SLM核心优势与操作系统应用趋势
一、SLM核心优势评估:低成本高精度颠覆AI部署范式
1.1 幻觉率显著优化:垂直数据训练实现精准响应
SLM通过采用领域专属数据集进行训练,从根本上减少了虚假或无关信息的生成,实现了对幻觉率的显著优化。这一机制的核心在于,相较于通用大模型(LLM)依赖海量但宽泛的互联网数据进行训练,SLM的训练数据高度聚焦于特定垂直领域,从而在相关任务上能够提供更高确定性与零容错特性的响应。例如,在中文处理场景中,Qwen2.5-1.5B模型通过针对性的训练,在多轮对话中上下文引用准确率高达96.7%,即使在连续10轮追问下也能保持稳定,有效降低了因上下文遗忘或混淆而产生的幻觉风险。同样,Qwen2.5-0.5B-Instruct模型通过大规模高质量中文语料训练和严格的指令微调,能够准确回溯多轮对话上下文,从而生成更精准的响应。这种精准响应能力不仅体现在对话中,也延伸至结构化输出。Qwen2.5-0.5B-Instruct通过知识蒸馏与强化微调,能够稳定返回符合预定Schema的JSON或表格格式内容,使其适合作为需要高可靠性的Agent后端或API接口引擎。这表明,通过训练数据的聚焦与深度微调,SLM在控制幻觉、提升响应准确性方面构建了系统性优势,为在要求高可靠性的场景(如操作系统指令解析、金融合规审核)中部署奠定了基础。
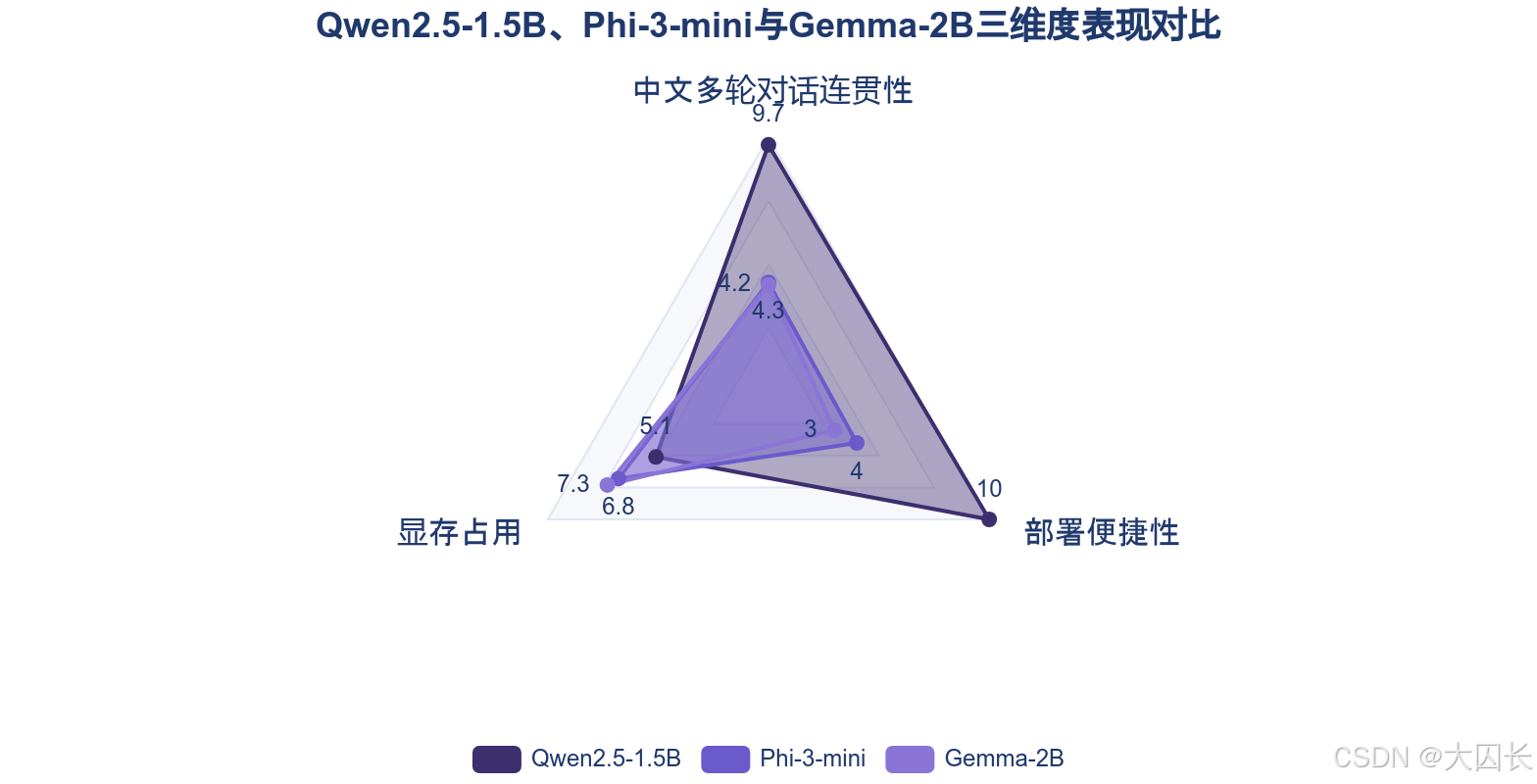
1.2 领域知识专精度突出:任务适配性超越通用模型
在垂直领域任务中,SLM凭借参数精简与架构的针对性优化,展现出超越通用模型的专家级性能表现。其高专精度并非源于参数规模的简单堆砌,而是通过专业化训练路径实现的深度领域知识适配。以代码生成领域为例,DeepSeek-Coder-1.5B虽参数量不大,但因其专门针对代码任务进行预训练和微调,在代码生成质量(4.7)、代码理解能力(4.8)和错误检测能力(4.6)三项关键指标上均显著高于同规模通用模型Qwen2.5-1.5B和Phi-3-mini。在医疗领域,70亿参数的Diabetica-7B在糖尿病相关测试中的精度甚至超越了GPT-4,这强有力地证明了SLM在垂直领域的深度知识掌握能力。此外,SLM的专精度具有明显的语言和场景适配特征。Qwen2.5系列模型在中文领域表现出突出优势,Qwen2.5-0.5B-Instruct在中文文学创作和代码生成任务中输出符合中文语境且正确完整,而Phi-3-mini则在中文指令理解和表达上常出现偏差,其优势更集中于英文场景。这种差异揭示了架构优化与训练数据对齐是驱动SLM在特定任务上达到高精度的核心路径,使其能够在电商客服、专业代码辅助、医疗诊断支持等场景中提供可靠的专业级服务。
1.3 成本效率优势凸显:边缘部署降低企业应用门槛
SLM的核心竞争力之一在于其卓越的成本效率,这主要体现在显著降低的训练与推理资源需求、更低的运行能耗以及前所未有的部署灵活性上,从而为中小企业规模化落地AI应用提供了可行性支撑。与动辄需要千亿参数、依赖昂贵云端算力的LLM相比,SLM的部署成本可降至同类LLM的1/10。例如,Cohere的Command R7B(70亿参数)可直接在标准CPU上运行,算力成本降低80%以上。在边缘侧,成本优势更为明显。微软Phi-3 Mini(38亿参数)和Qwen2.5-0.5B-Instruct均可直接运行于手机端,后者使用量化技术后模型体积可压缩至0.3GB,在树莓派等设备上仅需2GB内存,使得推理成本相比云端部署降低70%以上,年综合成本仅为云服务的6.8%。
| 模型 | 参数量 | 典型显存/内存占用 | 部署便捷性 | 适用设备 |
|---|---|---|---|---|
| Qwen2.5-1.5B | 15亿 | 5.1GB (显存) | 极高,一行配置开箱即用 | RTX 3060等消费级GPU |
| Qwen2.5-0.5B-Instruct | 5亿 | 2GB RAM (内存) | 高,支持量化至0.3GB | 树莓派、智能手机 |
| Phi-3-mini | 38亿 | 6.8GB (显存) | 中,需专用tokenizer等配置 | 手机端、标准CPU |
| Gemma-2B | 20亿 | 7.3GB (显存) | 低,中文场景表现不佳 | 消费级GPU |
这种经济性不仅体现在硬件成本上,也体现在技术门槛的降低。Qwen2.5-1.5B无需手动调参即可在RTX 3060显卡上开箱即用,而Qwen2.5-0.5B-Instruct仅需一行配置即可自动适配硬件与精度,实现了“零配置”本地部署。相比之下,Phi-3-mini的部署则需要更复杂的强制配置。因此,SLM通过其低资源消耗、低部署复杂度与高硬件兼容性,真正打破了企业,特别是中小企业在数据安全、网络延迟和预算限制下的AI应用壁垒,推动了智能技术的普惠化落地。
二、操作系统级SLM应用趋势:意图理解重构人机交互
2.1 意图识别智能化:实时响应优化任务执行效率
操作系统级SLM的核心价值在于,通过低延迟、高精度的意图理解,将用户指令转化为高效的系统任务执行。这依赖于一个从多模态感知到实时推理的完整技术链条。首先,SLM通过集成自动语音识别(ASR)、文本转语音(TTS)等能力,实现对用户语音、文本输入的精准捕获与解析。NVIDIA Riva ASR支持包括英语、中文在内的多种语言,且内存占用减少,为操作系统提供了跨语言的实时意图输入能力。在此基础上,SLM能够处理来自游戏世界或系统环境的音频、视觉和状态数据,实现多模态感知与复杂推理,从而深度理解用户指令的上下文与真实意图。
为实现实时响应,系统级SLM必须在设备端完成低延迟推理。NVIDIA ACE提供的针对设备端推理优化的小型AI模型,可在较小内存占用下实现高精度,并支持跨GPU、NPU、CPU的多硬件加速器推理。这为操作系统级SLM在本地硬件上运行提供了技术基础,确保了用户交互的即时性。例如,专为低延迟设计的Mistral-Nemo-Minitron系列SLM,能够满足每秒8-13次微决策的认知需求,足以支撑操作系统对用户意图的快速解析与任务调度。NVIDIA的游戏内推理(NVIGI)SDK则通过C++和CUDA实现AI模型与图形工作负载的协同调度,为这种低延迟、高并发的推理需求提供了底层架构支持。由此,当用户发出“整理桌面并打开工作报告”的复合指令时,系统级SLM能够实时解析意图,并自动调度文件管理、应用启动等多个后台任务,显著优化任务执行效率。
2.2 交互范式升维:无缝整合提升系统级协同能力
系统级SLM的深度集成,正推动操作系统的人机交互范式从被动的命令执行向主动的预测与协同升维。这一转变的关键在于SLM对用户行为模式的持续学习与上下文感知能力的增强。SLM能够根据用户的历史行为、偏好和当前情境动态调整响应策略,例如通过分析玩家的每一个选择与互动,转化为行为数据标签,从而预测其下一步意图并提供个性化服务。这种能力使交互不再局限于简单的“提问-回答”模式,而是进化为一种持续伴随、智能辅助的协同关系。
多模态融合是交互范式升维的另一核心。SLM通过整合语音、视觉乃至情感信号,实现更自然、更具表现力的交互。NVIDIA ACE的Audio2Face-3D和Audio2Emotion-3D模型可以从音频中实时生成面部动画与推断情绪状态,为数字助手或虚拟形象注入情感表达能力。这使得操作系统能够理解用户语音中的情感色彩,并做出更具共情力的回应,极大增强了交互的自然性与沉浸感。这种多模态能力与SLM的意图理解相结合,共同推动交互向无缝整合演进。例如,在虚拟协作场景中,基于NVIDIA ACE构建的虚拟人类能够智能地观察、感知环境,并通过自然语言交流给出建议,体现了系统级协同的潜力。
最终,这种无缝整合依赖于统一的技术框架。NVIDIA ACE通过与Unreal Engine、NVIDIA Omniverse等工具的集成,实现了微服务间的高效协调,为操作系统提供了端到端的意图理解与响应控制架构。在此框架下,SLM驱动的智能体能够理解并支持用户目标,例如通过语音指令协作完成复杂任务,识别准确率可达92%,这标志着人机交互正从工具使用范式迈向真正的智能协同范式。
三、应用级SLM游戏场景创新:动态NPC与智能助手重塑体验
3.1 智能攻略助手:行为分析驱动个性化内容生成
应用级SLM作为智能攻略助手,其核心价值在于通过深度分析玩家行为数据,实现游戏内容的动态适配与个性化生成。这一过程通常结合了检索增强生成(RAG)技术,使SLM能够基于玩家的实时偏好与历史行为,动态生成任务、剧情乃至道具推荐。例如,在《寂静追凶录》中,玩家的具体行为(如选择信任直觉或依赖技术)被转化为行为标签,这些标签直接驱动NPC调整决策并解锁隐藏剧情,实现了基于玩家推理风格的动态内容生成。这表明,SLM驱动的攻略助手超越了静态的攻略查询,能够根据玩家的独特游玩路径提供定制化的引导与提示。
在此基础上,SLM通过多模态交互与后训练技术,将个性化内容生成提升至实时响应与情感共鸣的层面。在《永劫无间》手游中,AI队友不仅能够精准解析玩家的语音指令(如“集火敌人”),还能通过记忆感知后训练,抓取玩家感知更强的记忆点,生成“意外惊喜”式的互动,从而作为动态提示生成器,提升玩家的策略决策体验。育碧的实验项目《队友》(Teammates)进一步展示了SLM作为智能助手的深度整合能力,其中的AI语音助手贾斯帕(Jaspar)不仅能依据玩家语音指令提供敌人标示、背景资讯等辅助功能,还能以剧情角色的身份提供世界观解读与行动指引,动态生成符合场景的引导内容,极大地增强了游戏的沉浸感。腾讯在《王者荣耀》中应用的AI Coaching技术,同样结合了大语言模型与语音技术,为玩家提供个性化的语音教学与实时指导,实现了从行为分析到内容生成的闭环。

3.2 动态NPC协作:自主决策提升战斗与策略深度
SLM赋予游戏NPC环境感知与自主规划能力,使其从脚本驱动的静态角色转变为具有动机与个性的动态协作伙伴,从根本上提升了战斗与策略的深度。这一转变的关键在于SLM能够处理多模态输入(如视觉、音频、游戏状态),并进行复杂推理。以生活模拟游戏《inZOI》为例,其中的NPC(Smart Zoi)能在生活目标驱动下自主行动,根据环境特征、人际关系和经济状态动态调整行为,例如因失业而主动求职,或对流浪者表现出同情并购买食物。这种基于内在动机的决策机制,创造了复杂的社会互动,为游戏世界注入了高度的真实感与不可预测性。
在战斗与策略场景中,SLM驱动的动态NPC通过持续学习与自适应,实现了与玩家的深度协同与对抗。在《传奇5》(MIR 5)中,AI Boss能够通过NVIDIA ACE等技术持续学习玩家的战术、技能和装备,并动态调整攻击策略,使每次对战都独一无二,迫使玩家不断适应与提升,避免了传统Boss战的模式化应对。在协作方面,《永劫无间》手游PC版与《PUBG: BATTLEGROUNDS》中的AI队友,能够理解玩家目标,提供有效的战术建议、资源共享乃至并肩作战。特别是《永劫无间》中的AI队友,可在PC端侧本地运行,协助玩家进行战斗决策、交换装备并提供技能解锁建议,展现了低延迟、高响应的协同作战能力。
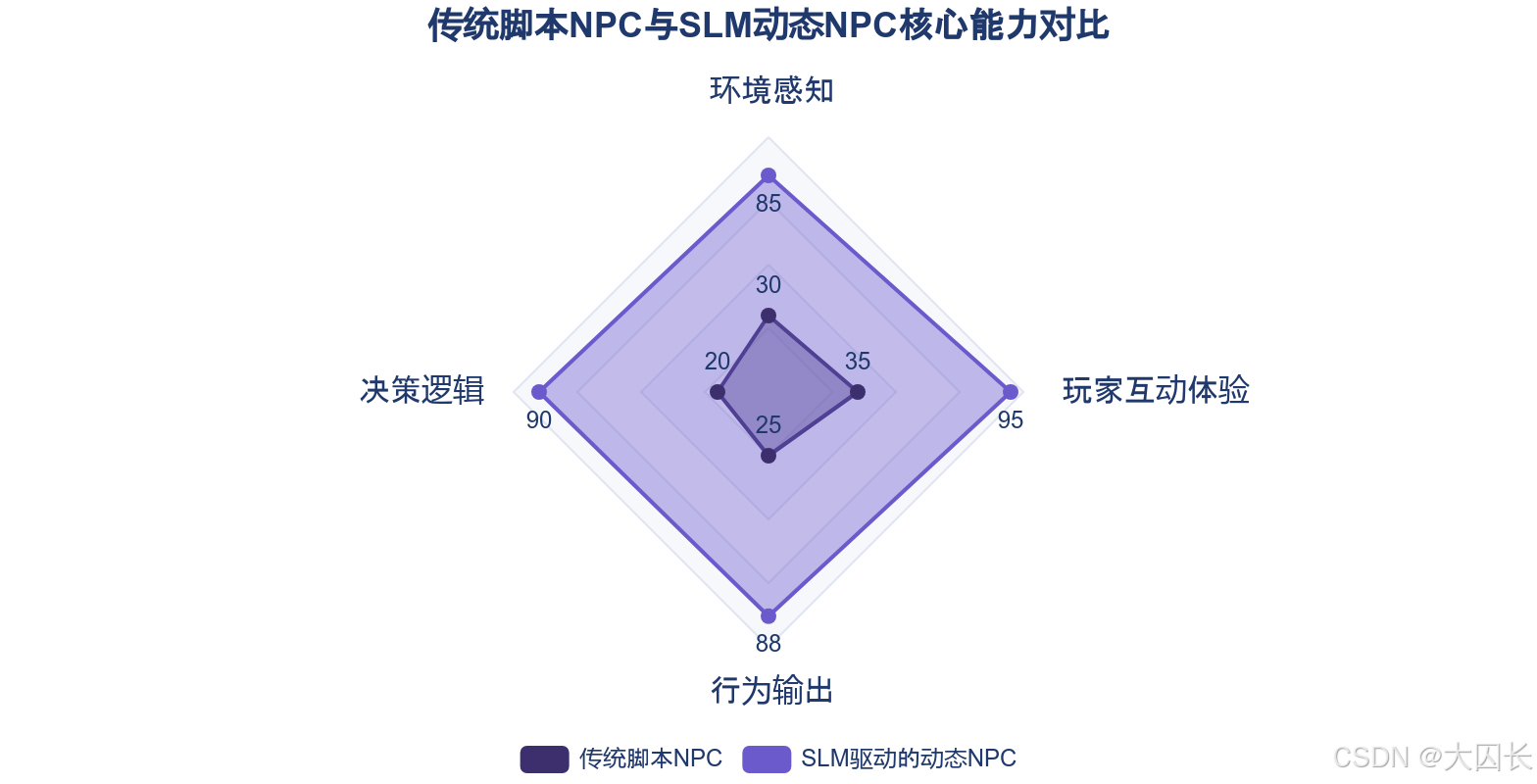
更为复杂的协作机制体现在NPC具备类人的权衡与决策过程。例如,《新倩女幽魂》端游的家臣系统中,NPC会基于自身基准薪资、与玩家的关系亲疏及出身背景等多重动态因素,自主决定是否接受玩家的报价。该系统采用思维链(CoT)技术,使NPC在决策时能通过对话模型与心理状态描写,向玩家呈现其内部的权衡与妥协过程,极大地增强了策略互动的真实性与深度。腾讯魔方工作室的《F.A.C.U.L》项目则融合了语音输入与大语言模型,使AI队友能够识别游戏中的数千种物体并提供战略支持,进一步拓展了动态NPC的协作边界。这些案例共同表明,SLM通过赋予NPC自主决策与学习能力,正在重塑玩家与游戏世界的交互范式,从简单的指令执行迈向深度的策略共生。
四、智能交互范式重构:SLM驱动操作系统与应用层协同进化
4.1 模块化集成:构建灵活可扩展的智能交互内核
SLM的轻量特性使其成为构建操作系统智能交互内核的理想组件,支持模块化集成与灵活组合。SLM因其参数精简、推理高效和资源友好的特点,能够部署于手机、边缘设备等资源受限环境,为操作系统提供本地化、低延迟的智能处理能力。这种特性使其能够作为智能代理(Agentic AI)的核心引擎,支持在操作系统中模块化集成工具链,实现环境感知、自主规划与多模态交互。例如,微软Phi-3 Mini(38亿参数)可流畅运行于手机端,在对话AI和代码生成任务中表现优异,证明了SLM足以支撑操作系统内置AI功能的轻量化升级。通过这种模块化设计,操作系统能够根据应用层任务需求,动态组合不同的SLM模块(如文本处理、图像识别、音频分析),形成针对性的智能处理流水线,从而重构从被动响应到主动感知的交互范式。
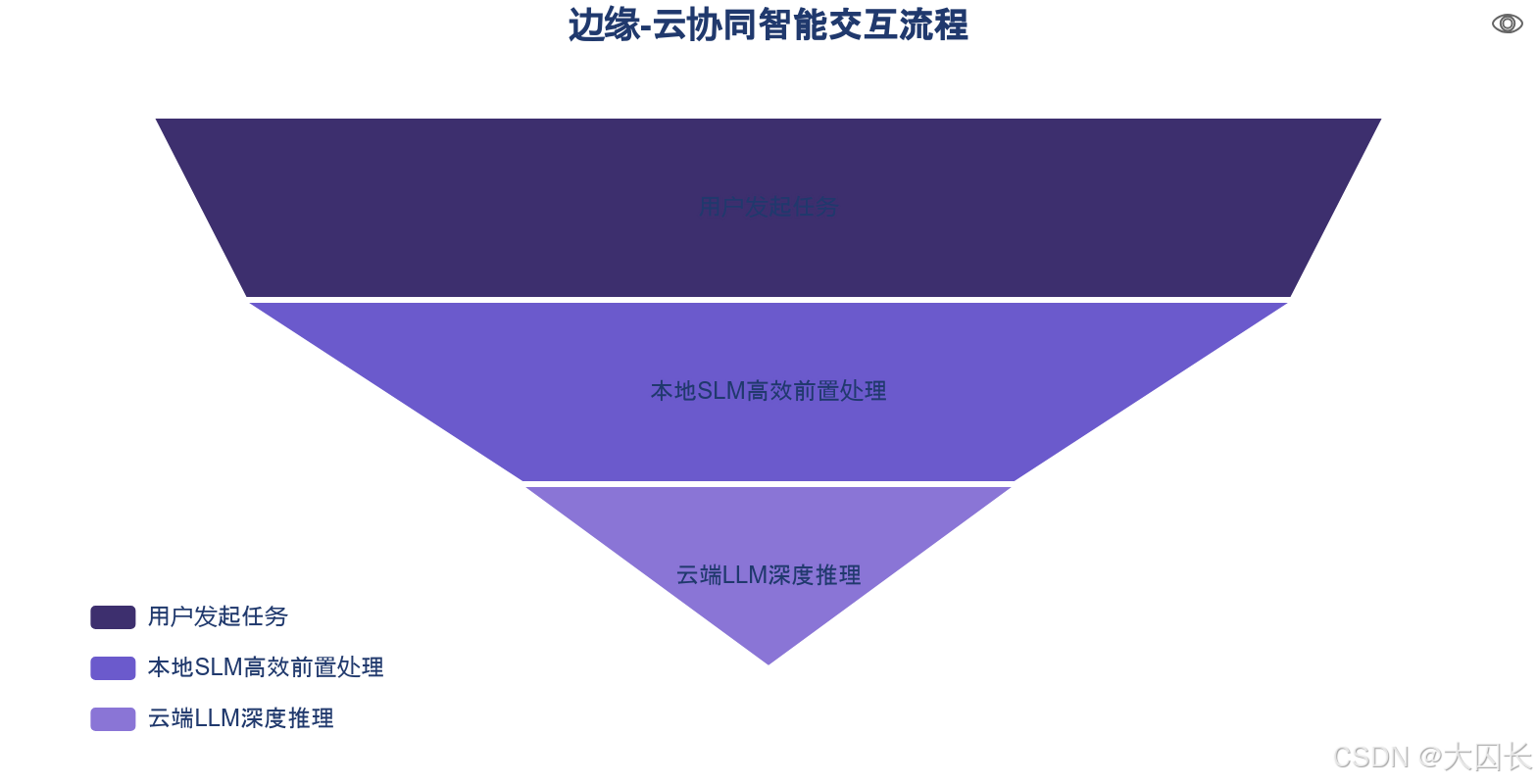
4.2 实时反馈循环:边缘-云协同优化响应效率
SLM与通用大模型(LLM)的协同工作,构建了高效的实时反馈循环,显著优化了系统响应效率与资源利用率。在边缘-云协同架构中,本地SLM负责处理实时、高频的轻量级任务,而复杂任务则被卸载至云端LLM进行深度推理。这种分工模式在多个场景中得到验证:在智能车载语音交互中,SLM本地响应基础请求,复杂查询转发至云端;在电商客服场景中,SLM快速识别用户意图,复杂问题路由至LLM,效率可提升40%。苹果“Apple Intelligence”与华为HarmonyOS的实践也体现了这一范式,前者在本地部署30亿参数模型处理基础任务,后者采用轻量版盘古大模型与云端协作实现混合推理。此外,通过级联预测或条件推理机制,SLM可生成草稿响应或根据置信度分数触发LLM介入,在保证响应质量的同时,大幅降低系统平均延迟与资源开销。这种协同机制使操作系统能够在资源受限的条件下,实现高性能的智能交互。
4.3 多智能体协同:从单点智能到系统级共生
SLM的普及推动了操作系统内从单点智能应用向多智能体协同系统的演进,实现了应用层功能的深度互联与自主协作。SLM可作为多个专用智能代理的基础模型,每个代理专注于特定领域(如日程管理、文档处理、系统优化)。这些代理在操作系统的统一调度下,能够相互通信、共享上下文并协作完成复杂任务。例如,一个SLM驱动的邮件分类代理可以与日历管理代理协同,自动从邮件中提取会议信息并创建日程提醒。在游戏场景中,这一范式可延伸为多个由SLM驱动的AI NPC(非玩家角色)与智能环境之间的动态协作,共同响应玩家行为并塑造游戏进程。这种多智能体架构的核心优势在于其分布式决策与资源高效性,多个轻量级SLM代理可以并行运行,在标准CPU上即可实现复杂的社会性交互与任务规划,而无需依赖单一的、资源消耗巨大的中心化模型。这标志着智能交互从工具化的单点辅助,迈向系统级、社会化的共生协同。
4.4 未来方向:隐私优先与多模态融合深化
展望未来,SLM驱动的智能交互范式将朝着隐私计算强化与多模态深度融合两个关键方向持续演进。在隐私保护方面,SLM的本地化部署能力使其能够直接在终端处理敏感数据,满足GDPR、HIPAA及国内数据安全法规的严格要求。在医疗等场景中,本地SLM可先对数据进行匿名化处理(如消除标识符、添加差分隐私噪声),仅将脱敏后的特征向量发送至云端,从而在保障数据安全的前提下实现智能服务。这推动了操作系统向“隐私优先”架构的演进。同时,多模态能力将成为下一代SLM的标配。支持文本、图像、音频处理的SLM(如Gemma3-4B)将作为多模态交互的统一入口,使操作系统能够更自然地理解用户的复合指令(如“把这张图片里提到的商品加入购物车”),并调度相应的应用服务。随着芯片性能提升与模型压缩技术(如知识蒸馏)的成熟,更强大的多模态SLM将得以在端侧部署,最终实现无处不在、自然流畅、且充分保障用户主权的高阶智能交互。
五、结论与实施路径
5.1 战略协同价值:SLM优势与应用趋势的融合效应
SLM的核心优势与其在操作系统中的应用趋势形成了紧密的战略协同,共同指向一个低成本、高响应、强隐私的智能交互未来。SLM的低成本与高精度特性,使其能够作为操作系统智能内核的模块化组件,在本地高效运行,这直接支撑了系统级意图理解所需的低延迟与实时响应能力。同时,SLM的边缘部署与数据本地化处理优势,完美契合了操作系统对用户隐私保护的核心要求,使得如小米澎湃OS中的“超级小爱同学”能够在不依赖云端的情况下,实现个性化的多模态交互与记忆。这种优势与趋势的结合,不仅降低了企业(尤其是中小企业)将AI深度集成至系统底层的技术门槛与资金成本,更通过**“端-边-云”协同架构**,实现了通用智能与垂直专精的平衡,为重构人机交互范式提供了坚实的技术与经济基础。
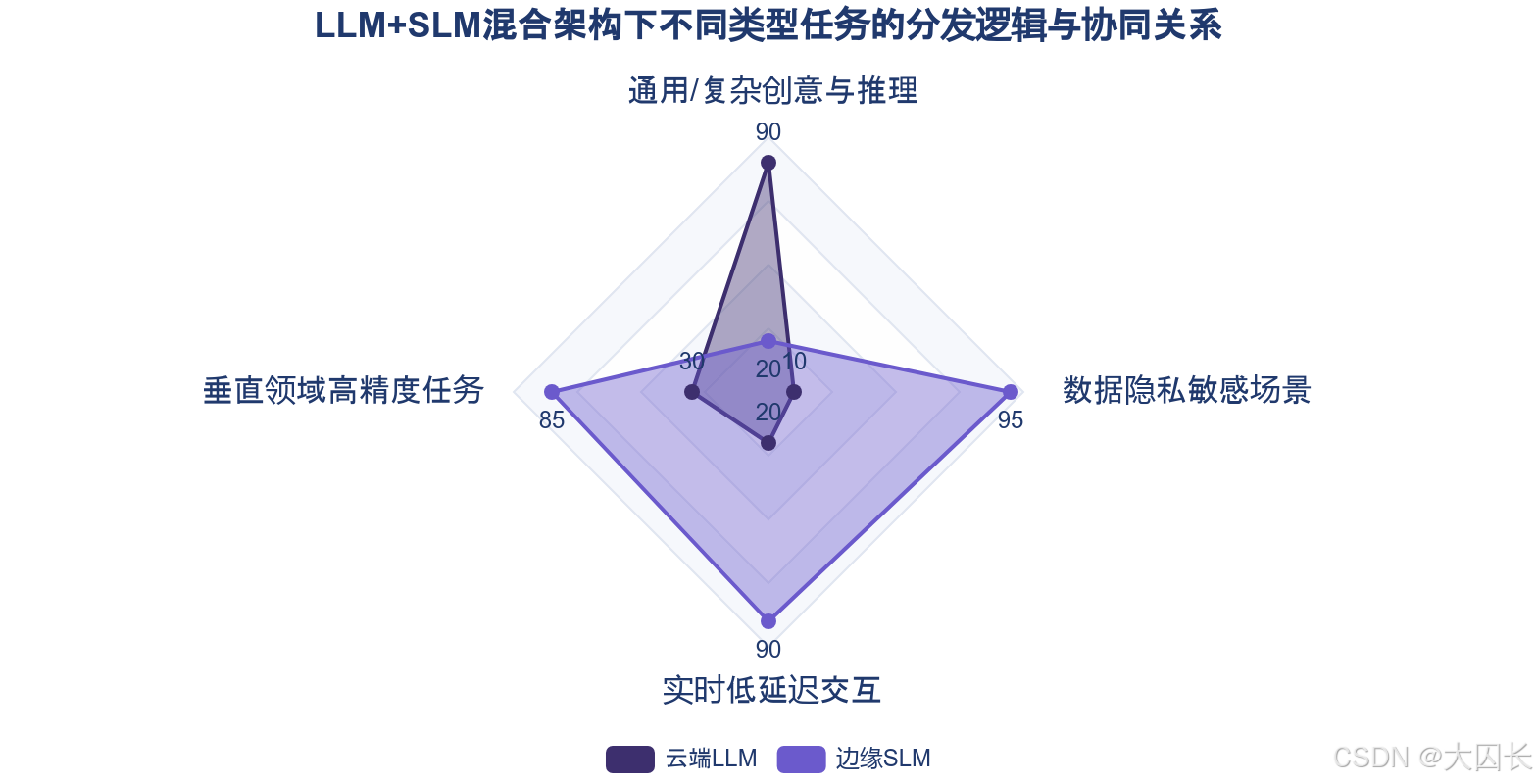
5.2 技术选型与架构部署标准
企业或操作系统开发者引入SLM时,需建立清晰的技术选型与架构部署标准,以最大化其价值。技术选型应首要考虑任务匹配度:对于垂直领域高精度任务(如医疗报告分析、金融票据识别)、实时低延迟交互(如语音助手、游戏NPC)以及数据隐私敏感场景,SLM是优先选择。参数规模通常在数千万到数十亿之间的模型,如微软Phi-3 Mini(38亿参数)或阿里Qwen2.5-1.5B(15亿参数),在性能与效率间取得了良好平衡,并已验证可在手机或CPU上流畅运行。在架构部署上,应摒弃“SLM替代LLM”的片面思维,转而构建**“LLM+SLM”混合架构**。通用、复杂的创意与推理任务由云端LLM处理,而垂直、实时、隐私敏感的任务则由部署在终端或边缘的SLM完成。这种模式既保障了数据隐私与响应速度,又充分利用了云端算力,金融行业已通过该模式实现客户数据本地处理、特征脱敏后云端分析的成熟实践。
5.3 实施路径与关键行动建议
基于当前技术生态与发展趋势,推动SLM在操作系统中深度集成的实施路径可分为三个阶段。短期(1年内),行动重点在于场景验证与轻量化集成。企业应优先在已有明确需求的垂直场景(如智能终端的本地语音助手、游戏内的FAQ机器人)中部署开源或成熟的商用SLM(如Meta的Llama系列、Microsoft的Phi系列),利用QLoRA等轻量化微调技术快速适配,并与RAG技术结合以低成本增强事实准确性,完成概念验证。中期(1-3年),目标是构建混合架构与开放生态。操作系统厂商需建立标准的SLM运行时框架与API,支持多模型动态加载与调度,如同Google在Android中集成Gemini Nano并向开发者开放。同时,企业需培养或借助如MoPaaS等AI平台提供的端到端LLMOps服务,构建支持灵活交换不同SLM的专业化运维能力,以应对技术快速迭代的挑战。长期(3年以上),愿景是实现多智能体协同与系统级共生。推动SLM作为分布式智能体的核心,在操作系统层面实现跨应用、跨设备的自主协作与资源调度。这需要芯片、终端硬件与模型算法的深度协同,依赖如高通、Intel等提供的专用NPU硬件支撑,最终实现从单点智能到全域共生的高阶交互范式演进。
| 阶段 | 核心目标 | 关键行动 | 技术/资源依赖 | 主要风险与应对 |
|---|---|---|---|---|
| 短期 (1年内) | 场景验证与价值证明 | 1. 在隐私敏感、实时响应场景(如端侧助手)试点部署SLM。 2. 采用“SLM+RAG”架构处理垂直领域知识问答。 3. 评估并引入轻量化微调工具(如QLoRA)。 |
开源SLM模型(如Phi-3, Qwen2.5)、消费级GPU、领域专属数据集。 | 模型在特定场景外表现不佳;需明确任务边界,避免泛化使用。 |
| 中期 (1-3年) | 架构标准化与生态构建 | 1. 在操作系统中集成SLM运行时框架,制定调用标准。 2. 构建“LLM+SLM”混合云边协同架构。 3. 建立专业的ML Ops团队或借助第三方平台能力。 |
端侧计算芯片(NPU)、AI平台(如MoPaaS)、云端LLM服务。 | 技术选型快速变化;需构建可插拔的模型管理系统以保持灵活性。 |
| 长期 (3年以上) | 系统智能与多体协同 | 1. 推动SLM作为基础智能体,实现跨应用任务调度。 2. 深化多模态SLM与系统传感器的融合。 3. 实现芯片-硬件-操作系统-应用的全栈优化。 |
高性能边缘算力、统一的多模态学习框架、产业协同标准。 | 分布式协同的复杂度与可靠性挑战;需从协议到安全的全栈设计。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)