我是怎么使用 LLM 的?
一、认识大型语言模型——从「压缩文件」到智能助手
模型就像在玩文字接龙游戏,每一步都选择概率最高的路径前进。
1.1 LLM 是什么?
大型语言模型(LLM),如 ChatGPT,可以被形象地比作「互联网的压缩文件」。这个「压缩文件」里存储了海量的知识和信息,但与普通压缩文件不同的是,它不是精确无损的,而是带有一定的模糊性和概率性。换句话说,LLM 并不能完美地记住互联网上的每一个细节,而是通过学习大量数据,掌握了知识的「大概」和「趋势」。
在技术层面,LLM 是由神经网络构成的,包含了约 1 万亿个参数,这些参数的集合大约占 1TB 的存储空间。这个神经网络的任务是预测文本中的下一个词(或词元,token),但在这个过程中,它实际上学会了理解和生成语言,乃至掌握了广泛的世界知识。
LLM 的训练过程分为两个主要阶段:
-
预训练(Pre-training)
:在这个阶段,模型会「阅读」互联网上的大量文本数据,并尝试预测每个词的下一个词。通过这种方式,模型逐渐「压缩」了互联网的知识,学会了语言的结构和世界的运作规律。然而,这个过程非常耗时且昂贵——训练一个大型模型可能需要数月时间和数千万美元的成本。因此,预训练通常不会频繁进行,这也导致模型的知识有一个「截止日期」(Knowledge Cutoff),即模型只了解训练数据收集时之前的信息。
-
后训练(Post-training)
:预训练后的模型虽然掌握了大量知识,但并不知道如何与人类进行对话。后训练阶段通过使用人工 curated 的对话数据,教模型如何以助手的身份回应用户的问题。这个过程让模型学会了如何礼貌、准确地回答问题,赋予了它「人格」。
尽管 LLM 拥有惊人的知识储备,但它也有局限性:
- 知识截止日期:由于预训练的成本高昂,模型的知识通常落后于当前时间数月甚至一年。例如,GPT-4o 的知识可能截止到一年前。
- 知识的模糊性:模型对互联网上频繁出现的信息有较好的记忆,但对于罕见或冷门的信息,记忆可能较为模糊,类似于人类的记忆方式。
1.2 LLM 如何工作?
要理解 LLM 的工作原理,首先需要了解「词元」(Token)的概念。词元是文本的基本单位,类似于拼图中的一块块拼图。文本在输入模型之前,会被分解成一系列的词元,每个词元可能是一个词、一个字或其他文本片段。
例如,如果你输入「Write a haiku」,这个短语会被分解成若干个词元(具体数量取决于分词器)。你可以使用 TikTokenizer 这样的工具来查看文本是如何被分解的。TikTokenizer 会显示每个词元及其对应的 ID,模型实际看到的是这些 ID 的序列。
你可以自行在Tiktokenizer网站进行试用,下图就是一个例子:
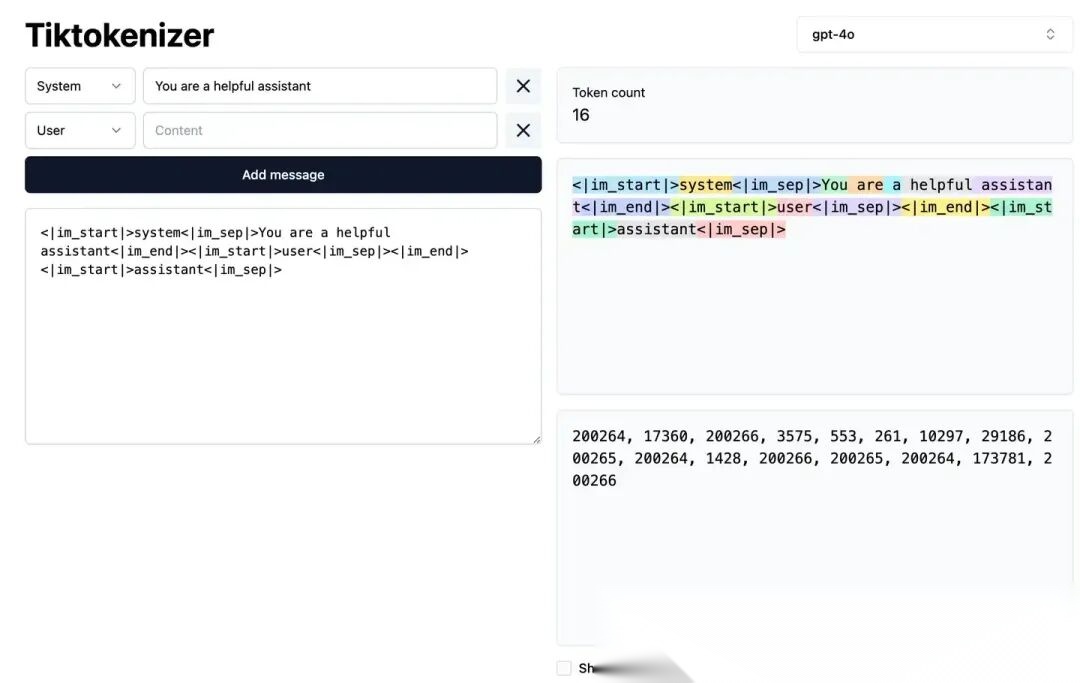
在 LLM 中,所有的对话都发生在一个「上下文窗口」(Context Window)中。上下文窗口就像是模型的「工作记忆」,它存储了当前对话的所有词元序列。每次你开始一个新的对话(比如点击「New Chat」),上下文窗口就会被清空,模型从零开始。
对话的本质是用户和模型共同构建一个一维的词元流。用户输入一些词元,然后模型根据这些词元预测并生成更多的词元作为回应。例如,用户输入 15 个词元,模型回应 19 个词元,整个对话就是 34 个词元的序列(不包括特殊的控制词元)。
为了保持对话的高效性,建议在切换话题时开始一个新的对话。这样可以清空上下文窗口,避免无关信息干扰模型的注意力,同时减少计算成本。
而LLM生成回答,就是一个「根据上下文不停地推测下一个token是什么」的过程。
二、LLM 的日常应用——从写诗到百科全书
在掌握了 LLM 的基本原理后,我们现在来看看如何将其融入日常生活。LLM 不仅能帮助我们完成创意写作,还能回答各种问题,成为我们随身的智能助手。让我们从基础交互开始,逐步了解它的实用性。
2.1 基础交互:文本的魔法
LLM 最常见的用途之一是生成文本。无论是写诗、起草邮件,还是润色简历,它都能快速提供帮助。以下是一个简单的例子:我们让DeepSeek来写一下《红楼梦》中的海棠诗。

说不上有多好,但基本功已经远超大部分普通人了,不仅展示了 LLM 的创作能力,还反映了它指令遵循的能力。只需要简单的指令,它就能生成符合要求的文本,这种便捷性让它成为日常生活的得力工具。你只需要像与朋友聊天一样——输入你的需求,等待回应。无论是「帮我写一封道歉邮件」还是「给我讲个笑话」,它都能迅速给出答案。
2.2 知识查询:私人百科全书
LLM 内置了庞大的知识库,可以回答从生活琐事到学术问题的大量查询。
适用场景:
- 高频信息:如食物营养成分、历史事件、基本科学知识等。
- 快速解答:适合需要即时答案的场合,比如临时查资料或解决争论。
局限性:
- 知识截止日期:LLM 的训练数据有时间限制(例如截至 2023 年 10 月),无法提供最新信息,如最近的新闻或天气预报。
- 准确性风险:回答基于「记忆」生成,偶尔可能出现模糊或错误,重要信息建议二次验证。
实用建议:
- 对于静态、常见的问题,LLM 是快速查询的理想选择。
- 如果需要最新数据,建议提供充足的上下文(比如把原始文件一并提供给LLM),或者搭配搜索增强技术(RAG)。
2.3 对话管理:保持高效
为了让 LLM 在对话中保持高效,管理好上下文非常重要。以下是一些实用技巧:
- 新对话:
每次开始新话题时,建议清空上下文(如点击「New Chat」),让模型专注于当前任务,避免无关信息干扰。 - 上下文窗口:
LLM 会记住对话中的内容,但窗口容量有限。过多的旧信息可能分散模型注意力,降低回答质量。 - 管理技巧:
- 定期刷新对话,尤其在切换主题时。
- 如果需要保留关键信息,可以手动总结或使用「记忆」功能。
三、高级工具——让 LLM 更强大
除了基础功能,LLM 还可以结合一系列高级工具,让它能够应对更复杂的需求。这些工具包括思维模型、互联网搜索、Python 解释器和深度研究等。
3.1 思维模型(Thinking Models)
思维模型,有时也被称作推理模型(Reasoning Models),是经过强化学习优化的 LLM,能够模拟人类解决问题的思考过程。它会在回答前进行「内心独白」,逐步推理,从而提高复杂任务的准确性。OpenAI的o系列、DeepSeek的R1都是这类模型的代表。
应用场景:
- 数学问题:如解方程或计算概率。
- 编程调试:比如分析代码中的错误,类似 Karpathy 演讲中提到的梯度检查失败问题,思维模型能通过推理找到根源。
特点:
- 耗时较长:需要几秒到几分钟来「思考」。
- 精度更高:在逻辑推理和复杂计算中表现优于普通模型。
使用建议:
- 简单任务用普通模式,节省时间。
- 复杂问题切换到思维模型,确保结果可靠。
3.2 搜索增强技术(RAG)
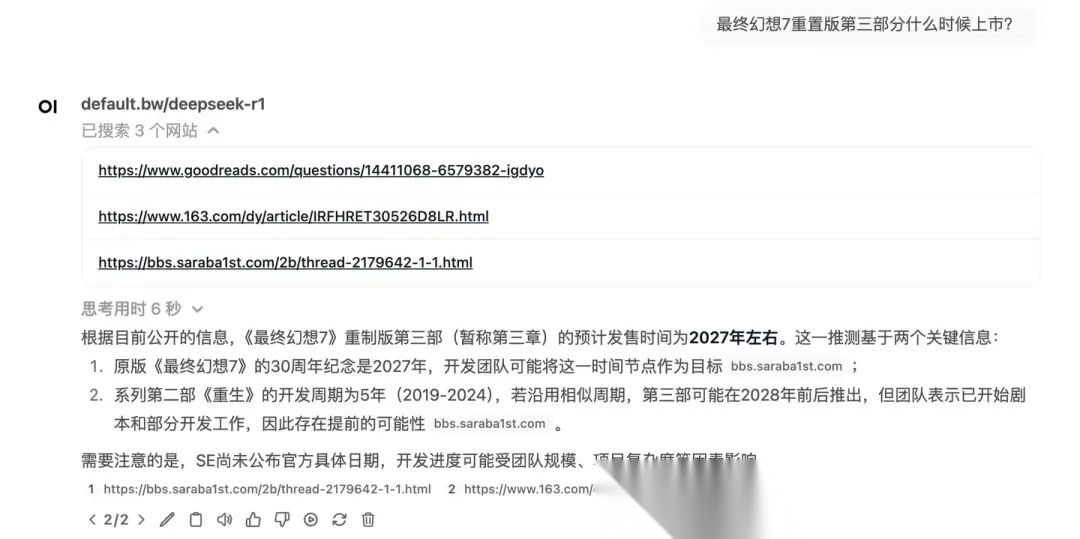
有很多用户抱怨 LLM 经常「瞎编」,其实它不是故意要「欺骗」你,而是它的原理决定了它本质上追求的是「概率」,无法完全保证「真实」,这在专业领域常被称作LLM的「幻觉」。而搜索增强技术(RAG)说白了就是让LLM可以「上网搜索」,获取最新的信息,补充上下文,让出现「幻觉」的可能变小。
这是不开启「联网搜索」功能的回答,只能依靠模型自身的知识:

这是开启了「联网搜索」的回答,先搜索再根据搜索结果进行回答(也会受到搜索方案质量的影响):
3.3 Python 解释器
LLM 还有一个缺点,就是「算术」(注意,不要笼统理解为「数学」)能力不强,这也是跟它的「猜词」原理有关。克服这个缺陷,有一个方案,最早是ChatGPT提出的,叫做「代码解释器」,也就是说让LLM先根据需求写出代码,然后提供给他一个可执行的代码运行环境(相当于一个计算器),去计算结果,然后根据执行结果再回答问题。以下是一个例子:
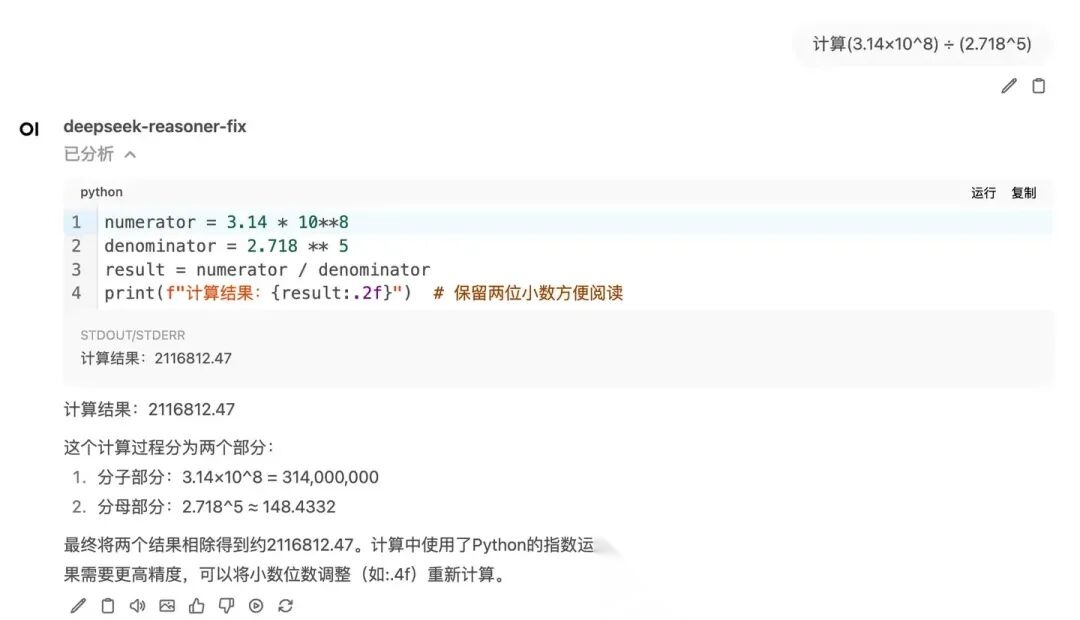
这种思路不止可以用在简单的算术问题上,还可以用于负责的数据分析、快速编写小程序或调试代码等场景上。
3.4 深度研究(Deep Research)
可以看做是加强版的RAG,让功能更强大的「思考模型」配合搜索工具,生成详细的研究报告。适用于需要全面分析的主题,如科学课题或市场趋势。
以下是一个Grok-3「分析2024年全球造船业」的案例:
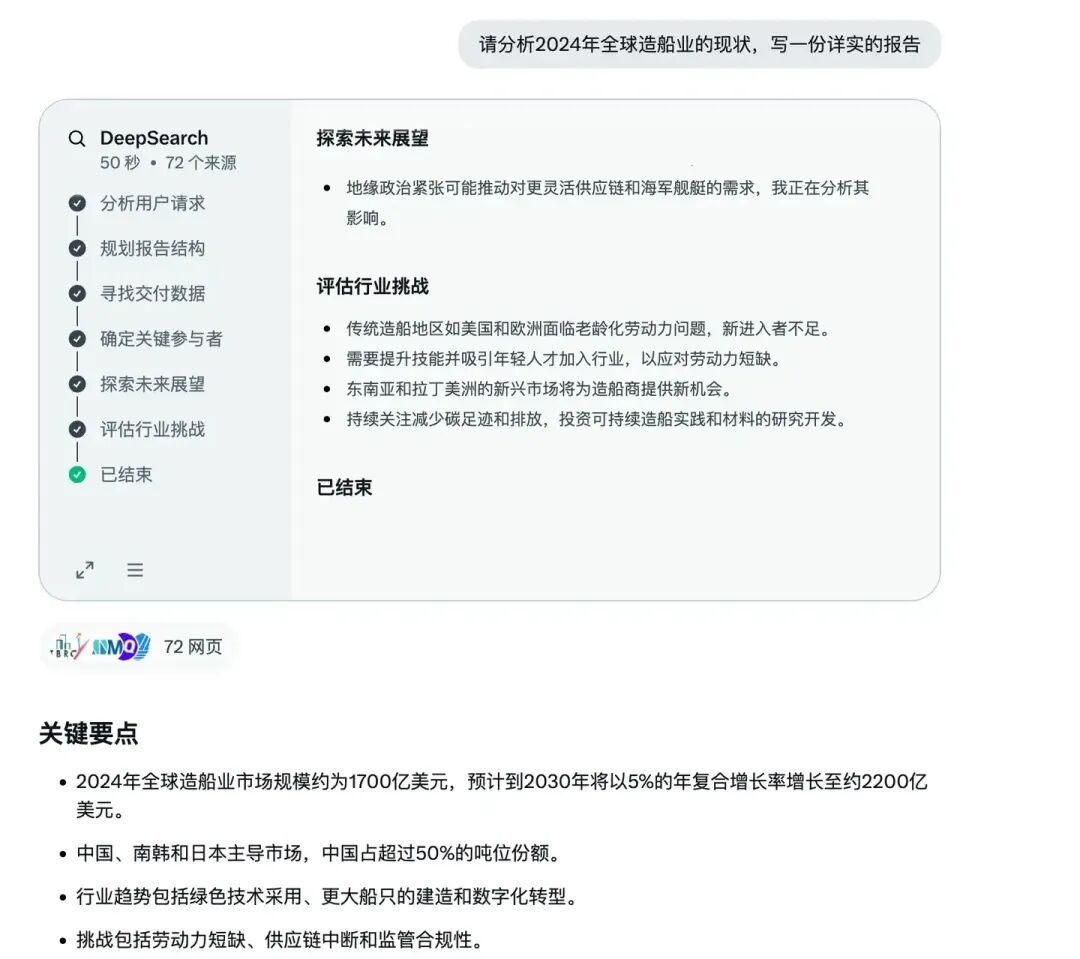
后续报告比较长,就不贴完整了。
3.5 文件上传与分析
现在很多LLM应用都支持上传 PDF、文档等长篇文件(其实就是帮你做了文档解析的步骤,最终给LLM的仍然是文本),可以用来做书籍阅读、学术文献研究等等,把 LLM 当作「阅读助手」,快速理解复杂内容,提升学习效率。
我曾经写过自己的论文阅读工作流,可以参考:
tomsheep:我的论文解读工作流81 赞同 · 5 评论文章
四、多模态交互——超越文字
大型语言模型(LLM)早已不再是只能处理文字的工具。随着技术的发展,它们现在能够理解和生成语音、图像甚至视频等多种形式的信息。这种多模态能力让 AI 与用户的互动更接近人类自然交流的方式。本部分将带你了解 LLM 如何超越文字,探索语音交互和视觉处理的奥秘。
4.1 语音交互
语音交互是多模态功能中最常见的一种。通过语音,你可以直接「开口」向 LLM 提问,而无需敲键盘。根据处理方式的不同,语音交互分为「假音频」和「真音频」两种类型。
假音频(Fake Audio)
用户的语音先被转换为文字(语音转文字),LLM 基于文字生成回答,然后将回答转回语音(文字转语音)。
举个例子:在手机上使用 ChatGPT 时,你可以说「明天北京天气如何」,系统会把这句话转为文字,生成回答后用语音播报「明天北京晴,温度 20-28 度」。
- 特点:
- 简单高效,依赖成熟的语音识别技术。
- 适合快速查询,比如问时间、查资料。
- 局限:
- 无法捕捉语音中的语气或情感,比如你生气地说「快点回答」,模型可能无视你的情绪。
- 小建议:
如果你用 Mac,可以试试 Super Whisper 这样的工具,把语音实时转成文字,提升输入效率。
真音频(True Audio)
LLM 直接处理音频数据(以 token 形式),无需文字转换,能理解声音并生成语音回应。
举个例子:在 ChatGPT 的「Advanced Voice Mode」中,你可以说「用海盗口吻告诉我月球有多大」,模型会用粗犷的海盗声音回答:「啊哈,月球直径约 3500 公里,伙计!」
- 特点:
- 对话更自然,支持语气和风格变化。
- 可以模仿某些声音,比如名人或角色(有限范围内)。
- 局限:
- 目前功能还在完善,比如要求模仿猫叫,模型可能会拒绝。
- 小建议:
- 想体验趣味交互时,试试真音频模式,尤其适合娱乐或教育场景。
4.2 图像与视频
除了语音,LLM 还能处理图像和视频,让你通过上传图片或展示物体与 AI 互动,甚至生成视觉内容,这些功能都让技术更贴近生活。
图像输入
- 功能:你可以上传图片,LLM 会分析内容并回答问题。
- 举个例子:
- 上传一张食品包装的营养标签,问「这个有没有添加糖?」
- 上传血检报告,问「我的胆固醇正常吗?」
- 小建议:
- 图片要清晰,尤其是文字部分。
- 对于健康相关问题,建议结合专业意见验证结果。
图像生成
- 工具:如 DALL-E 3,能根据文字描述生成图像。
- 举个例子:输入「画一幅赛博朋克风格的城市夜景」,几秒后就能得到一张未来感十足的图片。
- 应用:
- 创作博客配图、设计灵感草稿,或生成个性化头像。
视频交互
- 输入:你可以用手机摄像头展示物体,LLM 实时识别并回答。
- 比如,拿着一本书问「这是什么书」,模型会识别封面并介绍内容。
- 生成:借助 AI 工具(如 Runway),输入「生成一段森林里的小鹿动画」,就能得到短视频。
- 特点:
- 直观有趣,尤其适合移动设备用户。
五、高级定制——打造你的 AI 分身
5.1 记忆网络:让模型真正「懂你」
个性化知识库构建:
通过持续对话,AI应用可以根据历史自动生成用户画像。目前底层的 LLM 模型基本上都是「无状态的」,这些「画像」需要模型层或者应用层的记忆拓展。不过对于用户来说,这个功能是透明的。
{ "饮食偏好": {"素食倾向": 70%, "过敏原": ["花生"]}, "学习轨迹": {"韩语": "TOPIK 2级", "最近查询": "敬语使用场景"} }
隐私保护机制:
在 ChatGPT 设置中开启「临时会话」模式,敏感咨询不留存历史记录
5.2 自定义 GPT:垂直领域专家养成
韩语学习 GPT 搭建实录:
-
基础设定
:
角色:韩语母语级导师
核心功能:
语法纠错(标注敬语等级)
文化背景扩展(如成语典故)
TOPIK考题解析
-
知识注入
:
- 上传《延世韩国语》PDF,指令:「提取所有语法点,按难度分级」
-
交互测试
:
- 用户输入:
「~아/어 보다和~ㄴ/은 적이 있다有什么区别?」 - 模型输出:
| 语法点 | 含义 | 例句 |
|---|---|---|
| ~아/어 보다 | 尝试做某事 | 한국어를 배워 봤어요 |
| ~ㄴ/은 적이 있다 | 有过某种经历 | 부산에 간 적이 있어요 |
5.3 开发者模式:Vibe Coding
Karpathy把自己实践的「AI 与人类的协作编程范式」叫做Vibe Coding(氛围编程):只描述需求、提出修改意见、验收结果,扮演一个甲方角色即可,实施的部分都由AI这个乙方来完成。
示例:
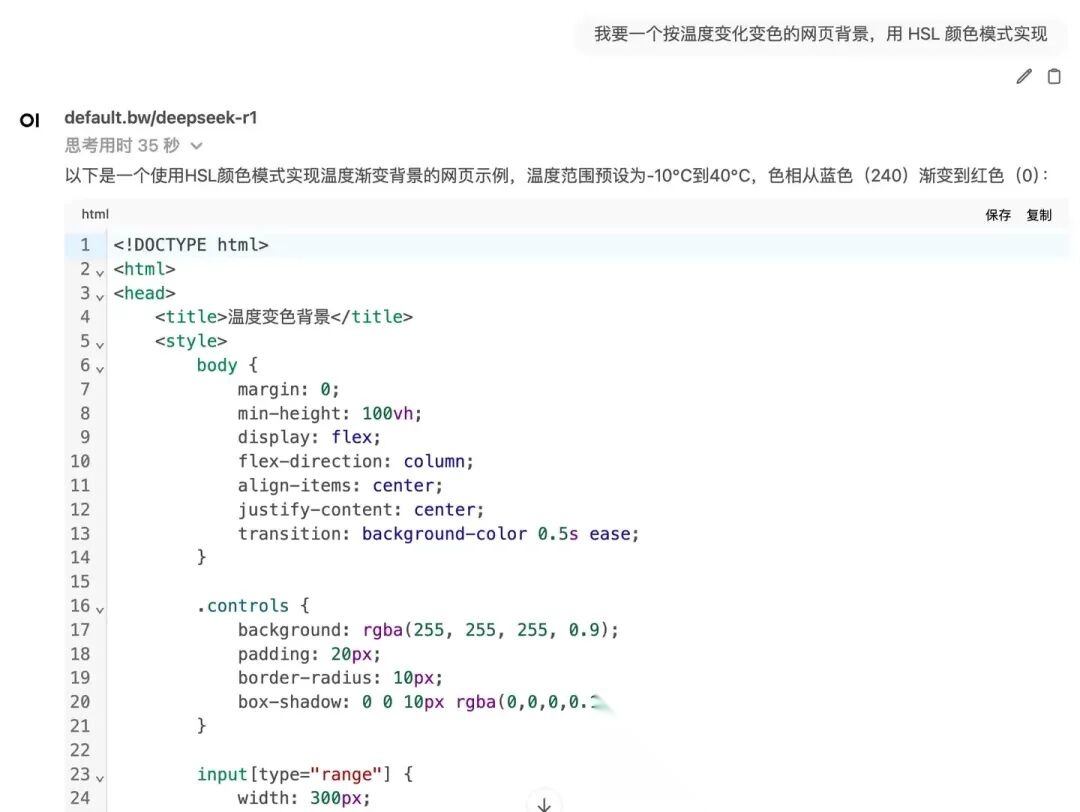
如果对结果不满意,可以进行多次交互,要求改版(这才是甲方该有的样子)。
目前有很多IDE都集成了AI能力,可以提供比「聊天」更丰富的功能,比如Cursor、windcurf、cline等,也可以试用。
5.4 复杂问题解决框架
数学证明协作流程
> 命题:证明√2是无理数- [用户] 提供基本命题- [AI] 反证法框架搭建: 假设√2 = a/b(a,b互质)- [用户] 指出a²=2b²的推导- [AI] 引导发现矛盾点: a和b必为偶数,与互质假设冲突- [协作成果] 完整证明文档生成
跨文档分析案例
输入:- 2023年新能源汽车白皮书.pdf- 特斯拉Q4财报.docx- 锂电池技术专利分析.txt输出:▸ 市场趋势:固态电池商业化进度延迟▸ 投资风险:4680电池良品率低于预期▸ 战略建议:关注磷酸铁锂技术路线
5.5 效率倍增秘籍
上下文管理四原则
- 话题隔离:每个新主题创建独立对话
- 记忆摘要:定期提炼关键结论
- 断点续传:
上次我们讨论到…现在继续 - 知识存档:重要结论导出为 Markdown
快捷指令模板库
维护自己的指令模板,用的时候快捷调出:
/邮件:生成包含[主题][重点][语气]的商务邮件/代码:用[语言]实现[功能],要求[性能指标]/学习:用[3岁小孩能懂]的方式解释[相对论]
六、结语
未来已来,只是分布不均。 —— William Gibson
我们处在异常变革的前夕,这场变革要求我们:
-
重塑知识获取
:从记忆事实转向驾驭智能
-
升级思维模式
:从线性思考到系统协同
-
重建协作范式
:人机互补的进化之路
我们不是在教会机器思考,而是在学习如何与思考的机器共舞。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)