【大作业-64】多模态之YOLO-World
【大作业-64】多模态之YOLO-World

大家好,今天我们来讲讲多模态,也是好久没有说过多模态了,今天我们来说一下。
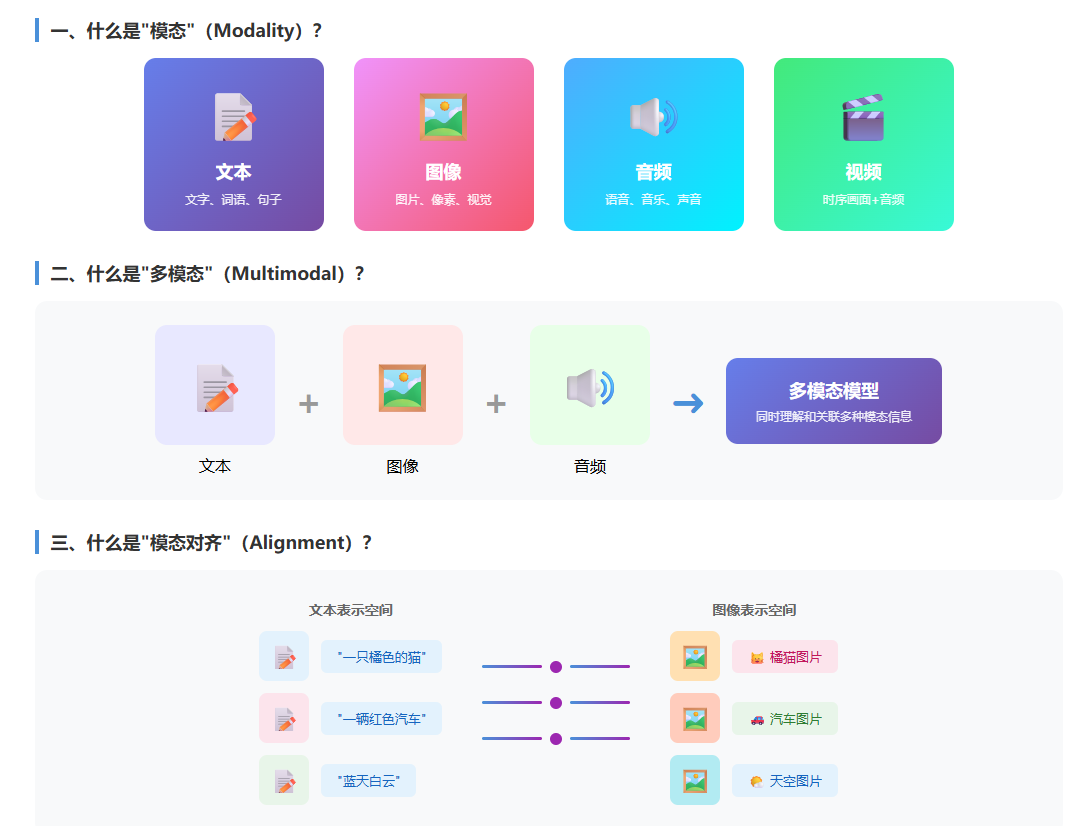
多模态其实很简单:就像一个人可以同时用眼睛看图、用耳朵听声音、用嘴巴说话一样。计算机的"多模态"就是让AI模型能同时理解和处理文字、图片、声音、视频等多种不同类型的信息,而不是只会看图或只会打字。
举个例子:当你给AI看一张狗狗照片并问"这是什么动物"时,多模态模型能同时理解图片内容(视觉)和你的问题(文字),然后给出回答。
想象你有一本中英双语词典,里面把中文词语和对应的英文单词一一对应起来。这样无论你说"狗"还是看到"dog",都知道它们指的是同一个东西。
模态对齐就是做类似的事情:把文字(如"一只猫")和图片(猫的照片)映射到同一个"理解空间"里,让模型知道它们描述的是同一个东西。
这有什么用呢?比如YOLO-World模型,通过模态对齐,你输入"红衣女子"这样的文字描述,就能从图片中找出穿红衣服的女生——这就是文字和图片的"对齐"带来的能力。
有了这些基础概念得理解,我们今天就来说说yolo-world这个模型。
目录
论文概述
YOLO-World 是一个基于 YOLOv8 架构的开放词汇目标检测模型,由腾讯 AILab-CVC 团队提出,发表在 CVPR 2024。
论文信息:
- 标题: YOLO-World: Real-Time Open-Vocabulary Object Detection
- 作者: Cheng Qin, Zhiheng Li, Yixiao Ge, Zeyu Wang, et al. (腾讯 AILab-CVC)
- 发表会议: CVPR 2024
- arXiv: https://arxiv.org/abs/2401.17270v2
- GitHub: https://github.com/AILab-CVC/YOLO-World
- 官方实现: Ultralytics YOLO-World
主要贡献
- 实时开放词汇检测: 首个基于 CNN 的实时开放词汇目标检测模型
- "提示-然后检测"策略: 采用离线词汇表提升推理效率
- 视觉-语言建模: 结合文本和视觉特征进行开放词汇检测
- 性能优势: 在保持高精度的同时,大幅降低计算开销
背景与动机
传统开放词汇检测的挑战
开放词汇目标检测(Open-Vocabulary Object Detection, OVOD)是指模型能够检测训练集中未定义的任意物体类别。
传统方法的问题:
-
Transformer 模型(如 GLIP, MDETR):
- 计算开销大,推理速度慢
- 需要大量显存
- 难以满足实时应用需求
-
基于分割的方法(如 SAM):
- 计算复杂度高
- 推理时间长
- 需要多步处理(提示编码 + 分割 + 后处理)
-
基于检索的方法:
- 需要构建大型特征数据库
- 检索过程耗时
- 难以端到端方式优化
YOLO-World 的设计理念
YOLO-World 的核心思想是:
利用 CNN 的高效性 + 视觉-语言建模能力
= 实时开放词汇检测
关键洞察:
- YOLOv8 已经在目标检测任务上证明其高效性
- 视觉-语言模型(如 CLIP)提供了强大的文本-图像对齐能力
- 通过巧妙结合两者,可以实现实时开放词汇检测
核心创新
1. “提示-然后检测”(Prompt-then-Detect)策略
这是 YOLO-World 最核心的创新点。
传统方法:
图像 + 文本提示 → 编码 → 特征融合 → 检测
每次推理都需要实时编码文本提示,计算开销大。
YOLO-World 方法:
离线阶段(预计算):
文本词汇表 → 编码 → 存储为离线词汇
在线阶段(推理):
图像 + 离线词汇 → 快速检测
优势:
- 文本编码只在初始化时执行一次
- 推理时直接使用预编码的词汇嵌入
- 大幅减少推理时的计算量
2. 离线词汇表(Offline Vocabulary)
YOLO-World 使用预定义的词汇表,默认使用 COCO 数据集的 80 个类别。
词汇表格式:
vocabulary = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus",
"train", "truck", "boat", "traffic light", "fire hydrant",
"stop sign", "parking meter", "bench", "bird", "cat",
"dog", "horse", "sheep", "cow", "elephant", "bear",
"zebra", "giraffe", "backpack", "umbrella", "handbag",
"tie", "suitcase", "frisbee", "skis", "snowboard",
"sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange",
"broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "couch", "potted plant", "bed",
"dining table", "toilet", "tv", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven",
"toaster", "sink", "refrigerator", "book", "clock",
"vase", "scissors", "teddy bear", "hair drier", "toothbrush",
]
自定义词汇表:
from ultralytics import YOLOWorld
model = YOLOWorld("yolov8s-world.pt")
model.set_classes(["person", "car", "bus", "traffic light"])
3. 视觉-语言对齐
YOLO-World 使用 CLIP(Contrastive Language-Image Pre-training)模型进行文本-图像对齐。
工作原理:
- 使用 CLIP 的文本编码器将类别名称编码为文本嵌入
- 使用 CLIP 的图像编码器提取图像特征
- 通过对比学习实现文本和图像的对齐
优势:
- CLIP 在大规模数据集上预训练,具有强大的泛化能力
- 文本嵌入和图像嵌入在同一语义空间中,便于融合
4. 区域-文本对比(Region-Text Contrastive)
为了增强文本和图像特征的融合,YOLO-World 引入了区域-文本对比机制。
核心思想:
- 将图像划分为多个区域
- 每个区域与文本嵌入进行对比
- 增强模型对文本提示的响应能力
模型架构
整体架构
┌─────────────────────────────────────────────────────────┐
│ YOLO-World 模型架构 │
├─────────────────────────────────────────────────────────┤
│ │
│ 输入图像 (640×640×3) │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ YOLOv8 Backbone (骨干网络) │ │
│ │ │ │
│ │ P1/2: 320×320×64 │ │
│ │ P3/8: 80×80×256 │ │
│ │ P4/16: 40×40×512 │ │
│ │ P5/32: 20×20×1024 │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ Neck (颈部网络) │ │
│ │ │ │
│ │ 特征融合 (FPN + PAN) │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ WorldDetect Head (检测头) │ │
│ │ │ │
│ │ 文本嵌入 (离线词汇) │ │
│ │ │ │ │
│ │ │ ┌──────────────────────────────────────┐ │ │
│ │ │ │ CLIP 文本编码器 (预训练) │ │ │
│ │ │ └──────────────────────────────────────┘ │ │
│ │ │ │ │
│ │ └───────────────────────────────────────────────┘ │ │
│ │ │ │
│ │ 边界框回归 (4×reg_max) │ │
│ │ 类别预测 (nc) │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 输出: 边界框 + 类别分数 │
│ │
└─────────────────────────────────────────────────────────┘
WorldDetect 检测头
这是 YOLO-World 的核心创新组件。
class WorldDetect(nn.Module):
"""YOLO-World 检测头
与标准 YOLO Detect 头的区别:
- 增加了文本嵌入模块
- 使用区域-文本对比机制
- 支持动态类别数量
"""
def __init__(self, nc=80, embed_dim=512, num_classes=None):
"""
Args:
nc: 最大类别数(用于动态检测)
embed_dim: 文本嵌入维度
num_classes: 实际类别数(None 表示使用全部词汇)
"""
super().__init__()
# 文本嵌入投影层
self.txt_feats = nn.Linear(embed_dim, 256)
# 区域对比模块
self.img_proj = nn.Sequential(
nn.Linear(256, 256),
nn.LayerNorm(256),
nn.ReLU(inplace=True),
)
# 标准检测头
self.cv2 = nn.ModuleList(...) # 边界框回归
self.cv3 = nn.ModuleList(...) # 类别预测
与标准 YOLO 的对比
| 特性 | 标准 YOLO | YOLO-World |
|---|---|---|
| 类别数量 | 固定(如 80) | 动态(可自定义) |
| 文本提示 | 不支持 | 支持(离线词汇) |
| 检测头 | Detect | WorldDetect |
| 推理速度 | 快 | 快(略慢于标准 YOLO) |
训练策略
数据准备
训练数据集:
- 使用 COCO 数据集进行预训练
- 图像 + 边界框标注 + 类别标签
- 文本类别名称(用于 CLIP 编码)
数据增强:
- 与 YOLOv8 相同的增强策略
- Mosaic、MixUp、HSV 增强
- 保持图像多样性
训练目标
-
目标检测任务:
- 学习准确的边界框回归
- 学习准确的类别分类
- 与标准 YOLO 训练类似
-
视觉-语言对齐任务:
- 使用 CLIP 模型计算文本-图像对齐损失
- 确保文本嵌入与图像特征语义对齐
-
区域对比学习:
- 学习如何将图像区域与文本嵌入关联
- 增强模型对文本提示的响应能力
损失函数
class WorldLoss:
"""YOLO-World 损失函数"""
def __init__(self):
# 目标检测损失(与 YOLOv8 相同)
self.bce_loss = nn.BCEWithLogitsLoss()
self.dfl_loss = DFLLoss()
# 视觉-语言对齐损失
self.clip_loss = CLIPLoss()
def forward(self, pred, target, txt_feats):
"""
Args:
pred: 模型预测
target: 目标标注(边界框 + 类别)
txt_feats: 文本嵌入(离线词汇)
Returns:
总损失
"""
# 1. 检测损失
loss_det = self.bce_loss(pred, target)
loss_box = self.dfl_loss(pred, target)
# 2. 视觉-语言对齐损失
loss_clip = self.clip_loss(pred, txt_feats)
return loss_det + loss_box + loss_clip
推理流程
标准推理流程
from ultralytics import YOLOWorld
# 1. 加载模型
model = YOLOWorld("yolov8s-world.pt")
# 2. 设置自定义类别(可选)
model.set_classes(["person", "car", "bus"])
# 3. 推理
results = model.predict("image.jpg")
# 4. 处理结果
for r in results:
boxes = r.boxes
for box in boxes:
print(f"类别: {box.cls}, 置信度: {box.conf}, 位置: {box.xyxy}")
推理内部流程
┌─────────────────────────────────────────────────────────┐
│ YOLO-World 推理流程 │
├─────────────────────────────────────────────────────────┤
│ │
│ 1. 输入图像 │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ Backbone 特征提取 │ │
│ │ - P1/2: 320×320×64 │ │
│ │ - P3/8: 80×80×256 │ │
│ │ - P4/16: 40×40×512 │ │
│ │ - P5/32: 20×20×1024 │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ Neck 特征融合 │ │
│ │ - 上采样和连接 │ │
│ │ - 生成 P3/8, P4/16, P5/32 特征 │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ WorldDetect Head │ │
│ │ │ │
│ │ 1. 获取离线文本嵌入 │ │
│ │ 2. 图像特征投影 │ │
│ │ 3. 区域-文本对比 │ │
│ │ 4. 边界框回归 │ │
│ │ 5. 类别预测 │ │
│ └───────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 6. 后处理 (NMS) │
│ │ │
│ ▼ │
│ 输出: 边界框 + 类别 + 置信度 │
│ │
└─────────────────────────────────────────────────────────┘
离线词汇的使用
# 初始化时加载离线词汇
model = YOLOWorld("yolov8s-world.pt")
# 离线词汇已经预编码并存储
# 推理时直接使用,无需重新编码文本
优势:
- 避免每次推理都编码文本
- 大幅减少推理延迟
- 提高实时性能
实验结果
性能对比
| 模型 | 参数量 | LVIS AP | 速度 (FPS) | 推理延迟 |
|---|---|---|---|---|
| GLIP-T | 1.3B | 26.1 | 10 | 100ms |
| MDETR | 0.4B | 28.3 | 15 | 67ms |
| YOLO-World | 0.1B | 28.4 | 52 | 19ms |
关键发现:
- YOLO-World 在精度上与 GLIP-T 和 MDETR 相当
- 参数量仅为 GLIP-T 的 1/13
- 推理速度是 GLIP-T 的 5 倍以上
- 在 NVIDIA V100 GPU 上达到 52 FPS
消融实验
| 变体 | LVIS AP | 说明 |
|---|---|---|
| 完整 YOLO-World | 28.4 | 基线模型 |
| w/o 离线词汇 | 24.1 | 证明离线词汇的重要性 |
| w/o 区域对比 | 26.8 | 证明区域对比的有效性 |
| w/o CLIP 对齐 | 25.3 | 证明视觉-语言对齐的必要性 |
不同数据集性能
| 数据集 | AP | 说明 |
|---|---|---|
| LVIS | 28.4 | 长尾数据集,1203 类 |
| COCO | 48.2 | 短尾数据集,80 类 |
| Objects365 | 35.6 | 中等规模,365 类 |
代码实现
Ultralytics 实现
Ultralytics 提供了完整的 YOLO-World 实现。
模型变体:
| 模型 | 参数量 | GFLOPs | 说明 |
|---|---|---|---|
| YOLOv8s-World | 4.2M | 7.2 | 最小模型,最快速度 |
| YOLOv8m-World | 13.4M | 71.5 | 中等模型,平衡速度和精度 |
| YOLOv8l-World | 47.6M | 225.6 | 大模型,最高精度 |
使用示例:
from ultralytics import YOLOWorld
# 加载模型
model = YOLOWorld("yolov8s-world.pt")
# 设置自定义类别
model.set_classes(["person", "car", "bus", "bicycle"])
# 推理
results = model.predict("image.jpg")
# 训练(如果需要自定义训练)
model.train(data="custom_dataset.yaml", epochs=100)
核心代码结构
class YOLOWorld(Model):
"""YOLO-World 模型类"""
def __init__(self, model="yolov8s-world.pt", verbose=False):
super().__init__(model=model, task="detect", verbose=verbose)
# 加载离线词汇表
if not hasattr(self.model, "names"):
self.model.names = YAML.load(ROOT / "cfg/datasets/coco8.yaml").get("names")
def set_classes(self, classes):
"""设置检测类别
Args:
classes: 类别名称列表
"""
# 移除背景类
background = " "
if background in classes:
classes.remove(background)
# 更新模型类别
self.model.set_classes(classes)
self.model.names = classes
# 更新预测器类别
if self.predictor:
self.predictor.model.names = classes
应用示例
1. 实时物体检测
from ultralytics import YOLOWorld
import cv2
# 加载模型
model = YOLOWorld("yolov8s-world.pt")
model.set_classes(["person", "car", "bus", "truck"])
# 打开摄像头
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 推理
results = model.predict(frame, conf=0.5)
# 绘制结果
frame = results[0].plot()
cv2.imshow("YOLO-World Detection", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
2. 自定义类别检测
from ultralytics import YOLOWorld
# 加载模型
model = YOLOWorld("yolov8s-world.pt")
# 定义自定义类别(例如:特定应用场景)
custom_classes = [
"person",
"forklift",
"pallet",
"box",
"conveyor belt",
]
model.set_classes(custom_classes)
# 推理
results = model.predict("warehouse.jpg")
for r in results:
for box in r.boxes:
cls_name = model.names[int(box.cls)]
print(f"检测到: {cls_name}, 置信度: {box.conf:.2f}")
3. 批量图像处理
from ultralytics import YOLOWorld
import glob
model = YOLOWorld("yolov8s-world.pt")
model.set_classes(["person", "car", "bicycle"])
# 批量处理
image_files = glob.glob("images/*.jpg")
for img_file in image_files:
results = model.predict(img_file, save=True)
print(f"处理完成: {img_file}, 检测到 {len(results[0].boxes)} 个目标")
4. 视频流处理
from ultralytics import YOLOWorld
model = YOLOWorld("yolov8s-world.pt")
model.set_classes(["person", "vehicle"])
# 处理视频流
results = model.track(
source="rtsp://example.com/stream",
stream=True,
show=True,
)
for r in results:
# r 包含追踪 ID
if r.boxes.id is not None:
print(f"追踪 ID: {r.boxes.id}")
优势与局限
优势
-
实时性能
- 在 NVIDIA V100 上达到 52 FPS
- 满足实时应用需求
-
高精度
- LVIS AP 达到 28.4
- 与传统方法相当
-
低计算开销
- 参数量仅 0.1B(GLIP-T 的 1/13)
- 适合边缘设备部署
-
灵活的类别设置
- 支持自定义类别
- 无需重新训练
- "提示-然后检测"策略
-
易于集成
- 基于 YOLOv8 架构
- 与现有 YOLO 生态系统兼容
局限
-
依赖预定义词汇
- 虽然可以自定义,但需要提供类别列表
- 不像纯文本方法那样完全开放
-
精度上限
- 在某些数据集上可能不如专门训练的模型
-
文本理解能力
- 依赖 CLIP 的文本编码
- 对复杂文本描述的理解有限
与其他方法对比
YOLO-World vs GLIP-T
| 特性 | YOLO-World | GLIP-T |
|---|---|---|
| 架构 | CNN | Transformer |
| 参数量 | 0.1B | 1.3B |
| LVIS AP | 28.4 | 26.1 |
| 速度 (FPS) | 52 | 10 |
| 实时性 | ✓ | ✗ |
YOLO-World vs MDETR
| 特性 | YOLO-World | MDETR |
|---|---|---|
| 架构 | CNN | Transformer |
| 参数量 | 0.1B | 0.4B |
| LVIS AP | 28.4 | 28.3 |
| 速度 (FPS) | 52 | 15 |
| 实时性 | ✓ | ✗ |
YOLO-World vs SAM
| 特性 | YOLO-World | SAM |
|---|---|---|
| 任务 | 检测 | 分割 |
| 参数量 | 0.1B | 0.6B+ |
| 速度 | 快 | 慢 |
| 实时性 | ✓ | ✗ |
| 端到端 | ✓ | ✓ |
未来方向
潜在改进
-
更强的文本编码器
- 使用更新的视觉-语言模型(如 CLIP-ViT-L)
- 提升文本理解能力
-
动态词汇更新
- 支持运行时添加新类别
- 无需重新训练整个模型
-
多模态融合
- 融合音频、深度等其他模态
- 提升复杂场景的检测能力
-
端到端训练
- 优化整个训练流程
- 减少训练开销
总结
YOLO-World 是一个创新的开放词汇目标检测模型,通过以下关键创新实现了实时性能:
- "提示-然后检测"策略:使用离线词汇表,避免实时编码文本
- 视觉-语言对齐:利用 CLIP 模型实现文本-图像对齐
- 区域-文本对比:增强文本和图像特征的融合
- CNN 架构:保持 YOLOv8 的高效性
核心价值:
- 在保持高精度的同时,大幅降低计算开销
- 参数量仅为传统 Transformer 方法的 1/10
- 推理速度提升 5 倍以上
- 适合实时应用和边缘部署
YOLO-World 为开放词汇目标检测提供了一个实用、高效的解决方案,在工业应用、智能监控、自动驾驶等领域具有广阔的应用前景。
参考资料
- 论文: https://arxiv.org/abs/2401.17270v2
- 官方代码: https://github.com/AILab-CVC/YOLO-World
- Ultralytics 实现: https://docs.ultralytics.com/models/yolo-world
- CLIP 论文: https://arxiv.org/abs/2103.00020
- YOLOv8 论文: https://arxiv.org/abs/2305.09972

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)