从串口丢数据说起——环形缓冲区的几个实战心得
摘自:一枚嵌入式码农
链接:https://mp.weixin.qq.com/s/KQw3ta74YhkeZmCvYVTiAw
目录
做嵌入式开发的朋友,大概都经历过这么一个场景:
串口中断里收数据,主循环里解析协议。测试的时候一切正常,一上量产板子,数据就开始莫名其妙地丢。加了printf调试,反而更丢了。你盯着逻辑分析仪的波形,确认硬件没问题,数据确实发过来了——但软件这边就是少了几个字节。
问题出在哪?多半是你的缓冲区方案不对。
很多人第一反应是用一个全局数组,搞两个下标,一个写、一个读。思路没错,但细节上有不少门道。今天不讲教科书理论,就聊聊在实际项目中围绕环形缓冲区踩过的坑和积累的经验。
为什么是"环"?
先说最基本的东西。环形缓冲区本质上就是一个定长数组,加上两个索引——head(写指针)和 tail(读指针)。写数据时 head 往前走,读数据时 tail 往前走。关键在于:走到数组末尾时,绕回开头。
这就是"环"的由来。物理上是一段连续内存,逻辑上首尾相连:
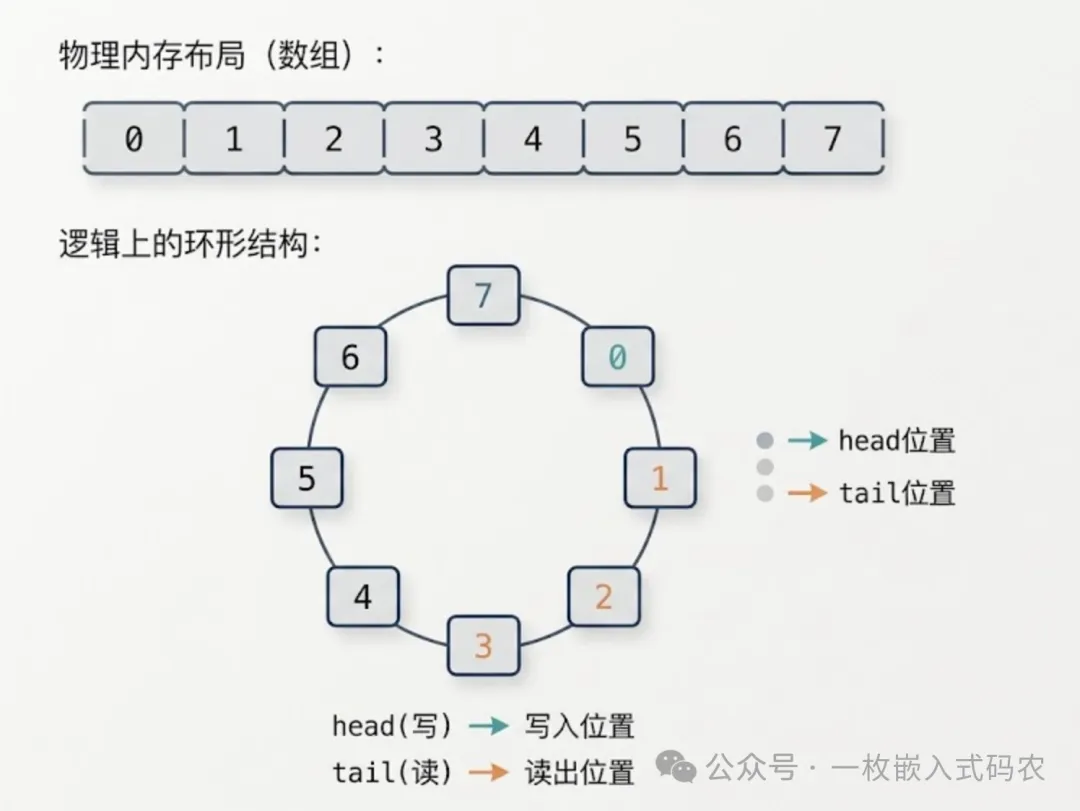
上图画的不太对,应该是head在前,tail在后,先写后读。
和普通队列比,环形缓冲区最大的好处是不需要搬移数据。普通数组队列读完前面的数据后,要么整体前移,要么浪费空间。环形缓冲区天然解决了这个问题——读写指针追着跑就行。
对嵌入式场景来说还有一个关键优势:内存在编译期就确定了,不需要动态分配。在资源紧张的MCU上,这一点非常重要。
动手写一个:但别急着抄
网上环形缓冲区的代码满天飞,但很多实现在嵌入式环境下会出问题。我贴一个网上随便找的开源版本代码,重点说说每个决策背后的原因。
#define RING_BUF_SIZE 256 /* 必须是2的幂次方! */
typedef struct {
uint8_t buf[RING_BUF_SIZE];
volatile uint32_t head; /* 写索引 */
volatile uint32_t tail; /* 读索引 */
} ring_buf_t;
/* 写入一个字节 —— 通常在中断中调用 */
int ring_buf_put(ring_buf_t *rb, uint8_t data)
{
uint32_t next = (rb->head + 1) & (RING_BUF_SIZE - 1);
if (next == rb->tail)
return -1; /* 满了,丢弃 */
rb->buf[rb->head] = data;
rb->head = next;
return 0;
}
/* 读出一个字节 —— 通常在主循环中调用 */
int ring_buf_get(ring_buf_t *rb, uint8_t *data)
{
if (rb->head == rb->tail)
return -1; /* 空的 */
*data = rb->buf[rb->tail];
rb->tail = (rb->tail + 1) & (RING_BUF_SIZE - 1);
return 0;
}
代码不长,但有几个细节值得展开讲。
三个实战技巧,都是踩坑换来的
技巧一:缓冲区大小必须是2的幂次方
注意看取模操作,这里没有用 %,而是用了 &:
(rb->head + 1) & (RING_BUF_SIZE - 1)
当 RING_BUF_SIZE 是2的幂次方(如 64、128、256)时,x % SIZE 等价于 x & (SIZE - 1)。位与操作比取模快得多,在没有硬件除法器的MCU上(比如Cortex-M0),这个差距相当可观。
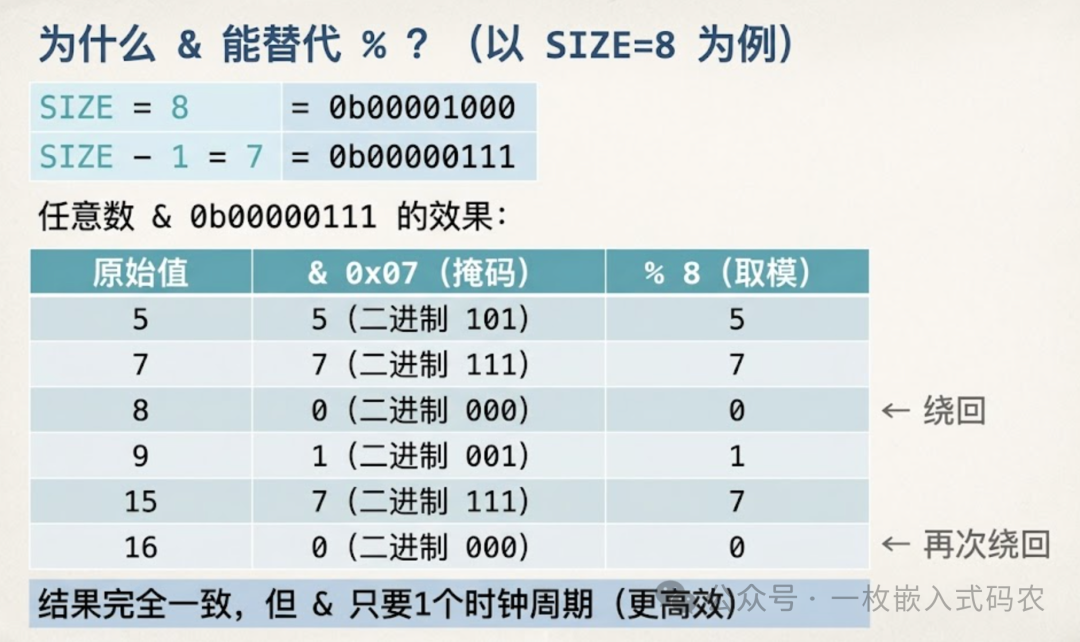
这个技巧在Linux内核的 kfifo 里也是这么用的,属于经典做法。
技巧二:volatile不是万能的,但不能没有
注意 head 和 tail 都声明成了 volatile。为什么?
在典型的嵌入式使用场景中,中断写 head,主循环读 head;主循环写 tail,中断读 tail。如果不加 volatile,编译器可能把 head 的值缓存到寄存器里,主循环永远看到的是旧值——数据明明写进去了,但读端以为缓冲区是空的。

但要注意:volatile 只保证每次都从内存读取,不保证操作的原子性。在单核MCU上,单生产者单消费者的场景下,volatile 就够了。但如果是多核系统或者涉及DMA,还需要额外的内存屏障(memory barrier),这是另一个话题了。
volatile怎么防止编译器优化了
volatile 是 C/C++ 中的类型修饰符,核心作用是告诉编译器:这个变量的值可能会被当前程序之外的因素修改(如硬件、中断、多线程),编译器绝对不能对这个变量做 “自作聪明” 的优化。
你可以把它理解为:给变量贴一个 “警告标签”——「编译器别瞎改,这个变量的值随时可能变,每次用都必须去内存里读,每次改都必须立刻写回内存」。
💥 编译器对普通变量的 “优化坑”(没有 volatile 时)
先看一个例子,理解编译器会做哪些优化,而 volatile 如何阻止这些优化:
场景 1:重复读取优化(寄存器缓存)
// 普通变量(无 volatile)
int flag = 0;
while(flag == 0) {
// 循环等待 flag 被其他因素修改
}
编译器优化后可能会:
- 第一次读取内存 flag 到 CPU 寄存器;
- 后续循环不再去内存读 flag,直接用寄存器里的旧值(偷懒);
- 即使内存中 flag 被硬件 / 中断改成 1,循环也永远不会退出。
场景 2:无用赋值优化(删除 “看似无效” 的操作)
// 普通变量(无 volatile)
int *addr = (int*)0x12345678; // 硬件寄存器地址
addr = 1; // 给硬件寄存器写值
addr = 2; // 再次写值
编译器优化后可能会:
- 认为连续给同一个变量赋值,只有最后一次有效,直接删除 addr = 1;(偷懒);
- 但硬件寄存器可能需要先写 1 触发初始化,再写 2 生效,优化后逻辑完全错误。
✨ volatile 如何 “阻止” 这些优化?
给变量加上 volatile 后,编译器会遵守 3 条铁律:
1. 禁止寄存器缓存(每次读写都走内存)
// volatile 变量
volatile int flag = 0;
while(flag == 0) {
// 每次循环都会从内存重新读取 flag 的值
// 即使内存中 flag 被外部修改,循环能立刻感知
}
2. 禁止指令重排(按代码顺序执行读写)
编译器不会调整 volatile 变量相关指令的执行顺序,保证硬件 / 其他线程能按预期看到变量的修改顺序。
3. 禁止删除 “无用” 赋值(保留所有写操作)
volatile int *addr = (volatile int*)0x12345678;
addr = 1; // 必须执行,写入内存
addr = 2; // 必须执行,写入内存
编译器不会删除任何对 volatile 变量的赋值,因为这些赋值可能是给硬件寄存器发指令,而非普通内存操作。
🎯 实际应用场景(为什么需要 volatile?)
- 硬件寄存器操作(如你代码中的嵌入式 / 驱动场景):
硬件寄存器的地址映射到内存,读写这些地址是和硬件交互,必须每次都真读写,不能优化。 - 中断服务程序(ISR)与主程序共享变量:
主程序等待中断触发的标志位,标志位在中断里修改,必须加 volatile 才能让主程序看到最新值。 - 多线程共享变量(简单场景):
虽然多线程更推荐用 mutex/atomic,但 volatile 能保证变量读写不被优化(注意:volatile 不保证原子性,仅阻止编译器优化)。
📌 关键注意事项
- volatile 不是 线程安全的 “银弹”:它只阻止编译器优化,不保证多线程下的原子性(如 i++ 仍可能竞态),复杂场景需用 std::atomic 或锁。
- volatile 修饰的变量,所有操作都要显式加 volatile:比如指针 volatile int *p 表示指针指向的内容是 volatile,int *volatile p 表示指针本身是 volatile。
- 仅对 “可能被外部修改” 的变量使用:滥用 volatile 会降低性能(失去编译器优化的好处)。
技巧三:留一个空位来区分"满"和"空"
环形缓冲区有个经典问题:当 head == tail 时,到底是"满"还是"空"?
上面的实现采用了最常见的做法——牺牲一个存储位。满的判断条件是 next_head == tail,意味着 head 追上 tail 之前就停下来,永远保留一个空位。

另一种做法是加一个 count 变量记录当前数据量,就能用满全部空间。
但 count 的自增自减在中断和主循环中都要操作,必须保证原子性——这在某些平台上反而更麻烦。所以多数时候,浪费一个字节是更划算的选择。
进阶玩法:DMA + 环形缓冲区
如果你的串口波特率到了 921600 甚至更高,逐字节中断的方案就撑不住了——中断太频繁,CPU被打断得喘不过气。这时候就该让DMA上场。
思路是这样的:让DMA直接往环形缓冲区的数组里搬数据,CPU只需要定期来看看DMA搬到哪了。

关键代码片段:
/* DMA配置为循环模式,目标地址指向 rb.buf */
/* 获取DMA当前写到哪了 */
uint32_t dma_get_head(ring_buf_t *rb)
{
/* NDTR: 剩余未传输的数据数量 */
/* DMA写位置 = 总大小 - 剩余数量 */
return (RING_BUF_SIZE - __HAL_DMA_GET_COUNTER(&hdma_rx))
& (RING_BUF_SIZE - 1);
}
/* 在主循环或定时器中断中调用 */
void process_uart_data(ring_buf_t *rb)
{
uint32_t head = dma_get_head(rb);
while (rb->tail != head) {
uint8_t byte = rb->buf[rb->tail];
rb->tail = (rb->tail + 1) & (RING_BUF_SIZE - 1);
/* 送给协议解析器处理 */
protocol_feed(byte);
}
}
这种方案的好处是:接收数据完全不需要CPU介入。DMA在后台默默搬运,CPU想什么时候来取就什么时候来取。哪怕主循环偶尔卡一下也没关系,只要别卡到缓冲区被覆盖就行。
最后
回头看环形缓冲区这个东西,代码量不大,但用好它需要理解中断机制、编译器优化、内存模型这些底层知识。这也是嵌入式开发有意思的地方——越简单的东西,越考验基本功。
不知道你有没有注意到,环形缓冲区其实是一个典型的生产者-消费者模型。中断是生产者,主循环是消费者,缓冲区是它们之间的"解耦层"。这种解耦的思想,在软件设计中无处不在。
很多嵌入式工程师觉得"设计模式"是Java/C++那帮人的东西,跟我们写单片机的没关系。但你仔细想想——环形缓冲区不就是生产者-消费者模式吗?状态机不就是状态模式吗?回调函数不就是观察者模式的简化版吗?HAL库的分层抽象不就是策略模式吗?
我们天天在用设计模式,只是没有意识到而已。
当你有意识地去理解这些模式背后的思想,再反过来审视自己的代码,很多之前想不通的架构问题会豁然开朗。写出来的代码也会从"能跑"变成"好维护"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)