不改模型参数,准确率翻倍:Memento-Skills 让 Agent 自己设计 Agent
不改模型参数,准确率翻倍:Memento-Skills 让 Agent 自己设计 Agent
论文标题:Memento-Skills: Let Agents Design Agents
作者团队:Huichi Zhou, Siyuan Guo, Anjie Liu 等 17 人(Memento-Team)
机构:University College London、吉林大学、港科大(广州)、AI Lab, The Yangtze River Delta
发布时间:2026 年 3 月 19 日
论文地址:https://arxiv.org/abs/2603.18743
代码地址:https://github.com/Memento-Teams/Memento-Skills
当前 LLM Agent 面临一个根本性矛盾——模型参数在部署后冻结不变,却要应对千变万化的真实任务。Memento-Skills 提出了一条不修改模型权重的持续学习路径:让 Agent 在执行任务的过程中自主创建、测试、优化可复用的"技能文件夹",通过 Read-Write 反射学习循环不断扩展技能库。在 GAIA 和 Humanity’s Last Exam 两个基准上,该系统分别实现了 26.2% 和 116.2% 的相对准确率提升,技能库从 5 个原子技能自动增长到 235 个,且全程零梯度更新。
1. 核心问题:冻结的大脑,流动的任务
现代 LLM 的部署范式存在一个不可回避的事实:参数 θ\thetaθ 在预训练之后就被冻结了。无论是 SFT、RLHF 还是 DPO,本质上都是在部署前修改 θ\thetaθ。一旦上线,Agent 面对新任务只能依赖 prompt 和上下文窗口中的信息——它无法从自己的失败中学习。
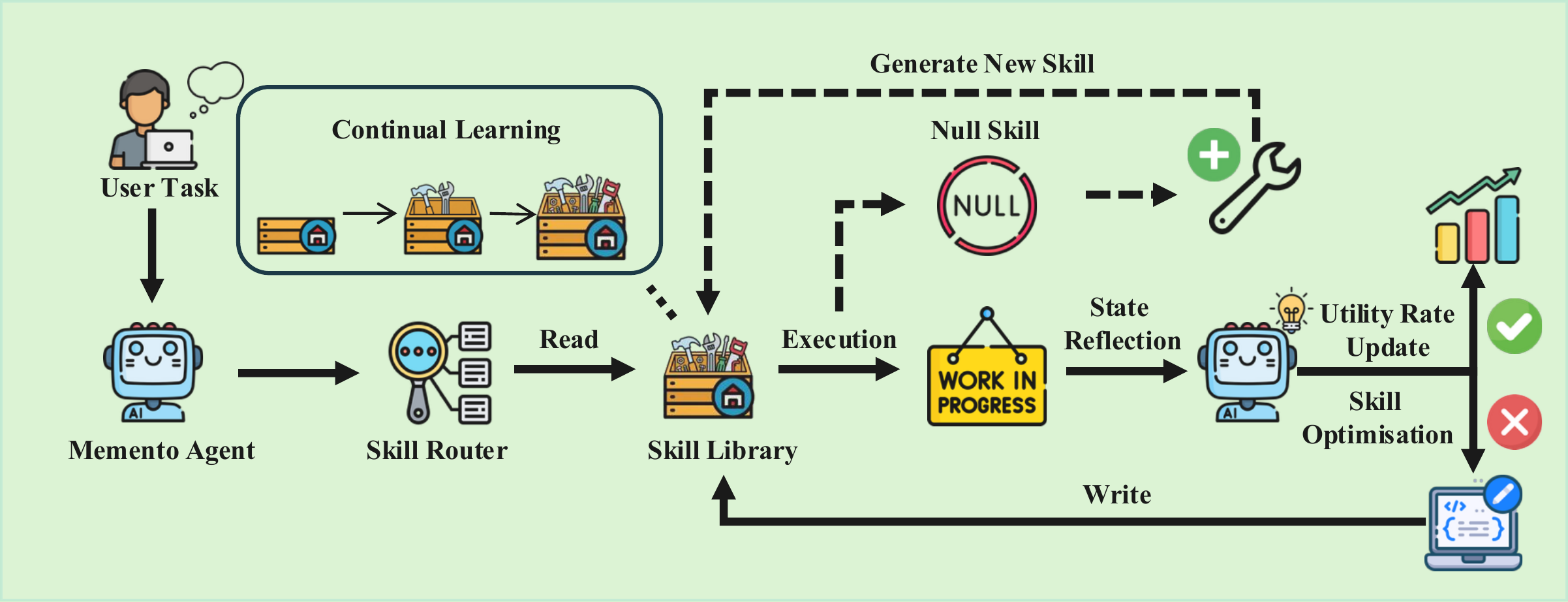
图1:Read-Write 反射学习循环。用户任务进入后,Agent 从技能库中 Read 匹配的技能,执行后根据反馈进行 Reflection,再 Write 回技能库完成技能优化。整个过程零参数更新。
这就好比一个学生参加考试:预训练阶段读了海量教材,微调阶段做了几千道练习题,但考场上遇到新题型时——他不能翻书,也不能回顾刚才做错的题。Memento-Skills 的核心洞见是:如果 θ\thetaθ 固定不变,那么所有的适应都必须来自输入端——prompt、上下文、或者记忆。
Memento-Skills 提出的"部署时学习"范式与传统方法的对比:
| 范式 | 学习对象 | 学习时机 | 计算代价 |
|---|---|---|---|
| 预训练 | 模型权重 θ\thetaθ | 部署前 | ~万亿 token |
| 微调 | 模型权重 θ\thetaθ | 部署前 | ~千级样本 |
| 部署时学习 | 外部技能库 M\mathcal{M}M | 每次交互 | 零梯度更新 |
2. 技术框架:Read-Write 反射学习
2.1 状态化反射决策过程
Memento-Skills 的理论根基来自 Memento 2 中的 Stateful Reflective Decision Process(SRDP)。核心思想是通过引入可增长的外部技能记忆 Mt\mathcal{M}_tMt,将状态重新定义为 xt:=(st,Mt)x_t := (s_t, \mathcal{M}_t)xt:=(st,Mt),从而恢复马尔可夫性质。
Agent 的策略被表示为:
πμ(a∣s,Mt)=∑c∈Mtμ(c∣s,Mt)⋅pLLM(a∣s,c)\pi^{\mu}(a \mid s, \mathcal{M}_t) = \sum_{c \in \mathcal{M}_t} \mu(c \mid s, \mathcal{M}_t) \cdot p_{\text{LLM}}(a \mid s, c)πμ(a∣s,Mt)=c∈Mt∑μ(c∣s,Mt)⋅pLLM(a∣s,c)
其中 pLLMp_{\text{LLM}}pLLM 是冻结的 LLM 决策核心,ccc 是从技能库中检索到的技能,μ\muμ 是检索策略。关键在于——LLM 不变,但策略随着技能库的演化而改变。就像 RPG 游戏中角色等级不变,但装备越来越好。
2.2 五步循环:Observe → Read → Act → Feedback → Write
整个系统的核心运转机制可以用一个紧凑的循环来描述:
第一步 Observe:接收用户任务 qtq_tqt,构造增强输入 xt=(qt,Tt)x_t = (q_t, \mathcal{T}_t)xt=(qt,Tt)
第二步 Read——技能选择:Skill Router 从技能库中检索最相关的技能 ctc_tct。如果没有匹配的技能且启用了 CreateOnMiss,系统会自动生成一个新技能。
第三步 Execute:用检索到的技能引导 LLM 执行多步工作流 at←LLM(xt,ct)a_t \leftarrow \text{LLM}(x_t, c_t)at←LLM(xt,ct)
第四步 Feedback:一个 LLM Judge 对执行结果进行评判 rt←Judge(qt,at,at⋆)r_t \leftarrow \text{Judge}(q_t, a_t, a_t^{\star})rt←Judge(qt,at,at⋆)
第五步 Write——反射更新:这是最关键的一步,包含三个子操作:
- 效用更新:Ut+1(ct)←nsucc(ct)nsucc(ct)+nfail(ct)U_{t+1}(c_t) \leftarrow \frac{n_{\text{succ}}(c_t)}{n_{\text{succ}}(c_t) + n_{\text{fail}}(c_t)}Ut+1(ct)←nsucc(ct)+nfail(ct)nsucc(ct)
- Tip 记忆积累:将通用经验写入 tip 库
- 技能进化:当某个技能的效用分数低于阈值 δ\deltaδ 时,系统会进行技能发现(生成新技能替代)或技能优化(原地修补)
这个循环的一个重要设计是单元测试门控——所有技能变异都会自动生成合成测试用例,验证通过才被持久化,否则回滚。这防止了"改了新 bug"的连锁退化。

图2:技能进化组件流程。任务输入 → 执行 → Judge 判定 → 正确则保存结果;错误则生成反馈进入 optimizer → 单元测试门控 → 通过则更新,失败则回滚。
2.3 技能的具体形态
每个技能不是一段简单的文本提示,而是一个完整的技能文件夹,包含:
SKILL.md:声明式规范文件,定义技能的目标、适用场景、工作流步骤- 辅助脚本:可执行的 Python 代码
- 提示模板:结构化 prompt
这种设计使得 Write 操作不只是追加日志,而是直接改写策略本身——修改代码、调整 prompt、更新规范。策略被物化并存储在技能文件夹中。
3. 行为对齐的技能路由:不是"语义最近"而是"执行最佳"
3.1 传统语义检索的失败
一个容易被忽视但至关重要的技术点是技能路由。论文发现,纯语义检索(BM25 或 Qwen-Embedding)在技能选择场景下表现很差。原因在于:很多技能共享相同的领域术语,但执行策略完全不同。高余弦相似度不等于高行为相关性。
3.2 InfoNCE + 单步离线 RL
Memento-Skills 将路由建模为一步 MDP 的离线 RL 问题:
- 状态 qqq:用户查询
- 动作 ddd:选择的技能
- 奖励 r(q,d)r(q, d)r(q,d):该技能是否成功执行了该任务
学到的 score 函数 s(d,q)=e(d)⊤u(q)s(d, q) = \mathbf{e}(d)^{\top}\mathbf{u}(q)s(d,q)=e(d)⊤u(q) 被解释为 soft Q-function,产生 Boltzmann 路由策略:
πθ(d∣q)=exp(Qθ(q,d)/τ)∑d′exp(Qθ(q,d′)/τ)\pi_{\theta}(d \mid q) = \frac{\exp(Q_{\theta}(q, d)/\tau)}{\sum_{d'} \exp(Q_{\theta}(q, d')/\tau)}πθ(d∣q)=∑d′exp(Qθ(q,d′)/τ)exp(Qθ(q,d)/τ)
训练使用多正例 InfoNCE 损失,在约 8k 个技能和合成查询对上进行训练。
3.3 路由效果
| 指标 | BM25 | Qwen3-emb-0.6B | Memento-Qwen |
|---|---|---|---|
| Recall@1 | 0.32 | 0.54 | 0.60 |
| Recall@5 | 0.47 | 0.79 | 0.82 |
| Recall@10 | 0.53 | 0.86 | 0.90 |
| Route Hit Rate | 0.29 | 0.53 | 0.58 |
| Judge Success Rate | 0.50 | 0.79 | 0.80 |
Recall@1 从 BM25 的 0.32 提升到 0.60,相对提升 87.5%。端到端的 Judge Success Rate 从 0.50 提升到 0.80,表明行为对齐的路由确实转化为了实际执行效果的提升。
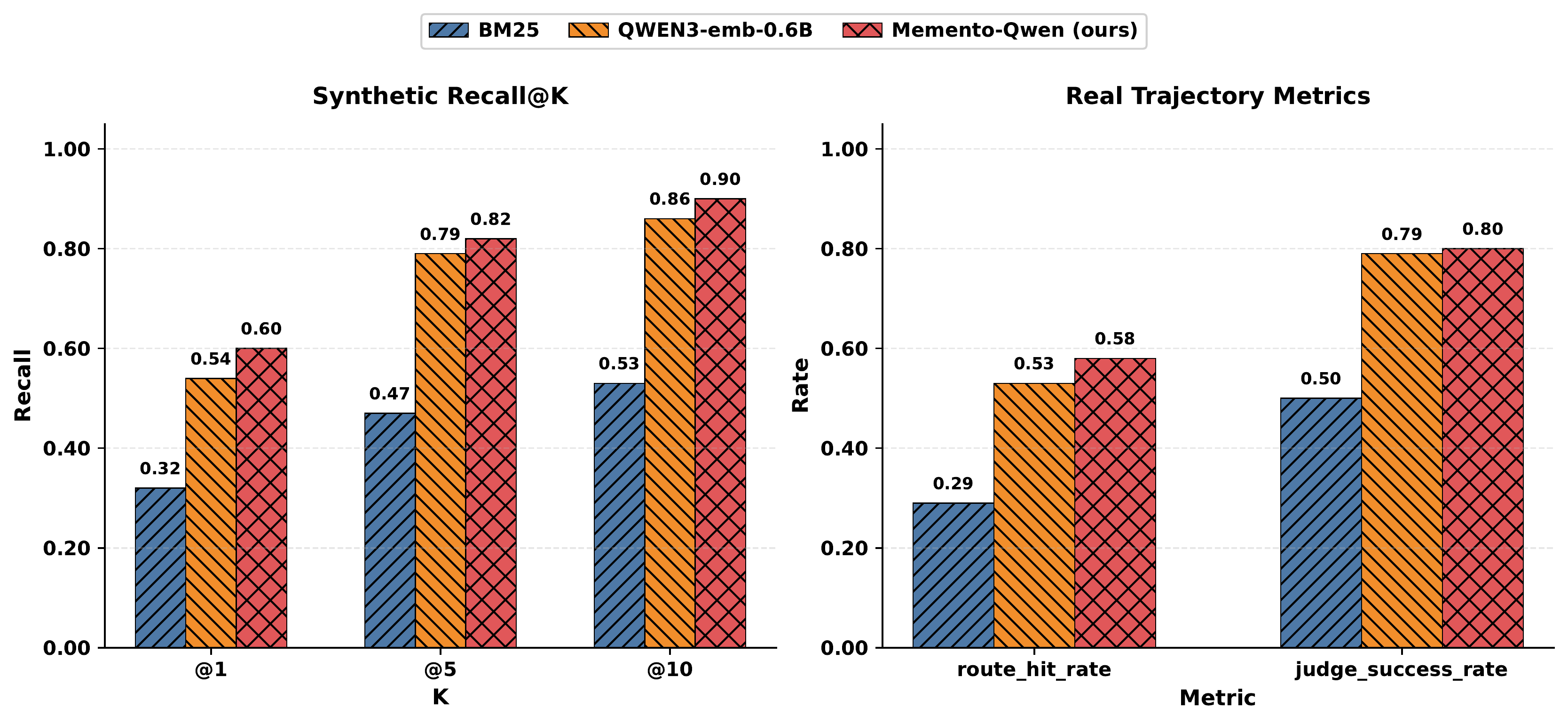
图3:技能路由方法对比。左侧为合成数据上的 Recall@K,右侧为真实轨迹上的 route_hit_rate 和 judge_success_rate。Memento-Qwen 在各指标上全面领先 BM25 和 Qwen3-emb。
4. 实验:两大基准上的自进化验证
所有实验均使用 Gemini-3.1-Flash 作为底层 LLM。
4.1 GAIA 基准
数据规模:165 道题,100 训练 + 65 测试。涵盖多步推理、多模态、Web 浏览等。
训练过程中的进化:
| 轮次 | Level 1 | Level 2 | Level 3 | 总体 |
|---|---|---|---|---|
| Round 0(初始) | 86.5% | 58.0% | 43.5% | 65.1% |
| Round 1 | 93.1% | 74.4% | — | — |
| Round 3 | 94.4% | 75.7% | 65.1% | 91.6% |
训练成功率从 65.1% 爬升到 91.6%。
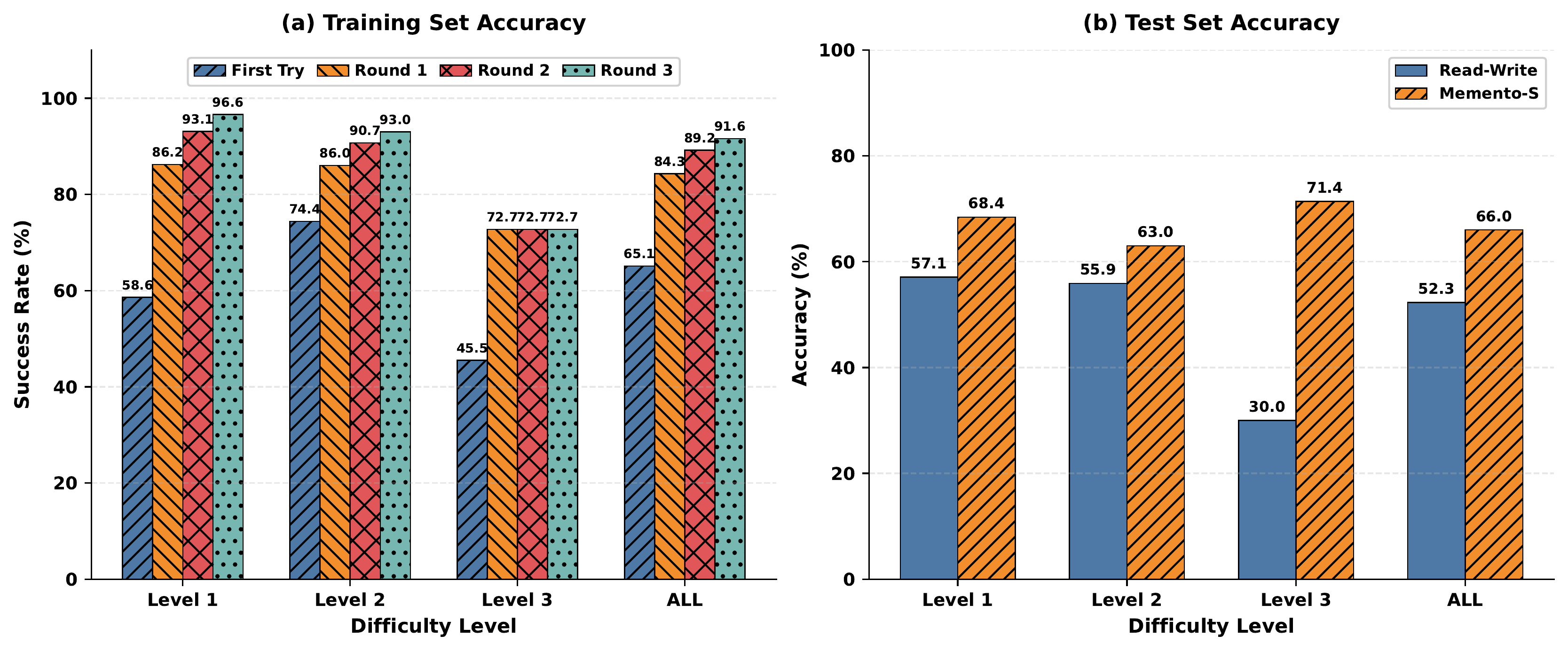
图4:GAIA 基准上的训练集(左)和测试集(右)准确率。训练集上 Level 1 达到 96.6%,测试集上 Memento-Skills(蓝色)在 Level 3 上相对 Read-Write 基线(灰色)提升最为显著(30.0% → 52.3%)。
测试集表现:
| 方法 | Level 1 | Level 2 | Level 3 | 总体 |
|---|---|---|---|---|
| Read-Write(无技能进化) | 68.4% | 57.1% | 30.0% | 52.3% |
| Memento-Skills | 63.0% | 55.9% | 52.3% | 66.0% |
总体准确率从 52.3% 提升到 66.0%,绝对提升 13.7 个百分点。一个有趣的发现是:Level 3(最难)的提升最大,从 30.0% 跃升至 52.3%,说明技能进化对复杂任务的增益最为显著。
但也暴露了一个问题:GAIA 上的跨任务迁移有限。训练集上 91.6% 的成功率与测试集 66.0% 之间存在明显差距,案例分析表明大部分训练中优化的技能在测试时从未被触发——GAIA 题目间的推理模式差异太大。
4.2 Humanity’s Last Exam 基准
数据规模:从 2500 道题中采样,788 训练 + 342 测试,覆盖 8 个学科领域。
训练过程中的进化:
| 轮次 | 总体准确率 |
|---|---|
| R0 | 30.8% |
| R1 | ~42% |
| R2 | ~49% |
| R3 | 54.5% |
四轮训练后,总体成功率从 30.8% 提升到 54.5%,人文和生物学科获益最大,分别达到 66.7% 和 60.7%。而工程学科在 42.1% 时趋于饱和,暗示某些领域仅靠技能抽象难以覆盖。
测试集表现:
| 方法 | Bio. | Chem. | CS | Eng. | Human. | Math | Other | Phy. | 总体 |
|---|---|---|---|---|---|---|---|---|---|
| Read-Write | 13.6% | 13.9% | 12.0% | 37.0% | 23.7% | 15.4% | 19.0% | — | 17.9% |
| Memento-Skills | 57.4% | 41.0% | 30.8% | 41.3% | 23.7% | 10.0% | 25.9% | 16.9% | 38.7% |
总体从 17.9% 提升到 38.7%,相对提升 116.2%,准确率翻倍有余。生物学科的提升尤为惊人:从 13.6% 到 57.4%。这验证了论文的核心假说——当训练和测试共享结构化的学科分类时,技能迁移效果最强。
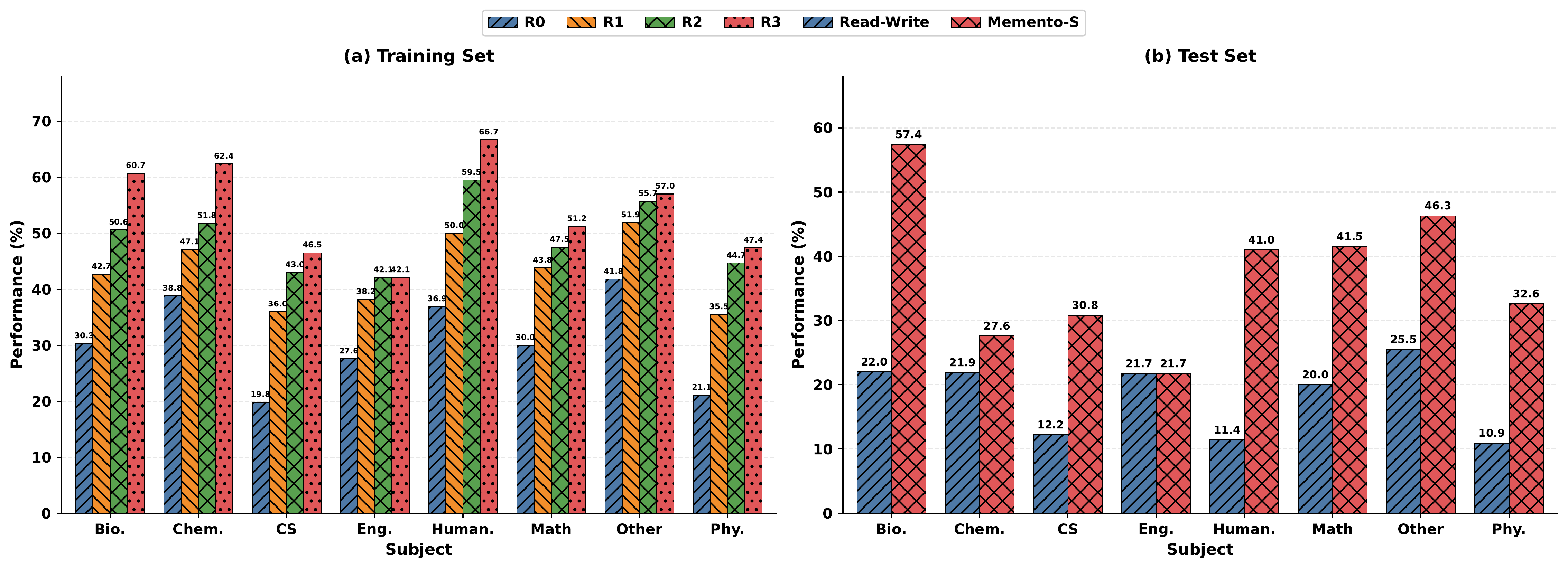
图5:Humanity’s Last Exam 分学科的训练集(左)和测试集(右)表现。Human. 和 Chem. 学科在训练中提升最大(分别达 66.7% 和 62.4%),Bio. 在测试集上以 57.4% 领先。
4.3 技能库增长可视化
t-SNE 投影显示:
- GAIA 学习后:技能库从 5 个原子技能增长到 41 个
- HLE 学习后:技能库扩展到 235 个,形成 8 个语义簇(Search/Web 48 个, Quantum/Physics 47 个, Math/Chemistry 44 个, Code/Text 38 个等)
技能以语义连贯的聚类方式组织,每个簇对应一种领域能力,这种结构与 HLE 的 8 个学科类别高度吻合。
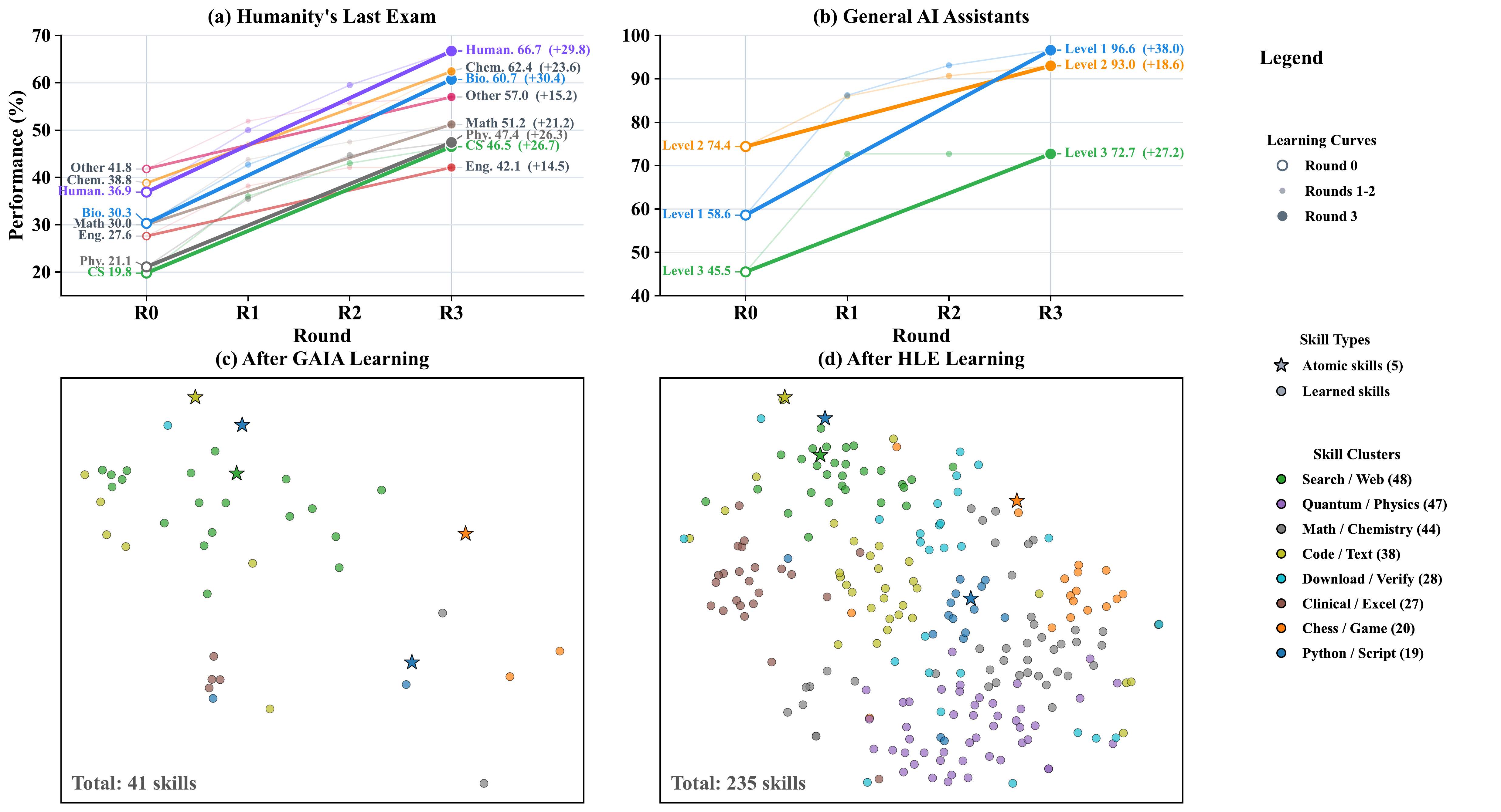
图6:上排为 HLE(左)和 GAIA(右)的逐轮学习曲线,下排为 GAIA 学习后(41 个技能)和 HLE 学习后(235 个技能)的 t-SNE 技能簇分布。星形标记为 5 个原子技能,圆点为自动学习的技能,颜色区分 8 大语义簇。
5. 理论保障:收敛性分析
论文给出了性能差距的分解公式(来自 Memento 2 的推论 15):
sups∣Vπ∗(s)−VπM(s)∣≤2Rmax(1−γ)2(εLLM(rM)+δM)\sup_s |V^{\pi^*}(s) - V^{\pi_{\mathcal{M}}}(s)| \leq \frac{2R_{\max}}{(1-\gamma)^2}\big(\varepsilon_{\text{LLM}}(r_{\mathcal{M}}) + \delta_{\mathcal{M}}\big)ssup∣Vπ∗(s)−VπM(s)∣≤(1−γ)22Rmax(εLLM(rM)+δM)
其中 εLLM(rM)\varepsilon_{\text{LLM}}(r_{\mathcal{M}})εLLM(rM) 是 LLM 的泛化误差,δM\delta_{\mathcal{M}}δM 是检索误差,rMr_{\mathcal{M}}rM 是记忆覆盖半径。
随着技能库增长,rMr_{\mathcal{M}}rM 缩小(LLM 只需在更小的邻域内泛化),同时 δM\delta_{\mathcal{M}}δM 也下降(路由器更容易找到匹配的技能)。这解释了实验中观察到的边际递减现象——早期轮次增长最快,后期趋于饱和。
该公式也揭示了三个独立的性能提升杠杆:更强的 LLM(降低 εLLM\varepsilon_{\text{LLM}}εLLM)、更多的学习轮次(降低 rMr_{\mathcal{M}}rM)、更好的 Embedding(降低 δM\delta_{\mathcal{M}}δM)。三者互不干扰,可独立升级。
6. 系统工程:从理论到可部署系统
论文以极其罕见的写作方式,将系统工程细节与理论推导交织呈现。Memento-Skills 的组件架构包含:
- Entry Layer:CLI / Desktop GUI 双入口
- Agent Orchestration Layer:MementoSAgent 负责意图识别、任务规划、执行循环、步骤反思
- Tool Dispatcher Layer:安全策略 + 内置工具 + 技能工具
- Skill System:SkillGateway 统一接口 + SkillStore 存储 + SkillExecutor 执行 + UxSandbox 安全沙箱
- Infrastructure Layer:LLMClient(限流+重试+熔断)、SQLite 会话管理、ConfigManager
这不是一个玩具 demo,而是一个有安全策略、熔断机制、单元测试门控的工程级系统。
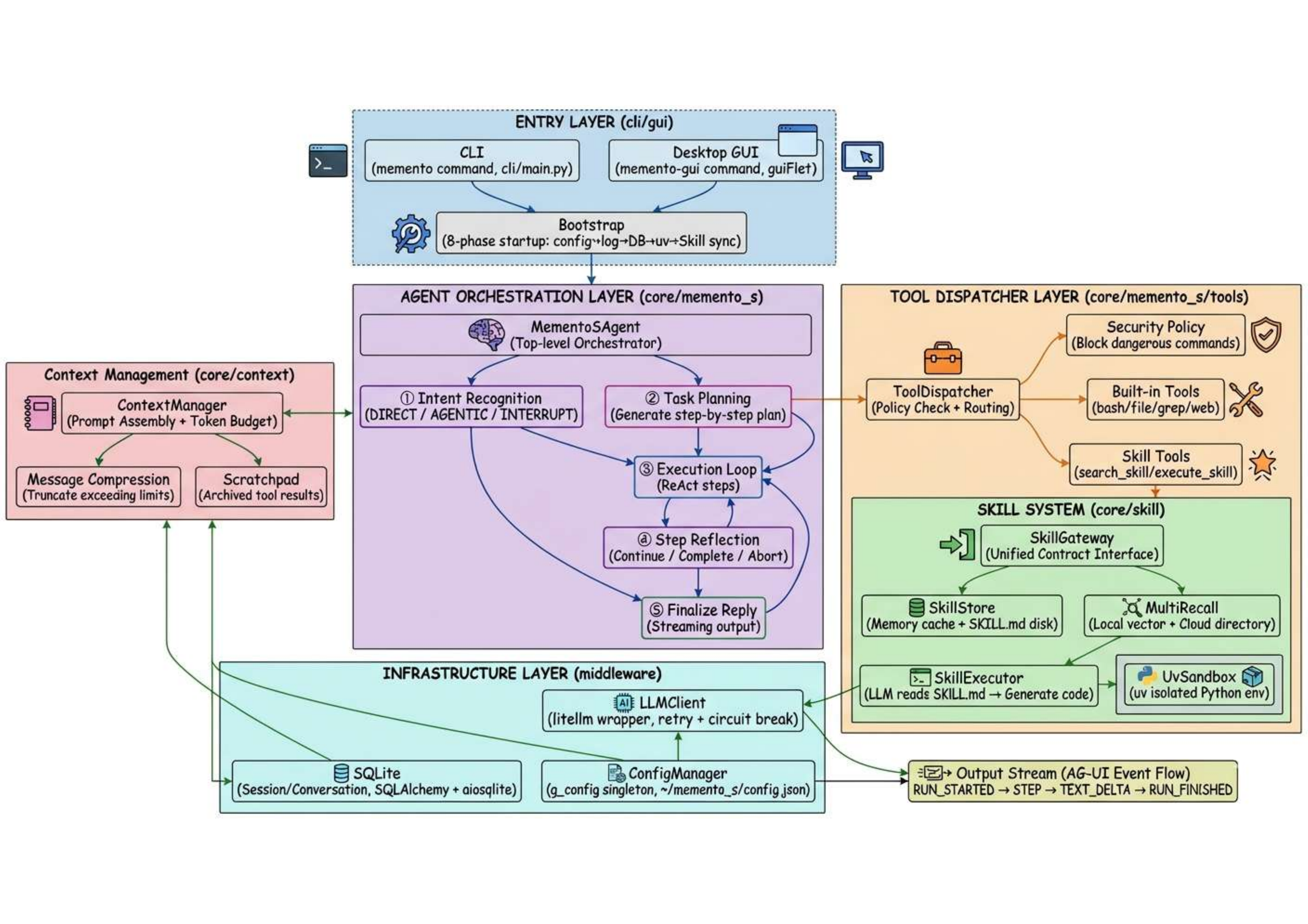
图7:Memento-Skills 完整系统架构。CLI/GUI 双入口 → 8 阶段 Bootstrap → Agent Orchestration(意图识别→任务规划→执行循环→步骤反思)→ Tool Dispatcher → Skill System(SkillGateway + SkillStore + MultiRecall + SkillExecutor)→ Infrastructure Layer(LLMClient + SQLite + ConfigManager)。
7. 批判性分析:亮点与局限
亮点
- 零参数更新的持续学习:技能作为外部记忆单元的设计打通了"部署时学习"的闭环,完全绕开了灾难性遗忘问题
- 行为对齐路由:将技能检索从语义匹配提升为行为预测,用单步 RL 训练 contrastive router 是一个简洁有效的方案
- 理论-工程双轨叙事:论文同时面向研究者和工程师,Research Track 和 Practitioner Track 的分轨设计值得借鉴
局限
- 跨任务迁移的脆弱性:GAIA 上训练集 91.6% vs 测试集 66.0% 的巨大差距说明,当任务间缺乏结构化领域重叠时,技能迁移大打折扣。系统更像是"领域专精"而非"通用学习"
- 底层 LLM 依赖:所有实验仅使用 Gemini-3.1-Flash,缺少对不同 LLM 的消融实验。性能提升中有多少归功于 Gemini 本身的能力?换一个更弱的模型是否还能 work?
- 安全性未充分验证:论文承认沙箱安全是 “future work”。当 Agent 自动生成并执行代码时,安全风险不容忽视
- 技能库规模的可扩展性:235 个技能是否已经是实际上限?当技能达到数千甚至上万时,路由和管理的开销如何?论文未给出分析
- 评估局限:仅在 GAIA 和 HLE 上测试,缺少对更广泛 Agent 基准(如 SWE-bench、WebArena)的验证
8. 与相关工作的定位
| 方法 | 记忆类型 | 是否可执行 | 是否自进化 | 路由方式 |
|---|---|---|---|---|
| RAG | 文档片段 | 否 | 否 | 语义检索 |
| GEPA | 提示演化 | 否 | 是 | — |
| Letta | 可执行技能 | 是 | 部分 | — |
| ProcMem | 过程记忆 | 部分 | 是 | 语义检索 |
| PlugMem | 结构化知识 | 否 | 是 | 语义检索 |
| Memento-Skills | 技能文件夹 | 是 | 是 | 行为对齐 RL |
Memento-Skills 的独特性在于:它是目前唯一同时具备可执行技能、反射自进化、以及行为对齐路由的系统。
总结
Memento-Skills 展示了一种令人兴奋的可能性:持续学习不必驻留在模型权重中。一个不断增长的、自我改进的技能库可以作为任何冻结 LLM 都能调用的持久化智能层。这种"技能即记忆"的范式,将 Agent 的能力进化从昂贵的参数更新转移到了轻量级的文件操作上。
但这也引发了更深层的问题:当 Agent 开始设计自己的技能,甚至设计新的 Agent 时,我们如何确保这个自进化过程不会脱离控制?论文中单元测试门控和回滚机制是初步的安全网,但距离生产级的安全保障还有很长的路要走。
无论如何,"让 Agent 自己设计 Agent"不再只是一个口号——Memento-Skills 给出了一个有理论保障、有工程实现、有实验验证的完整答案。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 32
32 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)