从第一性原理理解如何选择机器学习算法
在机器学习的浩瀚海洋中,初学者常常会问:“哪个算法是最好的?”而经验丰富的老手则会沉吟片刻,反问:“你的问题是什么?”
今天,就让我们深入算法的“第一性原理”,自上而下地剖析“算法选择理论”,拨开迷雾,看清那条指导我们做出明智选择的根本路径。
一、 核心决策流程图:自上而下的选择逻辑
在我们深入理论之前,先通过一张心智地图俯瞰全局。算法选择的本质,是一个从问题出发,匹配本质,到实验验证的闭环过程。
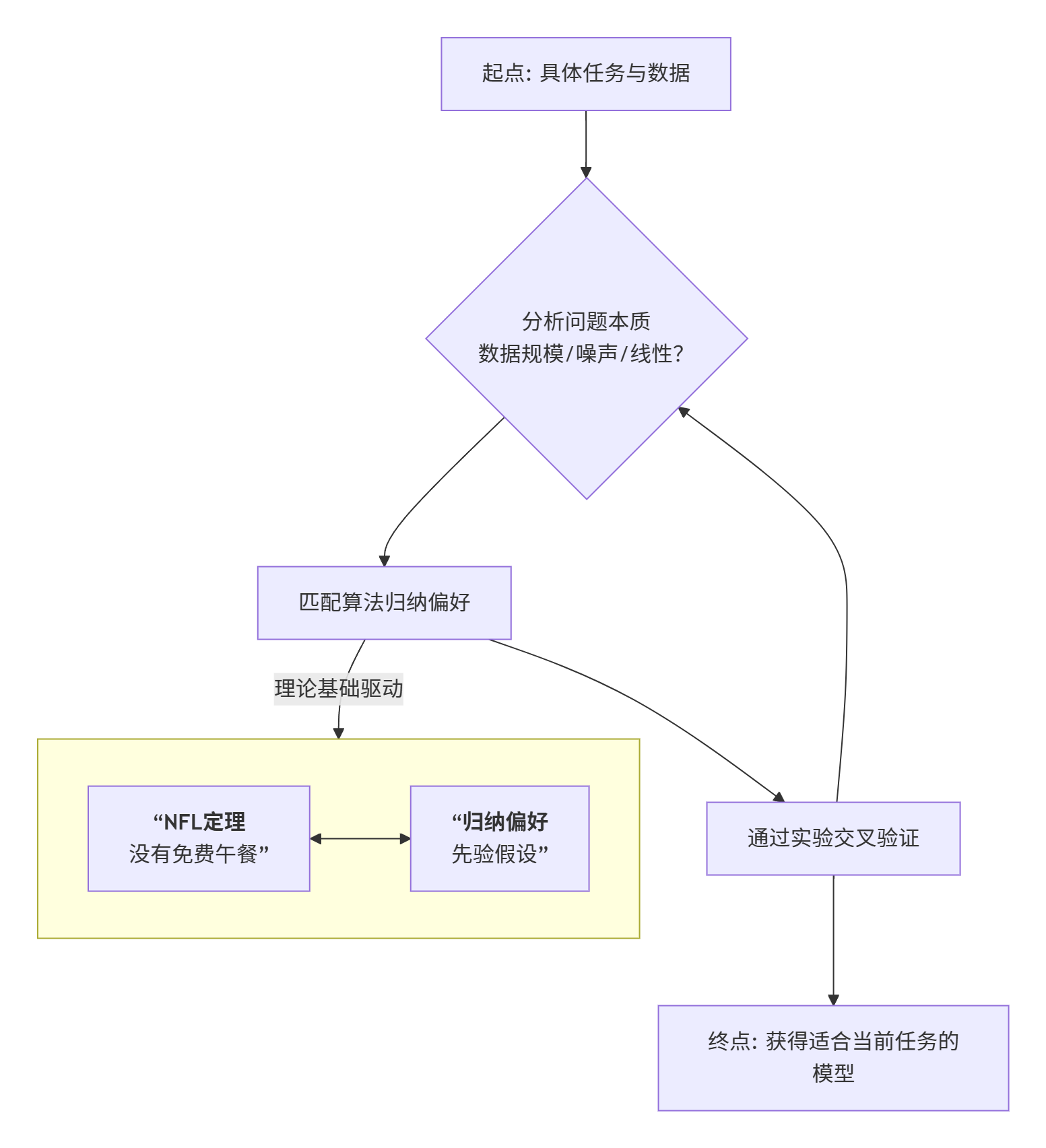
如图所示,一切始于你的具体问题。而背后的驱动力量,正是两大相互依存的理论基石:NFL 定理告诉我们没有万能药,归纳偏好则为我们提供了开锁的钥匙。下面,我们深入这两大支柱。
二、 理论支柱一:NFL 定理——对“银弹”的终极否定
第一性原理起点:我们一切努力的终极目标是最小化泛化误差,即模型在未知数据上的表现。这误差取决于两个根本因素:世界的本质(数据背后的真实分布)和我们的算法(从数据中学习的方式)。
核心推导与结论:
如果我们以最“干净”的起点思考——不对现实世界做任何先验假设,即认为所有可能的数据分布出现的可能性都相同,那么一个深刻的数学结论便浮现出来:
在所有可能问题的平均表现上,任何两个学习算法的性能是完全相同的。
这就是著名的 **“没有免费午餐”定理。它冷酷地揭示:如果一个算法在某一类问题上表现更好(例如神经网络在图像识别上),那么必然存在**另一类问题上它会更差(可能恰好是另一个算法的强项)。算法之间的优劣,是“能量守恒”的。
🚨 实践启示:
- 脱离具体问题谈论“最强算法”是毫无意义的。下次看到“XX 模型彻底打败了 YY 模型”的标题时,请立刻思考:在什么任务上?数据有什么特点?
- 这一定理将我们的目光从“追逐潮流”强行拉回至理解自身任务。它是我们避免被炒作带偏的“定海神针”。
三、 理论支柱二:归纳偏好——我们如何“合理偏心”
NFL 定理让我们陷入困境:如果没有任何偏好,学习就无法进行(因为从有限数据中无法唯一确定一个模型)。我们必须“偏心”,但必须“合理”地偏心。
第一性原理起点:这个“合理的偏心”就是归纳偏好——算法在众多与训练数据一致的假设中做出选择的固有倾向。而它的基石,是奥卡姆剃刀。
奥卡姆剃刀:偏好的公理
“如无必要,勿增实体。” —— 威廉·奥卡姆
在机器学习中,它意味着:在其他条件相同时,应优先选择更简单、复杂度更低的假设。
- 数学直观:简单模型对应更小的假设空间。在有限数据下,它纯粹由巧合(即拟合噪声)而完美解释数据的概率更低,因此其泛化能力更强的先验概率更高。
常见算法的“偏好光谱”:
| 算法 | 隐含的归纳偏好 | 适用的场景暗示 |
|---|---|---|
| 线性回归/逻辑回归 | 偏好认为目标是特征的线性组合。 | 问题本质接近线性关系,或特征经过很好的工程构造。 |
| 决策树 | 偏好基于单个特征的轴平行边界进行决策。 | 特征具有明确的、阶梯式的决策边界。 |
| 支持向量机 | 偏好最大化分类边界到样本的间隔。 | 相信两类数据之间存在一个清晰的、宽阔的分离带。 |
| 深度神经网络 | 偏好通过多层非线性变换逼近高度复杂的函数。 | 问题结构极其复杂(如图像、语音),且拥有海量数据。 |
🚨 实践启示:
- 选择算法,本质是将问题的本质结构与算法的归纳偏好进行匹配。
- 如果你的数据背后是简单的线性规律,用复杂的深度模型(偏好复杂函数)反而容易过拟合(记住了噪声而非规律)。
- 偏好没有对错,只有匹配与否。
归纳偏好的通俗理解:
对于一个任务,给定一个训练数据集,通常会有多个模型(假设)都能‘拟合’这些数据(即完成归纳)。而不同的算法(学习器),会根据其自身设计固有的原则(偏好),自动从中选择一个作为最终模型。我们(人类)的‘经验’则体现在:根据对问题的理解,去选择一个其内置偏好与问题特性相匹配的算法。
四、 自上而下的实践路线图
理论最终要指导实践。结合 NFL 和归纳偏好,我们可以形成一套稳健的算法选择方法论:
-
深度剖析你的问题:
- 任务是什么? (分类、回归、聚类…)
- 数据规模与维度? (样本多少?特征多少?)
- 数据质量如何? (噪声大吗?有缺失吗?)
- 领域知识暗示了什么结构? (物理上是否线性?医学上是否有关键指标?)
-
基于偏好进行初步匹配:
- **“简单问题简单对待”:数据量小、结构疑似简单时,从强偏好简单模型**的算法开始(如线性模型 + 正则化)。
- **“复杂问题赋予容量”:数据量大、结构明显非线性时,考虑表达能力更强的算法(如树模型集成、神经网络),但必须配备正则化、Dropout** 等“刹车”装置来控制其复杂偏好。
-
实验验证与迭代:
- 设定合理的评估流程(如交叉验证)。
- 在几个匹配度高的候选算法间进行公平比较。
- 理解误差来源:是偏差过大(模型太简单,偏好与事实不符),还是方差过大(模型太复杂,对噪声敏感)?根据分析调整偏好。
总结
- NFL 定理是清醒剂,它从根本上否定了“万能算法”的存在,迫使我们必须聚焦于具体问题。
- 归纳偏好是导航仪,它基于“奥卡姆剃刀”这一思维公理,为我们在无限的假设海洋中提供了做出合理选择的依据。
- 明智的实践,是一个自上而下的循环:从理解世界(问题)出发,到挑选合适的工具(匹配偏好),再到实验反馈,不断迭代。
所以,请记住:在机器学习的世界里,最好的算法,就是最适合你所解问题本质的那个算法。 没有免费的午餐,但有一张需要你用智慧和洞察去填写的、精准的菜单。
<div>
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js?client=ca-pub-3673170584746784" crossorigin="anonymous"></script>
<ins class="adsbygoogle"
style="display:block; text-align:center;"
data-ad-layout="in-article"
data-ad-format="fluid"
data-ad-client="ca-pub-3673170584746784"
data-ad-slot="2899723242"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
</div>

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)