大模型落地必看:训练跑通≠上线!揭秘推理系统架构与成本优化秘籍,告别高延迟与低利用率
为什么训练跑通 ≠ 系统可用
在大模型进入实际业务后,很多团队都会经历一个认知转变:
一开始,关注点往往是“模型有多大?训练效果如何?用了多少GPU?”
然而,模型上线后真正影响业务的,不是训练本身,而是推理阶段的稳定性和成本:
●接口延迟高,影响用户体验
●GPU资源占用不稳定,利用率低
●推理成本快速上升,难以规模化
●高并发场景下系统可能不稳定
这让团队意识到:训练和推理,本质上是两套完全不同的系统工程。
在落地过程中,合理区分训练与推理体系,并针对不同阶段优化算力,才能实现模型高效落地。
PART.01
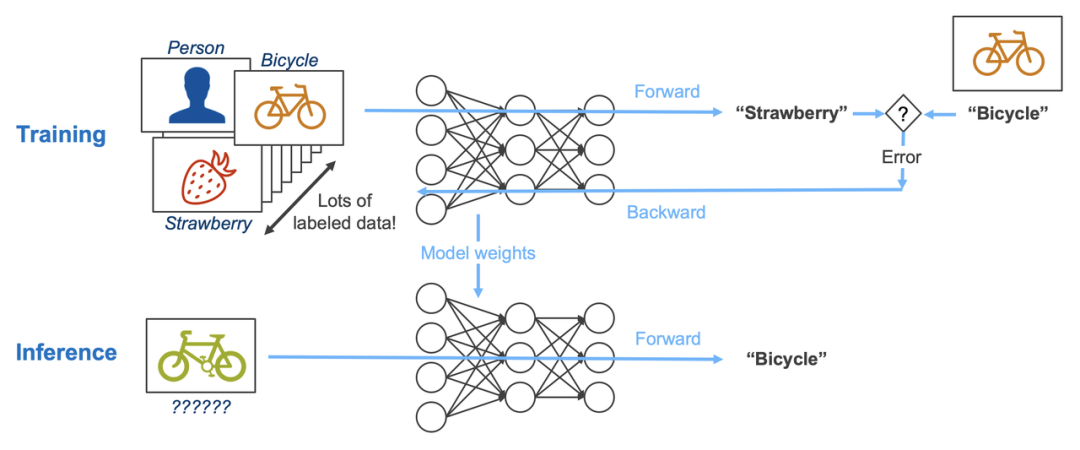
AI训练 vs AI推理:两个阶段的系统差异
定义与目标
**● AI训练(AI Model Training):**通过大规模数据优化模型参数,发现历史数据中的模式与规律。
**● AI推理(AI Model Inference):**使用训练好的模型对新数据进行预测,实现实时业务价值。
在工程实践中,这两者差异不仅体现在“是否更新参数”,还涉及:
1. 时间维度
● 训练:周期性任务(数小时到数天)
● 推理:持续运行,每次用户请求都触发
2. 计算模式
● 训练:大规模批处理
● 推理:实时请求
3. 系统目标
● 训练:优化模型精度(accuracy/loss)
● 推理:优化系统指标(latency/throughput/cost)
因此,“训练跑通”并不意味着系统可以直接上线投入使用。

PART.02
为什么推理成本往往超过训练?
在大模型部署实践中,推理成本占比往往高达 70%-90%。原因包括:
**1. 推理是持续发生的:**训练可能每周或每月跑一次,但推理每次用户请求都要执行。
**2. 请求规模不可控:**业务增长、用户访问和API调用直接影响推理负载。
**3. 单次推理成本上升:**大模型上下文长度增加、推理链路复杂、reasoning计算增强。
在规划大模型部署或AI应用上线时,首要评估的指标是“单次推理成本”和“推理并发规模”,这决定了长期成本结构。
PART.03
AI推理系统的真实复杂度
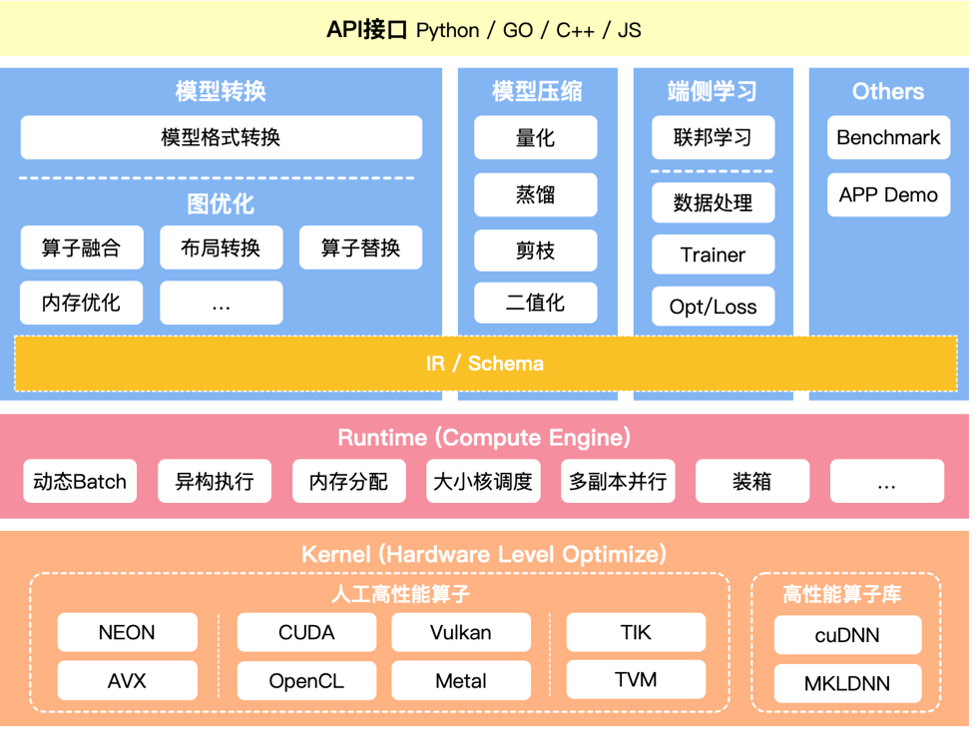
完整的推理系统远比“加载模型+返回结果”复杂,包括:
**1. 数据入口层:**API请求、流式数据(Kafka/日志)、实时输入
**2. 模型服务层:**模型加载、前向计算、多模型调度
**3. 系统能力层:**动态批处理、弹性扩缩容、多硬件调度、缓存与加速
**4. 监控与反馈:**延迟、吞吐、错误率、数据回流训练
在实际落地中,为了保证系统性能和稳定性,我们通常有一套专属的AI推理体系,针对实时预测、成本优化和高并发场景进行专项优化。
PART.04
训练系统 vs 推理系统:架构差异
一句话概括:训练系统是吞吐优先,推理系统是延迟优先
AI训练特点
● 大规模GPU/TPU集群
● 高带宽互联(NVLink / InfiniBand)
● 分布式训练框架(DeepSpeed / Megatron-LM)
● 高IO数据管道
● 主要目标:高效完成大规模训练任务,保证模型精度
赋创AI训练方案

平台**:**SYS-821GE-TNHR *1
CPU**:Intel**Platinum 8558P *2
**显卡:**NVIDIA HGX GPU 8-H200 141G *1
内存**:**128G DDR5 RECC 6400 *16
存储1**:**960G U.2 NVMe PCIe4 2.5寸 SSD 企业级*2
存储2**:**7.68T U.2 NVMe PCIe4 2.5寸 SSD 企业级*4
**网卡:**Mellanox CX-7 单口400G网卡*8
AI推理特点
● 微服务架构
● 弹性扩展(Kubernetes/Autoscaling)
● 多租户调度
● 成本优化机制
● 主要目标:低延迟、高吞吐、持续可用
两套体系独立优化,才能同时满足模型精度和系统性能要求。
赋创AI推理方案

平台**:**FG4812T-A4 *1
CPU**:AMD**EPYC 9654 *2
**显卡:**NVIDIA RTX 5090 32G双宽涡轮卡 *8
内存**:**64G DDR5 RECC 4800*8
存储1**:**480G SATA 2.5寸 SSD 企业级 *2
存储2**:**3.84T SATA 2.5寸 SSD 企业级 *3
**网卡:**Mellanox CX-6 LX 双口100G网卡*1
PART.05
推理优化:降低成本与提升性能的关键
在AI系统中,推理优化直接决定ROI。主要路径包括:
模型侧优化
**● 量化(Quantization):**FP32 → INT8
**● 剪枝(Pruning):**减少冗余参数
**● 蒸馏(Distillation):**小模型替代大模型
系统侧优化
● 批处理调度(Batching)
● GPU资源切分(GPU Fraction)
● 推测解码(Speculative Decoding)
● KV Cache优化
这些优化通常可以在我们的AI推理方案中实施,使系统在高并发下保持低延迟、低成本,同时保证预测准确性。
PART.06
推理正在“训练化”
随着大模型推理需求增加,推理计算量也在增加:
● 多路径生成
● 验证与重排序
● 在线优化
这意味着推理阶段也需要部分训练能力支撑,系统设计需要同时考虑批量梯度流和实时推理计算。
这带来一个新趋势:Inference-Time Compute(推理时计算)成为新竞争点。
PART.07
企业如何做AI算力规划?
在实际部署中,建议从以下维度规划训练和推理:
**1. 延迟要求:**是否需要实时响应(<100ms)
**2. 推理规模:**QPS/并发量
**3. 成本结构:**训练一次性成本 vs 推理长期成本
**4. 部署环境:**云/本地/边缘
**5. 数据安全:**是否需要私有化部署
结合这些指标,企业可以分别构建AI训练方案和 AI推理方案,形成完整的能力体系。

PART.08
总结与落地建议
AI落地的核心,不再只是模型本身,而是训练与推理两套工程能力的平衡:
**● 赋创AI训练方案:**保证大模型精度和训练效率
**● 赋创AI推理方案:**保证预测实时性、系统稳定性和成本可控。
企业若能在训练与推理两端建立清晰体系,就能让大模型真正落地,既保证业务价值,又控制运营成本。
如果您正在规划大模型部署、推理优化或GPU算力配置,了解训练与推理的系统架构与优化策略至关重要。

赋创可以基于您的业务场景和需求,提供定制化的训练与推理算力架构方案,帮助您实现高性能、低成本的AI落地。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)