RAG和Embedding技术解析:从理论到实践的探索
文章目录
一、RAG原理介绍
1、RAG三大核心:知识库+检索+大语言模型(LLM)
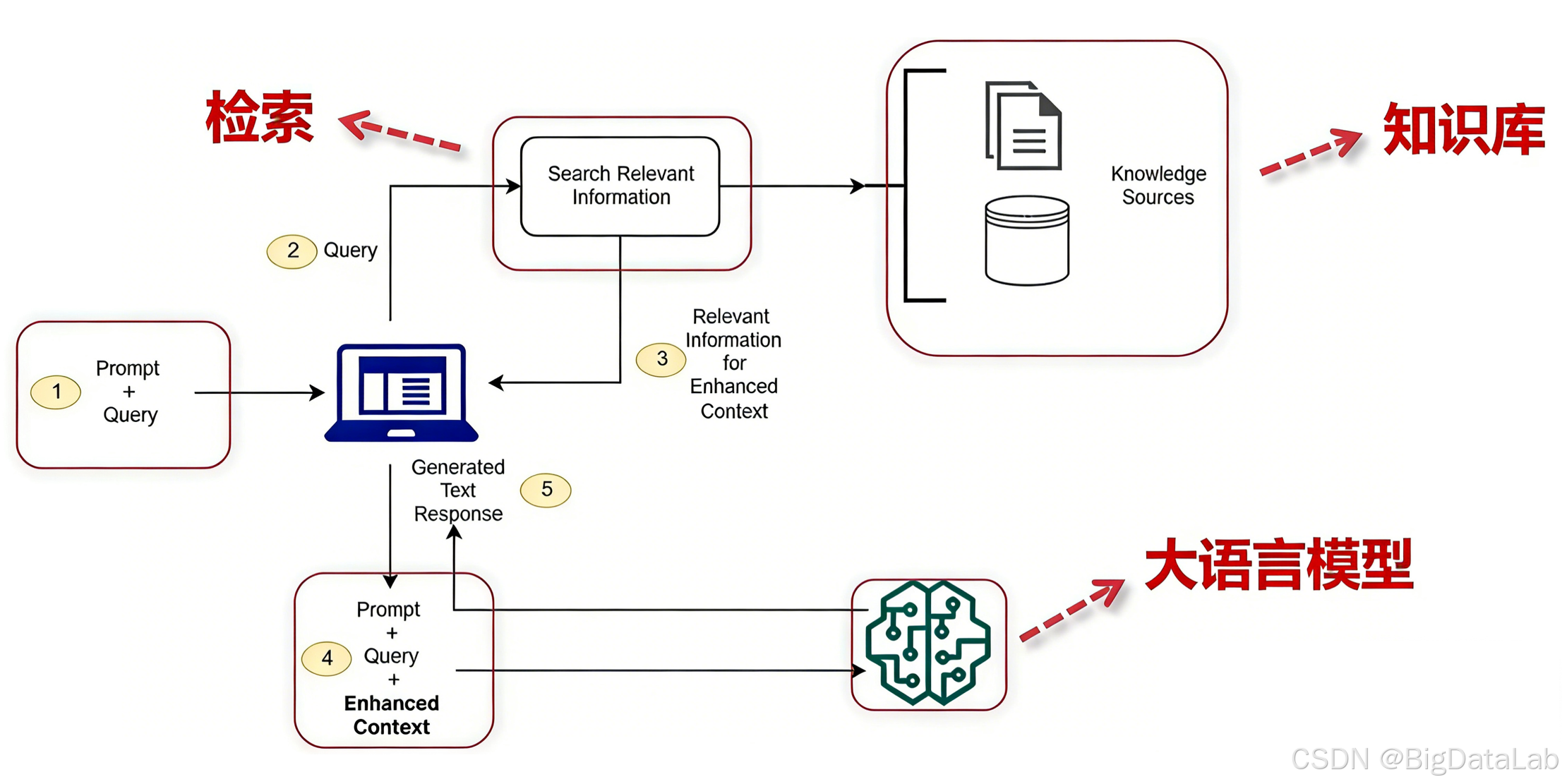
无RAG的LLM:用户查询 -> 大模型分析
有RAG的LLM:用户查询 -> 问题向量化 -> (已向量化的)知识库检索(计算相似度、排序等)-> 大模型分析(用户查询+检索文本)
中间多了向量化和知识库检索的过程,那为什么要增加这个步骤呢,就要看看LLM本身有哪些限制。
2、LLM的缺陷&RAG的作用:
1、数据非实时,他所学到的是截止到模型训练完成那一刻的知识,不具备知识更新能力
RAG:可以检索最新的信息,快速生成相关文本,避免重新训练带来的时间成本和算力成本
2、不具备私有领域的知识
RAG:可以通过配置私有知识库,同时避免了隐私数据进行模型训练的安全风险
3、存在幻觉,看似合理实际上是错误的答案
RAG:通过检索信息,提高生成文本的准确性,降低幻觉,可以追溯来源,提高可解释性
4、长文本推理限制,上下文能力存在上限,且推理成本高,也容易出现记忆混乱
RAG:解决了上下文token量的限制,信息可追溯,推理消耗的token大大降低
3、RAG三大核心如何理解?
① 知识库:存数据的容器,把原始数据变成 “能快速检索、语义完整” 的形式,这个过程需要“清洗→分块→向量化→建索引”这一系列处理,存储方式也各式各样,比如前面我们通过Dify搭建的知识库,他是通过PostgreSQL配合pgvector插件来实现向量检索的能力,当然,纯向量数据库是目前主流的载体,例如Chroma、Milvus等等。这块内容我们下次细讲。
②大模型:底层逻辑就是通过计算所有下一个token的概率,再根据一些规则去筛选,主要依赖这三个参数就可以控制大模型输出的效果:
-
**温度:**temperature=1时代表保持原状;temperature<1时,概率会被放大,概率高的token会高的更明显,相反剩余的概率就会更低;temperature>1时,温度越大,概率值会越平均。
-
**Top-K:**正整数,表示在模型计算在top k的范围里随机取值作为输出,K值越大,那么随机性就越高,K值越小,那相对越稳健。
-
**Top-p:**百分比,表示计算得出的概率在p值以上的范围内去随机选择,p值越大,结果越稳定,p值越小,结果越随机,相对Top-K是一个绝对范围,而Top-p是个相对范围。
③检索:从知识库中找到与问题最相关的信息,包括“查询->召回->排序->过滤”,下面就重点讲解下向量检索的过程。
二、RAG和Embedding的关系
Embedding 是 RAG 的 底层技术底座:
- Embedding(向量嵌入):把文本变成数字向量,让机器能 “算相似度”。
- RAG(检索增强生成):用相似度检索从知识库查询相关知识。
三、Embedding原理介绍
Embedding是将数据对象映射到固定大小的连续一维数字数组的技术。向量空间通常具有几百到几千的维度,每个维度代表某个语义特征或属性。
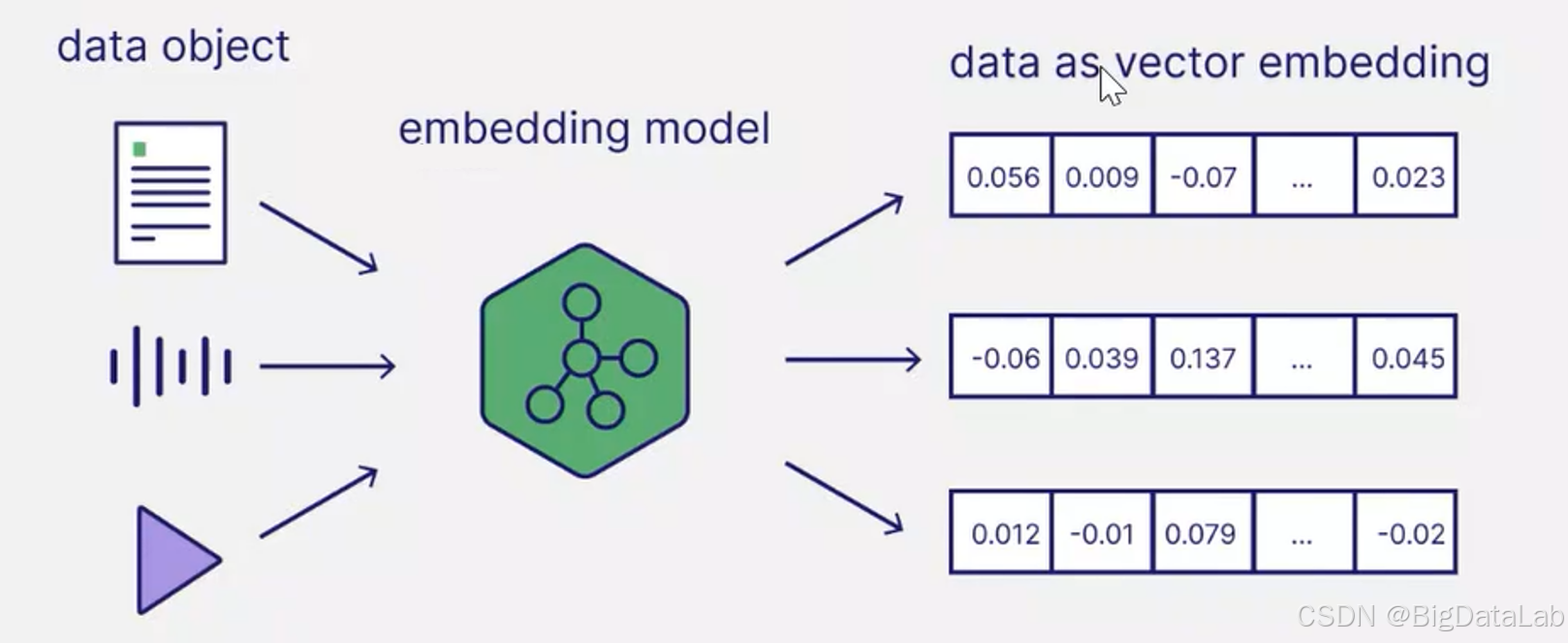
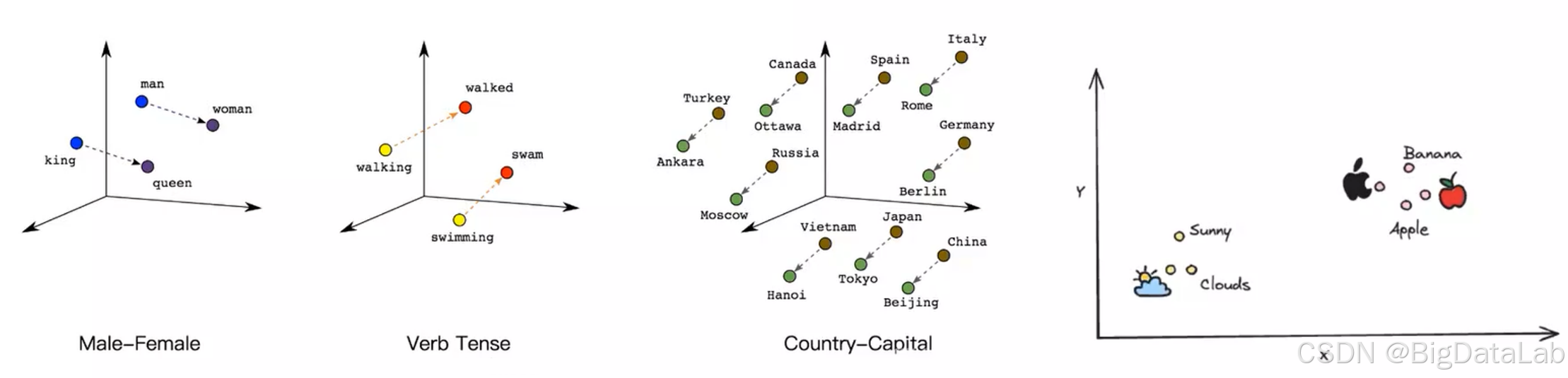
在embedding向量空间中,语义相似的实体在向量空间中映射得更近,而不相似的实体映射得更远。
Embedding的工作流程:
① 离线构建知识库(必须用 Embedding)
- 文档 → 分块(chunk)
- 分块文本 → Embedding 模型 → 向量
- 向量存入向量库(Chroma/Milvus/FAISS)
👉 这里 Embedding 是 “编码器”
② 用户提问(必须用 Embedding)
- 用户问题 → Embedding 模型 → 问题向量
- 向量库做相似度检索 → 找出最相关的文档块
👉 这里 Embedding 是 “检索钥匙”
③ 大模型生成答案
把问题 + 检索到的文本 → 丢给 LLM 生成回答
👉 RAG 是整套流程,Embedding 是流程里最关键一步
四、实战演练
transformers:Transformer 底层库,需手动实现分词等功能,但是可定制化能力强
sentence_transformers:开箱即用,新手友好;专门用于句子、文本嵌入
1、前置依赖
Embedding模型库:下载地址:https://www.modelscope.cn/models/AI-ModelScope/gte-large-zh
python依赖包:transformers,sentence_transformers,pytorch
建议python版本3.9-3.11,我的python版本3.11,更高版本存在不兼容情况,创建python虚拟环境进行试验
2、transformers方式
# 导入所需库:
# AutoModel/AutoTokenizer:HuggingFace transformers 核心类,用于加载预训练模型和分词器
from transformers import AutoModel, AutoTokenizer
# cos_sim:sentence_transformers 提供的余弦相似度计算函数(更简洁)
from sentence_transformers.util import cos_sim
# F:PyTorch 功能模块,用于向量归一化等操作
import torch.nn.functional as F
# ===================== 1. 定义实验文本 =====================
# 优化后的实验文本:包含强相关/弱相关/无关梯度,验证语义嵌入效果
input_texts = [
"中国的首都是哪里?", # 基准句(用于对比相似度)
"中华人民共和国的首都位于哪里", # 强相关(同义改写)
"请问北京是不是中国的首都", # 强相关(反问形式)
"中国的首都有什么特色美食", # 弱相关(同主体不同维度)
"东京是日本的首都", # 弱干扰(同句式不同内容)
"今天天气怎么样", # 完全无关(跨领域)
"北京是中国的首都"
]
# ===================== 2. 加载模型和分词器 =====================
# 模型本地路径(Windows 路径建议用 r 前缀避免转义,或用 / 代替 \)
model_path = r"D:\Model\gte-large-zh"
# 加载预训练模型:指定 cpu 设备(无 GPU 时使用)
model = AutoModel.from_pretrained(model_path).to("cpu")
# 加载对应分词器:与模型权重匹配,用于文本转 token
tokenizer = AutoTokenizer.from_pretrained(model_path)
# ===================== 3. 文本分词处理 =====================
# 对输入文本批量分词:
# max_length=30:限制每个文本最多 30 个 token(截断过长文本)
# padding=True:按批次内最长文本补齐(用 [PAD] token 填充)
# truncation=True:超过 max_length 时截断
# return_tensors="pt":返回 PyTorch 张量格式
batch_tokens = tokenizer(
input_texts,
max_length=30,
padding=True,
truncation=True,
return_tensors="pt"
)
# ===================== 4. 分词结果解析(调试用) =====================
token = tokenizer.convert_ids_to_tokens(batch_tokens.input_ids[0]) # id 转 token 字符串
print("第一句话的分词结果:", token)
# 获取第一句话的 token id(模型可识别的数字编码)
token_id = batch_tokens.input_ids[0]
print("第一句话的 token id:", token_id)
# ===================== 5. 模型推理生成嵌入 =====================
# 将分词后的张量传入模型,获取模型输出(包含隐藏层状态、池化输出等)
# **batch_tokens:自动解包 input_ids/attention_mask 等参数传入模型
outputs = model(**batch_tokens)
# ===================== 6. 生成句子嵌入向量 =====================
# 提取 CLS token 作为句子嵌入:
# outputs.last_hidden_state[:,0]:取每个句子的第一个 token(CLS token)的向量
# F.normalize(..., p=2, dim=1):L2 归一化(必须!否则相似度计算失真)
embeddings = F.normalize(outputs.last_hidden_state[:, 0], p=2, dim=1)
# ===================== 7. 计算并输出相似度 =====================
# 遍历所有文本,计算与基准句(第一句)的余弦相似度
print("=== 文本语义相似度对比结果(与基准句:{})===".format(input_texts[0]))
for i in range(len(input_texts)):
# cos_sim:计算两个向量的余弦相似度(返回 tensor 类型)
similarity = cos_sim(embeddings[0], embeddings[i])
# 输出结果:保留 4 位小数,转换为浮点数更易读
print(f"{input_texts[i]} → 相似度:{similarity.item():.4f}")
返回结果如下:
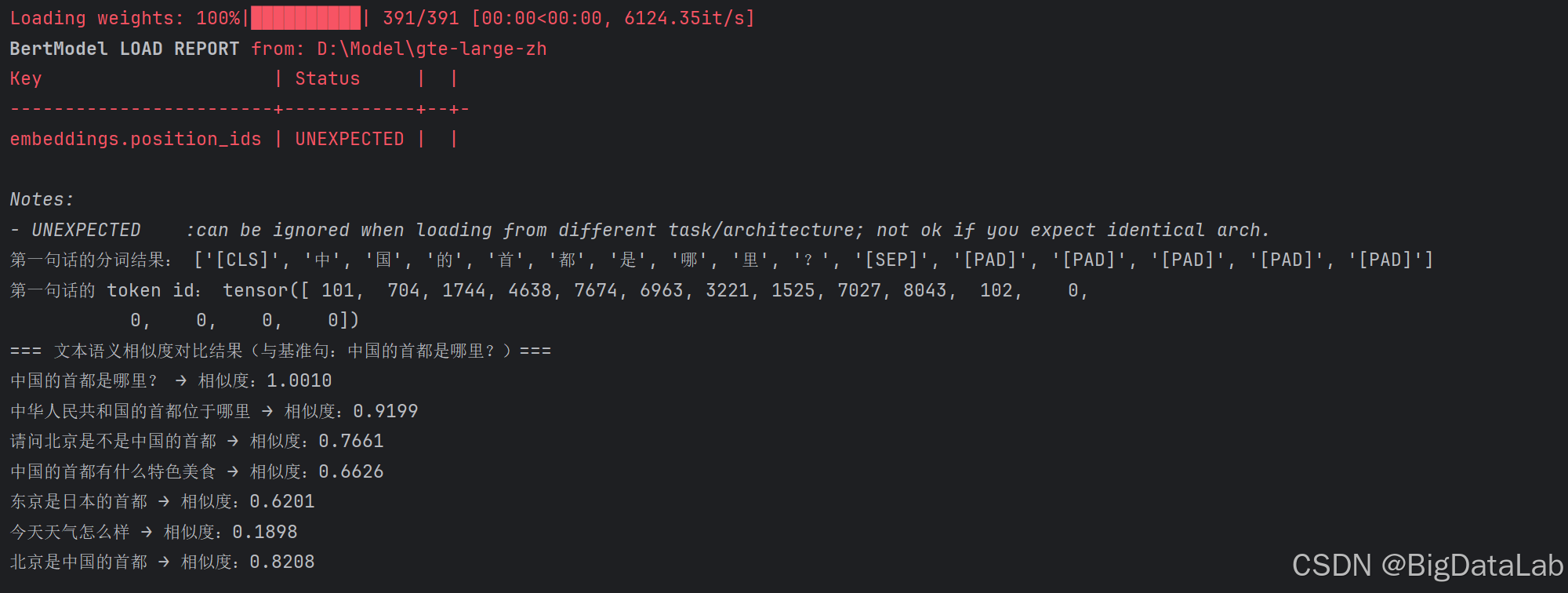
CLS:分类token,预留汇总整句话含义的位置,SEP:句子结束标识,PAD:根据最长token数补位标识。
这些就组成了固定长度的向量,以此来进行向量相似度的计算,可以根据相似度对比结果看出来,含义越一致的语句相似度越接近于1,答案的相似度也比较高,而干扰项的相似度整体偏低,可以结合Top-K来选取哪些内容作为上下文传给下游。
3、sentence_transformers方式
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
input_texts = [
"中国的首都是哪里?", # 基准句(用于对比相似度)
"中华人民共和国的首都位于哪里", # 强相关(同义改写)
"请问北京是不是中国的首都", # 强相关(反问形式)
"中国的首都有什么特色美食", # 弱相关(同主体不同维度)
"东京是日本的首都", # 弱干扰(同句式不同内容)
"今天天气怎么样", # 完全无关(跨领域)
"北京是中国的首都"
]
model_path = "D:\Model\gte-large-zh"
model = SentenceTransformer(model_path)
embeddings = model.encode(input_texts)
for i in range(len(input_texts)):
similarity = cos_sim(embeddings[0], embeddings[i])
print(f"{input_texts[i]} → 相似度:{similarity.item():.4f}")
返回结果如下:
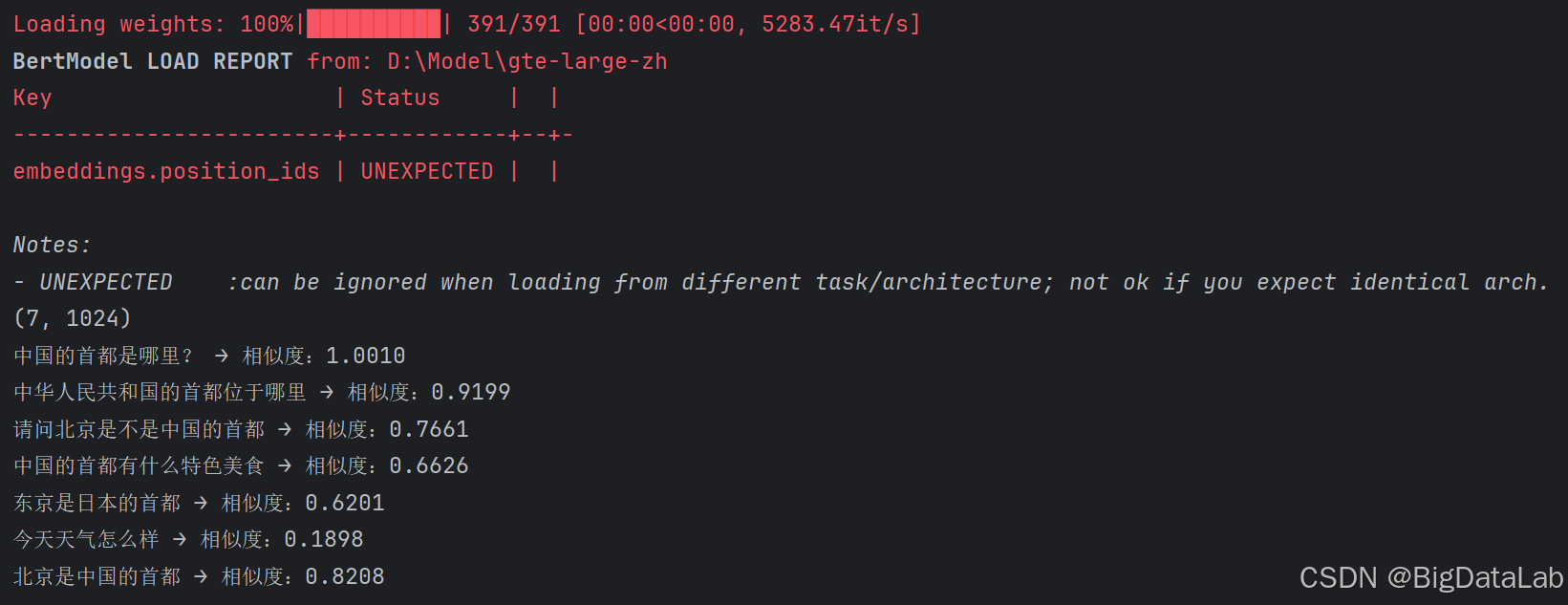
这个代码就简洁多了,sentence_transformers除了对功能的封装外,还可以通过真实数据再进行微调,效果更好。
————————THE END————————
今天的内容就分享到这里。【原文链接】
有问题欢迎留言交流,也可以加我微信深入探讨(公众号:BigDataLab)。
关注我,不错过每一篇干货,下期继续为你带来更实用的内容!
(如果需要python、大数据、大模型相关学习资料,欢迎公众号“BigDataLab”留言“资料”)
————————精彩推荐————————

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)