SenseVoicecpp sense-voice识别语音[AI人工智能(六十八)]—东方仙盟
核心代码
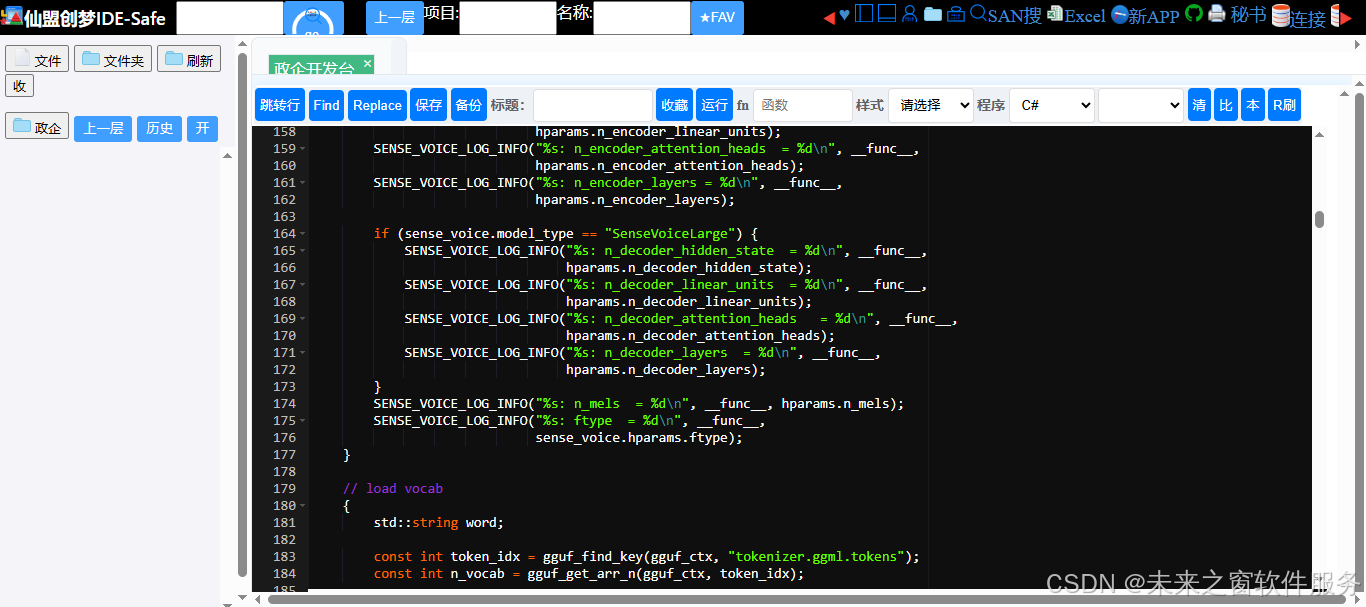
完整代码
//
// Created by lovemefan on 2024/7/19.
//
#include "sense-voice.h"
#include "common.h"
#include "sense-voice-cmvn.h"
#include "sense-voice-decoder.h"
#include "sense-voice-encoder.h"
#include "silero-vad.h"
#include <cassert>
#include <functional>
#include <thread>
#define SENSE_VOICE_MAX_NODES 8192
#define SENSE_VOICE_MAX_DECODERS 8
#define SENSE_VOICE_CHUNK_SIZE 20
#define SENSE_VOICE_FEATURES_DIM 560
int sense_voice_lang_id(const char *lang) {
if (!g_lang.count(lang)) {
for (const auto &kv: g_lang) {
if (kv.second.second == lang) {
return kv.second.first;
}
}
SENSE_VOICE_LOG_ERROR("%s: unknown language '%s'\n", __func__, lang);
return -1;
}
return g_lang.at(lang).first;
}
const char *sense_voice_lang_str(int id) {
for (const auto &kv: g_lang) {
if (kv.second.first == id) {
return kv.first.c_str();
}
}
SENSE_VOICE_LOG_ERROR("%s: unknown language id %d\n", __func__, id);
return nullptr;
}
static ggml_backend_buffer_type_t sense_voice_default_buffer_type(const sense_voice_context_params ¶ms) {
if (!params.use_gpu) {
return ggml_backend_cpu_buffer_type();
}
for (size_t i = 0; i < ggml_backend_dev_count(); ++i) {
ggml_backend_dev_t dev = ggml_backend_dev_get(i);
if (ggml_backend_dev_type(dev) == GGML_BACKEND_DEVICE_TYPE_GPU) {
SENSE_VOICE_LOG_INFO("%s: using device %s (%s)\n", __func__, ggml_backend_dev_name(dev), ggml_backend_dev_description(dev));
return ggml_backend_dev_buffer_type(dev);
}
}
return ggml_backend_cpu_buffer_type();
}
static ggml_backend_t sense_voice_backend_init_gpu(const sense_voice_context_params ¶ms) {
ggml_backend_t result = nullptr;
if (params.use_gpu) {
for (size_t i = 0; i < ggml_backend_dev_count(); ++i) {
ggml_backend_dev_t dev = ggml_backend_dev_get(i);
if (ggml_backend_dev_type(dev) == GGML_BACKEND_DEVICE_TYPE_GPU) {
SENSE_VOICE_LOG_INFO("%s: using %s backend\n", __func__, ggml_backend_dev_name(dev));
ggml_backend_t result = ggml_backend_dev_init(dev, nullptr);
if (!result) {
SENSE_VOICE_LOG_ERROR("%s: failed to initialize %s backend\n", __func__, ggml_backend_dev_name(dev));
}
return result;
}
}
}
return result;
}
// load the model from a gguf file
// see the convert-pt-to-ggml.py script for details
bool sense_voice_model_load(const char *path_model, sense_voice_context &sctx) {
struct gguf_init_params gguf_params = {
/*.no_alloc = */ true,
/*.ctx = */ &sctx.model.ctx,
};
struct gguf_context *gguf_ctx = gguf_init_from_file(path_model, gguf_params);
// kv data
{
SENSE_VOICE_LOG_INFO("%s: version: %d\n", __func__,
gguf_get_version(gguf_ctx));
SENSE_VOICE_LOG_INFO("%s: alignment: %zu\n", __func__,
gguf_get_alignment(gguf_ctx));
SENSE_VOICE_LOG_INFO("%s: data offset: %zu\n", __func__,
gguf_get_data_offset(gguf_ctx));
const int n_kv = gguf_get_n_kv(gguf_ctx);
SENSE_VOICE_LOG_DEBUG("%s: n_kv: %d\n", __func__, n_kv);
}
SENSE_VOICE_LOG_INFO("%s: loading model\n", __func__);
const int64_t t_start_ms = ggml_time_ms();
sctx.t_start_ms = t_start_ms;
auto &vad_model = sctx.vad_model;
auto &sense_voice = sctx.model;
auto &vocab = sctx.vocab;
auto &hparams = sense_voice.hparams;
sense_voice.model_type = gguf_get_val_str(gguf_ctx, 0);
// load hparams
{
if (gguf_find_key(gguf_ctx, "general.file_type") != -1) {
hparams.ftype = gguf_get_val_u32(
gguf_ctx, gguf_find_key(gguf_ctx, "general.file_type"));
}
hparams.n_vocab = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "tokenizer.vocab_size"));
hparams.n_encoder_hidden_state =
gguf_get_val_i32(gguf_ctx, gguf_find_key(gguf_ctx, "encoder.output_size"));
hparams.n_encoder_linear_units = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "encoder.linear_units"));
hparams.n_encoder_attention_heads = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "encoder.attention_heads"));
hparams.n_encoder_layers = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "encoder.num_blocks"));
hparams.n_tp_encoder_layers = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "encoder.tp_blocks"));
if (sense_voice.model_type == "SenseVoiceLarge") {
hparams.n_decoder_hidden_state =
gguf_get_val_i32(gguf_ctx, gguf_find_key(gguf_ctx, "model.inner_dim"));
hparams.n_decoder_linear_units = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "decoder.linear_units"));
hparams.n_decoder_attention_heads = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "decoder.attention_heads"));
hparams.n_decoder_layers = gguf_get_val_i32(
gguf_ctx, gguf_find_key(gguf_ctx, "decoder.num_blocks"));
}
// for the big tensors, we have the option to store the data in 16-bit
// floats or quantized in order to save memory and also to speed up the
// computation
sctx.wtype = ggml_ftype_to_ggml_type((ggml_ftype) (sense_voice.hparams.ftype));
if (sctx.wtype == GGML_TYPE_COUNT) {
SENSE_VOICE_LOG_INFO("%s: invalid model (bad ftype value %d)\n", __func__,
sense_voice.hparams.ftype);
return false;
}
SENSE_VOICE_LOG_INFO("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
SENSE_VOICE_LOG_INFO("%s: n_encoder_hidden_state = %d\n", __func__,
hparams.n_encoder_hidden_state);
SENSE_VOICE_LOG_INFO("%s: n_encoder_linear_units = %d\n", __func__,
hparams.n_encoder_linear_units);
SENSE_VOICE_LOG_INFO("%s: n_encoder_attention_heads = %d\n", __func__,
hparams.n_encoder_attention_heads);
SENSE_VOICE_LOG_INFO("%s: n_encoder_layers = %d\n", __func__,
hparams.n_encoder_layers);
if (sense_voice.model_type == "SenseVoiceLarge") {
SENSE_VOICE_LOG_INFO("%s: n_decoder_hidden_state = %d\n", __func__,
hparams.n_decoder_hidden_state);
SENSE_VOICE_LOG_INFO("%s: n_decoder_linear_units = %d\n", __func__,
hparams.n_decoder_linear_units);
SENSE_VOICE_LOG_INFO("%s: n_decoder_attention_heads = %d\n", __func__,
hparams.n_decoder_attention_heads);
SENSE_VOICE_LOG_INFO("%s: n_decoder_layers = %d\n", __func__,
hparams.n_decoder_layers);
}
SENSE_VOICE_LOG_INFO("%s: n_mels = %d\n", __func__, hparams.n_mels);
SENSE_VOICE_LOG_INFO("%s: ftype = %d\n", __func__,
sense_voice.hparams.ftype);
}
// load vocab
{
std::string word;
const int token_idx = gguf_find_key(gguf_ctx, "tokenizer.ggml.tokens");
const int n_vocab = gguf_get_arr_n(gguf_ctx, token_idx);
if (n_vocab != sense_voice.hparams.n_vocab) {
SENSE_VOICE_LOG_ERROR(
"%s: vocabulary loaded from model file error - vocabulary size is "
"%d, but got %d .\n",
__func__, sense_voice.hparams.n_vocab, n_vocab);
}
std::vector<const char *> tokens;
tokens.resize(n_vocab);
for (int i = 0; i < n_vocab; i++) {
word = gguf_get_arr_str(gguf_ctx, token_idx, i);
vocab.token_to_id[word] = i;
vocab.id_to_token[i] = word;
}
SENSE_VOICE_LOG_INFO("%s: vocab[%d] loaded\n", __func__, n_vocab);
}
vocab.n_vocab = sense_voice.hparams.n_vocab;
{
// initialize all memory buffers
// always have at least one decoder
// allocate tensors in the backend buffers
sctx.model.buffer = ggml_backend_alloc_ctx_tensors_from_buft(sctx.model.ctx, sense_voice_default_buffer_type(sctx.params));
if (!sctx.model.buffer) {
SENSE_VOICE_LOG_ERROR("%s: failed to allocate memory for the model\n", __func__);
return false;
}
size_t size_main = ggml_backend_buffer_get_size(sctx.model.buffer);
SENSE_VOICE_LOG_INFO("%s: %s total size = %8.2f MB\n", __func__, ggml_backend_buffer_name(sctx.model.buffer), size_main / 1e6);
// load weights
{
// host buffer for CUDA loading
std::vector<uint8_t> read_buf;
const int n_tensors = gguf_get_n_tensors(gguf_ctx);
SENSE_VOICE_LOG_INFO("%s: n_tensors: %d\n", __func__, n_tensors);
sense_voice.n_loaded = 0;
// model tensor sizing
size_t buffer_size = 32 * 1024;// need some extra room??
for (int i = 0; i < n_tensors; ++i) {
const char *name = gguf_get_tensor_name(gguf_ctx, i);
struct ggml_tensor *cur = ggml_get_tensor(sctx.model.ctx, name);
size_t tensor_size = ggml_nbytes(cur);
buffer_size += tensor_size;
}
// open model gguf file
auto fin = std::ifstream(path_model, std::ios::binary);
if (!fin) {
fprintf(stderr, "cannot open model file for loading tensors\n");
return false;
}
for (int i = 0; i < n_tensors; ++i) {
const std::string name = gguf_get_tensor_name(gguf_ctx, i);
struct ggml_tensor *cur = ggml_get_tensor(sctx.model.ctx, name.c_str());
sense_voice.tensors[name] = cur;
// seek to the tensor data in the file
const size_t offset = gguf_get_data_offset(gguf_ctx) + gguf_get_tensor_offset(gguf_ctx, i);
fin.seekg(offset, std::ios::beg);
if (!fin) {
fprintf(stderr, "%s: failed to seek for tensor %s\n", __func__, name.c_str());
return false;
}
// read in data and copy to device if needed
int num_bytes = ggml_nbytes(cur);
if (ggml_backend_buffer_is_host(sctx.model.buffer)) {
// for the CPU and Metal backend, we can read directly into the tensor
fin.read(reinterpret_cast<char *>(cur->data), num_bytes);
} else {
// read into a temporary buffer first, then copy to device memory
read_buf.resize(num_bytes);
fin.read(reinterpret_cast<char *>(read_buf.data()), num_bytes);
ggml_backend_tensor_set(cur, read_buf.data(), 0, num_bytes);
}
auto n_dim = ggml_n_dims(cur);
std::stringstream shape;
if (n_dim == 1)
shape << cur->ne[0];
else if (n_dim == 2)
shape << cur->ne[0] << ',' << cur->ne[1];
else if (n_dim == 3)
shape << cur->ne[0] << ',' << cur->ne[1] << ',' << cur->ne[2];
else
shape << cur->ne[0] << ',' << cur->ne[1] << ',' << cur->ne[2] << ','
<< cur->ne[3];
SENSE_VOICE_LOG_DEBUG(
"%s: tensor[%d]: n_dims = %d, shape = (%s), name = %s, "
"data = %p\n",
__func__, i, ggml_n_dims(cur), shape.str().c_str(), cur->name,
cur->data);
}
}
ggml_backend_buffer_set_usage(sctx.model.buffer, GGML_BACKEND_BUFFER_USAGE_WEIGHTS);
gguf_free(gguf_ctx);
}
{
// build model
vad_model.model = new struct silero_vad;
vad_model.model->encoders_layer = std::vector<silero_vad_encoder_layer>(hparams.n_vad_encoder_layers);
sense_voice.vad_model = vad_model.model;
sense_voice.model = new struct sense_voice;
sense_voice.model->encoder = new struct sense_voice_encoder;
sense_voice.model->encoder->encoders_layer = std::vector<sense_voice_layer_encoder>(hparams.n_encoder_layers - 1);
sense_voice.model->encoder->tp_encoders_layer = std::vector<sense_voice_layer_encoder>(hparams.n_tp_encoder_layers);
// load vad model
{
vad_model.model->stft.forward_basis_buffer = sense_voice.tensors["_model.stft.forward_basis_buffer.weight"];
for (int i = 0; i < hparams.n_vad_encoder_layers; i++) {
vad_model.model->encoders_layer[i].reparam_conv_w = sense_voice.tensors["_model.encoder." + std::to_string(i) + ".reparam_conv.weight"];
vad_model.model->encoders_layer[i].reparam_conv_b = sense_voice.tensors["_model.encoder." + std::to_string(i) + ".reparam_conv.bias"];
}
vad_model.model->decoder.lstm_weight_ih = sense_voice.tensors["_model.decoder.rnn.weight_ih"];
vad_model.model->decoder.lstm_weight_hh = sense_voice.tensors["_model.decoder.rnn.weight_hh"];
vad_model.model->decoder.lstm_bias_ih = sense_voice.tensors["_model.decoder.rnn.bias_ih"];
vad_model.model->decoder.lstm_bias_hh = sense_voice.tensors["_model.decoder.rnn.bias_hh"];
vad_model.model->decoder.decoder_conv_w = sense_voice.tensors["_model.decoder.decoder.2.weight"];
vad_model.model->decoder.decoder_conv_b = sense_voice.tensors["_model.decoder.decoder.2.bias"];
}
// load encoder weights, multi layers of EncoderLayerSANM
{
sense_voice.model->embedding = sense_voice.tensors["embed.weight"];
std::vector<sense_voice_layer_encoder> tmp_encoder0;
tmp_encoder0.push_back(sense_voice.model->encoder->encoder0);
set_sense_voice_encoder_layer_sanm(tmp_encoder0, sense_voice.tensors, 1, "encoders0");
sense_voice.model->encoder->encoder0 = tmp_encoder0[0];
set_sense_voice_encoder_layer_sanm(sense_voice.model->encoder->encoders_layer, sense_voice.tensors, hparams.n_encoder_layers - 1, "encoders");
set_sense_voice_encoder_layer_sanm(sense_voice.model->encoder->tp_encoders_layer, sense_voice.tensors, hparams.n_tp_encoder_layers, "tp_encoders");
sense_voice.model->encoder->e_after_norm_w = sense_voice.tensors["encoder.after_norm.weight"];
sense_voice.model->encoder->e_after_norm_b = sense_voice.tensors["encoder.after_norm.bias"];
sense_voice.model->encoder->e_tp_norm_w = sense_voice.tensors["encoder.tp_norm.weight"];
sense_voice.model->encoder->e_tp_norm_b = sense_voice.tensors["encoder.tp_norm.bias"];
sense_voice.model->ctc_out_linear_weight = sense_voice.tensors["ctc.ctc_lo.weight"];
sense_voice.model->ctc_out_linear_bias = sense_voice.tensors["ctc.ctc_lo.bias"];
}
}
// decoder layers
if (sense_voice.model_type == "SenseVoiceLarge") {
}
sctx.t_load_ms = ggml_time_ms() - t_start_ms;
SENSE_VOICE_LOG_INFO("%s: load %s takes %f second \n", __func__, sense_voice.model_type.c_str(),
sctx.t_load_ms * 1.0 / 1000);
return true;
}
struct sense_voice_context *sense_voice_init_with_params_no_state(
const char *path_model, sense_voice_context_params params) {
ggml_time_init();
SENSE_VOICE_LOG_INFO("%s: use gpu = %d\n", __func__, params.use_gpu);
SENSE_VOICE_LOG_INFO("%s: flash attn = %d\n", __func__, params.flash_attn);
SENSE_VOICE_LOG_INFO("%s: gpu_device = %d\n", __func__, params.gpu_device);
SENSE_VOICE_LOG_INFO("%s: devices = %zu\n", __func__, ggml_backend_dev_count());
SENSE_VOICE_LOG_INFO("%s: backends = %zu\n", __func__, ggml_backend_reg_count());
auto *ctx = new struct sense_voice_context;
ctx->params = params;
if (!sense_voice_model_load(path_model, *ctx)) {
SENSE_VOICE_LOG_ERROR("%s: failed to load model\n", __func__);
delete ctx;
return nullptr;
}
return ctx;
}
struct sense_voice_context *sense_voice_small_init_from_file_with_params_no_state(const char *path_model, struct sense_voice_context_params params) {
SENSE_VOICE_LOG_INFO("%s: loading model from '%s'\n", __func__, path_model);
auto ctx = sense_voice_init_with_params_no_state(path_model, params);
if (ctx) {
ctx->path_model = path_model;
}
return ctx;
}
static std::vector<ggml_backend_t> sense_voice_backend_init(
const sense_voice_context_params ¶ms) {
std::vector<ggml_backend_t> result;
ggml_backend_t backend_gpu = sense_voice_backend_init_gpu(params);
if (backend_gpu) {
result.push_back(backend_gpu);
}
for (size_t i = 0; i < ggml_backend_dev_count(); ++i) {
ggml_backend_dev_t dev = ggml_backend_dev_get(i);
if (ggml_backend_dev_type(dev) == GGML_BACKEND_DEVICE_TYPE_ACCEL || ggml_backend_dev_type(dev) == GGML_BACKEND_DEVICE_TYPE_CPU) {
SENSE_VOICE_LOG_INFO("%s: using %s backend\n", __func__, ggml_backend_dev_name(dev));
ggml_backend_t backend = ggml_backend_dev_init(dev, nullptr);
if (!backend) {
SENSE_VOICE_LOG_ERROR("%s: failed to initialize %s backend\n", __func__, ggml_backend_dev_name(dev));
continue;
}
result.push_back(backend);
}
}
GGML_UNUSED(params);
return result;
}
static bool sense_voice_kv_cache_init(
struct sense_voice_kv_cache &cache,
ggml_backend_t backend,
ggml_type wtype,
int64_t n_text_state,
int64_t n_text_layer,
int n_ctx) {
const int64_t n_mem = n_text_layer * n_ctx;
const int64_t n_elements = n_text_state * n_mem;
struct ggml_init_params params = {
/*.mem_size =*/2 * ggml_tensor_overhead(),
/*.mem_buffer =*/nullptr,
/*.no_alloc =*/true,
};
cache.head = 0;
cache.size = n_ctx;
cache.cells.clear();
cache.cells.resize(n_ctx);
cache.ctx = ggml_init(params);
if (!cache.ctx) {
SENSE_VOICE_LOG_ERROR("%s: failed to allocate memory for the kv cache context\n", __func__);
return false;
}
cache.k = ggml_new_tensor_1d(cache.ctx, wtype, n_elements);
cache.v = ggml_new_tensor_1d(cache.ctx, wtype, n_elements);
cache.buffer = ggml_backend_alloc_ctx_tensors(cache.ctx, backend);
if (!cache.buffer) {
SENSE_VOICE_LOG_ERROR("%s: failed to allocate memory for the kv cache\n", __func__);
return false;
}
ggml_backend_buffer_clear(cache.buffer, 0);
return true;
}
static void sense_voice_kv_cache_free(struct sense_voice_kv_cache &cache) {
ggml_free(cache.ctx);
ggml_backend_buffer_free(cache.buffer);
cache.ctx = nullptr;
}
// measure the memory usage of a graph and prepare the allocr's internal data
// buffer
static bool sense_voice_sched_graph_init(
struct sense_voice_sched &allocr, std::vector<ggml_backend_t> backends,
std::function<struct ggml_cgraph *()> &&get_graph) {
auto &sched = allocr.sched;
auto &meta = allocr.meta;
sched = ggml_backend_sched_new(backends.data(), nullptr, backends.size(), SENSE_VOICE_MAX_NODES, false, true);
meta.resize(ggml_tensor_overhead() * SENSE_VOICE_MAX_NODES +
ggml_graph_overhead());
// since there are dependencies between the different graphs,
// we need to allocate them instead of only reserving to get the correct compute buffer size
if (!ggml_backend_sched_alloc_graph(sched, get_graph())) {
// failed to allocate the compute buffer
SENSE_VOICE_LOG_ERROR("%s: failed to allocate the compute buffer\n", __func__);
return false;
}
ggml_backend_sched_reset(sched);
return true;
}
void sense_voice_free_state(struct sense_voice_state *state) {
if (state) {
sense_voice_kv_cache_free(state->kv_pad);
{
{
ggml_free(state->feature.ctx);
ggml_free(state->vad_ctx);
ggml_backend_buffer_free(state->feature.buffer);
ggml_backend_buffer_free(state->vad_lstm_hidden_state_buffer);
ggml_backend_buffer_free(state->vad_lstm_context_buffer);
state->feature.ctx = nullptr;
state->feature.tensor = nullptr;
state->feature.buffer = nullptr;
}
state->encoder_out = nullptr;
}
#ifdef SENSE_VOICE_USE_COREML
if (state->ctx_coreml != nullptr) {
sense_voice_coreml_free(state->ctx_coreml);
state->ctx_coreml = nullptr;
}
#endif
#ifdef SENSE_VOICE_USE_OPENVINO
if (state->ctx_openvino != nullptr) {
sense_voice_openvino_free(state->ctx_openvino);
state->ctx_openvino = nullptr;
}
#endif
ggml_backend_sched_free(state->sched_encode.sched);
ggml_backend_sched_free(state->sched_decode.sched);
for (auto &backend: state->backends) {
ggml_backend_free(backend);
}
delete state;
}
}
static size_t sense_voice_sched_size(struct sense_voice_sched &sched) {
size_t size = sched.meta.size();
for (int i = 0; i < ggml_backend_sched_get_n_backends(sched.sched); ++i) {
ggml_backend_t backend = ggml_backend_sched_get_backend(sched.sched, i);
size += ggml_backend_sched_get_buffer_size(sched.sched, backend);
}
return size;
}
struct sense_voice_state *sense_voice_init_state(sense_voice_context *ctx) {
ctx->state = new sense_voice_state;
auto state = ctx->state;
state->backends = sense_voice_backend_init(ctx->params);
if (state->backends.empty()) {
SENSE_VOICE_LOG_ERROR("%s: sense_voice_backend_init() failed\n", __func__);
sense_voice_free_state(state);
return nullptr;
}
if (!sense_voice_kv_cache_init(state->kv_pad, state->backends[0], ctx->itype,
ctx->model.hparams.n_encoder_hidden_state,
1,
GGML_PAD(ctx->model.hparams.n_audio_ctx, 256))) {
SENSE_VOICE_LOG_ERROR("%s: sense_voice_kv_cache_init() failed for self-attention cache\n", __func__);
sense_voice_free_state(state);
return nullptr;
}
{
const size_t memory_size = ggml_nbytes(state->kv_pad.k) + ggml_nbytes(state->kv_pad.v);
SENSE_VOICE_LOG_INFO("%s: kv pad size = %7.2f MB\n", __func__, memory_size / 1e6);
}
// set input
{
// init features
state->feature.n_len = SENSE_VOICE_CHUNK_SIZE;
state->feature.ctx = ggml_init({ggml_tensor_overhead(), nullptr, true});
state->feature.tensor = ggml_new_tensor_2d(state->feature.ctx,
GGML_TYPE_F32,
SENSE_VOICE_FEATURES_DIM,
state->feature.n_len);
}
// state->logits_id.reserve(ctx->model.hparams.n_vocab);
// vad allocator
{
bool ok = sense_voice_sched_graph_init(
state->sched_vad, state->backends,
[&]() { return silero_vad_build_graph(*ctx, *state); });
if (!ok) {
SENSE_VOICE_LOG_ERROR("%s: failed to init vad model allocator\n", __func__);
sense_voice_free_state(state);
return nullptr;
}
SENSE_VOICE_LOG_INFO("%s: compute buffer (encoder) = %7.2f MB\n", __func__,
sense_voice_sched_size(state->sched_vad) / 1e6);
}
// encoder allocator
{
bool ok = sense_voice_sched_graph_init(
state->sched_encode, state->backends,
[&]() { return sense_voice_build_graph_encoder(*ctx, *state); });
if (!ok) {
SENSE_VOICE_LOG_ERROR("%s: failed to init encode allocator\n", __func__);
sense_voice_free_state(state);
return nullptr;
}
SENSE_VOICE_LOG_INFO("%s: compute buffer (encoder) = %7.2f MB\n", __func__,
sense_voice_sched_size(state->sched_encode) / 1e6);
}
{
bool ok = sense_voice_sched_graph_init(
state->sched_decode, state->backends,
[&]() { return sense_voice_build_graph_ctc_decoder(*ctx, *state); });
if (!ok) {
SENSE_VOICE_LOG_ERROR("%s: failed to init encode allocator\n", __func__);
sense_voice_free_state(state);
return nullptr;
}
SENSE_VOICE_LOG_INFO("%s: compute buffer (decoder) = %7.2f MB\n", __func__,
sense_voice_sched_size(state->sched_decode) / 1e6);
}
return state;
}
// 500 -> 00:05.000
// 6000 -> 01:00.000
static std::string to_timestamp(int64_t t, bool comma = false) {
int64_t msec = t * 10;
int64_t hr = msec / (1000 * 60 * 60);
msec = msec - hr * (1000 * 60 * 60);
int64_t min = msec / (1000 * 60);
msec = msec - min * (1000 * 60);
int64_t sec = msec / 1000;
msec = msec - sec * 1000;
char buf[32];
snprintf(buf, sizeof(buf), "%02d:%02d:%02d%s%03d", (int) hr, (int) min, (int) sec, comma ? "," : ".", (int) msec);
return std::string(buf);
}
struct sense_voice_context *sense_voice_small_init_from_file_with_params(const char *path_model, struct sense_voice_context_params params) {
sense_voice_context *ctx = sense_voice_small_init_from_file_with_params_no_state(path_model, params);
if (!ctx) {
return nullptr;
}
ctx->state = sense_voice_init_state(ctx);
// if (!ctx->state) {
// sense_voice_small_free(ctx);
// return nullptr;
// }
return ctx;
}
int sense_voice_pcm_to_feature_with_state(struct sense_voice_context *ctx,
struct sense_voice_state *state,
std::vector<double> &pcmf32,
bool debug,
int n_threads) {
const int64_t t_start_us = ggml_time_us();
struct sense_voice_cmvn cmvn;
cmvn.cmvn_means = std::vector<float>(CMVN_MEANS, CMVN_MEANS + cmvn_length);
cmvn.cmvn_vars = std::vector<float>(CMVN_VARS, CMVN_VARS + cmvn_length);
fbank_lfr_cmvn_feature(pcmf32, pcmf32.size(),
state->feature.frame_size,
state->feature.frame_step,
state->feature.n_mel,
n_threads, true, cmvn, state->feature);
state->t_feature_us = ggml_time_us() - t_start_us;
// set input
{
// 释放之前的资源以防止内存泄漏
if (state->feature.ctx) {
ggml_free(state->feature.ctx);
state->feature.ctx = nullptr;
}
if (state->feature.buffer) {
ggml_backend_buffer_free(state->feature.buffer);
state->feature.buffer = nullptr;
}
state->feature.tensor = nullptr;
// init features
state->feature.n_len = state->feature.data.size() / (state->feature.n_mel * state->feature.lfr_m);
state->feature.ctx = ggml_init({ggml_tensor_overhead(), nullptr, true});
state->feature.tensor = ggml_new_tensor_2d(state->feature.ctx,
GGML_TYPE_F32,
state->feature.lfr_m * state->feature.n_mel,
state->feature.n_len);
state->feature.buffer = ggml_backend_alloc_buffer(state->backends[0],
ggml_nbytes(state->feature.tensor) + ggml_backend_get_alignment(state->backends[0]));
auto alloc = ggml_tallocr_new(state->feature.buffer);
ggml_tallocr_alloc(&alloc, state->feature.tensor);
auto &feature = state->feature.tensor;
assert(state->feature.n_mel == ctx->model.hparams.n_mels);
ggml_backend_tensor_set(feature, state->feature.data.data(), 0,
ggml_nbytes(feature));
// state->feature.tensor = ggml_transpose(state->feature.ctx, state->feature.tensor);
}
SENSE_VOICE_LOG_DEBUG("%s: calculate fbank and cmvn takes %.3f ms\n", __func__,
state->t_feature_us / 1000.0);
return 0;
}
int sense_voice_full_with_state(
struct sense_voice_context *ctx,
struct sense_voice_state *state,
struct sense_voice_full_params params,
std::vector<double> pcmf32,
int n_samples) {
// compute features (fbank + cmvn)
if (n_samples > 0) {
sense_voice_pcm_to_feature_with_state(ctx, state, pcmf32, params.debug_mode, params.n_threads);
}
// initialize the decoders
int n_decoders = 1;
switch (params.strategy) {
case SENSE_VOICE_SAMPLING_GREEDY: {
n_decoders = params.greedy.best_of;
} break;
case SENSE_VOICE_SAMPLING_BEAM_SEARCH: {
n_decoders = std::max(params.greedy.best_of, params.beam_search.beam_size);
} break;
};
if (n_decoders > SENSE_VOICE_MAX_DECODERS) {
SENSE_VOICE_LOG_ERROR("%s: too many decoders requested (%d), max = %d\n", __func__, n_decoders, SENSE_VOICE_MAX_DECODERS);
return -4;
}
// overwrite audio_ctx, max allowed is hparams.n_audio_ctx
if (params.audio_ctx > ctx->model.hparams.n_audio_ctx) {
SENSE_VOICE_LOG_ERROR("%s: audio_ctx is larger than the maximum allowed (%d > %d)\n", __func__, params.audio_ctx, ctx->model.hparams.n_audio_ctx);
return -5;
}
state->exp_n_audio_ctx = params.audio_ctx;
// encode audio features starting at offset seek
if (!sense_voice_encode_internal(*ctx, *state, params.n_threads)) {
SENSE_VOICE_LOG_ERROR("%s: failed to encode\n", __func__);
return -6;
}
// encode audio features starting at offset seek
if (!sense_voice_decode_internal(*ctx, *state, params.n_threads)) {
SENSE_VOICE_LOG_ERROR("%s: failed to decode\n", __func__);
return -6;
}
SENSE_VOICE_LOG_DEBUG("\n%s: decoder audio use %f s, rtf is %f. \n\n",
__func__,
(state->t_encode_us + state->t_decode_us) / 1e6,
(state->t_encode_us + state->t_decode_us) / (1e6 * state->duration));
return 0;
}
int sense_voice_full_parallel(struct sense_voice_context *ctx,
sense_voice_full_params ¶ms,
std::vector<double> &pcmf32,
int n_samples,
int n_processors) {
return sense_voice_full_with_state(ctx, ctx->state, params, pcmf32, n_samples);
}
void sense_voice_print_output(struct sense_voice_context *ctx, bool need_prefix, bool use_itn, bool refresh_self) {
for (size_t i = (need_prefix ? 0 : 4); i < ctx->state->ids.size(); i++) {
int id = ctx->state->ids[i];
if (i > 0 && ctx->state->ids[i - 1] == ctx->state->ids[i])
continue;
if (id)
printf("%s", ctx->vocab.id_to_token[id].c_str());
}
if (!refresh_self) printf("\n");
}
int sense_voice_batch_pcm_to_feature_with_state(struct sense_voice_context *ctx,
struct sense_voice_state *state,
bool debug,
int n_threads) {
const int64_t t_start_us = ggml_time_us();
struct sense_voice_cmvn cmvn;
cmvn.cmvn_means = std::vector<float>(CMVN_MEANS, CMVN_MEANS + cmvn_length);
cmvn.cmvn_vars = std::vector<float>(CMVN_VARS, CMVN_VARS + cmvn_length);
state->feature.input_data.clear();
size_t max_len = 0;
for (size_t segmentID: state->segmentIDs)
max_len = std::max(max_len, state->result_all[segmentID].samples.size());
for (size_t segmentID: state->segmentIDs)
{
std::vector<float>& pcmf32 = state->result_all[segmentID].samples;
if(pcmf32.size() < max_len) {
pcmf32.insert(pcmf32.end(), max_len - pcmf32.size(), 0);
}
// 这里实际上可以const。
fbank_lfr_cmvn_feature(pcmf32, pcmf32.size(),
state->feature.frame_size,
state->feature.frame_step,
state->feature.n_mel,
n_threads, false, cmvn, state->feature);
state->feature.input_data.insert(state->feature.input_data.end(), state->feature.data.begin(), state->feature.data.end());
}
state->t_feature_us += ggml_time_us() - t_start_us;
// set input
{
// 释放之前的资源以防止内存泄漏
if (state->feature.ctx) {
ggml_free(state->feature.ctx);
state->feature.ctx = nullptr;
}
if (state->feature.buffer) {
ggml_backend_buffer_free(state->feature.buffer);
state->feature.buffer = nullptr;
}
state->feature.tensor = nullptr;
// init features
state->feature.n_len = state->feature.data.size() / (state->feature.n_mel * state->feature.lfr_m);
state->feature.ctx = ggml_init({ggml_tensor_overhead(), nullptr, true});
state->feature.tensor = ggml_new_tensor_3d(state->feature.ctx,
GGML_TYPE_F32,
state->feature.lfr_m * state->feature.n_mel,
state->feature.n_len,
state->segmentIDs.size());// Batch size
state->feature.buffer = ggml_backend_alloc_buffer(state->backends[0],
ggml_nbytes(state->feature.tensor) + ggml_backend_get_alignment(state->backends[0]));
auto alloc = ggml_tallocr_new(state->feature.buffer);
ggml_tallocr_alloc(&alloc, state->feature.tensor);
auto &feature = state->feature.tensor;
assert(state->feature.n_mel == ctx->model.hparams.n_mels);
ggml_backend_tensor_set(feature, state->feature.input_data.data(), 0,
ggml_nbytes(feature));
// state->feature.tensor = ggml_transpose(state->feature.ctx, state->feature.tensor);
}
SENSE_VOICE_LOG_DEBUG("%s: calculate fbank and cmvn takes %.3f ms\n", __func__,
state->t_feature_us / 1000.0);
return 0;
}
int sense_voice_batch_full(struct sense_voice_context *ctx, const sense_voice_full_params ¶ms) {
sense_voice_state *state = ctx->state;
// compute features (fbank + cmvn)
sense_voice_batch_pcm_to_feature_with_state(ctx, state, params.debug_mode, params.n_threads);
// initialize the decoders
int n_decoders = 1;
switch (params.strategy) {
case SENSE_VOICE_SAMPLING_GREEDY: {
n_decoders = params.greedy.best_of;
} break;
case SENSE_VOICE_SAMPLING_BEAM_SEARCH: {
n_decoders = std::max(params.greedy.best_of, params.beam_search.beam_size);
} break;
};
if (n_decoders > SENSE_VOICE_MAX_DECODERS) {
SENSE_VOICE_LOG_ERROR("%s: too many decoders requested (%d), max = %d\n", __func__, n_decoders, SENSE_VOICE_MAX_DECODERS);
return -4;
}
// overwrite audio_ctx, max allowed is hparams.n_audio_ctx
if (params.audio_ctx > ctx->model.hparams.n_audio_ctx) {
SENSE_VOICE_LOG_ERROR("%s: audio_ctx is larger than the maximum allowed (%d > %d)\n", __func__, params.audio_ctx, ctx->model.hparams.n_audio_ctx);
return -5;
}
state->exp_n_audio_ctx = params.audio_ctx;
// encode audio features starting at offset seek
if (!sense_voice_encode_internal(*ctx, *state, params.n_threads)) {
SENSE_VOICE_LOG_ERROR("%s: failed to encode\n", __func__);
return -6;
}
//
//
// // encode audio features starting at offset seek
if (!sense_voice_decode_internal(*ctx, *state, params.n_threads)) {
SENSE_VOICE_LOG_ERROR("%s: failed to decode\n", __func__);
return -6;
}
SENSE_VOICE_LOG_DEBUG("\n%s: decoder audio use %f s, rtf is %f. \n\n",
__func__,
(state->t_encode_us + state->t_decode_us) / 1e6,
(state->t_encode_us + state->t_decode_us) / (1e6 * state->duration));
return 0;
}
int sense_voice_batch_pcmf(struct sense_voice_context *ctx, const sense_voice_full_params ¶ms, std::vector<std::vector<float>> &pcmf32,
size_t max_batch_len, size_t max_batch_cnt,
bool use_prefix, bool use_itn)
{
// 还是要有ctx,重复生成会重复读取模型,有点耗性能
// ctx中的参数需要在外面赋值,外面的参数形态各异,带不进来
// pcmf32是vector<vecotr>,因此不需要split
for(size_t segmentID = 0; segmentID < pcmf32.size(); segmentID++)
{
sense_voice_segment pcmf_tmp;
pcmf_tmp.t0 = pcmf_tmp.t1 = 0;
pcmf_tmp.samples = pcmf32[segmentID];
ctx->state->result_all.push_back(pcmf_tmp);
}
size_t max_len = 0, batch_L = ctx->state->result_all.size();
for (size_t i = 0; i < ctx->state->result_all.size(); i++) {
if (batch_L >= ctx->state->result_all.size()) {
batch_L = i;
max_len = ctx->state->result_all[i].samples.size();
ctx->state->segmentIDs.push_back(i);
continue;// 这里可以直接推进,收拢到下一个循环处理[batch_L, i]之间的关系
}
max_len = std::max(max_len, ctx->state->result_all[i].samples.size());
// 这里确保了i>batch_L
if (max_len * (i - batch_L + 1) > max_batch_len || i - batch_L >= max_batch_cnt) {
sense_voice_batch_full(ctx, params);
sense_voice_batch_print_output(ctx, use_prefix, use_itn);
batch_L = i;
max_len = ctx->state->result_all[i].samples.size();
ctx->state->segmentIDs.clear();
}
ctx->state->segmentIDs.push_back(i);
}
// 最后一组
if (batch_L < ctx->state->result_all.size()) {
// 识别全部即可
sense_voice_batch_full(ctx, params);
sense_voice_batch_print_output(ctx, use_prefix, use_itn);
ctx->state->segmentIDs.clear();
batch_L = ctx->state->result_all.size();
max_len = 0;
}
return 0;
}
void sense_voice_batch_print_output(struct sense_voice_context *ctx, bool need_prefix, bool use_itn, bool refresh_self) {
SENSE_VOICE_LOG_INFO("=======================================\n");
SENSE_VOICE_LOG_INFO("batch size: %ld\n", ctx->state->segmentIDs.size());
for (size_t i = 0; i < ctx->state->segmentIDs.size(); i++) {
const int resultID = ctx->state->segmentIDs[i];
const sense_voice_segment &result = ctx->state->result_all[resultID];
printf("[%.2f-%.2f]", result.t0 * 1.0 / SENSE_VOICE_SAMPLE_RATE, result.t1 * 1.0 / SENSE_VOICE_SAMPLE_RATE);
for (size_t j = (need_prefix ? 0 : 4); j < result.tokens.size(); j++) {
int id = result.tokens[j];
if (!id || (j > 0 && result.tokens[j - 1] == id))
continue;
printf("%s", ctx->vocab.id_to_token[id].c_str());
}
if (!refresh_self) printf("\n");
}
}
加载 GGUF 格式的 SenseVoice 模型 → 初始化计算后端(CPU/GPU)→ 把音频转成模型能识别的特征 → 编码 + 解码输出文字 → 支持单条 / 批量识别。
分模块极简总结
1. 语言管理
- 语言 ID ↔ 语言名称互相转换
- 校验输入语言是否合法
2. 计算后端(CPU/GPU)初始化
- 自动选择 CPU 或 GPU 运行
- 初始化 ggml 计算后端、设备、缓冲区
3. 模型加载(最核心)
- 从
.gguf模型文件读取参数、权重、词表 - 解析编码器、解码器、VAD 结构
- 加载所有神经网络层权重
- 分配内存并把权重拷贝到设备
4. 上下文与状态初始化
- 创建模型运行上下文
- 初始化 KV 缓存(注意力机制用)
- 初始化 VAD、编码器、解码器的计算图
- 分配计算内存缓冲区
5. 音频特征预处理
- 将音频 PCM 数据转为 Fbank 特征
- 做 LFR、CMVN 归一化
- 转成模型输入张量
6. 识别推理核心
sense_voice_full_with_state:单段语音完整识别流程- 特征提取 → 编码 → 解码 → 输出文本
sense_voice_full_parallel:并行识别接口
7. 批量识别
- 支持同时处理多段音频
- 批量特征提取、批量编码解码
- 批量输出带时间戳的结果
8. 结果输出
- 打印识别文本
- 输出带时间戳格式
- 支持跳过前缀、逆文本标准化
9. 内存管理
- 安全释放模型、状态、缓冲区、计算图
- 避免内存泄漏
人人皆为创造者,共创方能共成长
每个人都是使用者,也是创造者;是数字世界的消费者,更是价值的生产者与分享者。在智能时代的浪潮里,单打独斗的发展模式早已落幕,唯有开放连接、创意共创、利益共享,才能让个体价值汇聚成生态合力,让技术与创意双向奔赴,实现平台与伙伴的快速成长、共赢致远。
原创永久分成,共赴星辰大海
原创创意共创、永久收益分成,是东方仙盟始终坚守的核心理念。我们坚信,每一份原创智慧都值得被尊重与回馈,以永久分成锚定共创初心,让创意者长期享有价值红利,携手万千伙伴向着科技星辰大海笃定前行,拥抱硅基 生命与数字智能交融的未来,共筑跨越时代的数字文明共同体。
东方仙盟:拥抱知识开源,共筑数字新生态
在全球化与数字化浪潮中,东方仙盟始终秉持开放协作、知识共享的理念,积极拥抱开源技术与开放标准。我们相信,唯有打破技术壁垒、汇聚全球智慧,才能真正推动行业的可持续发展。
开源赋能中小商户:通过将前端异常检测、跨系统数据互联等核心能力开源化,东方仙盟为全球中小商户提供了低成本、高可靠的技术解决方案,让更多商家能够平等享受数字转型的红利。
共建行业标准:我们积极参与国际技术社区,与全球开发者、合作伙伴共同制定开放协议 与技术规范,推动跨境零售、文旅、餐饮等多业态的系统互联互通,构建更加公平、高效的数字生态。
知识普惠,共促发展:通过开源社区 、技术文档与培训体系,东方仙盟致力于将前沿技术转化为可落地的行业实践,赋能全球合作伙伴,共同培育创新人才,推动数字经济 的普惠式增长
阿雪技术观
在科技发展浪潮中,我们不妨积极投身技术共享。不满足于做受益者,更要主动担当贡献者。无论是分享代码、撰写技术博客,还是参与开源项目 维护改进,每一个微小举动都可能蕴含推动技术进步的巨大能量。东方仙盟是汇聚力量的天地,我们携手在此探索硅基 生命,为科技进步添砖加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets , hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)