Chunked-Prefill介绍
写在前面:本文是对提出Chunked-Prefill的论文:SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills 的介绍,以下内容均基于个人理解,欢迎指正。
第一部分:核心痛点(SARATHI 要解决什么?)
在标准的 LLM 推理(迭代级调度)中,系统面临几个致命的效率黑洞:
1.P/D两阶段计算特点的割裂:
- 预填充 (Prefill): 计算密集型。哪怕 Batch=1,因为输入了极长的 Prompt,巨大的矩阵乘法能让 GPU 算力瞬间跑满。
- 解码 (Decode): 访存密集型。每次只生成 1 个 Token,矩阵乘法退化为向量乘法,GPU 绝大部分时间在干等数百 GB 的模型权重从显存搬运到计算核心。
2.传统迭代式调度的缺点:在传统的迭代式调度中,单次调度只能调度一种计算(P或D),并且P总是优先调度,nano-vLLM中的调度机制就是如此。这样导致的问题就是,如果突然来了一个超长的P,就会导致当前所有的D延迟大增,显然这是用户不能接受的。
3.流水线气泡 (Pipeline Bubbles): 在多卡流水线并行(PP)中,如果微批次(Micro-batch)的计算时间长短不一(比如一个批次全是长 Prefill,下一个全是短 Decode),会导致下游 GPU 陷入漫长的空转等待(气泡)。
注:原文中提到的痛点是本处的1和3。
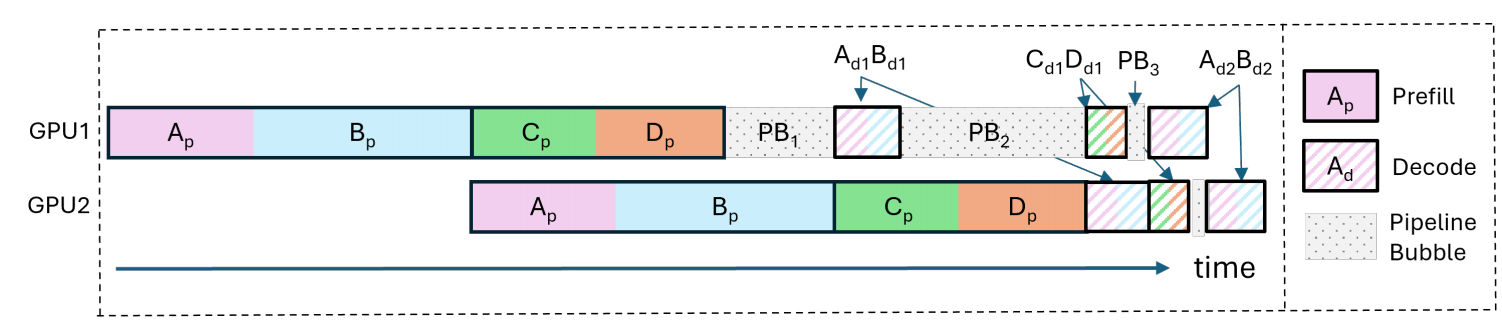
这里附上原文的图介绍下三种流水线气泡:
气泡的成因:三种不平衡 (PB1, PB2, PB3)
- PB1 (Prefill vs. Prefill 气泡):
- 成因: 连续两个微批次(Micro-batch)的预填充词元数量不同。
- 场景: 微批次 1 处理了一个 50 个词元的超短 Prompt,瞬间算完;微批次 2 处理了一个 2000 个词元的超长 Prompt,耗时极长。处理微批次 1 的下游 GPU 不得不陷入漫长的等待。
- PB2 (Prefill vs. Decode 气泡):
- 成因: 预填充阶段和解码阶段的绝对计算时间存在巨大差异。
- 场景: 流水线上,一个纯预填充的微批次(大矩阵乘法,算得久)紧挨着一个纯解码的微批次(小向量乘法,极其受限于访存,算得相对快或慢,取决于 Batch 大小)。这种任务性质的突变导致了流水线节拍的严重错乱。
- PB3 (Decode vs. Decode 气泡):
- 成因: 不同微批次之间,累积的上下文长度(KV Cache 长度)不同,导致解码耗时存在差异。
- 场景: 微批次 A 中的请求刚开始解码(历史 KV Cache 只有 100),算注意力很快;微批次 B 中的请求已经快生成完了(历史 KV Cache 高达 4000),算注意力需要搬运大量显存,耗时更长。
第二部分:SARATHI 核心机制(如何解决?)
SARATHI 的破局之道在于:强行打碎预填充,让解码任务“搭便车”(piggyback)。
1. 分块预填充 (Chunked-Prefills)
- 原理: 打破“一个请求必须一次性算完”的规矩。将超长的 Prompt(如 2000 个 Token)按固定大小(如 256)强行切分成多个 Chunk。
- 效果: 每一个 Chunk 成为一个新的、计算耗时绝对标准化的微批次,从而彻底消灭了多卡流水线并行中的气泡。
2. 解码最大化批处理 (Decode-Maximal Batching / "搭便车")
- 原理: 构建一个混合批次 (Hybrid Batch)。系统拿出一个 Prefill Chunk(确保 GPU 算力满载),然后把剩下的空余位置,全部塞满正在排队等待的 Decode 请求(搭便车)。
- 物理效果: Decode 任务巧妙地利用了 Prefill 加载庞大模型权重的访存窗口,顺手完成了自己的小矩阵乘法计算。单 Token 解码耗时断崖式下降(如从 12.49ms 降至 1.2ms),实现了近乎零成本的解码。
3. 底层算子调度
为了让混合批次能在 GPU 上跑通,SARATHI 在 CUDA 层面做了极致的调度:
- 合(融合线性层): 将 Prefill 的 Lp 个 Token 和 Decode 的 Bd 个独立 Token,在 Sequence 维度拼接成一个大矩阵 [Lp+Bd,H]。送入 GEMM 算子统一计算 Q,K,V 和 FFN,榨干 Tensor Core 算力。
- 分(分离注意力): 算出 Q,K,V 后,利用“指针偏移”将显存零拷贝切分。Prefill 送入 FlashAttention(算内部注意力),Decode 送入 PagedAttention(各自查历史 KV)。避免了不同逻辑在同一 Kernel 导致的线程分歧。
- 再合(同步机制): 两个并行的 Attention Kernel 跑完后,通过 CUDA Stream 和 Event 机制进行显式同步,将结果精准写回预分配的连续显存中,再次合并为 [Lp+Bd,H] 进入下一层。
注:3可以理解为为了实现1和2底层需要做的优化。
第三部分:关键参数的计算与选择
1.解码批次(Decode Batch)
可以与预填充块一起“搭便车”的最大解码批次大小,是基于可用的 GPU 显存 (MG)、模型每张 GPU 的参数内存需求 (MS) 以及模型支持的最大序列长度 (L) 来决定的。每个请求的预填充 (P) 和解码 (D) 词元总数不能超过这个最大序列长度。假设一个词元的一对 K 和 V 所需的内存为 mkv,则最大允许的批次大小 B 确定如下:
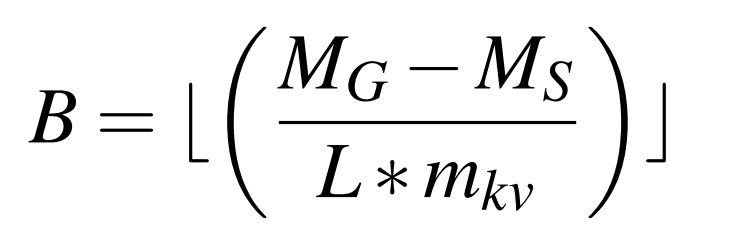
这个公式中算出的批次是不区分P和D的,可以看到这个B的计算方式是显存余量除以每个batch可能需要的最大的显存量,也就是说,在一个混合批次中,我们可以向其中放入一个P和(B-1)个D,这个是由硬件和模型决定的,与后面无关。
2. 块大小 (chunk size) 与 P:D 比例 (P:D Ratio)
这是一个经典的系统级权衡:
- P:D 比例: 当前批次中预填充 Token 数量与解码 Token 数量的比值。由真实的业务场景决定(比如代码补全场景 P 小 D 大,文档总结场景 P 大 D 小)。
- 选择逻辑:
- Chunk 越小: 能切出的块越多,能搭载的 Decode 乘客就越多。但如果 Chunk 太小(比如小于 128),Prefill 自身的矩阵乘法效率会下降,喂不饱 GPU。
- Chunk 越大: Prefill 效率极高,但能切出的块少,导致大量 Decode 任务搭不上车,只能回退到低效的单独解码。
- 结论: 调度器需要根据宏观的 P:D 预期,找到那个“牺牲极少 Prefill 性能,换取极大 Decode 吞吐量”的甜点值。换句话说,尽量让每个D都能搭上P的便车。
如何确定PD Ratio?
1.offline profiling:根据业务场景区分,不同的业务场景通常PD Ratio不一样。
2.online scheduling:调度时动态填缝。
3. Tile 量化效应 (Tile Quantization Effect)
- 原理: GPU 矩阵乘法是按二维网格(Tile,如 128×128)分配给线程块(Thread Block)执行的。
- 规则: 混合矩阵的行数 (Lp+Bd)必须是 Tile Size(如 128 或 256)的整数倍。
- 反面教材: 如果行数是 257,GPU 必须为其分配 3 个线程块,第 3 个线程块只算 1 行有效数据,剩下 127 行全在算零,导致多算 1 个 Token 耗时暴涨 32%。SARATHI 必须动态微调 Lp 以严格对齐这个倍数。
总结一下这个参数选取的逻辑:
首先,每个混合批次一次只能携带(B-1)个D,这个是由硬件和模型的特性决定的,是改变不了的,即:不论chunk size是多大,我们都只能在其中填入一个P和(B-1)个D。
在这种情况下,我们想让所有的D都搭上P的便车,就只能去调整chunk size,chunk size越小,分出来的chunk就越多,能携带的D就越多,但是chunk size过大过小都不好,存在着上面提到的权衡。
如何基于上面的前提选择chunk size又被分成了两步:1).基于PD Ratio确定。2).基于Tile量化效应微调。
第四部分:SARATH如何通过上面的机制解决上述痛点
痛点1:PD计算特点的分离
通过Chunked-Prefill和Decode-Maximal Batching机制,将每个batch构造成了混合batch, 每个batch都不会浪费GPU的算力资源。
痛点2:传统迭代式调度造成的D延迟过长
通过构造混合batch,让每次调度D都会和P一起执行,不会再会被P阻塞。
痛点3:PP中的流水线bubble
对抗 PB1:分块预填充 (Chunked-Prefills)
- 解决逻辑: SARATHI 拒绝处理长短不一的预填充任务。它将所有超长的 Prompt 强制切分成固定大小(例如 Lchunk=256)的块。
- 消除 PB1: 无论用户输入的是 50 个词还是 2000 个词,GPU 每次拿到手的预填充任务计算量全被标准化了。大家都是处理 256 个词元的矩阵乘法,耗时严丝合缝地对齐,PB1 彻底消失。
对抗 PB2 和 PB3:解码最大化批处理 (Decode-Maximal Batching)
- 解决逻辑: SARATHI 彻底消灭了“纯预填充批次”和“纯解码批次”的区别。它规定,每一个微批次都必须是一个“混合体”:一个标准的预填充块(Chunk) + 见缝插针塞进去的解码请求(搭便车)。
- 消除 PB2: 因为每个微批次现在的计算主体(耗时大头)都是那个固定大小的预填充 Chunk 带来的密集型 GEMM(矩阵乘法)计算,流水线再也不会出现“一会重、一会轻”的节拍突变。
- 消除 PB3: 虽然解码任务的 KV Cache 长度不同会导致轻微的耗时波动,但因为解码任务现在只是在预填充大矩阵计算读取权重的间隙“顺便”完成的,它极低的计算量和轻微的耗时波动,完全被庞大且稳定的预填充计算耗时给掩盖(吸收)了(D的计算量波动相比P的计算量不值一提)。
思考:为什么非得让每个D搭上P的便车?
原文中提到的最开始预想的chunk size是让GPU算力满载的最小的chunk size,意思是尽可能往大了选取chunk size,这样导致的结果是最后面的D会搭不上P的便车,只能单独组成解码批次,造成效率低下。其实原因还是因为D是访存密集型的,访存的时间要比计算时间多很多,这里访存不仅仅是KV Cache,还有模型参数,虽然P和D的KV Cache不能共享,但是模型参数是可以共享的,这里举一个Gemini生成的例子,不一定足够严谨,但是理解这个问题还是够用的:
方案 A:最大化 Prefill 效率
假设总共有 1536 个 Prefill Token,我们用大块切(Chunk = 512),切成 3 块。剩下排队等着搭车的 Decode 任务有 90 个,每趟车最多带 15 个。
第 1 阶段:3 个“大”混合批次 (512 Prefill + 15 Decode)
- 计算耗时:约 30 ms (Prefill) + 1 ms (Decode) = 31 ms。
- 搬运耗时:10 ms。
- 这趟车的真实耗时:max(10,31)=31 ms。
- 发 3 趟车:3×31=93 ms。
- 战果:算完了 1536 个 Prefill,但只拉走了 45 个 Decode,还有 45 个 Decode 在风中凌乱。
第 2 阶段:剩下的只能跑 3 个全 Decode 批次 (15 Decode)
- 计算耗时:1 ms。
- 搬运耗时:10 ms。
- 这趟车的真实耗时:max(10,1)=10 ms。(这里被访存卡死了,计算核心干等了 9 ms)
- 发 3 趟车:3×10=30 ms。
【方案 A 总账单】 总发车:6 趟。总耗时:93+30=123 ms。
方案 B:SARATHI 解码最大化
同样是 1536 个 Prefill Token,我们用小块切(Chunk = 256),切成 6 块。90 个 Decode 任务,每趟带 15 个。
唯一阶段:6 个“小”混合批次 (256 Prefill + 15 Decode)
- 计算耗时:约 15 ms (Prefill) + 1 ms (Decode) = 16 ms。
- 搬运耗时:10 ms。
- 这趟车的真实耗时:max(10,16)=16 ms。(完美的 Compute-bound!搬运时间的 10ms 被这 16ms 的计算时间完美掩盖/隐藏了。)
- 发 6 趟车:6×16=96 ms。
- 战果:算完了 1536 个 Prefill,并且完美拉走了所有 90 个 Decode!
【方案 B 总账单】 总发车:6 趟。总耗时:96 ms。
方案 A (123 ms) 比方案 B (96 ms) 慢了将近 30%。
总结一下本文的介绍:
SARATHI
|
|
├─────核心痛点
| ├──1.P、D两阶段计算特点的割裂
| ├──2.迭代式调度导致如果有一个长P请求,其他D请求的延迟暴涨
| └──3.传统PD调度在PP时会造成大量空泡
| └──三种bubble:……
|
├─────SARATHI的核心机制
| ├──1.分块预填充(ChunkedPrefill):把一个Prefill分成多个chunk,
| | 每一个chunk参与组成一个新的micro batch
| ├──2.解码最大化批处理(Decode-Maximal Batching):构建混合batch,
| | 每一个prefill搭配多个decode,让decode请求进行piggyback
| └──3.底层算子调度:将一个混合batch中的线性操作合并,PD的注意力
| 计算则分开进行,合->分->合
|
├─────一些核心参数的选取/计算
| ├──1.每次混合batch能携带的最多decode数:确保不会OOM
| └──2.chunk size:
| ├──1).通过PD Ratio设置,尽量让每个decode都能搭上prefill的便车
| └──2).根据tile量化效应,chunk size+decode batch size必须是
| tile size的整数倍
|
└─────如何通过ChunkedPrefill和Decode-Maximal Batching解决三个痛点
└──1.…… 2.…… 3.……
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)