Agent招聘需求暴涨6倍!小白程序员必收藏,轻松入门大模型时代
本文深入浅出地介绍了Agent的核心概念、架构、工作原理以及实际应用,详细解析了多智能体协同、设计模式、状态管理、评估方法等关键知识点,并针对Agentic RAG、多模态处理等前沿技术进行了专项讲解,旨在帮助读者全面掌握Agent技术,抓住2026年AI发展新趋势。

核心概念与架构篇
Q1:请简述Agent的基本架构组成,并解释其与传统LLM Chain的区别。
回答要点:Agent = LLM + 规划(Planning) + 记忆(Memory) + 工具使用(Tool Use)。
区别:
- Chain是预定义的、线性的硬编码工作流。
- Agent具备”自主性”,它根据目标自发决定执行路径,通过推理循环(Reasoning Loop)不断调整策略。
Q2:解释ReAct模式的工作原理。
回答要点:ReAct (Reasoning + Acting)是Agent的基石。它将”;思考”(Thought)和”行动”(Action)结合。LLM先生成一段推理,说明下一步要做什么,然后调用工具观察(Observation)结果,再根据结果进入下一轮推理。
Q3:如何实现Agent的长期记忆(Long-term Memory)?
回答要点:
- 短期记忆:利用Context Window,存储当前会话的历史(Chat History)。
- 长期记忆:通过RAG (检索增强)。将历史经验、知识编码为Embedding存入向量数据库,Agent在执行任务前检索相关经验(Experience Retrieval)。
- 2026新趋势:利用长文本模型(Long-context LLMs)直接处理超长历史,或者通过”摘要层级结构”对记忆进行递归压缩。
多智能体协同(Multi-Agent Systems, MAS)
Q4:单Agent遇到瓶颈时,为什么需要Multi-Agent?常见的协作模式有哪些?
回答要点:
原因:单个Agent在处理复杂、跨领域长任务时容易出现”注意力漂移”或”推理链断裂”。
协作模式:
- 中心化(Boss-Worker):一个主Agent拆分任务并指派给子Agent。
- 流水线(Pipeline/Sequential):A的输出作为B的输入(如代码生成 -> 代码审查 -> 修复)。
- 民主协作(Joint Discussion):多个Agent共同讨论得出结论。
Q5:多智能体系统中如何解决”无限循环”或”通信冗余”问题?
回答要点:
- 循环检测:引入状态机控制流程,设置最大迭代次数。
- Token控制:对Agent间的对话进行摘要处理。
- 终止条件:明确定义任务完成的标准(Definition of Done)。
Agent核心设计模式 (Design Patterns)
Q6:请对比”工作流(Workflows)”与”自主智能体(Autonomous Agents)”的优劣。
回答要点:
- Workflows:通过DAG(有向无环图)或状态机硬编码路径。优点是高可靠性、结果可预期,适用于报销审批、标准化客服。
- Autonomous Agents:由LLM决定循环次数和工具调用。优点是灵活性极高,适用于开放式研究、代码编写。
- 面试金句:2026年的工程趋势是”用Workflow约束Agent”,即在框架定义的路径内给予Agent局部决策权。
Q7:详细解释”编排者-执行者(Orchestrator-Workers)”模式。
回答要点:主Agent(Orchestrator)负责将复杂任务分解为子任务,分发给具有不同Skill的Worker Agents,最后汇总结果。
适用场景:大型软件开发(一个写UI,一个写后端,一个写测试)。
难点:任务分解的粒度。如果拆得太细,通信成本极高;太粗,Worker会产生幻觉。
Q8:什么是”反思/自我纠正(Reflection/Self-Correction)”模式?
回答要点:这是提升Agent成功率最有效的模式。Agent生成输出后,由另一个(或同一个)Agent扮演批评者(Critic),检查输出是否符合约束条件,并提供反馈让前者迭代。
技术细节:可以使用Reflexion架构,记录”失败轨迹”作为长短期记忆,避免重复同样的错误。
深度技术实现与状态管理
Q9:在多轮对话Agent中,如何处理”状态爆炸”和”上下文溢出”?
回答要点:
- State Schema:定义严格的状态结构(如使用LangGraph的 TypedDict ),只保存核心变量。
- Trim Strategy:不仅是简单的截断,而是根据语义重要性保留(例如保留System Prompt、最近N轮对话和当前任务目标)。
- Summary Buffer:将旧的对话摘要化,将摘要存入Context头部。
Q10:如何保证Agent调用工具(Function Calling)的可靠性?
回答要点:
- 语法层面:利用JSON Mode或强类型约束。
- 逻辑层面:引入”确认机制(Human-in-the-loop)”,对于高风险操作(如删库、转账)必须由人点击确认。
- 重试逻辑:如果LLM生成的参数不合法,将报错信息返回给LLM,让其自我修复(Self-heal)。
Q11:LangGraph中的”节点(Node)”和”边(Edge)”与传统工作流有何不同?
回答要点:
- 传统工作流的边是固定的。
- LangGraph的边可以是条件边(Conditional Edges),由LLM的输出决定下一步走向哪个Node。
- 支持循环(Cycles),这是Agent能够不断尝试直到成功的核心。
2026必考的Evals(评估)
Q12:你如何量化一个Agent的性能?
回答要点:
- 任务成功率 (Success Rate):这是核心指标。
- 平均推理步数 (Avg Steps):步数越少,成本越低,响应越快。
- 工具调用准确率 (Tool Call Accuracy)。
- 影子测试 (Shadow Testing):在生产环境并行跑新旧Agent逻辑,对比输出差异。
Agentic RAG专项问答
Q13:RAG系统中经常遇到检索出来的片段(Chunk)互相冲突,Agent该听谁的?
回答要点:
- 元数据加权:根据文档的实时性、权威性(部门等级)进行权重排序。
- 多智能体辩论(Multi-Agent Debate):让不同的Agent持不同的Chunk进行对比,识别出冲突点并反馈给用户,或者根据逻辑一致性选择最合理的解释。
- 引用溯源:强制要求输出必须附带Source链接,让用户做最后校验。
Q14:如何处理企业知识库中的”权限隔离”问题?Agent会不会把高管工资查出来给普通员工?
回答要点:
核心策略:RAG权限对齐。
实现方式:在向量数据库中,每个Embedding向量都附带 ACL (访问控制列表)元数据。在Agent触发检索请求时,强制将”当前用户信息”作为Filter注入检索语句中。确保在向量检索阶段就完成物理隔离,而不是靠提示词拦截。
Q15:当知识库内容更新很快(如每日新闻或实时股价)时,你的RAG系统如何应对?
回答要点:
- 动态路由:Agent根据问题类型识别出”实时性要求”,如果是实时问题,优先调用实时API或搜索工具,而非检索向量库。
- 流式索引更新:利用数据流(如Kafka)监听知识库变化,实现增量Embedding写入。
- 缓存失效策略:针对高频问题设置TTL缓存,并在源数据更新时触发缓存失效。
Q16:如何提升问答准确度
提升准确度不能只靠 Prompt,而是一套组合拳:
1.深度解析层:Layout-Aware Parsing(布局感知解析)
- 痛点:传统的文本分割(Chunking)会打断表格结构或将标题与正文分离,导致语义断裂。
- 解决方案:
- 使用 Layout Analysis 模型(如 DocLayout-YOLO 或
Unstructured)。将文档识别为:标题、正文、表格、图片、列表。 - 语义分块:按标题层级(H1-H4)进行切分,而不是按字符数。确保每个 Chunk 都有完整的上下文。
- 检索增强层:Multi-Stage Retrieval
- 混合检索(Hybrid Search):向量检索(语义)+ BM25(关键词,解决专有名词、缩写问题)。
- 重排序(Reranking):使用 Cross-Encoder 模型(如 BGE-Reranker)对初筛的 Top-50 进行精排。这是提升准确度性价比最高的方法。
- 查询扩展(Query Expansion):Agent 自动生成 3 个同义问题并行检索,解决用户提问过于简单的问题。
3. 生成校验层:Self-Correction (Self-RAG)
- 验证节点:在生成答案前,让 Agent 判断:
- “检索到的内容是否足以回答问题?”(不够则重新检索)
- “答案中是否有任何内容是检索结果里没提到的?”(防止幻觉)
Q17:回答中如何包含原文档相关的图和表格
这是目前工业界的难点,核心在于**“多模态对齐”和“引用索引”**。
1. 表格的处理(Tables)
- 解析阶段:不要将表格转为纯文本。
- 最佳实践:将表格解析为****Markdown 或 HTML 格式。LLM 对结构化标记语言的理解能力远强于纯文本。
- 摘要索引:为每个表格生成一个自然语言摘要(Summary),将摘要存入向量库。检索时通过摘要定位表格,但在生成时把完整的 Markdown 表格喂给 LLM。
- 渲染阶段:前端直接渲染 LLM 输出的 Markdown 表格。
2. 图片的处理(Images)
- 多模态索引法:
- Image Captioning:使用多模态模型(如 GPT-4o-mini 或本地的 Qwen-VL)为图片生成详细描述。
- 存入向量库:将“图片描述 + 图片 ID + 所在页码”存入向量库。
- 检索逻辑:当用户问到“XX流程图”时,匹配到图片描述。
- 回显机制:
- 在返回给用户的答案中,使用特定占位符,如
[IMAGE_ID: 123]。 - 前端解析该占位符,从静态资源服务器(OSS)调用对应的图片 URL 进行展示。
处理流程图
展示你对整个链路的工程化理解:
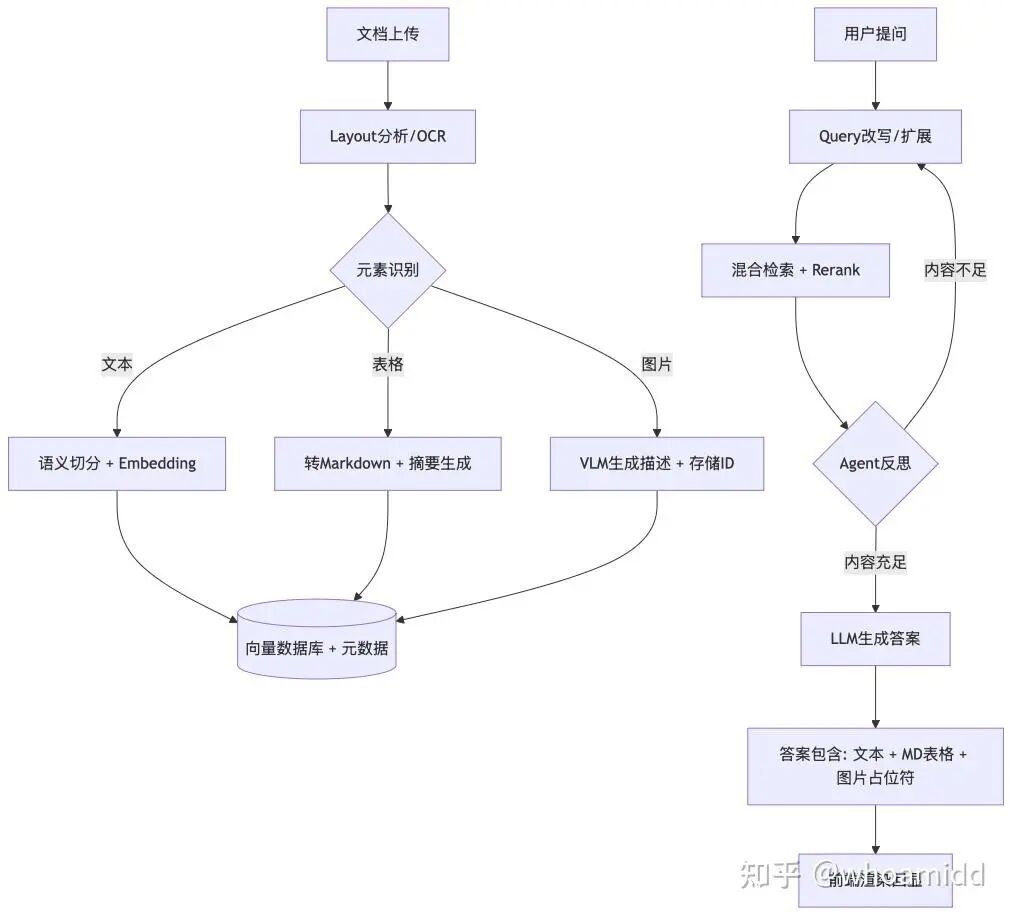
多模态处理专项问答
Q18:在生成答案时,你如何确保LLM知道要在哪里插入哪张图?
回答要点:引用占位符机制。
_“我在Prompt中强制约束LLM:’如果在检索到的内容中发现图片占位符(如 [IMG001] ),且该图片与答案高度相关,请在回复的相应位置保留该占位符’。 最终在前端展示时,我会写一个解析器,匹配这些占位符并从存储服务器(如OSS)中拉取真实图片进行渲染。这样既保证了图文位置对应,又避免了把大图片数据直接塞进Context导致的Token浪费。”
Q19:表格非常大,放入Prompt会导致上下文溢出或干扰模型,怎么优化?
回答要点:先摘要,后选择,再读取(Select-then-Read)。
“对于超大型表格,我不会一股脑塞给模型。 1. 第一步:Agent先通过表格的Schema(表头信息)和摘要判断该表是否包含所需数据。 2. 第二步:如果是,Agent会生成一个查询指令(类似SQL或Python代码),只提取表格中相关的行列。 3. 第三步:将提取后的精简子表喂给生成节点。这大大减少了干扰信息,准确度反而更高。”
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。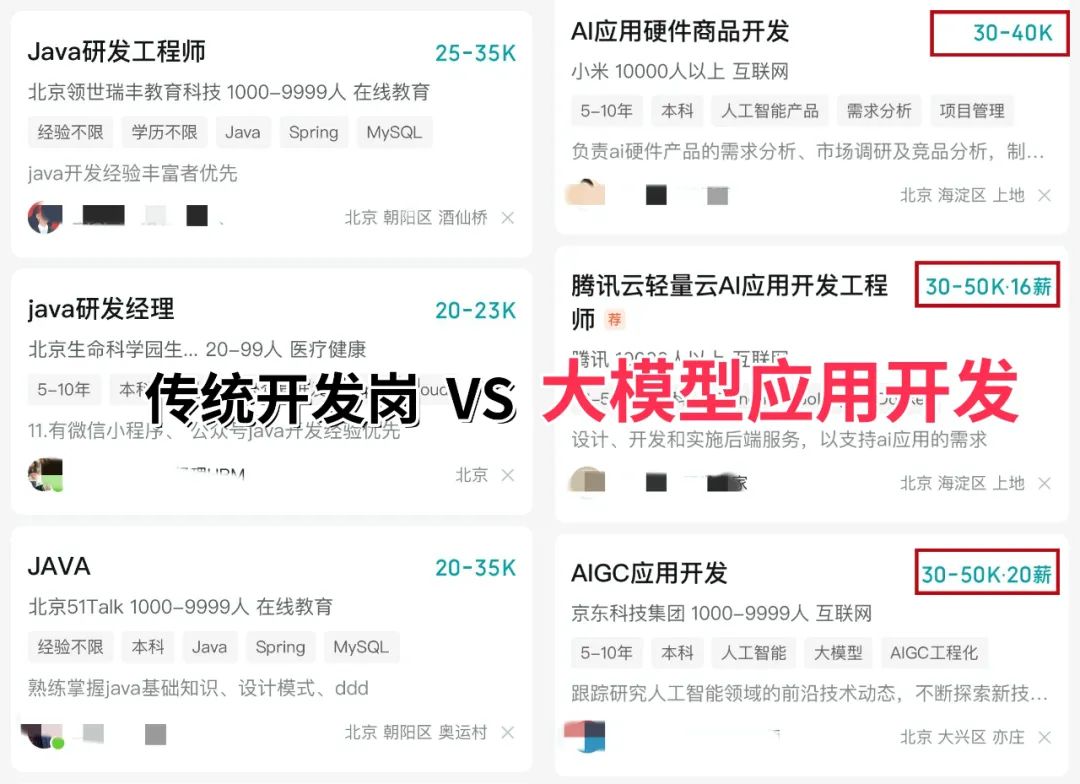
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)