Qwen3.5多卡微调全流程(非常详细),大模型训练与部署从入门到精通,收藏这一篇就够了!
2卡分布式训练专用教程:环境搭建 → 数据准备 → 2卡 LoRA 微调 → 推理测试 → 部署上线
基于 MS-SWIFT 框架 | DeepSpeed ZeRO-2 | 每个参数详细解释 | 复制即用
第一步:环境准备
亲测可用:以下环境配置已在实际项目中验证通过
1.1 创建 Conda 环境
# 创建新环境conda create -n swift python=3.11 -y# 激活环境conda activate swift
1.2 安装核心依赖
根据官方文档,Qwen3.5 需要安装以下依赖:
# MS-SWIFTpip install uv uv pip install -U ms-swift# Transformers 和相关库uv pip install -U "transformers==5.2.0""qwen_vl_utils>=0.0.14" peft liger-kernel# Flash-Linear-Attention(请安装 main 分支)uv pip install -U git+https://github.com/fla-org/flash-linear-attention# Causal-Conv1dpip install -U git+https://github.com/Dao-AILab/causal-conv1d --no-build-isolation# Flash-Attention (可以跳过安装,不安装也能训练,这个安装需要耗时3小时,建议跳过)uv pip install "flash-attn==2.8.3" --no-build-isolation# DeepSpeed(多卡训练必须安装)uv pip install deepspeed# vLLM(可选,推理/部署时需要),这个可以暂时不安装uv pip install -U "vllm>=0.17.0"# 再安装一遍,防止 vllm的版本把这个覆盖掉;uv pip install transformers==5.2.0
重要提示:
- ⚠️
transformers==5.3.0目前会报错,已实测验证- ✅ 推荐使用
transformers==5.2.0版本- 如果安装了 vLLM,训练需要覆盖 vLLM 默认版本,再次安装一遍:
uv pip install -U "transformers==5.2.0"- 🔥 多卡训练必须安装 DeepSpeed
1.3 验证安装
# 查看 swift 命令行工具swift sft --help# 如果能显示帮助信息,说明安装成功# 验证 DeepSpeed 安装ds_report# 应该显示 DeepSpeed 版本和 CUDA 信息
验证成功示例:

数据集准备
支持的数据格式
MS-SWIFT 支持多种数据格式,以下是常用的文本数据格式。
1. 纯文本数据
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "介绍一下杭州"}, {"role": "assistant", "content": "杭州是浙江省省会..."}]}
2. 多轮对话数据
{"messages": [{"role": "system", "content": "你是一个专业的AI助手"}, {"role": "user", "content": "什么是机器学习?"}, {"role": "assistant", "content": "机器学习是人工智能的一个分支..."}, {"role": "user", "content": "它有哪些应用?"}, {"role": "assistant", "content": "机器学习广泛应用于图像识别、自然语言处理、推荐系统等领域..."}]}
说明:
- 支持多轮对话历史
system角色可选,用于设置助手行为- 对话轮次不限
3. Agent 工具调用数据(常用)
{"messages": [{"role": "user", "content": "帮我查一下北京今天的天气"}, {"role": "assistant", "content": "好的,我来帮你查询北京的天气信息。"}, {"role": "tool_call", "content": "{\"name\": \"get_weather\", \"arguments\": {\"city\": \"北京\"}}"}, {"role": "tool_response", "content": "{\"temperature\": \"15°C\", \"condition\": \"晴\"}"}, {"role": "assistant", "content": "北京今天的天气是晴天,温度15°C。"}], "tools": [{"type": "function", "function": {"name": "get_weather", "description": "获取指定城市的天气信息", "parameters": {"type": "object", "properties": {"city": {"type": "string", "description": "城市名称"}}, "required": ["city"]}}}]}
说明:
tool_call: 模型调用工具的请求tool_response: 工具返回的结果tools: 可用工具列表(函数定义)- 支持多次工具调用和多个工具
使用内置数据集
MS-SWIFT 提供了 150+ 内置数据集,可直接使用:
# 常用数据集AI-ModelScope/alpaca-gpt4-data-zh # 中文指令数据AI-ModelScope/alpaca-gpt4-data-en # 英文指令数据swift/self-cognition # 自我认知数据AI-ModelScope/LaTeX_OCR:human_handwrite # LaTeX OCR 数据
数据集采样语法:
# 基本格式:数据集id:子数据集#采样数量--dataset AI-ModelScope/alpaca-gpt4-data-zh#500# 多个数据集--dataset AI-ModelScope/alpaca-gpt4-data-zh#500 \ AI-ModelScope/alpaca-gpt4-data-en#500 \ swift/self-cognition#500# 使用子数据集--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#2000
自定义数据集
将数据保存为 .jsonl 格式,在训练时指定:
--dataset train.jsonl --val_dataset val.jsonl
2卡训练快速开始
本教程提供完整的2卡训练脚本,所有参数都有详细解释。如需了解更多参数配置,请参考后文的"参数详细解释"部分。
完整多卡训练脚本示例
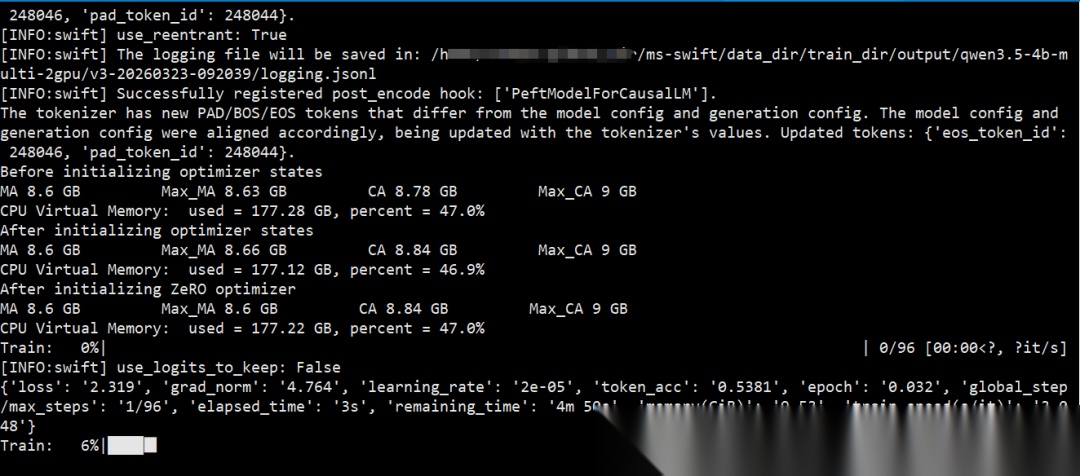
⭐ 核心部分:以下是完整的可运行多卡训练脚本,包含详细的训练过程截图展示
示例 1: 基础多卡 LoRA 微调(2卡,入门推荐)
#!/bin/bash# 2卡训练脚本 - 使用 DeepSpeed ZeRO-2# 数据集参数说明请参考前文"数据集准备"章节export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:TrueNCCL_P2P_DISABLE=1 \NPROC_PER_NODE=2 \CUDA_VISIBLE_DEVICES=0,1 \swift sft \ --model Qwen/Qwen3.5-4B \ --dataset AI-ModelScope/alpaca-gpt4-data-zh#2000 \ --tuner_type lora \ --lora_rank 16 \ --lora_alpha 32 \ --target_modules all-linear \ --torch_dtype bfloat16 \ --deepspeed zero2 \ --num_train_epochs 3 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 4 \ --learning_rate 1e-4 \ --warmup_ratio 0.05 \ --max_length 2048 \ --gradient_checkpointing true \ --output_dir output/qwen3.5-4b-multi-2gpu \ --logging_steps 10 \ --save_steps 200 \ --eval_steps 200 \ --save_total_limit 3
参数详细解释
环境变量配置
| 参数 | 含义 | 说明 |
|---|---|---|
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True |
PyTorch CUDA 内存分配优化 | 强烈推荐 :启用可扩展内存段,避免显存碎片化导致的OOM错误。PyTorch 2.0+必备 |
NCCL_P2P_DISABLE=1 |
禁用 NCCL P2P 通信 | 某些GPU拓扑结构下P2P通信可能不稳定,禁用后使用更稳定的通信方式 |
NPROC_PER_NODE=2 |
每个节点的进程数 | 指定使用2个GPU,每个GPU对应1个训练进程 |
CUDA_VISIBLE_DEVICES=0,1 |
可见的GPU设备 | 指定使用GPU 0和1进行训练 |
模型和数据参数
| 参数 | 含义 | 说明 |
|---|---|---|
--model Qwen/Qwen3.5-4B |
模型路径 | 指定要微调的基础模型,可以是ModelScope ID或本地路径 |
--dataset AI-ModelScope/alpaca-gpt4-data-zh#2000 |
训练数据集 | 使用alpaca中文数据集,采样2000条数据。格式:数据集ID#采样数量 |
LoRA 微调参数
| 参数 | 含义 | 说明 |
|---|---|---|
--tuner_type lora |
微调方法 | 使用LoRA(Low-Rank Adaptation)进行参数高效微调 |
--lora_rank 16 |
LoRA秩 | 低秩矩阵的秩,控制LoRA参数量。值越大效果越好但参数越多,推荐8-32 |
--lora_alpha 32 |
LoRA缩放系数 | 控制LoRA权重的缩放,通常设为rank的2-4倍,影响学习强度 |
--target_modules all-linear |
应用LoRA的模块 | 对所有线性层应用LoRA,覆盖范围最广,效果最好 |
训练精度和优化
| 参数 | 含义 | 说明 |
|---|---|---|
--torch_dtype bfloat16 |
模型数据类型 | 使用bfloat16混合精度训练,节省显存且训练稳定。如GPU不支持可改为float16 |
--deepspeed zero2 |
DeepSpeed配置 | 使用ZeRO-2优化,将优化器状态和梯度分片到多卡,节省显存30-40% |
--gradient_checkpointing true |
梯度检查点 | 通过重计算中间激活值节省显存,可降低显存占用30-40%,训练速度略慢10% |
训练超参数
| 参数 | 含义 | 说明 |
|---|---|---|
--num_train_epochs 3 |
训练轮数 | 完整遍历数据集的次数,3轮通常足够,过多可能过拟合 |
--per_device_train_batch_size 2 |
每卡批次大小 | 每个GPU每次处理2个样本,显存不足可降为1 |
--gradient_accumulation_steps 4 |
梯度累积步数 | 累积4次梯度后更新参数,等效批次=2×4×2=16 |
--learning_rate 1e-4 |
学习率 | LoRA推荐1e-4,控制参数更新幅度,过大不稳定,过小收敛慢 |
--warmup_ratio 0.05 |
预热比例 | 前5%步数学习率线性增长,帮助训练初期稳定 |
--max_length 2048 |
最大序列长度 | 单个样本最大token数,超过会被截断,显存不足可降为1024 |
保存和日志参数
| 参数 | 含义 | 说明 |
|---|---|---|
--output_dir output/qwen3.5-4b-multi-2gpu |
输出目录 | 保存模型检查点、日志等文件的目录 |
--logging_steps 10 |
日志记录间隔 | 每10步记录一次训练指标(loss、学习率等) |
--save_steps 200 |
保存间隔 | 每200步保存一次模型检查点 |
--eval_steps 200 |
评估间隔 | 每200步在验证集上评估一次(需要有验证集) |
--save_total_limit 3 |
最多保存检查点数 | 只保留最新的3个检查点,节省磁盘空间 |
关键配置说明
有效批次大小计算:
有效批次 = per_device_train_batch_size × gradient_accumulation_steps × GPU数量 = 2 × 4 × 2 = 16
显存占用估算(Qwen3.5-4B + LoRA):
- 基础配置:约18-20GB/卡
- 启用梯度检查点:约12-14GB/卡
- 使用ZeRO-2:约10-12GB/卡
提示:
- 如果GPU不支持bfloat16(如GTX系列),将
--torch_dtype bfloat16改为--torch_dtype float16- 如果显存不足,可以降低
per_device_train_batch_size为1,或降低max_length为1024
推理部署
命令行推理
基础推理
CUDA_VISIBLE_DEVICES=0 \swift infer \ --adapters output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-xxx \ --stream true \ --max_new_tokens 512
推理参数说明
| 参数 | 说明 | 默认值 | 示例 |
|---|---|---|---|
--adapters |
LoRA 权重路径 | [] | output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-200 |
--stream |
流式输出 | None | true |
--max_new_tokens |
最大生成 token 数 | None | 512 , 1024 |
--temperature |
温度参数 | 从 config 读取 | 0.7 , 0 (确定性) |
--top_k |
Top-K 采样 | None | 50 |
--top_p |
Top-P 采样 | None | 0.9 |
--enable_thinking |
开启思考模式 | None | false |
--load_data_args |
加载训练时的数据参数 | False | true (验证集推理) |
推理技巧:
- 确定性输出:
--temperature 0或--top_k 1 - 验证集推理:
--load_data_args true会自动加载训练时切分的验证集
Python 推理
import osos.environ['CUDA_VISIBLE_DEVICES'] = '0'from peft import PeftModelfrom swift import get_model_processor, get_templatefrom swift.infer_engine import TransformersEngine, InferRequest, RequestConfig# 加载模型和 LoRAadapter_dir = 'output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-xxx'model, processor = get_model_processor('Qwen/Qwen3.5-4B')model = PeftModel.from_pretrained(model, adapter_dir)# 创建模板和引擎template = get_template(processor, enable_thinking=False)engine = TransformersEngine(model, template=template)# 推理infer_request = InferRequest(messages=[{ "role": "user", "content": '你好,你是谁?',}])request_config = RequestConfig(max_tokens=256, temperature=0.7)resp_list = engine.infer([infer_request], request_config=request_config)response = resp_list[0].choices[0].message.contentprint(response)# 流式推理request_config = RequestConfig(max_tokens=256, temperature=0.7, stream=True)gen_list = engine.infer([infer_request], request_config=request_config)for chunk in gen_list[0]: if chunk isNone: continue print(chunk.choices[0].delta.content, end='', flush=True)print()
部署 API 服务
CUDA_VISIBLE_DEVICES=0 \swift deploy \ --adapters output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-xxx \ --served_model_name Qwen3.5-4B-lora \ --port 8025
部署参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
--port |
服务端口 | 8000 |
--host |
服务地址 | 0.0.0.0 |
--api_key |
API 密钥 | None |
注意: 目前 vllm、sglang、lmdeploy 对 Qwen3.5 的 LoRA 加载存在兼容性问题,推荐使用默认的 transformers 后端,等待官方后续修复。
Web 界面
CUDA_VISIBLE_DEVICES=0 \swift app \ --adapters output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-xxx \ --stream true
浏览器打开显示的地址(通常是 http://localhost:7860)即可对话。
常见问题与解决方案
Q1: 多卡训练显存不足 (OOM)
解决方案(按优先级):
-
启用 PyTorch CUDA 内存优化(必备!)
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True为什么必须添加:
实际效果:
-
不启用:训练到一半突然 OOM,显存使用率只有 70%
-
启用后:同样配置可以正常训练完成,显存利用率提升到 95%
-
PyTorch 默认的显存分配器会产生显存碎片化问题
-
即使总显存充足,但由于碎片化导致无法分配连续大块显存,引发 OOM
-
expandable_segments:True启用可扩展内存段,允许 PyTorch 动态扩展内存块 -
特别是在多卡训练、DeepSpeed、梯度检查点等场景下,显存碎片化问题更严重
-
PyTorch 2.0+ 强烈推荐启用,可以避免 90% 的显存碎片化 OOM 问题
-
使用 DeepSpeed ZeRO-3
--deepspeed zero3 -
启用梯度检查点
--gradient_checkpointing true -
减小批次大小
--per_device_train_batch_size 1 \--gradient_accumulation_steps 8 -
使用 Liger Kernel
--use_liger_kernel true -
降低最大长度
--max_length 1024 -
CPU Offload(自定义 DeepSpeed 配置)
"offload_optimizer": { "device": "cpu", "pin_memory": true}
Q2: 多卡训练速度慢
加速方法:
-
增加每卡批次大小
--per_device_train_batch_size 4 \--gradient_accumulation_steps 2 -
使用 bf16 精度
--torch_dtype bfloat16 -
使用数据缓存
--load_from_cache_file true \--dataset_num_proc 16 -
优化 DeepSpeed 配置
- 使用 ZeRO-2 而非 ZeRO-3(如果显存足够)
- 启用通信优化:
overlap_comm: true
-
安装 Flash Attention
pip install flash-attn --no-build-isolation
Q3: GPU 利用率不均衡
解决方案:
-
检查数据分布
--dataset_shuffle true \--group_by_length true -
使用 DeepSpeed ZeRO-3
- 自动平衡各卡负载
- 检查 CUDA_VISIBLE_DEVICES
- 确保指定的 GPU 都可用
Q4: 训练效果不好
调优建议:
-
增加数据量(多卡可用更多数据)
--dataset AI-ModelScope/alpaca-gpt4-data-zh#5000 -
增加训练轮数
--num_train_epochs 5 -
调整学习率
--learning_rate 5e-5 \--warmup_ratio 0.1 -
增大 LoRA rank(多卡显存充足)
--lora_rank 64 -
使用 DoRA
--use_dora true
Q5: 如何断点续训
swift sft \ --resume_from_checkpoint output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-200 \ <其他参数保持不变>
注意:
- 保持其他参数不变,包括 GPU 数量和 DeepSpeed 配置
- 会自动加载优化器状态和随机种子
- 从上次的步数继续训练
Q6: 如何合并 LoRA 权重
swift export \ --adapters output/qwen3.5-4b-multi-2gpu/vx-xxx/checkpoint-200 \ --merge_lora true \ --output_dir output/qwen3.5-4b-merged
Q7: DeepSpeed 初始化失败
常见原因和解决方案:
-
未安装 DeepSpeed
pip install deepspeed -
CUDA 版本不兼容
# 检查 CUDA 版本nvcc --version# 重新安装对应版本的 DeepSpeed -
环境变量问题
export CUDA_HOME=/usr/local/cudaexport PATH=$CUDA_HOME/bin:$PATH
训练监控
TensorBoard
# 安装pip install tensorboard# 启动tensorboard --logdir output/qwen3.5-4b-multi-2gpu# 浏览器打开http://localhost:6006
SwanLab
swift sft \ --report_to swanlab \ --swanlab_token your_token \ --swanlab_project qwen3.5-multi-gpu-training \ <其他参数>
性能参考
Qwen3.5-4B LoRA 多卡训练性能
| GPU配置 | 批次大小 | 显存占用/卡 | 训练速度 |
|---|---|---|---|
| 2卡 + ZeRO-2 | 2×4×2=16 | ~16GB | ~200 samples/s |
| 4卡 + ZeRO-2 | 2×4×4=32 | ~14GB | ~400 samples/s |
| 8卡 + ZeRO-2 | 4×2×8=64 | ~12GB | ~800 samples/s |
| 4卡 + ZeRO-3 | 1×8×4=32 | ~10GB | ~350 samples/s |
DeepSpeed 优化效果
| 配置 | 显存节省 | 速度影响 | 适用场景 |
|---|---|---|---|
| ZeRO-2 | 30-40% | 基准 | 2-8卡常规训练 |
| ZeRO-3 | 50-60% | 略慢 10-15% | 大模型或显存不足 |
| ZeRO-2 + CPU Offload | 40-50% | 略慢 20% | 显存紧张 |
| ZeRO-3 + CPU Offload | 60-70% | 略慢 30% | 超大模型 |
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献196条内容
已为社区贡献196条内容

所有评论(0)