的双重位置编码 (Adapted Position Embeddings)
在自然语言处理中,T5 模型通常使用相对位置编码来感知距离。但在 MSC-GRec 的多模态序列中,每个商品由多个模态组成,每个模态又由多层代码(Level 1, Level 2…)组成。
传统的对数分箱(Logarithmically Spaced Bins)相对位置编码无法理解这种复杂的结构嵌套。为此,作者设计了双重相对位置编码机制:
- 跨商品位置编码(Across-items):用于感知两个代码在交互历史中属于第几个不同的商品(宏观时间跨度)。
- 商品内位置编码(Within-items):用于感知两个代码在同一个商品内部处于何种模态、何种量化层级(微观结构关系)。
两者相加作为最终的相对位置偏置注入注意力机制,极大增强了 Transformer 对复杂代码结构的理解能力。
五、实验结果与分析
为了证明 MSC-GRec 的统治力,作者在三个超大规模真实数据集上进行了极为硬核的评测。这不仅是学术验证,更是直指工业级落地的压力测试。
1. 实验数据集的“巨大化”
不同于以往生成式推荐论文只在几十万条日志的极小数据集上测试,本文选用了规模大一个数量级的工业级数据:
- • Amazon Beauty (2023 最新版):拥有 72 万用户,超 20 万商品,642 万次交互。
- • Amazon Sports (2023 最新版):拥有 40 万用户,超 15 万商品,343 万次交互。
- • PixelRec:这是一个专门针对图像推荐的庞大数据集,拥有惊人的 888 万用户,40 万商品,高达 1.58 亿次交互,且极其稀疏(99.996%)。
2. 突破历史时刻:首个击败 SASRec 的生成式模型
在推荐系统学术界有一个著名的“痛点”:尽管花里胡哨的新模型层出不穷,但只要把超参数调好,极其简单暴力的 SASRec(基于 ID 的纯自注意力序列模型)往往能碾压一切,特别是在商品库巨大时。
实验结果(见论文 Table 2)极其振奋人心:
- • 对阵生成式基线模型:MSC-GRec 表现出断崖式的领先。在 Amazon Beauty 上,它的 Recall@10 比表现最好的生成式对手(ETEGRec)高出 10.9%,NDCG@10 高出 12.0%。在图像主导的极大数据集 PixelRec 上,其 Recall@10 甚至比基线高出了恐怖的 33.6%。这证明了多模态联合输入远胜于试图将模态强行对齐对冲的过往方案。
- • 对阵最强序列模型 SASRec:MSC-GRec 成为首个在大规模数据集上全面超越 SASRec 的生成式推荐方法。特别是在严格的排名指标 Recall@1(精准预测下一个商品)上,在 PixelRec 数据集中,SASRec 仅为 0.0044,而 MSC-GRec 达到了 0.0066,相对提升超过 50%。
为什么会有这样的结果?
因为 MSC-GRec 相当于“站在了 SASRec 的肩膀上”。传统的 SASRec 虽然强,但面对长尾物品容易受制于纯基于共现频率的稀疏性。MSC-GRec 将 SASRec 的输出提炼为离散代码作为“协同模态”,同时输入给大模型极其丰富的文本和图像语义代码。当大模型遇到长尾新商品时,协同模态的代码可能很模糊,但图像和文本模态提供了坚实的语义支撑,使得泛化预测成为可能。并且,MSC-GRec 仅使用离散代码表述商品,这就彻底解决了 SASRec 无法突破的“百 GB 级内存墙”问题。
3. Ablation Study:剖析模块的真正价值(沙普利值分析)
为了严谨地证明“多模态”不是在堆砌特征,作者借用了博弈论中的**沙普利值(Shapley Values)**来量化每一种模态对最终收益的绝对贡献。
- • 分析表明,协同过滤(Collaborative)模态依然是推荐系统的主力军,其对性能的贡献占比最大。
- • 但是,即使剥离协同信号(仅保留文本和图像),MSC-GRec 的表现依然超越了目前所有的纯生成式推荐 Baseline。文本和图像展示了显著且正交的贡献价值,证明了框架对多模态信息的有效融合与抗残缺(Missing Modalities)鲁棒性。
在图像提取方式对比中(Table 3c),使用作者独创的 RQ-DINO 进行端到端自监督量化,其指标显著高于传统的“先用 DINO 提取特征,再用 RQ 进行后置量化(Post-hoc)”。这印证了我们之前的分析:将量化约束直接写入网络的前向传播中,有助于大模型主动丢弃对于推荐无用的高频像素噪声,专心提炼意图语义。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献218条内容
已为社区贡献218条内容

所有评论(0)