RK3588 QWen3VL模型部署
15_RK3588 QWen3:VL模型部署
转化工具(所需要的代码几乎都在这):https://github.com/airockchip/rknn-llm,git clone下来就行
本博客花费18小时实现和编写,且博主经过五个小时从零搭建环境-通过实验验证了可行性,只需要跟着教程走,保证能行!
总体流程
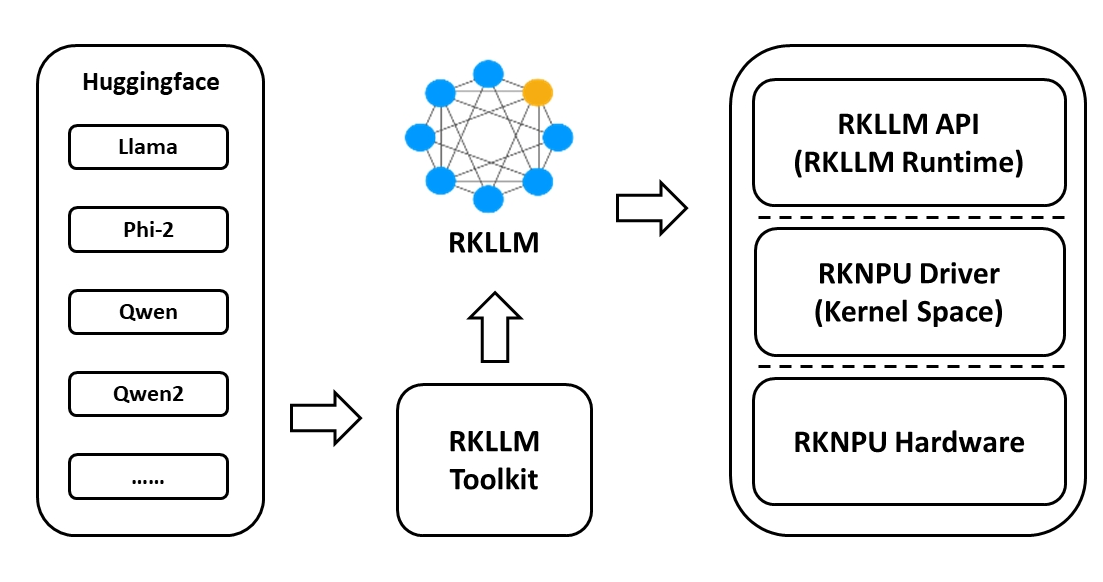
上面就是简单介绍一下,初步搭建时无需特别关注,让我们正式开始吧!
安装RKLLM_SDK
您可以从RKLLM_SDK下载最新包,获取代码:rkllm
当然也可以直接
git clone https://github.com/airockchip/rknn-llm
内容是一样的
项目内容如下
doc
└──Rockchip_RKLLM_SDK_CN.pdf # RKLLM SDK 中文说明文档
└──Rockchip_RKLLM_SDK_EN.pdf # RKLLM SDK 英文说明文档
examples
├──multimodal_model_demo # 多模态推理调用示例工程
├──rkllm_api_demo # 板端 API 推理调用示例工程
└──rkllm_server_demo # RKLLM-Server 部署示例工程
rkllm-runtime
│ └── Android
│ └── librkllm_api
│ └──arm64-v8a
│ └── librkllmrt.so # 64 位 Runtime 库
│ └──armeabi-v7a
│ └── librkllmrt.so # 32 位 Runtime 库
│ └──include
│ └── rkllm.h
│ └── Linux
│ └── librkllm_api
│ └──aarch64
│ └── librkllmrt.so # 64 位 Runtime 库
│ └──armhf
│ └── librkllmrt.so # 32 位 Runtime 库
│ └──include
│ └── rkllm.h
rkllm-toolkit
│ └── packages
│ └──rkllm_toolkit-x.x.x-cp3xx-cp3xx-linux_x86_64.whl
│ └── examples
rknpu-driver
└──rknpu_driver_x.x.x_xxxxxxx.tar.bz2
scripts
├──fix_freq_rk3576.sh # RK3576 定频脚本
└──fix_freq_rk3588.sh # RK3588 定频脚本
└──fix_freq_rk3562.sh # RK3562 定频脚本
└──fix_freq_rv1126b.sh # RV1126B 定频脚本
当然您可以直接从rkllm_mode_zoo下载转换后的rkllm模型,获取代码:rkllm
下面从模型转换和板端部署来实现学习
一、模型转换
该部分如果发现实现不了,或者资源有限,可跳过这部分,直接到第二部分、模型部署,提供了已经转化好的模型!
环境安装
环境要求
rknn-toolkit2>=2.3.2
Python==3.9
rkllm>=1.2.3(或者叫rkllm-toolkit)
先安装RKNN
conda create -n qwen3_env python=3.9 -y
pip install rknn-toolkit2 -i https://mirrors.aliyun.com/pypi/simple
再安装RKLLM环境
等待虚拟环境安装完毕即可
依靠RKLLM 的sdk来进行部署
视觉+投影模块 → ONNX → RKNN → RKLLM
步骤一:视觉+投影模块 → ONNX ONNX → RKNN (计算机的眼睛)
步骤二: LLM部分 → RKLLM (计算机的脑子)
使用文章末尾的requests.txt来解决依赖关系
conda activate qwen3_env
cd rknn-llm/rkllm-toolkit/packages
//使用 pip 工具直接安装所提供的工具链 whl 包, 在安装过程中, 安装工具会自动下载RKLLM-Toolkit 工具所需要的相关依赖包。
//安装对应python版本的依赖环境
pip3 install rkllm_toolkit-1.2.3-cp39-cp39-linux_x86_64.whl
等待安装完毕,30分钟以上,这里安装最好是系统代理成功,详细设置请看博客
Successfully installed XXX XXX XXX
测试是否安装成功
python
from rkllm.api import RKLLM
没报错即可
对于Qwen3-VL的其他依赖要求
需要指定的环境依赖版本
pip install transformers==4.57.0
pip install onnx==1.18.0
下载模型
demo is available at: Qwen2-VL-2B, Qwen2-VL-7B
使用魔搭下载即可,注意下载的路径为 ~/.cache/modelscope/hub/models/Qwen/下面,可以复制到工程目录下面来
①原始模型PyTorch -> .onnx -> rknn
将下载的Qwen3-VL-2B模型中的模型中Vision Encoder(视觉编码器) 部分转换为 .onnx 格式,当作普通的神经网络模型运行(即前面学习的哪些模型结构)。
cd rknn-llm/examples/multimodal_model_demo/export
python ./export_vision.py --path=/home/yl/qwen3/rknn-llm/Qwen3-VL-2B-Instruct --model_name=qwen3-vl --height=224 --width=224
- –height=224 --width=224,必须是这个,不能为448x448 分辨率下的某些算子参数超出了 RK3588 NPU 的寄存器限制。这通常会导致生成的模型不可用(即使文件生成了),也是导致运行崩溃的潜在原因。
输出
...
Exported to ./onnx/qwen3-vl_vision.onnx
在export目录onnx下面生成了rknn-llm/examples/multimodal_model_demo/export/export_vision.py文件
转化的这部分模型是负责将输入的图像(像素数据)处理成大语言模型(LLM)可以理解的图像特征嵌入
它不包含 LLM(大语言模型)的文本处理部分(如 Decoder、Text Embeddings 等)。LLM 部分通常会通过 rkllm-toolkit 直接转换为 .rkllm 格式,而不需要先转为 ONNX。
具体的参数请看
examples/multimodal_model_demo/README.md
那我们已经成功转化了Qwen3-VL-2B的视觉编码器为.onnx格式的文件
接着
②.onnx->rknn
cd rknn-llm/examples/multimodal_model_demo/export
conda activate qwen3_env
python export_vision_rknn.py --path ./onnx/qwen3-vl_vision.onnx --target-platform rk3588 --model_name qwen3-vl --height 224 --width 224
I Saving : 100%|█████████████████████████████████████████████████| 259/259 [00:00<00:00, 399.46it/s]
I rknn building ...
E RKNN: [10:59:46.098] Unkown op target: 0
I rknn building done.
成功生成文件
rknn/
└── qwen3-vl_vision_rk3588.rknn
③将大语言模型LLM部分转换为RKLLM
这一步与前两部是独立的,整个Qwen3_VL分为两部分走,该部分是处理纯文本模型的部分
1.量化前准备工作
官方文档:我们从MMBench_DEV_EN数据集中收集了20个图像-文本示例,存储在 data/datasets.json 和 data/datasets 中。要使用这些数据,首先需要创建 input_embeds 来量化RKLLM模型。运行以下代码生成 data/inputs.json 。
由于环境原因,我重写了data下面的程序
在data下创建一个make_input_embeds_qwen3.py文件,是根据make_input_embeds_for_quantize.py改写的整队Qwen3-VL语言大模型部分的转换代码
import torch
import os
import torchvision.transforms as T
from torchvision.transforms.functional import InterpolationMode
from PIL import Image
import json
import numpy as np
from tqdm import tqdm
from transformers import AutoModel, AutoTokenizer, AutoProcessor, Qwen2VLForConditionalGeneration
try:
from transformers import Qwen3VLForConditionalGeneration
except ImportError:
Qwen3VLForConditionalGeneration = None
import argparse
argparse = argparse.ArgumentParser()
argparse.add_argument('--path', type=str, default='Qwen/Qwen2-VL-2B-Instruct', help='model path', required=False)
args = argparse.parse_args()
path = args.path
if 'qwen3' in path.lower() and Qwen3VLForConditionalGeneration is not None:
print(f"Loading Qwen3-VL model from {path}")
model = Qwen3VLForConditionalGeneration.from_pretrained(
path, torch_dtype="auto", device_map="cpu",
low_cpu_mem_usage=True,
trust_remote_code=True).eval()
else:
print(f"Loading Qwen2-VL model from {path}")
model = Qwen2VLForConditionalGeneration.from_pretrained(
path, torch_dtype="auto", device_map="cpu",
low_cpu_mem_usage=True,
trust_remote_code=True).eval()
processor = AutoProcessor.from_pretrained(path, trust_remote_code=True)
datasets = json.load(open("data/datasets.json", 'r'))
for data in datasets:
image_name = data["image"].split(".")[0]
imgp = os.path.join(data["image_path"], data["image"])
image = Image.open(imgp)
conversation = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": data["input"]},
],
}
]
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
inputs = processor(
text=[text_prompt], images=[image], padding=True, return_tensors="pt"
)
inputs = inputs.to(model.device)
if 'qwen3' in path.lower():
inputs_embeds = model.model.language_model.embed_tokens(inputs["input_ids"])
pixel_values = inputs["pixel_values"].type(model.dtype)
else:
inputs_embeds = model.model.embed_tokens(inputs["input_ids"])
pixel_values = inputs["pixel_values"].type(model.visual.get_dtype())
image_mask = inputs["input_ids"] == model.config.image_token_id
visual_output = model.visual(pixel_values, grid_thw=inputs["image_grid_thw"])
if isinstance(visual_output, tuple):
image_embeds = visual_output[0]
else:
image_embeds = visual_output
image_embeds = image_embeds.to(inputs_embeds.device)
inputs_embeds[image_mask] = image_embeds
print("inputs_embeds", inputs_embeds.shape)
os.makedirs("data/inputs_embeds/", exist_ok=True)
np.save("data/inputs_embeds/{}".format(image_name), inputs_embeds.to(dtype=torch.float16).cpu().detach().numpy())
with open('data/inputs.json', 'w') as json_file:
json_file.write('[\n')
first = True
for data in tqdm(datasets):
input_embed = np.load(os.path.join("data/inputs_embeds", data["image"].split(".")[0]+'.npy'))
target = data["target"]
input_dict = {
"input_embed": input_embed.tolist(),
"target": target
}
if not first:
json_file.write(',\n')
else:
first = False
json.dump(input_dict, json_file)
json_file.write('\n]')
print("Done")
运行此文件,输入
cd rknn-llm/examples/multimodal_model_demo
python data/make_input_embeds_qwen3.py --path /home/yl/qwen3/rknn-llm/Qwen3-VL-2B-Instruct
输出
inputs_embeds torch.Size([1, 311, 2048])
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:07<00:00, 2.60it/s]
Done
生成了data下面的inputs_embeds目录,存放目录中包含的是 多模态输入嵌入(Multimodal Input Embeddings) 的 .npy 文件。
此文件是专用于多模态输入,普通的语言大模型是不需要这一步的
2.导出RKLLM模型。
这一步会用到inputs_embeds目录下的文件来进行量化工作
cd rknn-llm/examples/multimodal_model_demo
python export/export_rkllm.py --path /home/yl/qwen3/rknn-llm/Qwen3-VL-2B-Instruct --target-platform rk3588 --num_npu_core 3 --quantized_dtype w8a8 --device cpu --savepath ./export/rkllm/qwen3-vl-llm_rk3588.rkllm
等待运行完毕
Building model: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 427/427 [00:09<00:00, 43.52it/s]
Generating train split: 20 examples [00:01, 12.68 examples/s]
Optimizing model: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 28/28 [12:37<00:00, 27.07s/it]
INFO: Setting token_id of eos to 151645
INFO: Setting add_bos_token to False
Converting model: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 311/311 [00:00<00:00, 2811268.41it/s]
INFO: Setting max_context_limit to 4096
INFO: Exporting the model, please wait ....
[=================================================>] 597/597 (100%)
INFO: Model has been saved to ./rkllm/qwen3-vl-2b-instruct_w8a8_rk3588.rkllm!
//转化成功的文件为
-rw-rw-r-- 1 yl yl 2.3G 11月 30 11:45 qwen3-vl-2b-instruct_w8a8_rk3588.rkllm
生成的 qwen3-vl-llm_rk3588.rkllm 文件只包含大语言模型(LLM)的部分(即处理 Embedding 并生成文本的 Transformer 层),不包含视觉编码器(Vision Encoder)的权重结构。
总结 模型转化
qwen3-vl-2b-instruct_w8a8_rk3588.rkllm 和 qwen3-vl_vision_rk3588.rknn 是同一个多模态大模型(Qwen3-VL)在 Rockchip 平台上部署时拆分出来的两个核心组件。它们就像人的“大脑”和“眼睛”,必须协同工作才能完成图文理解任务。
qwen3-vl_vision_rk3588.rknn (眼睛):
功能: 负责视觉感知。它接收原始图像,提取出计算机可以理解的高维特征向量。
本质: 这是一个基于 CNN 或 ViT 的视觉编码器。
运行: 在 NPU 上作为普通的神经网络模型运行。
qwen3-vl-2b-instruct_w8a8_rk3588.rkllm (大脑):
功能: 负责逻辑推理和文本生成。它接收文本提示和视觉特征,理解上下文,并生成回答。
本质: 这是一个基于 Transformer Decoder 的大语言模型(LLM)
运行: 在 NPU 上通过专门的 RKLLM 运行时库运行,支持 KV Cache 等加速技术。
它们是上下游关系
在实际推理过程中,数据是这样流动的:
-
输入: 用户提供一张图片 + 一个问题(例如“这张图里有什么?”)。
-
视觉处理 (RKNN):
图片 →→
qwen3-vl_vision_rk3588.rknn→→ 图像特征 (Image Embeddings) -
特征融合:
C++ 代码会将这些图像特征插入到用户问题的文本 Token 序列中(通常替换掉
<image>占位符)。 -
语言推理 (RKLLM):
(图像特征 + 文本 Token) →→
qwen3-vl-2b-instruct_w8a8_rk3588.rkllm→→ 生成的回答文本
项目中
在模型转换部分我们得到两个文件是:
1.qwen3-vl_vision_rk3588.rknn
2.qwen3-vl-2b-instruct_w8a8_rk3588.rkllm
这两个文件将用于模型部署
二、模型部署
上面的模型转化,是不需要使用到交叉编译链的,因此在任何服务器上都可以实现,只需要生成的最后那两个文件
您可以从rkllm_mode_zoo下载转换后的rkllm模型,获取代码:rkllm
下载rkllm model_z00/1.2.3/RK3588/Qwen3-VL-2B下的两个文件
qwen3-vl-2b-instruct_w8a8_rk3588.rkllm
qwen3-vl-2b_vision_rk3588.rknn
让我们开始在板子上部署吧!
RKLLM Runtime 库的使用
在所发布的的 RKLLM 工具链文件中, 包含 RKLLM Runtime 的全部文件:
1) librkllmrt.so: 适用于板端进行模型推理的 RKLLM Runtime 库;
后面我们会将此文件推送到开发板中,按照步骤操作即可,
更新NPU内核(可选)
如果你没有内核编译的经历,请使用原来的版本v0.9.2吧,博主这边是自己更新了测试的,具体行不行,试了就知道
确认板端的 NPU 内核是否为 v0.9.8 版本
root@ATK-DLRK3588:/# cat /sys/kernel/debug/rknpu/version
RKNPU driver: v0.9.2
若所查询的 NPU 内核版本低于 v0.9.8, 需要使用rknn-llm/rknpu-driver下的文件进行更新
具体更新步骤:
参考doc/Rockchip_RKLLM_SDK_CN_1.2.3.pdf 第 2.4 芯片内核更新
1) 下载压缩包 rknpu_driver_0.9.8_20241009.tar.bz2。
2) 解压该压缩包, 将其中的 rknpu 驱动代码覆盖到当前内核代码目录(kernel/drivers/rknpu)。
rknn-llm-release-v1.2.3/rknpu-driver/drivers/rknpu$ cp ./* /home/alientek/rk3588_linux_sdk/kernel/drivers/rknpu/ -r
3) 重新编译内核。
4) 将新编译的内核烧录到设备中。
进入目录下面
./build.sh kernel
实测编译内核的过程中, 出现错误日志
drivers/rknpu/rknpu_devfreq.c:237:18: error: 'rockchip_opp_set_low_length' undeclared here (not in a function); did you mean 'rockchip_pvtpll_add_length'?
237 | .set_soc_info = rockchip_opp_set_low_length,
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~
| rockchip_pvtpll_add_length
make[3]: *** [scripts/Makefile.build:273:drivers/rknpu/rknpu_devfreq.o] 错误 1
make[3]: *** 正在等待未完成的任务....
AR drivers/media/i2c/built-in.a
AR drivers/media/built-in.a
drivers/rknpu/rknpu_gem.c: In function 'rknpu_gem_mmap_pages':
drivers/rknpu/rknpu_gem.c:998:2: error: implicit declaration of function 'vm_flags_set' [-Werror=implicit-function-declaration]
998 | vm_flags_set(vma, VM_MIXEDMAP);
| ^~~~~~~~~~~~
drivers/rknpu/rknpu_gem.c: In function 'rknpu_gem_mmap_buffer':
drivers/rknpu/rknpu_gem.c:1148:2: error: implicit declaration of function 'vm_flags_clear' [-Werror=implicit-function-declaration]
1148 | vm_flags_clear(vma, VM_PFNMAP);
| ^~~~~~~~~~~~~~
cc1: all warnings being treated as errors
make[3]: *** [scripts/Makefile.build:273:drivers/rknpu/rknpu_gem.o] 错误 1
make[2]: *** [scripts/Makefile.build:516:drivers/rknpu] 错误 2
make[1]: *** [Makefile:1937:drivers] 错误 2
用户需要修改内核头文件 kernel/include/linux/mm.h, 文件末尾加入以下代码:
#endif /* __KERNEL__ */
static inline void vm_flags_set(struct vm_area_struct *vma,vm_flags_t flags)
{
vma->vm_flags |= flags;
}
static inline void vm_flags_clear(struct vm_area_struct *vma,vm_flags_t flags)
{
vma->vm_flags &= ~flags;
}
#endif /* _LINUX_MM_H */
同时修改
rknpu/rknpu_devfreq.c
235行加入一个函数,这个函数只有 RK3576 用到了它,应该直接写空函数,以免编译内核出错
static int rockchip_opp_set_low_length(struct device *dev, struct device_node *np,\
int bin, int process, int volt_sel)\
{\
return 0;\
}\
编译结果在out/firmware下面的boot.img
进行烧写,开发板进行烧写模式
使用rkflash.sh(进入loader)
adb reboot loader
或者使用/rkflash.sh
sudo ./rkflash.sh boot //下载镜像和设备树
sudo ./rkflash.sh rd //重启开发板
再次查看版本
cat /sys/kernel/debug/rknpu/version
输出
RKNPU driver: v0.9.8
更新完毕
编译程序文件
目的:生成一个程序来运行上面我们编译出来的两个文件,即Qwen3-VL的 眼睛和大脑
进入 deploy 目录,运行构建脚本:
交叉编译器:我下载了gcc-linaro-11.3.1-2022.06-x86_64_aarch64-linux-gnu.tar.xz,点击下载,下载后解压就能使用
buid-linux.sh,修改为自己的交叉编译器的路径,
set -e
rm -rf build
mkdir build && cd build
GCC_COMPILER=/home/alientek/software/gcc-linaro-11.3.1-2022.06-x86_64_aarch64-linux-gnu
cmake .. -DCMAKE_CXX_COMPILER=${GCC_COMPILER}/bin/aarch64-linux-gnu-g++ \
-DCMAKE_C_COMPILER=${GCC_COMPILER}/bin/aarch64-linux-gnu-gcc \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_SYSTEM_NAME=Linux \
-DCMAKE_SYSTEM_PROCESSOR=aarch64 \
make -j8
make install
./buid-linux.sh
[100%] Built target demo
[100%] Built target imgenc
[ 50%] Built target demo
[100%] Built target imgenc
Install the project...
-- Install configuration: "Release"
-- Installing: /home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/./imgenc
-- Set runtime path of "/home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/./imgenc" to ""
-- Installing: /home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/./demo
-- Set runtime path of "/home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/./demo" to ""
-- Installing: /home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/lib/librknnrt.so
-- Installing: /home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/lib/librkllmrt.so
-- Installing: /home/alientek/software/vllm/rknn-llm-release-v1.2.3/examples/multimodal_model_demo/deploy/install/demo_Linux_aarch64/./demo.jpg
可以看到已经在deploy/install/demo_Linux_aarch64目录下生成了运行程序所需要的全部文件
├── demo ->二进制可运行文件,我们主要使用他
├── demo.jpg
├── imgenc ->图像编码器(调用 RKNN
└── lib
├── librkllmrt.so
└── librknnrt.so
需在 src/main.cpp 中正确设置 param.img_start、param.img_end 等 token 占位符,这些是 Qwen2-VL 的特殊图像标记。如果Qwen3-VL 使用的特殊标记是否与 Qwen2-VL 一致。暂不需要修改,如果不一致,你需要查阅 Qwen3-VL 的 tokenizer_config.json 或相关文档,找到对应的 vision_start_token、vision_end_token 和 image_pad_token 的字符串表示,并在运行 demo 时通过命令行传入。
先不关注上面的部分
直接试试部署吧
将两个模型文件也发在这个目录下面,同时实测发现需要一个库文件libgomp.so.1,将交叉编译器里面的该库文件拷贝到lib过来
gcc-linaro-11.3.1-2022.06-x86_64_aarch64-linux-gnu$ find -name libgomp.so.1
./aarch64-linux-gnu/libc/lib/libgomp.so.1 <- 拷贝这个文件
./aarch64-linux-gnu/lib64/libgomp.so.1
目录如下:
.
├── demo
├── demo.jpg
├── imgenc
├── lib
│ ├── librkllmrt.so
│ └── librknnrt.so
│ └── libgomp.so.1
└── models
├── qwen3-vl-2b-instruct_w8a8_rk3588.rkllm
└── qwen3-vl_vision_rk3588.rknn
lib下面有所需要的库文件,将上面所有内容使用adb发送到开发板上
板端运行
adb push ./* /userdata/vllm/Qwen3-VL
cd /userdata/vllm/Qwen3-VL
# export lib path
export LD_LIBRARY_PATH=./lib
# soft link models dir
export RKLLM_LOG_LEVEL=1
echo "1 4 1 7" > /proc/sys/kernel/printk
运行编码器
# run imgenc
./imgenc models/qwen3-vl_vision_rk3588.rknn demo.jpg 3
可以传输其他的jpg图片上去
./imgenc models/qwen3-vl_vision_rk3588.rknn cat.jpg 3
./imgenc models/qwen3-vl_vision_rk3588.rknn dinner.jpg 3
输出过程:
===the core num is 3===
model input num: 1, output num: 1
input tensors:
index=0, name=pixel, n_dims=4, dims=[1, 224, 224, 3], n_elems=150528, size=301056, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
output tensors:
index=0, name=4745, n_dims=2, dims=[49, 2048, 0, 0], n_elems=100352, size=200704, fmt=UNDEFINED, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
model input height=224, width=224, channel=3
main: Model loaded in 946.25 ms
main: Encoder the image cost 536.05 ms
结果:
img_vec.bin即图的编码结果,能被计算机识别的内容!
推理
运行语言大模型
# run demo(Multimodal Example)
./demo demo.jpg models/qwen3-vl_vision_rk3588.rknn models/qwen3-vl-2b-instruct_w8a8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
./demo cat.jpg models/qwen3-vl_vision_rk3588.rknn models/qwen3-vl-2b-instruct_w8a8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
./demo dinner.jpg models/qwen3-vl_vision_rk3588.rknn models/qwen3-vl-2b-instruct_w8a8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
./demo get.jpg models/qwen3-vl_vision_rk3588.rknn models/qwen3-vl-2b-instruct_w8a8_rk3588.rkllm 2048 4096 3 "<|vision_start|>" "<|vision_end|>" "<|image_pad|>"
<image>如果检查到偷东西的嫌疑,需要触发警报么?
<image>是否检查到人影?
目前demo只处理了一张图片,可以修改代码支持多图片的输出!
可以再开一个窗口查看NPU利用率
watch -n 2 cat /sys/kernel/debug/rknpu/load
输出:
Every 0.5s: cat /sys/kernel/debug/rkn... ATK-DLRK3588: Sun Nov 30 19:11:14 2025
NPU load: Core0: 49%, Core1: 58%, Core2: 62%,
最后查看效果吧

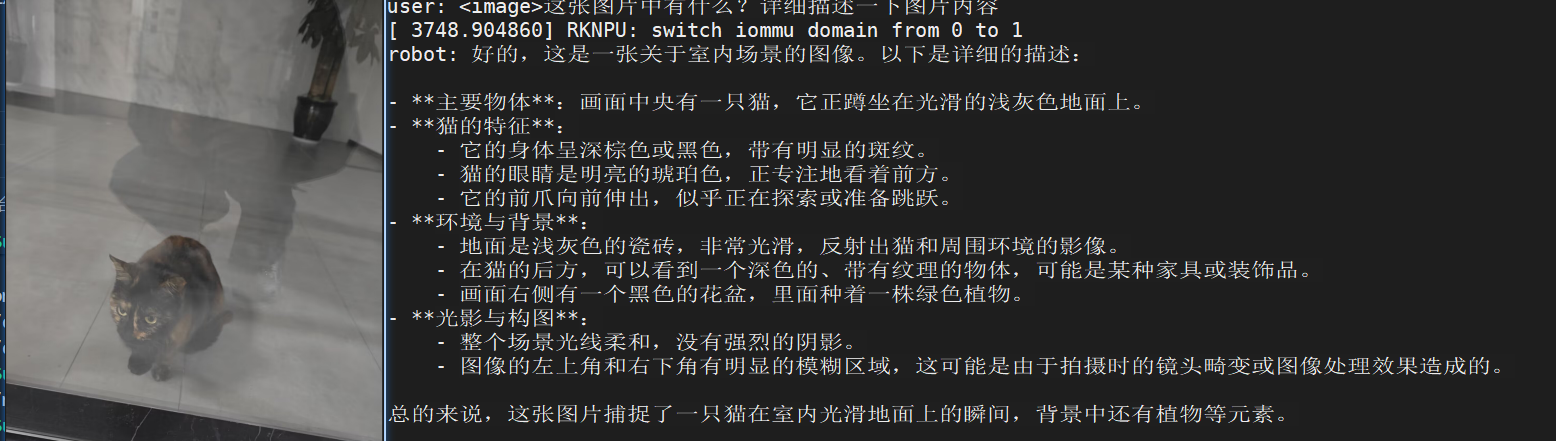
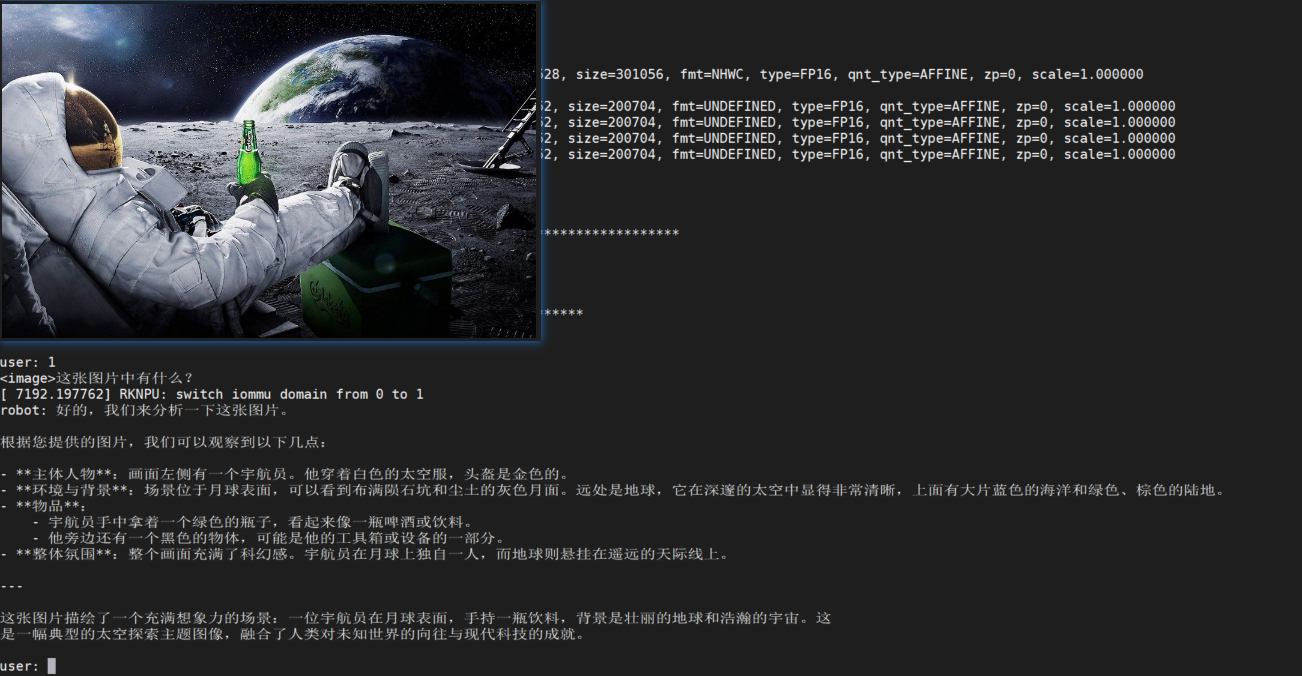

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)