Hadoop HA安装
安装方法绝大部分参考了“尚硅谷Hadoop3”。
报错的,基本上都在DeepSeek上找到了解决办法。
每安装好一步,建议打个快照,并备注好当前安装好的组件、服务。
【安装好单台机器,打个镜像。安装大数据组件时,不打镜像。】
1. 配置单台节点
1.1. 安装vmware
略。要更改VMware的虚拟网络编辑器.
VMware
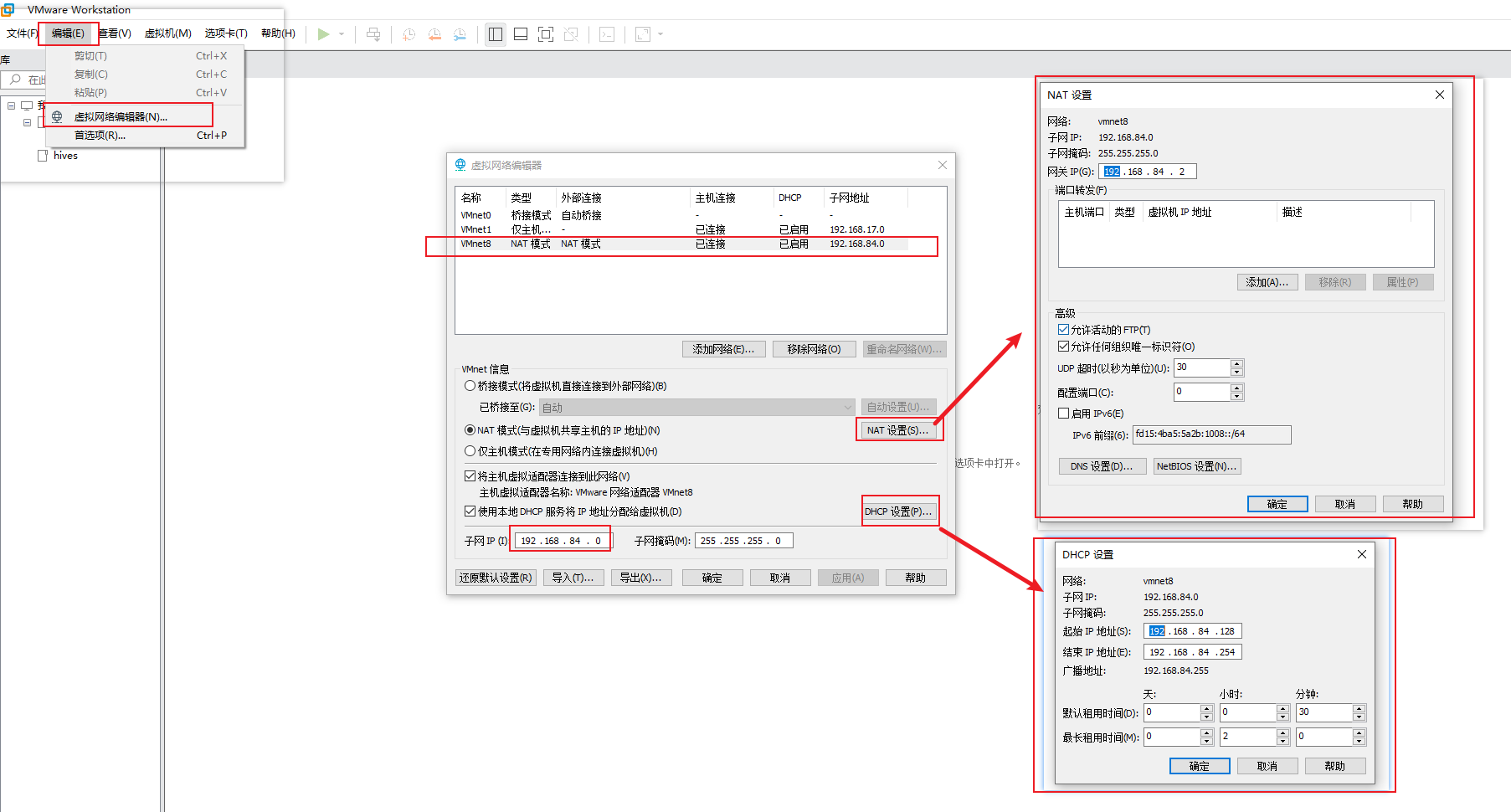
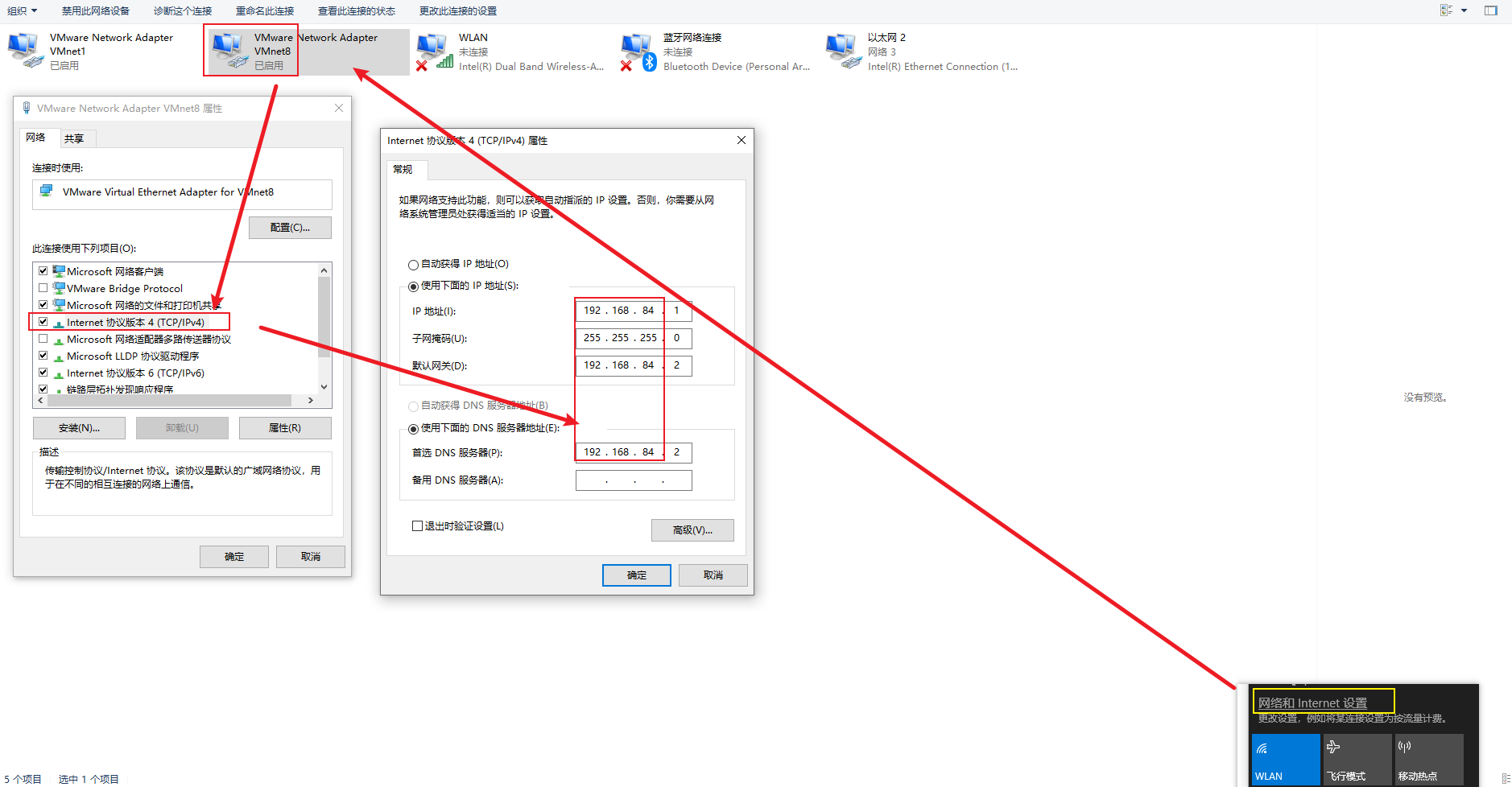
Windows网络适配器
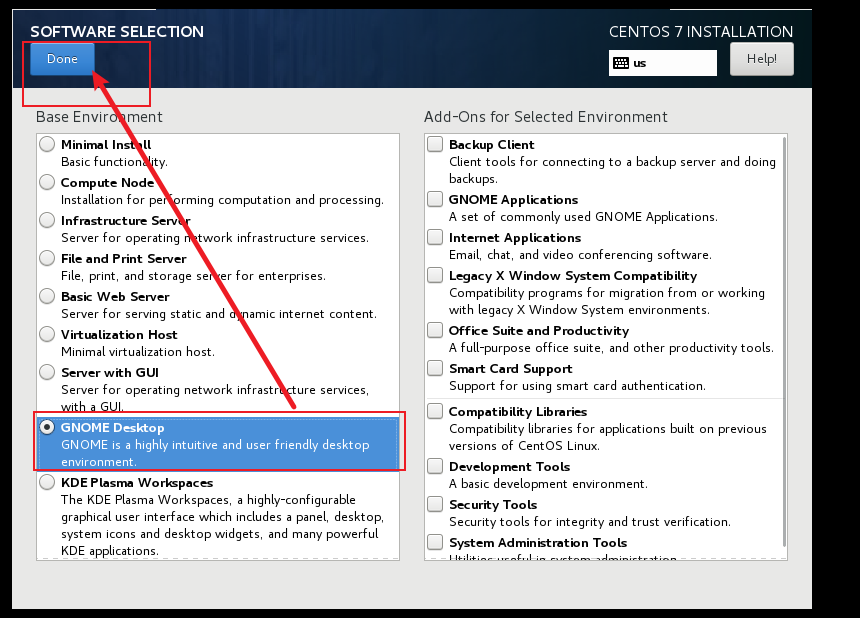
1.2. 安装Centos7
镜像名:CentOS-7.5-x86_64-DVD-1804.iso,4.16GB
【不确定虚拟机给多少资源,直接内存1G,1核。熟练后,再独立安装,修改】
【不要安装最小的模式。选择安装GNOME桌面。太小的版本,很多软件安装费劲,新手不友好】
显示橙色的,点进去,直接点Done,即可,一次不行,多点两次。
设置完后,点Begin Install。等。安装完成后,点击“REBOOT”。
创建一个非root用户,如zengxiao。
用xshell等软件连接虚拟机。后续都在xshell中操作。
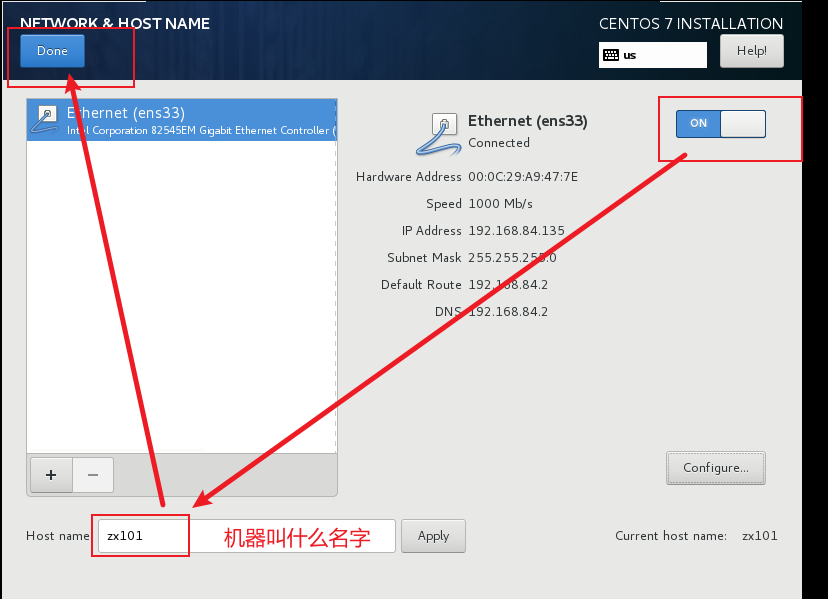
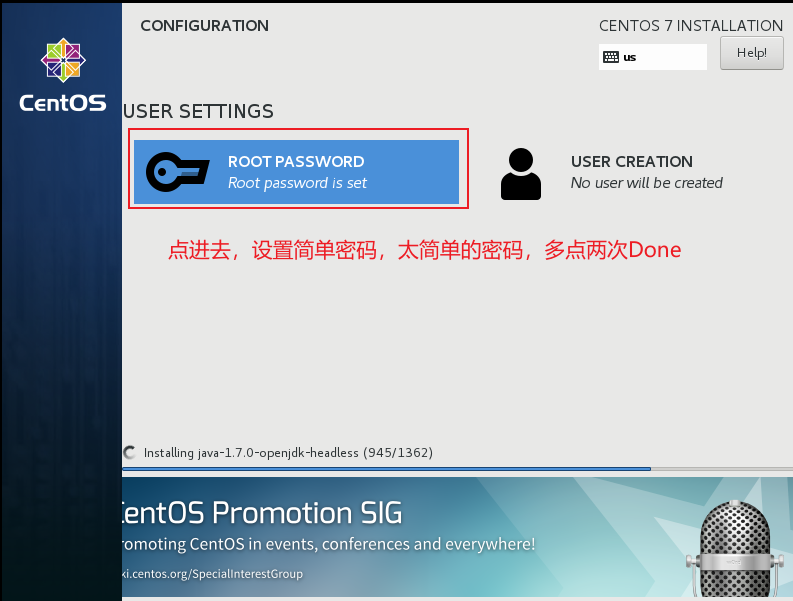
1.3. 修改Centos机器信息(root用户操作)
1.3.1 修改ip地址
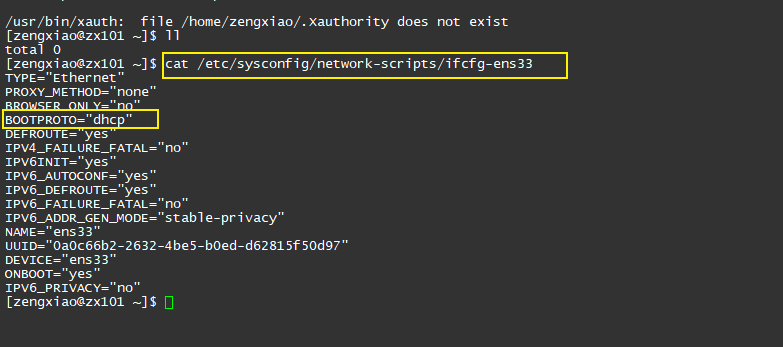
修改之前(如下图)
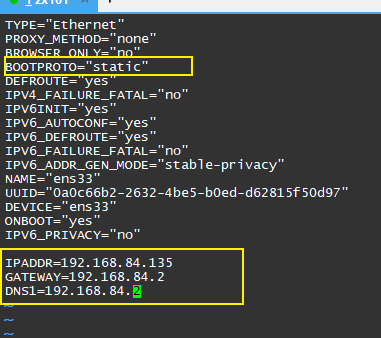
修改之后(如下图)
cat /etc/sysconfig/network-scripts/ifcfg-ens32
vim /etc/sysconfig/network-scripts/ifcfg-ens32BOOTPROTO="static"
IPADDR=192.168.84.101 #IP地址
GATEWAY=192.168.84.2 #网关
DNS1=192.168.84.2 #域名解析器# 然后重启网络服务
systemctl restart network
1.3.2 修改机器hosts
hosts里面的机器名,机器IPv4编码的最后一部分,自定义即可。
修改之前(如下图)

修改后(如下图)

安装Centos的时候,如果没有改hostname,现在也可以改
vim /etc/hostname
zx101
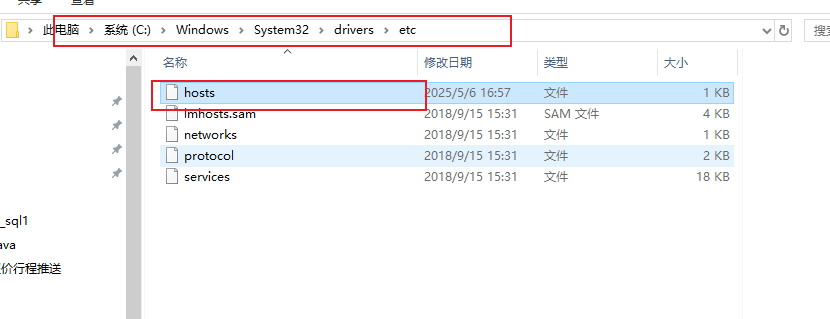
1.3.3 修改windows映射
# windows在此路径下,用windows自带的文件管理器打开
C:\Windows\System32\drivers\etc
1.3.4 安装小工具仓库
修改成阿里云镜像源,下载更faster
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repoyum clean all
yum makecache
如果上面这步骤报错:
Trying other mirror. base/7/x86_64/other_db FAILED http://mirrors.aliyuncs.com/centos/7/os/x86_64/repodata/ecaab5cc3b9c10fefe6be2ecbf6f9fcb437231dac3e82cab8d9d2cf70e99644d-other.sqlite.bz2: [Errno 14] curl#7 - "Failed connect to mirrors.aliyuncs.com:80; Connection refused"可以在
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
DNS2=223.5.5.5
# 重启服务
systemctl restart networkyum install -y epel-release1.3.5 关防火墙
systemctl stop firewalld
systemctl disable firewalld.service1.3.6 创建用户(配置集群的时候用非root用户操作)
# 新增用户
useradd zengxiao
passwd zengxiao123456
# 修改用户权限
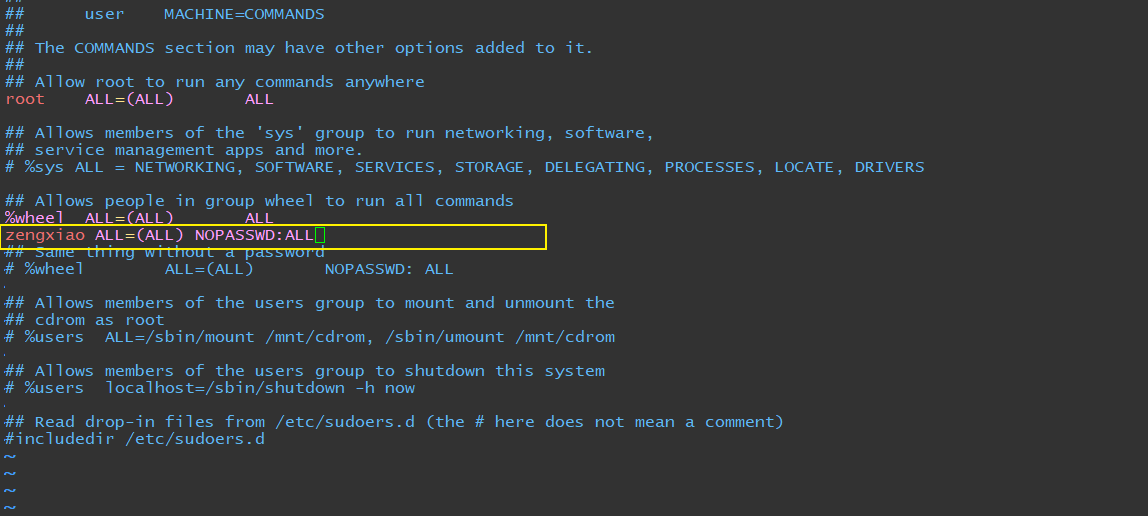
vim /etc/sudoers## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
zengxiao ALL=(ALL) NOPASSWD:ALL
只读文件不让保存,试试:[:wq!]
1.3.7 卸载自带JDK
# 用root账户执行
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps1.3.8 关机并克隆2份
克隆操作,在VMware上完成
shutdown -h now 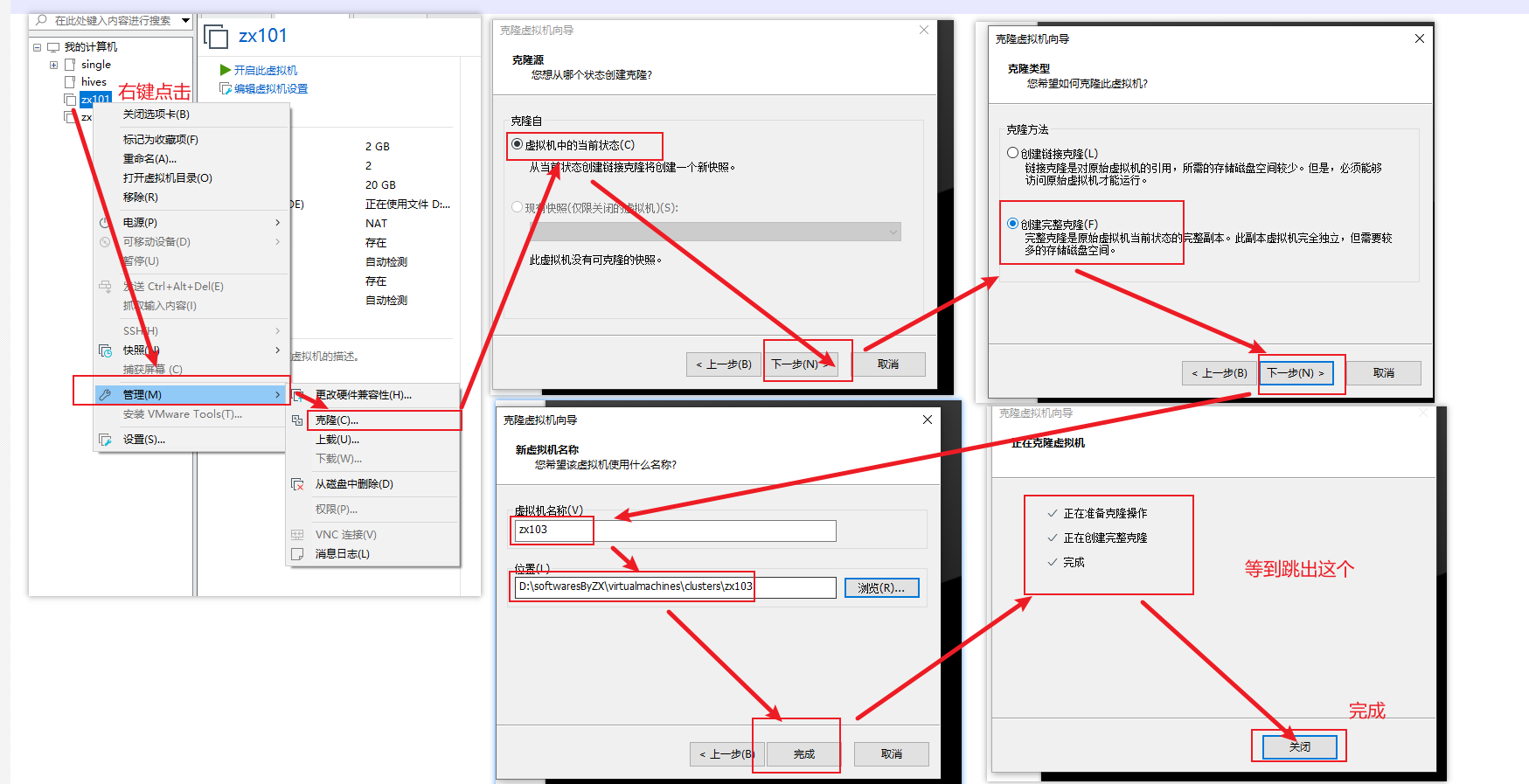
2. 安装Hadoop HA
2.1 修改克隆机器的ip
启动第二、三台机器
vim /etc/hostname
zx102
---------------------------------------
vim /etc/sysconfig/network-scripts/ifcfg-ens33IPADDR=192.168.84.136
重启第二、三台机器
切换账号
非root -> root
su
输入root的密码
root -> 非root
su - zengxiao
2.2 新建文件夹
# 主界面新增文件夹, 非root用户没有权限
mkdir /component
# 把新增文件夹的所有者权限改成指定用户
chown zengxiao:zengxiao -R /component2.3 解压、安装JDK
jdk名字:jdk-8u212-linux-x64.tar.gz
下载地址:Java Archive Downloads - Java SE 8u211 and later
Windows下载好之后,用xftp传输到虚拟机中。
【传输如果显示错误,排查一下,文件夹的所属账户和xftp的账户是否有权限传输!!,修改成同一个账户即可】
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /component/
# 名字太长,改短点
cd /component
mv jdk1.8.0_212/ jdk
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/component/jdk
export PATH=$PATH:$JAVA_HOME/bin
# 刷新
source /etc/profile
# 查看
java -version2.4 解压、安装Hadoop
安装包名:hadoop-3.1.3.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz -C /component/
# 改名字
mv hadoop-3.1.3/ hadoop
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/component/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 刷新
source /etc/profile
# 查看版本
hadoop version2.5 解压、安装zookeeper
安装包名:apache-zookeeper-3.7.2-bin.tar.gz
tar -zxvf apache-zookeeper-3.7.2-bin.tar.gz -C /component/
# 改名
cd ..
mv apache-zookeeper-3.7.2-bin/ zookeeper
# 其他修改
cd zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/component/zookeeper/tmp/
server.1=zx101:2888:3888
server.2=zx102:2888:3888
server.3=zx103:2888:3888
# 创建data目录
cd /component/zookeeper
mkdir data
cd tmp
echo 1 > myid # 在第二节点 echo 2 > myid;第三个第四个
# 修改环境变量
#ZOOKEEPER
export ZOOKEEPER_HOME=/component/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin改之前(如图)

改之后(如图)

2.6 配置免密登录
# 在每一台机器上运行以下3行
ssh zx101
ssh zx102
ssh zx103
# exit回本机.
# 都执行完之后, 在每个/home/用户名/.ssh文件夹下生成一个know_hosts文件, 里面有每个机器的一条信息(本机也有)
# 进入.ssh目录
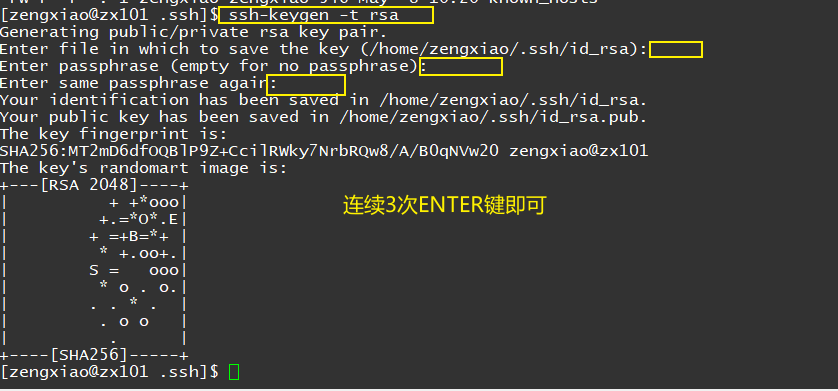
cd ~/.ssh
ssh-keygen -t rsa
# 在每个机器上, 不要一次性输入, 因为每次都要输入密码
ssh-copy-id zx101
ssh-copy-id zx102
ssh-copy-id zx103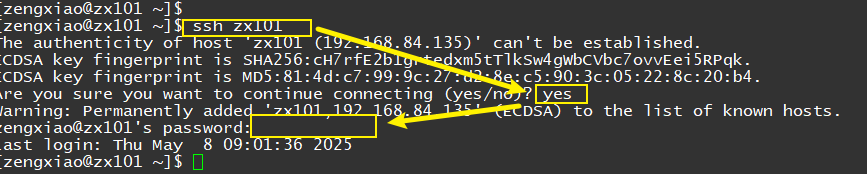
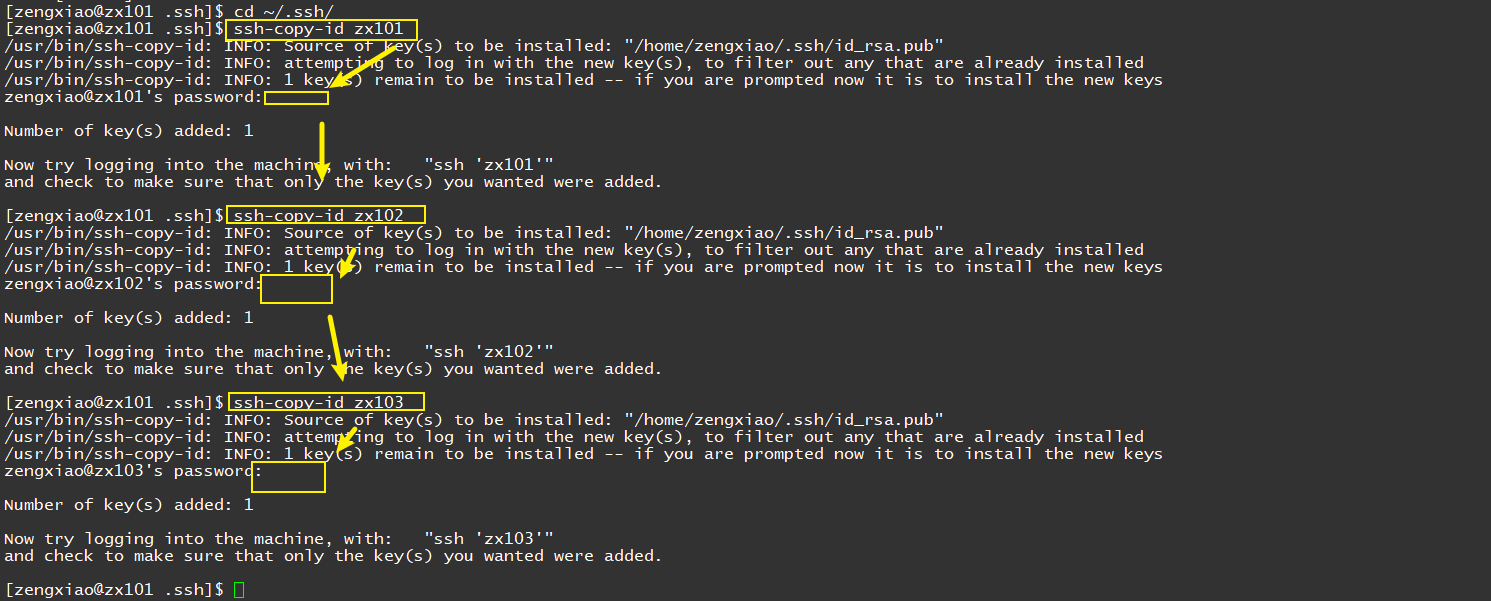

2.7 分发脚本xsync
cd ~/bin
vim xsync # 把下面代码复制进去,保存退出
【如果机器名不同,要修改zx101那一坨】
chmod +x xsync
好了
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in zx101 zx102 zx103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done1. 分发环境变量文件,root账户的文件,要特殊命令,sudo
sudo ~/bin/xsync /etc/profile.d/my_env.sh
# 去其他节点瞅一眼
2. 在其他两个节点创建/component目录
cd /
sudo mkdir component
sudo chown zengxiao:zengxiao -R component
3. 把zx101的component所有内容,都xsync一下,非常fast。
xsync zookeeper
xsync hadoop
xsync jdk
4. 修改Zookeeper的myid
vim /component/zookeeper/data/myid
2
5. 验证环境变量生效否
hadoop version
java -version
【zookeeper验证命令,我也不知】
2.8 集群节点预设
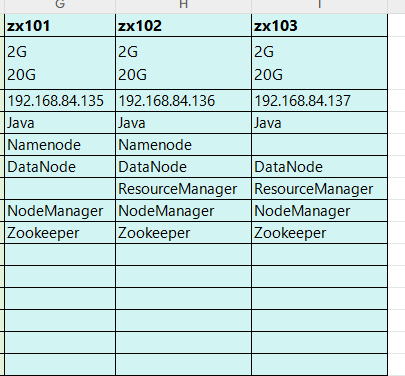
2.9 修改Hadoop配置文件(HA)
cd /component/hadoop/etc/hadoop/
vim core-site.xml
......
这些配置完,不要直接启动Hadoop,还要初始化Zookeeper,Hadoop之后,再启动。耐心一步步来。
2.9.1 core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopHA:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///component/hadoop/data</value>
</property>
<!--指定自动故障转移的集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>zx101:2181,zx102:2181,zx103:2181</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为zengxiao -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>zengxiao</value>
</property>
2.9.2 hdfs-site.xml
<!--配置HDFS块的副本数(全分布式默认副本为3,最大副本512)-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--配置HDFS元数据的存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///component/hadoop/tmp/dfs/name</value>
</property>
<!--配置HDFS真正的数据内容(数据块)的存储目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///component/hadoop/tmp/dfs/data</value>
</property>
<!--配置虚拟服务名-->
<property>
<name>dfs.nameservices</name>
<value>hadoopHA</value>
</property>
<!--为虚拟服务指定两个NameNode(目前每个服务器最多两个NameNode)-->
<property>
<name>dfs.ha.namenodes.hadoopHA</name>
<value>nn1,nn2</value>
</property>
<!--配置NameNode(nn1)的RPC地址,这里默认值是8020,在core-site.xml中也能设置-->
<property>
<name>dfs.namenode.rpc-address.hadoopHA.nn1</name>
<value>zx101:9000</value>
</property>
<!--配置NameNode(nn2)的RPC地址-->
<property>
<name>dfs.namenode.rpc-address.hadoopHA.nn2</name>
<value>zx102:9000</value>
</property>
<!--配置NameNode(nn1)的HTTP地址-->
<property>
<name>dfs.namenode.http-address.hadoopHA.nn1</name>
<value>zx101:9870</value>
</property>
<!--配置NameNode(nn2)的HTTP地址-->
<property>
<name>dfs.namenode.http-address.hadoopHA.nn2</name>
<value>zx102:9870</value>
</property>
<!--配置JournalNode通信地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://zx101:8485;zx102:8485;zx103:8485/hadoopHA</value>
</property>
<!--配置NameNode出现故障时,启用备用NameNode的代理-->
<property>
<name>dfs.client.failover.proxy.provider.hadoopHA</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置防止脑裂的手段,shell脚本-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<!-- 配置 DataNode 的 HTTP 端口(默认 9864) -->
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:9864</value>
</property>
<!-- 配置 DataNode 的 HTTPS 端口(默认 9865) -->
<property>
<name>dfs.datanode.https.address</name>
<value>0.0.0.0:9865</value>
</property>
2.9.3 yarn-site.xml
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>zx102</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>zx103</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zx101:2181,zx102:2181,zx103:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2.9.4 mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>zx101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>zx101:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
2.9.5 workers
# 配置worker
vim /component/hadoop/etc/hadoop/workers
zx101
zx102
zx1032.9.6 修改的内容,分发
cd /component/hadoop/etc/hadoop
xsync ./*
完了,去其他节点cat一下
2.10 初始化zookeeper,hadoop
1. zookeeper初始化
/component/zookeeper/bin/zkServer.sh start # 在每个节点上启动
hdfs zkfc -formatZK # 任意namenode节点上,初始化

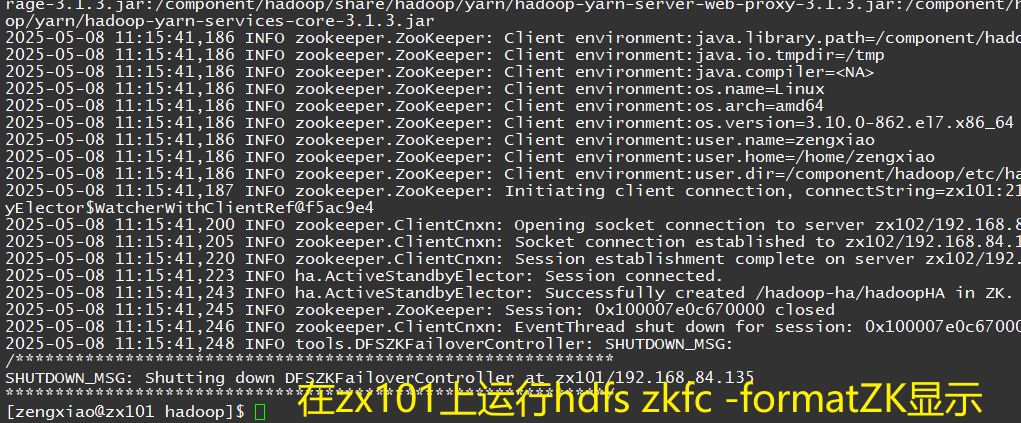
2. Hadoop初始化
hdfs --daemon start journalnode # 在所有的节点上运行(包括namenode,datanode)
hdfs namenode -format # 在设置的nn1节点上运行
hdfs --daemon start namenode # 在设置的nn1节点上运行
hdfs namenode -bootstrapStandby # 在设置的nn2节点上运行
hdfs --daemon start namenode # 在设置的nn2节点上运行【进行到这一步时,会发现两个NN都是standby】(hdfs haadmin -getServiceState nn1,使用这个命令可以看到)
/component/hadoop/sbin/start-all.sh #【执行完这一步,再去看网页,只有一个standby了。Linux命令:hdfs haadmin -getServiceState nn1】
可以去"http://zx101:9870"看看webui界面了。
2.11 一键启动代码
zookeeper.sh
hadoop.sh
jpsall
2.11.1 jpsall
#!/bin/bash
for host in zx101 zx102 zx103
do
echo =============== $host ===============
ssh $host jps
done2.11.2 zookeeper.sh
#!/bin/bash
for host in zx101 zx102 zx103
do
case $1 in
"start"){
echo " "
echo "--------------- 启 动 zookeeper ---------------"
echo "------------ $host zookeeper -----------"
ssh $host "source ~/.bash_profile; zkServer.sh start"
};;
"stop"){
echo " "
echo "--------------- 关 闭 zookeeper ---------------"
echo "------------ $host zookeeper -----------"
ssh $host "source ~/.bash_profile; zkServer.sh stop"
};;
"status"){
echo " "
echo "-------------- 查看zookeeper状态 --------------"
echo "------------ $host zookeeper -----------"
ssh $host "source ~/.bash_profile; zkServer.sh status"
};;
esac
done2.11.3 hadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh zx101 "/component/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh zx102 "/component/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh zx101 "/component/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh zx101 "/component/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh zx102 "/component/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh zx101 "/component/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac2.11.4 一键关机所有节点
vim allshutdown
zx101节点要留在最后面
#!/bin/bash
for host in zx103 zx102 zx101
do
echo =============== $host ===============
ssh $host sudo shutdown -h now
done3. 异常情况
3.1 HA挂了,重启
# 停止所有hadoop进程
/component/hadoop/sbin/stop-dfs.sh
/component/hadoop/sbin/stop-yarn.sh
hadoop-daemon.sh stop journalnode -- 执行前, 先jps一下
# 在所有节点上备份hadoop的软件文件以及数据文件
cp /component/hadoop /component/hadoop_backup
# 进入决定丢弃元数据节点的current目录.
# 测试时, 丢弃了hadoop101的元数据, 从hadoop102中拉取元数据
cd /component/hadoop/tmp/dfs/name/current
# 进入hadoop101元数据目录, 全部删除
rm -rf ./*
# 在hadoop102节点上把元数据导入过来
cd /component/hadoop/tmp/dfs/name/current # 在hadoop102节点执行
ll # 查看hadoop102节点文件的事务ID是否连续且完整
scp ./* zengxiao@hadoop101:/component/hadoop/tmp/dfs/name/current/
# 正常启动集群
hadoop/sbin/start-dfs.shnamenode日志阅读方法
# 转换为可读模式
hdfs oiv -i /某目录/fsimage_000xxx_active -o fsimage_active_output.xml -p XML
hdfs oiv -i /某目录/fsimage_000xxx_standby -o fsimage_standby_output.xml -p XML
# 转换成txt格式,把所有目录和文件的信息列出来
hdfs oiv -i fsimage_000xxx_active -o /某/fsimage_000xxx_active -p Delimited
hdfs oiv -i fsimage_000xxx_standby -o /某/fsimage_000xxx_standby -p Delimited
# 简要信息,文件区间及个数,文件夹数,块数,总空间,最大文件
hdfs oiv -i fsimage_000xxx_active -o /某/fsimage_000xxx_active -p FileDistribution
hdfs oiv -i fsimage_000xxx_standby -o /某/fsimage_000xxx_standby -p FileDistribution
# 比较两个Fsimage, 原则
# 1. 谁的事务ID越大, 谁更全
# 2. 谁的数据块信息越多, 谁更全3.2 如果zookeeper异常了,把/component/zookeeper全删了,重新安装
3.3 如果Hadoop异常了,把Hadoop的元数据和Journalnode目录下的全删了,重新初始化即可。
【遇到启动不起来的,去hadoop/logs/目录下看具体的报错信息,针对性处理。】
【最简单的方法,卸了重装】
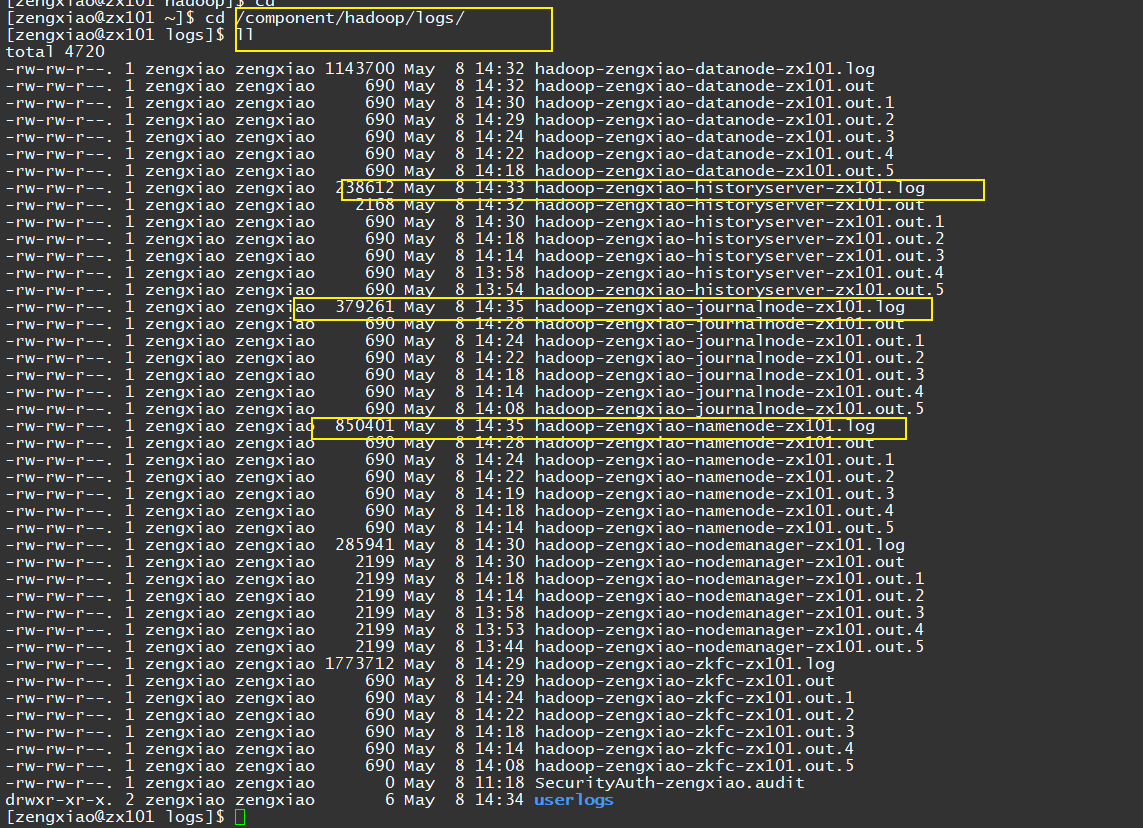
JournalNode
historyserver
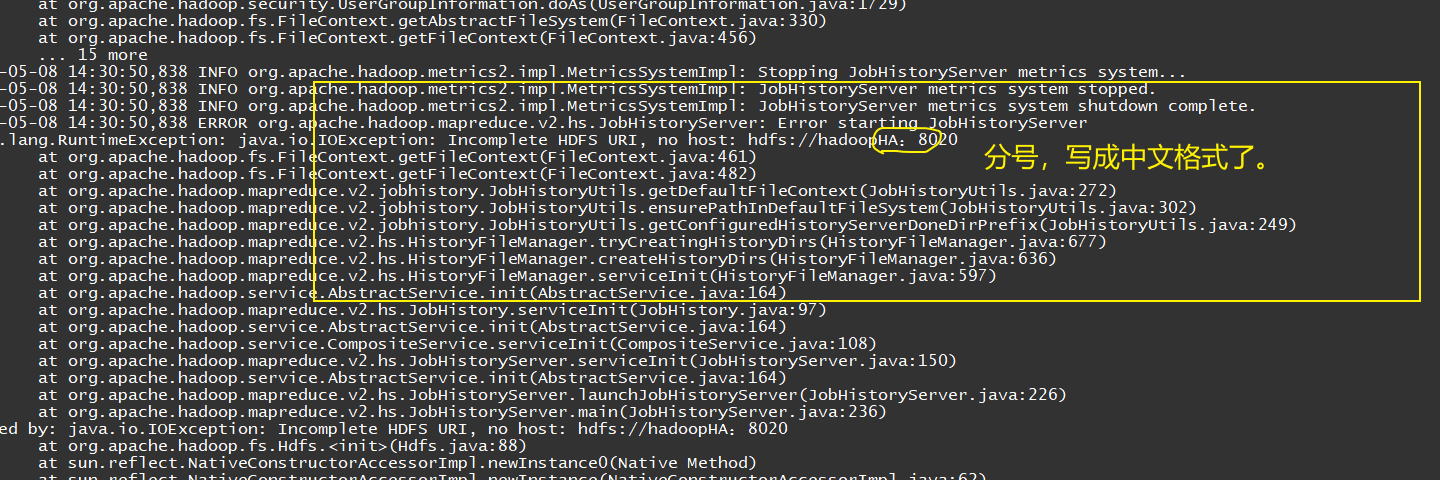
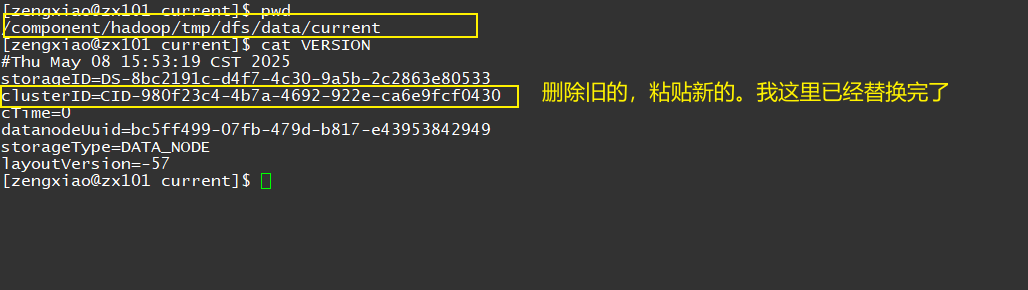
3.4 NN重新初始化,导致DN和NN的clusterID不一致。
找到NN的clusterID
cd /component/hadoop/tmp/dfs/name/current
cat VERSION
修改每个DN节点的VERSION的clusterID
cd /component/hadoop/tmp/dfs/data/current
vim VERSION


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)