从 LLM 到 Agent Skill,一篇文章带你打通底层逻辑!
最近 AI 圈子里,新名词层出不穷:
LLM、Token、Context、Context Window、Prompt、Tool、MCP、Agent、Agent Skill……
这些词你大概率都听过。刷文章会看到,刷视频会看到,听别人分享也会看到。
但我想问一个很直接的问题:
你真的能准确说清楚它们分别是什么意思吗?
更进一步说,你真的知道它们在一个 AI 系统里,各自扮演什么角色吗?
很多人其实并不清楚。
表面上看,好像大家都在聊 AI。可一旦深入一点,你就会发现,很多讨论其实都停留在“听过名词”的层面:
-
知道 LLM 很火,但说不清它本质上在干什么
-
知道 Token 很重要,但不知道为什么一长段话会那么费 Token
-
知道 Prompt 影响回答质量,但不理解 System Prompt 和 User Prompt 的区别
-
知道 Agent 很高级,但不清楚它和普通聊天机器人到底差在哪里
-
知道 MCP 很火,却不知道它其实解决的是“工具接入标准”的问题
所以这篇文章,不讲商业概念。不谈“AI 将重塑未来”,也不谈“下一代生产力革命”这种大词。只做一件事:
从最底层的工程视角出发,把这几个概念一一讲清楚。
你看完之后,最大的变化不是你又多记住了几个术语。而是你会第一次真正看懂:今天大多数 AI 产品,底层到底是怎么运作的。
不喜欢看文字,想看视频的朋友们可以移步视频号。
视频来源:马克的工作坊
https://www.youtube.com/watch?v=7qO8-kx3gW8
一、先从最底层开始:LLM
1. 什么是 LLM
LLM 全称 Large Language Model,翻译成中文就是:
大语言模型
平时大家也会直接叫它:
大模型
从字面上理解:
- Large
:规模很大,参数很多,训练数据也很多
- Language
:处理语言,包括自然语言、代码、符号等
- Model
:它归根到底是一个数学模型
所以,LLM 不是“电子大脑”这种玄学概念。
更准确地说,它是一个超大规模的语言建模系统。
2. 现在的大模型,几乎都站在 Transformer 之上
今天主流的大模型,基本都是基于 Transformer 架构训练出来的。
如果你看过 Transformer 的那张经典结构图,大概率会有一种感觉:
看不懂,但大受震撼。
这很正常。
因为那张图本来就不是给零基础读者一眼看懂的。
今天我们也不打算展开讲它的数学细节,比如:
-
Self-Attention 怎么算
-
Q、K、V 到底代表什么
-
多头注意力为什么有效
-
前馈层、残差连接、LayerNorm 又分别在干什么
这些内容当然重要,但不是今天的重点。
你现在只需要先记住一句话:
大模型的核心底层引擎,就是 Transformer。
3. Transformer 是谁提出来的?
Transformer 架构最早是由 Google 团队在 2017 年提出的。
那篇论文的名字非常有名:
Attention Is All You Need
可以说,今天这波生成式 AI 大爆发,技术火种就是从这里点起来的。
但技术史里常常有个很有意思的现象:
-
发明火种的人,不一定是把世界点燃的人
-
开创架构的人,不一定是让全球用户真正感受到冲击的人
Google 提出了 Transformer,
而真正把“大模型”这件事推向全球、推向大众视野的,是 OpenAI。
4. 为什么 GPT 系列会成为一个时代节点?
大家应该都记得,2022 年底 GPT-3.5 出现时,很多人第一次真正感受到:
原来 AI 已经不是实验室里的概念了。
它不是简单地回答几个模板化问题,
而是真的能:
-
聊天
-
写代码
-
改文案
-
总结资料
-
解释概念
-
帮人完成实际任务
这和过去那种“智能客服式”的体验,完全不是一个量级。
接着在 2023 年 3 月,GPT-4 发布。
这一步,又把大家对 AI 能力上限的认知整体往上抬了一层。
所以你会发现,GPT 系列的意义不只是“模型更强了”,而是:
它让全世界第一次大规模意识到:大模型是一个通用平台级能力。
5. 如今已经不是 OpenAI 一家独大
当然,现在的 AI 世界早就不是 OpenAI 的独角戏了。
后面陆续出现了很多强力选手,比如:
-
Claude
-
Gemini
-
各种开源模型
-
各类垂直场景模型
它们在不同方向上各有优势:
-
有的擅长长上下文
-
有的擅长代码生成
-
有的擅长工具调用
-
有的擅长多模态
-
有的擅长企业落地
这说明一件事:
今天的大模型竞争,已经从“谁先做出来”进入到“谁在哪些场景更强”的阶段。
6. LLM 的本质,其实非常朴素
很多人第一次接触 AI,会下意识把它想得很神秘。
但如果你从最底层原理去看,会发现它的本质其实很朴素:
它就是在做“下一个 Token 预测”。
也就是说,大模型的核心任务不是“理解世界”,
而是根据当前已经看到的内容,去预测:
下一个最可能出现的 Token 是什么。
举个最简单的例子
假设你问模型一句话:
繁光的文章怎么样?
模型不会一下子把整句回答全部想好再吐出来。
它真正的工作方式更像这样:
第一步,它看着输入内容,预测下一个最可能出现的 Token。
比如它预测出:
特别
然后,它把这个“特别”重新拼回上下文里。
输入就变成了:
繁光的文章怎么样 特别
接着它再继续预测下一个 Token。
比如预测出:
得
然后再拼回去。
继续预测:
棒
于是,回答就一步一步长出来了:
特别得棒
等它觉得该说的话说完了,就会输出一个结束标记,整段回答到此结束。
7. 为什么 AI 总是一个字一个词往外冒?
因为它本来就是这么工作的。
它不是先写完一整篇文章,然后再一次性显示给你。
它是:
-
先看当前输入
-
预测下一个 Token
-
把这个 Token 接回去
-
再继续预测下一个
-
如此循环,直到结束
这也是为什么很多 AI 产品都支持“流式输出”。
因为这不是表演形式,而是它的真实生成机制。
二、Token:大模型真正处理的,不是“词”,而是 Token
刚才为了让大家容易理解,我们用了“一个词一个词生成”的说法。
但严格来讲,大模型真正处理的,不是词,而是:
Token
这是理解大模型最重要的基础概念之一。
1. 为什么模型不能直接处理文字?
因为模型本质上是个数学系统。
它内部做的是:
-
向量运算
-
矩阵乘法
-
概率分布计算
它认识的是数字,不是汉字,不是英文,不是代码字符本身。
所以在人类文字和模型之间,必须有一个“翻译层”。
这个翻译层就是:
Tokenizer
2. Tokenizer 是干什么的?
Tokenizer 负责两件事情:
1)编码 (Encode)
把人类的文字转换成模型能处理的数字。
2)解码 (Decode)
把模型输出的数字,再还原成人类能读懂的文字。
你可以把它理解成一个双向翻译官。
-
人类说的是自然语言
-
模型吃的是数字序列
-
Tokenizer 负责来回转换
3. Token 是怎么来的?
还是用前面的句子举例:
繁光的文章怎么样
Tokenizer 在编码时,一般会做两步:
第一步:切分
把这句话拆成一个一个最小片段。
这些片段就叫 Token。
第二步:映射
再把每个 Token 映射成一个数字。
这个数字叫 Token ID。
于是:
-
Token 是文本层面的单位
-
Token ID 是数值层面的编号
最后,模型真正接收到的,不是这句汉字本身,而是一串 Token ID。
4. 模型输出时也是一样的
模型内部一通计算之后,吐出来的仍然不是“文字”,
而是一个新的 Token ID。
然后 Tokenizer 再把这个 Token ID 解码成对应的文本,
你才会在界面里看到一个字、一个词、一个符号。
所以,从头到尾,大模型真正处理的基本单位都不是“句子”,也不是“词语”,而是:
Token
5. 很多人会误会:Token 不就是词吗?
不是。
这是一个非常常见、但也非常关键的误解。
Token 和“词”不是一一对应的关系。
有时候它们看起来像一样,那只是碰巧。
比如:
繁光的文章怎么样
这个例子里,它可能正好被切成:
-
繁光
-
的
-
文章
-
怎么样
这会让人误以为:
“哦,原来一个词就是一个 Token。”
但换个例子你就会发现不是这样。
6. 为什么 Token 不等于词?
例如这句话:
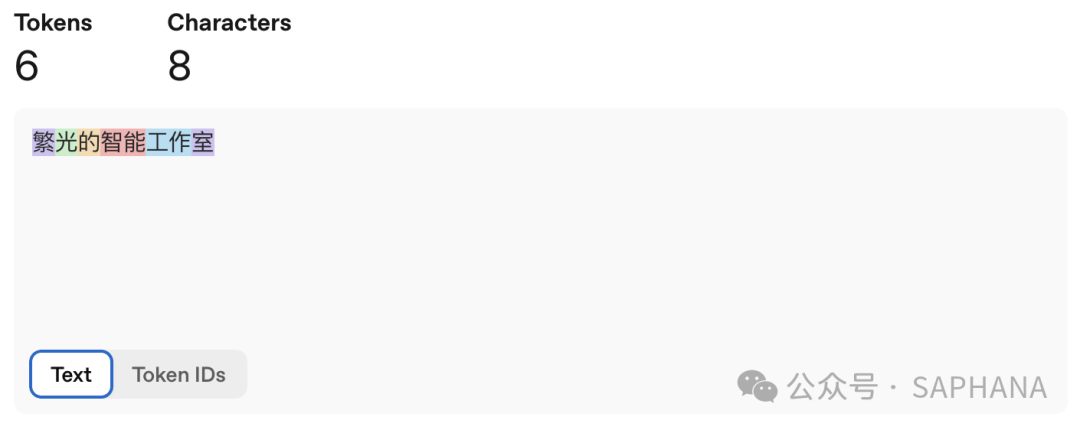
繁光的智能工作室
从人的直觉出发,可能会觉得可以切成:
-
繁光
-
的
-
智能
-
工作室
但在很多 Tokenizer 里,“工作室”并不一定是一个 Token,
它可能会被拆成:
-
工作
-
室
于是总共就变成了 6 个 Token,而不是 4 个。
再比如:
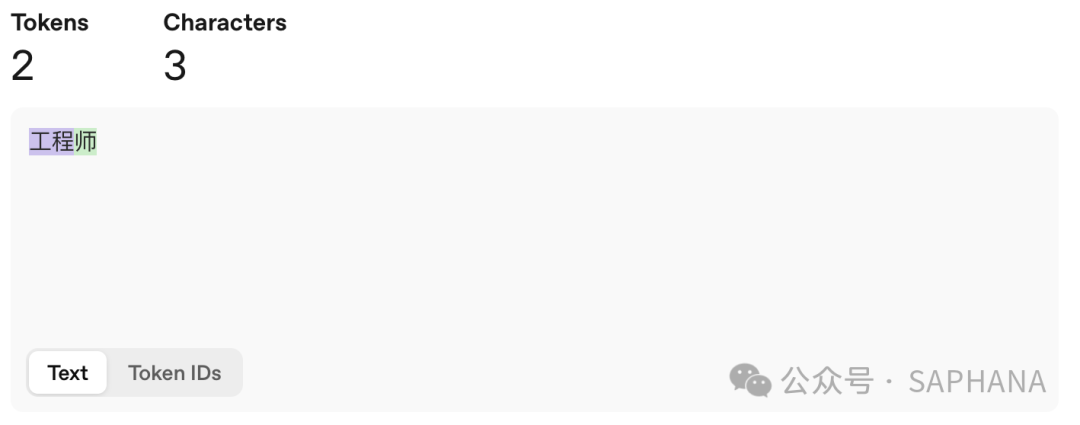
工程师
从语义上讲,这是个完整的词。
但在 Tokenizer 眼里,它也可能被拆成:
-
工程
-
师
也就是说:
词是人类语言学上的概念,Token 是模型为了计算方便学出来的一套切分规则。
这两者,不必完全一致。
7. 英文是不是就一定一个单词一个 Token?
也不是。
有些常见英文单词,确实可能正好对应一个 Token。
比如:
-
hello
-
going
但这并不是固定规则。
例如:
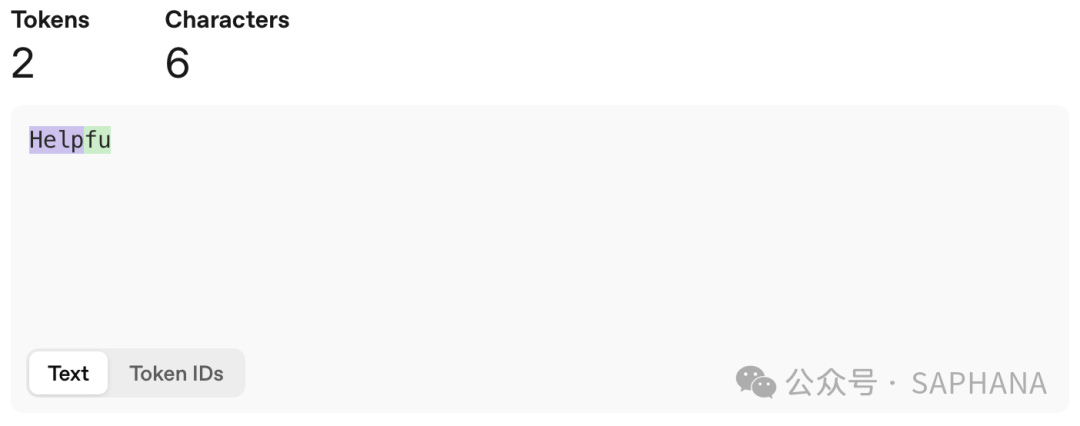
-
helpful
它就可能被拆成:
-
help
-
ful
https://platform.openai.com/tokenizer
甚至某些特殊字符,一个字符还可能对应多个 Token。
所以,不要把 Token 简单理解成“词”。
更准确的理解是:
Token 是模型可处理的最小文本单元。
8. Token 的一个实用理解方式
你可以这样记:
Token 不是语文老师定义的“词”,
而是模型自己学会的一套“最合适的文本切分颗粒度”。
这个定义非常接近真实工程含义。
9. Token 和字数怎么换算?
很多人第一次看到“100 万 Token”的时候没概念。
所以这里给一个粗略换算:
- 1 个 Token ≈ 0.75 个英文单词
- 1 个 Token ≈ 1.5 到 2 个汉字
于是:
- 40 万 Token ≈ 60 到 80 万汉字
- 100 万 Token ≈ 150 万到 200 万汉字
当然这只是经验值。实际数量会因为文本类型不同而有明显波动,比如:
-
中文和英文不同
-
代码和自然语言不同
-
JSON、表格、URL 往往更吃 Token
-
特殊符号密集内容也更贵
这也是为什么很多人会惊讶:
“我明明没写多少字,怎么 Token 消耗这么快?”
因为你以为自己给的是“一段文字”,
模型看到的是一大串细粒度切分后的 Token。
三、Context:大模型的“临时记忆体”
讲完 Token,再来看一个几乎所有人都经历过、但不一定认真想过的问题。
我们平时和 AI 聊天,会发现它似乎能记住前面说过的话。
比如你在开头说:
我叫繁光
过一会儿你再问:
我叫什么?
它通常能回答出来。
这就会让很多人产生一种错觉:
大模型是不是像人一样真的有记忆?
其实不是。
1. 模型本身并不会天然“记住”你
从底层来看,大模型依然只是一个函数:
-
给它输入
-
它给你输出
它不像人一样,有一个自然形成的、长期稳定的个人记忆系统。
那它为什么还能记住前文?
答案其实很简单:
因为程序在每次调用模型时,会把前面的对话内容一起发过去。
模型不是“记住了”,
而是“又重新看到了”。
2. 这就引出了 Context
所谓 Context,中文通常翻译为:
上下文
它指的是:
模型在当前这一次处理任务时,接收到的全部信息总和。
注意,是“全部信息总和”,而不是只指你最新输入的那句话。
3. Context 里面通常包含什么?
在真实系统里,Context 可能包括:
-
当前用户输入
-
历史对话记录
-
System Prompt
-
可用工具列表
-
工具调用结果
-
平台追加的控制信息
-
模型当前生成中的内容
所以当你觉得模型“记得”你之前说过什么时,本质上发生的事情并不是它脑子里有记忆,而是:
之前的信息被重新放进了这次的 Context 里。
4. 为什么可以把 Context 理解成“临时记忆”?
因为从效果上看,它很像模型的工作记忆区。
它里面装着:
-
当前任务所需的信息
-
前面对话留下来的痕迹
-
系统给它的行为规则
-
工具返回的数据
模型就是基于这些东西继续往下推理的。
所以你可以把 Context 理解为:
模型每次开工时手边摊开的那一摞材料。
不是“永久记忆”,
而是“本轮工作台上的资料”。
四、Context Window:上下文窗口
既然 Context 是模型每次处理任务时能看到的全部信息,那自然就会问:
它最多能看到多少?
这就是:Context Window
中文一般叫:上下文窗口
1. 它的定义非常直接
Context Window 指的是:
模型一次推理中,最多能容纳多少 Token 的上下文。
如果某个模型的 Context Window 是 1 万,
就意味着这次调用中,所有上下文加起来最多只能有 1 万 Token。
注意,这个“所有上下文”不只是你的问题,还包括:
-
历史对话
-
System Prompt
-
工具结果
-
当前问题
-
模型生成中的内容
这些都会一起占用窗口空间。
2. 为什么 Context Window 很重要?
因为它直接决定了模型很多能力边界。
比如:
-
能不能看长文档
-
能不能记住长对话
-
能不能处理大代码仓库
-
Agent 能连续跑多久
-
工具返回内容会不会把上下文撑爆
你平时遇到很多“AI 突然变笨”的现象,其实背后都可能和 Context Window 有关。
比如:
-
聊久了开始忘前面内容
-
做长任务做到后面质量下降
-
明明刚刚说过的规则,后面又被忽略
-
多轮工具调用后回答突然混乱
这些都不是玄学。
很多时候,它只是因为上下文压力变大了。
3. 100 万 Token 到底是什么概念?
前面说过,1 个 Token 大概等于 1.5 到 2 个汉字。
所以:
- 100 万 Token,大约就是 150 万到 200 万汉字
这个量级已经非常惊人了。
从直觉上说,很多超长文档、整本书,甚至多本书拼起来,都可能塞得进去。
这也是为什么近两年很多模型都在强调自己支持“超长上下文”。
因为这会显著提升:
-
长文档问答
-
长代码分析
-
大项目理解
-
多步 Agent 执行
4. 但窗口再大,也不代表你应该什么都往里塞
这里有个特别容易误解的点:
Context Window 大,不等于最佳做法就是“把所有内容一股脑全塞进去”。
为什么?
第一,成本会失控
Token 越多,调用成本越高。
第二,信息噪音会增大
上下文太长,不相关信息太多,反而可能干扰模型判断。
所以在工程里,真正重要的不是“塞得越多越好”,
而是:
给模型最相关的信息。
5. 这就是 RAG 的意义
假设你有一本几千页的产品手册,希望模型根据它回答用户问题。这时候你当然可以尝试把整本书都塞进上下文。但在大多数实际工程里,更合理的做法是:
RAG(检索增强生成,Retrieval-Augmented Generation)
它的基本思路是:
-
先把大文档切分并建立索引
-
当用户提问时,先去检索最相关的几个片段
-
只把这些最相关片段放进 Context
-
再让模型基于这些片段回答
这样做的好处很明显:
-
节省成本
-
降低噪音
-
提高相关性
-
更适合企业知识库、客服问答、文档检索场景
所以,长上下文很重要,
但“检索出对的问题片段再喂给模型”同样重要。
五、Prompt:你给模型下达的任务指令
接下来讲一个很多人最早接触、但也最容易被神化的概念:
Prompt
中文通常翻译成:提示词
但其实你完全不用把它想得很玄。它本质上就是:
你给模型输入的问题、指令、要求、规则。
1. 最简单的 Prompt,就是你说的话
比如你对模型说:
帮我写一首诗
这句话本身就是一个 Prompt。所以 Prompt 不一定是什么复杂模板、神秘黑话。它最朴素的定义就是:
你让模型做什么。
2. 为什么 Prompt 很重要?
因为模型的输出质量,很大程度上取决于:
你有没有把要求说清楚。
比如你只说:
帮我写一首诗
模型可能写:
-
古诗
-
现代诗
-
打油诗
-
抒情诗
-
搞笑诗
因为你的要求太模糊了。
但如果你这样说:
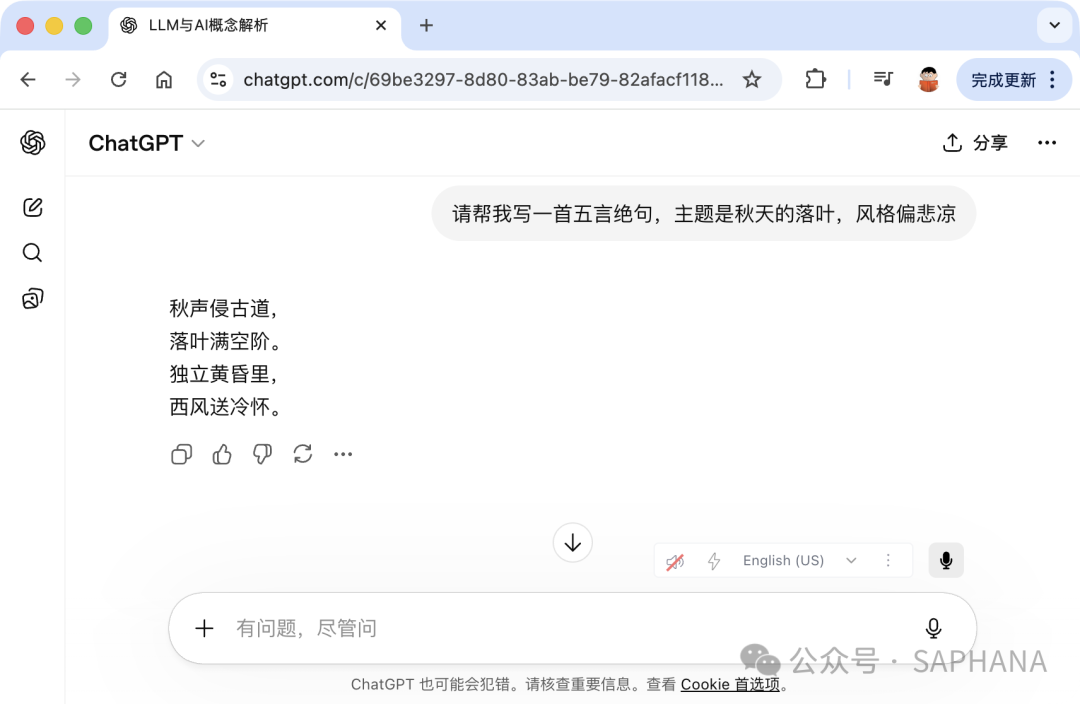
请帮我写一首五言绝句,主题是秋天的落叶,风格偏悲凉
那模型的输出就会稳定得多。
因为它知道了:
-
体裁
-
主题
-
情绪风格
这就是 Prompt 的价值。
3. Prompt Engineering,到底在干什么?
所谓 Prompt Engineering,说白了就是:
研究怎么把话说明白,让模型更准确理解你的意图。
过去这个概念非常火,因为早期模型能力没那么强,Prompt 稍微写得好一点,效果差别就会很明显。
但今天模型能力越来越强,很多模糊表达它也能大概猜出来。所以 Prompt Engineering 的神秘感下降了。不过这并不意味着 Prompt 不重要。它只是意味着:
-
炫技式 Prompt 没那么重要了
-
清晰表达仍然很重要
-
在复杂系统和 Agent 场景里,高质量 Prompt 依然是基础功
六、Prompt 还分两类:User Prompt 和 System Prompt
事情到这里还没有结束。
因为在真实系统里,模型接收到的“指令”往往不只有用户输入的那一句话。
有时候我们还需要提前告诉模型:
-
你是谁
-
你应该扮演什么角色
-
你必须遵守什么规则
-
你不能怎么做
-
你的输出风格是什么
于是,Prompt 就分成了两类。
1)User Prompt:用户提示词
User Prompt 很简单,就是用户在界面里直接输入给模型的话。
例如:
-
帮我写一首诗
-
3 加 5 等于几
-
总结一下这篇文章
-
帮我改写这段文案
这些都属于 User Prompt。
2)System Prompt:系统提示词
System Prompt 则是开发者在后台设置的规则。用户通常看不到,但它会持续影响模型行为。
比如开发者可以写:
-
你是一个耐心的数学老师
-
不要直接告诉学生答案
-
要引导对方一步一步思考
-
回复语气要温和
-
不要使用过于复杂的术语
这些就属于 System Prompt。
一个特别经典的例子:数学辅导机器人
假设你要做一个数学辅导机器人,你的目标不是让它直接报答案,而是引导学生思考。那你就可以这样设计:
System Prompt
你是一个耐心的数学老师。当学生问你数学题时,不要直接给出答案,而是一步一步引导他们理解解题思路。
User Prompt
3 加 5 等于几?
模型同时看到这两层信息后,回答很可能会变成:
我们可以这样想,你手里有 3 个苹果,又拿了 5 个苹果,现在一共有多少个呢?你可以试着数一数。
如果没有 System Prompt,它很可能直接回答:
8
所以你会发现:
- User Prompt 决定“做什么”
- System Prompt 决定“以什么方式做”
这两者叠加在一起,才构成了模型实际行为的控制逻辑。
七、Tool:AI 为什么突然“能查天气、能读文件、能执行代码”了?
下面进入一个真正让大模型从“会聊天”升级到“能做事”的关键概念:
Tool
很多人第一次听“工具”这个词,会觉得太抽象。
但如果换个说法,就立刻清楚了:
Tool,本质上就是函数。
1. 为什么大模型需要 Tool?
因为大模型有一个天然弱点:
它没法直接感知外部世界。
比如你问它:
今天上海天气怎么样?
如果它没有联网、没有外部查询能力,它只能说:
-
我无法获取实时天气
-
我的知识截止到某个时间
-
我无法提供今天的实时信息
为什么?
因为大模型的能力来源于训练数据和当前上下文。
它不会自己去打开天气网站,也不会自己去查实时数据库。
它需要一个外部接口,替它完成“查”的动作。
这就是 Tool 的价值。
2. Tool 的本质是什么?
Tool 本质上就是一个函数接口:
-
你传入参数
-
它返回结果
比如“天气查询工具”,可能需要:
-
城市
-
日期
或者:
-
经度
-
纬度
它内部也许会:
-
调用天气 API
-
查数据库
-
连第三方服务
但对模型来说,这些都不是重点。
模型关心的是:
-
这个工具叫什么
-
它能干什么
-
需要什么参数
-
会返回什么信息
Tool 调用时,系统里到底发生了什么?这里通常会涉及四个角色:
-
用户
-
平台
-
大模型
-
工具
其中,平台很关键。你可以把它理解成中间的调度员、传话筒、执行器。
因为:
-
用户不会直接调用工具
-
模型也不会真的自己执行函数
-
工具也不会自己把结果交给用户
平台负责把这一切串起来。
3. 一个完整例子:查天气
比如用户问:
今天上海天气怎么样?
流程通常是这样的:
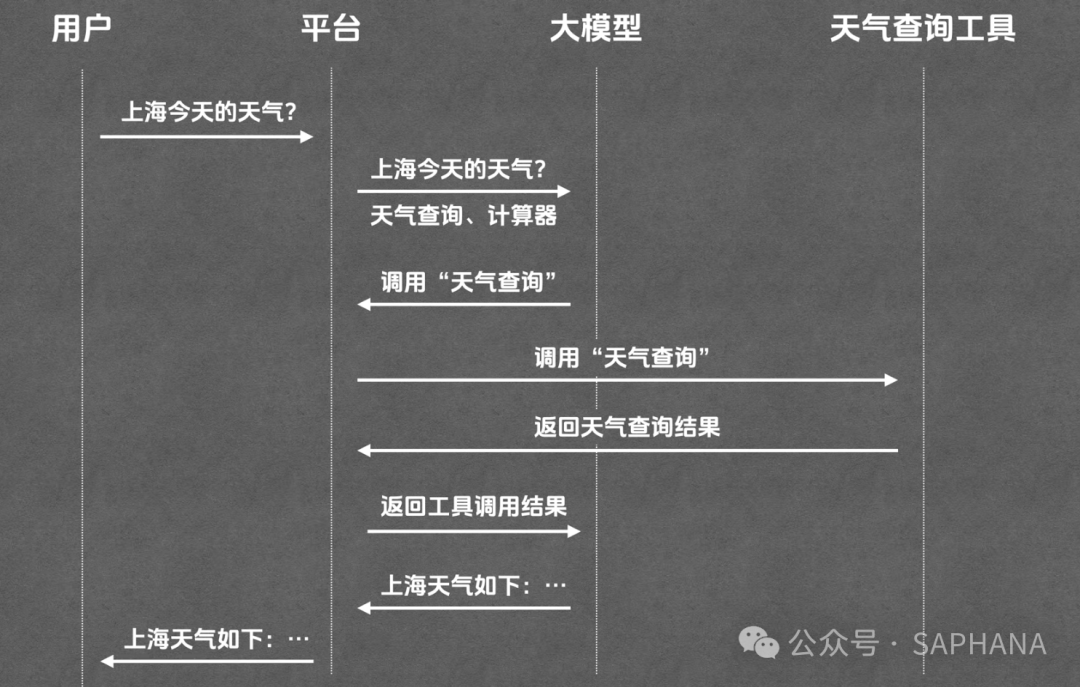
第一步:用户把问题发给平台
不是直接发给工具。
第二步:平台把问题和“可用工具列表”一起发给模型
模型看到的不只是问题,还有当前可用能力。
例如:
-
weather 工具
-
calculator 工具
-
search 工具
第三步:模型判断是否需要调用工具
模型会分析:
-
用户问的是天气
-
我自己没有实时天气数据
-
但这里有 weather 工具可用
-
所以应该调用它
第四步:模型输出工具调用指令
注意,模型不会真的去执行函数。
它只能输出一段结构化指令,大意像这样:
-
调用工具:weather
-
参数:city=上海,date=今天
第五步:平台真正执行工具
平台看到这个指令后,才会实际调用 weather 这个函数。
第六步:平台拿到工具返回结果
比如:
-
晴
-
15℃ 到 25℃
-
东风 3 级
第七步:平台把这个结果再发给模型
模型看到工具返回后,会把它整理成人类更容易读懂的话。
第八步:平台把最终结果返回给用户
比如:
今天上海天气晴,气温 15 到 25 度,整体比较舒适。
4. 一个特别容易搞错的点
很多人会误以为:
是模型在调用工具
其实不准确。
更准确的说法是:
模型负责决定“用哪个工具、传什么参数”,
真正执行工具的是平台。
模型依然只是一个“生成文本 / 生成指令”的系统。
真正对外部世界产生作用的,是平台和工具执行层。
5. 所以,Tool 的意义是什么?
一句话总结:
Tool 是模型连接外部世界的手和眼。
没有 Tool 的模型,本质上仍然只是一个基于训练数据和上下文生成文本的系统。
有了 Tool,它才开始具备:
-
查天气
-
查地图
-
查数据库
-
跑代码
-
读文件
-
调接口
-
控浏览器
-
操作企业系统
这些真实能力。
也正是从这里开始,AI 才逐渐从“会说话”走向“会做事”。
八、MCP:为什么 AI 工具也需要一个“Type-C 接口”?
理解了 Tool 之后,很快就会遇到一个工程问题:
工具怎么接进不同平台?
如果每个平台的接入规范都不一样,那开发者会非常痛苦。
于是,这就引出了:
MCP
1. MCP 是什么?
MCP,全称是:
Model Context Protocol
中文一般翻译成:
模型上下文协议
这个名字听起来稍微有点学术。
如果你想快速理解它,可以直接把它理解成:
统一的工具接入标准。
2. 为什么会需要 MCP?
假设你开发了一个很好用的工具。你希望它既能在 OpenAI 生态里使用,也能在 Anthropic、Google 或其他平台里使用。如果大家各自有一套不同的工具接入方式,你就得:
-
按 OpenAI 的标准写一套
-
按 Anthropic 的标准再写一套
-
按 Google 的标准再写一套
同一个工具,重复适配很多次。这非常低效。于是,AI 工具生态就会变得很碎片化。
3. MCP 想解决的,就是“重复适配”问题
它的目标很明确:
能不能定义一套统一标准,让工具开发者只开发一次,就能被所有支持该标准的平台接入?
如果这个目标实现,整个生态都会轻松很多:
-
工具开发者更省事
-
平台更容易接入工具
-
产品之间更容易互通
-
Agent 更容易复用外部能力
4. 用一个特别形象的类比来理解
你可以把 MCP 理解成:
AI 工具世界里的 Type-C 接口。
以前不同手机有不同充电口,后来大家逐渐统一到 Type-C,体验立刻提升。MCP 做的事情很像:
-
它不是发明工具
-
也不是发明模型
-
它是在统一“接头规范”
这样一来,大家接起来就顺多了。
5. MCP 的价值,不在“变聪明”,而在“变顺畅”
这一点很重要。MCP 不是让模型突然更聪明,它解决的不是“智力问题”,而是“工程接入问题”。它的价值是:
-
降低接入成本
-
提升生态互联效率
-
让工具更容易跨平台复用
-
让 Agent 和工具生态更容易成长起来
所以 MCP 很重要,但它的重要性是“基础设施层”的重要,不是“模型推理层”的重要。
九、Agent:从“回答问题”,走向“完成任务”
到这里为止,我们已经有了:
-
LLM
-
Prompt
-
Tool
-
MCP
看起来已经很强了。但为什么行业里又多了一个特别火的词:
Agent
因为仅仅“会回答”和“会调一次工具”,还不够。真正复杂的任务,往往需要:
-
多步规划
-
条件判断
-
连续执行
-
动态决定下一步做什么
这就是 Agent 的价值所在。
1. 一个简单问题,和一个复杂任务的区别
如果用户只是问:
今天上海天气怎么样?
模型调用一次天气工具,拿到结果后总结一下,就结束了。这是一个典型的单步任务。
但如果用户说:
今天我这里天气怎么样?如果下雨的话,顺便帮我查一下附近有没有卖雨伞的店。
这个问题就变复杂了。它不是一个动作,而是一个多步流程:
-
先确定我在哪里
-
再查当前位置天气
-
判断是不是下雨
-
如果下雨,再查附近雨伞店
-
最后整合答案
这已经不是“简单调用一个工具”了。而是需要边做边判断。
2. 从模型视角看,Agent 在干什么?
以这个场景为例,模型的内部推理流程很像这样:
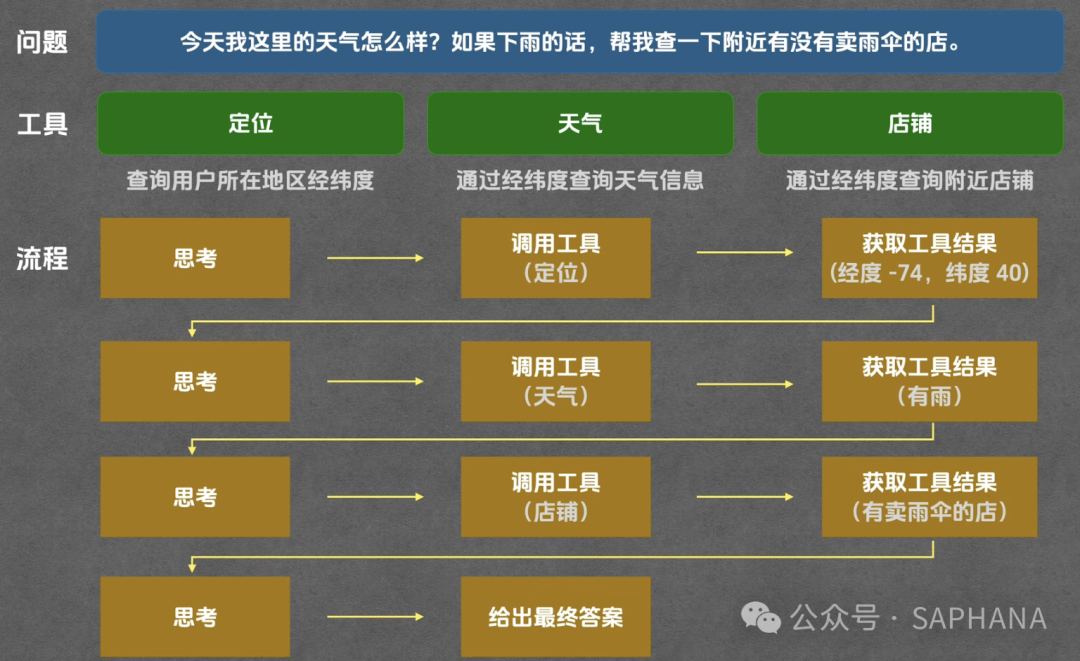
第一步:
用户问天气。
要查天气,先得知道位置。
当前有定位工具,所以先调用定位工具。
第二步:
拿到经纬度后,下一步是查天气。
当前有天气工具,于是调用天气工具。
第三步:
天气结果出来了,发现有雨。
用户要求说“如果下雨,就帮我查卖伞的地方”。
于是继续调用店铺搜索工具。
第四步:
店铺结果出来后,整合所有信息,输出最终回答。
注意,这里最关键的不是“会用工具”,而是:
它会根据当前状态,决定下一步该做什么。
2. Agent 的定义
所以,Agent 可以理解为:
能够自主理解目标、自主规划步骤、自主调用工具,并持续运行直到完成用户任务的系统。
它和普通聊天模型最大的区别就在于:
普通模型更像:
你问一句,我答一句
而 Agent 更像:
你给我一个目标,我自己拆步骤把它办完
3. Agent 的关键不在“能回答”,而在“能持续行动”
从工程角度看,一个成熟的 Agent,通常会涉及这些能力:
-
任务理解
-
步骤规划
-
工具选择
-
参数生成
-
条件判断
-
结果利用
-
多轮循环
-
最终归纳
所以 Agent 不是某个单点功能,而是一种“可持续执行任务”的系统结构。
4. 为什么 Agent 这两年这么火?
因为它把模型的角色从“会聊天的助手”,推进到了“会做事的执行者”。
这意味着 AI 的应用边界一下子被拉宽了:
-
不只是回答问题
-
还可以帮你查资料
-
帮你写代码
-
帮你跑脚本
-
帮你分析项目
-
帮你连接系统
-
帮你完成一条完整工作流
这也是为什么市面上开始出现大量 Agent 类产品,例如:
-
Claude Code
-
Codex
-
Gemini CLI
-
各类自动化智能体
-
AI 开发代理
-
企业级任务助手
它们的底层思路虽然不同,但核心都在做同一件事:
让 AI 从“答题”升级为“执行”。
十、Agent Skill:为什么 Agent 还需要“说明书”?
你可能会想,既然 Agent 都已经能规划、能调用工具、能执行任务了,那是不是已经很完美了?
现实是:还差一步。
因为 AI 虽然会做事,但它不一定会按照你喜欢的方式做事。这时候就需要:
Agent Skill
1. Agent Skill 是什么?
一句话概括:
Agent Skill,就是写给 Agent 看的说明文档。
它不是给终端用户看的,而是给 Agent 的“工作手册”。
里面会写清楚:
-
你要完成什么目标
-
你应该按什么步骤做
-
你要遵守哪些规则
-
你要用什么格式输出
-
你最好参考什么示例
2. 为什么 Agent 需要 Skill?
举个生活化例子。
假设你想让 Agent 变成你的“出门助手”。每次出门前,它都帮你查天气,并提醒你该带什么。但你有自己的一套个人习惯:
-
下雨带伞
-
太阳太强带帽子
-
空气差带口罩
-
风大穿防风外套
-
无论如何手机必带
而且你还很在意回答格式:
-
先一句总结
-
再列物品清单
-
不要啰嗦
-
不要自由发挥太多
如果没有预设这些规则,那你每次都得重新写一大串 Prompt。
这显然很麻烦。
所以最好的办法就是把这些规则提前写好,做成一个可复用的 Skill。
3. Agent Skill 的本质是什么?
从本质上看,它其实就是:
把反复会用到的任务规则,外置成一份结构化说明文档。
这件事的价值非常大,因为它能让 Agent 的行为从“临场发挥”变成“可复用、可维护、可解释的执行逻辑”。
4. 一个 Skill 通常会写什么?
一般来说,一个 Agent Skill 可以分成两部分。
第一部分:元数据层
这相当于封面,告诉 Agent:
-
这个 Skill 叫什么
-
它是做什么的
常见字段至少有:
-
Name
-
Description
第二部分:指令层
也就是正文。这里通常会写:
-
目标
-
执行步骤
-
判断规则
-
输出格式
-
示例
比如“出门清单”这个 Skill 可以这样设计:SKILL.md
---
name: go-out-checklist
description: 生成出门清单。当用户询问“出门要带什么/要准备什么/今天外出需要带哪些东西”时使用
---
# 目标
你是一个贴心的“出门清单助手”。你的任务是根据用户所在位置的实时天气情况,告诉用户出门必须携带的物品。
# 执行步骤
1. 调用“定位工具”,获取用户当前所在位置的经纬度。
2. 将获取到的经纬度作为参数,调用“天气工具”,一次性获取降雨情况、光照强度、空气质量和风力大小这四项数据。
3. 根据天气数据结果,按照下方的“判断规则”整理出门需要携带的物品。
4. 严格按照下方的“输出格式”向用户输出最终结果。
# 判断规则
1. 手机:无条件必带。
2. 伞:当“天气工具”返回“有雨”时,必须携带。
3. 帽子:当“天气工具”返回“光照强”时,必须携带。
4. 口罩:当“天气工具”返回“空气质量差”时,必须携带。
5. 防风外套:当“天气工具”返回“强风”时,必须携带。
# 输出格式
你必须输出两段:
【结论一句话】
用一句话总结今天出门最关键的注意点(例如“有雨 + 光照强”,或“风力大”)。
【出门清单】
- 物品(原因)
- 物品(原因)
# 示例
## 用户问题
我马上要出门,帮我看看今天需要准备带些什么?
## 工具返回
### 定位工具
{
"经度": -73.9855,
"纬度": 40.7580
}
### 天气工具
{
"降雨情况": "有雨",
"光照强度": "弱",
"空气质量": "良",
"风力大小": "强风"
}
## 最终输出
【结论一句话】
有雨 + 强风
【出门清单】
手机(必带)
伞(有雨)
防风外套(强风)5. Agent Skill 为什么这么有用?
因为它把“经验”变成了“规则”。这在工程里特别重要。任何靠模型临场猜测的行为,都可能波动。而显式写出来的规则,则会大幅提升:
-
输出一致性
-
行为可控性
-
修改便利性
-
团队协作效率
-
复用能力
所以你可以把 Agent Skill 理解成:
Agent 的岗位 SOP。
6. 它在系统里怎么落地?
以 Claude Code 这类产品为例,Skill 往往不是随便放个文档就行,而是有明确约定。例如:
-
存放在特定目录
-
每个 Skill 一个独立文件夹,例 go-out-checklist
-
文件夹名和 Skill 名要一致
-
正文文件名必须叫
SKILL.md
这说明一件事:
Agent Skill 不是普通文档,而是被系统识别和加载的一类特殊文档。
7. Skill 不只是“文档”,而是行为配置层
更进一步讲,Agent Skill 的价值不只是“省得你重复打字”。它实际上把 Agent 的行为逻辑,从部分代码层,外置到了文档层。这会带来很多高级价值:
-
降低开发门槛
-
让业务人员也能参与规则定义
-
方便版本管理
-
方便团队复用
-
便于形成领域技能库
-
节省 Context 中重复注入的大量 Token
所以 Agent Skill 的出现,标志着 Agent 系统开始往“工程化、产品化、团队化”方向走了。
十一、把这整套体系串起来,你就真正看懂 AI 了
到这里,我们已经把这些概念一个个拆开讲完了。现在把它们重新串起来看,你会更容易理解整个 AI 系统的结构。
第一层:LLM
这是核心大脑。
负责推理、生成、判断、规划,本质是不断预测下一个 Token。
第二层:Token
这是最小处理单位。
模型不是按“词”处理,而是按 Token 处理。
第三层:Context
这是模型本轮任务看到的信息总和。
你可以把它看成模型的临时工作记忆。
第四层:Context Window
这是这块临时记忆的容量上限。
它限制了模型一次最多能看多少 Token。
第五层:Prompt
这是当前给模型下达的任务说明。
包括用户要求和系统规则。
第六层:Tool
这是模型连接外部世界的函数接口。
它让模型具备查数据、做动作、调系统的能力。
第七层:MCP
这是统一工具接入格式的标准协议。
它让工具生态更容易互联。
第八层:Agent
这是会自主规划和连续执行的系统。
它不只是回答,而是持续完成任务。
第九层:Agent Skill
这是给 Agent 看的说明文档。
它规定规则、步骤、格式和示例,让 Agent 更稳定地做事。
十二、为什么理解这几个词,比追热点更重要?
因为今天 AI 圈子里几乎所有新产品、新技术、新包装,最后都逃不开这套框架。无论你看到的是:
-
Claude Code
-
Codex
-
Gemini CLI
-
AI IDE
-
企业知识库
-
智能客服
-
自动化工作流
-
编程代理
-
智能运维助手
它们本质上都在这几个层面做增强和组合:
-
模型更强
-
上下文更长
-
Prompt 管理更成熟
-
Tool 更丰富
-
MCP 更统一
-
Agent 更会规划
-
Skill 更可复用
所以真正重要的,不是死记硬背名词。而是看懂它们分别属于哪一层、解决的是什么问题。当你具备这种视角之后,别人再抛给你一个新名词,你的第一反应就不会是:
这个词好高级,我得去背一下
而会变成:
它到底是在讲模型能力?上下文管理?工具接入?还是 Agent 编排?
这时候,你才算真正拥有了“理解 AI”的框架。
十三、最后,用一句话记住每个概念
为了方便收藏和复习,最后我们再把每个概念压缩成一句话。
-
LLM:大语言模型,是整个 AI 系统的核心推理引擎。
-
Token:模型处理文本的最基本单位,不等于“词”。
-
Context:模型本轮任务接收到的全部信息总和,相当于临时工作记忆。
-
Context Window:Context 最多能装下多少 Token 的容量上限。
-
Prompt:用户或系统当前给模型下达的具体任务、问题或规则。
User Prompt:用户直接输入给模型的话。
System Prompt:开发者在后台配置给模型的人设和行为规则。
-
Tool:模型用来感知和影响外部环境的函数接口。
-
MCP:统一工具接入格式的标准协议,降低跨平台适配成本。
-
Agent:能够自主规划、自主调用工具、持续执行直到完成任务的系统。
-
Agent Skill:写给 Agent 看的说明文档,用来规定步骤、规则、格式和示例。
十四、结尾
如果你能把这几个概念真正吃透,你以后再看 AI 领域的新产品、新技术、新趋势,就不会再被表面的名词轰炸带着跑了。因为你已经知道:
-
LLM 是核心引擎
-
Token 是最小颗粒
-
Context 是临时记忆
-
Context Window 是容量限制
-
Prompt 是任务入口
-
Tool 是连接外部世界的手和眼
-
MCP 是统一接头标准
-
Agent 是任务执行者
-
Agent Skill 是操作说明书
说到底,今天大多数 AI 产品的花样再多,底层也离不开这一套结构。理解这套结构,比追逐每一个新名词更重要。因为当你真正看见骨架之后,那些五花八门的外壳,就不再那么容易把你绕晕了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)