MiroThinker-1.7 & H1:搜索 Agent 的天花板不在“搜得多“,而在“每步都靠谱“
MiroThinker-1.7 & H1:搜索 Agent 的天花板不在"搜得多",而在"每步都靠谱"
论文标题:MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
作者:MiroMind Team: S. Bai, L. Bing, L. Lei, R. Li, X. Li, X. Lin, E. Min, L. Su, B. Wang, L. Wang, L. Wang, S. Wang, X. Wang, Y. Zhang, Z. Zhang, G. Chen, L. Chen, Z. Cheng, Y. Deng, Z. Huang, D. Ng, J. Ni, Q. Ren, X. Tang, B.L. Wang, H. Wang, N. Wang, C. Wei, Q. Wu, J. Xia, Y. Xiao, H. Xu, X. Xu, C. Xue, Z. Yang, Z. Yang, F. Ye, H. Ye, J. Yu, C. Zhang, W. Zhang, H. Zhao, P. Zhu(共 42 位作者)
机构:MiroMind(陈天桥与代季峰联合创立的 AGI 公司)
论文链接:https://arxiv.org/abs/2603.15726
代码/模型:https://github.com/MiroMindAI/MiroThinker
产品体验:https://dr.miromind.ai/
🎯 核心摘要
搜索 Agent 过去两年的军备竞赛集中在一个维度:搜得更多——更长的上下文、更多的工具调用、更深的交互链条。但 MiroMind 团队从自家 v1.0/v1.5 的迭代中发现了一个反直觉的事实:200 步推理链中只要一步出错,后续所有推理全部建立在错误的地基上。交互越深,错误传播的风险反而越大。
MiroThinker-1.7 换了一条路:在预训练和 SFT 之间插入 Agentic Mid-Training 阶段,强化每一步的"原子决策"质量(规划、推理、工具使用、答案汇总)。MiroThinker-H1 再叠加一套 Local + Global 双重验证机制,让模型"做一步查一步、交卷前全局复审"。结果是 BrowseComp 88.2%、GAIA 88.5%——前者 OpenAI Deep Research 只有 51.5%,Gemini-3.1-Pro 是 85.9。
定位判断:核心技术贡献在于训练侧的 Agentic Mid-Training + 推理侧的验证机制这套组合拳。但 H1 闭源、验证机制实现细节偏薄,学术可复现性打了折扣。更像一份高质量的产品技术报告,而非一篇方法论突破的学术论文。
📖 问题动机:交互越深,为什么反而越不稳?
搜索 Agent 赛道的发展轨迹清晰可追溯。MiroThinker v1.0(2025 年 8 月)的核心卖点是"交互深度 Scaling":256K 上下文窗口、单任务最多 600 次工具调用,提出了"性能 ∝ 交互深度 × 反思频率"的 Scaling Law。v1.5(2026 年 1 月)把这条路推得更远,30B 参数在 BrowseComp-ZH 上打赢万亿参数的 Kimi-K2-Thinking,单次推理成本仅 $0.07。
数字很亮眼,但到了 v1.7,团队的关注点发生了质变。论文开篇直接摆出核心论点:
“Scaling the length of reasoning trajectories alone does not reliably improve performance. When intermediate steps are inaccurate or poorly grounded, longer interaction trajectories may instead accumulate noise, propagate errors, and ultimately degrade solution quality.”
翻译成人话:搜得越多≠答得越准。一个 Agent 在 200 步的推理链中,只要某一步搜错了关键词、误读了一条信息、在两个矛盾来源之间选错了,后续所有推理都像在流沙上盖楼。
论文用 MiroThinker-1.5 和 1.7-mini(同为 30B 参数)的对比直接佐证了这一点:1.7-mini 在五个基准上平均性能高 16.7%,但交互轮次反而少了 43%。HLE 任务上更极端——性能提升 17.4%,轮次减少 61.6%。
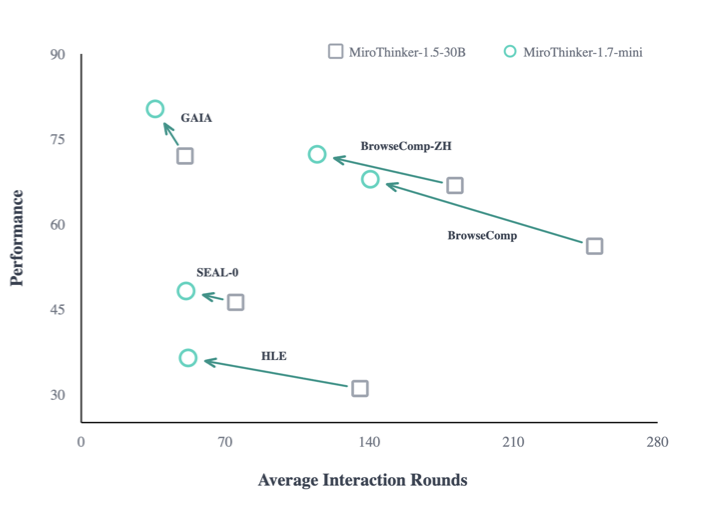
图1:性能 vs 平均交互轮次。箭头从 MiroThinker-1.5-30B 指向 1.7-mini(同为 30B),所有轨迹都向左上方移动——更高性能、更少轮次。
这就引出了论文的核心命题:改善长链推理的关键不在于延长交互链条,而在于让每一步交互更有效(effective interaction scaling)。
🏗️ 方法设计:四阶段训练 + 双重验证推理
基座选择:Qwen3 MoE
一个容易被忽略的关键信息:MiroThinker-1.7 不是从头预训练的,而是基于开源的 Qwen3 MoE 模型做继续训练。这意味着 MiroThinker-1.7-mini(30B 总参数,3B 激活参数)和 MiroThinker-1.7(235B 总参数)本质上是 MoE 架构。选择 MoE 作为基座可以在保持推理效率的同时获得大容量——3B 激活参数跑出的性能足以和很多 30B+ 稠密模型掰手腕。
四阶段训练流水线
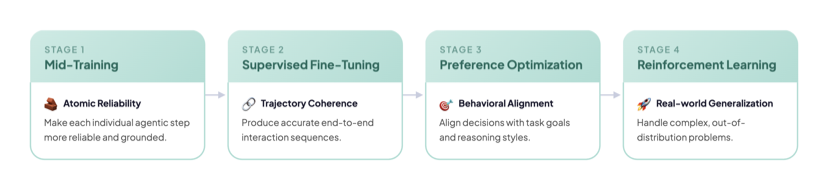
图2:MiroThinker-1.7 的四阶段训练流水线——Mid-Training 强化原子能力 → SFT 学习交互行为 → DPO 对齐偏好 → RL 促进创造性探索。
Stage 1:Agentic Mid-Training——在 SFT 之前就修地基
这是论文训练层面的核心创新。传统做法是直接在预训练模型上跑 SFT 教它做 Agent,但这相当于让一个从没做过研究的人直接照着操作手册上手——学到的只是"模仿步骤"而非"理解为什么这么做"。
Mid-Training 的目标是让模型在 SFT 之前就大量接触 Agent 场景的数据分布。具体拆成三类训练信号:
-
Agentic Planning Boosting:从用户 query 出发生成结构化计划 + 第一次工具调用。关键在于质量保障——设计了一个"planner-judge"过滤流水线,按问题类型(逻辑推理、多跳检索、直接检索)分别定义拒绝标准,拦截"直接复制 query 当搜索词"、“过度约束的搜索表达”、"过早猜测实体"等常见失败模式。被拒的生成最多重采样 K 次,仍不合格就直接丢弃。
-
Agentic Reasoning & Summarization:从成功的多轮 Agent 轨迹中抽取单步进行重写,目标不是监督整条轨迹,而是在给定完整前文(对话历史、先前工具调用、中间输出)的条件下,将某一步改写为更高质量的版本。训练时随机应用上下文摘要策略,让模型学会在不完整/动态变化的状态下进行推理,而非依赖完美的完整轨迹。
训练目标统一为标准的 next-token prediction,对第 kkk 步的目标输出 yky_kyk 做条件生成:
Lmid(θ)=−E(C<k,yk)∼Dmid[logπθ(yk∣C<k)]\mathcal{L}_{\text{mid}}(\theta) = -\mathbb{E}_{(C_{\lt k}, y_k) \sim \mathcal{D}_{\text{mid}}} \left[\log \pi_\theta(y_k \mid C_{\lt k})\right]Lmid(θ)=−E(C<k,yk)∼Dmid[logπθ(yk∣C<k)]
同时混入通用指令跟随和知识密集型数据,防止灾难性遗忘。
Stage 2:Agentic SFT——学习结构化交互行为
用专家轨迹(thought-action-observation 三元组序列)做标准的对话式 SFT。论文特别强调,原始轨迹哪怕是强 LLM 生成的,也充满噪声——重复内容、格式错误的工具调用、未定义工具的幻觉调用。因此在训练前做了大量规则过滤和清洗。
Stage 3:Agentic DPO——基于正确性的偏好对齐
收集 SFT 模型的成功/失败轨迹对,按答案正确性(而非人工启发式规则)做排序。论文明确指出不施加刚性结构约束(如固定规划长度、步骤数、推理模板),因为这些约束会引入系统性偏差。偏好信号只看一件事:最终答案对不对。
DPO 损失加上偏好轨迹的辅助 SFT 损失来稳定训练:
LPO(θ)=E[LDPO]+λLSFT(+)(θ)\mathcal{L}_{\text{PO}}(\theta) = \mathbb{E}[\mathcal{L}_{\text{DPO}}] + \lambda \mathcal{L}_{\text{SFT}}^{(+)}(\theta)LPO(θ)=E[LDPO]+λLSFT(+)(θ)
对 mini 版本还用了偏好蒸馏——从更强模型转移对齐信号。
Stage 4:Agentic RL——GRPO 强化学习
用 GRPO(Group Relative Policy Optimization)做在线 RL,每批 rollout 只做一步策略梯度更新。这里有两个工程亮点:
- 优先级调度:长尾 rollout 容易被排除在训练分布之外,引入优先级策略确保困难样本尽早纳入训练
- 熵控制:对负 rollout 中的低概率 token 施加额外的 KL 惩罚,防止策略熵过早坍塌
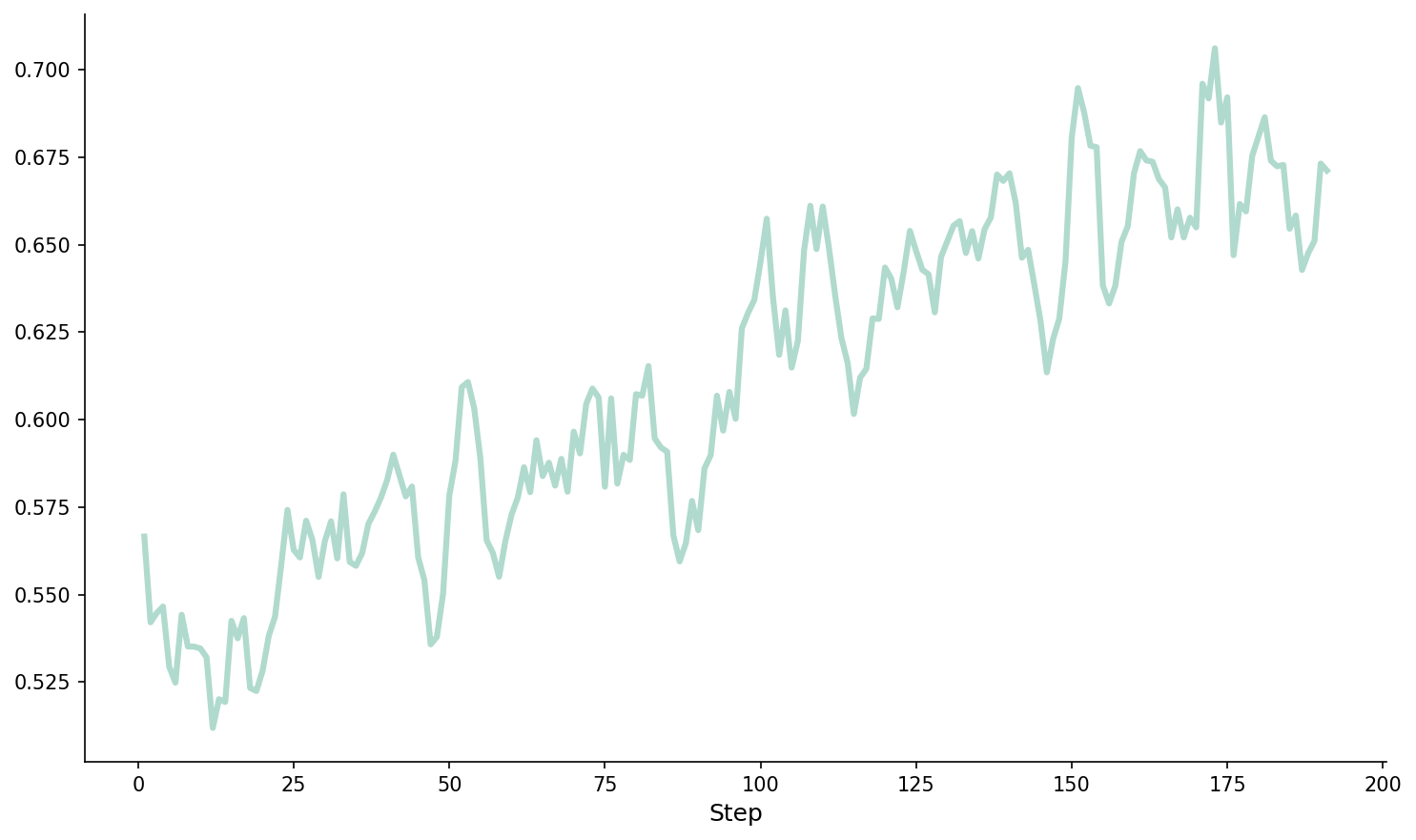
图3:MiroThinker-1.7-mini 的 GRPO RL 训练动态——左图为训练奖励随步数的变化,右图为 BrowseComp-200 验证集准确率。
Heavy-Duty 推理模式:Local + Global 双重验证
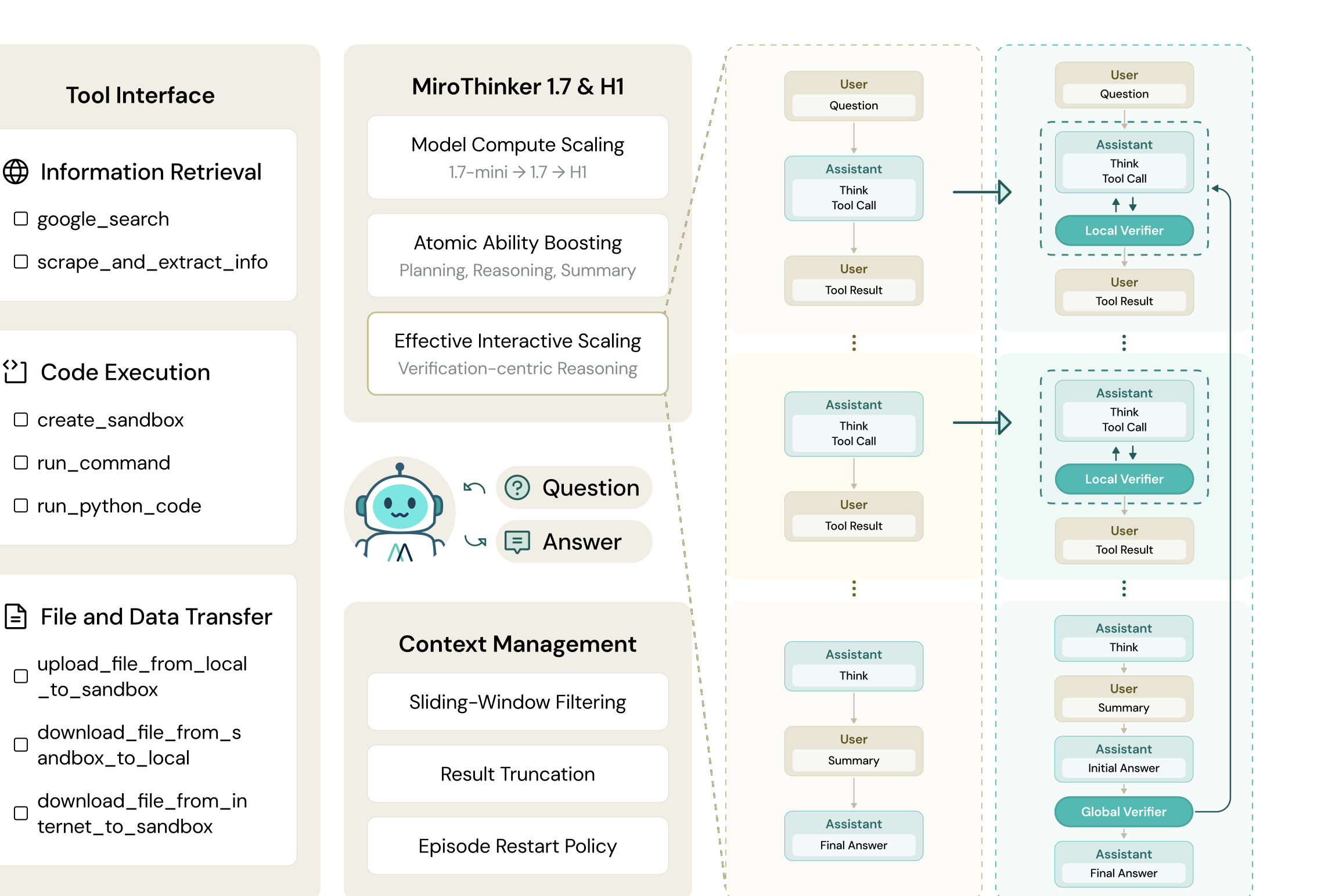
图4:MiroThinker-1.7 & H1 的整体架构——左侧是标准 ReAct 循环(搜索→推理→工具调用),右侧是 H1 的验证增强模式(Local Verifier 审计每步决策,Global Verifier 全局复审证据链)。
Local Verifier 解决的问题是:标准 ReAct 范式下,Agent 天然沿着最高概率路径走。遇到难题时,这种概率偏差会把 Agent 困在习惯性思维里。Local Verification 的作用是"逼"Agent 探索那些它本不会选择的路径,从环境中主动收集反馈——鼓励更充分的解空间搜索,而非反复确认模型自身的偏好。
Global Verifier 利用了一个被长期忽视的不对称性:验证比生成容易得多。Global Verification 在可控的算力预算内组织完整的证据链,如果证据不足就要求 Agent 重新采样或补全推理链,最终选择由最完整、最可靠证据支撑的答案。
🔧 Agent 工作流:滑动窗口 + 多 Episode 重启
MiroThinker-1.7 的 Agent 框架采用双循环结构:外层 Episode 循环处理轨迹级重启,内层 Step 循环驱动推理-工具调用-观察。
一个关键的工程设计是滑动窗口上下文管理:只保留最近 K=5 步的完整 observation,更早的 observation 被遮蔽(但 thought 和 action 全程保留)。这背后的经验发现是:Agent 在第 t 步的决策主要依赖最近的观察;保留远处输出收益递减,代价却是大量 token 消耗。
当一个 Episode 耗尽最大轮次 TmaxT_{\max}Tmax 仍没产出有效答案时,Agent 会丢弃所有先前状态、回到原始 query 重新开始——干净重启避免了退化上下文的累积偏差。最后一个 Episode 不再延迟答案生成:即使再次达到 TmaxT_{\max}Tmax,也会强制输出最佳中间答案。
工具分三类:信息检索(google_search + scrape_and_extract_info)、代码执行(E2B Linux 沙箱)、文件传输。检索工具用多级回退管线保障鲁棒性,抓取的原始内容由轻量 LLM 蒸馏为任务相关的摘要,避免把大段网页塞进上下文。
🧪 数据工程:双管线 QA 合成
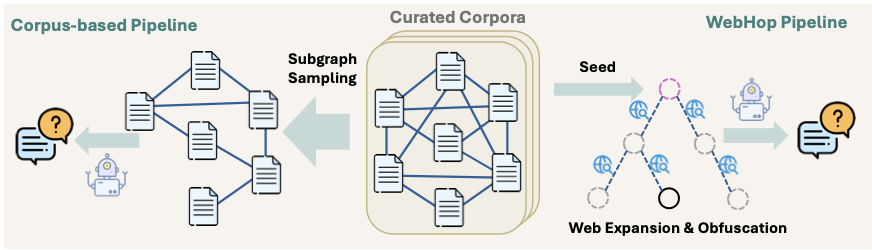
图5:双管线 QA 合成框架——左侧 Corpus-based Pipeline 从文档子图批量生成,保证广度;右侧 WebHop Pipeline 构建带验证的推理树,保证深度和难度可控。
训练数据的质量直接决定了 Agent 的上限。论文设计了两条互补的 QA 合成管线:
Corpus-based Pipeline 从高度互链的文档(Wikipedia、OpenAlex)构建子图,提取跨文档事实,用强 LLM 合成多跳 QA。优势是高吞吐和广覆盖,劣势是难度控制是隐式的。
WebHop Pipeline 用三个机制补足短板:
- 构建以答案实体为根的有向推理树,树深控制推理跳数
- 通过实时网络搜索扩展知识分布(排除百科类来源以引入真正新知识)
- 分层可解性验证——对每个父子关系验证"知道子节点能否缩小父节点候选范围",对根实体验证"能否从一跳邻居唯一确定"
训练数据还做了难度自适应过滤:弱 Agent 能解的题分配给 SFT 阶段,强 Agent 也解不了的题留给 RL 阶段——形成课程学习式的难度梯度。
📊 实验结果:数字拆解
主表:Agentic 基准
| 模型 | BrowseComp | BrowseComp-ZH | HLE | GAIA | xbench-DS | SEAL-0 | DeepSearchQA |
|---|---|---|---|---|---|---|---|
| OpenAI GPT-5 | 54.9 | 65.0 | 35.2 | 76.4 | 75.0 | 51.4 | 79.0 |
| OpenAI GPT-5.4 | 82.7 | — | 52.1 | — | — | — | — |
| Gemini-3.1-Pro | 85.9 | — | 51.4 | — | — | — | — |
| Claude-4.6-Opus | 84.0 | — | 53.1 | — | — | — | 91.3 |
| Seed-2.0-Pro | 77.3 | 82.4 | 54.2 | — | — | 49.5 | 77.4 |
| Kimi-K2.5 | 78.4 | — | 50.2 | — | 46.0 | 57.4 | 77.1 |
| DeepSeek-V3.2 | 67.6 | 65.0 | 40.8 | — | — | 49.5 | 60.9 |
| GLM-5.0 | 75.9 | 72.7 | 50.4 | — | — | — | — |
| Qwen3.5-397B | 78.6 | 70.3 | 48.3 | — | — | 46.9 | — |
| Tongyi-DR-30B | 43.4 | 46.7 | 32.9 | 70.9 | 55.0 | — | — |
| MiroThinker-1.7-mini | 67.9 | 72.3 | 36.4 | 80.3 | 57.2 | 48.2 | 67.9 |
| MiroThinker-1.7 | 74.0 | 75.3 | 42.9 | 82.7 | 62.0 | 53.0 | 72.1 |
| MiroThinker-H1 | 88.2 | 84.4 | 47.7 | 88.5 | 72.0 | 61.3 | 80.6 |
几个关键数据点:
- BrowseComp 88.2%:超越 Gemini-3.1-Pro(85.9)和 Claude-4.6-Opus(84.0),拿到搜索 Agent 赛道的绝对王座。BrowseComp 由 OpenAI 在 2025 年 4 月推出,包含 1266 个极高难度网页检索问题——GPT-4o 在上面只有 0.6%,OpenAI 自己的 Deep Research 也只有 51.5%
- GAIA 88.5%:超越第二名 OpenAI GPT-5(76.4)整整 12.1 个百分点。GAIA 是 Meta+HuggingFace+AutoGPT 联合推出的通用 AI 助手基准,466 个现实世界问题,被公认为 Agent 领域最权威的综合评测之一
- 1.7-mini 只有 3B 激活参数,就在 BrowseComp-ZH 和 GAIA 上超越了 GPT-5 和 DeepSeek-V3.2——这验证了 MoE + 高质量训练数据的组合能以极低成本打出高性能
不过 HLE(47.7)没能拿到最高分——Seed-2.0-Pro(54.2)和 Claude-4.6-Opus(53.1)都更高。HLE 是 Scale AI 联合全球专家出的"人类终极考试",3000 道题涵盖 100+ 学科,需要纯粹的推理和深度知识,搜索能力在这里的加成有限。
专业领域基准
| 模型 | FrontierSci-Olympiad | SUPERChem | FinSearchComp | MedBrowseComp |
|---|---|---|---|---|
| GPT-5.2-high | 77.1 | 58.0 | 73.8 | — |
| Gemini-3-Pro | 76.1 | 63.2 | 52.7 | — |
| Seed-2.0-Pro | 74.0 | 53.0 | 70.2 | — |
| Claude-4.5-Opus | 71.4 | 43.2 | 66.2 | — |
| MiroThinker-1.7-mini | 67.9 | 36.8 | 62.6 | 48.2 |
| MiroThinker-1.7 | 71.5 | 42.1 | 67.9 | 54.2 |
| MiroThinker-H1 | 79.0 | 51.3 | 73.9 | 56.5 |
FrontierSci-Olympiad 79.0 超越 GPT-5.2-high(77.1),FinSearchComp 73.9 和 GPT-5.2-high 基本持平。MedBrowseComp 56.5 是目前唯一公开的测评结果。SUPERChem 上 Gemini-3-Pro(63.2)领先——化学推理对检索依赖较低,纯推理能力更重要。
Local Verifier 的量化贡献
论文给出了 H1 验证机制的消融数据——这是整篇论文最有说服力的定量分析:
| 模型 | BrowseComp 难题集 Pass@1 | 交互步数 |
|---|---|---|
| MiroThinker-1.7 | 32.1 | 1185.2 |
| H1 w/ Local Verifier Only | 58.5(+26.4) | 210.8(-974.4) |
在 BrowseComp 中 MiroThinker-1.7 频繁失败的 295 道难题上,仅加 Local Verifier 就将准确率从 32.1% 提升到 58.5%,同时交互步数从 1185 锐减到 211——只有原来的 1/6。步数减少不是设计目标,而是 Local Verification 的自然副产物:当每步决策更可靠时,不需要靠暴力试错来碰运气。
Token Scaling 曲线
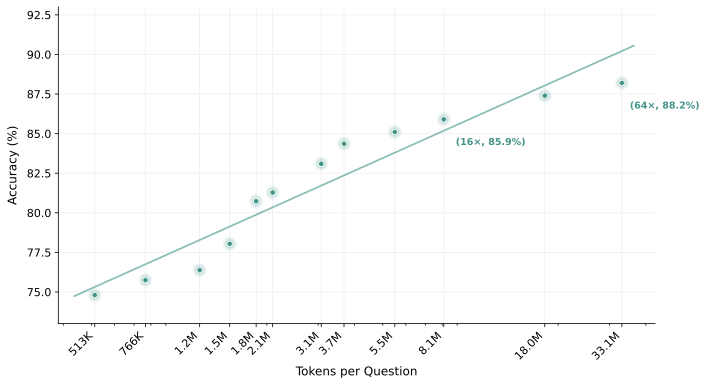
图6:MiroThinker-H1 在 BrowseComp 上的 Token Scaling 曲线——16× 算力预算(所有基准的默认设置)达到 85.9,扩展到 64× 进一步提升到 88.2。
Global Verifier 配合算力扩展呈现近似对数线性的增长趋势。88.2% 这个数字是在 64× 算力预算下拿到的——这意味着 H1 的"重型"模式确实需要更多计算。
长报告生成
| 模型 | Report | Factuality | Overall |
|---|---|---|---|
| ChatGPT-5.4 Deep Research | 76.4 | 85.5 | 81.0 |
| MiroThinker-H1 | 76.8 | 79.1 | 78.0 |
| Gemini-3.1-Pro Deep Research | 72.3 | 73.3 | 72.8 |
| Kimi-K2.5 Deep Research | 76.0 | 64.1 | 70.0 |
| GLM-5 Agent | 66.0 | 72.7 | 69.4 |
MiroThinker-H1 在报告质量维度拿到全场最高(76.8),但事实性还和 ChatGPT-5.4 有差距(79.1 vs 85.5)。综合评分 78.0 仅次于 ChatGPT-5.4 的 81.0——对于一个开源基座 + 四阶段训练的模型来说,这个成绩相当强。
🔬 技术演进:从"搜得更多"到"搜得更准"
把 MiroThinker 的版本线串起来,核心理念的演变一目了然:
| 版本 | 时间 | 核心命题 | 关键参数 |
|---|---|---|---|
| v1.0 | 2025.08 | 交互深度 Scaling | 256K 上下文、600 次工具调用 |
| v1.5 | 2026.01 | 小模型通过深度交互碾压大模型 | 30B 打赢 1T 参数模型,$0.07/次 |
| v1.7 | 2026.03 | 每步交互的可靠性 | Agentic Mid-Training,4 阶段流水线 |
| H1 | 2026.03 | 推理过程的可验证性 | Local+Global Verifier,BrowseComp 88.2% |
一个有趣的变化:v1.0 支持 600 次工具调用,到了 v1.7 降到了最多 300 次。更少但更可靠的交互,换来了更好的结果——这恰好是论文"effective interaction scaling"核心论点的直接体现。
🤔 批判性审视
H1 不开源,验证机制是黑箱
MiroThinker-1.7(235B 和 30B/3B-active)是开源的,但 H1 是闭源的。论文对 Local 和 Global Verifier 的描述停留在概念层面:Local Verification “prompting the agent to explore more thoroughly”,Global Verification “organizes the full chain of evidence”——但具体怎么实现?是 prompt engineering?独立的 verifier 模型?RL 阶段引入的验证奖励?一概不提。
如果 Local Verification 只是在 system prompt 里加了一句"请检查你上一步的推理",那它和普通的 self-reflection 没本质区别;如果训练了独立的 verifier 模型或在 RL 阶段用了验证信号做奖励,技术含量就完全不同。论文不给细节,外人无法判断它在光谱的哪一端。
对比同期的 OpenSeeker(完全开源训练数据 + 模型),MiroThinker 的开源策略明显更保守——开源基础版本,核心竞争力留在闭源产品里。
验证的算力开销没有坦诚讨论
BrowseComp 88.2% 是在 64× 算力预算下拿到的,16× 预算只有 85.9。这意味着 H1 的"重型"模式需要付出显著的计算代价。论文说了句"不卷速度卷验证",但对用户来说,一个 10 分钟返回答案的 Agent 和一个可能要 30-60 分钟但准确率高 3% 的 Agent,选哪个取决于场景。论文没有系统性地讨论这个权衡。
基准覆盖偏向搜索类任务
所有基准——BrowseComp、GAIA、HLE、DeepSearchQA、SEAL-0 以及四个领域基准——全部偏向"搜索 + 长链推理"。这恰好是 MiroThinker 的绝对强项。
有没有测 SWE-Bench(代码修复)?有没有测 MATH-500(纯数学推理)?有没有测 MT-Bench(多轮对话质量)?论文一个都没报。在自己最擅长的赛道上跑分,说服力打折扣。
42 位作者 vs 技术深度的薄度
42 人署名的技术报告,核心创新点(Agentic Mid-Training 和 Verification)在实现层面的描述都偏概要。Mid-Training 具体用了多少数据、训练了多少步?Verifier 的判断标准怎么来的?论文留下了大量空白。
Heavy-Duty Reasoning 部分的 tts.tex 整个文件只有 24 行——这是整篇论文的核心卖点,却只用了不到一页纸来描述。
📊 与同类工作对比
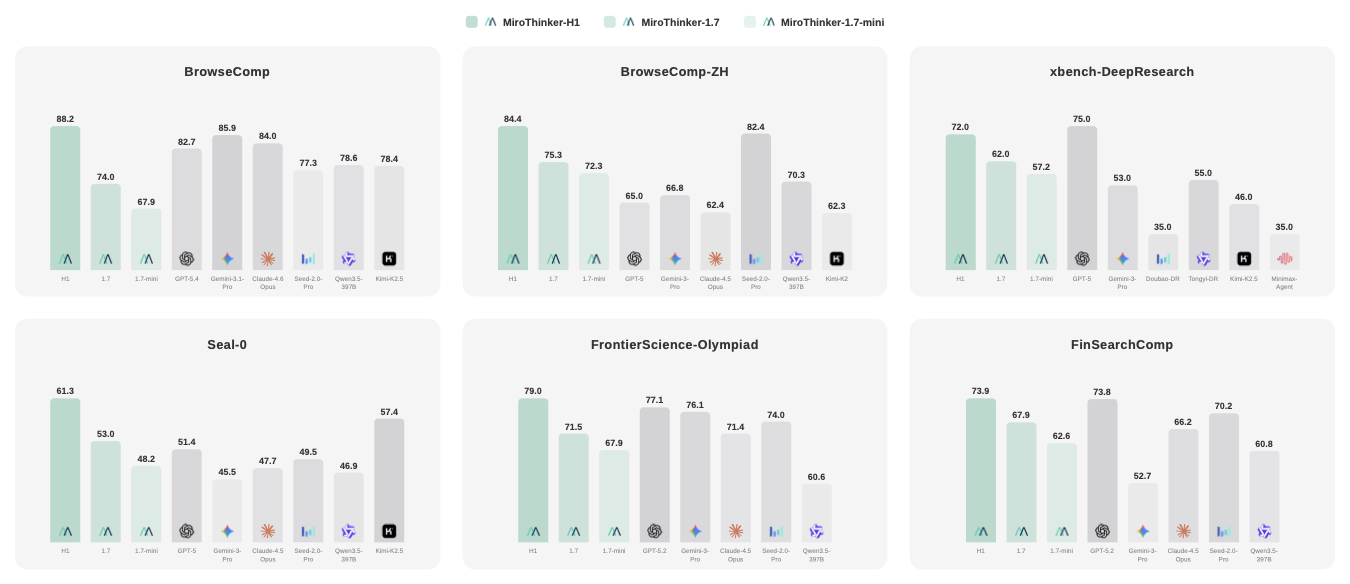
图7:MiroThinker 与 SOTA Agent 和基础模型的性能对比总览。
| 维度 | MiroThinker-H1 | OpenAI GPT-5/DR | Gemini-3.1-Pro | OpenSeeker |
|---|---|---|---|---|
| BrowseComp | 88.2% | 54.9/51.5 | 85.9 | — |
| GAIA | 88.5% | 76.4 | — | — |
| 开源基座模型 | ✅(235B/30B MoE) | ❌ | ❌ | ✅(30B) |
| 开源训练数据 | 部分(MiroVerse) | ❌ | ❌ | ✅ |
| 核心技术开源 | ❌(H1 闭源) | ❌ | ❌ | ✅ |
| 验证机制 | ✅ Local+Global | 未公开 | 未公开 | ❌ |
💡 工程启示
Mid-Training 作为独立训练阶段值得认真对待。在 SFT 之前就让模型接触"规划→推理→工具调用→摘要"的数据模式,后续的 SFT 和 RL 能学到更深层的任务理解,而不只是行为模仿。MiroTrain 仓库公开了基于 MiroVerse 数据集的 SFT 和 DPO 配置,可直接参考。
工具调用数不是越多越好。v1.0 支持 600 次,v1.7 砍到 300 次但性能更强。Agent 的性能瓶颈不在"搜得够不够多",而在每次搜索的决策质量。
"验证比生成容易"这个不对称性值得利用。即使没有 H1 那么复杂的机制,在自己的 Agent pipeline 里加入"中间步骤自查"逻辑——比如每 5 步暂停一下检查前面的推理是否一致——就可能带来可观的准确率提升。
MoE + 高质量数据的组合效率惊人。3B 激活参数的 mini 版本就能在 GAIA 上拿到 80.3%,超越了很多 30B+ 稠密模型。预算有限的开发者不需要追求最大参数模型。
🔗 相关资源
- 论文:https://arxiv.org/abs/2603.15726
- GitHub:https://github.com/MiroMindAI/MiroThinker
- 产品体验:https://dr.miromind.ai/
- 相关基准:BrowseComp(OpenAI, 2025.04)、GAIA(Meta+HuggingFace, 2023.11)、HLE(Scale AI, 2025.01)
- 同赛道参考:OpenSeeker(完全开源搜索 Agent)、Tongyi-DeepResearch-30B、WebExplorer-8B-RL
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)