【第三周】论文精读:GPS: Graph-guided Proactive Information Seeking in Large Language Models
前言:在检索增强生成(RAG)系统中,面对用户模糊或不完整的提问(Underspecified Queries),现有大语言模型(LLM)往往因缺乏领域知识而直接给出错误答案,或陷入低效的盲目追问。来自北京大学的研究团队提出了 GPS (Graph-guided Proactive Information Seeking),一种基于有向无环图(DAG)的两阶段主动信息寻求框架。GPS 创新性地从检索文档中显式提取条件推理规则构建 DAG,并通过动态遍历算法根据用户回答实时剪枝,从而以最小的交互轮次精准定位缺失信息。实验表明,GPS 在三个基准测试中平均成功率提升 7.5%,澄清效率提升 4.2%,显著优于现有的提示工程(Prompting)和微调(Fine-tuning)方法,为构建高可靠、高效率的交互式 RAG 系统提供了新范式。
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | GPS: Graph-guided Proactive Information Seeking in Large Language Models |
| 核心方法名 | GPS (Graph-guided Proactive Information Seeking) |
| 作者 | Ruiqing Li, Yifeng Xu, Xinke Jiang, et al. |
| 所属机构 | Peking University (National Engineering Research Center for Software Engineering), Nanhu Laboratory |
| 发表年份 | 2026 (ICLR Conference Paper) |
| 核心领域 | Proactive Clarification, RAG, Graph-based Reasoning, Reinforcement Learning |
| 关键数据集 | ConditionalQA, ShARC, Synthetic (Conditional Path Guided) |
| 代码开源 | GitHub - lrq111/GPS |
🔍 研究背景与痛点
1. 模糊查询的挑战
- 现实困境:用户常因缺乏领域知识或习惯省略细节,提出如“我有资格领取残疾津贴吗?”这类模糊问题。实际答案取决于收入、年龄、残疾程度等未声明的条件。
- 现有 RAG 的缺陷:传统 RAG 假设查询信息充分,直接基于检索文档生成答案,极易产生幻觉或误导性结论。
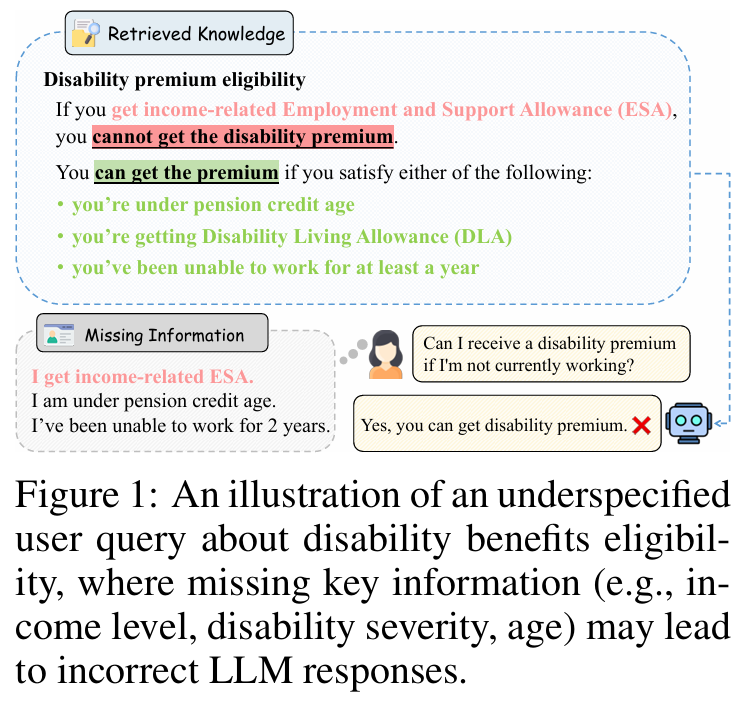
2. 现有澄清方法的局限
- 提示工程(Prompting):依赖 LLM 自身的推理能力识别歧义。小模型难以捕捉复杂逻辑,大模型易受长上下文干扰(Lost-in-the-middle),且缺乏结构化引导,容易问出无关问题。
- 微调方法(Fine-tuning):
- 数据稀缺:高
质量的多轮澄清对话数据标注成本极高。 - 搜索空间无序:自采样生成的数据缺乏对澄清路径的约束,导致模型学习到冗余或低效的提问策略。
- 数据稀缺:高
- 核心缺失:现有方法忽略了检索文档中隐含的基于规则的推理结构(如 if-then 逻辑链),这是解决歧义的关键。
3. GPS 的核心洞察
- 结构化推理:将文档中的条件规则显式建模为 DAG(有向无环图),理论上可表达任意布尔函数,确保逻辑完备性。
- 动态剪枝:利用 DAG 的拓扑结构,根据用户回答动态剪除不一致分支,将澄清复杂度从 O ( k ) O(k) O(k)(总条件数)降低至 O ( r ) O(r) O(r)(平均推理深度)。
- 效率与效果并重:通过强化学习优化 DAG 构建,同时追求答案正确性和交互轮次最小化。
🛠️ 核心方法:GPS 架构详解
GPS 是一个两阶段框架:推理阶段(Reasoning Stage)构建 DAG,澄清阶段(Clarification Stage)执行动态遍历。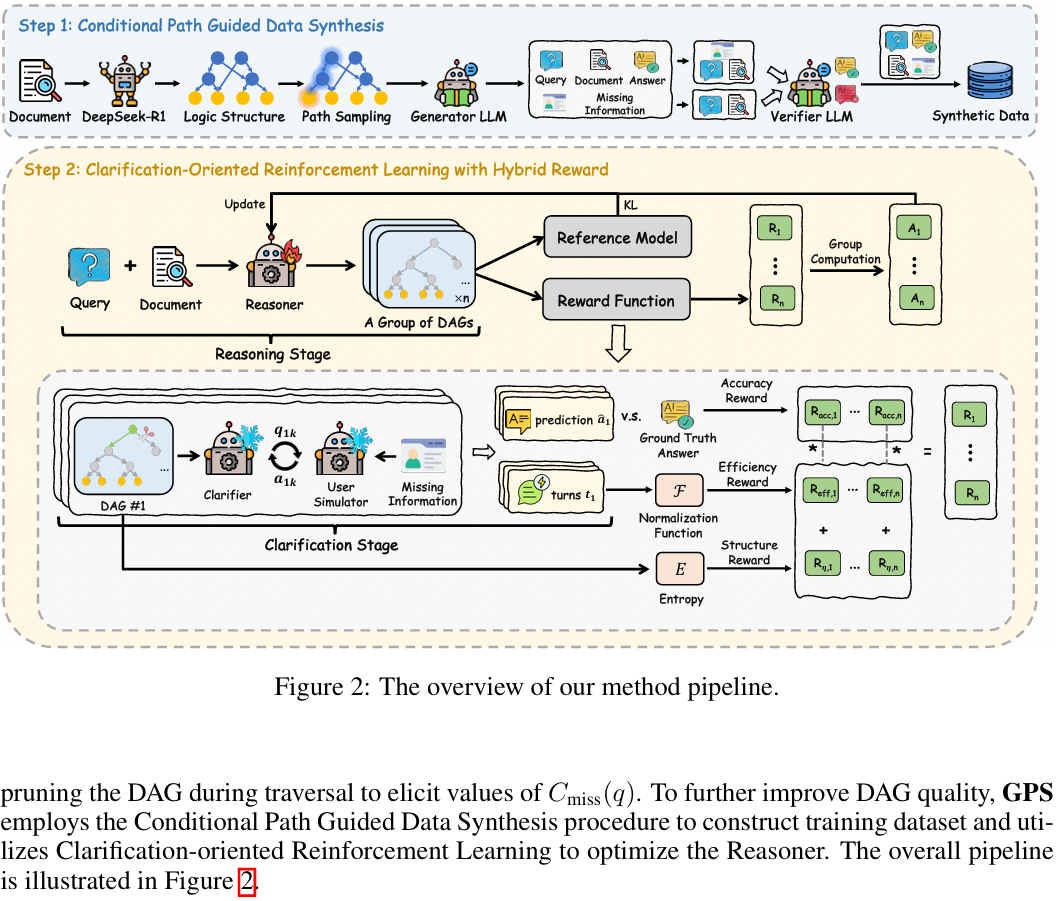
1. 阶段一:条件推理 DAG 构建
- 结构设计:
- 节点:非终端节点代表用户条件变量(如“是否领取 ESA”),终端节点代表最终答案(如“符合资格”)。
- 边:标记条件的具体取值(Yes/No 或多选)。
- 逻辑关系:单前驱隐含 AND 关系,多前驱隐含 OR 关系。
- 理论保证:论文证明了该 DAG 结构等价于析取范式(DNF),能够完整表达文档中的任意有限值函数逻辑。
- 数据合成(解决数据稀缺):
- 提出 Conditional Path Guided Data Synthesis 方法。
- 利用高级 LLM(如 DeepSeek-R1)从文档中生成包含多条件推理路径的模糊问答对。
- 验证过滤:仅保留那些“缺少条件时无法回答,提供条件后可正确回答”的高质量样本。
2. 阶段二:基于动态遍历的澄清
- 候选集选择:根据入度(In-degree)确定当前可询问的条件节点(即所有前驱已 resolved 的节点)。
- 启发式排序:计算每个候选节点的期望剩余深度,优先询问能最快导向结论的条件。
- 动态剪枝:
- 用户回答某个条件。
- 沿 DAG 中对应值的边前进。
- 剪除所有与该回答冲突的分支。
- 重复直到到达终端节点或无候选节点。
- 复杂度优势:平均交互轮次仅取决于真实推理路径长度 r r r,远小于文档中的总条件数 k k k。
3. 面向澄清的强化学习 (Clarification-Oriented RL)
为了优化 Reasoner 构建高质量 DAG 的能力,作者设计了基于 GRPO 的强化学习流程:
- 混合奖励函数 (Hybrid Reward):
- 有效性奖励 ( R a c c R_{acc} Racc):最终答案是否正确。
- 效率奖励 ( R e f f R_{eff} Reff):澄清轮次越少,奖励越高。
- 结构质量奖励 ( R η R_{\eta} Rη):基于信息转换效率。计算图的分裂熵( H g r a p h H_{graph} Hgraph)与叶子节点熵( H l e a f H_{leaf} Hleaf)的比值。鼓励模型构建“每次提问都能有效区分最终结论”的紧凑 DAG,惩罚冗余分支。
- 优化目标:联合最大化上述三项奖励,使模型学会构建既准确又高效的推理图。
🏆 实验结果与分析
作者在 Synthetic, ConditionalQA, ShARC 三个数据集上,使用 LLaMA3-8B 和 Qwen2.5-7B 进行了评估。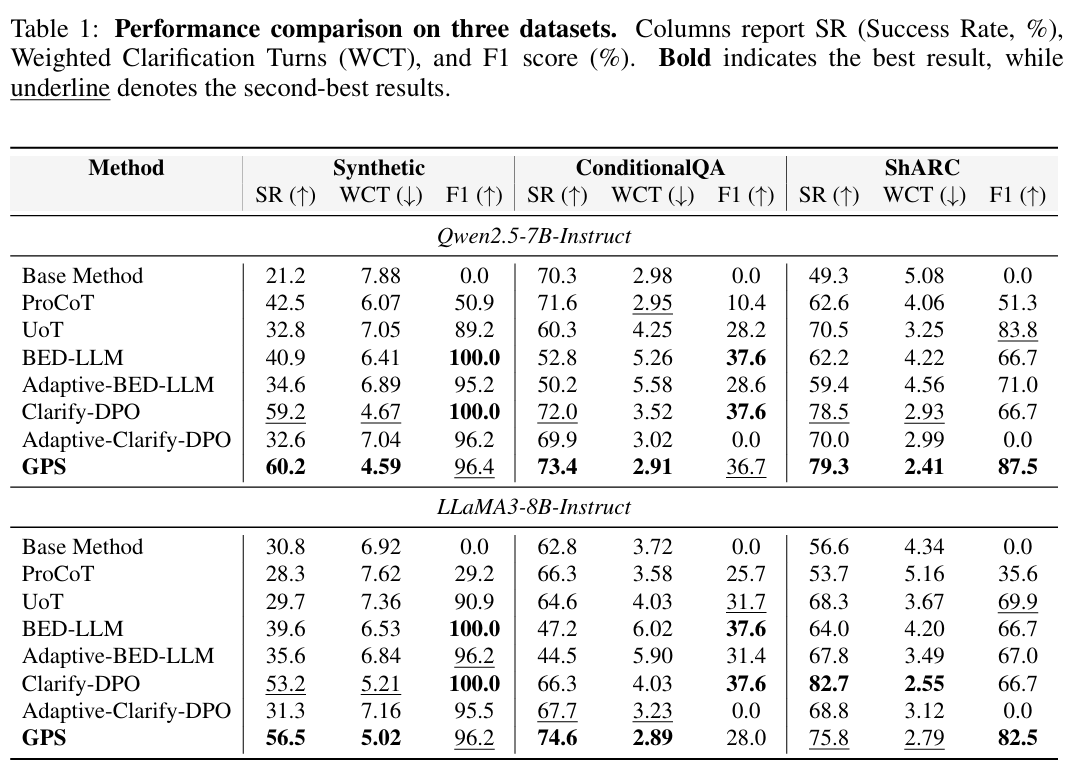
1. 性能全面超越 SOTA
- 成功率 (Success Rate, SR):
- GPS 在三个数据集上平均 SR 比次优方法高出 7.5%。
- 在 LLaMA3-8B 上,GPS 在 Synthetic 数据集达到 56.5%,远超 ProCoT (28.3%) 和 Base Method (30.8%)。
- 澄清效率 (Weighted Clarification Turns, WCT):
- 引入加权轮次指标(失败样本计入最大轮次惩罚),GPS 取得了最低的 WCT,表明其在保证正确性的前提下交互成本最低。
- 平均效率提升 4.2%。
2. 泛化能力强劲
- 跨域表现:在 ShARC 数据集(短文档、Yes/No 问答)上,尽管 GPS 未在 ShARC 上直接训练(主要用 ConditionalQA 合成数据),其表现仍与专门在该数据上训练的 Clarify-DPO 相当甚至更优,证明了 DAG 结构的强泛化性。
- 小模型赋能:即使是 7B/8B 级别的小模型,配合 GPS 框架也能展现出超越大模型 Prompting 的澄清能力。
3. 消融实验关键发现
- RL 的必要性:移除 RL(w/o RL)导致 SR 显著下降,WCT 上升,证明混合奖励对优化 DAG 结构至关重要。
- 结构质量奖励的作用:移除 R η R_{\eta} Rη 会导致模型构建冗余图,增加不必要的澄清轮次。
- 动态遍历的价值:固定顺序遍历相比动态剪枝,效率明显降低。
4. 案例分析 (Qualitative Analysis)
- 对比 Clarify-DPO:基线方法往往遗漏关键条件(如“是否领取 ESA”),导致直接给出错误结论。GPS 通过 DAG 强制覆盖所有逻辑分支,成功识别并询问了该关键条件,得出正确答案。
- 对比 UoT:UoT 基于不确定性提问,常在获取部分信息后过早停止。GPS 则严格遵循 DAG 路径,确保所有必要条件都被核实。
💡 主要创新点总结
-
首创图引导的主动澄清框架:
- 首次将条件推理 DAG引入 RAG 澄清任务,将非结构化的对话问题转化为结构化的图遍历问题,确保了逻辑的完备性。
-
理论驱动的动态剪枝算法:
- 证明了 DAG 表示的逻辑完备性,并设计了 O ( r ) O(r) O(r) 复杂度的动态遍历算法,从根本上解决了多条件场景下的交互效率瓶颈。
-
信息转换效率奖励机制:
- 创新性地提出基于熵的结构质量奖励 ( R η R_{\eta} Rη),量化了中间提问对最终结论的区分度,引导模型学习“少而精”的提问策略。
-
路径引导的数据合成流水线:
- 提出了一套自动化的数据合成与验证方案,有效解决了澄清任务训练数据稀缺的难题,使得在小模型上微调成为可能。
⚠️ 局限性与挑战
- DAG 构建依赖:整体效果高度依赖 Reasoner 构建 DAG 的准确性。如果文档逻辑极其复杂或表述混乱,DAG 构建失败会导致后续澄清全盘皆输。
- 计算开销:虽然交互轮次减少,但在推理阶段需要 LLM 生成结构化的 DAG JSON,增加了首字延迟(Time to First Token)。
- 领域适应性:对于非规则类文档(如叙事性文本、情感分析),条件逻辑不明显,DAG 构建的优势可能无法体现。
📝 总结与工程建议
《GPS》为解决 RAG 系统中的模糊查询问题提供了一套严谨且高效的解决方案。它证明了结构化推理结合强化学习可以显著提升小模型在复杂交互任务中的表现。
🚀 对开发者的实战建议:
-
引入结构化中间表示:
- 在处理政策、法规、医疗指南等强逻辑文档时,不要直接让 LLM 生成回答。先让 LLM 提取决策树或状态机(类似 DAG),再基于此结构进行交互。
-
实施动态剪枝策略:
- 在多轮对话中,维护一个“待确认条件池”。每获得一个用户反馈,立即更新内部状态并剔除不可能的路径,避免重复询问或询问无关条件。
-
优化奖励函数设计:
- 若使用 RL 微调澄清模型,务必在奖励函数中加入效率惩罚(轮次越多扣分越多)和信息增益奖励,防止模型学会“废话文学”或过度谨慎。
-
自动化数据构建:
- 利用大模型(如 DeepSeek-R1, GPT-4)从现有文档中反向合成“模糊问答对”,并通过“掩码验证”(Masked Verification)筛选高质量数据,低成本构建垂直领域的澄清数据集。
-
混合架构思维:
- 对于简单问题直接使用 Base RAG;对于检测到高不确定性的问题,切换至 GPS 模式进行主动澄清,实现成本与体验的平衡。
一句话总结:GPS 通过“DAG 结构化推理 + 动态剪枝遍历 + 效率导向 RL”的组合拳,实现了 RAG 系统在模糊查询场景下准确率与交互效率的双重飞跃,是构建下一代智能问答助手的关键技术参考。
参考文献:
[1] Li R, Xu Y, Jiang X, et al. GPS: Graph-guided Proactive Information Seeking in Large Language Models[C]//The Thirteenth International Conference on Learning Representations (ICLR). 2026.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)