揭开LoRA微调的神秘面纱:推理时,LoRA究竟是怎么起作用的?
在当前的大模型(LLM)时代,LoRA (Low-Rank Adaptation) 几乎成了微调(Fine-tuning)的代名词。无论你是用Stable Diffusion画图,还是微调Llama、Qwen等文本模型,你最终都会得到一个几十MB到几百MB不等的“LoRA权重文件夹”。
很多初学者都有一个疑问:我的基础模型有几十GB,这个保存在硬盘上的小小LoRA文件,在最终做推理(生成文本/图像)时,到底是怎么加载的?它在什么时候发挥了作用?
今天,我们就从通俗比喻、数学理论、文件结构到实战代码,把这个问题彻底掰扯清楚。
一、 通俗理解:游戏本体与DLC扩展包
在深入枯燥的理论之前,我们先打个比方。
把基础模型(Base Model)想象成一个庞大的《上古卷轴5》游戏本体(几十个GB)。它包含了所有的基础世界观、物理引擎和NPC对话逻辑。
把LoRA模型想象成一个保存在你硬盘上的**“二次元人物替换Mod扩展包”**(几十个MB)。
在推理(玩游戏)时,你有两种方式让硬盘上的这个Mod起作用:
- 外挂模式(动态加载):游戏本体文件不动。游戏启动时,Mod引擎读取硬盘上的Mod文件。每次游戏渲染人物时,引擎会“拦截”指令,把二次元人物的贴图动态叠加到原来的模型上。
- 打补丁模式(权重合并):在游戏启动前,用一个工具直接把硬盘上的Mod文件写入并覆盖到几十GB的游戏本体中。之后你玩的就是一个全新的魔改版游戏,不再需要Mod文件了。
LoRA的推理,完全对应这两种模式。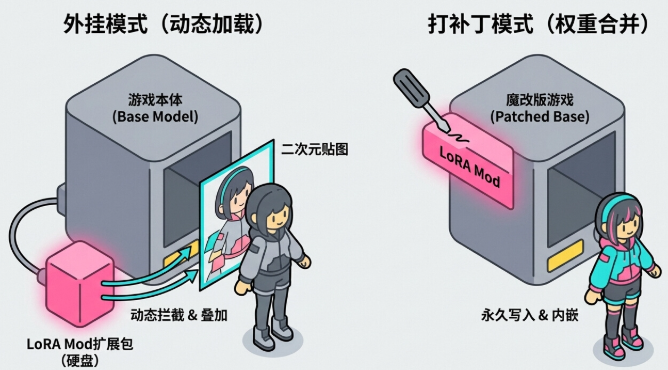
二、 核心理论:LoRA到底改变了什么?
在大模型中,发挥作用最多的是线性层(Linear Layer)。基础模型的每一次计算,本质上是矩阵乘法:
h=W0⋅x h = W_0 \cdot x h=W0⋅x
(其中 xxx 是输入,W0W_0W0 是基础模型冻结的权重,hhh 是输出)
LoRA并没有直接修改基础权重 W0W_0W0,而是旁路增加了两个小型的低秩矩阵 AAA 和 BBB。在推理时,LoRA是这样起作用的:
h=W0⋅x+(B⋅A⋅x)×αr h = W_0 \cdot x + (B \cdot A \cdot x) \times \frac{\alpha}{r} h=W0⋅x+(B⋅A⋅x)×rα
图文解析:LoRA的前向传播路径
我们可以用下面这个流程图来看看,当一个词的向量(Input X)进入模型时,发生了什么:
(图解:蓝色部分即为LoRA起作用的路径。两者同时计算,并在该层的末端将结果相加)
三、 深入文件:LoRA保存在哪?怎么加载的?
当你训练完一个LoRA模型并保存后,你的硬盘上通常会多出一个文件夹(例如叫 my_lora_model),里面通常只有两个核心文件:
adapter_config.json:说明书。记录了这个LoRA的参数(如秩r=8)、缩放系数alpha,以及它需要挂载到基础模型的哪些层(比如只挂载到q_proj和v_proj注意力层)。adapter_model.safetensors(或.bin):实体权重。这里面只保存了上述公式中 AAA 矩阵和 BBB 矩阵的具体数值。所以它特别小,只有十几MB。
Hugging Face 是怎么加载它的?
当你在代码中调用 PeftModel.from_pretrained(base_model, "my_lora_model") 时,框架做了以下几件事:
- 查阅说明书:读取
json文件,得知要去寻找基础模型中的q_proj和v_proj层。 - 结构改造:把基础模型原有的
nn.Linear替换成一个特制的lora.Linear(这个特制层包含了原权重和旁路分支)。 - 注入灵魂:把
safetensors文件里的 AAA 和 BBB 矩阵的数值,填入到刚刚建好的旁路分支中。
四、 实战代码演练 (完整流程:保存 -> 加载 -> 推理 -> 合并)
下面是一段完整且可直接运行的 Python 代码。为了真实还原工作流,我们将:先构建一个LoRA并存入硬盘 -> 清空内存 -> 从硬盘加载LoRA做推理 -> 最后做合并。
(选用体积极小的 Qwen2.5-0.5B-Instruct 模型,普通电脑/免费GPU皆可秒跑通)
准备环境
pip install torch transformers peft
完整代码
import torch
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, PeftModel
import time
model_id = "Qwen/Qwen2.5-0.5B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
lora_save_path = "./my_lora_dummy" # LoRA保存在硬盘的路径
# =====================================================================
# 阶段一:模拟训练完毕,将 LoRA 保存到硬盘
# =====================================================================
print("1. 初始化基础模型并生成 LoRA,准备保存到硬盘...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
base_model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
# 构建 LoRA 配置并包裹基础模型
config = LoraConfig(
r=8, lora_alpha=16,
target_modules=["q_proj", "v_proj"], # 指定挂载点
bias="none"
)
lora_model_for_train = get_peft_model(base_model, config)
# 【核心步骤】:将 LoRA 单独保存到本地文件夹!
# 这时硬盘上会生成 adapter_config.json 和 adapter_model.safetensors
lora_model_for_train.save_pretrained(lora_save_path)
print(f"✅ LoRA 已保存至硬盘目录: {os.path.abspath(lora_save_path)}")
# 清空内存,模拟我们是在第二天重新打开电脑做推理
del lora_model_for_train
del base_model
if torch.cuda.is_available(): torch.cuda.empty_cache()
# =====================================================================
# 阶段二:真实的推理场景(从硬盘加载 LoRA)-- 动态外挂模式
# =====================================================================
print("\n2. 模拟真实推理场景:加载基础模型 + 从硬盘加载 LoRA...")
prompt = "请用一句话解释什么是黑洞。"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 1. 先加载纯净的基础模型
clean_base_model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
# 2. 【核心步骤】:使用 PeftModel 从硬盘读取 LoRA 并动态挂载
# 此时,框架会读取 adapter_config.json,并把权重注入到 q_proj 和 v_proj 层
lora_model_for_infer = PeftModel.from_pretrained(clean_base_model, lora_save_path)
start = time.time()
with torch.no_grad():
lora_outputs = lora_model_for_infer.generate(**inputs, max_new_tokens=30)
print("\n[LoRA外挂模式输出]:", tokenizer.decode(lora_outputs[0], skip_special_tokens=True))
print(f"耗时: {time.time() - start:.2f}秒 (动态挂载,内存中存在基础+LoRA两套权重)")
# =====================================================================
# 阶段三:部署时的终极方案 -- 权重合并模式 (Merge and Unload)
# =====================================================================
print("\n3. 将 LoRA 权重永久合并进基础模型 (打补丁模式)...")
# 这一步执行了数学上的: W_new = W_base + (B * A) * (alpha/r)
# 并把旁路的 A 和 B 矩阵从内存中摧毁删除
merged_model = lora_model_for_infer.merge_and_unload()
start = time.time()
with torch.no_grad():
merged_outputs = merged_model.generate(**inputs, max_new_tokens=30)
print("\n[合并模式输出]:", tokenizer.decode(merged_outputs[0], skip_special_tokens=True))
print(f"耗时: {time.time() - start:.2f}秒 (合并后,速度恢复至最快,结构变回普通模型)")
# 验证合并后的模型是否彻底剥离了peft依赖
print(f"\n当前模型类型是否还是PeftModel? {isinstance(merged_model, PeftModel)}")
# 输出将是 False,它完全变回了普通的 HuggingFace 基础模型!
你可以在本地观察到的现象:
运行代码后,去你的项目目录下看看,会多出一个 my_lora_dummy 文件夹。打开它,你能清晰地看到 json 配置文件和 safetensors 权重文件。这就是你辛辛苦苦训练出来的“结晶”!
总结
现在,你应该彻底明白LoRA在推理时是怎么运作的了:
- 它保存在哪里? 保存在硬盘上的一个小文件夹里,由配置文件(去哪挂载)和低秩权重(具体的数值 A,BA, BA,B)组成。
- 它怎么加载? 通过
PeftModel.from_pretrained(),框架根据配置文件,在基础模型的特定层(如Attention)动态创建旁路计算分支,并填入权重。 - 它什么时候起作用?
- 如果是动态外挂(代码阶段二):在生成每一个Token的瞬间,基础模型和LoRA会同时计算,并把结果相加。极度灵活,可随时插拔,但稍微拖慢一点点速度。
- 如果是权重合并(代码阶段三):在推理正式开始前,执行矩阵加法 Wnew=W0+B⋅AW_{new} = W_0 + B \cdot AWnew=W0+B⋅A。合并后,LoRA 结构消失,完全化作了基础模型的一部分,推理速度最快。vLLM等推理引擎通常使用这种方式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)