优化|ProOPF: 首个面向电力系统运筹优化建模大模型的专用 Dataset + Benchmark

原文标题: ProOPF: Benchmarking and Improving LLMs for Professional-Grade Power Systems Optimization Modeling
作者: Chao Shen, Zihan Guo, Xu Wan, Zhenghao Yang, Yifan Zhang, Wenqi Huang, Jie Song, Zongyan Zhang, Mingyang Sun
研究团队: 北京大学 IDEAL-Lab (实验室主页: https://www.ideallab-smy.com/ )
原文链接: https://arxiv.org/abs/2602.03070
项目仓库: https://anonymous.4open.science/r/ProOPF-Benchmarking-and-Improving-LLMs-for-Professional-Grade-Power-Systems-Optimization-Modeling-249C
数据集涵盖电力优化问题列表: https://anonymous.4open.science/r/ProOPF-Benchmarking-and-Improving-LLMs-for-Professional-Grade-Power-Systems-Optimization-Modeling-249C/opf_variants_references.pdf
编者按:
随着可再生能源渗透率持续提升,电力系统运行中的不确定性显著增强,调度目标与运行约束也需要根据实际工况频繁调整,这对近实时优化建模能力提出了更高要求。近年来,大语言模型(LLMs)为将自然语言形式的运行需求自动转化为可执行优化模型提供了新的技术路径。然而,现有大语言模型辅助优化建模基准大多侧重跨领域、粗粒度的通用建模能力评估,尚缺乏面向电力系统运筹优化自动化建模的系统化、工程级评测框架,难以精准构建最优潮流(OPF)、最优拓扑重构(OTS)、经济调度(ED)、安全约束机组组合(SCUC)等典型大规模非线性优化问题,以及考虑概率鲁棒约束、N-1安全约束等关键扩展场景。为此,本研究构建了面向电力优化问题自动化建模与求解的专用数据集与评测基准——ProOPF-D 与ProOPF-B。
- ProOPF-B 包含 121 个覆盖四个难度层级的基准实例,由领域专家基于公开文献选取并标注,配备标准答案代码。 评测表明:主流大语言模型在既有优化建模基准上准确率可超 90%,但在 ProOPF-B 上表现低于 30%,凸显了构建细粒度、面向电力领域特性评估框架的必要性(如图 2(b) 所示)。
- ProOPF-D 包含约 12,000 个样本,依据参数表达形式(显式给定与语义推断)及结构扩展程度划分为四个难度层级(Level1-4)。 数据集采用"基于修改"的表示方式,将每个实例定义为对规范 OPF 模型的差异化调整(参数变更与结构扩展),并配套自然语言描述与可执行参考实现,用于模型训练与能力分析。以 Qwen3-30B-A3B 为例,在 ProOPF-D 上训练后,Level 2 相较现有通用模型(GPT-5.2、Claude 4.5 Sonnet 等)最优结果提升 26.63%;在更具挑战性的 Level 4 上,GPT-5.2、Claude 4.5 Sonnet等通用大模型准确率均为 0,而训练后Qwen3-30B-A3B模型实现了零的突破,达到 11.54%,体现了该数据集对复杂电力优化建模任务的有效支撑(数据生成流程见图 1)。
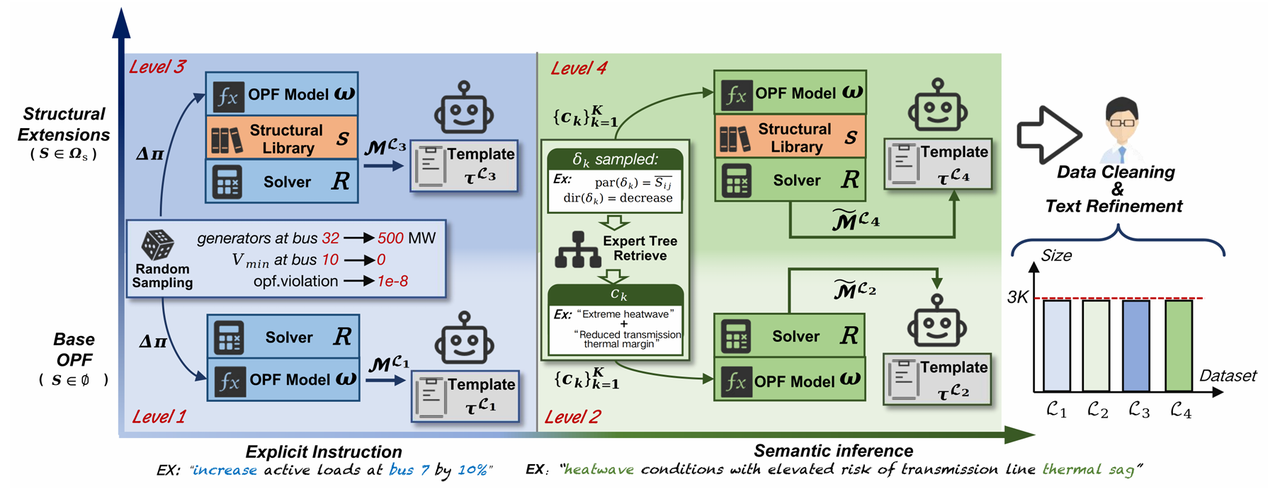
图1:ProOPF-D 四层级数据集与评测指标构建流程
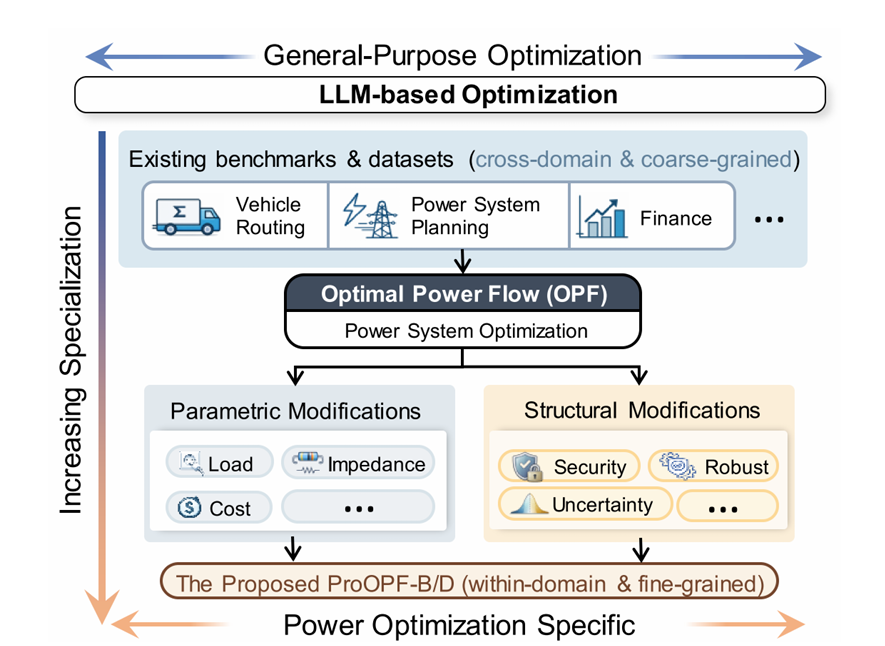
图2 (a):ProOPF 与既有基准的对比(领域内细粒度建模)
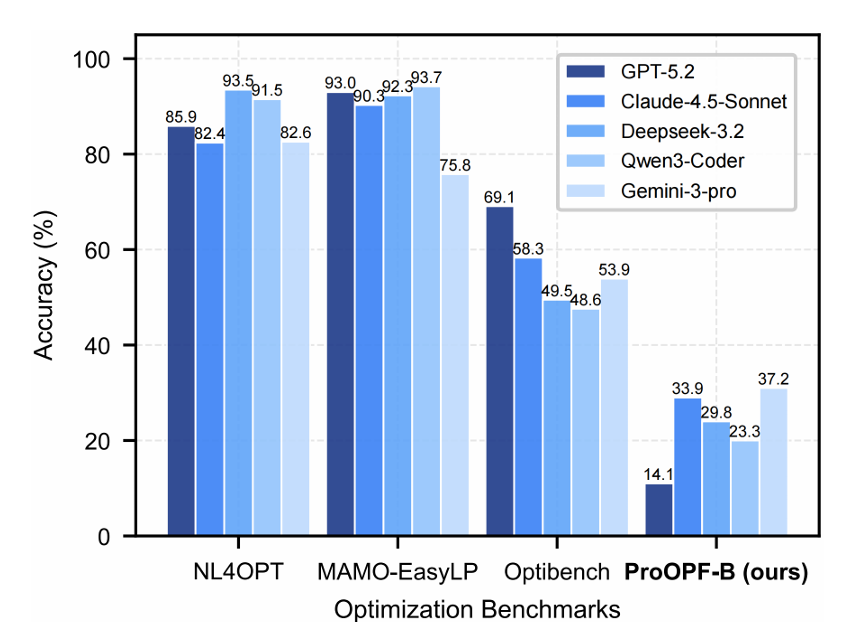
图2 (b):主流大模型在既有基准与 ProOPF-B 上的评测结果对比
1. 研究动机
随着可再生能源渗透率提高与电网规模扩大,电力系统运行的不确定性与场景多样性显著增加,调度目标与安全约束需要更频繁地调整。现实中,运行与规划涉及的并非单一问题,而是一系列相互关联的电力系统优化问题(如经济调度、机组组合、最优潮流及其安全/鲁棒扩展、灵活性资源协同等)。这些任务虽可由专家“手工建模”,但真正的工程难点在于:**面对持续变化的系统运行状态以及专家对场景的多样化描述,如何将需求快速、准确地转化为可执行的优化模型与代码,并确保模型在持续修改过程中始终符合电力系统的物理规律与运行可行性。**这种高频、强约束、依赖经验的建模迭代流程,正成为近实时决策与快速试算的瓶颈。
近年来,大语言模型(LLMs)在语义理解与代码生成方面的能力提升,使“自然语言运行需求 → 可执行优化建模/代码”逐渐可行,为降低建模门槛、加速从需求到可计算模型的闭环提供了新路径。然而,现有面向优化建模的基准与训练语料多强调跨领域、粗粒度的任务覆盖;当评估落到电力系统优化这一兼具强物理耦合、规模大、约束严格的专业场景时,仍缺乏能够刻画“在共享的基础建模框架上进行可靠修改(参数更新与结构扩展)”的工程级评估框架与数据支撑。其局限性主要体现在以下四个层面:
- 任务粒度粗泛:任务设置侧重跨领域泛化,缺乏对电力场景中细粒度建模(参数更新、结构扩展)的检验。
- 实例规模失配:通用基准在规模与结构复杂度上与电力工程任务存在系统性差距,难以刻画 OPF 等高维强耦合非线性问题特征。
- 合成扰动失真:数据合成过程中对种子问题的扰动不显式约束领域物理(如潮流方程),即使数学形式正确,物理可行性仍可能被违反,易产生工程语义偏离的监督信号。
- 生成目标冗余:监督偏向端到端完整生成,而电力场景多共享基础建模框架、差异限于参数与有限结构扩展,从零生成既冗余又易引入物理与建模不一致。
2. 本研究贡献
针对上述问题,本文构建了面向电力系统优化自动化建模能力评估的专用数据集与基准——ProOPF-D(Dataset) 与 ProOPF-B(Benchmark)。与既有基准侧重跨领域粗粒度泛化不同,ProOPF 以OPF 为统一的基础建模框架,在共享物理约束与问题结构的前提下,聚焦电力优化场景中“参数更新 + 结构扩展”的领域内细粒度建模能力评估与训练,如图 2、3 所示。
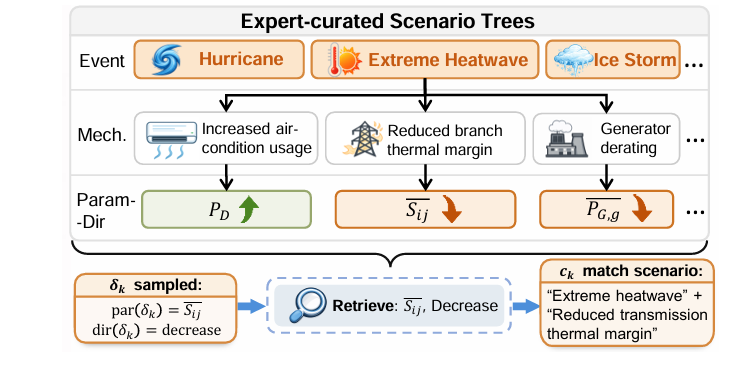
图3:用于 L2 合成的专家构建场景树
本研究的主要贡献总结如下:
- 提出 ProOPF-D/B,构建首个面向电力系统专业优化建模的大语言模型数据集与评测基准,推动基于大语言模型的优化建模研究由通用跨领域任务向大规模、复杂电力系统场景的专业化建模转变。ProOPF 所支持的电力优化问题可参考ProOPF支持电力优化问题列表。
- 针对 ProOPF-D,提出多层级数据构建流程,实现从显式参数到语义推断参数、从参数级修改到结构级扩展的逐层递进。每个样本均表示为对规范 OPF 模型的差异化修改,并在物理可行域内进行约束,同时配套自然语言描述、建模规范说明与可执行实现代码,形成统一的结构化数据体系。
- 针对 ProOPF-B,构建基于专家筛选文献的分层基准体系,并与 ProOPF-D 的难度划分保持一致。提出分层评测协议,区分具体参数建模与抽象语义建模两类任务,实现对模型可执行正确性的端到端严格评估。
3. 电力系统优化建模基础
3.1 基准模型:交流最优潮流模型(ACOPF)
交流最优潮流(ACOPF)在电力潮流物理规律与运行约束条件下,寻求最优的发电机出力和网络运行状态,使发电成本最小。将电力系统建模为图结构,节点集 N\mathcal{N}N 表示母线、边集 E\mathcal{E}E 表示支路、发电机集 G⊆N\mathcal{G}\subseteq\mathcal{N}G⊆N 表示机组,完整 OPF 问题可表述为:
minV,θ,PG,QG∑g∈G(agPG,g2+bgPG,g+cg)s.t.PG,i−PD,i=Vi∑j∈NVj(Gijcosθij+Bijsinθij),∀i∈NQG,i−QD,i=Vi∑j∈NVj(Gijsinθij−Bijcosθij),∀i∈N∣Sf,ij∣≤S‾ij, ∣St,ij∣≤S‾ij,∀(i,j)∈EVi∈[V‾i,V‾i], θi∈[θ‾i,θ‾i],∀i∈NPG,g∈[P‾G,g,P‾G,g], QG,g∈[Q‾G,g,Q‾G,g],∀g∈G\begin{aligned} \min_{\boldsymbol{V},\boldsymbol{\theta},\boldsymbol{P}_G,\boldsymbol{Q}_G}\quad & \sum_{g\in\mathcal{G}} \left( a_g P_{G,g}^2 + b_g P_{G,g} + c_g \right) \\ \text{s.t.}\quad & P_{G,i} - P_{D,i} = V_i \sum_{j\in\mathcal{N}} V_j \left( G_{ij}\cos\theta_{ij} + B_{ij}\sin\theta_{ij} \right), \quad \forall i\in\mathcal{N} \\ & Q_{G,i} - Q_{D,i} = V_i \sum_{j\in\mathcal{N}} V_j \left( G_{ij}\sin\theta_{ij} - B_{ij}\cos\theta_{ij} \right), \quad \forall i\in\mathcal{N} \\ & |S_{f,ij}| \le \overline{S}_{ij},\; |S_{t,ij}| \le \overline{S}_{ij}, \quad \forall (i,j)\in\mathcal{E} \\ & V_i\in[\underline{V}_i,\overline{V}_i],\;\theta_i\in[\underline{\theta}_i,\overline{\theta}_i],\quad \forall i\in\mathcal{N} \\ & P_{G,g}\in[\underline{P}_{G,g},\overline{P}_{G,g}],\;Q_{G,g}\in[\underline{Q}_{G,g},\overline{Q}_{G,g}],\quad \forall g\in\mathcal{G} \end{aligned}V,θ,PG,QGmins.t.g∈G∑(agPG,g2+bgPG,g+cg)PG,i−PD,i=Vij∈N∑Vj(Gijcosθij+Bijsinθij),∀i∈NQG,i−QD,i=Vij∈N∑Vj(Gijsinθij−Bijcosθij),∀i∈N∣Sf,ij∣≤Sij,∣St,ij∣≤Sij,∀(i,j)∈EVi∈[Vi,Vi],θi∈[θi,θi],∀i∈NPG,g∈[PG,g,PG,g],QG,g∈[QG,g,QG,g],∀g∈G
3.2 基于基准模型的建模表示
规范 ACOPF 具有 O(∣N∣+∣G∣)\mathcal{O}(|\mathcal{N}|+|\mathcal{G}|)O(∣N∣+∣G∣) 个变量与 O(∣N∣+∣E∣+∣G∣)\mathcal{O}(|\mathcal{N}|+|\mathcal{E}|+|\mathcal{G}|)O(∣N∣+∣E∣+∣G∣) 个约束,完整标注成本高昂,从零生成易出错。本文利用 OPF 实例共享的基础建模框架,仅监督变化部分(参数更新与结构扩展),将每个实例表示为对规范基准模型 Q0\mathcal{Q}_0Q0 的修改。形式化地,Q0\mathcal{Q}_0Q0 由基准系统参数 πsys\boldsymbol{\pi}_{\text{sys}}πsys 参数化(含成本系数、导纳、热限、负荷等)。目标模型 Q\mathcal{Q}Q 表示为
Q(Δπ,s∣πsys)≜Modifys (Q0(πsys+Δπ))\mathcal{Q}(\Delta\boldsymbol{\pi}, s \mid \boldsymbol{\pi}_{\text{sys}}) \triangleq \mathrm{Modify}_s\!\left(\mathcal{Q}_0(\boldsymbol{\pi}_{\text{sys}} + \Delta\boldsymbol{\pi})\right)Q(Δπ,s∣πsys)≜Modifys(Q0(πsys+Δπ))
其中 Δπ∈Ωπ\Delta\boldsymbol{\pi}\in\Omega_{\boldsymbol{\pi}}Δπ∈Ωπ 为参数修改,s∈Ωss\in\Omega_ss∈Ωs 为结构修改算子(可为空)。这种基于修改的表示将共同基准模型与场景差异化需求分开表示,为 ProOPF-D/B 奠定基础。
4. ProOPF-D:多层级数据集构建
4.1 结构化样本表示
ProOPF-D 中的每个样本 z={P,M,I}z=\{\mathcal{P}, \mathcal{M}, \mathcal{I}\}z={P,M,I},其中 P\mathcal{P}P 为自然语言需求描述,I\mathcal{I}I 为可执行代码(MATPOWER)。M\mathcal{M}M 展开为 {ω,Δπ,s,R}\{\omega, \Delta\boldsymbol{\pi}, s, \mathcal{R}\}{ω,Δπ,s,R}:ω\omegaω 标识基准系统;Δπ\Delta\boldsymbol{\pi}Δπ 为参数修改(patch δk\delta_kδk 编码组件、参数、操作及数值);sss 为结构修改(含问题类型 sps_psp、约束扩展 scs_csc、目标扩展 sos_oso);R\mathcal{R}R 为求解器配置。图 4、5 分别展示 Level 1/3 与 Level 2/4 的样本案例。

图4:Level 1 与 Level 3 示例——具体参数建模

图5:Level 2 与 Level 4 示例——抽象语义建模
4.2 四层级难度划分与合成流程
ProOPF-D 依据参数表达形式(显式给定 vs 语义推断)与结构扩展程度(无扩展 vs 需结构扩展)两个正交维度划分为四个难度层级,系统覆盖建模动作空间 Ωπ×(S∪{∅})\Omega_{\boldsymbol{\pi}} \times (\mathcal{S} \cup \{\varnothing\})Ωπ×(S∪{∅}),如图 1 所示。
Level 1(L1\mathcal{L}_1L1):显式参数指定,无结构扩展。 自然语言中直接给出参数修改的数值(如「将母线 7 有功负荷增加 10%」),模型需解析并映射至 OPF 参数配置。数据合成:从采样空间 ΩML1:=Ωsys×Ωπ×{∅}×ΩR\Omega_{\mathcal{M}}^{\mathcal{L}_1} := \Omega_{\text{sys}} \times \Omega_{\boldsymbol{\pi}} \times \{\varnothing\} \times \Omega_{\mathcal{R}}ΩML1:=Ωsys×Ωπ×{∅}×ΩR 均匀采样 M\mathcal{M}M,再以 M\mathcal{M}M 与指令规范 τL1\boldsymbol{\tau}^{\mathcal{L}_1}τL1 为条件,由 LLM 生成 P\mathcal{P}P 与 I\mathcal{I}I。对应控制室运行与假设分析等场景。
Level 2(L2\mathcal{L}_2L2):语义参数推断,无结构扩展。 参数修改隐含于运行场景描述中(如「极端高温导致输电线路热稳定裕度下降」),模型需从语义推断受影响参数类型及变化方向(Increase/Decrease/SetZero)。为避免泄露推断目标,引入专家标注场景树 T\mathcal{T}T:从事件层(如极端高温)到机制层(如输电热裕度下降)再到叶节点(参数-方向对),将 Δπ∈Ωπdir\Delta\boldsymbol{\pi} \in \Omega_{\boldsymbol{\pi}}^{\text{dir}}Δπ∈Ωπdir 检索为场景片段 {ck}\{c_k\}{ck},替换 Δπ\Delta\boldsymbol{\pi}Δπ 形成中间规范 M~L2\widetilde{\mathcal{M}}^{\mathcal{L}_2}M L2,再由 LLM 将片段聚合为连贯运行叙述并生成带占位符的参数化实现。典型于事件驱动的运行工况。场景树结构示意如图 6 所示。
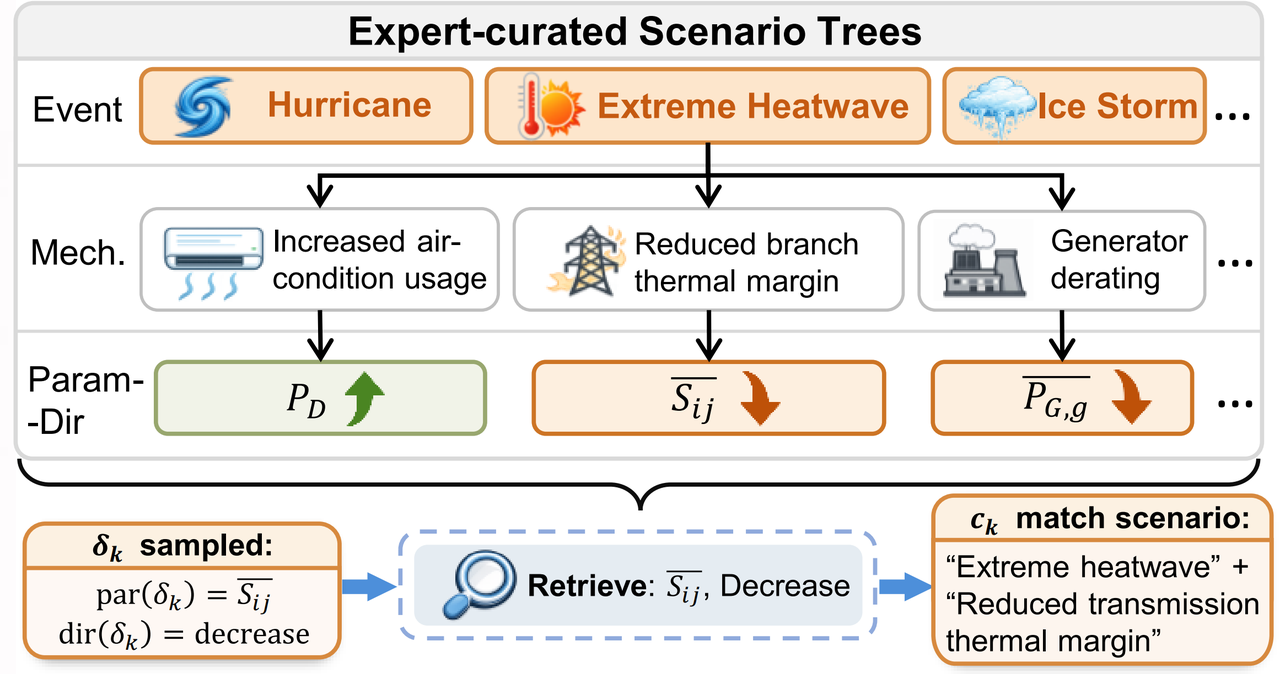
图6:专家标注场景树
Level 3(L3\mathcal{L}_3L3):显式参数 + 结构扩展。 在显式参数修改基础上引入结构扩展。结构修改空间 Ωs\Omega_sΩs 由专家从文献与工程实践遴选,包含决策变量扩展 Sp\mathcal{S}_pSp(7 种,如 DCOPF、机组组合)、目标扩展 So\mathcal{S}_oSo(15 种)、约束扩展 Sc\mathcal{S}_cSc(9 种),四位领域专家为各变体提供设计依据与实现代码。每样本构造 s=(sp,so,sc)s=(s_p, s_o, s_c)s=(sp,so,sc),其余组件同 L1\mathcal{L}_1L1。τL3\boldsymbol{\tau}^{\mathcal{L}_3}τL3 在 τL1\boldsymbol{\tau}^{\mathcal{L}_1}τL1 基础上纳入变体名称、设计依据及结构组件的实现指导。
Level 4(L4\mathcal{L}_4L4):语义参数推断 + 结构扩展。结合 L2\mathcal{L}_2L2 的 Ωπdir\Omega_{\boldsymbol{\pi}}^{\text{dir}}Ωπdir 与场景树机制,以及 L3\mathcal{L}_3L3 的 Ωs\Omega_sΩs(采用更宽松的 sos_oso、scs_csc 基数约束),为最具挑战性的专家级建模场景。
4.3 数据清洗与文本精炼
合成样本经后处理:(1)兼容性过滤:专家规则表 C\mathcal{C}C 剔除无效 (s,Δπ)(s, \Delta\boldsymbol{\pi})(s,Δπ) 组合(如 DCOPF 不适用无功/电压修改);(2)表述多样化:LLM 对等价类内样本复述,丰富 P\mathcal{P}P 表达形式。最终约 12,000 样本,四层级各约 3,000。
5. ProOPF-B:专家标注评测基准与分层评估协议
ProOPF-B 是面向 OPF 建模能力的专家标注评测基准,与 ProOPF-D 的四层级难度划分保持一致。本研究招募四位电力系统领域专家,从同行评审文献中遴选代表性 OPF 建模任务,并基于 MATPOWER 工具链提供对齐的参考实现。ProOPF-B 共包含 121 个测试用例,覆盖四个层级(Level 1:36;Level 2:30;Level 3:29;Level 4:26),所有实例经审计确保与 ProOPF-D 无重叠。
评测采用分层评估协议,依据自然语言描述 P\mathcal{P}P 是否给出具体参数实例化,区分为两类端到端评测流程(如图 7 所示):
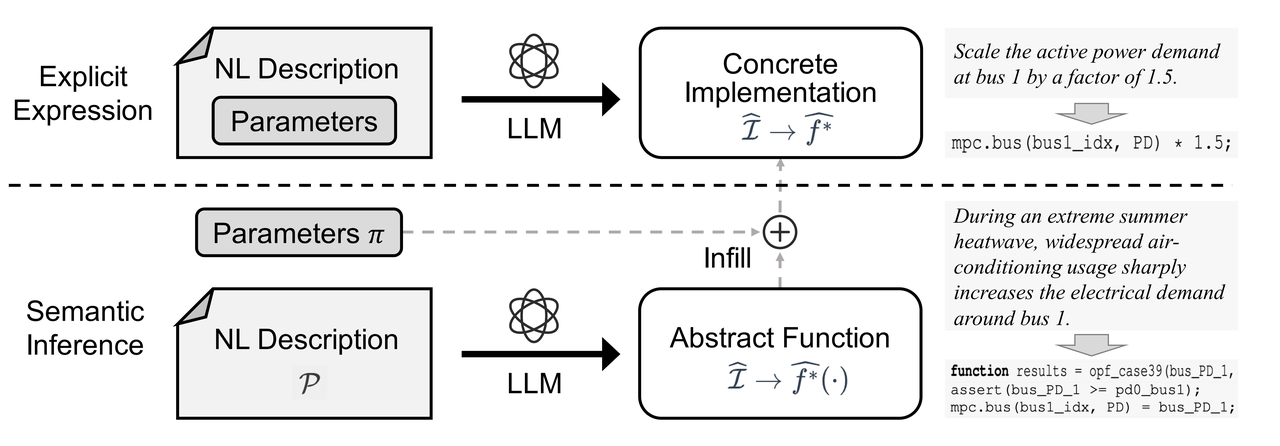
图7:ProOPF-B 分层评测流程——具体参数建模(Level 1/3)与抽象语义建模(Level 2/4)
- 具体参数建模(Level 1/3):样本 z={P,I,f∗}z=\{\mathcal{P}, \mathcal{I}, f^*\}z={P,I,f∗},其中 f∗f^*f∗ 为执行参考实现 I\mathcal{I}I 所得的最优目标值。模型根据 P\mathcal{P}P 生成实现 I^\widehat{\mathcal{I}}I ,执行后得到 f∗^\widehat{f^*}f∗ ;若∣f∗^−f∗∣≤ϵ|\widehat{f^*} - f^*| \le \epsilon∣f∗ −f∗∣≤ϵ(ϵ\epsilonϵ 为容差阈值),则判为正确。
- 抽象语义建模(Level 2/4):样本 z={P,I,π,f∗(π)}z=\{\mathcal{P}, \mathcal{I}, \boldsymbol{\pi}, f^*(\boldsymbol{\pi})\}z={P,I,π,f∗(π)},其中 π\boldsymbol{\pi}π 为与 P\mathcal{P}P 语义一致的预定义参数实例化。模型生成参数化实现 I^(⋅)\widehat{\mathcal{I}}(\cdot)I (⋅),以 π\boldsymbol{\pi}π 为输入执行得到 f∗^(π)\widehat{f^*}(\boldsymbol{\pi})f∗ (π);若 ∣f∗^(π)−f∗(π)∣≤ϵ|\widehat{f^*}(\boldsymbol{\pi}) - f^*(\boldsymbol{\pi})| \le \epsilon∣f∗ (π)−f∗(π)∣≤ϵ,则判为正确。
6. 实验分析
6.1 实验设置
评测在 ProOPF-B 四个难度层级上进行,以生成实现的目标值精度判定正确性(pass@1)。基线模型包括 GPT-5.2、Claude 4.5 Sonnet、DeepSeek V3.2、Gemini 3.0 Pro、Qwen3-Coder、Qwen3-30B-A3B,在 zero-shot 与 few-shot 两种设定下评估。针对监督微调(SFT),以 Qwen3-30B-A3B 为预训练模型,在 ProOPF-D 上微调。
6.2 主实验结果
表 1 展示了各模型在 ProOPF-B 四层级上的准确率(%)。具体参数建模(Level 1/3)与抽象语义建模(Level 2/4)分别对应显式参数与语义推断两类任务。
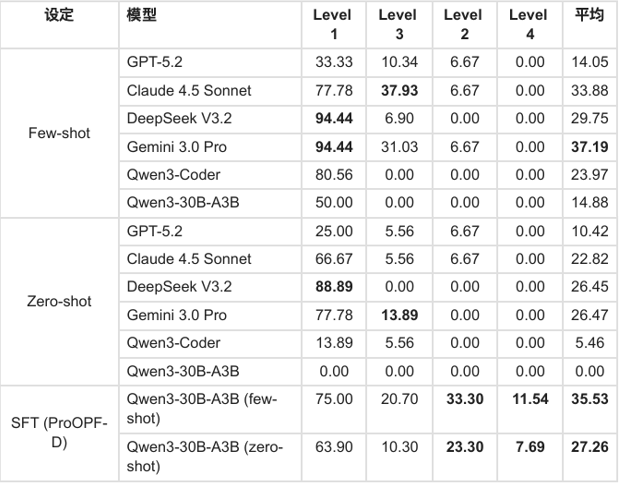
表1:各模型在 ProOPF-B 四层级上的准确率(%)
6.3 基线模型分析
从显式到语义:模型表现与任务抽象程度呈显著负相关。Gemini 3.0 Pro、DeepSeek V3.2 等在 Level 1 上可达 94.44%,但 Level 2 引入语义歧义后准确率骤降至接近零。Level 4 结合语义推断与结构扩展,所有基线模型均为 0.00%。
从 Few-shot 到 Zero-shot:移除 few-shot 示例后,结构修改能力大幅下降,相对准确率降低 50%–85%,表明当前模型严重依赖上下文示例来应对拓扑与实现约束。
诊断性失败分析:基于六维能力分解(见图 8),可识别三类典型失败模式:(1)实现鸿沟:多数模型在结构修改识别上达 60%–72%,但无法转化为可执行代码,瓶颈在于求解器配置与 API 知识;(2)建模正确但无法执行:如 GPT-5.2 具有较高可执行正确率但可执行率极低,即 formulation 逻辑正确却因语法错误或求解器配置失效而无法运行;(3)语义壁垒:Level 2/4 的普遍失败源于语义参数推断能力近乎为零,模型无法将定性描述(如「重负荷」)映射至定量领域标准。
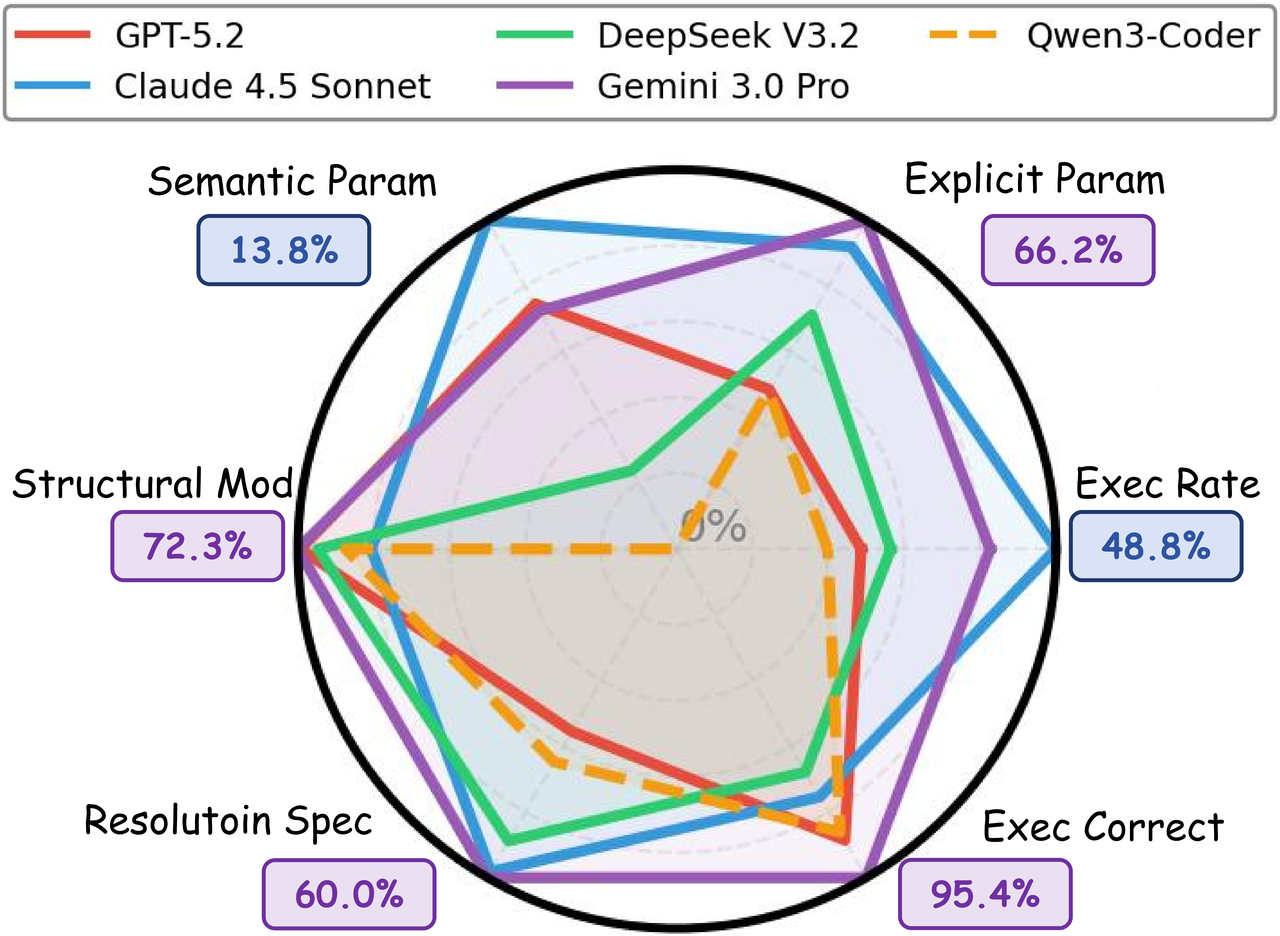
图8:OPF 建模六维能力雷达图——各轴对应一项基础能力,数值以百分比表示
6.4 监督微调效果
在 ProOPF-D 上微调 Qwen3-30B-A3B 后,few-shot 平均准确率从 14.88% 提升至 35.53%。Level 2 提升最为显著,从 0.00% 跃升至 33.30%;Level 4 在所有基线均为 0% 的情况下,微调模型达到 11.54%,首次取得非零结果。Zero-shot 下四个层级均有至少 7.69% 的提升。结果表明 ProOPF-D 的基于修改表示与多层级设计能有效支撑模型学习领域知识,缓解实现模式与语义推理两大瓶颈;Level 2(20.70%)与 Level 4(11.54%)仍有提升空间,语义参数推断与复合挑战仍是未来研究方向。
7. 总结与未来展望
本文围绕“自然语言运行需求 → 可执行电力系统优化模型/代码”的自动化建模目标,构建了面向专业电力优化建模的评测体系:通过 ProOPF-D 提供可训练的多层级样本,并以 ProOPF-B 给出端到端、可执行的严格评测协议。实验结果显示,主流大模型在通用优化建模基准上表现优异,但在电力工程级场景(尤其是语义参数推断与结构扩展的组合挑战)上仍存在显著差距;而基于 ProOPF-D 的监督微调能够有效提升整体表现,验证了“数据与评测牵引能力提升”的研究路径。
面向未来,我们更关注三条更“工程落地导向”的路径:(1)从以 OPF 为核心扩展到更广泛的电力优化任务族:在已覆盖机组组合、拓扑重构与多时间尺度优化等典型场景的基础上,进一步扩展到电力市场出清/报价与辅助服务协同、源网荷储与需求响应的市场化调度、以及电力设备与资源选址/规划(如储能选址定容、可再生能源并网选址、FACTS/无功补偿配置、充电基础设施布局等)等更丰富的真实任务;(2)人机协同的闭环建模:支持“提出需求—生成修改—仿真/求解验证—交互修订”的迭代流程,把模型作为助手而非替代者,服务近实时决策与快速试算;(3)基于强化学习(RL)的可执行反馈微调(fine-tuning):将“可执行/通过率、目标值质量、物理可行性、运行安全规则”等可计算指标构造成奖励信号,结合求解器/仿真器的执行反馈对模型进行 RL 微调,使其在真实工具链约束下学会更稳健的建模、调试与工具使用策略,从而系统提升稳定性与可复用性。我们期待 ProOPF 能为后续研究提供可复用的基准与数据基础,推动大模型在电力系统专业优化建模中的可靠落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)