4B 小模型击败 GPT-5:Learning to Self-Evolve 用强化学习教会 LLM 在测试时自我进化
4B 小模型击败 GPT-5:Learning to Self-Evolve 用强化学习教会 LLM 在测试时自我进化
论文标题:Learning to Self-Evolve
作者:Xiaoyin Chen, Canwen Xu, Yite Wang, Boyi Liu, Zhewei Yao, Yuxiong He
机构:Mila – Quebec AI Institute、University of Montreal、Snowflake
论文链接:https://arxiv.org/abs/2603.18620
发布日期:2026 年 3 月 19 日
当 LLM 在部署后遇到新任务时,最常见的做法是"自我反思"——让模型审视之前的失败并修改自己的 prompt。但这里有个根本问题:没人教过模型怎么做"自我进化"这件事。所有现有方法(TextGrad、GEPA 等)都依赖模型天生的推理能力来做 prompt 优化,从未专门训练过这项技能。
Snowflake 团队提出的 LSE(Learning to Self-Evolve)框架正面解决了这个问题:用强化学习训练一个 4B 参数的"自进化策略",专门学习如何改进上下文。配合 UCB 树搜索防止进化路径塌缩,LSE 训练的 Qwen3-4B 在 Text-to-SQL(BIRD)上以 67.3% 超越 GPT-5 的 65.2%,在 MMLU-Redux 上以 73.3% 超过 GPT-5 的 72.5%。更关键的是,训练好的自进化策略可以零样本迁移到完全不同的模型上,为其提供 +6.7% 的提升。
🎯 问题:为什么"自我反思"不够用?
测试时自进化(test-time self-evolution)的场景是这样的:模型在一批问题上执行后获得反馈,然后需要修改自己的上下文(prompt/指令),使得在下一批新问题上表现更好。这个循环重复 T 轮。
已有的方法面临三个问题:
问题一:从未被专门训练。 TextGrad 和 GEPA 等 prompt 优化方法完全依赖 LLM 的固有推理能力。这就像让一个从未学过教学的博士生去当老师——知识储备够了,但教学技巧是零。
问题二:线性链路径锁死。 大多数自进化方法采用线性链结构:每轮编辑都基于上一轮的结果。一旦某轮产生了糟糕的编辑,后续所有轮次都被拖入歧途,无法回溯。
问题三:奖励信号含噪。 如果直接用编辑后的绝对性能作为 RL 奖励,模型会偏向"在本来就容易的上下文上小修小补",而不是"在困难的上下文上做出关键改进"。
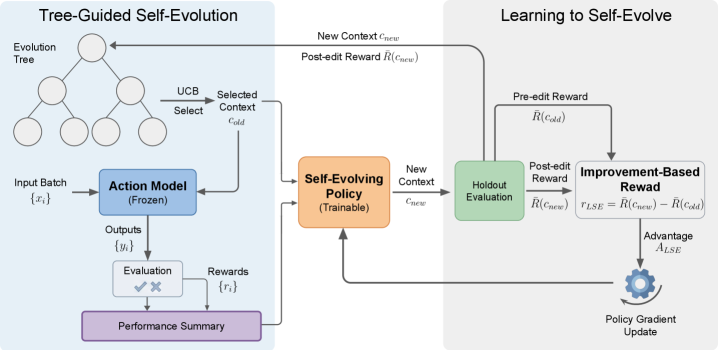
图1:LSE 框架总览。左侧为测试时的树引导自进化循环——UCB 算法从进化树中选择节点,Action Model 在新批次上执行后生成性能摘要,Self-Evolving Policy 据此提出新上下文。右侧为训练流程——用改进量(编辑后性能 - 编辑前性能)作为 RL 奖励信号。
🏗️ 方法:两个核心设计
核心一:改进量奖励——把多步优化简化为单步 RL
LSE 的数学设计非常简洁。给定当前上下文 coldc_{\text{old}}cold 和编辑后的上下文 cnewc_{\text{new}}cnew,奖励定义为:
rLSE=Rˉ(cnew)−Rˉ(cold)r_{\text{LSE}} = \bar{R}(c_{\text{new}}) - \bar{R}(c_{\text{old}})rLSE=Rˉ(cnew)−Rˉ(cold)
其中 Rˉ\bar{R}Rˉ 是在 holdout 问题集上的平均奖励。这个"差值奖励"的妙处在于:
- 自带 baseline:Rˉ(cold)\bar{R}(c_{\text{old}})Rˉ(cold) 天然充当优势函数中的基线,无需额外训练价值网络
- 消除路径偏差:不管当前上下文的绝对性能如何,只要编辑带来了改进就给正奖励。这避免了标准 GRPO 优势函数偏向"在好上下文上继续好"的问题
- 多步→单步:原本需要建模 T 步轨迹的优化问题,被简化为独立的单步决策,大幅降低了训练难度
消融实验直接验证了这个设计的价值:在 BIRD 上,使用标准 GRPO 优势函数 AGRPOA_{\text{GRPO}}AGRPO 的平均准确率为 63.0%,而使用改进量奖励 ALSEA_{\text{LSE}}ALSE 则达到 67.3%,差距 +4.3 个百分点。
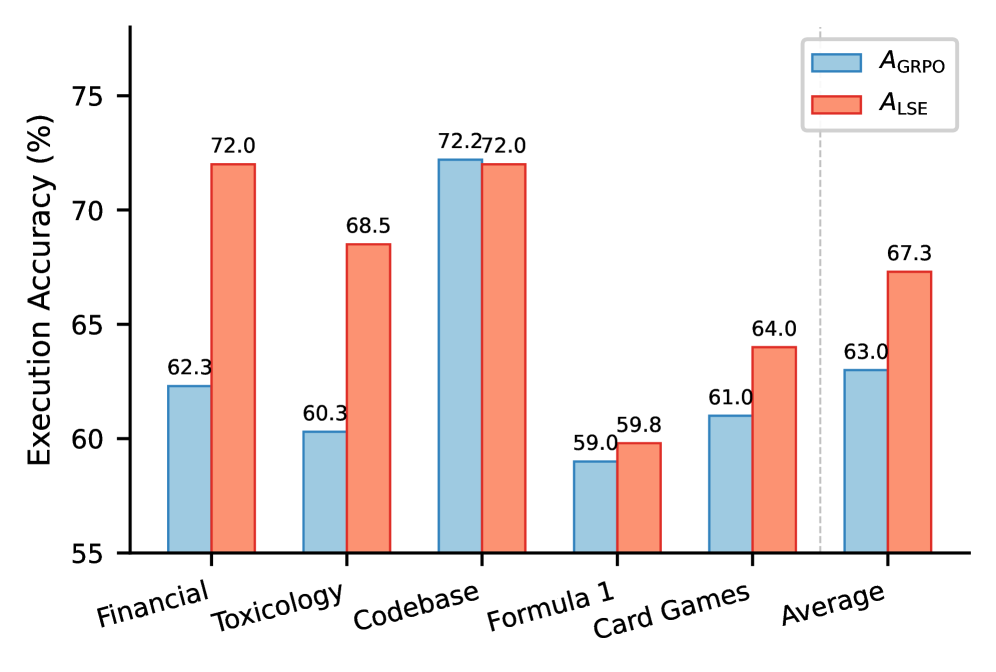
图2(a):奖励设计消融(BIRD)。AGRPOA_{\text{GRPO}}AGRPO(蓝色)使用标准 GRPO 优势函数,ALSEA_{\text{LSE}}ALSE(红色)使用改进量奖励。在 Financial 和 Toxicology 等域上差距尤为明显。
核心二:UCB 树搜索——让进化可以"回头"
进化过程维护一棵树而非一条链。每个节点存储:上下文 ccc、性能摘要、holdout 均值 Rˉ\bar{R}Rˉ、访问次数 vvv。节点选择遵循 UCB 公式:
n∗=argmaxn[Rˉn+ClnNvn]n^* = \arg\max_n \left[\bar{R}_n + C\sqrt{\frac{\ln N}{v_n}}\right]n∗=argnmax[Rˉn+CvnlnN]
前半部分是 exploitation(选高分节点),后半部分是 exploration(选访问少的节点)。当某个编辑方向走进死胡同时,UCB 会自动回溯到性能更高的祖先节点重新出发。
这在实验中的效果非常直观——线性链在 BIRD Card Games 上从 Round 10 开始急剧下跌至 27%,而树搜索始终维持在 55% 以上。
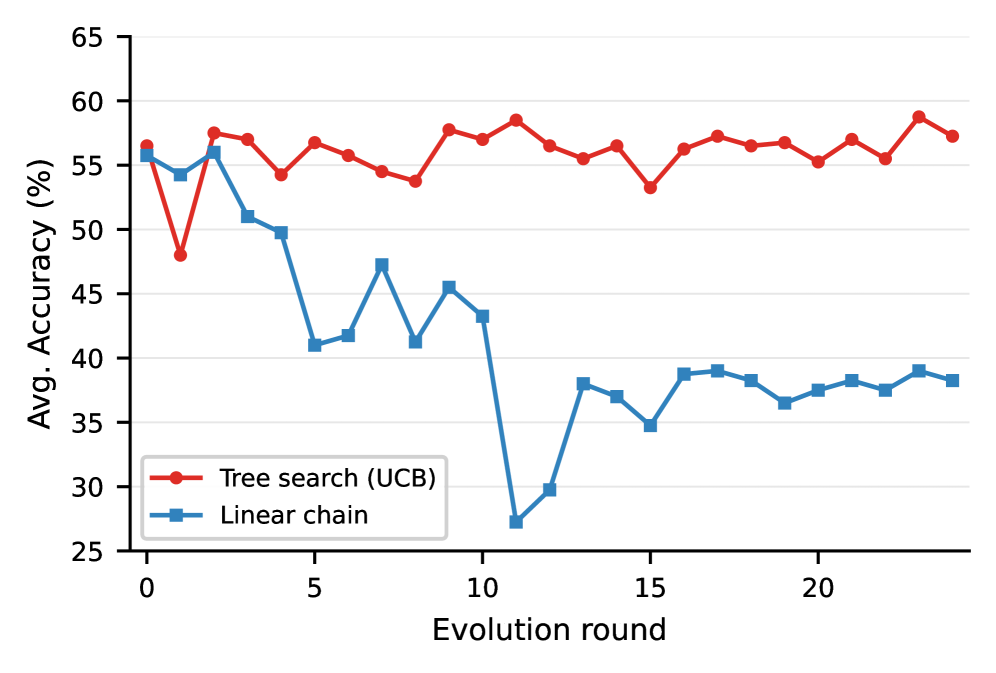
图3:BIRD Card Games 上逐轮准确率对比。线性链(蓝色方块)在 Round 10 后崩溃至 27%,无法恢复;树搜索(红色圆点)通过 UCB 回溯保持稳定在 55-58% 区间。
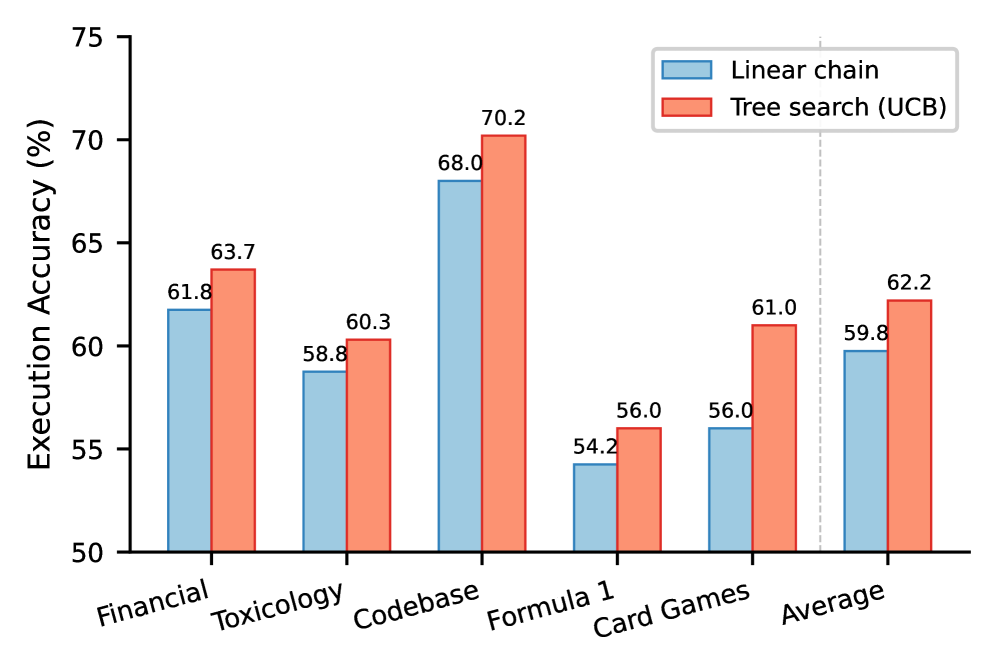
图2(b):搜索策略消融(BIRD 各域)。树搜索(UCB)在所有 5 个域上均优于线性链,平均 62.2% vs 59.8%。
🧪 实验结果
主实验:Text-to-SQL(BIRD)
所有方法使用 Qwen3-4B-Instruct 作为执行模型(action policy)。自进化策略在 5 个数据库域上各跑 25 轮进化:
| 方法 | Financial | Toxicology | Codebase | Formula 1 | Card Games | 平均 |
|---|---|---|---|---|---|---|
| Seed prompt | 51.0 | 60.3 | 63.7 | 54.5 | 56.5 | 57.2 |
| Qwen3-4B-Instruct | 63.7 | 60.3 | 70.2 | 56.0 | 61.0 | 62.2 |
| Claude Sonnet 4.5 | 70.8 | 63.8 | 67.8 | 57.3 | 63.0 | 64.5 |
| GPT-5 | 70.8 | 65.8 | 72.0 | 54.3 | 63.3 | 65.2 |
| GEPA | 64.0 | 62.0 | 72.0 | 54.0 | 62.0 | 62.8 |
| TextGrad | 60.3 | 66.0 | 71.5 | 56.5 | 61.3 | 63.1 |
| LSE(ours) | 72.0 | 68.5 | 72.0 | 59.8 | 64.0 | 67.3 |
几个值得关注的数据:
4B 击败 GPT-5:LSE 以 67.3% 超过 GPT-5 的 65.2%,绝对领先 2.1 个百分点。要知道,GPT-5 的参数量比 Qwen3-4B 大了至少两个数量级。这说明自进化是一项可以专门训练的技能,而不是只能依赖模型规模。
超越 prompt 优化方法:GEPA 62.8%、TextGrad 63.1%,均低于 LSE。这两个方法本质上也在做 prompt 优化,但它们没有通过 RL 专门训练这项能力。
未训练的 Qwen3-4B 也不差:即使不用 LSE 训练,单纯用 Qwen3-4B 做自进化也达到了 62.2%——说明树搜索框架本身就有贡献。
主实验:通用问答(MMLU-Redux)
| 方法 | 10 个学科域平均 |
|---|---|
| Seed prompt | 67.6 |
| Qwen3-4B-Instruct | 71.2 |
| Claude Sonnet 4.5 | 72.0 |
| GPT-5 | 72.5 |
| GEPA | 73.0 |
| TextGrad | 69.1 |
| LSE(ours) | 73.3 |
在 MMLU-Redux 上,LSE 以 73.3% 继续领先 GPT-5 的 72.5%,与 GEPA 的 73.0% 差距缩小到 0.3 个百分点。TextGrad 在这个基准上表现最差(69.1%),甚至低于未训练的 Qwen3-4B(71.2%),暗示基于梯度的文本优化在 QA 任务上可能不如 prompt 编辑类方法稳定。
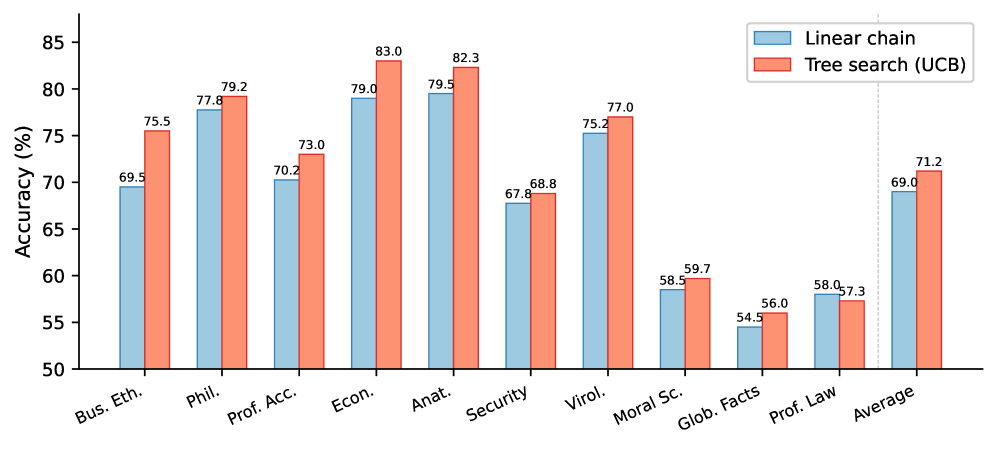
图4:MMLU-Redux 上搜索策略消融。树搜索(UCB)在 10 个学科域上均优于或持平线性链,平均 71.2% vs 69.0%。
跨模型迁移:零样本泛化
这是 LSE 最有说服力的实验。用 LSE 训练好的 Qwen3-4B 自进化策略,不做任何额外训练,直接用来引导另一个完全不同的模型——Arctic-Text2SQL-R1-7B(一个专门的 SQL 模型):
| 配置 | Financial | Toxicology | Codebase | Formula 1 | Card Games | 平均 |
|---|---|---|---|---|---|---|
| Seed prompt | 56.8 | 54.5 | 65.3 | 52.3 | 59.5 | 57.7 |
| + LSE evolution | 68.3 | 62.3 | 71.5 | 57.0 | 63.0 | 64.4 |
平均提升 +6.7 个百分点。这表明 LSE 学到的不是针对特定模型的技巧,而是一种通用的"如何从反馈中改进上下文"的元能力。
🔬 消融分析
论文的消融实验覆盖了两个关键设计维度:
| 消融维度 | 变体 | BIRD 平均 | 差值 |
|---|---|---|---|
| 奖励设计 | AGRPOA_{\text{GRPO}}AGRPO(标准优势) | 63.0% | — |
| ALSEA_{\text{LSE}}ALSE(改进量) | 67.3% | +4.3% | |
| 搜索策略 | 线性链 | 59.8% | — |
| UCB 树搜索 | 62.2% | +2.4% |
两个维度的贡献加起来约 6.7%,与最终系统(seed prompt 57.2% → LSE 67.3% 的 +10.1% 提升)基本吻合。改进量奖励的贡献(+4.3%)大于树搜索(+2.4%),说明 教模型怎么改"比"给模型更好的搜索策略"更关键。
🤔 批判性分析
亮点
- 问题定义清晰:将"自我进化"从一个模糊的概念提炼为可训练的单步 RL 问题,数学上优雅且工程上可行
- 改进量奖励的设计:自带 baseline、消除路径偏差,避免了训练价值网络的复杂性——这可能是论文最有启发性的技术贡献
- 跨模型迁移:证明了自进化能力的可移植性,暗示可以训练一个通用的"prompt 优化器"服务于不同的下游模型
局限与疑问
-
评估基准有限:仅在 BIRD(Text-to-SQL)和 MMLU-Redux(多选题 QA)上测试。这两个基准都有明确的正误判定——对于开放式生成、创意写作等缺乏客观评价指标的任务,LSE 的奖励信号从何而来?
-
"击败 GPT-5"的含义需要厘清:LSE 并非用 4B 模型直接做 SQL 生成,而是用 4B 模型做 prompt 优化。真正执行任务的 action model 仍然是 Qwen3-4B,而 GPT-5 是直接做自进化。换言之,这是在比较"LSE 训练的 4B prompt 优化器"vs"GPT-5 的零样本 prompt 优化能力"。如果给 GPT-5 也用 LSE 训练呢?论文未探讨。
-
进化轮次的选择:25 轮进化意味着每个域需要 25 批问题的反馈。在真实部署中,这些"用于进化的问题"是否会消耗宝贵的测试预算?论文假设这些问题的标注是免费的,但现实中未必如此。
-
与 In-Context Learning 的关系:LSE 本质上是在优化 prompt,这与 ICL 中的 few-shot exemplar 选择有密切联系。论文没有与 DAIL-SQL 等针对 Text-to-SQL 的 ICL 方法做对比。
-
树搜索的开销:UCB 树搜索需要在每轮维护和评估多个节点。当进化轮次和树的深度增长时,计算开销如何变化?论文未给出详细的时间/算力分析。
📊 与相关工作的定位
| 方法 | 核心思路 | 是否专门训练 | 搜索策略 | BIRD 平均 |
|---|---|---|---|---|
| TextGrad | 文本梯度反向传播 | ❌ | 线性 | 63.1% |
| GEPA | 进化式 prompt 搜索 | ❌ | 进化算法 | 62.8% |
| GPT-5(自进化) | 依赖固有推理能力 | ❌ | 线性 | 65.2% |
| LSE | RL 训练自进化策略 | ✅ | UCB 树搜索 | 67.3% |
LSE 的独特性在于:它是第一个将"自我进化"作为可学习技能进行专门训练的方法。这个视角的转变——从"依赖模型天生的推理能力"到"专门训练这项能力"——是论文最核心的贡献。
总结
LSE 展示了一个简洁但有说服力的结论:自我进化不应该是 LLM 的副产品,而应该是一项专门训练的技能。改进量奖励将多步轨迹优化简化为单步 RL,UCB 树搜索为进化过程提供了回溯能力,两者结合使得 4B 模型在 prompt 优化这一特定任务上超越了 GPT-5。
从工程角度看,LSE 最有价值的启示是"自进化策略"的可迁移性——训练一次,即可应用于不同的下游模型。这意味着未来可能出现专门的"prompt 优化器"模型,像编译器优化代码一样优化 prompt。但这一愿景的实现还需要在更多样化的任务类型和评估场景中验证。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)