彻底解决上下文膨胀?用LangChain 的 Deep Agents + Skills构建高效的多智能体应用
你有没有过这种感受,就是在给 AI 下达一系列执行任务或者在使用claude、gemini写代码的时候,会发现AI思考轮次越多,AI变的越笨了? 随着任务越来越复杂,AI的脑子好像开始变得“不太好使”了,开始在无关的细节里打转,甚至忘了最开始你给它定的目标是啥?
这就是典型的Context Bloat(上下文膨胀)导致的问题。
什么是 Context Bloat(上下文膨胀)?
上下文膨胀指的是当大型语言模型在其输入上下文窗口中被过载、无关或冗余信息时,性能下降和成本增加。
比如你要写个爬取资讯的工具:
- agent A 搜索网页(产生一堆 HTML 噪音)。
- agent B 解析内容(又是一堆 Token)。
- agent C 报错调试(错误日志占满屏幕)。
等到最后要写代码时,上下文里全是垃圾信息,真正有用的逻辑被挤到了角落。
而LangChain 前一段发布的 Deep Agents,就是通过子智能体进行角色解耦,实现上下文的隔离,以解决多智能体开发中最让人头疼的Context Bloat(上下文膨胀)问题。
Deep Agents引入了两个核心机制,其中, Subagents(子智能体)来隔离上下文,Skills 来按需加载工具 Prompt,下我们就来结合实际例子看一下这两个模块怎么搭配使用。
传统模式 vs Deep Agents 模式
传统模式(一把梭):
一个 Agent 从头干到尾。搜索网页 -> 失败 -> 重试 -> 分析 -> 写代码。
后果:主线程里堆满了“尝试连接失败”、“页面 404”这种垃圾信息。到了最后一步要写代码时,Token 已经快爆了,模型注意力分散,写出的代码质量极差。
Deep Agents 模式(老板+打工人):
Deep Agents 的核心逻辑其实就是模拟人类的高效工作流,主要由两个概念组成:
1. Subagents:上下文隔离
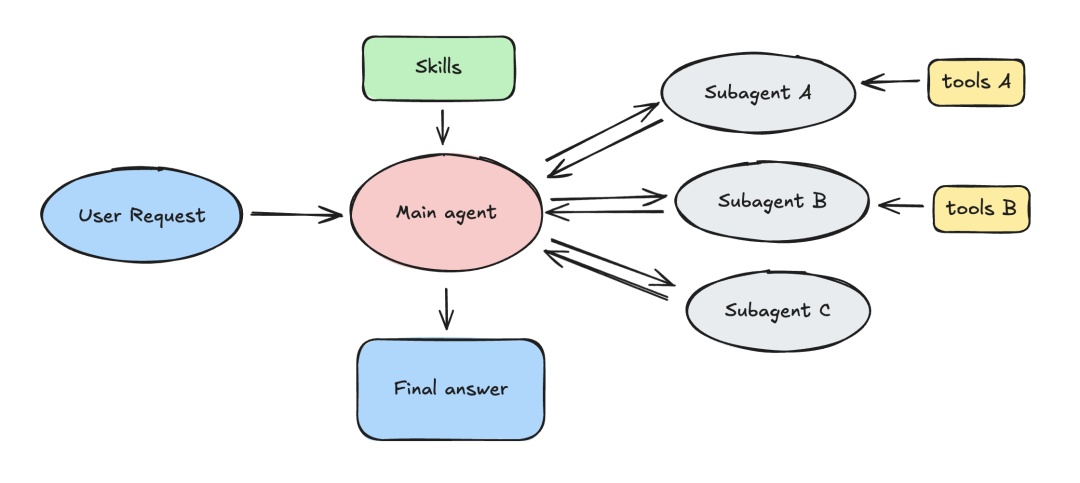
以前我们写 Agent,是一个大循环跑到底。现在,Deep Agents 允许你定义子智能体Subagents,子智能体可以在它自己的沙盒里进行 20 次搜索、翻阅 50 个网页。等它折腾完了,只把最终结论返回给主智能体。
- 原理:主智能体(Main Agent)像是项目经理,当遇到“去查阅文档”这种脏活累活时,它会丢给“调研子智能体”去干。
- 关键点:子智能体有自己独立的上下文窗口,它在里面哪怕进行了 50 次网页搜索,最后只把“总结报告”返回给主智能体。
- 好处:主智能体的上下文永远是干净的,不会被中间过程的噪音污染,始终保持“高智商”在线。
2. Skills:渐进式能力加载
没错,就是那个现在火的一塌糊涂的SKILL.md,Deep Agents也支持skill的定义,再不用像以前一样,把几十个工具的定义和一大堆 Prompt 全部塞进 System Prompt 里从头用到尾了。
- 原理:它引入了
SKILL.md文件。Agent 一开始只知道技能的名字和简介(比如“部署代码”)。 - 按需加载:只有当 Agent 真的决定要用这个技能时,它才会去读取文件里的详细步骤。
- 好处:省 Token,而且维护极其方便。想修改部署流程?改 markdown 文件就行,不用动代码。
在Multi-Agent项目中使用
这里我们设计组建一个迷你的 “量化投资团队”,这个团队的目标很简单:当用户输入“分析一下英伟达”时,整个Agent团队需要自动分工,完成资讯收集、指标计算,最后过风控,告诉用户能不能买。
第一步:定义技能Skill
量化交易最讲究纪律。我们将“分析一只股票的标准作业程序”写进 SKILL.md。
文件路径:.deepagents/skills/finance/SKILL.md
---name: stock_analysis_pipelinedescription: 执行股票分析的标准作业流程tags: [finance, trading]---# 股票分析标准作业程序 (SOP)当接收到分析某只股票(Ticker)的指令时,必须按顺序执行以下步骤:1. **搜集情报**:调用 `search_news` 获取该股票最近 24 小时的关键利好/利空消息。2. **计算指标**:调用 `calculate_indicators` 获取当前的 RSI 和 MACD 信号。3. **风控审查**:基于情报和指标,询问风控官(Risk Agent)是否允许开仓。4. **最终决策**:综合上述信息,输出简短的交易建议(Buy/Sell/Hold)。
第二步:组建 Agent 团队
我们要招聘三个不同的“专家”子智能体,并把它们塞进主智能体里:
- 资讯员 (News Scout):负责联网查实时新闻、基本面等相关信息。
- 量化员 (Quant Analyst):负责计算各种指标因子。
- 风控官 (Risk Officer):负责决策前的风险控制。
- 定义工具 (Tools)
from deepagents import create_deep_agentfrom deepagents.backends import FilesystemBackend# 模拟联网搜索和计算工具def search_news(ticker: str): """搜索最近的市场新闻""" return f"Found 3 articles for {ticker}: CEO speaks about AI demand; Earnings beat expectations."def calculate_indicators(ticker: str): """计算技术指标""" return {"RSI": 65, "MA_200": "Bullish Trend"}
- 定义子智能体 (Subagents)
# 子智能体 A: 资讯员 - 专门负责看新闻,防止主Agent被海量文本淹没news_agent = { "name": "info_researcher", "description": "负责搜索互联网新闻和市场舆情。", "tools": [search_news]}# 子智能体 B: 量化员 - 专门负责计算quant_agent = { "name": "math_wizard", "description": "负责计算技术指标,处理数字逻辑。", "tools": [calculate_indicators]}# 子智能体 C: 风控官 - 专门负责审核风险risk_agent = { "name": "risk_manager", "description": "负责风险控制。如果RSI超过80或有重大利空,必须拒绝交易。", "system_prompt": "你是一个保守的风控官,宁可错过不可做错。", "model": "openai:gpt-4o"}
- 创建主智能体 (Main Agent)
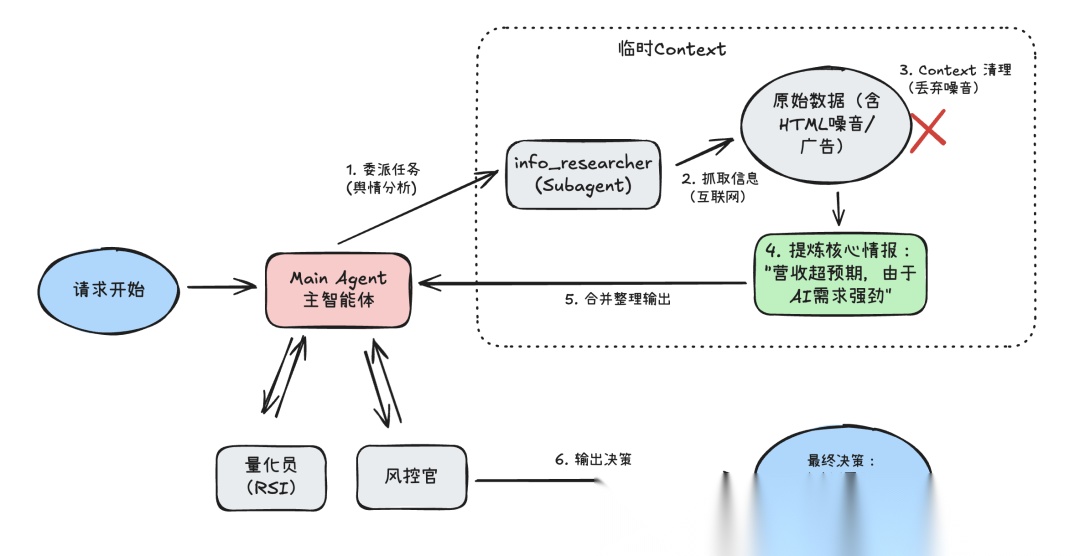
agent = create_deep_agent( model="claude-sonnet-4-5-20250929", # 将三个打工人都加进来 subagents=[news_agent, quant_agent, risk_agent], # 挂载技能库,让大家知道干活的流程 backend=FilesystemBackend(root_dir="./"), skills=[".deepagents/skills/finance"], )# --- 4. 跑起来! ---print("🚀 量化投研团队已就位...\n")# 用户只给一个模糊指令,Deep Agents 会根据 SOP 自动调度三个子智能体user_input = "帮我分析一下 NVDA (英伟达) 现在能不能买?"response = agent.invoke({"messages": [{"role": "user", "content": user_input}]})# 预期流程:# 1. 主Agent 读取 Skill -> 派 info_researcher 查新闻# 2. 派 math_wizard 算指标# 3. 派 risk_manager 结合前两者的结果做审查# 4. 主Agent 汇总输出print(f"\n📊 投研报告:\n{response.content}")
当你运行这段代码时,Deep Agents 的内部流转是这样的:
我的思考与吐槽
玩了两天,我有几个很直观的感受:
- **这不就是“微服务”架构吗?**以前搞 Agent 像是在写单体应用,所有逻辑塞一坨。Deep Agents 的 Subagents 模式,实际上是把复杂任务拆解成了微服务。主 Agent 做网关和路由,Subagent 做具体业务。
- 结合SKILL.md确实很方便比如风控规则变了(RSI > 80 改成 > 85),只需要修改 SKILL.md,用户甚至不需要懂 Python 代码,通过文字就能理解 AI 的操作手册。这比把工具 Prompt 写死在代码里方便太多了。
- 坑点预警虽然隔离了上下文,但子智能体的划分需要很有经验。如果拆得太细,Agent 之间来回“踢皮球”会增加延迟;如果拆得太粗,又起不到隔离上下文的作用。这块还得在实战中多磨合。
总的来说,Deep Agents 并没有搞什么花里胡哨的新算法,而是用工程化的手段解决了 LLM 应用落地的痛点。如果你正在被 Token 限制和模型“变笨”折磨,强烈建议试一试这套 Subagent + Skills 的组合。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)