11 deepseek介绍
一句话定位:
DeepSeek 是由中国杭州深度求索(DeepSeek)团队推出的开源高性能大语言模型系列,以 高推理能力、低训练成本、强中文支持 为核心优势,在数学、代码、长文本等任务上媲美甚至超越国际顶尖模型(如 GPT-4、Claude 3.5),成为国产大模型的重要代表。
一、背景:为什么需要 DeepSeek?
1. 行业痛点
- 算力封锁:中国无法获得英伟达 A100/H100,只能使用降频版 H800;
- 成本高昂:千亿参数稠密模型训练动辄数千万美元;
- 推理弱化:多数开源模型重生成轻推理(如 LLaMA 擅长写文但不会解题);
- 中文短板:国际主流模型在中文理解、古文、专业术语上表现不足。
2. DeepSeek 的使命
“在受限算力下,构建一个高效、可扩展、强推理的通用认知智能系统。”
依托母公司幻方量化(知名对冲基金)的算力积累与 AI 投入(2021 年起投入超 1.4 亿美元),DeepSeek 团队从 2023 年启动研发,目标直指 推理型大模型(Reasoning LLM)。
二、核心挑战:DeepSeek 要解决哪些难题?
| 难题 | 具体表现 |
|---|---|
| 1. 算力受限下的性能突破 | 如何用 H800 集群(非 A100)训练出媲美 GPT-4 的模型? |
| 2. 推理能力 vs 生成流畅性的平衡 | 多数模型“会说人话但不会思考”,如何让 AI 真正具备深度推理? |
| 3. 长上下文高效处理 | 支持 128K+ 上下文的同时,保持低延迟与高精度? |
| 4. 中文与多模态能力强化 | 如何在中文语境、古文、专业领域(金融、医疗)建立壁垒? |
| 5. 开源与商业化的协同 | 如何通过开源吸引生态,同时支撑企业级 API 服务? |
三、关键技术方案:DeepSeek
1. 架构创新:混合专家(MoE) + 动态稀疏激活
- 模型结构:DeepSeek-V3 采用 Hierarchical MoE 架构:
- 总参数:671B
- 每 token 激活参数:仅 37B(约 5.5%)
- 每层含 256 个专家 + 1 个共享专家
- 优势:
- ✅ 推理速度比稠密模型快 3~5 倍;
- ✅ 训练成本降低 40%+;
- ✅ 支持专业化分工(如数学专家、代码专家)。
💡 面试考点:MoE 不是简单堆参数,而是通过动态路由实现“按需调用专家”,兼顾容量与效率。
MoE(Mixture of Experts)是一种网络层结构, 网络层主要包括三部分:
- 专家网络(Expert Network):是一个前馈网络,逻辑上一个专家网络擅长处理一类专项的子任务,所有专家都接受相同的输入,来做特定计算处理,产出不同的输出。
- 门控网络(Gating Network):跟专家网络接收一样的输入,负责产出专家偏好的权重。来指示对于一个输入,不同专家的重要程度。
- 选择器(selector):是一种根据专家权重来做专家选择的策略。可以选择权重最高的Top1专家或选择TopK专家来融合得到最终的结果。
DeepSeek 的主要改动点,就是把专家分成了两拨,分别是 Shared Expert 和 Routed Expert。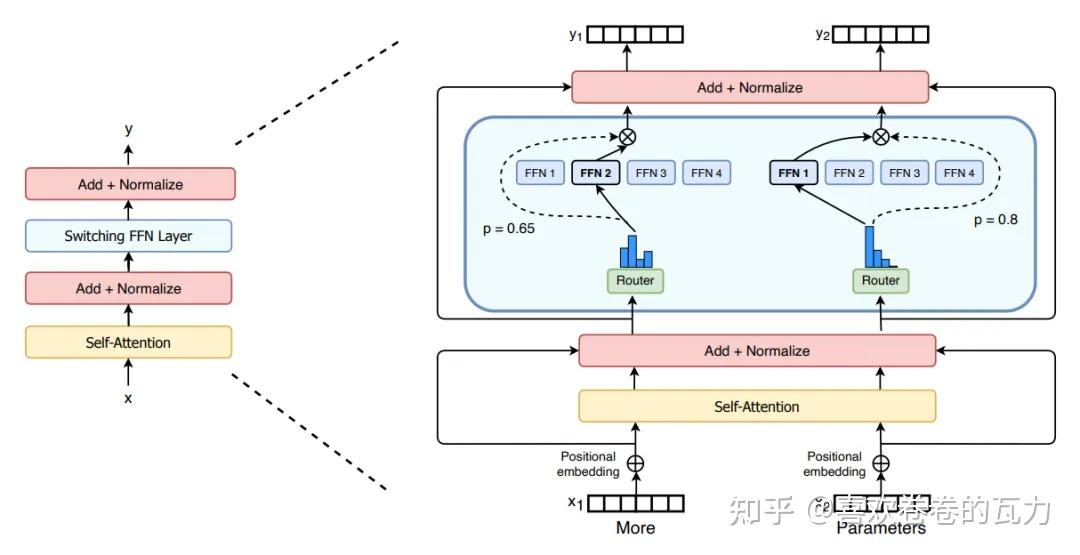
通俗来讲,就好比学校的常驻教授和客座教授,常驻教授是一直在的,而客座教授则经常会变,不同的教学主题,有不同的客座教授。
在 DeepSeek 的 MoE 中,稀疏 MoE 层一般用来替代传统 Transformer 模型中的前馈网络 (FFN) 层。其中Shared Expert 是一直激活的,也就是输入的 token 会被 Shared Expert 计算,Routed Expert 和普通的 MoE 一样,要先计算相似度,也就是专家的得分,再选择 top-k 进行推理。但是我们分析 DeepSeek 的源码可以发现,代码实际在计算 top-k 时,会先将 N 个 Expert 进行分组 n_groups,将每个组中 top-2 个专家的相似度得分加起来,算出得分最高的那些 top_k_group 组,然后在这些组里选择 top-k 个专家。最后将所有的 Shared Expert 输出和 Routed Expert 输出做加权相加,得到 MoE 层的最终输出。这里 Deepseek-v3 和 Deepseek-R1 采用了 256 个 Routed Expert 和 1个 Shared Expert,并在 Router 中选出 8 个来,参数量是 671B,而实际激活的参数量只有 37B。
3.1 专家选择流程(Step-by-Step)
以 DeepSeek-V3 为例(256 专家,Top-2 激活):
步骤 1️⃣:输入 token 的隐藏状态
- 当前 token 经过 Attention 后的表示为:
x∈Rd(d=5120) x \in \mathbb{R}^{d} \quad (d = 5120) x∈Rd(d=5120)
步骤 2️⃣:路由网络计算 logits
- 路由网络是一个线性层:
logits=Wg⋅x∈RN,N=256 \text{logits} = W_g \cdot x \in \mathbb{R}^{N}, \quad N = 256 logits=Wg⋅x∈RN,N=256- $ W_g \in \mathbb{R}^{256 \times d} $:可学习的路由权重矩阵
步骤 3️⃣:添加噪声(仅训练时)
- 训练时加入高斯噪声防止过早收敛:
noisy_logits=logits+ϵ,ϵ∼N(0,σ2) \text{noisy\_logits} = \text{logits} + \epsilon, \quad \epsilon \sim \mathcal{N}(0, \sigma^2) noisy_logits=logits+ϵ,ϵ∼N(0,σ2)- 推理时 不加噪声
步骤 4️⃣:选择 Top-K 专家
- 取分数最高的 K=2 个专家:
topk_indices=TopK(noisy_logits,K=2) \text{topk\_indices} = \text{TopK}(\text{noisy\_logits}, K=2) topk_indices=TopK(noisy_logits,K=2)- 示例:
[128, 45]
- 示例:
步骤 5️⃣:计算 softmax 权重
- 对 top-K 分数做 softmax:
weights=Softmax(topk_logits)∈R2 \text{weights} = \text{Softmax}(\text{topk\_logits}) \in \mathbb{R}^{2} weights=Softmax(topk_logits)∈R2- 示例:
[0.62, 0.38]
- 示例:
步骤 6️⃣:调度并融合输出
- 调用选中的专家和共享专家:
y=w1⋅E128(x)+w2⋅E45(x)+Eshared(x) y = w_1 \cdot E_{128}(x) + w_2 \cdot E_{45}(x) + E_{\text{shared}}(x) y=w1⋅E128(x)+w2⋅E45(x)+Eshared(x)
ref : https://zhuanlan.zhihu.com/p/21208287743

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)