【MIT 6.824】LEC 9 CRAQ
论文: Object Storage on CRAQ
现在读论文的策略换了,前面部分还是尽量看。后面很多讨论和细节部分,由于这个领域不是那么熟悉,硬看也记不住,用有道翻译快点。
Chain Replication with Apportioned Queries
Our basic approach, an improvement on Chain Replication, maintains strong consistency while greatly improving read throughput. By distributing load across all object replicas, CRAQ scales linearly with chain size without increasing consistency coordination. 我们的基本方法是对Chain Replication的改进,在保持强一致性的同时大大提高了读吞吐量。通过在所有对象副本上分配负载,CRAQ可以随链大小线性扩展,而不会增加一致性协调。
1 Introduction
Recently, van Renesse and Schneider presented a chain replication method for object storage [47] over fail-stop servers, designed to provide strong consistency yet improve throughput. The basic approach organizes all nodes storing an object in a chain, where the chain tail handles all read requests, and the chain head handles all write requests. Writes propagate down the chain before the client is acknowledged, thus providing a simple ordering of all object operations—and hence strong consistency—at the tail. The lack of any complex or multi-round protocols yields simplicity, good throughput, and easy recovery. 基本方法将存储对象的所有节点组织在一个链中,其中链尾处理所有读请求,链头处理所有写请求。在客户端得到确认之前,写操作沿着链传播,从而在尾部提供了所有对象操作的简单排序——因此具有很强的一致性。没有任何复杂的或多轮的协议,从而产生了简单性、良好的吞吐量和易于恢复
Unfortunately, the basic chain replication approach has some limitations. All reads for an object must go to the same node, leading to potential hotspots. Multiple chains can be constructed across a cluster of nodes for better load balancing—via consistent hashing [29] or a more centralized directory approach [22]—but these algorithms might still find load imbalances if particular objects are disproportionally popular, a real issue in practice [17]. Perhaps an even more serious issue arises when attempting to build chains across multiple datacenters, as all reads to a chain may then be handled by a potentially-distant node (the chain’s tail) 不幸的是,基本链复制方法有一些局限性。对一个对象的所有读取都必须到同一节点,从而导致潜在的热点。通过一致性哈希[29]或更集中的目录方法[22],可以在节点集群上构建多个链以实现更好的负载平衡,但如果特定对象不成比例地流行,这些算法仍然可能发现负载不平衡,这在实践中是一个真正的问题[17]。当尝试跨多个数据中心构建链时,可能会出现更严重的问题,因为对链的所有读取都可能被处理
This paper presents the design, implementation, and evaluation of CRAQ (Chain Replication with Apportioned Queries), an object storage system that, while maintaining the strong consistency properties of chain replication [47], provides lower latency and higher throughput for read operations by supporting apportioned queries: that is, dividing read operations over all nodes in a chain, as opposed to requiring that they all be handled by a single primary node. 本文介绍了CRAQ (Chain Replication with aptioned Queries)的设计、实现和评估。CRAQ是一种对象存储系统,它在保持链复制的强一致性特性[47]的同时,通过支持分配查询,为读操作提供了更低的延迟和更高的吞吐量:即,将读操作划分到链中的所有节点上,而不是要求它们全部由单个主节点处理。
- CRAQ enables any chain node to handle read operations while preserving strong consistency, thus supporting load balancing across all nodes storing an object. Furthermore, when workloads are read mostly—an assumption used in other systems such as the Google File System [22] and Memcached [18]—the performance of CRAQ rivals systems offering only eventual consistency. CRAQ使任何链节点都可以处理读操作,同时保持强一致性,从而支持存储对象的所有节点之间的负载均衡。此外,当大部分工作负载被读取时(这是其他系统(如Google File System[22]和Memcached[18])所采用的假设),CRAQ的性能与其他系统相比只提供最终一致性。
- In addition to strong consistency, CRAQ’s design naturally supports eventual-consistency among read operations for lower-latency reads during write contention and degradation to read-only behavior during transient partitions. CRAQ allows applications to specify the maximum staleness acceptable for read operations. 除了强一致性之外,CRAQ的设计自然支持在写争用期间进行低延迟读的读操作之间的最终一致性,以及在瞬态分区期间降级为只读行为。CRAQ允许应用程序指定读操作可接受的最大过期时间。
- Leveraging these load-balancing properties, we describe a wide-area system design for building CRAQ chains across geographically-diverse clusters that preserves strong locality properties. Specifically, reads can be handled either completely by a local cluster, or at worst, require concise metadata information to be transmitted across the wide-area during times of high write contention. We also present our use of ZooKeeper [48], a PAXOS-like group membership system, to manage these deployments. 利用这些负载平衡特性,我们描述了一个广域系统设计,用于跨地理上不同的集群构建CRAQ链,以保持强局域性。具体来说,读取可以完全由本地集群处理,或者在最坏的情况下,需要在写争用频繁的时候跨广域传输简明的元数据信息。我们还介绍了ZooKeeper[48]的使用,这是一个类似paxos的组成员系统,用于管理这些部署。
2 Basic System Model
2.1 Interface and Consistency Model
We will be discussing two main types of consistency, taken with respect to individual objects.
- Strong Consistency in our system provides the guarantee that all read and write operations to an object are executed in some sequential order, and that a read to an object always sees the latest written value.
- Eventual Consistency in our system implies that writes to an object are still applied in a sequential order on all nodes, but eventually-consistent reads to different nodes can return stale data for some period of inconsistency (i.e., before writes are applied on all nodes). Once all replicas receive the write, however, read operations will never return an older version than this latest committed write. In fact, a client will also see monotonic read consistency1 if it maintains a session with a particular node (although not across sessions with different nodes).
2.2 Chain Replication
Once the write reaches the tail node, it has been applied to all replicas in the chain, and it is considered committed. The tail node handles all read operations, so only values which are committed can be returned by a read.
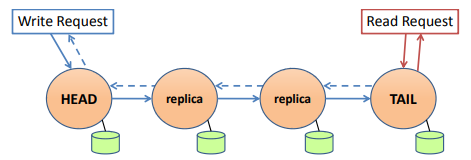
The CR paper describes the tail sending a message directly back to the client; because we use TCP, our implementation actually has the head respond after it receives an acknowledgment from the tail, given its pre-existing network connection with the client. This acknowledgment propagation is shown with the dashed line in the figure. CR论文描述了尾部直接向客户端发送消息;因为我们使用TCP,我们的实现实际上让头部在收到来自尾部的确认后做出响应,前提是它与客户端已经存在网络连接。此确认传播用图中的虚线表示。
The simple topology of CR makes write operations cheaper than in other protocols offering strong consistency. Multiple concurrent writes can be pipelined down the chain, with transmission costs equally spread over all nodes CR的简单拓扑使得写操作比其他协议更便宜,并且提供了强一致性。多个并发写操作可以通过管道在链上进行,传输成本在所有节点上平均分摊
Chain replication achieves strong consistency: As all reads go to the tail, and all writes are committed only when they reach the tail, the chain tail can trivially apply a total ordering over all operations. This does come at a cost, however, as it reduces read throughput to that of a single node, instead of being able to scale out with chain size 链式复制实现了强一致性:由于所有的读操作都到尾部,所有的写操作只有在到达尾部时才提交,因此链尾可以轻松地对所有操作应用总排序。然而,这确实是有代价的,因为它将读取吞吐量降低到单个节点的吞吐量,而不是能够随着链的大小进行扩展。But it is necessary, as querying intermediate nodes could otherwise violate the strong consistency guarantee; specifically, concurrent reads to different nodes could see different writes as they are in the process of propagating down the chain. 但这是必要的,否则查询中间节点会违反强一致性保证;具体来说,对不同节点的并发读可能会看到不同的写,因为它们正在沿着链向下传播。
2.3 Chain Replication with Apportioned Queries
Motivated by the popularity of read-mostly workload environments, CRAQ seeks to increase read throughput by allowing any node in the chain to handle read operations while still providing strong consistency guarantees. The main CRAQ extensions are as follows. 受以读为主的工作负载环境的流行推动,CRAQ试图通过允许链中的任何节点处理读操作,同时仍然提供强大的一致性保证来提高读吞吐量。
- A node in CRAQ can store multiple versions of an object, each including a monotonically-increasing version number and an additional attribute whether the version is
cleanordirty. All versions are initially marked as clean. CRAQ中的节点可以存储对象的多个版本,每个版本都包含一个单调递增的版本号和一个附加属性,无论该版本是干净的还是脏的。所有版本最初都被标记为干净。 - When a node receives a new version of an object (via a write being propagated down the chain), the node appends this latest version to its list for the object. 当节点接收到对象的新版本时(通过沿链向下传播的写操作),该节点将这个最新版本附加到该对象的列表中。
- If the node is not the tail, it marks the version as dirty, and propagates the write to its successor 如果该节点不是尾节点,则将该版本标记为脏节点,并将写入操作传播给后继节点
- Otherwise, if the node is the tail, it marks the version as
clean, at which time we call the object version (write) ascommitted. The tail node can then notify all other nodes of the commit by sending an acknowledgement backwards through the chain. 否则,如果节点是尾部,它将版本标记为干净,此时我们将对象版本(写入)称为已提交。然后,尾部节点可以通过链向后发送确认,通知所有其他节点提交。
- When an
acknowledgmentmessage for an object version arrives at a node, the node marks the object version as clean. The node can then delete all prior versions of the object. 当对象版本的确认消息到达节点时,该节点将该对象版本标记为干净。然后,节点可以删除该对象的所有先前版本。 - When a node receives a read request for an object:
- If the latest known version of the requested object is
clean, the node returns this value. 如果所请求对象的最新已知版本是干净的,则节点返回此值。 - Otherwise, if the latest version number of the object requested is
dirty, the node contacts the tail and asks for the tail’s last committed version number (aversion query). 否则,如果所请求对象的最新版本号是脏的,则节点联系尾部并请求尾部最后提交的版本号(版本查询)。 The node then returns that version of the object; by construction, the node is guaranteed to be storing this version of the object. 然后节点返回对象的那个版本;通过构造,节点保证存储这个版本的对象 We note that although the tail could commit a new version between when it replied to the version request and when the intermediate node sends a reply to the client, this does not violate our definition of strong consistency, as read operations are serialized with respect to the tail. 我们注意到,虽然尾巴可以在它回复版本请求和中间节点向客户端发送回复之间提交新版本,但这并不违反我们对强一致性的定义,因为读操作是相对于尾巴序列化的。
- If the latest known version of the requested object is
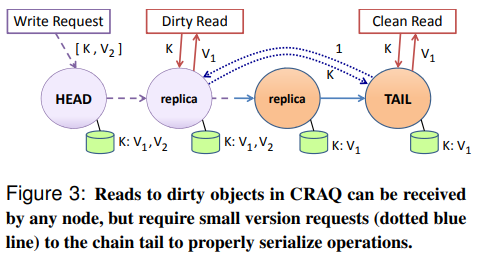
CRAQ’s throughput improvements over CR arise in two different scenarios:
- **Read-Mostly Workloads **have most of the read requests handled solely by the C−1 non-tail nodes (as clean reads), and thus throughput in these scenarios scales linearly with chain size C. read - most工作负载的大部分读请求都由C−1非尾节点单独处理(作为干净的读),因此这些场景中的吞吐量与链大小C呈线性增长。
- Write-Heavy Workloads have most read requests to non-tail nodes as dirty, thus require version queries to the tail. We suggest, however, that these version queries are lighter-weight than full reads, allowing the tail to process them at a much higher rate before it becomes saturated. This leads to a total read throughput that is still higher than CR.
2.4 Consistency Models on CRAQ
- Strong Consistency (the default) is described in the model above (§2.1). All object reads are guaranteed to be consistent with the last committed write
- Eventual Consistency allows read operations to a chain node to return the newest object version known to it. Thus, a subsequent read operation to a different node may return an object version older than the one previously returned
- Eventual Consistency with Maximum-Bounded Inconsistency allows read operations to return newly written objects before they commit, but only to a certain point. The limit imposed can be based on time (relative to a node’s local clock) or on absolute version numbers. In this model, a value returned from a read operation is guaranteed to have a maximum inconsistency period (defined over time or versioning).
2.5 Failure Recovery in CRAQ
As the basic structure of CRAQ is similar to CR, CRAQ uses the same techniques to recover from failure.
3 Scaling CRAQ
3.2 CRAQ within a Datacenter
The choice of how to distribute multiple chains across a datacenter was investigated in the original Chain Replication work. In CRAQ’s current implementation, we place chains within a datacenter using consistent hashing [29, 45], mapping potentially many chain identifiers to a single head node. This is similar to a growing number of datacenter-based object stores [15, 16] 在最初的Chain Replication工作中,研究了如何在数据中心分布多个链的选择。在CRAQ当前的实现中,我们使用一致哈希[29,45]在数据中心内放置链,将潜在的许多链标识符映射到单个头节点。这类似于越来越多的基于数据中心的对象存储[15,16]。
3.3 CRAQ Across Multiple Datacenters
3.4 ZooKeeper Coordination Service
We subsequently opted to leverage ZooKeeper [48], however, to provide CRAQ with a robust, distributed, high-performance method for tracking group membership and an easy way to store chain metadata. Through the use of Zookeper, CRAQ nodes are guaranteed to receive a notification when nodes are added to or removed from a group. 然而,我们随后选择利用ZooKeeper[48],为CRAQ提供了一种强大的、分布式的、高性能的方法来跟踪组成员关系,并提供了一种简单的方法来存储链元数据。通过使用zookeeper, CRAQ节点保证在节点被添加到组或从组中删除时收到通知。
4 Extensions
略
LEC 9 课程
这节课我想完成两件事情,第一个是结束关于Zookeeper的讨论,第二就是讨论CRAQ。
Zookeeper里面我最感兴趣的事情是它的API设计。Zookeeper的API设计使得它可以成为一个通用的服务,从而分担一个分布式系统所需要的大量工作。那么为什么Zookeeper的API是一个好的设计?具体来看,因为它实现了一个值得去了解的概念:mini-transaction。
我们回忆一下Zookeeper的特点:
- Zookeeper基于(类似于)Raft框架,所以我们可以认为它是,当然它的确是容错的,它在发生网络分区的时候,也能有正确的行为。
- 当我们在分析各种Zookeeper的应用时,我们也需要记住Zookeeper有一些性能增强,使得读请求可以在任何副本被处理,因此,可能会返回旧数据。
- 另一方面,Zookeeper可以确保一次只处理一个写请求,并且所有的副本都能看到一致的写请求顺序。这样,所有副本的状态才能保证是一致的(写请求会改变状态,一致的写请求顺序可以保证状态一致)。
- 由一个客户端发出的所有读写请求会按照客户端发出的顺序执行。
- 一个特定客户端的连续请求,后来的请求总是能看到相比较于前一个请求相同或者更晚的状态(详见8.5 FIFO客户端序列)。
在我深入探讨Zookeeper的API长什么样和为什么它是有用的之前,我们可以考虑一下,Zookeeper的目标是解决什么问题,或者期望用来解决什么问题?
- 对于我来说,使用Zookeeper的一个主要原因是,它可以是一个VMware FT所需要的Test-and-Set服务(详见4.7)的实现。Test-and-Set服务在发生主备切换时是必须存在的,但是在VMware FT论文中对它的描述却又像个谜一样,论文里没有介绍:这个服务究竟是什么,它是容错的吗,它能容忍网络分区吗?Zookeeper实际的为我们提供工具来写一个容错的,完全满足VMware FT要求的Test-and-Set服务,并且可以在网络分区时,仍然有正确的行为。这是Zookeeper的核心功能之一。
- 使用Zookeeper还可以做很多其他有用的事情。其中一件是,人们可以用它来发布其他服务器使用的配置信息。例如,向某些Worker节点发布当前Master的IP地址。
- 另一个Zookeeper的经典应用是选举Master。当一个旧的Master节点故障时,哪怕说出现了网络分区,我们需要让所有的节点都认可同一个新的Master节点。
- 如果新选举的Master需要将其状态保持到最新,比如说GFS的Master需要存储对于一个特定的Chunk的Primary节点在哪,现在GFS的Master节点可以将其存储在Zookeeper中,并且知道Zookeeper不会丢失这个信息。当旧的Master崩溃了,一个新的Master被选出来替代旧的Master,这个新的Master可以直接从Zookeeper中读出旧Master的状态。
- 其他还有,对于一个类似于MapReduce的系统,Worker节点可以通过在Zookeeper中创建小文件来注册自己。
- 同样还是类似于MapReduce这样的系统,你可以设想Master节点通过向Zookeeper写入具体的工作,之后Worker节点从Zookeeper中一个一个的取出工作,执行,完成之后再删除工作。
以上就是Zookeeper可以用来完成的工作。

学生提问:Zookeeper应该如何应用在这些场景中?
Robert教授:通常来说,如果你有一个大的数据中心,并且在数据中心内运行各种东西,比如说Web服务器,存储系统,MapReduce等等。你或许会想要再运行一个包含了5个或者7个副本的Zookeeper集群,因为它可以用在很多场景下。之后,你可以部署各种各样的服务,并且在设计中,让这些服务存储一些关键的状态到你的全局的Zookeeper集群中。
Zookeeper的API某种程度上来说像是一个文件系统。它有一个层级化的目录结构,有一个根目录(root),之后每个应用程序有自己的子目录。比如说应用程序1将自己的文件保存在APP1目录下,应用程序2将自己的文件保存在APP2目录下,这些目录又可以包含文件和其他的目录。
这么设计的一个原因刚刚也说过,Zookeeper被设计成要被许多可能完全不相关的服务共享使用。所以我们需要一个命名系统来区分不同服务的信息,这样这些信息才不会弄混。对于每个使用Zookeeper的服务,围绕着文件,有很多很方便的方法来使用Zookeeper。我们在接下来几个小节会看几个例子。
所以,Zookeeper的API看起来像是一个文件系统,但是又不是一个实际的文件系统,比如说你不能mount一个文件,你不能运行ls和cat这样的命令等等。这里只是在内部,以这种路径名的形式命名各种对象。假设应用程序2下面有X,Y,Z这些文件。当你通过RPC向Zookeeper请求数据时,你可以直接指定/APP2/X。这就是一种层级化的命名方式。
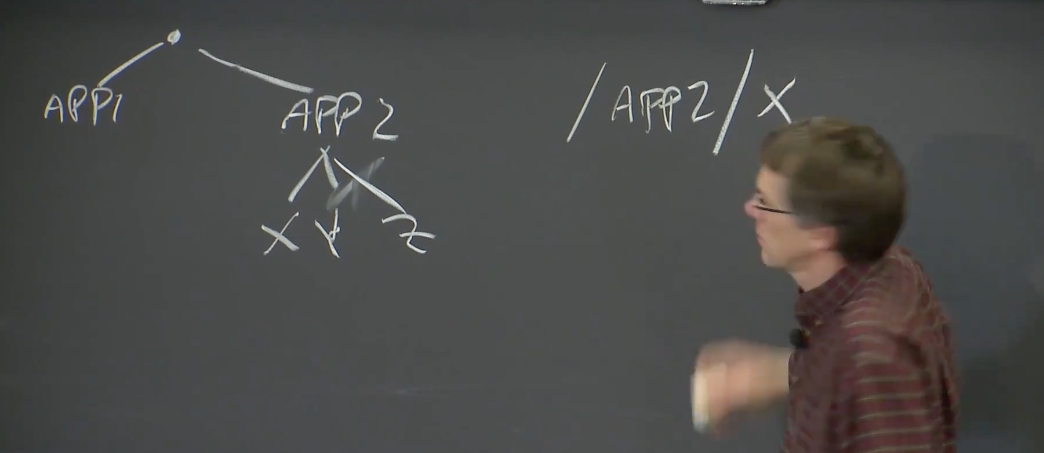
这里的文件和目录都被称为znodes。Zookeeper中包含了3种类型的znode,了解他们对于解决问题会有帮助。
- 第一种Regular znodes。这种znode一旦创建,就永久存在,除非你删除了它。
- 第二种是Ephemeral znodes。如果Zookeeper认为创建它的客户端挂了,它会删除这种类型的znodes。这种类型的znodes与客户端会话绑定在一起,所以客户端需要时不时的发送心跳给Zookeeper,告诉Zookeeper自己还活着,这样Zookeeper才不会删除客户端对应的ephemeral znodes。
- 最后一种类型是Sequential znodes。它的意思是,当你想要以特定的名字创建一个文件,Zookeeper实际上创建的文件名是你指定的文件名再加上一个数字。当有多个客户端同时创建Sequential文件时,Zookeeper会确保这里的数字不重合,同时也会确保这里的数字总是递增的。
这些在后面的例子中都会有介绍。
Zookeeper以RPC的方式暴露以下API。
CREATE(PATH,DATA,FLAG)。入参分别是文件的全路径名PATH,数据DATA,和表明znode类型的FLAG。这里有意思的是,CREATE的语义是排他的。也就是说,如果我向Zookeeper请求创建一个文件,如果我得到了yes的返回,那么说明这个文件之前不存在,我是第一个创建这个文件的客户端;如果我得到了no或者一个错误的返回,那么说明这个文件之前已经存在了。所以,客户端知道文件的创建是排他的。在后面有关锁的例子中,我们会看到,如果有多个客户端同时创建同一个文件,实际成功创建文件(获得了锁)的那个客户端是可以通过CREATE的返回知道的。DELETE(PATH,VERSION)。入参分别是文件的全路径名PATH,和版本号VERSION。有一件事情我之前没有提到,每一个znode都有一个表示当前版本号的version,当znode有更新时,version也会随之增加。对于delete和一些其他的update操作,你可以增加一个version参数,表明当且仅当znode的当前版本号与传入的version相同,才执行操作。当存在多个客户端同时要做相同的操作时,这里的参数version会非常有帮助(并发操作不会被覆盖)。所以,对于delete,你可以传入一个version表明,只有当znode版本匹配时才删除。EXIST(PATH,WATCH)。入参分别是文件的全路径名PATH,和一个有趣的额外参数WATCH。通过指定watch,你可以监听对应文件的变化。不论文件是否存在,你都可以设置watch为true,这样Zookeeper可以确保如果文件有任何变更,例如创建,删除,修改,都会通知到客户端。此外,判断文件是否存在和watch文件的变化,在Zookeeper内是原子操作。所以,当调用exist并传入watch为true时,不可能在Zookeeper实际判断文件是否存在,和建立watch通道之间,插入任何的创建文件的操作,这对于正确性来说非常重要。GETDATA(PATH,WATCH)。入参分别是文件的全路径名PATH,和WATCH标志位。这里的watch监听的是文件的内容的变化。SETDATA(PATH,DATA,VERSION)。入参分别是文件的全路径名PATH,数据DATA,和版本号VERSION。如果你传入了version,那么Zookeeper当且仅当文件的版本号与传入的version一致时,才会更新文件。LIST(PATH)。入参是目录的路径名,返回的是路径下的所有文件。
9.2 使用Zookeeper实现计数器
我们来看看是如何使用这些Zookeeper API的。
第一个很简单的例子是计数器,假设我们在Zookeeper中有一个文件,我们想要在那个文件存储一个统计数字,例如,统计客户端的请求次数,当收到了一个来自客户端的请求时,我们需要增加存储的数字。
现在关键问题是,多个客户端会同时并发发送请求导致存储的数字增加。所以,第一个要解决的问题是,除了管理数据以外(类似于简单的SET和GET),我们是不是真的需要一个特殊的接口来支持多个客户端的并发。Zookeeper API看起来像是个文件系统,我们能不能只使用典型的存储系统的读写操作来解决并发的问题。
比如说,在Lab3中,你们会构建一个key-value数据库,它只支持两个操作,一个是PUT(K,V),另一个是GET(K)。对于所有我们想要通过Zookeeper来实现的操作,我们可以使用Lab3中的key-value数据库来完成吗?或许我们真的可以使用只有两个操作接口的Lab3来完成这里的计数器功能。你可以这样实现,首先通过GET读出当前的计数值,之后通过PUT写入X + 1。
为什么这是一个错误的答案?是的,这里不是原子操作,这是问题的根源。
如果有两个客户端想要同时增加计数器的值,它们首先都会先通过GET读出旧的计数器值,比如说10。之后,它们都会对10加1得到11,并调用PUT将11写入。所以现在我们只对计数器加了1,但是实际上有两个客户端执行了增加计数器的操作,而我们本应该对计数器增加2。所以,这就是什么Lab3甚至都不能用在这个最简单的例子中。
但是,Zookeeper自身也有问题,在Zookeeper的世界中,GET可能得到的是旧数据。而Lab3中,GET不允许返回旧的数据。因为Zookeeper读数据可能得到旧的数据,如果你得到了一个旧版本的计数器值,并对它加1,那么你实际会写入一个错误的数值。如果最新的数据是11,但是你通过Zookeeper的GET得到的是旧的数据10,然后你加了1,再将11写入到Zookeeper,这是一个错误的行为,因为我们实际上应该将12写入到Zookeeper中。所以,Zookeeper也有问题,我们必须要考虑GET得到的不是最新数据的情况。
所以,如何通过Zookeeper实现一个计数器呢?我会这样通过Zookeeper来实现计数器。你需要将这里的代码放在一个循环里面,因为代码不一定能在第一次执行的时候成功。我们对于循环加上while true,之后我们调用GETDATA来获取当前计数器的值,代码是X,V = GETDATA(“f”),我们并不关心文件名是什么,所以这里直接传入一个“f”。
现在,我们获得了一个数值X,和一个版本号V,可能不是最新的,也可能是新的。之后,我们对于SETDATA("f", X + 1, V)加一个IF判断。如果返回true,表明它的确写入了数据,那么我们会从循环中跳出 break,如果返回false,那我们会回到循环的最开始,重新执行。
WHILE TRUE:
X, V = GETDATA("F")
IF SETDATA("f", X + 1, V):
BREAK
在代码的第2行,我们从某个副本读到了一个数据X和一个版本号V,或许是旧的或许是最新的。而第3行的SETDATA会在Zookeeper Leader节点执行,因为所有的写操作都要在Leader执行。第3行的意思是,只有当实际真实的版本号等于V的时候,才更新数据。如果系统没有其他的客户端在更新“f”对应的数据,那么我们可以直接读出最新的数据和最新的版本号,之后调用SETDATA时,我们对最新的数据加1,并且指定了最新的版本号,SETDATA最终会被Leader所接受并得到回复说写入成功,之后就可以通过BREAK跳出循环,因为此时,我们已经成功写入了数据。但是,如果我们在第2行得到的是旧的数据,或者得到的就是最新的数据,但是当我们的SETDATA送到Zookeeper Leader时,数据已经被其他的客户端修改了,这样我们的版本号就不再是最新的版本号。这时,SETDATA会失败,并且我们会得到一个错误的回复,这样我们的代码不会跳出循环,我们会回到循环的最开始,重头开始再执行,并且期望这次能执行成功。
学生提问:这里能确保循环一定退出吗?
Robert教授:不,我们这里并没有保证说循环一定会退出。例如在实际中,我们读取数据的副本与Leader失联了,并且永远返回给我们旧数据,那么这里永远都会陷在循环中。大部分情况下,Leader会使得所有的副本都趋向于拥有与Leader相同的数据。所以,如果我们第一次拿到的是旧的数据,在我们再次重试前,我们或许需要等待10ms。最终我们会看到最新的数据。
一种最坏的情况是,如果有1000个客户端并发请求要增加计数器,那么一次只有一个客户端可以成功。这1000个客户端中,第一个将SETDATA发到Leader的客户端可以成功增加计数,而其他的会失败,因为其他客户端持有的版本号已经过时了。之后,剩下的999个客户端会再次并发的发送请求,然后还是只有一个客户端能成功。所以,为了让所有的客户端都能成功计数,这里的复杂度是 O(n^2) 。这不太好,但是最终所有的请求都能够完成。所以,如果你的场景中有大量的客户端,那么这里你或许要使用一个不同的策略。前面介绍的策略只适合低负载的场景。
学生提问:Zookeeper的数据都存在内存吗?
Robert教授:是的。如果数据小于内存容量那就没问题,如果数据大于内存容量,那就是个灾难。所以当你在使用Zookeeper时,你必须时刻记住Zookeeper对于100MB的数据很友好,但是对于100GB的数据或许就很糟糕了。这就是为什么人们用Zookeeper来存储配置,而不是大型网站的真实数据。
学生提问:对于高负载的场景该如何处理呢?
Robert教授:我们可以在SETDATA失败之后等待一会。我会这么做,首先,等待(sleep)是必须的,其次,等待的时间每次需要加倍再加上一些随机。这里实际上跟Raft的Leader Election里的Exponential back-off是类似的。这是一种适应未知数量并发客户端请求的合理策略。
学生提问:提问过程比较长,听不太清,大概意思就是想使用WATCH机制来解决上面的 O(n^2) 的问题。
Robert教授:首先,如果我们在GETDATA的时候,增加WATCH=true,那么在我们实际调用SETDATA时,如果有人修改了计数器的值,我们是可以收到通知的。
但是这里的时序并不是按照你设想的那样工作,上面代码的第2,3行之间的时间理论上是0。但是如果有一个其他客户端在我们GETDATA之后发送了增加计数的请求,我们收到通知的时间可能会比较长。首先那个客户端的请求要发送到Leader,之后Leader要将这个请求转发到Follower,Follower执行完之后Follower会查找自己的Watch表单,然后才能给我们发送一个通知。所以,就算我们在GETDATA的时候设置了WATCH,我们在SETDATA的时候,也不一定能收到其他客户端修改数据的通知。
在任何情况下,我认为WATCH不能帮助我们。因为1000个客户端都会做相同的事情,它们都会调用GETDATA,设置WATCH,它们都会同时获得通知,并作出相同的决定。又或许没有一个客户端可以得到WATCH结果,因为没有人成功的SETDATA了。所以,最坏的情况是,所有的客户端从一个位置开始执行,它们都调用GETDATA,得到了版本号为1,同时设置了WATCH。因为现在还没有变更,这一千个客户端都通过RPC发送了SETDATA给Leader。之后,第一个客户端更新了数据,然后其他的999个客户端才能得到通知,但是现在太晚了,因为它们已经发送了SETDATA。
WATCH或许可以在这里帮到我们。接下来的Lock的例子解决了这里的问题。所以,我们可以采用论文中的第二个有关Lock的例子,在有大量客户端想要增加计数器时,使得计数器一次只处理一个客户端。
还有其他问题吗?
这个例子,其实就是大家常说的mini-transaction。这里之所以是事务的,是因为一旦我们操作成功了,我们对计数器达成了_读-更改-写_的原子操作。对于我们在Lab3中实现的数据库来说,它的读写操作不是原子的。而我们上面那段代码,一旦完成了,就是原子的。因为一旦完成了,我们的读,更改,写操作就不受其他任何客户端的干扰。
之所以称之为mini-transaction,是因为这里并不是一个完整的数据库事务(transaction)。一个真正的数据库可以使用完整的通用的事务,你可以指定事务的开始,然后执行任意的数据读写,之后结束事务。数据库可以聪明的将所有的操作作为一个原子事务提交。一个真实的事务可能会非常复杂,而Zookeeper支持这种非常简单的事务,使得我们可以对于一份数据实现原子操作。这对于计数器或者其他的一些简单功能足够了。所以,这里的事务并不通用,但是的确也提供了原子性,所以它被称为mini-transaction。
通过计数器这个例子里的策略可以实现很多功能,比如VMware FT所需要的Test-and-Set服务就可以以非常相似的方式来实现。如果旧的数据是0,一个虚机尝试将其设置成1,设置的时候会带上旧数据的版本号,如果没有其他的虚机介入也想写这个数据,我们就可以成功的将数据设置成1,因为Zookeeper里数据的版本号没有改变。如果某个客户端在我们读取数据之后更改了数据,那么Leader会通知我们说数据写入失败了,所以我们可以用这种方式来实现Test-and-Set服务。你应该记住这里的策略。
9.3 使用Zookeeper实现非扩展锁
这一部分我想讨论的例子是非扩展锁。我讨论它的原因并不是因为我强烈的认为这种锁是有用的,而是因为它在Zookeeper论文中出现了。
对于锁来说,常见的操作是Aquire Lock,获得锁。获得锁可以用下面的伪代码实现:
WHILE TRUE:
IF CREATE("f", data, ephemeral=TRUE): RETURN
IF EXIST("f", watch=TRUE):
WAIT
GOTO // 等待文件删除对应的watch通知,收到通知后继续循环
在代码的第2行,是尝试创建锁文件。除了指定文件名,还指定了ephemeral为TRUE(ephemeral的含义详见9.1)。如果锁文件创建成功了,表明我们获得了锁,直接RETURN。
如果锁文件创建失败了,我们需要等待锁释放。因为如果锁文件创建失败了,那表明锁已经被别人占住了,所以我们需要等待锁释放。最终锁会以删除文件的形式释放,所以我们这里通过EXIST函数加上watch=TRUE,来监测文件的删除。在代码的第3行,可以预期锁文件还存在,因为如果不存在的话,在代码的第2行就返回了。
在代码的第4行,等待文件删除对应的watch通知。收到通知之后,再回到循环的最开始,从代码的第2行开始执行。
所以,总的来说,先是通过CREATE创建锁文件,或许可以直接成功。如果失败了,我们需要等待持有锁的客户端释放锁。通过Zookeeper的watch机制,我们会在锁文件删除的时候得到一个watch通知。收到通知之后,我们回到最开始,尝试重新创建锁文件,如果运气足够好,那么这次是能创建成功的。
在这里,我们要问自己一个问题:如果多个客户端并发的请求锁会发生什么?
有一件事情可以确定,如果有两个客户端同时要创建锁文件,Zookeeper Leader会以某种顺序一次只执行一个请求。所以,要么是我的客户端先创建了锁文件,要么是另一个客户端创建了锁文件。如果我的客户端先创建了锁文件,我们的CREATE调用会返回TRUE,这表示我们获得了锁,然后我们直接RETURN返回,而另一个客户端调用CREATE必然会收到了FALSE。如果另一个客户端先创建了文件,那么我的客户端调用CREATE必然会得到FALSE。不管哪种情况,锁文件都会被创建。当有多个客户端同时请求锁时,因为Zookeeper一次只执行一个请求,所以还好。
如果我的客户端调用CREATE返回了FALSE,那么我接下来需要调用EXIST,如果锁在代码的第2行和第3行之间释放了会怎样呢?这就是为什么在代码的第3行,EXIST前面要加一个IF,因为锁文件有可能在调用EXIST之前就释放了。如果在代码的第3行,锁文件不存在,那么EXIST返回FALSE,代码又回到循环的最开始,重新尝试获得锁。
类似的,并且同时也更有意思的是,如果正好在我调用EXIST的时候,或者在与我交互的副本还在处理EXIST的过程中,锁释放了会怎样?不管我与哪个副本进行交互,在它的Log中,可以确保写请求会以某种顺序执行。所以,与我交互的副本,它的Log以某种方式向前增加。因为我的EXIST请求是个只读请求,所以它必然会在两个写请求之间执行。现在某个客户端的DELETE请求要在某个位置被处理,所以,在副本Log中的某处是来自其他客户端的DELETE请求。而我的EXIST请求有两种可能:要么完全的在DELETE请求之前处理,这样的话副本会认为,锁文件还存在,副本会在WATCH表单(详见8.7)中增加一条记录,之后才执行DELETE请求。
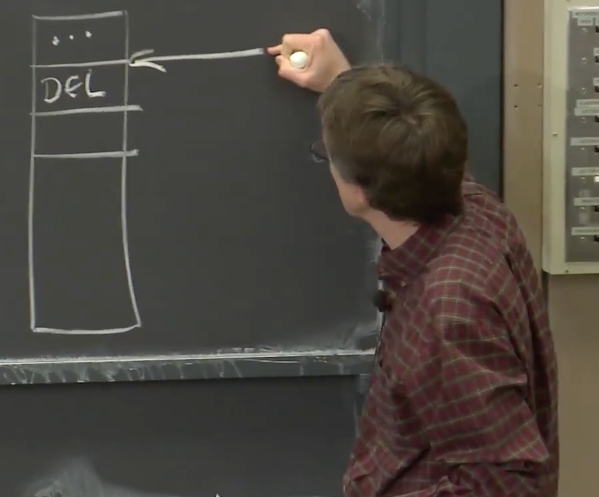
而当执行DELETE请求的时候,可以确保我的WATCH请求在副本的WATCH表单中,所以副本会给我发送一个通知,说锁文件被删除了。
要么我的EXIST请求在DELETE请求之后处理。这时,文件并不存在,EXIST返回FALSE,又回到了循环的最开始。

因为Zookeeper的写请求是序列化的,而读请求必然在副本Log的两个写请求之间确定的位置执行,所以这种情况也还好。
学生提问:如果EXIST返回FALSE,回到循环最开始,调用CREATE的时候,已经有其他人创建了锁会怎样呢?
Robert教授:那么CREATE会返回FALSE,我们又回到了EXIST,这次我们还是需要等待WATCH通知锁文件被删除了。
学生提问:为什么我们不关心锁的名字?
Robert教授:这只是一个名字,为了让不同的客户端可以使用同一个锁。所以,它只是个名字而已。当我获得锁之后,我可以对锁保护的数据做任何操作。比如,一次只有一个人可以在这个课堂里讲课,为了讲课,首先需要获得这个课堂的锁,那要先知道锁的名字,比如说34100(猜是教室名字)。这里讨论的锁本质上就是一个znode,但是没有人关心它的内容是什么。所以,我们需要对锁有一个统一的名字。所以,Zookeeper看起来像是一个文件系统,实际上它是一个命名系统(naming system)。
这里的锁设计并不是一个好的设计,因为它和前一个计数器的例子都受羊群效应(Herd Effect)的影响。所谓的羊群效应,对于计数器的例子来说,就是当有1000个客户端同时需要增加计数器时,我们的复杂度是 O(_n^_2) ,这是处理完1000个客户端的请求所需要的总时间。对于这一节的锁来说,也存在羊群效应,如果有1000个客户端同时要获得锁文件,为1000个客户端分发锁所需要的时间也是 O(_n^_2) 。因为每一次锁文件的释放,所有剩下的客户端都会收到WATCH的通知,并且回到循环的开始,再次尝试创建锁文件。所以CREATE对应的RPC总数与1000的平方成正比。所以这一节的例子也受羊群效应的影响,像羊群一样的客户端都阻塞在Zookeeper这。这一节实现的锁有另一个名字:非扩展锁(Non-Scalable Lock)。它对应的问题是真实存在的,我们会在其他系统中再次看到。
9.4 使用Zookeeper实现可扩展锁
在Zookeeper论文的结尾,讨论了如何使用Zookeeper解决非扩展锁的问题。有意思的是,因为Zookeeper的API足够灵活,可以用来设计另一个更复杂的锁,从而避免羊群效应。从而使得,即使有1000个客户端在等待锁释放,当锁释放时,另一个客户端获得锁的复杂度是_O_(1) 而不是_O_(n) 。这个设计有点复杂,下面是论文第6页中2.4部分的伪代码。在这个设计中,我们不再使用一个单独的锁文件,而是创建Sequential文件(详见9.1)。
CREATE("f", data, sequential=TRUE, ephemeral=TRUE)
WHILE TRUE:
LIST("f*")
IF NO LOWER #FILE: RETURN
IF EXIST(NEXT LOWER #FILE, watch=TRUE):
WAIT
在代码的第1行调用CREATE,并指定sequential=TRUE,我们创建了一个Sequential文件,如果这是以“f”开头的第27个Sequential文件,这里实际会创建类似以“f27”为名字的文件。这里有两点需要注意,第一是通过CREATE,我们获得了一个全局唯一序列号(比如27),第二Zookeeper生成的序号必然是递增的。
代码第3行,通过LIST列出了所有以“f”开头的文件,也就是所有的Sequential文件。
代码第4行,如果现存的Sequential文件的序列号都不小于我们在代码第1行得到的序列号,那么表明我们在并发竞争中赢了,我们获得了锁。所以当我们的Sequential文件对应的序列号在所有序列号中最小时,我们获得了锁,直接RETURN。序列号代表了不同客户端创建Sequential文件的顺序。在这种锁方案中,会使用这个顺序来向客户端分发锁。当存在更低序列号的Sequential文件时,我们要做的是等待拥有更低序列号的客户端释放锁。在这个方案中,释放锁的方式是删除文件。所以接下来,我们需要做的是等待序列号更低的锁文件删除,之后我们才能获得锁。
所以,在代码的第5行,我们调用EXIST,并设置WATCH,等待比自己序列号更小的下一个锁文件删除。如果等到了,我们回到循环的最开始。但是这次,我们不会再创建锁文件,代码从LIST开始执行。这是获得锁的过程,释放就是删除创建的锁文件。
学生提问:为什么重试的时候要在代码第3行再次LIST文件?
Robert教授:这是个好问题。问题是,我们在代码第3行得到了文件的列表,我们就知道了比自己序列号更小的下一个锁文件。Zookeeper可以确保,一旦一个序列号,比如说27,被使用了,那么之后创建的Sequential文件不会使用更小的序列号。所以,我们可以确定第一次LIST之后,不会有序列号低于27的锁文件被创建,那**为什么在重试的时候要再次LIST文件?为什么不直接跳过?**你们来猜猜答案。
答案是,持有更低序列号Sequential文件的客户端,可能在我们没有注意的时候就释放了锁,也可能已经挂了。比如说,我们是排在第27的客户端,但是排在第26的客户端在它获得锁之前就挂了。因为它挂了,Zookeeper会自动的删除它的锁文件(因为创建锁文件时,同时也指定了ephemeral=TRUE)。所以这时,我们要等待的是序列号25的锁文件释放。所以,尽管不可能再创建序列号更小的锁文件,但是排在前面的锁文件可能会有变化,所以我们需要在循环的最开始再次调用LIST,以防在等待锁的队列里排在我们前面的客户端挂了。
学生提问:如果不存在序列号更低的锁文件,那么当前客户端就获得了锁?
Robert教授:是的。
学生提问:为什么这种锁不会受羊群效应(Herd Effect)的影响?
Robert教授:假设我们有1000个客户端在等待获取锁,每个客户端都会在代码的第6行等待锁释放。但是每个客户端等待的锁文件都不一样,比如序列号为500的锁只会被序列号为501的客户端等待,而序列号500的客户端只会等待序列号499的锁文件。每个客户端只会等待一个锁文件,当一个锁文件被释放,只有下一个序列号对应的客户端才会收到通知,也只有这一个客户端会回到循环的开始,也就是代码的第3行,之后这个客户端会获得锁。所以,不管有多少个客户端在等待锁,每一次锁释放再被其他客户端获取的代价是一个常数。而在非扩展锁中,锁释放时,每个等待的客户端都会被通知到,之后,每个等待的客户端都会发送CREATE请求给Zookeeper,所以每一次锁释放再被其他客户端获取的代价与客户端数量成正比。
学生提问:那排在后面的客户端岂不是要等待很长的时间?
Robert教授:你可以去喝杯咖啡等一等。编程接口不是我们关心的内容,不过代码第6行的等待有两种可能,第一种是启动一个线程同步等待锁,在获得锁之前线程不会继续执行;第二种会更加复杂一些,你向Zookeeper发送请求,但是不等待其返回,同时有另外一个goroutine等待Zookeeper的返回,这跟前面介绍的AppCh(Apply Channel,详见6.6)一样,第二种方式更加常见。所以要么是多线程,要么是事件驱动,不管怎样,代码在等待的时候可以执行其他的动作。
学生提问:代码第5行EXIST返回TRUE意味着什么?
Robert教授:如果返回TRUE,意味着,要么对应的客户端还活着并持有着锁,要么还活着在等待其他的锁,我们不知道是哪种情况。如果EXIST返回FALSE,那么有两种可能:要么是序列号的前一个客户端释放了锁并删除了锁文件;要么是前一个客户端退出了,因为锁文件是ephemeral的,然后Zookeeper删除了锁文件。所以,不论EXIST返回什么,都有两种可能。所以我们重试的时候,要检查所有的信息,因为我们不知道EXIST完成之后是什么情况。
我第一次看到可扩展锁,是在一种完全不同的背景下,也就是在多线程代码中的可扩展锁。通常来说,这种锁称为可扩展锁(Scalable Lock)。我认为这是我见过的一种最有趣的结构,就像我很欣赏Zookeeper的API设计一样。
不得不说,我有点迷惑为什么Zookeeper论文要讨论锁。因为这里的锁并不像线程中的锁,在线程系统中,不存在线程随机的挂了然后下线。如果每个线程都正确使用了锁,你从线程锁中可以获得操作的原子性(Atomicity)。假如你获得了锁,并且执行了47个不同的读写操作,修改了一些变量,然后释放了锁。如果所有的线程都遵从这里的锁策略,没有人会看到一切奇怪的数据中间状态。这里的线程锁可以使得操作具备原子性。
而通过Zookeeper实现的锁就不太一样。如果持有锁的客户端挂了,它会释放锁,另一个客户端可以接着获得锁,所以它并不确保原子性。因为你在分布式系统中可能会有部分故障(Partial Failure),但是你在一个多线程代码中不会有部分故障。如果当前锁的持有者需要在锁释放前更新一系列被锁保护的数据,但是更新了一半就崩溃了,之后锁会被释放。然后你可以获得锁,然而当你查看数据的时候,只能看到垃圾数据,因为这些数据是只更新了一半的随机数据。所以,Zookeeper实现的锁,并没有提供类似于线程锁的原子性保证。
所以,读完了论文之后,我不禁陷入了沉思,为什么我们要用Zookeeper实现锁,为什么锁会是Zookeeper论文中的主要例子之一。
我认为,在一个分布式系统中,你可以这样使用Zookeeper实现的锁。每一个获得锁的客户端,需要做好准备清理之前锁持有者因为故障残留的数据。所以,当你获得锁时,你查看数据,你需要确认之前的客户端是否故障了,如果是的话,你该怎么修复数据。如果总是以确定的顺序来执行操作,假设前一个客户端崩溃了,你或许可以探测出前一个客户端是在操作序列中哪一步崩溃的。但是这里有点取巧,你需要好好设计一下。而对于线程锁,你就不需要考虑这些问题。
另外一个对于这些锁的合理的场景是:Soft Lock。Soft Lock用来保护一些不太重要的数据。举个例子,当你在运行MapReduce Job时,你可以用这样的锁来确保一个Task同时只被一个Work节点执行。例如,对于Task 37,执行它的Worker需要先获得相应的锁,再执行Task,并将Task标记成执行完成,之后释放锁。MapReduce本身可以容忍Worker节点崩溃,所以如果一个Worker节点获得了锁,然后执行了一半崩溃了,之后锁会被释放,下一个获得锁的Worker会发现任务并没有完成,并重新执行任务。这不会有问题,因为这就是MapReduce定义的工作方式。所以你可以将这里的锁用在Soft Lock的场景。
另一个值得考虑的问题是,我们可以用这里的代码来实现选举Master。
学生提问:有没有探测前一个锁持有者崩溃的方法?
Robert教授:还记录论文里说的吗?你可以先删除Ready file,之后做一些操作,最后再重建Ready file。这是一种非常好的探测并处理前一个Master或者锁持有者在半路崩溃的方法。因为可以通过Ready file是否存在来判断前一个锁持有者是否因为崩溃才退出。
学生提问:在Golang实现的多线程代码中,一个线程获得了锁,有没有可能在释放锁之前就崩溃了?
Robert教授:不幸的是,这个是可能的。对于单个线程来说有可能崩溃,或许在运算时除以0,或者一些其他的panic。我的建议是,现在程序已经故障了,最好把程序的进程杀掉。
在多线程的代码中,可以这么来看锁:当锁被持有时,数据是可变的,不稳定的。当锁的持有线程崩溃了,是没有安全的办法再继续执行代码的。因为不论锁保护的是什么数据,当锁没有释放时,数据都可以被认为是不稳定的。如果你足够聪明,你可以使用类似于Ready file的方法,但是在Golang里面实现这种方法超级难,因为内存模型决定了你不能依赖任何东西。如果你更新一些变量,之后设置一个类似于Ready file的Done标志位,这不意味任何事情,除非你释放了锁,其他人获得了锁。因为只有在那时线程的执行顺序是确定的,其他线程才能安全的读取Done标志位。所以在Golang里面,很难从一个持有了锁的线程的崩溃中恢复。但是在我们的锁里面,恢复或许会更加可能一些。
以上就是对于Zookeeper的一些介绍。有两点需要注意:
- 第一是Zookeeper聪明的从多个副本读数据从而提升了性能,但同时又牺牲了一些一致性;
- 另一个是Zookeeper的API设计,使得Zookeeper成为一个通用的协调服务,这是一个简单的put/get 服务所不能实现,这些API使你可以写出类似mini-transaction的代码,也可以帮你创建自己的锁。
9.5 链复制(Chain Replication)
这一部分,我们来讨论另一个论文CRAQ(Chain Replication with Apportioned Queries)。我们选择CRAQ论文有两个原因:第一个是它通过复制实现了容错;第二是它通过以链复制API请求这种有趣的方式,提供了与Raft相比不一样的属性。
CRAQ是对于一个叫链式复制(Chain Replication)的旧方案的改进。Chain Replication实际上用的还挺多的,有许多现实世界的系统使用了它,CRAQ是对它的改进。CRAQ采用的方式与Zookeeper非常相似,它通过将读请求分发到任意副本去执行,来提升读请求的吞吐量,所以副本的数量与读请求性能成正比。CRAQ有意思的地方在于,它在任意副本上执行读请求的前提下,还可以保证线性一致性(Linearizability)。这与Zookeeper不太一样,Zookeeper为了能够从任意副本执行读请求,不得不牺牲数据的实时性,因此也就不是线性一致的。CRAQ却可以从任意副本执行读请求,同时也保留线性一致性,这一点非常有趣。
首先,我想讨论旧的Chain Replication系统。Chain Replication是这样一种方案,你有多个副本,你想确保它们都看到相同顺序的写请求(这样副本的状态才能保持一致),这与Raft的思想是一致的,但是它却采用了与Raft不同的拓扑结构。
首先,在Chain Replication中,有一些服务器按照链排列。第一个服务器称为HEAD,最后一个被称为TAIL。
当客户端想要发送一个写请求,写请求总是发送给HEAD。
HEAD根据写请求更新本地数据,我们假设现在是一个支持PUT/GET的key-value数据库。所有的服务器本地数据都从A开始。
当HEAD收到了写请求,将本地数据更新成了B,之后会再将写请求通过链向下一个服务器传递。
下一个服务器执行完写请求之后,再将写请求向下一个服务器传递,以此类推,所有的服务器都可以看到写请求。
当写请求到达TAIL时,TAIL将回复发送给客户端,表明写请求已经完成了。这是处理写请求的过程。
对于读请求,如果一个客户端想要读数据,它将读请求发往TAIL,TAIL直接根据自己的当前状态来回复读请求。所以,如果当前状态是B,那么TAIL直接返回B。读请求处理的非常的简单。
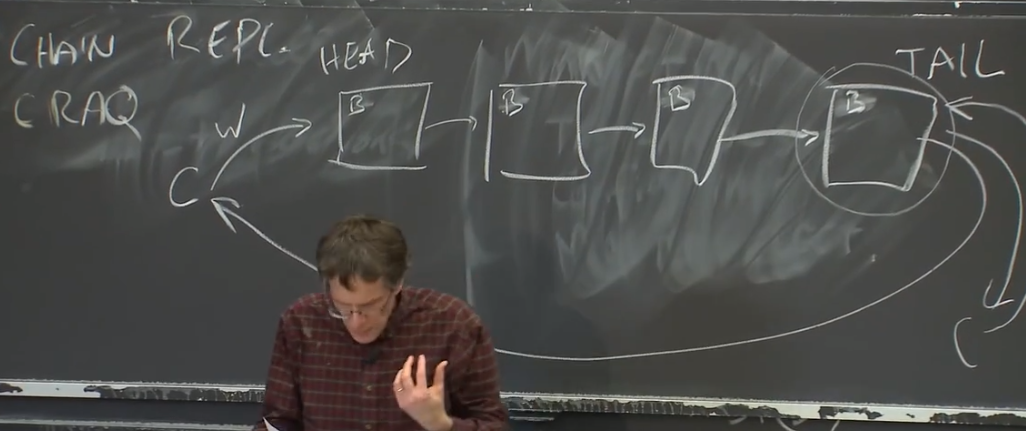
这里只是Chain Replication,并不是CRAQ。Chain Replication本身是线性一致的,在没有故障时,从一致性的角度来说,整个系统就像只有TAIL一台服务器一样,TAIL可以看到所有的写请求,也可以看到所有的读请求,它一次只处理一个请求,读请求可以看到最新写入的数据。如果没有出现故障的话,一致性是这么得到保证的,非常的简单。
从一个全局角度来看,除非写请求到达了TAIL,否则一个写请求是不会commit,也不会向客户端回复确认,也不能将数据通过读请求暴露出来。而为了让写请求到达TAIL,它需要经过并被链上的每一个服务器处理。所以我们知道,一旦我们commit一个写请求,一旦向客户端回复确认,一旦将写请求的数据通过读请求暴露出来,那意味着链上的每一个服务器都知道了这个写请求。
9.6 链复制的故障恢复(Fail Recover)
在Chain Replication中,出现故障后,你可以看到的状态是相对有限的。因为写请求的传播模式非常有规律,我们不会陷入到类似于Raft论文中图7和图8描述的那种令人毛骨悚然的复杂场景中。并且在出现故障之后,也不会出现不同的副本之间各种各样不同步的场景。
在Chain Replication中,因为写请求总是依次在链中处理,写请求要么可以达到TAIL并commit,要么只到达了链中的某一个服务器,之后这个服务器出现故障,在链中排在这个服务器后面的所有其他服务器不再能看到写请求。所以,只可能有两种情况:committed的写请求会被所有服务器看到;而如果一个写请求没有commit,那就意味着在导致系统出现故障之前,写请求已经执行到链中的某个服务器,所有在链里面这个服务器之前的服务器都看到了写请求,所有在这个服务器之后的服务器都没看到写请求。
总的来看,Chain Replication的故障恢复也相对的更简单。
如果HEAD出现故障,作为最接近的服务器,下一个节点可以接手成为新的HEAD,并不需要做任何其他的操作。对于还在处理中的请求,可以分为两种情况:
- 对于任何已经发送到了第二个节点的写请求,不会因为HEAD故障而停止转发,它会持续转发直到commit。
- 如果写请求发送到HEAD,在HEAD转发这个写请求之前HEAD就故障了,那么这个写请求必然没有commit,也必然没有人知道这个写请求,我们也必然没有向发送这个写请求的客户端确认这个请求,因为写请求必然没能送到TAIL。所以,对于只送到了HEAD,并且在HEAD将其转发前HEAD就故障了的写请求,我们不必做任何事情。或许客户端会重发这个写请求,但是这并不是我们需要担心的问题。
如果TAIL出现故障,处理流程也非常相似,TAIL的前一个节点可以接手成为新的TAIL。所有TAIL知道的信息,TAIL的前一个节点必然都知道,因为TAIL的所有信息都是其前一个节点告知的。
中间节点出现故障会稍微复杂一点,但是基本上来说,需要做的就是将故障节点从链中移除。或许有一些写请求被故障节点接收了,但是还没有被故障节点之后的节点接收,所以,当我们将其从链中移除时,故障节点的前一个节点或许需要重发最近的一些写请求给它的新后继节点。这是恢复中间节点流程的简单版本。
Chain Replication与Raft进行对比,有以下差别:
- 从性能上看,对于Raft,如果我们有一个Leader和一些Follower。Leader需要直接将数据发送给所有的Follower。所以,当客户端发送了一个写请求给Leader,Leader需要自己将这个请求发送给所有的Follower。然而在Chain Replication中,HEAD只需要将写请求发送到一个其他节点。数据在网络中发送的代价较高,所以Raft Leader的负担会比Chain Replication中HEAD的负担更高。当客户端请求变多时,Raft Leader会到达一个瓶颈,而不能在单位时间内处理更多的请求。而同等条件以下,Chain Replication的HEAD可以在单位时间处理更多的请求,瓶颈会来的更晚一些。
- 另一个与Raft相比的有趣的差别是,Raft中读请求同样也需要在Raft Leader中处理,所以Raft Leader可以看到所有的请求。而在Chain Replication中,每一个节点都可以看到写请求,但是只有TAIL可以看到读请求。所以负载在一定程度上,在HEAD和TAIL之间分担了,而不是集中在单个Leader节点。
- 前面分析的故障恢复,Chain Replication也比Raft更加简单。这也是使用Chain Replication的一个主要动力。
学生提问:如果一个写请求还在传递的过程中,还没有到达TAIL,TAIL就故障了,会发生什么?
Robert教授:如果这个时候TAIL故障了,TAIL的前一个节点最终会看到这个写请求,但是TAIL并没有看到。因为TAIL的故障,TAIL的前一个节点会成为新的TAIL,这个写请求实际上会完成commit,因为写请求到达了新的TAIL。所以新的TAIL可以回复给客户端,但是它极有可能不会回复,因为当它收到写请求时,它可能还不是TAIL。这样的话,客户端或许会重发写请求,但是这就太糟糕了,因为同一个写请求会在系统中处理两遍,所以我们需要能够在HEAD抑制重复请求。不过基本上我们讨论的所有系统都需要能够抑制重复的请求。
学生提问:假设第二个节点不能与HEAD进行通信,第二个节点能不能直接接管成为新的HEAD,并通知客户端将请求发给自己,而不是之前的HEAD?
Robert教授:这是个非常好的问题。你认为呢?
你的方案听起来比较可行。假设HEAD和第二个节点之间的网络出问题了,

HEAD还在正常运行,同时HEAD认为第二个节点挂了。然而第二个节点实际上还活着,它认为HEAD挂了。所以现在他们都会认为,另一个服务器挂了,我应该接管服务并处理写请求。因为从HEAD看来,其他服务器都失联了,HEAD会认为自己现在是唯一的副本,那么它接下来既会是HEAD,又会是TAIL。第二个节点会有类似的判断,会认为自己是新的HEAD。所以现在有了脑裂的两组数据,最终,这两组数据会变得完全不一样。
(下一节继续分析怎么解决这里的问题)
9.7 链复制的配置管理器(Configuration Manager)
所以,Chain Replication并不能抵御网络分区,也不能抵御脑裂。在实际场景中,这意味它不能单独使用。Chain Replication是一个有用的方案,但是它不是一个完整的复制方案。它在很多场景都有使用,但是会以一种特殊的方式来使用。总是会有一个外部的权威(External Authority)来决定谁是活的,谁挂了,并确保所有参与者都认可由哪些节点组成一条链,这样在链的组成上就不会有分歧。这个外部的权威通常称为Configuration Manager。
Configuration Manager的工作就是监测节点存活性,一旦Configuration Manager认为一个节点挂了,它会生成并送出一个新的配置,在这个新的配置中,描述了链的新的定义,包含了链中所有的节点,HEAD和TAIL。Configuration Manager认为挂了的节点,或许真的挂了也或许没有,但是我们并不关心。因为所有节点都会遵从新的配置内容,所以现在不存在分歧了。
现在只有一个角色(Configuration Manager)在做决定,它不可能否认自己,所以可以解决脑裂的问题。
当然,你是如何使得一个服务是容错的,不否认自己,同时当有网络分区时不会出现脑裂呢?答案是,Configuration Manager通常会基于Raft或者Paxos。在CRAQ的场景下,它会基于Zookeeper。而Zookeeper本身又是基于类似Raft的方案。

所以,你的数据中心内的设置通常是,你有一个基于Raft或者Paxos的Configuration Manager,它是容错的,也不会受脑裂的影响。之后,通过一系列的配置更新通知,Configuration Manager将数据中心内的服务器分成多个链。比如说,Configuration Manager决定链A由服务器S1,S2,S3组成,链B由服务器S4,S5,S6组成。
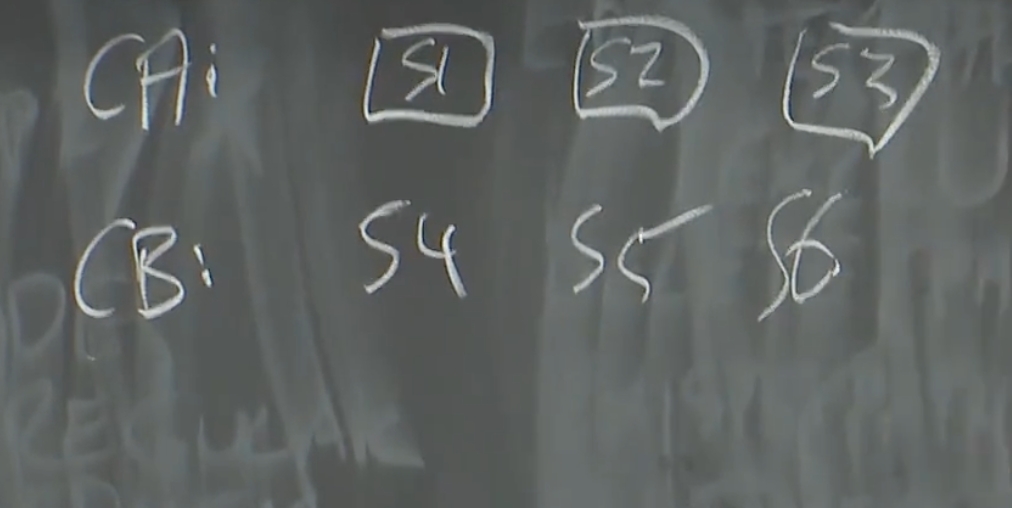
Configuration Manager通告给所有参与者整个链的信息,所以所有的客户端都知道HEAD在哪,TAIL在哪,所有的服务器也知道自己在链中的前一个节点和后一个节点是什么。现在,单个服务器对于其他服务器状态的判断,完全不重要。假如第二个节点真的挂了,在收到新的配置之前,HEAD需要不停的尝试重发请求。节点自己不允许决定谁是活着的,谁挂了。
这种架构极其常见,这是正确使用Chain Replication和CRAQ的方式。在这种架构下,像Chain Replication一样的系统不用担心网络分区和脑裂,进而可以使用类似于Chain Replication的方案来构建非常高速且有效的复制系统。比如在上图中,我们可以对数据分片(Sharding),每一个分片都是一个链。其中的每一个链都可以构建成极其高效的结构来存储你的数据,进而可以同时处理大量的读写请求。同时,我们也不用太担心网络分区的问题,因为它被一个可靠的,非脑裂的Configuration Manager所管理。
学生提问:为什么存储具体数据的时候用Chain Replication,而不是Raft?
Robert教授:这是一个非常合理的问题。其实数据用什么存并不重要。因为就算我们这里用了Raft,我们还是需要一个组件在产生冲突的时候来做决策。比如说数据如何在我们数百个复制系统中进行划分。如果我需要一个大的系统,我需要对数据进行分片,需要有个组件来决定数据是如何分配到不同的分区。随着时间推移,这里的划分可能会变化,因为硬件可能会有增减,数据可能会变多等等。Configuration Manager会决定以A或者B开头的key在第一个分区,以C或者D开头的key在第二个分区。至于在每一个分区,我们该使用什么样的复制方法,Chain Replication,Paxos,还是Raft,不同的人有不同的选择,有些人会使用Paxos,比如说Spanner,我们之后也会介绍。在这里,不使用Paxos或者Raft,是因为Chain Replication更加的高效,因为它减轻了Leader的负担,这或许是一个非常关键的问题。
某些场合可能更适合用Raft或者Paxos,因为它们不用等待一个慢的副本。而当有一个慢的副本时,Chain Replication会有性能的问题,因为每一个写请求需要经过每一个副本,只要有一个副本变慢了,就会使得所有的写请求处理变慢。这个可能非常严重,比如说你有1000个服务器,因为某人正在安装软件或者其他的原因,任意时间都有几个服务器响应比较慢。每个写请求都受限于当前最慢的服务器,这个影响还是挺大的。然而对于Raft,如果有一个副本响应速度较慢,Leader只需要等待过半服务器,而不用等待所有的副本。最终,所有的副本都能追上Leader的进度。所以,Raft在抵御短暂的慢响应方面表现的更好。一些基于Paxos的系统,也比较擅长处理副本相距较远的情况。对于Raft和Paxos,你只需要过半服务器确认,所以不用等待一个远距离数据中心的副本确认你的操作。这些原因也使得人们倾向于使用类似于Raft和Paxos这样的选举系统,而不是Chain Replication。这里的选择取决于系统的负担和系统要实现的目标。
不管怎样,配合一个外部的权威机构这种架构,我不确定是不是万能的,但的确是非常的通用。
学生提问:如果Configuration Manger认为两个服务器都活着,但是两个服务器之间的网络实际中断了会怎样?
Robert教授:对于没有网络故障的环境,总是可以假设计算机可以通过网络互通。对于出现网络故障的环境,可能是某人踢到了网线,一些路由器被错误配置了或者任何疯狂的事情都可能发生。所以,因为错误的配置你可能陷入到这样一个情况中,Chain Replication中的部分节点可以与Configuration Manager通信,并且Configuration Manager认为它们是活着的,但是它们彼此之间不能互相通信。

这是这种架构所不能处理的情况。如果你希望你的系统能抵御这样的故障。你的Configuration Manager需要更加小心的设计,它需要选出不仅是它能通信的服务器,同时这些服务器之间也能相互通信。在实际中,任意两个节点都有可能网络不通。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)