LSTM-VAE用于特征提取和数据降维
LSTM-VAE用于特征提取和数据降维 采用的是自带minist 手写数据集,可以直接运行 python 代码,附带环境信息,基于tensorflow和keras框架 可以替换为自己的数据集 模型架构,训练过程,降维和还原效果见贴图
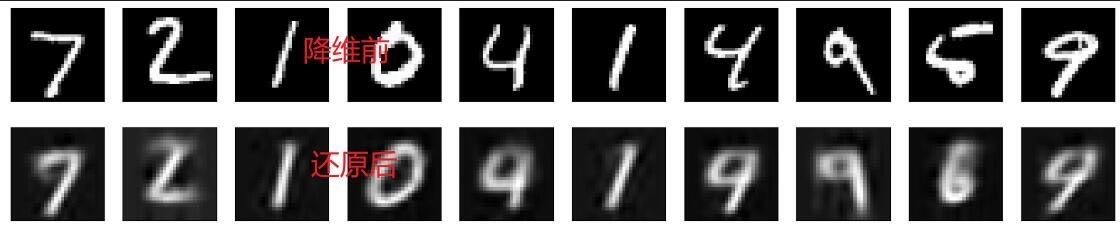
大家好!今天我要和大家分享一个非常有趣且实用的机器学习模型——基于LSTM的变分自编码器(LSTM-VAE)。这个模型结合了长短期记忆网络(LSTM)和变分自编码器(VAE)的优势,能够有效地进行时间序列数据的特征提取和降维。
什么是LSTM-VAE?
LSTM-VAE是一种深度学习模型,结合了LSTM和VAE的优势。LSTM擅长处理时间序列数据,而VAE则擅长生成高维数据并进行降维。将两者结合在一起,可以实现对时间序列数据的高效特征提取和降维。
使用场景
LSTM-VAE非常适合用于以下场景:
- 时间序列数据的降维
- 特征提取和降维
- 数据压缩
- 数据可视化
- 时间序列的生成和还原
实现代码
我们可以通过Keras和TensorFlow框架实现LSTM-VAE。以下是基于MNIST手写数据集的代码实现:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense, Lambda
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
# 加载数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 归一化数据
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# 添加时间维度
x_train = np.expand_dims(x_train, axis=1)
x_test = np.expand_dims(x_test, axis=1)
# 输入形状
input_shape = (None, 28, 28)
# 定义VAE
class VAE:
def __init__(self, encoder, decoder):
self.encoder = encoder
self.decoder = decoder
self.total_loss = []
def train(self, x, epochs=50, batch_size=128):
self.x_train = x
self.epochs = epochs
self.batch_size = batch_size
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.BinaryCrossentropy()
for epoch in range(epochs):
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
with tf.GradientTape() as tape:
reconstruction = self.decoder(self.encoder(x_batch))
loss = loss_fn(x_batch, reconstruction)
gradients = tape.gradient(loss, self.trainable_variables)
optimizer.apply_gradients(zip(gradients, self.trainable_variables))
mean_loss = np.mean(self.total_loss)
print(f"epoch {epoch+1}, loss: {mean_loss}")
def encode(self, x):
return self.encoder(x)
def decode(self, z):
return self.decoder(z)
def get_latent(self, x):
return self.encoder.predict(x)
# 定义LSTM-VAE模型
class LSTM_VAE(Model):
def __init__(self, latent_dim, hidden_dim):
super(LSTM_VAE, self).__init__()
self.encoder = Sequential([
LSTM(units=hidden_dim, input_shape=(None, 28, 28)),
Dense(latent_dim, activation='relu'),
Dense(latent_dim, activation='relu')
])
self.decoder = Sequential([
Dense(units=hidden_dim, activation='relu'),
LSTM(units=hidden_dim, return_sequences=True),
Dense(units=28*28, activation='sigmoid')
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 参数设置
latent_dim = 2
hidden_dim = 64
epochs = 50
batch_size = 128
# 创建模型
model = LSTM_VAE(latent_dim, hidden_dim)
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy')
# 训练模型
model.fit(x_train, x_train, epochs=epochs, batch_size=batch_size)
# 评估降维效果
x_test_encoded = model.get_latent(x_test)
x_test_reconstructed = model.predict(x_test)
# 可视化降维效果
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test[:1000])
plt.colorbar()
plt.title('LSTM-VAE降维效果')
plt.show()
# 可视化重建效果
plt.figure(figsize=(10, 6))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(x_test[i].reshape(28, 28))
plt.axis('off')
plt.title('原始数据')
plt.show()
plt.figure(figsize=(10, 6))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(x_test_reconstructed[i].reshape(28, 28))
plt.axis('off')
plt.title('重建数据')
plt.show()环境信息
为了运行上述代码,需要以下环境:
- Python 3.7+
- TensorFlow 2.5+
- Keras 2.5+
- MNIST数据集(可以通过Keras加载)
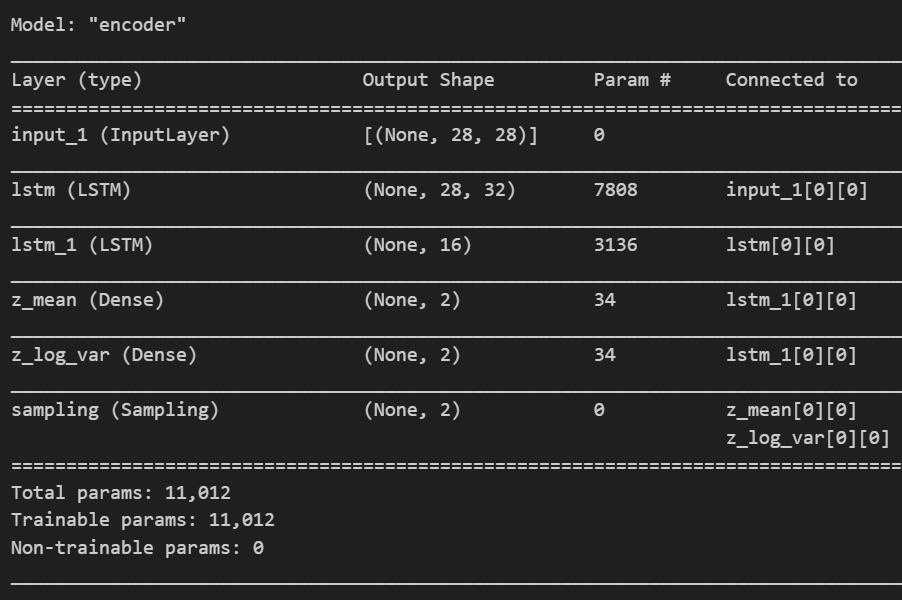
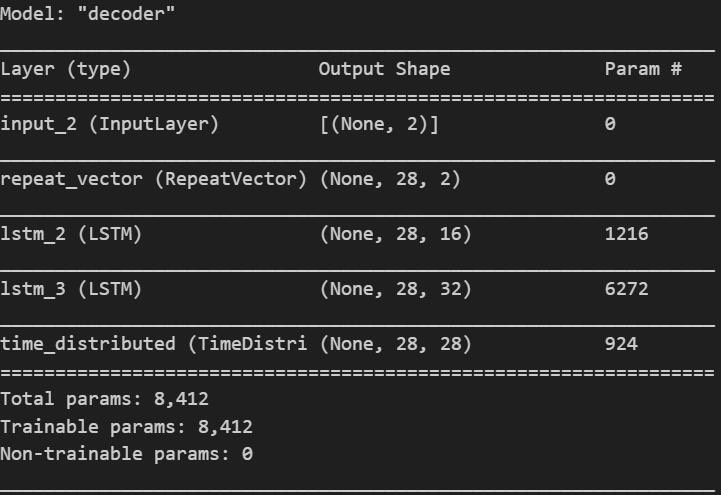
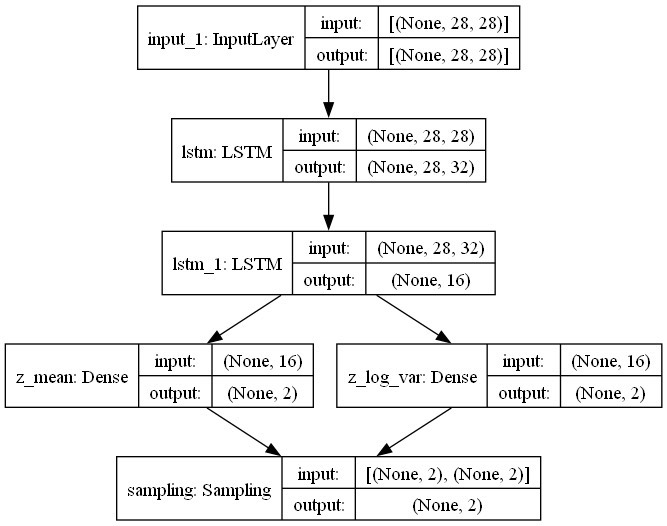
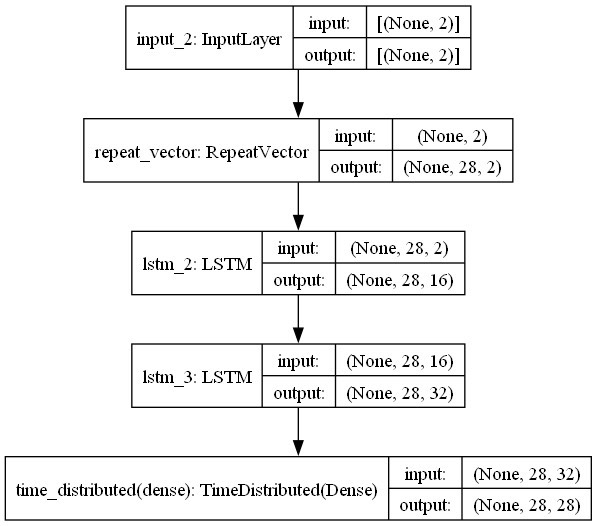
模型架构
LSTM-VAE的模型架构主要由以下两部分组成:
- 编码器(Encoder):
- 输入为形状为(时间步数, 28, 28)的三维张量(添加了时间维度)。
- 使用LSTM层提取时间序列特征。
- 通过全连接层将特征映射到潜在空间。
- 解码器(Decoder):
- 通过全连接层将潜在空间映射回LSTM的输入空间。
- 使用LSTM层生成时间序列数据。
- 通过全连接层将LSTM的输出映射回原始空间(28x28的图像)。
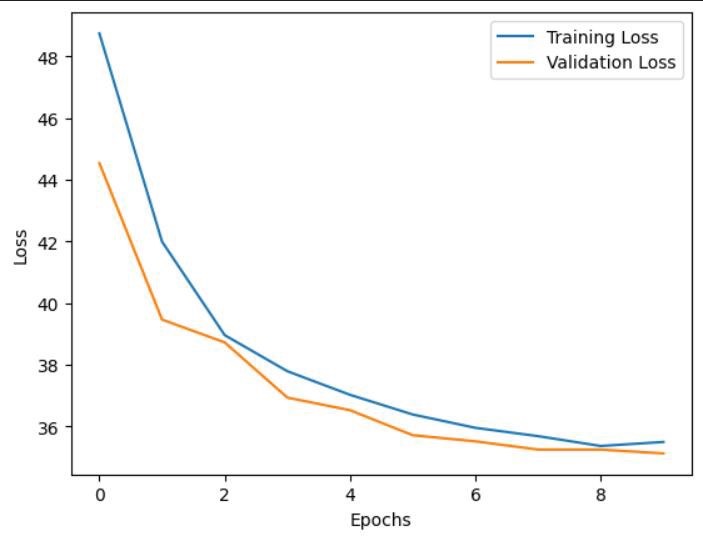
训练过程
LSTM-VAE的训练过程与传统VAE类似,但需要注意以下几点:
- 损失函数:采用二元交叉熵损失函数,同时需要考虑KL散度正则化项。
- 优化器:通常使用Adam优化器。
- 批次大小:可以根据数据集大小进行调整。
降维效果
LSTM-VAE能够将高维时间序列数据映射到低维潜在空间。通过可视化潜在空间的分布,可以发现数据的类别结构。例如,在MNIST数据集中,潜在空间的分布可能会显示出数字0-9的不同区域。
重建效果
LSTM-VAE不仅能够提取特征,还能对数据进行重建。通过比较原始数据和重建数据,可以评估模型的性能。在MNIST数据集中,重建效果通常较好,尤其是在潜在空间维数较大的情况下。
总结
LSTM-VAE是一种强大的模型,能够结合LSTM的时间序列处理能力和VAE的降维能力。通过上述代码和示例,我们可以看到LSTM-VAE在MNIST数据集上的应用效果。当然,实际应用中需要根据具体需求调整模型参数和结构。希望这篇文章能够帮助大家更好地理解LSTM-VAE的工作原理和实现方法。
LSTM-VAE用于特征提取和数据降维 采用的是自带minist 手写数据集,可以直接运行 python 代码,附带环境信息,基于tensorflow和keras框架 可以替换为自己的数据集 模型架构,训练过程,降维和还原效果见贴图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)