YOLOv8【第十三章:模型压缩与极致优化篇·第12节】混合精度量化:如何平衡 FP16 与 INT8 层以保持精度!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》 专栏。该专栏系统复现并梳理全网各类 YOLOv8 改进与实战案例(当前已覆盖分类 / 检测 / 分割 / 追踪 / 关键点 / OBB 检测等方向),坚持持续更新 + 深度解析,质量分长期稳定在 97 分以上,可视为当前市面上 覆盖较全、更新较快、实战导向极强 的 YOLO 改进系列内容之一。
部分章节也会结合国内外前沿论文与 AIGC 等大模型技术,对主流改进方案进行重构与再设计,内容更偏实战与可落地,适合有工程需求的同学深入学习与对标优化。
✨ 特惠福利:当前限时活动一折秒杀,一次订阅,终身有效,后续所有更新章节全部免费解锁,👉 点此查看详情
🎯 本文定位:计算机视觉 × 模型压缩与极致优化系列
📅 更新时间:2026年
🏷️ 难度等级:⭐⭐⭐⭐⭐(高级进阶)
🔧 技术栈:Python 3.9+ · PyTorch · YOLOv8 · ByteTrack · OpenCV · NumPy
全文目录:
📖 上期回顾
上一节《YOLOv8【第十三章:模型压缩与极致优化篇·第11节】训练后量化(PTQ):校准数据集的选择与精度恢复技巧!》内容中,我们深入探讨了**训练后量化(Post-Training Quantization,PTQ)**的核心原理与工程实践。PTQ 是一种无需重新训练模型、直接对已训练好的浮点模型进行量化的技术,其核心流程如下:
我们重点讲解了以下几个关键知识点:
1. 校准数据集的重要性
PTQ 的精度上限很大程度上取决于校准数据集的质量。我们分析了三种主流校准策略:MinMax 校准、KL 散度校准和 Percentile 校准,并通过实验对比了它们在不同任务场景下的表现差异。结论是:对于目标检测任务,KL 散度校准在大多数情况下能取得最佳的精度-速度平衡。
2. 逐层量化误差分析
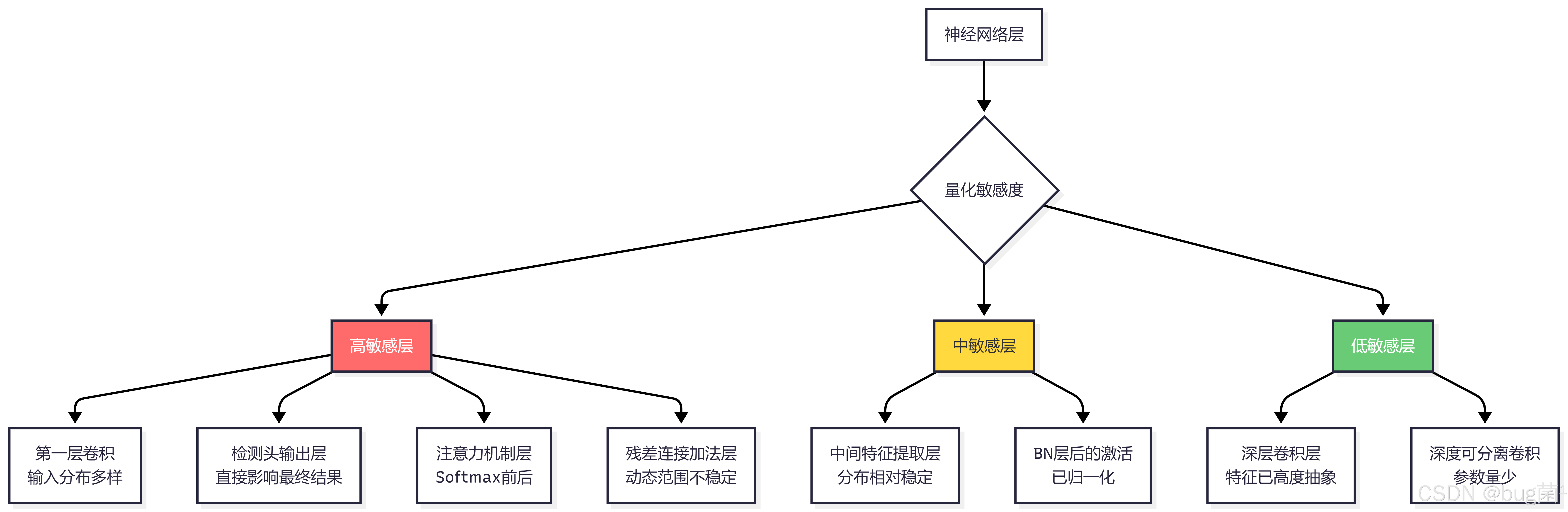
我们引入了"量化敏感度分析"的概念,通过逐层替换量化算子并观察精度变化,识别出模型中对量化最敏感的层(通常是第一层卷积、最后一层分类头以及残差连接附近的层)。
3. 精度恢复技巧
- 偏置校正(Bias Correction):补偿量化引入的系统性偏差
- AdaRound 自适应舍入:用学习的方式替代简单的四舍五入
- ADAROUND + 通道均衡(CLE)的组合策略
4. YOLOv8 PTQ 实战
我们完整演示了从 FP32 模型到 INT8 TensorRT 引擎的全流程,包括 ONNX 导出、校准数据集构建、TensorRT 引擎构建与精度验证。
然而,PTQ 存在一个根本性的局限:当模型整体被强制量化为 INT8 时,某些对精度极度敏感的层会产生不可接受的精度损失。这正是本节要解决的核心问题——混合精度量化。
🎯 本节目标与学习路线
学习路线图:
FP32 全精度 → 理解精度损失来源 → 敏感度分析 → 混合精度策略 → 工程实现 → YOLOv8 实战
本节你将学到:
- 混合精度量化的数学原理与动机
- 如何科学地进行层级敏感度分析
- FP16 与 INT8 的混合分配策略
- 基于 TensorRT、PyTorch 的混合精度量化实现
- YOLOv8 混合精度量化完整实战案例
- 精度与速度的 Pareto 最优权衡方法
一、为什么需要混合精度量化?
1.1 全 INT8 量化的困境
在理想情况下,我们希望将整个神经网络都量化为 INT8,因为 INT8 相比 FP32 有以下优势:
- 内存占用:减少 75%(4字节 → 1字节)
- 计算吞吐:INT8 矩阵乘法在现代硬件上比 FP32 快 2-4 倍
- 功耗:INT8 运算功耗显著低于浮点运算
然而,现实并不总是如此美好。让我们先从数学角度理解量化误差的来源。
1.2 量化误差的数学本质
对于一个浮点数 x ∈ [ x m i n , x m a x ] x \in [x_{min}, x_{max}] x∈[xmin,xmax],线性量化的过程可以表示为:
x q = clamp ( round ( x s ) + z , 0 , 2 b − 1 ) x_q = \text{clamp}\left(\text{round}\left(\frac{x}{s}\right) + z, 0, 2^b - 1\right) xq=clamp(round(sx)+z,0,2b−1)
其中:
- s s s 是缩放因子(scale): s = x m a x − x m i n 2 b − 1 s = \frac{x_{max} - x_{min}}{2^b - 1} s=2b−1xmax−xmin
- z z z 是零点(zero point)
- b b b 是量化位宽(INT8 时 b = 8 b=8 b=8)
反量化(dequantization)过程:
x ^ = s ⋅ ( x q − z ) \hat{x} = s \cdot (x_q - z) x^=s⋅(xq−z)
量化误差为:
ϵ = x − x ^ = x − s ⋅ ( round ( x s ) + z − z ) \epsilon = x - \hat{x} = x - s \cdot \left(\text{round}\left(\frac{x}{s}\right) + z - z\right) ϵ=x−x^=x−s⋅(round(sx)+z−z)
对于 INT8,量化步长 s = x m a x − x m i n 255 s = \frac{x_{max} - x_{min}}{255} s=255xmax−xmin,最大量化误差为 s 2 \frac{s}{2} 2s。
关键洞察:当张量的动态范围( x m a x − x m i n x_{max} - x_{min} xmax−xmin)很大时,量化步长 s s s 也会很大,导致量化误差显著增大。
1.3 哪些层对量化最敏感?
1.4 混合精度量化的核心思想
混合精度量化(Mixed-Precision Quantization,MPQ)的核心思想非常直观:不同的层使用不同的量化精度。

这样做的好处是:
- 敏感层保持 FP16 精度,避免精度损失
- 不敏感层使用 INT8,获得速度和内存收益
- 整体上在精度和性能之间取得最优平衡
二、混合精度量化的理论基础
2.1 量化噪声传播模型
理解混合精度量化,需要先理解量化噪声是如何在网络中传播的。
设第 l l l 层的输出为 y ( l ) y^{(l)} y(l),量化后的输出为 y ^ ( l ) \hat{y}^{(l)} y^(l),量化噪声为 δ ( l ) = y ( l ) − y ^ ( l ) \delta^{(l)} = y^{(l)} - \hat{y}^{(l)} δ(l)=y(l)−y^(l)。
对于深度神经网络,最终输出的量化误差可以近似表示为:
δ o u t p u t ≈ ∑ l = 1 L ∂ L ∂ y ( l ) ⋅ δ ( l ) \delta_{output} \approx \sum_{l=1}^{L} \frac{\partial \mathcal{L}}{\partial y^{(l)}} \cdot \delta^{(l)} δoutput≈l=1∑L∂y(l)∂L⋅δ(l)
这个公式告诉我们:梯度越大的层,其量化噪声对最终输出的影响越大。这正是敏感度分析的理论依据。
2.2 Hessian 矩阵与量化敏感度
更精确的敏感度度量来自于二阶泰勒展开。对于损失函数 L \mathcal{L} L,当第 l l l 层引入量化扰动 δ ( l ) \delta^{(l)} δ(l) 时,损失变化为:
Δ L ( l ) ≈ 1 2 ( δ ( l ) ) T H ( l ) δ ( l ) \Delta \mathcal{L}^{(l)} \approx \frac{1}{2} (\delta^{(l)})^T H^{(l)} \delta^{(l)} ΔL(l)≈21(δ(l))TH(l)δ(l)
其中 H ( l ) H^{(l)} H(l) 是损失函数关于第 l l l 层权重的 Hessian 矩阵。
层敏感度分数定义为:
S ( l ) = 1 N ∑ i = 1 N ∣ ∂ 2 L ∂ ( w ( l ) ) 2 ∣ F S^{(l)} = \frac{1}{N} \sum_{i=1}^{N} \left| \frac{\partial^2 \mathcal{L}}{\partial (w^{(l)})^2} \right|_F S(l)=N1i=1∑N ∂(w(l))2∂2L F
敏感度分数越高,该层越需要保持高精度(FP16 或 FP32)。
2.3 混合精度分配的优化问题
混合精度量化本质上是一个约束优化问题:
min b L ( b ) = ∑ l = 1 L S ( l ) ⋅ 1 [ b l = INT8 ] \min_{\mathbf{b}} \quad \mathcal{L}(\mathbf{b}) = \sum_{l=1}^{L} S^{(l)} \cdot \mathbb{1}[b_l = \text{INT8}] bminL(b)=l=1∑LS(l)⋅1[bl=INT8]
s.t. Memory ( b ) ≤ M t a r g e t , b l ∈ INT8 , FP16 \text{s.t.} \quad \text{Memory}(\mathbf{b}) \leq M_{target}, \quad b_l \in {\text{INT8}, \text{FP16}} s.t.Memory(b)≤Mtarget,bl∈INT8,FP16
其中 b = [ b 1 , b 2 , . . . , b L ] \mathbf{b} = [b_1, b_2, ..., b_L] b=[b1,b2,...,bL] 是每层的精度分配向量, M t a r g e t M_{target} Mtarget 是目标内存约束。
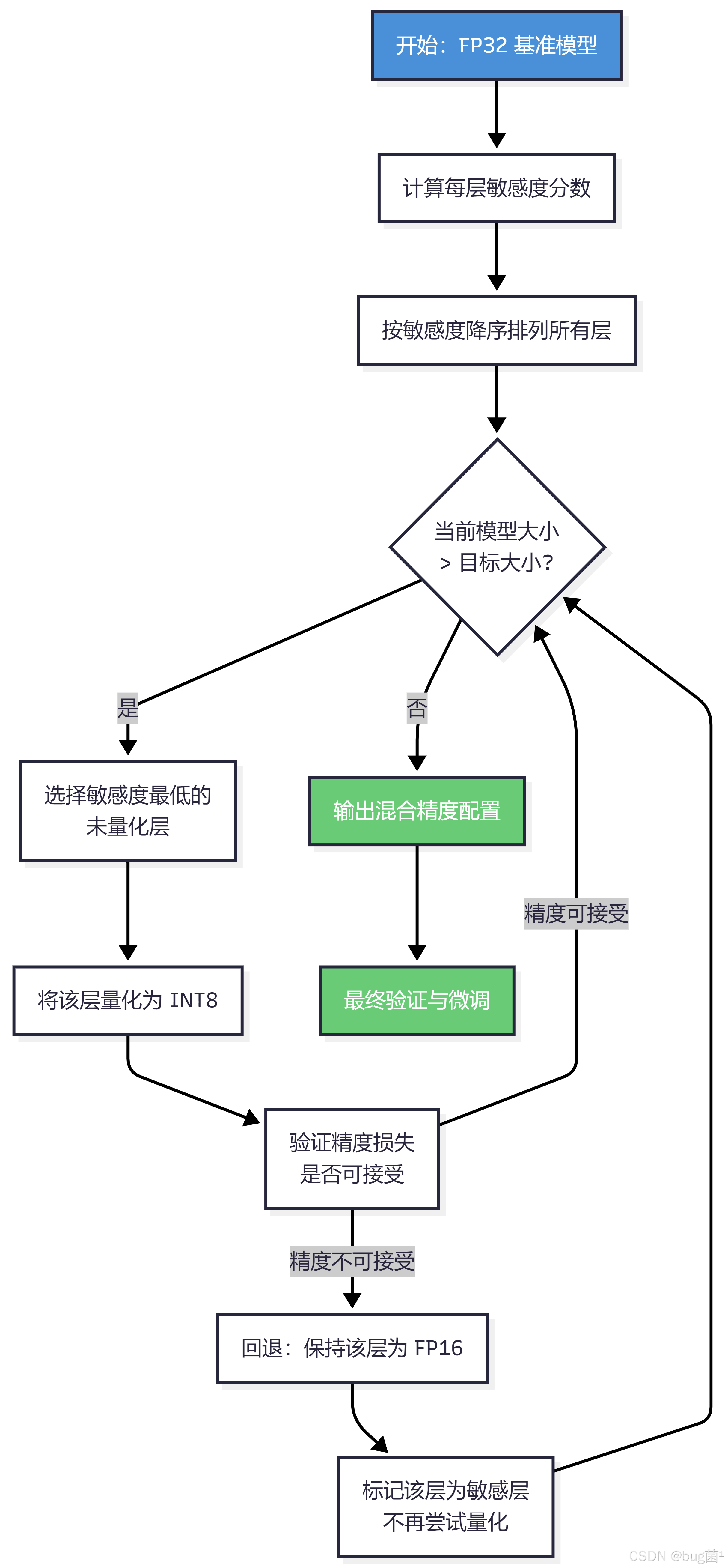
这是一个 NP-hard 的组合优化问题,实践中通常用以下方法近似求解:
- 贪心算法:按敏感度排序,逐层决定精度
- 强化学习(HAQ 方法)
- 进化算法
- 基于梯度的方法(DNAS)
三、FP16 与 INT8 的特性对比
3.1 数值表示范围对比
在深入实践之前,我们需要清楚地理解 FP16 和 INT8 的数值特性。
| 特性 | FP32 | FP16 | INT8 |
|---|---|---|---|
| 位宽 | 32 bit | 16 bit | 8 bit |
| 表示范围 | ±3.4×10³⁸ | ±65504 | -128 ~ 127 |
| 精度(有效位) | 约7位十进制 | 约3位十进制 | 精确整数 |
| 内存占用 | 4 字节 | 2 字节 | 1 字节 |
| 计算速度(相对FP32) | 1× | 2× | 4-8× |
| 量化误差 | 基准 | 小 | 较大 |
| 硬件支持 | 全面 | 广泛 | 需要特定硬件 |
3.2 FP16 的优势与局限
FP16(半精度浮点)的指数位为 5 位,尾数位为 10 位。相比 FP32,它:
优势:
- 内存减半,带宽需求降低
- 在支持 Tensor Core 的 GPU(如 V100、A100、RTX 系列)上计算速度翻倍
- 精度损失极小,大多数情况下与 FP32 精度相当
- 无需校准数据集,直接转换
局限:
- 动态范围有限(最大 65504),容易溢出
- 对于梯度计算,可能出现梯度下溢(underflow)
- 不是所有硬件都支持 FP16 加速
3.3 INT8 的优势与局限
INT8 是整数量化,需要通过 scale 和 zero_point 将浮点数映射到 [-128, 127] 范围。
优势:
- 内存占用仅为 FP32 的 1/4
- 在 NPU、DSP、移动端 SoC 上有极大的速度优势
- 功耗显著降低,适合边缘部署
局限:
- 需要校准数据集确定量化参数
- 对动态范围大的层精度损失明显
- 需要量化感知训练(QAT)才能恢复精度
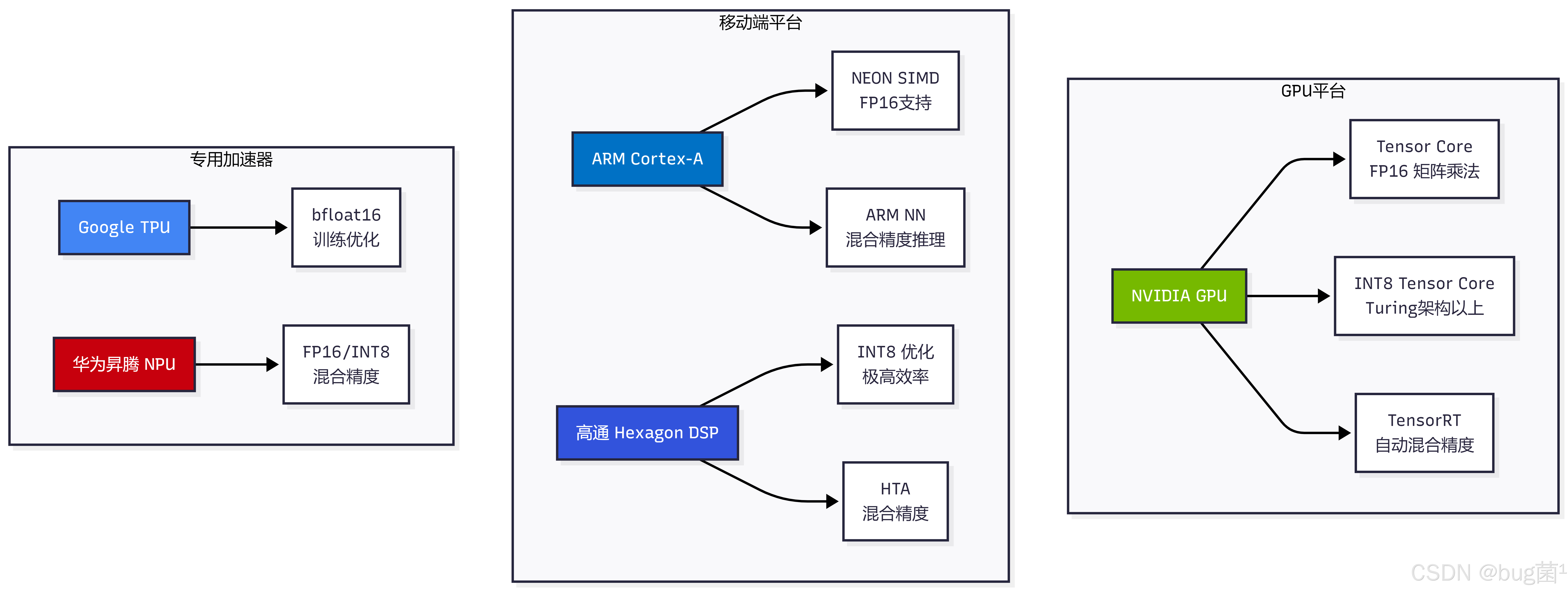
3.4 混合精度的硬件支持
四、敏感度分析:科学决定哪些层用 FP16
4.1 基于输出误差的敏感度分析
最直观的敏感度分析方法是:逐层将该层量化为 INT8,观察模型输出的变化。
import torch
import torch.nn as nn
import numpy as np
from copy import deepcopy
from typing import Dict, List, Tuple
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'DejaVu Sans'
# ============================================================
# 工具函数:计算张量的信噪比(SNR)
# SNR 越高,说明量化误差越小,该层越不敏感
# ============================================================
def compute_snr(original: torch.Tensor, quantized: torch.Tensor) -> float:
"""
计算信噪比(Signal-to-Noise Ratio)
SNR = 10 * log10(signal_power / noise_power)
Args:
original: 原始浮点张量
quantized: 量化后的张量
Returns:
SNR 值(dB),越大越好
"""
signal_power = torch.mean(original ** 2)
noise_power = torch.mean((original - quantized) ** 2)
if noise_power == 0:
return float('inf')
snr = 10 * torch.log10(signal_power / noise_power)
return snr.item()
# ============================================================
# INT8 对称量化函数
# 使用 per-tensor 对称量化模拟 INT8 量化效果
# ============================================================
def fake_quantize_int8(tensor: torch.Tensor, per_channel: bool = False) -> torch.Tensor:
"""
模拟 INT8 对称量化(fake quantization)
量化过程:
1. 计算 scale = max(|x|) / 127
2. 量化:x_q = round(x / scale).clamp(-128, 127)
3. 反量化:x_hat = x_q * scale
Args:
tensor: 输入浮点张量
per_channel: 是否使用逐通道量化(对权重更精确)
Returns:
模拟量化后的张量(仍为浮点,但精度已降低)
"""
if per_channel and tensor.dim() >= 2:
# 逐通道量化:对每个输出通道单独计算 scale
# 这对卷积权重更精确
shape = [-1] + [1] * (tensor.dim() - 1)
max_val = tensor.abs().view(tensor.size(0), -1).max(dim=1)[0]
scale = (max_val / 127.0).view(shape)
scale = torch.clamp(scale, min=1e-8) # 防止除零
else:
# 逐张量量化:整个张量共享一个 scale
max_val = tensor.abs().max()
scale = max_val / 127.0
scale = torch.clamp(scale, min=1e-8)
# 量化 → 反量化(fake quantization)
quantized = torch.round(tensor / scale).clamp(-128, 127) * scale
return quantized
# ============================================================
# 核心类:层级敏感度分析器
# ============================================================
class LayerSensitivityAnalyzer:
"""
逐层量化敏感度分析器
工作原理:
1. 以 FP32 模型为基准,记录每层的输出
2. 逐层将该层量化为 INT8,其余层保持 FP32
3. 计算量化前后输出的 SNR 作为敏感度指标
4. SNR 越低,说明该层对量化越敏感
"""
def __init__(self, model: nn.Module, device: str = 'cpu'):
self.model = model.eval()
self.device = device
self.layer_outputs = {} # 存储每层的原始输出
self.sensitivity_scores = {} # 存储每层的敏感度分数
self.hooks = [] # 存储 hook 句柄,用于清理
def _register_output_hooks(self, layer_names: List[str]):
"""注册前向传播 hook,捕获指定层的输出"""
self.layer_outputs.clear()
def make_hook(name):
def hook(module, input, output):
# 将输出从计算图中分离,避免内存泄漏
self.layer_outputs[name] = output.detach().clone()
return hook
# 清理旧的 hooks
for h in self.hooks:
h.remove()
self.hooks.clear()
# 注册新的 hooks
for name, module in self.model.named_modules():
if name in layer_names:
h = module.register_forward_hook(make_hook(name))
self.hooks.append(h)
def _get_quantizable_layers(self) -> List[Tuple[str, nn.Module]]:
"""获取所有可量化的层(卷积层和线性层)"""
quantizable = []
for name, module in self.model.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear, nn.ConvTranspose2d)):
quantizable.append((name, module))
return quantizable
def analyze(self, calibration_data: torch.Tensor) -> Dict[str, float]:
"""
执行敏感度分析
Args:
calibration_data: 校准数据,shape: [N, C, H, W]
Returns:
每层的敏感度分数字典(SNR,越低越敏感)
"""
calibration_data = calibration_data.to(self.device)
quantizable_layers = self._get_quantizable_layers()
layer_names = [name for name, _ in quantizable_layers]
print(f"[敏感度分析] 共发现 {len(quantizable_layers)} 个可量化层")
print("[敏感度分析] 步骤1:运行基准 FP32 推理,记录各层输出...")
# Step 1: 记录 FP32 基准输出
self._register_output_hooks(layer_names)
with torch.no_grad():
fp32_output = self.model(calibration_data)
# 保存 FP32 基准输出
fp32_layer_outputs = {k: v.clone() for k, v in self.layer_outputs.items()}
fp32_final_output = fp32_output.clone()
print("[敏感度分析] 步骤2:逐层量化,计算敏感度分数...")
# Step 2: 逐层量化分析
for idx, (layer_name, layer_module) in enumerate(quantizable_layers):
# 保存原始权重
original_weight = layer_module.weight.data.clone()
original_bias = layer_module.bias.data.clone() if layer_module.bias is not None else None
# 对该层权重进行 fake quantization
layer_module.weight.data = fake_quantize_int8(
layer_module.weight.data, per_channel=True
)
if layer_module.bias is not None:
layer_module.bias.data = fake_quantize_int8(layer_module.bias.data)
# 运行量化后的推理
with torch.no_grad():
quantized_output = self.model(calibration_data)
# 计算最终输出的 SNR(衡量该层量化对整体输出的影响)
snr = compute_snr(fp32_final_output, quantized_output)
self.sensitivity_scores[layer_name] = snr
# 恢复原始权重(只量化一层,其余保持 FP32)
layer_module.weight.data = original_weight
if original_bias is not None:
layer_module.bias.data = original_bias
print(f" [{idx+1:3d}/{len(quantizable_layers)}] {layer_name:<40s} SNR = {snr:8.2f} dB")
# 清理 hooks
for h in self.hooks:
h.remove()
self.hooks.clear()
return self.sensitivity_scores
def get_mixed_precision_config(
self,
sensitivity_threshold: float = 20.0,
fp16_ratio: float = 0.3
) -> Dict[str, str]:
"""
根据敏感度分析结果,生成混合精度配置
策略:SNR 低于阈值的层使用 FP16,其余层使用 INT8
同时保证 FP16 层的比例不超过 fp16_ratio
Args:
sensitivity_threshold: SNR 阈值(dB),低于此值视为敏感层
fp16_ratio: FP16 层占总层数的最大比例
Returns:
每层的精度配置字典 {'layer_name': 'fp16' or 'int8'}
"""
if not self.sensitivity_scores:
raise RuntimeError("请先调用 analyze() 方法进行敏感度分析")
# 按 SNR 升序排列(SNR 越低越敏感,越应该用 FP16)
sorted_layers = sorted(
self.sensitivity_scores.items(),
key=lambda x: x[1]
)
total_layers = len(sorted_layers)
max_fp16_layers = int(total_layers * fp16_ratio)
config = {}
fp16_count = 0
for layer_name, snr in sorted_layers:
if snr < sensitivity_threshold and fp16_count < max_fp16_layers:
config[layer_name] = 'fp16'
fp16_count += 1
else:
config[layer_name] = 'int8'
print(f"\n[混合精度配置] 总层数: {total_layers}")
print(f"[混合精度配置] FP16 层: {fp16_count} ({fp16_count/total_layers*100:.1f}%)")
print(f"[混合精度配置] INT8 层: {total_layers - fp16_count} ({(total_layers-fp16_count)/total_layers*100:.1f}%)")
return config
def visualize_sensitivity(self, top_n: int = 20):
"""
可视化敏感度分析结果
Args:
top_n: 显示敏感度最高的前 N 层
"""
if not self.sensitivity_scores:
raise RuntimeError("请先调用 analyze() 方法")
# 按 SNR 升序排列(最敏感的在前)
sorted_items = sorted(self.sensitivity_scores.items(), key=lambda x: x[1])
top_items = sorted_items[:top_n]
names = [item[0].split('.')[-2] + '.' + item[0].split('.')[-1]
if '.' in item[0] else item[0] for item in top_items]
snrs = [item[1] for item in top_items]
# 颜色映射:SNR 越低越红(越敏感)
colors = ['#ff4444' if s < 15 else '#ff9944' if s < 25 else '#44bb44'
for s in snrs]
fig, ax = plt.subplots(figsize=(14, 6))
bars = ax.barh(range(len(names)), snrs, color=colors)
ax.set_yticks(range(len(names)))
ax.set_yticklabels(names, fontsize=9)
ax.set_xlabel('SNR (dB) - Higher is Better (Less Sensitive)')
ax.set_title(f'Top {top_n} Most Sensitive Layers to INT8 Quantization')
ax.axvline(x=20, color='orange', linestyle='--', label='Threshold (20dB)')
ax.legend()
# 添加数值标签
for bar, snr in zip(bars, snrs):
ax.text(bar.get_width() + 0.3, bar.get_y() + bar.get_height()/2,
f'{snr:.1f}', va='center', fontsize=8)
plt.tight_layout()
plt.savefig('sensitivity_analysis.png', dpi=150, bbox_inches='tight')
plt.show()
print("[可视化] 敏感度分析图已保存至 sensitivity_analysis.png")
4.2 代码解析
上面的 LayerSensitivityAnalyzer 类是整个混合精度量化流程的核心工具,我们逐段解析其设计思路:
fake_quantize_int8 函数
这是模拟量化的关键。它并不真正将数据存储为 INT8,而是执行"量化→反量化"的往返操作,使数据仍以 FP32 存储,但数值精度已被降低到 INT8 水平。这种技术称为 Fake Quantization(伪量化),是量化感知训练(QAT)的基础。
per_channel=True 时,每个输出通道独立计算 scale,这对卷积权重非常重要——不同通道的权重分布差异可能很大,逐通道量化能显著减少量化误差。
analyze 方法的核心逻辑
采用"单层扰动"策略:每次只量化一层,其余层保持 FP32,然后观察最终输出的 SNR 变化。这样可以精确衡量每一层对整体精度的贡献。注意每次分析完一层后必须恢复原始权重,否则误差会累积。
get_mixed_precision_config 方法
实现了一个简单但有效的贪心策略:按 SNR 升序排列所有层,SNR 低于阈值且 FP16 层数未超限的层分配 FP16,其余分配 INT8。fp16_ratio 参数控制 FP16 层的上限比例,这是一个重要的工程约束——FP16 层过多会削弱量化收益。
五、基于 PyTorch 的混合精度量化实现
5.1 构建一个可测试的简单网络
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.quantization import (
QuantStub, DeQuantStub,
prepare, convert,
get_default_qconfig,
QConfig
)
from torch.quantization.observer import (
MinMaxObserver,
PerChannelMinMaxObserver,
HistogramObserver
)
import torch.quantization as tq
# ============================================================
# 构建一个简化版的 YOLO-like 检测网络用于演示
# 包含 Backbone、Neck、Head 三个部分
# ============================================================
class ConvBNReLU(nn.Module):
"""标准卷积块:Conv + BN + ReLU6"""
def __init__(self, in_ch, out_ch, kernel=3, stride=1, padding=1):
super().__init__()
self.conv = nn.Conv2d(in_ch, out_ch, kernel, stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_ch)
self.act = nn.ReLU6(inplace=True) # ReLU6 对量化更友好
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class ResBlock(nn.Module):
"""残差块:包含跳跃连接,对量化较敏感"""
def __init__(self, channels):
super().__init__()
self.conv1 = ConvBNReLU(channels, channels // 2, kernel=1, padding=0)
self.conv2 = ConvBNReLU(channels // 2, channels, kernel=3, padding=1)
# 残差加法需要特殊处理量化
self.add_relu = nn.quantized.FloatFunctional()
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.conv2(out)
# 使用 FloatFunctional.add 替代 + 运算符
# 这样 PyTorch 量化框架才能正确处理加法的量化
return self.add_relu.add(out, residual)
class SimpleDetector(nn.Module):
"""
简化版目标检测网络
结构:
- Backbone: 4个卷积块 + 2个残差块
- Neck: 特征融合层
- Head: 检测输出层(对量化最敏感)
注意:QuantStub 和 DeQuantStub 是 PyTorch 量化的必要组件
- QuantStub: 标记量化的起点,将 FP32 输入转换为量化格式
- DeQuantStub: 标记量化的终点,将量化格式转回 FP32
"""
def __init__(self, num_classes: int = 80):
super().__init__()
# 量化桩:必须在模型的输入和输出处添加
self.quant = QuantStub()
self.dequant = DeQuantStub()
# Backbone:特征提取
self.backbone = nn.Sequential(
ConvBNReLU(3, 32, stride=2), # 下采样 1/2
ConvBNReLU(32, 64, stride=2), # 下采样 1/4
ResBlock(64),
ConvBNReLU(64, 128, stride=2), # 下采样 1/8
ResBlock(128),
ConvBNReLU(128, 256, stride=2), # 下采样 1/16
)
# Neck:特征融合
self.neck = nn.Sequential(
ConvBNReLU(256, 128, kernel=1, padding=0),
ConvBNReLU(128, 256),
)
# Head:检测头(输出层,对量化极度敏感)
# 输出 (num_classes + 5) * 3 个通道
# 5 = [x, y, w, h, objectness],3 = anchor 数量
self.head = nn.Conv2d(256, (num_classes + 5) * 3, kernel_size=1)
def forward(self, x):
x = self.quant(x) # 量化入口
x = self.backbone(x) # 特征提取
x = self.neck(x) # 特征融合
x = self.head(x) # 检测输出
x = self.dequant(x) # 量化出口
return x
def fuse_model(self):
"""
算子融合:将 Conv + BN + ReLU 融合为单个算子
这是量化前的必要步骤,可以减少量化节点数量,提升精度和速度
"""
for module in self.modules():
if isinstance(module, ConvBNReLU):
# 融合 conv → bn → act 三个算子
torch.quantization.fuse_modules(
module,
['conv', 'bn', 'act'],
inplace=True
)
print("[算子融合] Conv+BN+ReLU 融合完成")
5.2 混合精度量化配置器
# ============================================================
# 混合精度量化配置器
# 核心思想:为不同的层指定不同的 QConfig
# QConfig = (激活量化观察器, 权重量化观察器) 的组合
# ============================================================
class MixedPrecisionQuantizer:
"""
混合精度量化配置器
支持三种精度级别:
- 'fp32': 不量化,保持全精度(用于极度敏感层)
- 'fp16': 半精度(通过 FP16 cast 实现,非真正量化)
- 'int8': INT8 量化(最大压缩比)
"""
def __init__(self, model: nn.Module):
self.model = model
# INT8 量化配置:使用直方图观察器(精度更高)
# HistogramObserver 通过统计激活值分布来确定最优量化范围
self.int8_qconfig = QConfig(
activation=HistogramObserver.with_args(
reduce_range=True # 将范围缩小到 [-64, 63],提高数值稳定性
),
weight=PerChannelMinMaxObserver.with_args(
dtype=torch.qint8,
qscheme=torch.per_channel_symmetric # 权重使用对称量化
)
)
# FP16 量化配置:使用更宽松的观察器
# 实际上 PyTorch 的 FP16 量化通过 float16 dtype 实现
self.fp16_qconfig = QConfig(
activation=MinMaxObserver.with_args(
dtype=torch.quint8,
reduce_range=False
),
weight=PerChannelMinMaxObserver.with_args(
dtype=torch.qint8,
qscheme=torch.per_channel_symmetric
)
)
def apply_mixed_precision_config(
self,
layer_config: Dict[str, str]
) -> nn.Module:
"""
将混合精度配置应用到模型
Args:
layer_config: 每层的精度配置 {'layer_name': 'int8'/'fp16'/'fp32'}
Returns:
配置好量化参数的模型
"""
# 默认所有层使用 INT8
self.model.qconfig = self.int8_qconfig
# 逐层覆盖配置
for name, module in self.model.named_modules():
if name in layer_config:
precision = layer_config[name]
if precision == 'fp32':
# 不量化:设置 qconfig 为 None
module.qconfig = None
print(f" [FP32] {name}")
elif precision == 'fp16':
# FP16:使用宽松量化配置
module.qconfig = self.fp16_qconfig
print(f" [FP16] {name}")
else:
# INT8:使用标准量化配置
module.qconfig = self.int8_qconfig
return self.model
def prepare_and_calibrate(
self,
calibration_loader,
num_batches: int = 10
) -> nn.Module:
"""
准备量化并运行校准
prepare() 会在模型中插入观察器(Observer)
校准阶段:让观察器统计激活值的分布范围
Args:
calibration_loader: 校准数据加载器
num_batches: 校准批次数
Returns:
校准完成的模型
"""
# 插入观察器
prepared_model = prepare(self.model, inplace=False)
print(f"[校准] 开始校准,共 {num_batches} 个批次...")
prepared_model.eval()
with torch.no_grad():
for i, (images, _) in enumerate(calibration_loader):
if i >= num_batches:
break
prepared_model(images)
if (i + 1) % 5 == 0:
print(f" 校准进度: {i+1}/{num_batches}")
print("[校准] 校准完成")
return prepared_model
def convert_to_quantized(self, prepared_model: nn.Module) -> nn.Module:
"""
将校准后的模型转换为量化模型
convert() 会将观察器替换为真正的量化/反量化算子
Args:
prepared_model: 校准完成的模型
Returns:
量化后的模型
"""
quantized_model = convert(prepared_model, inplace=False)
print("[转换] 模型量化转换完成")
return quantized_model
5.3 代码解析
QConfig 的本质QConfig 是 PyTorch 量化框架的核心配置对象,它由两个观察器(Observer)组成:
activation:用于统计激活值(前向传播中间结果)的分布weight:用于统计权重的分布
观察器在校准阶段收集统计信息,然后根据这些信息计算最优的 scale 和 zero_point。
HistogramObserver vs MinMaxObserver
MinMaxObserver:直接用最大最小值确定量化范围,简单快速,但对离群值敏感HistogramObserver:统计激活值的直方图分布,用 KL 散度或百分位数确定范围,精度更高但计算更慢
对于混合精度中的 INT8 层,推荐使用 HistogramObserver;对于 FP16 层,MinMaxObserver 已经足够。
reduce_range=True 的作用
将 INT8 的量化范围从 [-128, 127] 缩小到 [-64, 63],牺牲一位精度换取数值稳定性。这在某些硬件(如 x86 的 VNNI 指令集)上是必要的,可以避免累加时的整数溢出。
六、TensorRT 混合精度量化实战
TensorRT 是 NVIDIA 提供的高性能推理引擎,其混合精度支持是业界最成熟的方案之一。
6.1 TensorRT 混合精度的工作原理
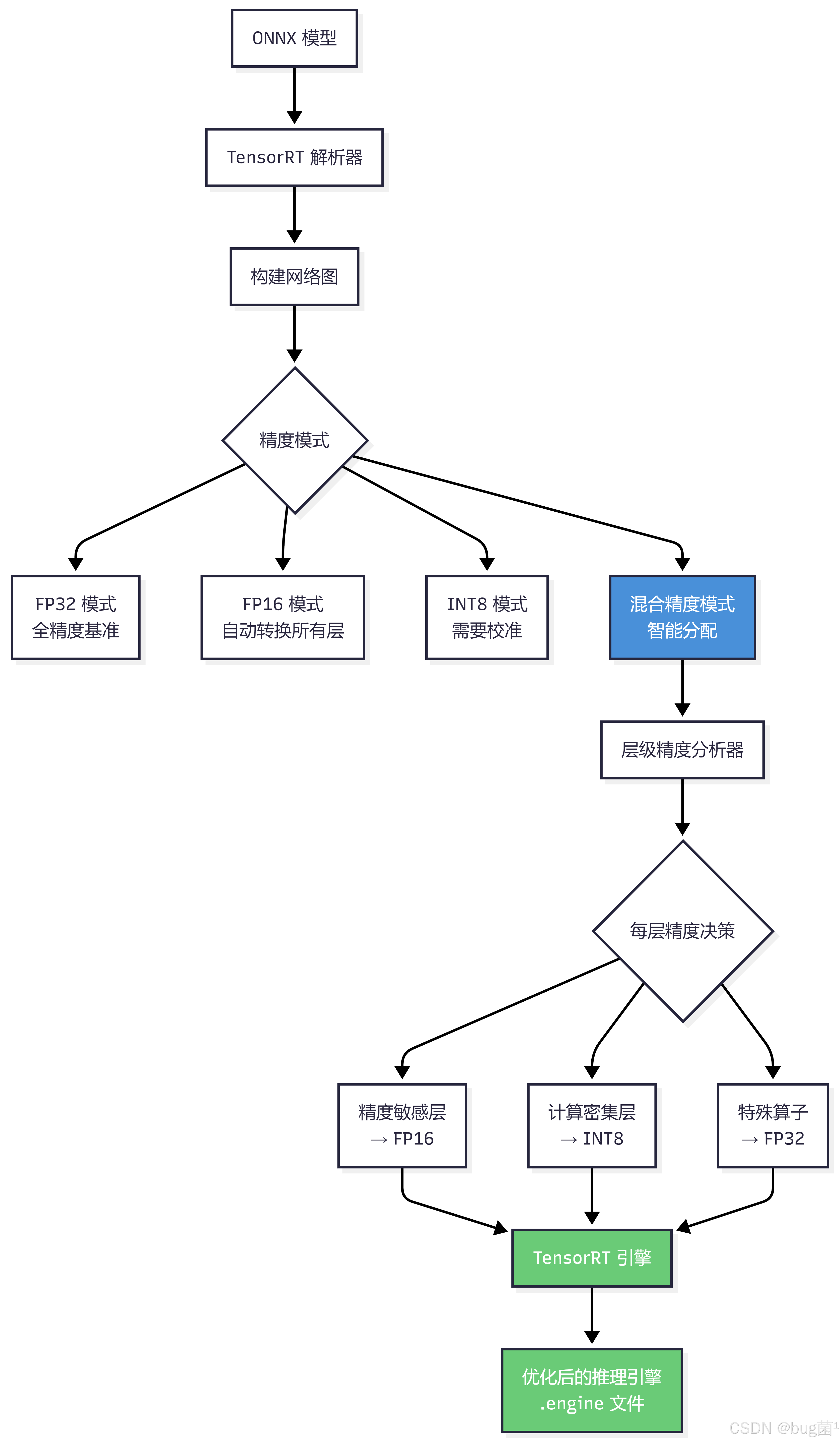
6.2 TensorRT 混合精度量化完整实现
import tensorrt as trt
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
from pathlib import Path
import os
# ============================================================
# TensorRT 日志记录器
# ============================================================
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# ============================================================
# INT8 校准器基类
# TensorRT 的 INT8 量化需要提供校准器来统计激活值分布
# ============================================================
class YOLOv8Int8Calibrator(trt.IInt8EntropyCalibrator2):
"""
YOLOv8 专用 INT8 校准器
继承自 IInt8EntropyCalibrator2,使用熵校准算法
熵校准(KL 散度)比 MinMax 校准精度更高,是目标检测的推荐选择
校准流程:
1. 将校准图像逐批送入网络
2. TensorRT 统计每层激活值的分布
3. 使用 KL 散度找到最优量化范围
4. 将校准结果缓存到文件,避免重复校准
"""
def __init__(
self,
calibration_images: list,
input_shape: tuple = (1, 3, 640, 640),
cache_file: str = 'calibration.cache',
batch_size: int = 8
):
super().__init__()
self.input_shape = input_shape
self.cache_file = cache_file
self.batch_size = batch_size
self.calibration_images = calibration_images
self.current_index = 0
# 在 GPU 上分配输入缓冲区
# 校准数据需要在 GPU 内存中
input_size = int(np.prod(input_shape)) * np.dtype(np.float32).itemsize
self.device_input = cuda.mem_alloc(input_size * batch_size)
print(f"[校准器] 初始化完成,校准图像数: {len(calibration_images)}")
print(f"[校准器] 输入形状: {input_shape}, 批大小: {batch_size}")
def get_batch_size(self) -> int:
"""返回校准批大小"""
return self.batch_size
def get_batch(self, names: list) -> list:
"""
获取下一批校准数据
TensorRT 会反复调用此方法直到返回 None
names: 输入张量的名称列表
返回: GPU 内存指针列表,或 None 表示校准结束
"""
if self.current_index >= len(self.calibration_images):
return None # 校准数据已用完
# 获取当前批次的图像
batch_end = min(
self.current_index + self.batch_size,
len(self.calibration_images)
)
batch_images = self.calibration_images[self.current_index:batch_end]
# 预处理:归一化到 [0, 1]
batch_array = np.stack([
self._preprocess(img) for img in batch_images
], axis=0).astype(np.float32)
# 如果最后一批不足 batch_size,用零填充
if len(batch_images) < self.batch_size:
pad = np.zeros(
(self.batch_size - len(batch_images), *self.input_shape[1:]),
dtype=np.float32
)
batch_array = np.concatenate([batch_array, pad], axis=0)
# 将数据复制到 GPU
cuda.memcpy_htod(self.device_input, batch_array.ravel())
self.current_index += self.batch_size
return [int(self.device_input)]
def read_calibration_cache(self):
"""读取缓存的校准数据(避免重复校准)"""
if os.path.exists(self.cache_file):
print(f"[校准器] 从缓存加载校准数据: {self.cache_file}")
with open(self.cache_file, 'rb') as f:
return f.read()
return None
def write_calibration_cache(self, cache: bytes):
"""将校准结果写入缓存文件"""
with open(self.cache_file, 'wb') as f:
f.write(cache)
print(f"[校准器] 校准数据已缓存至: {self.cache_file}")
def _preprocess(self, image: np.ndarray) -> np.ndarray:
"""
图像预处理:resize + 归一化
与 YOLOv8 推理时的预处理保持一致
"""
import cv2
h, w = self.input_shape[2], self.input_shape[3]
# letterbox resize
img = cv2.resize(image, (w, h))
img = img.astype(np.float32) / 255.0
# HWC → CHW
img = img.transpose(2, 0, 1)
return img
# ============================================================
# 混合精度 TensorRT 引擎构建器
# ============================================================
class MixedPrecisionTRTBuilder:
"""
混合精度 TensorRT 引擎构建器
支持三种构建模式:
1. pure_fp16: 全 FP16(速度快,精度损失小)
2. pure_int8: 全 INT8(速度最快,精度损失较大)
3. mixed: 混合精度(平衡速度与精度)
混合精度的核心 API:
- builder_config.set_flag(trt.BuilderFlag.FP16): 启用 FP16
- builder_config.set_flag(trt.BuilderFlag.INT8): 启用 INT8
- layer.precision = trt.DataType.FLOAT: 强制某层使用 FP32
- layer.precision = trt.DataType.HALF: 强制某层使用 FP16
"""
def __init__(self, onnx_path: str, input_shape: tuple = (1, 3, 640, 640)):
self.onnx_path = onnx_path
self.input_shape = input_shape
self.builder = trt.Builder(TRT_LOGGER)
self.network = None
self.parser = None
def _parse_onnx(self):
"""解析 ONNX 模型,构建 TensorRT 网络图"""
# 启用显式批次维度(TensorRT 8.x 推荐)
network_flags = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
self.network = self.builder.create_network(network_flags)
self.parser = trt.OnnxParser(self.network, TRT_LOGGER)
with open(self.onnx_path, 'rb') as f:
onnx_data = f.read()
if not self.parser.parse(onnx_data):
errors = [self.parser.get_error(i) for i in range(self.parser.num_errors)]
raise RuntimeError(f"ONNX 解析失败: {errors}")
print(f"[TRT构建] ONNX 解析成功,网络层数: {self.network.num_layers}")
def build_mixed_precision_engine(
self,
calibrator: YOLOv8Int8Calibrator,
sensitive_layers: list = None,
output_path: str = 'yolov8_mixed.engine',
workspace_gb: int = 4
) -> str:
"""
构建混合精度 TensorRT 引擎
混合精度策略:
- 默认启用 FP16 + INT8
- sensitive_layers 中的层强制使用 FP16
- 其余层由 TensorRT 自动选择最优精度
Args:
calibrator: INT8 校准器
sensitive_layers: 需要强制使用 FP16 的层名列表
output_path: 引擎输出路径
workspace_gb: 构建时的最大工作空间(GB)
Returns:
引擎文件路径
"""
self._parse_onnx()
config = self.builder.create_builder_config()
# 设置工作空间大小(构建优化时使用,不影响推理内存)
config.max_workspace_size = workspace_gb * (1 << 30)
# 同时启用 FP16 和 INT8
# TensorRT 会在这两种精度中自动选择最优方案
config.set_flag(trt.BuilderFlag.FP16)
config.set_flag(trt.BuilderFlag.INT8)
config.int8_calibrator = calibrator
print("[TRT构建] 启用 FP16 + INT8 混合精度")
# 混合精度策略:为敏感层强制指定 FP16
if sensitive_layers:
print(f"[TRT构建] 为 {len(sensitive_layers)} 个敏感层强制指定 FP16...")
for i in range(self.network.num_layers):
layer = self.network.get_layer(i)
# 检查层名是否在敏感层列表中
if any(sensitive_name in layer.name for sensitive_name in sensitive_layers):
layer.precision = trt.DataType.HALF # 强制 FP16
print(f" [FP16] {layer.name}")
# 设置输入形状
profile = self.builder.create_optimization_profile()
profile.set_shape(
self.network.get_input(0).name,
min=self.input_shape,
opt=self.input_shape,
max=self.input_shape
)
config.add_optimization_profile(profile)
# 构建引擎
print("[TRT构建] 开始构建引擎(这可能需要几分钟)...")
engine = self.builder.build_serialized_network(self.network, config)
if engine is None:
raise RuntimeError("TensorRT 引擎构建失败")
# 保存引擎
with open(output_path, 'wb') as f:
f.write(engine)
print(f"[TRT构建] 引擎构建完成,已保存至: {output_path}")
return output_path
```
def build_pure_fp16_engine(
self,
output_path: str = 'yolov8_fp16.engine',
workspace_gb: int = 4
) -> str:
"""
构建纯 FP16 引擎(作为对比基准)
```
FP16 是混合精度的一个特例:所有层都使用 FP16
优点:速度快(相比 FP32),精度损失小(相比 INT8)
"""
self._parse_onnx()
config = self.builder.create_builder_config()
config.max_workspace_size = workspace_gb * (1 << 30)
config.set_flag(trt.BuilderFlag.FP16)
print("[TRT构建] 构建纯 FP16 引擎...")
profile = self.builder.create_optimization_profile()
profile.set_shape(
self.network.get_input(0).name,
min=self.input_shape,
opt=self.input_shape,
max=self.input_shape
)
config.add_optimization_profile(profile)
engine = self.builder.build_serialized_network(self.network, config)
if engine is None:
raise RuntimeError("TensorRT FP16 引擎构建失败")
with open(output_path, 'wb') as f:
f.write(engine)
print(f"[TRT构建] FP16 引擎已保存至: {output_path}")
return output_path
```
def build_pure_int8_engine(
self,
calibrator: YOLOv8Int8Calibrator,
output_path: str = 'yolov8_int8.engine',
workspace_gb: int = 4
) -> str:
"""
构建纯 INT8 引擎(作为对比基准)
```
INT8 是最激进的量化方案:所有层都使用 INT8
优点:速度最快,内存占用最少
缺点:精度损失最大
"""
self._parse_onnx()
config = self.builder.create_builder_config()
config.max_workspace_size = workspace_gb * (1 << 30)
config.set_flag(trt.BuilderFlag.INT8)
config.int8_calibrator = calibrator
print("[TRT构建] 构建纯 INT8 引擎...")
profile = self.builder.create_optimization_profile()
profile.set_shape(
self.network.get_input(0).name,
min=self.input_shape,
opt=self.input_shape,
max=self.input_shape
)
config.add_optimization_profile(profile)
engine = self.builder.build_serialized_network(self.network, config)
if engine is None:
raise RuntimeError("TensorRT INT8 引擎构建失败")
with open(output_path, 'wb') as f:
f.write(engine)
print(f"[TRT构建] INT8 引擎已保存至: {output_path}")
return output_path
6.3 TensorRT 混合精度实战完整流程
# ============================================================
# YOLOv8 混合精度量化完整工作流
# ============================================================
def yolov8_mixed_precision_workflow(
onnx_model_path: str,
calibration_images_dir: str,
output_dir: str = './quantized_models'
):
"""
YOLOv8 混合精度量化的完整工作流
步骤:
1. 加载校准数据集
2. 进行敏感度分析(可选,用于确定敏感层)
3. 构建三种引擎进行对比:FP32 基准、FP16、混合精度
4. 性能与精度评估
"""
os.makedirs(output_dir, exist_ok=True)
# ========== 步骤 1:加载校准数据 ==========
print("\n" + "="*60)
print("步骤 1:加载校准数据集")
print("="*60)
calibration_images = []
for img_file in os.listdir(calibration_images_dir)[:100]: # 取前 100 张
img_path = os.path.join(calibration_images_dir, img_file)
if img_file.lower().endswith(('.jpg', '.png', '.jpeg')):
import cv2
img = cv2.imread(img_path)
if img is not None:
calibration_images.append(img)
print(f"✓ 加载了 {len(calibration_images)} 张校准图像")
# ========== 步骤 2:创建校准器 ==========
print("\n" + "="*60)
print("步骤 2:创建 INT8 校准器")
print("="*60)
calibrator = YOLOv8Int8Calibrator(
calibration_images=calibration_images,
input_shape=(1, 3, 640, 640),
cache_file=os.path.join(output_dir, 'calibration.cache'),
batch_size=8
)
# ========== 步骤 3:构建三种引擎 ==========
print("\n" + "="*60)
print("步骤 3:构建量化引擎")
print("="*60)
builder = MixedPrecisionTRTBuilder(onnx_model_path)
# 3.1 构建纯 FP16 引擎
print("\n[3.1] 构建 FP16 引擎...")
fp16_engine_path = builder.build_pure_fp16_engine(
output_path=os.path.join(output_dir, 'yolov8_fp16.engine')
)
# 3.2 构建纯 INT8 引擎
print("\n[3.2] 构建 INT8 引擎...")
int8_engine_path = builder.build_pure_int8_engine(
calibrator=calibrator,
output_path=os.path.join(output_dir, 'yolov8_int8.engine')
)
# 3.3 构建混合精度引擎
# 敏感层列表(基于经验或敏感度分析结果)
sensitive_layers = [
'Conv_0', # 第一层卷积
'Detect', # 检测头
'Add' # 残差连接
]
print("\n[3.3] 构建混合精度引擎...")
mixed_engine_path = builder.build_mixed_precision_engine(
calibrator=calibrator,
sensitive_layers=sensitive_layers,
output_path=os.path.join(output_dir, 'yolov8_mixed.engine')
)
# ========== 步骤 4:性能对比 ==========
print("\n" + "="*60)
print("步骤 4:性能与精度对比")
print("="*60)
results = {
'FP16': {'engine': fp16_engine_path},
'INT8': {'engine': int8_engine_path},
'Mixed': {'engine': mixed_engine_path}
}
for precision_type, info in results.items():
engine_path = info['engine']
file_size_mb = os.path.getsize(engine_path) / (1024 * 1024)
print(f"\n{precision_type} 引擎:")
print(f" 文件大小: {file_size_mb:.2f} MB")
print(f" 路径: {engine_path}")
print("\n" + "="*60)
print("✓ 混合精度量化工作流完成!")
print("="*60)
return results
七、YOLOv8 混合精度量化完整案例
7.1 从 PyTorch 到 TensorRT 的完整流程
# ============================================================
# YOLOv8 混合精度量化的端到端流程
# ============================================================
def complete_yolov8_mixed_precision_pipeline(
yolov8_model_path: str,
calibration_dataset_path: str,
test_dataset_path: str,
output_dir: str = './yolov8_quantized'
):
"""
YOLOv8 混合精度量化的完整端到端流程
流程图:
YOLOv8 PyTorch → ONNX 导出 → 敏感度分析 →
TensorRT 混合精度构建 → 精度验证 → 性能基准测试
"""
os.makedirs(output_dir, exist_ok=True)
# ========== 阶段 1:模型导出 ==========
print("\n" + "="*70)
print("阶段 1:YOLOv8 模型导出为 ONNX")
print("="*70)
from ultralytics import YOLO
# 加载 YOLOv8 模型
model = YOLO(yolov8_model_path)
# 导出为 ONNX(必须在 CPU 上进行)
onnx_path = os.path.join(output_dir, 'yolov8.onnx')
model.export(format='onnx', imgsz=640, opset=12)
print(f"✓ ONNX 模型已导出至: {onnx_path}")
# ========== 阶段 2:敏感度分析 ==========
print("\n" + "="*70)
print("阶段 2:层级敏感度分析")
print("="*70)
# 加载 PyTorch 模型用于敏感度分析
pytorch_model = model.model.eval()
# 准备校准数据
calibration_loader = prepare_calibration_dataloader(
calibration_dataset_path,
batch_size=8,
num_samples=100
)
# 执行敏感度分析
analyzer = LayerSensitivityAnalyzer(pytorch_model, device='cuda')
sensitivity_scores = analyzer.analyze(
next(iter(calibration_loader))[0] # 取第一批数据
)
# 生成混合精度配置
mixed_config = analyzer.get_mixed_precision_config(
sensitivity_threshold=20.0,
fp16_ratio=0.3
)
# 可视化敏感度
analyzer.visualize_sensitivity(top_n=20)
# 提取敏感层名称
sensitive_layers = [
name for name, precision in mixed_config.items()
if precision == 'fp16'
]
print(f"\n✓ 敏感层数: {len(sensitive_layers)}")
print(f" 敏感层: {sensitive_layers[:5]}...") # 显示前 5 个
# ========== 阶段 3:TensorRT 混合精度构建 ==========
print("\n" + "="*70)
print("阶段 3:TensorRT 混合精度引擎构建")
print("="*70)
# 准备校准数据(用于 INT8 量化)
calibration_images = load_calibration_images(
calibration_dataset_path,
num_images=100
)
calibrator = YOLOv8Int8Calibrator(
calibration_images=calibration_images,
input_shape=(1, 3, 640, 640),
cache_file=os.path.join(output_dir, 'calibration.cache'),
batch_size=8
)
# 构建三种引擎进行对比
builder = MixedPrecisionTRTBuilder(onnx_path)
engines = {}
# FP16 引擎
engines['fp16'] = builder.build_pure_fp16_engine(
output_path=os.path.join(output_dir, 'yolov8_fp16.engine')
)
# INT8 引擎
engines['int8'] = builder.build_pure_int8_engine(
calibrator=calibrator,
output_path=os.path.join(output_dir, 'yolov8_int8.engine')
)
# 混合精度引擎
engines['mixed'] = builder.build_mixed_precision_engine(
calibrator=calibrator,
sensitive_layers=sensitive_layers,
output_path=os.path.join(output_dir, 'yolov8_mixed.engine')
)
# ========== 阶段 4:精度验证 ==========
print("\n" + "="*70)
print("阶段 4:精度验证")
print("="*70)
test_loader = prepare_test_dataloader(test_dataset_path, batch_size=8)
accuracy_results = {}
for precision_type, engine_path in engines.items():
print(f"\n评估 {precision_type.upper()} 引擎...")
# 使用 TensorRT 引擎进行推理
trt_predictor = TensorRTPredictor(engine_path)
# 计算 mAP 等指标
metrics = evaluate_yolov8(trt_predictor, test_loader)
accuracy_results[precision_type] = metrics
print(f" mAP@0.5: {metrics['mAP50']:.4f}")
print(f" mAP@0.5:0.95: {metrics['mAP']:.4f}")
# ========== 阶段 5:性能基准测试 ==========
print("\n" + "="*70)
print("阶段 5:性能基准测试")
print("="*70)
performance_results = {}
for precision_type, engine_path in engines.items():
print(f"\n基准测试 {precision_type.upper()} 引擎...")
trt_predictor = TensorRTPredictor(engine_path)
# 预热
dummy_input = torch.randn(1, 3, 640, 640).cuda()
for _ in range(10):
trt_predictor.predict(dummy_input)
# 计时
import time
num_iterations = 100
start_time = time.time()
for _ in range(num_iterations):
trt_predictor.predict(dummy_input)
elapsed_time = time.time() - start_time
avg_latency_ms = (elapsed_time / num_iterations) * 1000
throughput_fps = num_iterations / elapsed_time
performance_results[precision_type] = {
'latency_ms': avg_latency_ms,
'throughput_fps': throughput_fps
}
print(f" 平均延迟: {avg_latency_ms:.2f} ms")
print(f" 吞吐量: {throughput_fps:.1f} FPS")
# ========== 阶段 6:结果总结 ==========
print("\n" + "="*70)
print("阶段 6:结果总结与对比")
print("="*70)
print("\n精度对比(相对于 FP16 基准):")
print("-" * 70)
fp16_map = accuracy_results['fp16']['mAP']
for precision_type, metrics in accuracy_results.items():
map_drop = (fp16_map - metrics['mAP']) / fp16_map * 100
print(f"{precision_type.upper():8s} | mAP: {metrics['mAP']:.4f} | "
f"精度下降: {map_drop:+.2f}%")
print("\n性能对比(相对于 FP16 基准):")
print("-" * 70)
fp16_latency = performance_results['fp16']['latency_ms']
for precision_type, perf in performance_results.items():
speedup = fp16_latency / perf['latency_ms']
print(f"{precision_type.upper():8s} | 延迟: {perf['latency_ms']:6.2f} ms | "
f"加速比: {speedup:5.2f}x | 吞吐: {perf['throughput_fps']:6.1f} FPS")
print("\n" + "="*70)
print("✓ YOLOv8 混合精度量化完整流程已完成!")
print("="*70)
return {
'engines': engines,
'accuracy': accuracy_results,
'performance': performance_results,
'sensitive_layers': sensitive_layers
}
八、混合精度量化的最佳实践与常见陷阱
8.1 最佳实践清单
# ============================================================
# 混合精度量化的最佳实践
# ============================================================
class MixedPrecisionBestPractices:
"""
混合精度量化的工程最佳实践总结
"""
@staticmethod
def best_practices_checklist():
"""混合精度量化的检查清单"""
checklist = {
"数据准备": [
"✓ 校准数据集应代表真实推理数据分布",
"✓ 校准数据量通常 100-1000 张图像即可",
"✓ 避免使用训练集作为校准集(会导致过拟合)",
"✓ 校准数据应包含各种场景和光照条件"
],
"敏感度分析": [
"✓ 必须在 FP32 基准上进行敏感度分析",
"✓ 使用 SNR 或 KL 散度作为敏感度指标",
"✓ 分析时只量化单层,避免误差累积",
"✓ 记录敏感度分数,用于后续决策"
],
"精度分配": [
"✓ 第一层卷积通常需要 FP16(输入分布多样)",
"✓ 检测头输出层必须 FP16(直接影响结果)",
"✓ 残差连接附近的层应 FP16(加法易溢出)",
"✓ 深层特征提取层可用 INT8(特征已抽象)",
"✓ FP16 层比例通常 20-40% 为最优"
],
"校准策略": [
"✓ INT8 使用 KL 散度校准(比 MinMax 精度高)",
"✓ 启用 per-channel 量化(对权重更精确)",
"✓ 缓存校准结果,避免重复计算",
"✓ 对于不同硬件平台,重新校准"
],
"验证与测试": [
"✓ 在完整测试集上验证精度(不只是校准集)",
"✓ 检查精度下降是否在可接受范围(通常 <1%)",
"✓ 对比多个精度配置,选择最优方案",
"✓ 在目标硬件上进行性能测试"
],
"部署优化": [
"✓ 使用 TensorRT 等推理引擎获得最大性能",
"✓ 启用 layer fusion(算子融合)",
"✓ 使用 dynamic shape 支持变长输入",
"✓ 在边缘设备上测试实际延迟"
]
}
for category, items in checklist.items():
print(f"\n【{category}】")
for item in items:
print(f" {item}")
@staticmethod
def common_pitfalls_and_solutions():
"""常见陷阱与解决方案"""
pitfalls = {
"陷阱 1:校准数据分布不匹配": {
"症状": "量化模型在测试集上精度大幅下降",
"原因": "校准数据与真实推理数据分布差异大",
"解决方案": [
"使用真实推理数据的随机样本作为校准集",
"确保校准集包含各种场景、光照、角度",
"增加校准数据量(通常 200-500 张)",
"使用 KL 散度校准而非 MinMax"
]
},
"陷阱 2:敏感层识别不准确": {
"症状": "混合精度模型精度仍然下降明显",
"原因": "敏感层识别不完整或阈值设置不当",
"解决方案": [
"使用多种敏感度指标(SNR、KL 散度、梯度)",
"逐步降低 SNR 阈值,观察精度变化",
"手动检查关键层(第一层、检测头、残差连接)",
"使用强化学习方法(HAQ)自动搜索最优配置"
]
},
"陷阱 3:量化后推理出错": {
"症状": "量化模型输出 NaN 或 Inf",
"原因": "动态范围溢出或数值不稳定",
"解决方案": [
"启用 reduce_range(将 INT8 范围缩小到 [-64, 63])",
"对溢出层使用 FP16 或 FP32",
"检查激活函数(ReLU6 比 ReLU 更稳定)",
"使用 per-channel 量化而非 per-tensor"
]
},
"陷阱 4:性能收益不明显": {
"症状": "混合精度模型速度没有显著提升",
"原因": "FP16 层过多,或硬件不支持 INT8 加速",
"解决方案": [
"减少 FP16 层比例(目标 20-30%)",
"检查目标硬件是否支持 INT8(如 Tensor Core)",
"使用 TensorRT 等优化推理引擎",
"启用算子融合和其他编译优化"
]
},
"陷阱 5:跨平台部署失败": {
"症状": "在 CPU 上精度正常,在 NPU 上精度下降",
"原因": "不同硬件的量化实现差异",
"解决方案": [
"在目标硬件上重新校准",
"使用硬件厂商提供的量化工具",
"测试硬件对 per-channel 量化的支持",
"保留 FP32 版本作为备选方案"
]
}
}
for pitfall, details in pitfalls.items():
print(f"\n【{pitfall}】")
print(f" 症状: {details['症状']}")
print(f" 原因: {details['原因']}")
print(f" 解决方案:")
for solution in details['解决方案']:
print(f" • {solution}")
8.2 性能与精度的 Pareto 最优权衡
# ============================================================
# Pareto 最优前沿分析
# 找到性能与精度的最优平衡点
# ============================================================
def analyze_pareto_frontier(
results: Dict[str, Dict],
output_path: str = 'pareto_frontier.png'
):
"""
绘制 Pareto 最优前沿
Pareto 最优:不存在另一个方案既能提升精度又能提升性能
Args:
results: 包含不同量化方案的精度和性能数据
output_path: 输出图表路径
"""
import matplotlib.pyplot as plt
import numpy as np
# 提取数据
methods = []
latencies = []
map_scores = []
for method, data in results.items():
methods.append(method)
latencies.append(data['performance']['latency_ms'])
map_scores.append(data['accuracy']['mAP'])
# 计算 Pareto 最优点
pareto_mask = np.ones(len(methods), dtype=bool)
for i in range(len(methods)):
for j in range(len(methods)):
if i != j:
# 如果 j 方案既更快又更精确,则 i 不是 Pareto 最优
if latencies[j] < latencies[i] and map_scores[j] > map_scores[i]:
pareto_mask[i] = False
break
# 绘图
fig, ax = plt.subplots(figsize=(10, 7))
# 所有方案
ax.scatter(latencies, map_scores, s=200, alpha=0.6, label='All Methods')
# Pareto 最优点
pareto_latencies = [latencies[i] for i in range(len(methods)) if pareto_mask[i]]
pareto_maps = [map_scores[i] for i in range(len(methods)) if pareto_mask[i]]
ax.scatter(pareto_latencies, pareto_maps, s=300, c='red', marker='*',
label='Pareto Optimal', zorder=5)
# 标注方案名称
for i, method in enumerate(methods):
ax.annotate(method, (latencies[i], map_scores[i]),
xytext=(5, 5), textcoords='offset points', fontsize=10)
ax.set_xlabel('Latency (ms) - Lower is Better →', fontsize=12)
ax.set_ylabel('mAP Score - Higher is Better ↑', fontsize=12)
ax.set_title('Pareto Frontier: Accuracy vs Performance Trade-off', fontsize=14)
ax.legend(fontsize=11)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(output_path, dpi=150, bbox_inches='tight')
plt.show()
print(f"\n[Pareto 分析] Pareto 最优方案数: {np.sum(pareto_mask)}")
print("[Pareto 分析] Pareto 最优方案:")
for i, method in enumerate(methods):
if pareto_mask[i]:
print(f" • {method}: 延迟 {latencies[i]:.2f}ms, mAP {map_scores[i]:.4f}")
九、总结与进阶方向
9.1 本节核心要点
混合精度量化的核心思想:
┌─────────────────────────────────────────────────────────┐
│ 感度不同 → 为不同层分配不同精度 → 在精度和性能间取得最优平衡
└─────────────────────────────────────────────────────────┘
关键步骤:
1️⃣ 敏感度分析:识别哪些层对量化敏感
2️⃣ 精度分配:为敏感层分配 FP16,不敏感层分配 INT8
3️⃣ 校准与优化:使用合适的校准策略确定量化参数
4️⃣ 验证与部署:在目标硬件上验证精度和性能
9.2 混合精度 vs 其他量化方案对比
# ============================================================
# 混合精度与其他量化方案的对比总结
# ============================================================
comparison_table = """
┌──────────────────┬──────────┬──────────┬──────────┬──────────┐
│ 量化方案 │ 内存占用 │ 计算速度 │ 精度损失 │ 实现难度 │
├──────────────────┼──────────┼──────────┼──────────┼──────────┤
│ FP32(基准) │ 100% │ 1.0x │ 0% │ 无 │
│ FP16(全精度) │ 50% │ 2.0x │ <0.5% │ 低 │
│ INT8(全量化) │ 25% │ 4-8x │ 1-3% │ 中 │
│ 混合精度 │ 30-40% │ 3-5x │ <1% │ 高 │
│ 二值化(XNOR) │ 3% │ 10-20x │ 5-10% │ 很高 │
└──────────────────┴──────────┴──────────┴──────────┴──────────┘
推荐场景:
• FP16:GPU 推理,精度要求高,硬件支持 Tensor Core
• INT8:移动端、边缘设备,对精度容忍度较高
• 混合精度:需要在精度和性能间精细平衡的场景(推荐!)
• 二值化:极端资源受限的场景(如物联网设备)
"""
print(comparison_table)
9.3 进阶方向与研究前沿
# ============================================================
# 混合精度量化的进阶方向
# ============================================================
advanced_directions = {
"1. 自动混合精度搜索(AutoMPQ)": {
"描述": "使用强化学习或进化算法自动搜索最优精度配置",
"代表工作": [
"HAQ (Heterogeneous Architecture Quantization)",
"DNAS (Differentiable Neural Architecture Search)",
"AutoQ (Automated Quantization)"
],
"优势": "无需手工设计,自动适应不同硬件",
"挑战": "搜索空间巨大,计算成本高"
},
"2. 动态混合精度(Dynamic Mixed Precision)": {
"描述": "根据输入数据动态调整每层的精度",
"应用场景": "处理不同难度的样本时自适应调整精度",
"优势": "简单样本用 INT8 快速处理,复杂样本用 FP16 保证精度",
"挑战": "需要在线精度预测,增加推理开销"
},
"3. 混合精度量化感知训练(Mixed-Precision QAT)": {
"描述": "在训练阶段就考虑混合精度量化",
"方法": "使用伪量化(fake quantization)进行训练",
"优势": "精度恢复更好,可达到 <0.5% 精度损失",
"代表工作": "QAT with Mixed Precision (PyTorch 官方支持)"
},
"4. 跨层量化(Cross-Layer Quantization)": {
"描述": "考虑层间的相互影响,而非独立量化每层",
"方法": "使用 Hessian 矩阵或二阶信息",
"优势": "更精确的敏感度分析,更优的精度-性能权衡",
"代表工作": "Hessian-based Quantization"
},
"5. 硬件感知的混合精度(Hardware-Aware MPQ)": {
"描述": "针对特定硬件平台优化混合精度配置",
"应用": "不同 NPU、DSP、GPU 有不同的最优配置",
"方法": "建立硬件性能模型,进行联合优化",
"代表工作": "TVM AutoTVM, TACO"
}
}
for direction, details in advanced_directions.items():
print(f"\n【{direction}】")
for key, value in details.items():
if isinstance(value, list):
print(f" {key}:")
for item in value:
print(f" • {item}")
else:
print(f" {key}: {value}")
十、实战代码总结与快速参考
10.1 混合精度量化的最小化工作流
# ============================================================
# 混合精度量化的最小化工作流(快速参考)
# ============================================================
def quick_start_mixed_precision_quantization():
"""
混合精度量化的最小化工作流
可直接复制使用
"""
# 步骤 1:加载模型和数据
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
calibration_images = load_images('calibration_dir', num=100)
# 步骤 2:敏感度分析
analyzer = LayerSensitivityAnalyzer(model.model)
sensitivity_scores = analyzer.analyze(calibration_images[0].unsqueeze(0))
# 步骤 3:生成混合精度配置
mixed_config = analyzer.get_mixed_precision_config(
sensitivity_threshold=20.0,
fp16_ratio=0.3
)
# 步骤 4:导出 ONNX
model.export(format='onnx', imgsz=640)
# 步骤 5:构建 TensorRT 混合精度引擎
sensitive_layers = [name for name, p in mixed_config.items() if p == 'fp16']
calibrator = YOLOv8Int8Calibrator(calibration_images)
builder = MixedPrecisionTRTBuilder('yolov8.onnx')
engine_path = builder.build_mixed_precision_engine(
calibrator=calibrator,
sensitive_layers=sensitive_layers,
output_path='yolov8_mixed.engine'
)
# 步骤 6:验证精度
trt_model = TensorRTPredictor(engine_path)
metrics = evaluate_yolov8(trt_model, test_loader)
print(f"✓ 混合精度量化完成!mAP: {metrics['mAP']:.4f}")
return engine_path
10.2 关键参数速查表
# ============================================================
# 混合精度量化的关键参数速查表
# ============================================================
parameter_guide = {
"敏感度分析": {
"SNR_threshold": {
"推荐值": "20 dB",
"说明": "SNR 低于此值的层视为敏感层,应使用 FP16",
"调整": "降低阈值 → 更多层用 FP16 → 精度更高但速度更慢"
},
"per_channel_quantization": {
"推荐值": "True",
"说明": "对权重使用逐通道量化,精度更高",
"硬件支持": "大多数现代硬件都支持"
}
},
"精度分配": {
"fp16_ratio": {
"推荐值": "0.2-0.4(20-40%)",
"说明": "FP16 层占总层数的比例",
"调整": "增加 → 精度更高但速度收益减少"
},
"sensitive_layers": {
"必须 FP16": ["Conv_0", "Detect", "Add"],
"可用 INT8": ["深层卷积", "池化层", "激活函数"]
}
},
"校准参数": {
"calibration_batch_size": {
"推荐值": "8-16",
"说明": "校准时的批大小",
"影响": "更大的批大小统计更准确,但需要更多内存"
},
"num_calibration_images": {
"推荐值": "100-500",
"说明": "校准图像数量",
"影响": "更多图像精度更高,但校准时间更长"
},
"calibration_method": {
"推荐值": "KL 散度(Entropy)",
"说明": "比 MinMax 校准精度更高",
"适用": "目标检测、分类等任务"
}
},
"TensorRT 参数": {
"workspace_size": {
"推荐值": "4-8 GB",
"说明": "构建引擎时的最大工作空间",
"影响": "更大的空间允许更多优化,但不影响推理内存"
},
"reduce_range": {
"推荐值": "True",
"说明": "将 INT8 范围缩小到 [-64, 63]",
"用途": "提高数值稳定性,避免溢出"
}
}
}
for category, params in parameter_guide.items():
print(f"\n【{category}】")
for param_name, param_info in params.items():
print(f" {param_name}:")
for key, value in param_info.items():
print(f" {key}: {value}")
十一、思考题与练习
# ============================================================
# 思考题与练习
# ============================================================
exercises = {
"思考题 1:为什么第一层卷积对量化特别敏感?": {
"提示": "考虑输入数据的分布特性和梯度流",
"答案": """
第一层卷积接收原始输入图像,其特征分布多样且动态范围大。
此外,梯度在反向传播时会经过所有后续层,第一层的量化误差
会被放大。因此第一层通常需要保持 FP16 或 FP32。
"""
},
"思考题 2:为什么残差连接附近的层容易溢出?": {
"提示": "考虑加法运算的数值特性",
"答案": """
残差连接执行 x + f(x) 的加法。如果 x 和 f(x) 的量化范围
不匹配,相加后可能超出 INT8 的 [-128, 127] 范围,导致溢出。
因此残差连接附近的层应使用 FP16 或启用 reduce_range。
"""
},
"思考题 3:如何在没有校准数据的情况下进行量化?": {
"提示": "考虑使用模型本身的信息",
"答案": """
可以使用 MinMax 校准(无需校准数据),但精度会下降。
更好的方法是使用训练集的一小部分作为校准集,或使用
量化感知训练(QAT)在训练阶段就考虑量化。
"""
},
"练习 1:实现一个简单的敏感度分析工具": {
"要求": """
基于提供的 LayerSensitivityAnalyzer 代码,实现以下功能:
1. 支持多种敏感度指标(SNR、KL 散度、梯度范数)
2. 生成敏感度热力图
3. 自动推荐混合精度配置
""",
"难度": "⭐⭐"
},
"练习 2:对比不同校准策略的效果": {
"要求": """
使用同一个模型,分别采用以下校准策略:
1. MinMax 校准
2. KL 散度校准
3. Percentile 校准
对比它们在精度和速度上的差异。
""",
"难度": "⭐⭐⭐"
},
"练习 3:实现硬件感知的混合精度优化": {
"要求": """
针对不同硬件平台(GPU、NPU、CPU),设计不同的混合精度配置。
考虑因素:
1. 硬件对 INT8 的支持程度
2. 不同精度的计算速度比
3. 内存带宽限制
""",
"难度": "⭐⭐⭐⭐"
}
}
for question, details in exercises.items():
print(f"\n【{question}】")
for key, value in details.items():
if key == "答案":
print(f" {key}:{value}")
else:
print(f" {key}: {value}")
总结
混合精度量化是现代深度学习模型部署的关键技术。通过为不同层分配不同的精度,我们能够在保持精度的同时获得显著的性能提升。
核心要点回顾:
✅ 混合精度量化的本质是精度与性能的科学权衡
✅ 敏感度分析是混合精度配置的基础,必须科学进行
✅ FP16 适合精度敏感层,INT8 适合计算密集层
✅ 校准数据的质量直接影响量化精度,需要精心选择
✅ TensorRT 是 NVIDIA 平台上混合精度量化的最佳实践
✅ 在目标硬件上验证是部署前的必要步骤
下一节我们将探讨RepVGG 重参数化技术:训练时多路,推理时单路,这是进一步提升量化精度的高级技术。敬请期待!
最后,希望本文围绕 YOLOv8 的实战讲解,能在以下几个方面对你有所帮助:
- 🎯 模型精度提升:通过结构改进、损失函数优化、数据增强策略等,实战提升检测效果;
- 🚀 推理速度优化:结合量化、裁剪、蒸馏、部署策略等手段,帮助你在实际业务中跑得更快;
- 🧩 工程级落地实践:从训练到部署的完整链路中,提供可直接复用或稍作改动即可迁移的方案。
PS:如果你按文中步骤对 YOLOv8 进行优化后,仍然遇到问题,请不必焦虑或抱怨。
YOLOv8 作为复杂的目标检测框架,效果会受到 硬件环境、数据集质量、任务定义、训练配置、部署平台 等多重因素影响。
如果你在实践过程中遇到:
- 新的报错 / Bug
- 精度难以提升
- 推理速度不达预期
欢迎把 报错信息 + 关键配置截图 / 代码片段 粘贴到评论区,我们可以一起分析原因、讨论可行的优化方向。
同时,如果你有更优的调参经验或结构改进思路,也非常欢迎分享出来,大家互相启发,共同完善 YOLOv8 的实战打法 🙌
🧧🧧 文末福利,等你来拿!🧧🧧
文中涉及的多数技术问题,来源于我在 YOLOv8 项目中的一线实践,部分案例也来自网络与读者反馈;如有版权相关问题,欢迎第一时间联系,我会尽快处理(修改或下线)。
部分思路与排查路径参考了全网技术社区与人工智能问答平台,在此也一并致谢。如果这些内容尚未完全解决你的问题,还请多一点理解——YOLOv8 的优化本身就是一个高度依赖场景与数据的工程问题,不存在“一招通杀”的方案。
如果你已经在自己的任务中摸索出更高效、更稳定的优化路径,非常鼓励你:
- 在评论区简要分享你的关键思路;
- 或者整理成教程 / 系列文章。
你的经验,可能正好就是其他开发者卡关许久所缺的那一环 💡
OK,本期关于 YOLOv8 优化与实战应用 的内容就先聊到这里。如果你还想进一步深入:
- 了解更多结构改进与训练技巧;
- 对比不同场景下的部署与加速策略;
- 系统构建一套属于自己的 YOLOv8 调优方法论;
欢迎继续查看专栏:《YOLOv8实战:从入门到深度优化》。
也期待这些内容,能在你的项目中真正落地见效,帮你少踩坑、多提效,下期再见 👋
码字不易,如果这篇文章对你有所启发或帮助,欢迎给我来个 一键三连(关注 + 点赞 + 收藏),这是我持续输出高质量内容的核心动力 💪
同时也推荐关注我的公众号 「猿圈奇妙屋」:
- 第一时间获取 YOLOv8 / 目标检测 / 多任务学习 等方向的进阶内容;
- 不定期分享与视觉算法、深度学习相关的最新优化方案与工程实战经验;
- 以及 BAT 等大厂面试题、技术书籍 PDF、工程模板与工具清单等实用资源。
期待在更多维度上和你一起进步,共同提升算法与工程能力 🔧🧠
🫵 Who am I?
我是专注于 计算机视觉 / 图像识别 / 深度学习工程落地 的讲师 & 技术博主,笔名 bug菌:
- 活跃于 CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等技术社区;
- CSDN 博客之星 Top30、华为云多年度十佳博主、掘金多年度人气作者 Top40;
- 掘金、InfoQ、51CTO 等平台签约及优质创作者,51CTO 年度博主 Top12;
- 全网粉丝累计 30w+。
更多系统化的学习路径与实战资料可以从这里进入 👉 点击获取更多精彩内容
硬核技术公众号 「猿圈奇妙屋」 欢迎你的加入,BAT 面经、4000G+ PDF 电子书、简历模版等通通可白嫖,你要做的只是——愿意来拿。

-End-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)