从推荐算法到工程部署:AI原生应用全链路开发指南
从推荐算法到工程部署:AI原生应用全链路开发指南
关键词:推荐算法、模型训练、工程部署、AI原生应用、全链路开发
摘要:本文将带你从推荐算法的基础原理出发,逐步拆解AI原生推荐系统的全链路开发流程,涵盖算法选型、模型训练、工程部署、监控优化等核心环节。通过生活类比、代码示例和实战案例,帮你理解“从实验室模型到线上服务”的完整路径,掌握推荐系统落地的关键技术点。
背景介绍
目的和范围
在抖音刷到“刚好喜欢”的视频、淘宝首页出现“想要的商品”、音乐软件精准推送“心动歌单”——这些体验背后都藏着推荐系统的身影。本文聚焦AI原生推荐系统(以数据和算法为核心驱动的应用),覆盖从算法设计到工程部署的全链路开发,帮开发者掌握“从0到1”落地推荐系统的能力。
预期读者
- 对推荐系统感兴趣的AI初学者
- 想了解工程落地的算法工程师
- 负责推荐服务的后端开发者
文档结构概述
本文将按“算法原理→模型训练→工程部署→实战验证”的主线展开,先通过生活案例理解推荐算法的底层逻辑,再拆解模型训练的关键步骤,最后重点讲解如何将模型部署为高可用服务,并通过实战案例巩固知识。
术语表
核心术语定义
- 协同过滤:通过“人找相似人”或“物找相似物”的方式做推荐(类比“朋友推荐”)。
- Embedding:将用户/物品的特征转化为低维向量(类比“给每个人/物贴一个数字标签”)。
- 模型推理:用训练好的模型对新数据做预测(类比“用菜谱快速做菜”)。
- 服务化:将模型封装为API,支持高并发请求(类比“开一家能同时接待100桌的餐厅”)。
缩略词列表
- AB测试:A/B Testing(同时运行两个版本服务,对比效果)
- QPS:Queries Per Second(每秒请求数)
- SLA:Service Level Agreement(服务等级协议,如“99.9%可用”)
核心概念与联系:推荐系统的“四架马车”
故事引入:奶茶店的“隐藏菜单”推荐
假设你开了一家奶茶店,想让顾客每次来都能喝到“想喝但没说”的奶茶。你会怎么做?
- 第一步:记录顾客数据(喜欢的口味、常点的配料、消费时间);
- 第二步:发现规律(比如“下午3点买冰奶茶的人,70%会加椰果”);
- 第三步:主动推荐(看到新顾客下午3点来,就说“试试冰奶茶+椰果?很多人喜欢~”)。
这就是推荐系统的核心逻辑:用历史数据找规律,为用户提供个性化建议。
核心概念解释(像给小学生讲故事)
推荐系统全链路涉及四个核心概念,我们用奶茶店类比理解:
1. 推荐算法:找规律的“小侦探”
推荐算法是“找规律”的工具。比如:
- 协同过滤:发现“喝杨枝甘露的人,80%也喜欢芒果椰椰”(物以类聚);
- 深度学习模型(如Wide&Deep):同时考虑“用户常买的品类”(记忆能力)和“用户可能喜欢的新品类”(泛化能力),像更聪明的侦探。
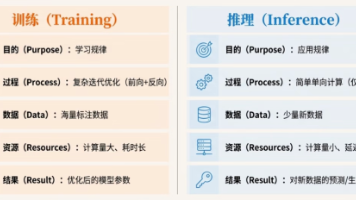
2. 模型训练:规律的“学习课”
模型训练是让算法“学规律”的过程。就像教小朋友认数字:
- 用历史数据(如10万条顾客点单记录)当“练习册”;
- 用“损失函数”判断“学得对不对”(比如预测顾客点冰奶茶的概率,和实际是否点了的差距);
- 用“优化器”调整参数(像老师纠正小朋友的错误,让下次更准)。
3. 模型推理:规律的“应用课”
模型推理是用学来的规律“做判断”。比如:
- 当新顾客进店(输入数据),模型快速计算“他最可能喜欢的3款奶茶”(输出结果);
- 推理需要“快”(顾客等不及)和“准”(推荐错了会失望)。
4. 工程部署:规律的“开店营业”
工程部署是把“能推理的模型”变成“能服务千万顾客的系统”。就像开奶茶连锁店:
- 需要“厨房”(计算资源)处理大量订单;
- 需要“点单系统”(API接口)让顾客方便下单;
- 需要“监控”(比如实时看订单量、出餐速度)确保不出问题。
核心概念之间的关系(用奶茶店类比)
四个概念就像奶茶店的“后厨四兄弟”:
- 算法设计“做奶茶的配方”(找规律);
- 训练是“后厨练习做奶茶”(学配方);
- 推理是“给顾客快速出奶茶”(用配方);
- 部署是“开分店让更多顾客喝到”(规模化)。
四者缺一不可:配方不好(算法差),奶茶不好喝;练习不够(训练不充分),做出来不稳定;出餐慢(推理延迟高),顾客会跑;分店管理乱(部署差),生意做不大。
核心概念原理和架构的文本示意图
推荐系统全链路可简化为:
数据采集 → 特征工程 → 模型训练 → 模型评估 → 模型导出 → 推理服务 → 监控优化
Mermaid 流程图
核心算法原理 & 具体操作步骤
推荐算法有很多种,我们以最经典的**协同过滤(Collaborative Filtering)和深度学习模型(Wide&Deep)**为例,讲解原理和实现。
1. 协同过滤:物以类聚,人以群分
原理
协同过滤的核心是“相似性”:
- 用户协同过滤(User-CF):找“和你口味像的人”,推荐他们喜欢的物品(比如“用户A和你都喜欢奶茶,用户A还喜欢果茶,所以推荐果茶给你”);
- 物品协同过滤(Item-CF):找“和你喜欢的物品像的物品”,推荐给你(比如“你喜欢杨枝甘露,杨枝甘露和芒果椰椰很像,所以推荐芒果椰椰”)。
数学模型
计算相似性常用余弦相似度:
相似性(u,v)=u⋅v∣∣u∣∣⋅∣∣v∣∣ \text{相似性}(u, v) = \frac{u \cdot v}{||u|| \cdot ||v||} 相似性(u,v)=∣∣u∣∣⋅∣∣v∣∣u⋅v
其中,uuu和vvv是用户或物品的特征向量,∣∣u∣∣||u||∣∣u∣∣是向量的模长。
Python代码示例(用户协同过滤)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 假设用户评分矩阵:行是用户,列是物品,值是评分(1-5分)
user_item_matrix = np.array([
[5, 3, 0, 1], # 用户1对物品1-4的评分
[4, 0, 4, 0], # 用户2
[0, 5, 1, 4], # 用户3
[1, 0, 5, 4] # 用户4
])
# 计算用户之间的余弦相似度
user_similarity = cosine_similarity(user_item_matrix)
print("用户相似度矩阵:\n", user_similarity)
# 为用户1推荐物品(假设用户1没评分的物品是物品3)
# 找和用户1最相似的用户(排除自己)
similar_users = np.argsort(user_similarity[0])[::-1][1:] # [2, 3, 1]
# 计算物品3的推荐分数:相似用户的评分加权平均
score = 0
total_sim = 0
for user in similar_users:
if user_item_matrix[user][2] != 0: # 用户对物品3有评分
score += user_similarity[0][user] * user_item_matrix[user][2]
total_sim += user_similarity[0][user]
recommend_score = score / total_sim if total_sim != 0 else 0
print("用户1对物品3的推荐分数:", recommend_score) # 输出约3.8
2. 深度学习模型(Wide&Deep):记忆+泛化的“全能选手”
原理
Wide&Deep模型由Google提出,结合了“宽模型(Wide)”和“深模型(Deep)”:
- 宽模型:直接学习历史数据中的“高频模式”(记忆能力),比如“用户A+物品B=点击”;
- 深模型:通过神经网络学习特征的“隐含关联”(泛化能力),比如“用户A的年龄+物品B的价格=可能点击”。
数学模型
模型输出是宽模型和深模型结果的线性组合:
预测=σ(Wwide⋅[x,ϕ(x)]+Wdeep⋅a(l)+b) \text{预测} = \sigma(W_{wide} \cdot [x, \phi(x)] + W_{deep} \cdot a^{(l)} + b) 预测=σ(Wwide⋅[x,ϕ(x)]+Wdeep⋅a(l)+b)
其中,σ\sigmaσ是sigmoid函数(输出0-1的概率),ϕ(x)\phi(x)ϕ(x)是交叉特征(如“年龄>25”和“价格<50”的组合),a(l)a^{(l)}a(l)是深层网络的最后一层激活值。
模型架构示意图
输入特征 → [宽模型(线性层+交叉特征) + 深模型(嵌入层→全连接层)] → 输出概率
数学模型和公式 & 详细讲解 & 举例说明
损失函数:判断“学得好不好”
推荐系统常用交叉熵损失(分类任务,如“用户是否点击”)或均方误差(回归任务,如“用户评分预测”)。
交叉熵损失公式(二分类):
L=−1N∑i=1N[yilog(y^i)+(1−yi)log(1−y^i)] L = -\frac{1}{N} \sum_{i=1}^N [y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i)] L=−N1i=1∑N[yilog(y^i)+(1−yi)log(1−y^i)]
其中,yiy_iyi是真实标签(0或1),y^i\hat{y}_iy^i是模型预测的概率(0-1)。
举例:如果用户实际点击了(yi=1y_i=1yi=1),但模型预测概率y^i=0.2\hat{y}_i=0.2y^i=0.2,损失会很大(因为log(0.2)≈−1.6\log(0.2)≈-1.6log(0.2)≈−1.6,损失项为−1×(−1.6)=1.6-1 \times (-1.6)=1.6−1×(−1.6)=1.6);如果预测y^i=0.9\hat{y}_i=0.9y^i=0.9,损失很小(log(0.9)≈−0.1\log(0.9)≈-0.1log(0.9)≈−0.1,损失项为0.1)。
均方误差(回归任务):
L=1N∑i=1N(yi−y^i)2 L = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2 L=N1i=1∑N(yi−y^i)2
举例:用户真实评分为4分,模型预测3.5分,误差是0.52=0.250.5^2=0.250.52=0.25;预测4.2分,误差是0.22=0.040.2^2=0.040.22=0.04。
优化器:让模型“越学越准”
常用优化器是随机梯度下降(SGD)和Adam。优化器的核心是计算损失函数对模型参数的梯度,然后沿梯度反方向更新参数(就像“往山下走”找最小损失)。
梯度公式(以参数www为例):
wt+1=wt−η⋅∂L∂wt w_{t+1} = w_t - \eta \cdot \frac{\partial L}{\partial w_t} wt+1=wt−η⋅∂wt∂L
其中,η\etaη是学习率(控制“下山步长”)。
项目实战:从0到1开发一个电影推荐系统
开发环境搭建
- 数据:使用MovieLens小数据集(10万条评分,用户-电影-评分);
- 工具:Python 3.8+、PyTorch 2.0、FastAPI(部署API)、Docker(容器化);
- 环境:本地用Jupyter Notebook训练,服务器用Ubuntu 20.04部署。
源代码详细实现和代码解读
步骤1:数据加载与预处理
import pandas as pd
from sklearn.model_selection import train_test_split
# 加载数据(用户ID、电影ID、评分)
data = pd.read_csv('ml-latest-small/ratings.csv')[['userId', 'movieId', 'rating']]
# 离散化用户ID和电影ID(转成连续整数)
user_ids = data['userId'].unique()
movie_ids = data['movieId'].unique()
user2idx = {u: i for i, u in enumerate(user_ids)}
movie2idx = {m: i for i, m in enumerate(movie_ids)}
data['userId'] = data['userId'].map(user2idx)
data['movieId'] = data['movieId'].map(movie2idx)
# 划分训练集和测试集
train, test = train_test_split(data, test_size=0.2, random_state=42)
步骤2:构建协同过滤模型(PyTorch实现)
import torch
import torch.nn as nn
class CollaborativeFiltering(nn.Module):
def __init__(self, num_users, num_movies, embedding_dim=64):
super().__init__()
# 用户和电影的Embedding层(将ID转成向量)
self.user_emb = nn.Embedding(num_users, embedding_dim)
self.movie_emb = nn.Embedding(num_movies, embedding_dim)
# 预测评分的线性层(用户向量和电影向量点积)
self.fc = nn.Linear(embedding_dim, 1)
def forward(self, user_ids, movie_ids):
user_vec = self.user_emb(user_ids) # [batch_size, embedding_dim]
movie_vec = self.movie_emb(movie_ids) # [batch_size, embedding_dim]
# 点积计算相似性(用户和电影的匹配程度)
dot_product = (user_vec * movie_vec).sum(dim=1) # [batch_size]
# 输出评分(范围1-5,用sigmoid缩放后乘以5)
return torch.sigmoid(dot_product) * 5
# 初始化模型
num_users = len(user_ids)
num_movies = len(movie_ids)
model = CollaborativeFiltering(num_users, num_movies, embedding_dim=64)
步骤3:模型训练
from torch.utils.data import DataLoader, TensorDataset
# 转换数据为PyTorch张量
train_dataset = TensorDataset(
torch.tensor(train['userId'].values, dtype=torch.long),
torch.tensor(train['movieId'].values, dtype=torch.long),
torch.tensor(train['rating'].values, dtype=torch.float32)
)
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(10):
model.train()
total_loss = 0
for user_ids, movie_ids, ratings in train_loader:
optimizer.zero_grad()
outputs = model(user_ids, movie_ids)
loss = criterion(outputs, ratings)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.4f}")
步骤4:模型导出(TorchScript)
# 导出为TorchScript(支持高效推理)
example_user = torch.tensor([0], dtype=torch.long) # 示例用户ID
example_movie = torch.tensor([0], dtype=torch.long) # 示例电影ID
traced_model = torch.jit.trace(model, (example_user, example_movie))
traced_model.save("cf_model.pt")
步骤5:推理服务部署(FastAPI)
from fastapi import FastAPI
import torch
app = FastAPI()
# 加载模型
model = torch.jit.load("cf_model.pt")
@app.get("/recommend")
async def recommend(user_id: int, top_k: int = 3):
# 假设获取用户未评分的电影ID(实际需查询数据库)
user_tensor = torch.tensor([user_id], dtype=torch.long)
# 计算所有电影的评分(这里简化为前100部电影)
movie_ids = torch.arange(100, dtype=torch.long)
with torch.no_grad():
scores = model(user_tensor.repeat(100), movie_ids)
# 取分数最高的top_k部电影
top_indices = scores.argsort(descending=True)[:top_k]
return {"recommended_movie_ids": top_indices.tolist()}
步骤6:容器化部署(Docker)
# Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建并运行容器:
docker build -t movie-recommender .
docker run -p 8000:8000 movie-recommender
实际应用场景
推荐系统的应用场景非常广泛,不同场景有不同的技术挑战:
1. 电商推荐(如淘宝、京东)
- 需求:实时性(用户浏览商品后立即推荐相似品)、多样性(避免“只推同类商品”);
- 挑战:商品数量大(亿级),需高效的Embedding检索(如使用FAISS库做近似最近邻搜索)。
2. 内容推荐(如抖音、头条)
- 需求:高实时性(用户刷视频时立即推荐下一条)、冷启动(新视频快速获得曝光);
- 挑战:内容更新快(每天百万级新视频),需结合内容特征(如视频标签、作者信息)和用户行为。
3. 音乐推荐(如网易云、QQ音乐)
- 需求:长期兴趣(用户几年前喜欢的歌可能现在还喜欢)、场景化(上班/运动时推荐不同歌单);
- 挑战:用户兴趣随时间变化(需时间序列模型,如Transformer)。
工具和资源推荐
数据处理
- Pandas:小数据集快速清洗(适合学习);
- Spark:大数据集分布式处理(工业级);
- DVC:数据版本管理(避免“数据混乱”)。
模型训练
- PyTorch:动态图,适合研究和快速迭代;
- TensorFlow:静态图,适合工业部署(配合TFServing);
- Hugging Face Transformers:快速集成大模型(如用BERT增强文本特征)。
模型部署
- TorchServe:PyTorch官方推理服务框架;
- TensorRT:NVIDIA的高性能推理优化工具(可加速3-10倍);
- Kubernetes:容器编排(管理成百上千个模型实例)。
监控与优化
- Prometheus+Grafana:监控QPS、延迟、错误率;
- MLflow:模型生命周期管理(记录训练参数、版本);
- AB实验平台:如Google的Firebase AB Testing(对比新旧模型效果)。
未来发展趋势与挑战
趋势1:大模型与推荐系统的融合
大语言模型(LLM)如GPT-4能理解用户的长文本意图(如“推荐适合情侣看的、轻松搞笑的电影”),未来推荐系统可能从“基于行为”转向“基于语义”,提供更自然的交互。
趋势2:边缘计算降低延迟
5G和物联网普及后,推荐服务可能从“云端”走向“边缘”(如手机、路由器),减少网络延迟,实现“毫秒级推荐”。
挑战1:隐私保护
用户数据敏感(如浏览记录、搜索词),需结合联邦学习(各设备本地训练模型,不上传数据)、差分隐私(添加噪声保护个体信息)。
挑战2:模型可解释性
用户可能问“为什么推荐这个商品?”,需开发可解释的推荐方法(如展示“因为你喜欢A商品,所以推荐B”)。
总结:学到了什么?
核心概念回顾
- 推荐算法:协同过滤(找相似)、深度学习(记忆+泛化);
- 模型训练:用数据“学规律”,损失函数判断“学得准不准”,优化器“越学越准”;
- 工程部署:将模型封装为API,用容器化、集群化实现高可用;
- 全链路:数据→训练→评估→部署→监控,形成闭环优化。
概念关系回顾
算法是“大脑”(决定推荐质量),工程是“身体”(决定推荐效率),两者结合才能做出用户喜欢的推荐系统。
思考题:动动小脑筋
- 如果你的推荐系统在AB测试中点击率比旧版高,但用户停留时间下降,可能是什么原因?该如何优化?
- 假设你要为新上线的短视频App设计推荐系统,如何解决“新用户没有历史行为”的冷启动问题?
- 模型推理延迟突然从100ms增加到500ms,可能的原因有哪些?如何快速定位?
附录:常见问题与解答
Q:模型训练时损失不下降怎么办?
A:可能原因:学习率太大(参数“跳过头”)、数据有噪声(错误标签影响训练)、模型太简单(无法捕捉规律)。解决方法:调小学习率、清洗数据、尝试更复杂的模型(如增加Embedding维度)。
Q:部署后服务QPS上不去(每秒只能处理100请求),怎么优化?
A:优化方向:
- 模型层面:用TensorRT优化推理速度,或简化模型(如减少Embedding维度);
- 工程层面:增加服务实例(Kubernetes扩缩容),使用异步API(非阻塞处理请求)。
Q:如何判断推荐系统是否“过拟合”?
A:过拟合表现为“训练集损失很低,测试集损失很高”(模型记住了训练数据的噪声)。解决方法:增加正则化(如L2正则)、提前终止训练(验证集损失不再下降时停止)。
扩展阅读 & 参考资料
- 经典书籍:《推荐系统实践》(项亮)、《深度学习推荐系统》(王喆);
- 论文:《Wide & Deep Learning for Recommender Systems》(Google)、《Collaborative Filtering for Implicit Feedback Datasets》(Yahoo);
- 工具文档:PyTorch官方教程(https://pytorch.org/tutorials/)、Kubernetes部署指南(https://kubernetes.io/docs/)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)