From Local to Global: A GraphRAG Approach to Query-Focused Summarization
题目:从局部到全局:一种基于 GraphRAG 的聚焦于查询的摘要方法
Abstract
检索增强生成(RAG)通过从外部知识源检索相关信息,让大语言模型(LLM)能够对私有或未见过的文档集进行问答。但 RAG 无法回答面向整个文本语料的全局问题(如 “数据集中的核心主题是什么?”),因为这类问题本质属于 ** 查询聚焦摘要(QFS)** 任务,而非显式检索任务。而现有的 QFS 方法又无法扩展到常规 RAG 系统所索引的大规模文本量。
为融合两种方法的优势,本文提出 GraphRAG:一种基于图、适用于私有文本语料的问答方法,能同时适配用户问题的通用性与源文本规模。该方法用大模型分两步构建图索引:
- 从源文档抽取实体知识图谱;
- 为所有紧密关联的实体组预生成社区摘要。
收到问题后,先由每个社区摘要生成局部答案,再将所有局部答案汇总生成最终回答。在百万 token 规模数据集的全局理解类问题上,GraphRAG 在答案的全面性与多样性上显著优于传统 RAG 基线。
1 Introduction
检索增强生成(RAG)(Lewis 等人,2020)是一种成熟的方法,它利用大语言模型(LLM),基于超出模型上下文窗口容量的海量数据来回答查询。上下文窗口指大语言模型单次能处理的最大文本令牌(token)数量(Kuratov 等人,2024;Liu 等人,2023)。
在标准 RAG 架构中,系统可访问大规模外部文本语料库,并从中检索出与查询相关、且整体大小能装进模型上下文窗口的一小部分文本。随后,大语言模型再结合查询与这些检索到的文本生成回答。
(模型)会结合查询语句与检索到的文本片段生成回答(Baumel et al., 2018; Dang, 2006; Laskar et al., 2020; Yao et al., 2017)。我们将这类传统方法统称为向量 RAG,它在处理仅需少量文本片段内的局部信息即可回答的查询时表现良好。然而,向量 RAG 方法无法支持全局理解类查询—— 即需要对整个数据集进行全局理解才能回答的查询,例如:“过去十年间,跨学科研究对科学发现产生影响的关键趋势是什么?”
意义建构任务需要对 “人物、地点与事件之间的关联进行推理,从而预判其发展趋势并采取有效行动”(Klein et al., 2006)。GPT(Achiam et al., 2023; Brown et al., 2020)、Llama(Touvron et al., 2023)、Gemini(Anil et al., 2023)等大语言模型,在科学发现(Microsoft, 2023)、情报分析(Ranade and Joshi, 2023)等复杂领域的意义建构上表现出色。当给定一个意义建构类查询,以及包含隐含且相互关联概念的文本时,大语言模型能够生成回答该查询的摘要。然而,当数据量巨大、需要采用 RAG 方案时,挑战便随之出现 ——向量 RAG 方法无法支持对整个语料库的意义建构。
在本文中,我们提出 GraphRAG—— 一种基于图结构的 RAG 方法,能够对大规模文本语料库进行全局意义建构。GraphRAG 首先利用大语言模型(LLM)构建知识图谱:其中节点对应语料中的关键实体,边代表实体之间的关系。随后,它将图谱划分为由紧密关联实体构成的层级化社区,再利用大语言模型生成社区级摘要。这些摘要按照提取出的社区层级结构自底向上生成,高层级摘要会递归融合低层级摘要内容。这些社区摘要共同提供了对语料库的全局描述与洞察。最后,GraphRAG 通过对社区摘要执行 Map-Reduce(映射 - 归约) 处理来回答查询:
- 在 Map 阶段,各摘要独立并行地为查询生成局部答案;
- 在 Reduce 阶段,将所有局部答案合并,生成最终的全局答案。
GraphRAG 方法及其对整份语料库执行全局意义建构的能力,构成了本文的核心贡献。为验证这一能力,我们对LLM-as-a-judge(大模型裁判) 技术(Zheng et al., 2024)提出了一种新的应用方式,使其适用于那些没有标准答案、面向宽泛议题与主题的问题。该方法首先使用一个大模型,基于语料库的特定应用场景生成多样化的全局意义建构问题;再用第二个大模型,按照预定义标准(见 3.3 节)对两种不同 RAG 系统的答案进行评判。我们借助该方法,在两个具有代表性的真实文本数据集上对比了 GraphRAG 与向量 RAG。结果表明,以 GPT-4 作为大模型时,GraphRAG 显著优于向量 RAG。
GraphRAG 已作为开源软件发布,地址为:https://github.com/microsoft/graphrag。此外,GraphRAG 方法的相关实现也已作为扩展插件集成到多个开源库中,包括 LangChain、LlamaIndex、NebulaGraph 以及 Neo4J。
2 Background
2.1 RAG Approaches and Systems
RAG 通常指一类系统:先根据用户查询从外部数据源中检索相关信息,再将这些信息融入大语言模型(LLM)或其他生成式 AI 模型(如多模态模型),以生成针对该查询的回答。查询与检索到的文本会被填入提示词模板,再送入大语言模型处理(Ram et al., 2023)。当数据源中的文本总量过大、无法全部放入单个提示词时(即数据源文本量超出大语言模型的上下文窗口),RAG 是理想的解决方案。
在标准 RAG 方法中,检索过程会返回与查询在语义上相似的固定数量文本片段,生成的答案仅使用这些检索到的片段中的信息。传统 RAG 的一种常用实现是采用文本嵌入技术,在向量空间中检索与查询最接近的文本 —— 这里的 “接近程度” 对应语义相似度(Gao et al., 2023)。尽管部分 RAG 方法可能使用其他检索机制,我们将这类传统方法统称为向量 RAG。GraphRAG 与向量 RAG 的核心区别在于:它能够回答需要对整个数据语料进行全局意义建构的查询。
GraphRAG 建立在现有先进 RAG 策略的研究基础之上。GraphRAG 将数据源中大规模文本片段的摘要用作一种 “自记忆” 形式(Cheng et al., 2024),后续再像 Mao et al. (2020) 的方法一样利用这些摘要回答查询。这些摘要采用并行生成,并通过迭代方式聚合为全局摘要,这与此前多项技术思路相似(Feng et al., 2023; Gao et al., 2023; Khattab et al., 2022; Shao et al., 2023; Su et al., 2020; Trivedi et al., 2022; Wang et al., 2024)。具体而言,GraphRAG 与其他采用层级索引生成摘要的方法较为接近(类似 Kim et al., 2023; Sarthi et al., 2024)。GraphRAG 与这些方法的不同之处在于:它从源数据中生成图索引,再通过基于图的社区发现实现数据的主题化划分。
2.2 Using Knowledge Graphs with LLMs and RAG
从自然语言文本语料库中抽取知识图谱的方法包括规则匹配、统计模式识别、聚类与嵌入技术(Etzioni 等人,2004;Kim 等人,2016;Mooney & Bunescu,2005;Yates 等人,2007)。GraphRAG 属于利用大语言模型进行知识图谱抽取的较新研究方向(Ban 等人,2023;Melnyk 等人,2022;OpenAI,2023;Tan 等人,2017;Trajanoska 等人,2023;Yao 等人,2023;Yates 等人,2007;Zhang 等人,2024a)。它同时也丰富了以知识图谱作为索引的 RAG 方法体系(Gao 等人,2023)。
部分技术会将子图、图元素或图结构属性直接用于提示词(Baek 等人,2023;He 等人,2024;Zhang,2023),或作为生成结果的事实依据(Kang 等人,2023;Ranade & Joshi,2023)。另一些方法(Wang 等人,2023b)则利用知识图谱增强检索能力:在查询阶段,基于大语言模型的智能体动态遍历一张图,其中节点代表文档元素(如段落、表格),边则编码词汇与语义相似度或结构关系。
GraphRAG 与这些方法的核心区别在于:它聚焦于该场景下此前未被探索的图结构特性——图的内在模块化(Newman,2006),以及将图划分为由紧密关联节点组成的嵌套模块化社区的能力(如 Louvain 算法,Blondel 等人,2008;Leiden 算法,Traag 等人,2019)。具体来说,GraphRAG 通过大语言模型对社区层级结构进行摘要生成,递归地构建出覆盖范围越来越广的全局摘要。
2.3 Adaptive benchmarking for RAG Evaluation
目前已存在许多用于开放域问答的基准数据集,包括 HotPotQA(Yang 等,2018)、MultiHop‑RAG(Tang 和 Yang,2024)以及 MT‑Bench(Zheng 等,2024)。然而,这些基准都面向向量 RAG 性能设计,即用于评估显式事实检索的效果。
在本研究中,我们提出一种方法,用于生成一组专门评估对整个语料库进行全局意义建构能力的问题。该方法与 Xu 和 Lapata(2021)等利用语料库生成问题、并以语料摘要作为答案的大模型方法相关。
但为了保证评估公平,我们的方法避免直接从语料库本身生成问题(一种可选实现方式是:从后续图谱抽取与答案评估步骤中,预留一部分语料子集专门用于出题)。
自适应基准测试指动态生成适配特定领域或使用场景的评估基准的过程。近期研究已将大语言模型(LLM)用于自适应基准测试,以确保评估的相关性、多样性,并与目标应用或任务保持一致(Yuan 等,2024;Zhang 等,2024b)。
在本研究中,我们提出一种自适应基准测试方法,用于为大语言模型生成全局意义建构查询。该方法基于此前基于大语言模型的角色生成相关工作 —— 即用大语言模型生成多样且真实的角色集合(Kosinski,2024;Salminen 等,2024;Shin 等,2024)。
我们的自适应基准测试流程通过角色生成,创建能代表真实 RAG 系统使用场景的查询。具体而言,该方法利用大语言模型推断可能使用 RAG 系统的潜在用户及其使用场景,并以此为指导,生成针对特定语料库的意义建构类查询。
2.4 RAG evaluation criteria
我们的评估依赖大语言模型(LLM)来判断 RAG 系统对所生成问题的回答效果。已有研究表明,大语言模型能够很好地评估自然语言生成质量,甚至其评估结果与人类评估不相上下(Wang 等,2023a;Zheng 等,2024)。部分先前工作还提出了相应指标,让大语言模型对生成文本的质量进行量化。
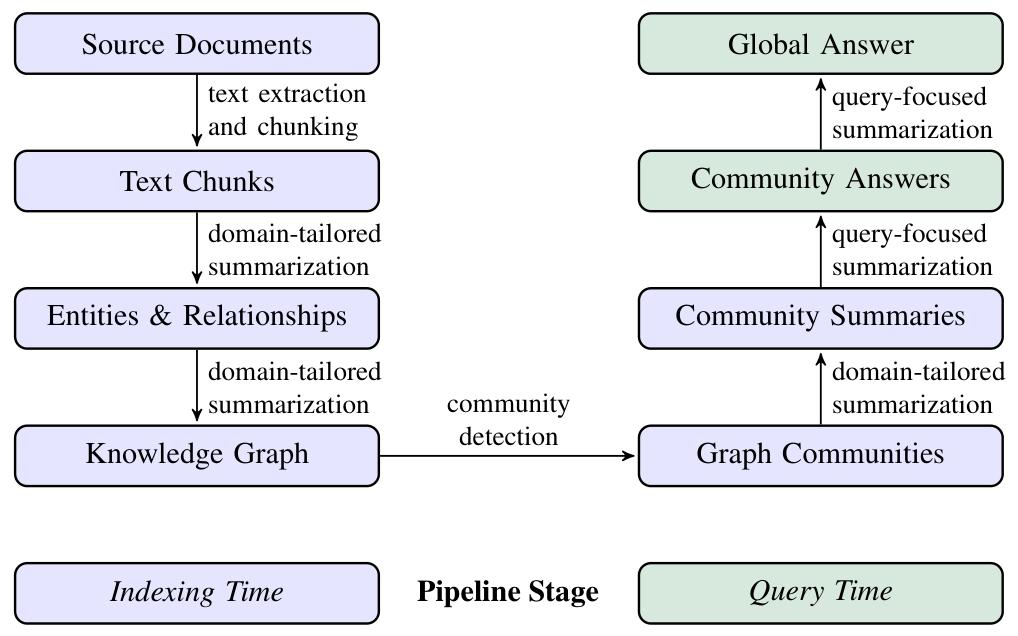
图 1:GraphRAG 流水线—— 利用大语言模型从源文档文本中构建图索引。该图索引包含由适配数据集领域的大模型提示词所检测、提取并摘要化的节点(如实体)、边(如关系)以及协变量(如事实声明)。
系统采用社区发现算法(如 Leiden 算法,Traag 等,2019)将图索引划分为多个元素组(节点、边、协变量),使大模型能够在索引阶段与查询阶段对这些组进行并行摘要。
针对给定查询的全局答案,通过对所有与该查询相关的社区摘要执行最后一轮查询聚焦式摘要生成。
诸如流畅度(fluency)这类用于评估生成文本的指标(Wang 等,2023a),其中部分指标是向量 RAG 系统的通用指标,与全局意义建构任务无关,例如上下文相关性、忠实度、答案相关性(RAGAS,Es 等,2023)。
由于评估缺乏标准答案(gold standard),我们可以通过让大语言模型对比两个不同模型的生成结果,来量化特定指标下的相对性能,即大模型裁判法(LLM-as-a-judge)(Zheng 等,2024)。
在本研究中,我们专门设计了用于评估 RAG 对全局意义建构问题所生成答案的评价指标,并使用上述对比方法开展实验评估。我们同时采用 ** 由大模型抽取的可验证事实陈述(即 “断言 /claims”)** 所得到的统计数据,对结果进行验证。
3 Methods
3.1 GraphRAG Workflow
图 1 展示了 GraphRAG 方法与流水线的高层级数据流。在本节中,我们将详细介绍每一步骤的核心设计参数、技术方案与实现细节。
3.1.1 Source Documents →Text Chunks
首先,将语料库中的文档切分为文本分块。大语言模型(LLM)从每个分块中提取信息,用于后续处理。选择分块大小是一项基础设计决策:文本分块越长,提取所需的 LLM 调用次数就越少(从而降低成本),但会导致分块前部信息的召回率下降(Kuratov 等,2024;Liu 等,2023)。关于提示词以及召回率 - 精确率权衡的示例,详见附录 A.1 节。
3.1.2 Text Chunks →Entities & Relationships
在这一步骤中,通过提示词引导大语言模型(LLM)从给定的文本分块中提取重要实体实例以及实体间的关系。此外,LLM 还会为这些实体和关系生成简短描述。为便于说明,假设某个文本分块包含如下内容:
新芯公司(NeoChip, NC)的股票在新科技交易所(NewTech Exchange)上市交易的首周大幅飙升。不过,市场分析师提醒,这家芯片制造商的首次公开亮相或许并不能反映其他科技类 IPO 的走势。新芯公司此前为私有企业,于 2016 年被量子系统公司(Quantum Systems)收购。这家创新型半导体企业专注于为可穿戴设备与物联网设备研发低功耗处理器。
通过提示词引导大语言模型提取出以下内容:
- 实体 NeoChip,描述为:“NeoChip 是一家上市公司,专注于为可穿戴设备和物联网设备提供低功耗处理器。”
- 实体 Quantum Systems,描述为:“Quantum Systems 是一家曾拥有 NeoChip 的公司。”
- NeoChip 与 Quantum Systems 之间的关系,描述为:“Quantum Systems 从 2016 年起持有 NeoChip,直至 NeoChip 上市。”
这些提示词可以通过为上下文学习选择适配领域的少样本示例,来针对文档语料的特定领域进行定制(Brown 等,2020)。例如,尽管我们的默认提示词会提取人物、地点、组织等广义的 “命名实体”,且具有普适性,但对于科学、医学、法律等专业知识领域,使用针对这些领域定制的少样本示例会带来更好效果。
还可以通过提示词引导大语言模型(LLM)提取关于已识别实体的断言(claims)。断言是关于实体的重要事实性陈述,例如日期、事件以及与其他实体的交互等。与实体和关系的提取类似,上下文学习示例可以提供领域特定的指导。从示例文本分块中提取的断言描述如下:
- 新芯公司(NeoChip)的股票在新科技交易所(NewTech Exchange)上市交易的首周大幅飙升。
- 新芯公司在新科技交易所首次公开上市。
- 量子系统公司(Quantum Systems)于 2016 年收购新芯公司,并一直持有其所有权,直至新芯公司上市。
有关实体与断言提取的提示词及实现细节,请参见附录 A。
3.1.3 Entities & Relationships →Knowledge Graph
使用大语言模型(LLM)提取实体、关系和断言,是一种抽象式摘要形式 —— 这些是对概念的有意义概括,对于关系和断言而言,它们在原文中可能并未被显式表述。实体 / 关系 / 断言的提取过程会为同一元素生成多个实例,因为同一个元素通常会在多篇文档中被多次检测和提取。
在知识图谱抽取流程的最后一步,这些实体和关系实例会成为图中的独立节点和边。系统会对每个节点和边的实体描述进行聚合与摘要。关系被聚合为图中的边,某一关系的重复出现次数则作为边权重。断言也以类似方式进行聚合。
在本文中,我们的分析采用精确字符串匹配进行实体匹配—— 即对同一实体的不同抽取名称进行归一化的任务(Barlaug and Gulla, 2021; Christen and Christen, 2012; Elmagarmid et al., 2006)。不过,只需对提示词或代码稍作调整,也可以采用更柔性的匹配方法。此外,GraphRAG 通常对重复实体具有鲁棒性,因为在后续步骤中,重复实体一般会被聚到一起进行摘要。
3.1.4 Knowledge Graph →Graph Communities
基于上一步构建的图索引,可采用多种社区发现算法将图划分为由强连通节点组成的社区(例如可参见 Fortunato(2010)与 Jin 等人(2021)的综述)。在我们的流水线中,以层级化方式使用Leiden 社区发现算法(Traag 等人,2019),在每个已检测出的社区内递归地发现子社区,直至到达无法再划分的叶社区。
该层级结构的每一层都提供了一种社区划分,以互斥且完全覆盖的方式包含图中的所有节点,从而支持分治策略下的全局摘要。在附录 B 中可以看到针对示例数据集的此类层级划分示意图。
3.1.5 Graph Communities →Community Summaries
下一步将采用一种专为超大规模数据集设计的方法,为社区层级结构中的每个社区生成类报告式摘要。这些摘要本身就具有独立价值,可用于理解数据集的全局结构与语义,即便在没有特定查询的情况下,也能用于对语料库进行意义建构。例如,用户可先浏览某一层级的社区摘要,寻找感兴趣的通用主题,再阅读下层关联报告以获取各子主题的更多细节。不过在本文中,我们重点关注其作为基于图的索引的一部分,在回答全局查询时的作用。
GraphRAG 通过将各类元素摘要(节点、边及相关断言)加入社区摘要模板来生成社区摘要。低层级社区的摘要按以下方式用于生成高层级社区的摘要:
• 叶级社区:对叶级社区的元素摘要进行优先级排序,然后迭代地加入大语言模型(LLM)的上下文窗口,直至达到令牌上限。优先级排序规则如下:按照每个社区边的源节点与目标节点度之和(即整体重要性)从高到低的顺序,依次添加源节点描述、目标节点描述、边本身的描述以及相关断言。
• 高层级社区。若所有元素摘要都能容纳在上下文窗口的令牌限制内,则按照叶级社区的方式处理,对社区内所有元素摘要进行概括。否则,按子社区的元素摘要令牌数从高到低排序,迭代地用子社区摘要(较短)替换其对应的元素摘要(较长),直至内容能容纳在上下文窗口内。
3.1.6 Community Summaries →Community Answers →Global Answer
给定用户查询,上一步生成的社区摘要可通过多阶段流程生成最终答案。社区结构的层级特性也意味着,可以使用来自不同层级的社区摘要来回答问题,这就引出了一个问题:在层级社区结构中,某一特定层级是否能在摘要细节与覆盖范围之间取得最佳平衡,以应对通用意义建构类问题(将在第 4 节中评估)。
对于给定的社区层级,任意用户查询的全局答案生成流程如下:
- 准备社区摘要:将社区摘要随机打乱,并按预先指定的令牌大小分块。这可确保相关信息均匀分布在各个分块中,而非集中在单个上下文窗口(从而可能丢失)。
- 映射社区答案:并行生成中间答案。同时要求大语言模型给出一个 0–100 的分数,表明所生成答案对目标问题的帮助程度。得分为 0 的答案将被过滤。
- 归约为全局答案:将社区中间答案按帮助度分数降序排列,并迭代加入新的上下文窗口,直至达到令牌上限。使用这一最终上下文生成并返回给用户的全局答案。
3.2 Global Sensemaking Question Generation
为评估 RAG 系统在全局意义建构任务中的有效性,我们使用大语言模型(LLM)生成一组特定于语料库的问题,这些问题旨在评估对给定语料库的高层级理解,而无需检索具体的低层级事实。相反,在给定语料库及其用途的高层级描述后,我们通过提示词引导 LLM 生成 RAG 系统假想用户的角色设定。针对每个假想用户,再通过提示词让 LLM 明确该用户会使用 RAG 系统完成的任务。最后,针对每个用户与任务的组合,通过提示词让 LLM 生成需要理解整个语料库才能回答的问题。
算法 1:问题生成的提示流程
- 输入:语料库描述、用户数量 K、每个用户的任务数量 N、每个(用户,任务)组合对应的问题数量 M。
- 输出:一组共 K×N×M 个需要对语料库具备全局理解的高层级问题。
- 过程 GENERATEQUESTIONS
- 基于语料库描述,提示大语言模型(LLM)完成以下操作:
- 描述该数据集的 K 个潜在用户角色。
- 为每个用户确定 N 个与其相关的任务。
- 针对每个用户 - 任务组合,生成 M 个高层级问题,这些问题需满足:
- 需要对整个语料库进行理解。
- 无需检索具体的低层级事实。
- 收集生成的问题,形成该数据集的 K×N×M 个测试问题。
- 过程结束
在我们的评估中,我们为每个数据集设定了总计 125 个测试问题。表 1 展示了两个评估数据集中各自的示例问题。
3.3 Criteria for Evaluating Global Sensemaking
由于我们基于活动的意义建构问题缺乏标准答案(gold standard answers),我们采用了 ** 大语言模型评估器进行两两对比(head-to-head comparison)** 的方法,由其根据特定标准判断相对性能。我们设计了三项目标标准,用以衡量全局意义建构活动所需的理想特质。
附录 F 展示了我们使用大语言模型评估器计算的两两对比指标的提示词,总结如下:
- 全面性:答案为覆盖问题的各个方面与细节提供了多少信息?
- 多样性:答案在为问题提供不同视角与见解方面,其丰富性与多元性如何?
- 赋能性:答案在多大程度上帮助读者理解该主题并做出有依据的判断?
表 1:大语言模型根据目标数据集的简要描述生成的潜在用户、任务及问题示例。这些问题旨在考察全局理解能力,而非具体细节。
数据集示例:全局意义建构问题的活动框架与生成
播客文本
用户:寻求科技行业洞见与趋势的科技记者任务:理解科技领袖如何看待政策与监管的作用问题:
- 哪些播客剧集主要探讨科技政策与政府监管?
- 嘉宾如何看待隐私法对技术发展的影响?
- 是否有嘉宾讨论创新与伦理考量之间的平衡?
- 嘉宾提及的现行政策改革建议有哪些?
- 节目中是否讨论了科技公司与政府的合作,以及合作方式是怎样的?
新闻文章
用户:将时事融入课程的教育工作者任务:开展健康与养生相关教学问题:
- 哪些当下的健康主题可融入健康教育课程?
- 新闻文章如何阐述预防医学与养生的概念?
- 是否存在观点相互矛盾的健康类文章?若存在,原因是什么?
- 从新闻报道中可得出关于公共卫生优先事项的哪些洞见?
- 教育工作者如何利用该数据集凸显健康素养的重要性?
此外,我们采用一项名为直接性(Directness)的 “控制标准”,用于回答 “答案在多大程度上具体且清晰地回应了问题?”。简单来说,直接性从通用意义上评估答案的简洁性,这一标准适用于任何由大语言模型生成的摘要。我们将其作为参照基准,以此判断其他标准下结果的可靠性。由于直接性与全面性、多样性本质上存在冲突,因此我们并不期望任何一种方法能在全部四项标准中都表现最优。
4 Analysis
4.1 Experiment 1
4.1.1 Datasets
我们选取了两个百万令牌量级的数据集,二者分别代表了用户在实际应用场景中可能遇到的语料类型:
播客文本。《与凯文・斯科特聊科技》(Behind the Tech with Kevin Scott)的公开文本,该播客收录了微软首席技术官凯文・斯科特与多位科技及思想领域领军人物的对话(Scott, 2024)。该语料库被划分为 1669 个 600 令牌的文本块,块间重叠 100 令牌(约 100 万令牌)。
新闻文章。这是一个基准数据集,由 2013 年 9 月至 2023 年 12 月期间发表的新闻文章构成,涵盖娱乐、商业、体育、科技、健康和科学等多个类别(Tang and Yang, 2024)。该语料库被划分为 3197 个 600 令牌的文本块,块间重叠 100 令牌(约 170 万令牌)。
4.1.2 Conditions
我们对比了六种实验条件,包括GraphRAG 在四个不同图社区层级(C0、C1、C2、C3)、一种直接将我们的映射 - 归约(map-reduce)方法应用于源文本的文本摘要方法(TS),以及一种向量 RAG “语义搜索” 方法(SS)。
- C0:使用根层级社区摘要(数量最少)来回答用户查询。
- C1:使用高层级社区摘要来回答查询。这些是 C0 的子社区(若存在),否则为 C0 社区向下投影得到的结果。
- C2:使用中间层级社区摘要来回答查询。这些是 C1 的子社区(若存在),否则为 C1 社区向下投影得到的结果。
- C3:使用低层级社区摘要(数量最多)来回答查询。这些是 C2 的子社区(若存在),否则为 C2 社区向下投影得到的结果。
- TS:采用与 3.1.6 节相同的方法,区别在于映射 - 归约摘要阶段打乱并分块的是源文本,而非社区摘要。
- SS:向量 RAG 的一种实现方式,即检索文本分块并加入可用上下文窗口,直至达到指定的令牌上限。
所有六种实验条件下,用于生成答案的上下文窗口大小和提示词均保持一致(仅为匹配所使用的上下文信息类型,对引用格式做了少量调整)。各条件的唯一区别在于上下文窗口内容的构建方式。
支持 C0–C3 实验条件的图索引,是通过我们用于实体和关系抽取的通用提示词构建的,其中实体类型和少样本示例根据数据所属领域进行了定制。
4.1.3 Configuration
我们使用8k 令牌的固定上下文窗口来生成社区摘要、社区答案和全局答案(详见附录 C)。在虚拟机(16GB 内存,Intel (R) Xeon (R) Platinum 8171M CPU @ 2.60GHz)上,并通过公共 OpenAI 端点调用 gpt-4-turbo(2M TPM,10k RPM),采用600 令牌窗口进行图索引构建(详见 A.2 节),播客数据集的处理耗时为 281 分钟。
我们使用 graspologic 库实现了 Leiden 社区检测算法(Chung et al., 2019)。用于生成图索引和全局答案的提示词见附录 E,而依据我们的评估标准对大语言模型回复进行评估的提示词则见附录 F。下一节所展示结果的完整统计分析见附录 G。
4.2 Experiment 2
为验证实验 1 中得到的全面性与多样性结果,我们实现了基于断言(claim-based)的指标来衡量这些特质。我们采用了 Ni 等人(2024)对事实断言的定义,即 “明确呈现可验证事实的陈述”。例如,句子 “加利福尼亚州和纽约州为推广可再生能源应用实施了激励措施,凸显了可持续发展在政策决策中的广泛重要性” 包含两个事实断言:(1) 加利福尼亚州为推广可再生能源应用实施了激励措施;(2) 纽约州为推广可再生能源应用实施了激励措施。
我们使用 graspologic 库实现了 Leiden 社区检测(Chung 等人,2019)。用于生成图索引和全局答案的提示词见附录 E,而依据我们的评估标准对大语言模型响应进行评估的提示词则见附录 F。下一节中展示结果的完整统计分析见附录 G。
我们定义了两项指标,数值越高表示性能越好:
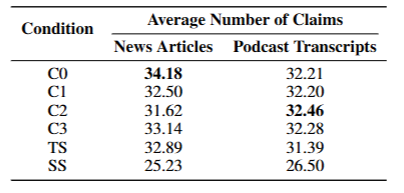
- 全面性:以每种实验条件下生成的答案中提取出的断言平均数量来衡量。
- 多样性:通过对每个答案的断言进行聚类,并计算聚类的平均数量来衡量。
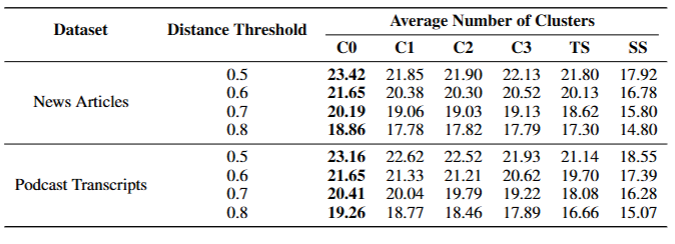
在聚类方面,我们采用了 Padmakumar 和 He(2024)提出的方法,该方法使用了 Scikit-learn 实现的凝聚层次聚类(Pedregosa 等人,2011)。聚类通过 ** 完全链接(complete linkage)** 进行合并,即仅当两个聚类中最远点之间的最大距离小于或等于预设距离阈值时才进行合并。所使用的距离度量为 1 − ROUGE-L。由于距离阈值会影响聚类数量,我们报告了一系列不同阈值下的结果。
5 Results
5.1 Experiment 1
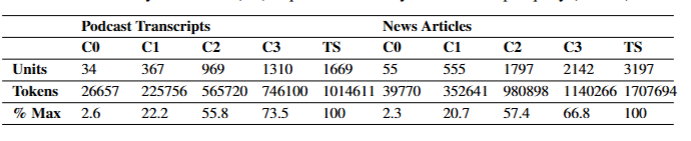
索引过程生成的图结构中,播客数据集包含 8,564 个节点和 20,691 条边,新闻数据集则是规模更大的图,包含 15,754 个节点和 19,520 条边。表 2 展示了每个图社区层级中不同层级的社区摘要数量
全局方法与向量 RAG 对比。如图 2 和表 6 所示,在所有数据集上,全局方法在全面性和多样性指标上均显著优于传统向量 RAG(SS)。具体而言,全局方法在播客文本数据集上的全面性胜率为 72–83%(p<.001),在新闻文章数据集上为 72–80%(p<.001);多样性胜率则分别为 75–82%(p<.001)和 62–71%(p<.01)。我们将直接性作为有效性检验,结果证实向量 RAG 在所有对比中生成的响应最为直接。
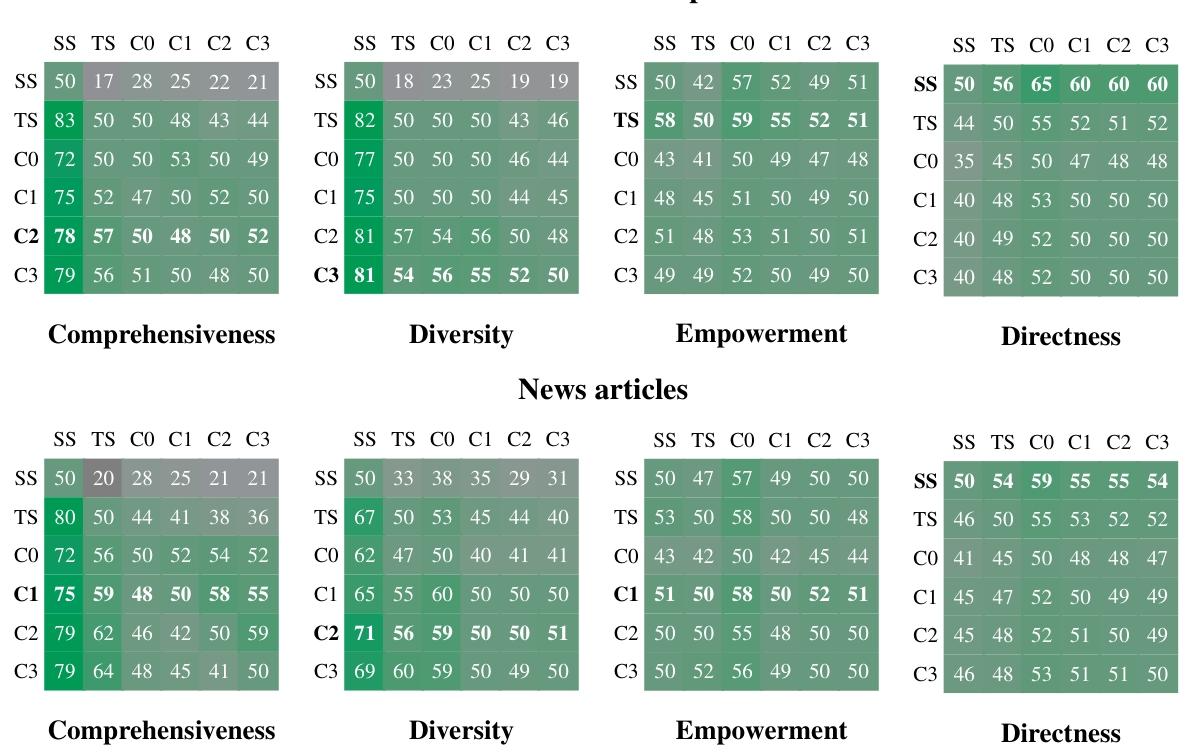
图 2:在两个数据集、四项指标上,(行条件)相对(列条件)的两两对决战胜率(百分比),每项对比包含 125 个问题(每个问题重复 5 次并取平均值)。每个数据集和指标下的总体最优方法以粗体显示。未计算自对战胜率,但为便于参考,将其标注为预期的 50%。所有 GraphRAG 条件在全面性和多样性上均优于朴素 RAG。C1–C3 条件相较于 TS(无图索引的全局文本摘要),在答案的全面性和多样性上也有小幅提升。
表 2:上下文单元数量(C0–C3 为社区摘要,TS 为文本块)、对应的令牌数,以及占最大令牌数的百分比。对源文本的映射 - 归约摘要方法是资源消耗最大的方案,需要的上下文令牌数量最多。根层级社区摘要(C0)每次查询所需的令牌数大幅减少(为前者的 1/9 至 1/43)。
示例、引述和引用被认为是帮助用户形成有依据的理解的关键。对元素抽取提示词进行调优,有助于在 GraphRAG 索引中保留更多此类细节。
社区摘要与源文本对比:在使用 GraphRAG 将社区摘要与源文本进行比较时,除根层级摘要外,社区摘要通常在答案的全面性和多样性上带来小幅但稳定的提升。播客数据集中的中间层级摘要与新闻数据集中的低层级社区摘要,其全面性胜率分别达到 57%(p<.001)和 64%(p<.001)。多样性胜率方面,播客中间层级摘要为 57%(p=.036),新闻低层级社区摘要为 60%(p<.001)。
表 2 同样体现了 GraphRAG 相较于源文本摘要的可扩展性优势:对于低层级社区摘要(C3),GraphRAG 所需的上下文令牌减少 26%–33%;而对于根层级社区摘要(C0),令牌需求减少超过 97%。尽管与其他全局方法相比性能略有下降,但根层级 GraphRAG 为具有意义建构活动特征的迭代式问答提供了一种高效方法,同时在全面性(72% 胜率)和多样性(62% 胜率)上仍优于向量 RAG。
表 3:按实验条件和数据集类型划分的提取断言平均数量。加粗数值表示每列中的最高得分。
5.2 Experiment 2
表 3 展示了每种实验条件下提取断言的平均数量(即基于断言的全面性指标)。在新闻和播客两个数据集中,所有全局搜索条件(C0–C3)与源文本摘要(TS)的全面性均高于向量 RAG(SS)。所有情况下的差异均具有统计学意义(p < .05)。这些发现与实验 1 中基于大语言模型的胜率结果一致。
表 3 展示了每种实验条件下提取断言的平均数量(即基于断言的全面性指标)。在新闻和播客两个数据集中,所有全局搜索条件(C0–C3)与源文本摘要(TS)的全面性均高于向量 RAG(SS)。所有情况下的差异均具有统计学意义(p < .05)。这些发现与实验 1 中基于大语言模型的胜率结果一致。
表 4 展示了聚类平均数量的结果,即基于断言的多样性指标。对于播客数据集,在所有距离阈值下,所有全局搜索条件的多样性均显著优于 SS(p < .05),这与实验 1 中观察到的胜率一致。然而,对于新闻数据集,仅 C0 在所有距离阈值下均显著优于 SS(p < .05);C1–C3 的平均聚类数量也高于 SS,但仅在特定距离阈值下差异具有统计学意义。在实验 1 中,新闻数据集里所有全局搜索条件均显著优于 SS—— 而非仅 C0。不过,新闻数据集中 SS 与全局搜索条件之间的多样性平均分差异,小于播客数据集,这与基于断言的结果在趋势上一致。
在全面性和多样性两个指标上,跨两个数据集,全局搜索条件之间以及全局搜索与 TS 之间均未观察到具有统计学意义的差异。
最后,针对实验 1 中的每一组两两对比,我们检验了大语言模型(LLM)所偏好的答案是否与基于断言指标得出的优胜者一致。由于实验 1 中的每一组两两对比均执行了五次,而基于断言的指标每组对比仅给出一个结果,因此我们通过多数投票法将实验 1 的结果聚合为单一标签。例如,若在某一问题的全面性评估中,C0 在五次判断里三次战胜 SS,则将 C0 标记为胜者,SS 为败者。但如果 C0 胜两次、SS 胜一次、平局两次,则不存在多数结果,最终标签记为平局。
我们发现,基于断言的指标中完全平局的情况十分罕见。一种可行的解决办法是基于阈值定义平局(例如,条件 A 与条件 B 基于断言的结果之差的绝对值必须小于或等于 x)。然而,我们观察到结果对阈值的选择非常敏感。
因此,我们仅关注聚合后的大语言模型标签非平局的情况,这类情况在全面性和多样性的两两对比中分别占 33% 和 39%。在这些案例中,聚合后的大语言模型标签与基于断言的标签一致率为:全面性 78%,多样性 69%–70%(在所有距离阈值下),表明二者具有中等偏强的一致性。
6 Discussion
6.1 Limitations of evaluation approach
截至目前,我们的评估主要聚焦于针对两个语料库的意义建构类问题,每个语料库包含约 100 万令牌。仍需开展更多工作,以探究该方法在不同领域、不同应用场景的数据集上的泛化性能。对 ** 幻觉生成率(捏造率)** 的对比分析(例如采用 SelfCheckGPT 等方法,Manakul et al., 2023)也将进一步完善当前的分析工作。
表 4:按实验条件和数据集类型划分的、不同距离阈值下的聚类平均数量。加粗数值表示每行中的最高得分。
6.2 Future work
支撑当前 GraphRAG 方法的图索引、富文本标注与层级化社区结构,为后续的优化与适配提供了诸多可能。这包括通过基于嵌入的用户查询与图标注匹配,以更局部化的方式运行的 RAG 方案。
我们尤其看好混合 RAG 架构的潜力:在应用我们的映射 - 归约摘要机制之前,先将基于嵌入的匹配与即时生成的社区报告相结合。这种 “上卷(roll-up)” 思路还可拓展至社区层级的多个层面,也可实现为更具探索性的 “下钻(drill down)” 机制,沿着高层级社区摘要中蕴含的信息线索逐层深入。
支撑当前 GraphRAG 方法的图索引、富文本标注与层级化社区结构,为后续的优化与适配提供了诸多可能。这包括通过基于嵌入的用户查询与图标注匹配,以更局部化的方式运行的 RAG 方案。
我们尤其看好混合 RAG 架构的潜力:在应用我们的映射 - 归约摘要机制之前,先将基于嵌入的匹配与即时生成的社区报告相结合。这种 “上卷(roll-up)” 思路还可拓展至社区层级的多个层面,也可实现为更具探索性的 “下钻(drill down)” 机制,沿着高层级社区摘要中蕴含的信息线索逐层深入。
7 Conclusion
我们提出了 GraphRAG,这是一种将知识图谱生成与 ** 面向查询的摘要生成(QFS)** 相结合的检索增强生成(RAG)方法,用于支持人类对整个文本语料库进行意义建构。初步评估表明,在答案的全面性和多样性方面,该方法相较于向量 RAG 基线有显著提升,并且与采用映射 - 归约源文本摘要、不依赖图谱的全局方法相比也表现出色。
对于需要在同一数据集上执行大量全局查询的场景,基于实体的图索引中根层级社区的摘要所构成的数据索引,不仅优于向量 RAG,而且在仅消耗极少令牌成本的情况下,达到了与其他全局方法相当的性能。
关键术语注释(必看)
- RAG (Retrieval-Augmented Generation):检索增强生成
- LLM (Large Language Model):大语言模型
- QFS (Query-Focused Summarization):查询聚焦摘要
- Global question:全局问题(需理解整个语料)
- Knowledge graph:知识图谱
- Community:社区(图中高度关联的实体集群)
- Community summary:社区摘要
- Sensemaking:全局理解 / 意义建构
- Corpus:语料库
- Token:令牌(文本处理单位)
- user query:用户查询
- external data sources:外部数据源
- generative AI model:生成式 AI 模型
- multi-media model:多模态模型
- prompt template:提示词模板
- context window:上下文窗口
- retrieved records:检索到的文本 / 记录
- advanced RAG strategies:先进 RAG 策略
- self-memory:自记忆
- hierarchical indexing:层级索引
- graph index:图索引
- community detection:社区发现
- thematic partitioning:主题化划分
- global summaries:全局摘要
- open-domain question answering:开放域问答
- benchmark datasets:基准数据集
- explicit fact retrieval:显式事实检索
- global sensemaking:全局意义建构
- held-out subset:预留子集 / 隔离子集
- fluency:流畅度
- context relevance:上下文相关性
- faithfulness:忠实度
- answer relevance:答案相关性
- gold standard:标准答案、金标准
- LLM-as-a-judge:大模型裁判
- global sensemaking questions:全局意义建构问题
- verifiable facts:可验证事实
- claims:断言、事实声明

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)