Tranformer 代码实现3:手搓 FNN 层
·
为读者更好的阅读体验,请跳转至:https://z6d2i3en.html2web.com
一、FNN 在 Transformer 架构中的位置
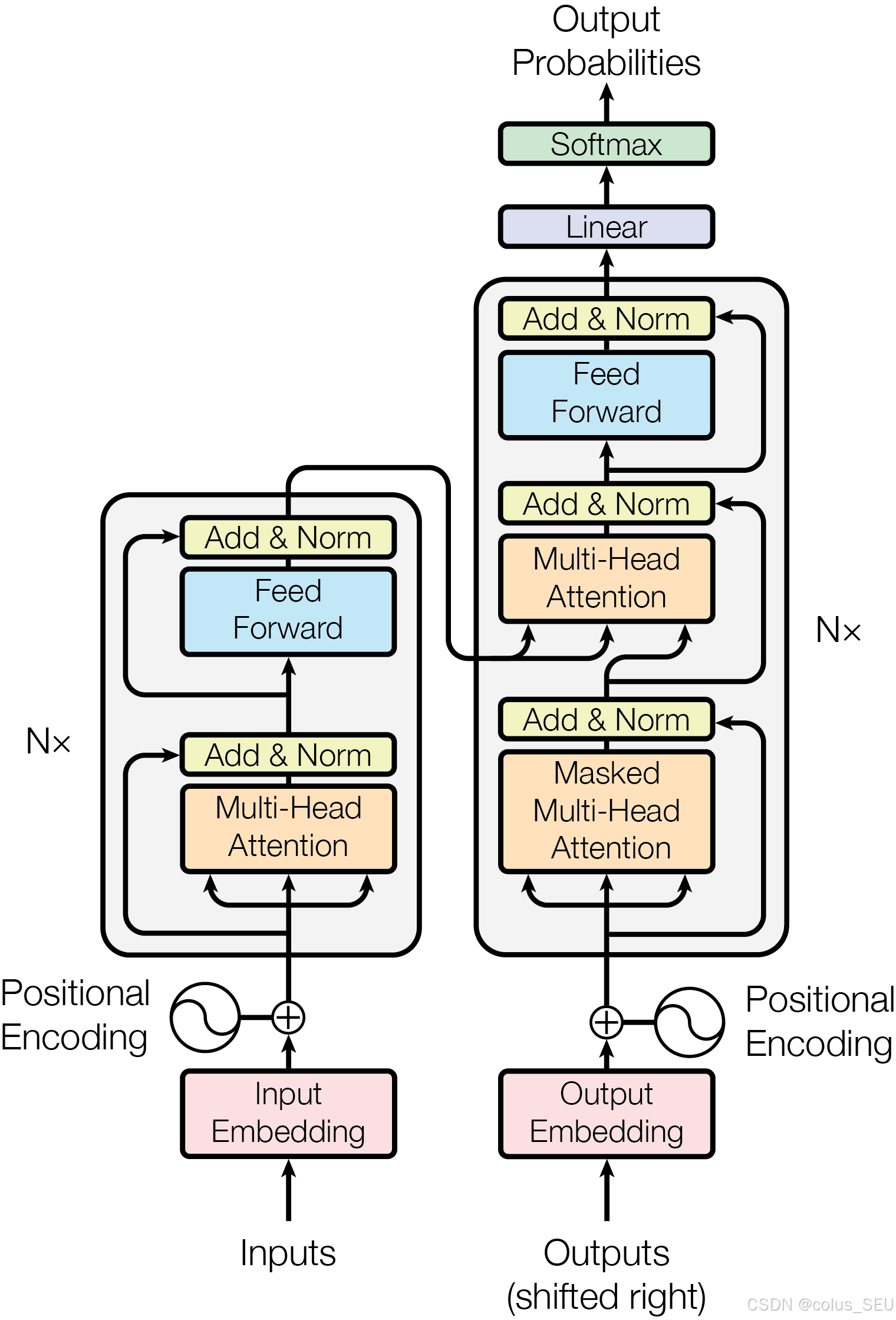
从架构图中可以看出,FNN 层处在每一个注意力层之后,其核心功能包括:
-
引入非线性变换能力
-
独立加工每个位置的特征:FFN是“位置独立”的,这意味着它会对序列中的每一个词向量(token)进行独立且相同的处理。
-
增加模型容量,充当“知识库”:FFN的结构通常是先将维度扩展(例如扩展4倍),再通过激活函数,最后收缩回原始维度。这种“先升维后降维”的设计,使得FFN实际上包含了Transformer中大部分的可学习参数。
二、代码实现分析
首先还是导入必要库:
import torch import torch.nn as nn import torch.nn.functional as F
定义 FNN 类,还是继承自 nn.Module
class PositionwiseFeedForward(nn.Module):
类的构造函数实现 “先升维后降维” 的结构:
def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedForward, self).__init__() # 第一层线性变换: d_model → d_ff (升维) # 将输入从 d_model 维映射到更高维的 d_ff 维 # 这增加了网络的表示能力 self.w_1 = nn.Linear(d_model, d_ff) # 第二层线性变换: d_ff → d_model (降维) # 将中间表示映射回原始维度 d_model self.w_2 = nn.Linear(d_ff, d_model) # Dropout 层,防止过拟合 # 在 ReLU 激活后、第二层线性变换前应用 self.dropout = nn.Dropout(dropout)
前向传播实现具体公式:
$$
\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
$$
def forward(self, x): return self.w_2(self.dropout(F.relu(self.w_1(x))))
完整代码
import torch import torch.nn as nn import torch.nn.functional as F class PositionwiseFeedForward(nn.Module): def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedForward, self).__init__() self.w_1 = nn.Linear(d_model, d_ff) self.w_2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) def forward(self, x): return self.w_2(self.dropout(F.relu(self.w_1(x))))
带注释的完整代码
import torch import torch.nn as nn import torch.nn.functional as F class PositionwiseFeedForward(nn.Module): """ 位置前馈神经网络 功能:对每个位置独立应用相同的两层全连接网络 "Position-wise" 意味着对序列中的每个位置使用相同的参数 网络结构: 输入 (d_model) → Linear → ReLU → Dropout → Linear → 输出 (d_model) ↓ 中间层 (d_ff) 公式: FFN(x) = max(0, xW₁ + b₁)W₂ + b₂ 即: FFN(x) = ReLU(xW₁ + b₁)W₂ + b₂ 参数: d_model: 模型的输入/输出维度,论文中为 512 d_ff: 中间隐藏层的维度,论文中为 2048 dropout: Dropout 比率 为什么 d_ff = 2048 (是 d_model 的 4 倍)? 1. 增加模型的容量和表达能力 2. 先升维再降维,可以学习更复杂的特征变换 3. 论文实验表明这个比例效果最好 示例 (batch_size=2, seq_len=10, d_model=512, d_ff=2048): 输入: (2, 10, 512) 中间: (2, 10, 2048) 输出: (2, 10, 512) 注意: 这个网络对序列中的每个位置独立处理,不同位置之间没有交互 位置之间的信息交互完全由注意力机制完成 """ def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedForward, self).__init__() # 第一层线性变换: d_model → d_ff (升维) # 将输入从 d_model 维映射到更高维的 d_ff 维 # 这增加了网络的表示能力 self.w_1 = nn.Linear(d_model, d_ff) # 第二层线性变换: d_ff → d_model (降维) # 将中间表示映射回原始维度 d_model self.w_2 = nn.Linear(d_ff, d_model) # Dropout 层,防止过拟合 # 在 ReLU 激活后、第二层线性变换前应用 self.dropout = nn.Dropout(dropout) def forward(self, x): """ 前向传播 参数: x: 输入张量,形状 (batch_size, seq_len, d_model) 返回: 输出张量,形状 (batch_size, seq_len, d_model) 计算流程: 1. w_1(x): 线性变换,形状 (batch, seq_len, d_ff) 2. ReLU: 激活函数,引入非线性 3. dropout: 随机置零,正则化 4. w_2: 线性变换,形状 (batch, seq_len, d_model) 为什么使用 ReLU? 1. 计算简单高效 2. 缓解梯度消失问题 3. 产生稀疏激活,有助于模型学习更鲁棒的特征 代码等价于: hidden = self.w_1(x) # (batch, seq, d_ff) hidden = F.relu(hidden) # ReLU 激活 hidden = self.dropout(hidden) # Dropout output = self.w_2(hidden) # (batch, seq, d_model) return output """ return self.w_2(self.dropout(F.relu(self.w_1(x))))

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)