OpenClaw多Agent实战指南:从单智能体到AI协作团队(非常详细),从入门到精通,收藏这一篇就够了!
Gartner 数据显示,2024 年 Q1 到 2025 年 Q2,企业对多智能体系统的咨询量激增 1445%,越来越多开发者从单 AI Agent 的「单兵作战」转向多 Agent 的「团队协作」。但实际使用中,很多人用 OpenClaw 时会遇到这样的问题:让同一个 Agent 兼顾工作开发和日常写作,结果它在写文案时冒出代码逻辑,工作群聊里泄露私人对话;系统提示词越写越长,每次对话都要消耗大量 token,甚至多个会话互相阻塞,运行效率大幅下降。
如果你也被这些问题困扰,那说明是时候给你的 OpenClaw 搭建多 Agent 体系了。不同于学术论文中靠自然语言委派任务的 Multi-Agent 框架,也区别于 Claude Code 侧重代码分工的多 Agent 设计,OpenClaw 的多 Agent 能让你在本地设备实现「一人多岗」—— 写作、开发、生活助手各有专属 Agent,独立记忆、独立工作目录,彻底告别串线问题。本文就从实操角度,带你从零搭建 OpenClaw 多 Agent 体系,从配置到隔离,从路由到安全,一步到位落地。
一、为什么单 Agent 撑不起你的 AI 工作流?
在 AI 原生工作流中,「先跑起来,再迭代」是核心原则,OpenClaw 的使用也建议从单 Agent 起步:通过openclaw onboard向导完成配置、Workspace 初始化和渠道连接,一个默认的main Agent 就能实现基础的对话与工具调用需求。
但随着使用场景的丰富,单 Agent 的局限性会逐渐显现。从行业实践来看,多智能体系统的核心价值就是用「专业化分工」解决单智能体的「上下文混乱、效率低下」问题,而这一点在 OpenClaw 的实际使用中尤为明显:单 Agent 的所有会话共享同一个 Workspace 和记忆文件,工具执行也在同一个进程中,当场景超过 1-2 个时,各种问题会接踵而至。这也是为什么社区中关于 OpenClaw 多 Agent 配置的讨论越来越多,成为从「能用」到「用好」的关键节点。
二、OpenClaw 中一个 Agent 的核心构成
在搭建多 Agent 之前,首先要明确:OpenClaw 中的一个 Agent 不是简单的「名字 + 系统提示词」,而是一个完整的隔离单元,包含三块彼此独立的核心资源,不同 Agent 之间默认不共享任何信息,这是实现「不串线」的基础。

一个容易被忽略的细节是:Workspace 是 Agent 工具执行时的默认工作目录,

所有相对路径都从这里开始,但它并非「硬沙箱」—— 如果 Agent 通过绝对路径执行操作,仍能访问宿主机的其他位置,若需要更强的文件隔离,需配合后续的 Sandbox 功能。
从架构链路来看,单 Agent 模式是「渠道接入→Gateway→命令队列→Agent Loop→模型→回写」,而多 Agent 模式仅在 Gateway 后增加了路由环节:Gateway 收到消息后,先通过路由规则判断交给哪个 Agent 处理,再进入对应 Agent 的队列和循环,其余链路完全复用,这让多 Agent 的搭建具备「低改造成本」的特点。
三、从单到多:判断拆分 Agent 的三个信号
多 Agent 并非「越早上越好」,反而会增加配置复杂度,因此只有当单 Agent 出现明确问题时,拆分才具备实际价值。结合社区实践和 OpenClaw 的技术特性,当出现以下三个信号,就是搭建多 Agent 的最佳时机:
信号一:记忆串线,场景混淆
工作群聊中的 Agent 突然提及私人私聊内容,开发任务中冒出写作相关的记忆,核心原因是所有会话共享同一个 Workspace 和 MEMORY.md,Agent 无法区分不同场景的记忆边界。
信号二:System Prompt 臃肿,上下文膨胀
为了适配不同场景,给 Agent 叠加了大量要求,系统提示词越来越长,每次对话都要消耗数万 token 加载,而上下文膨胀是长时运行 Agent 的「头号杀手」,直接导致响应变慢、效率降低。
信号三:Compaction 互相阻塞,会话卡顿
OpenClaw 的 Compaction 机制用于治理工具副作用,但在单 Agent 模式下,一个会话的 Compaction 运行时,其他所有会话都会被阻塞,多个场景同时使用时,卡顿问题会非常明显。
这三个信号的本质,都是单 Agent 的「资源共享」无法适配多场景的「资源隔离」需求,而多 Agent 的拆分,就是从根本上解决这个矛盾。
四、手把手搭建多 Agent 体系:创建与路由
当确定需要拆分 Agent 后,搭建工作分为「创建 Agent」和「配置消息路由」两步,前者实现 Agent 的物理隔离,后者决定「消息该交给谁处理」,两者结合才能实现多 Agent 的正常运转。
4.1 快速创建多个 Agent
OpenClaw 提供了便捷的 Agent 管理命令,一行代码就能完成 Agent 创建,自动生成独立的 Workspace、AgentDir 和 Sessions 目录,并在配置文件中添加对应条目:
# 创建工作专属Agent
openclaw agents add work
# 创建写作专属Agent
openclaw agents add writing
如果需要精细化控制(如设置默认 Agent、自定义名称),可直接编辑配置文件~/.openclaw/openclaw.json,在agents.list中添加配置:
{
"agents": {
"list": [
{
"id": "home",
"default": true,
"name": "生活助手",
"workspace": "~/.openclaw/workspace-home"
},
{
"id": "work",
"name": "工作开发",
"workspace": "~/.openclaw/workspace-work"
}
]
}
}
配置要点:
-
每个 Agent 的
workspace路径必须唯一,否则会导致记忆和配置互相污染; -
agentDir禁止跨 Agent 复用,会引发认证失败和会话冲突;
-
标记
default: true的 Agent 接收所有未匹配到路由规则的消息,未设置时,列表第一个 Agent 为默认值。
创建完成后,可通过以下命令验证 Agent 是否创建成功:
openclaw agents list --bindings
4.2 配置消息路由:bindings 决定「谁接活」
Agent 创建完成后,核心问题是「渠道消息该交给哪个 Agent 处理」,答案就是bindings 路由规则—— 一组确定性的映射规则,将消息的匹配条件(如渠道、群聊、账户)与agentId关联,实现消息的精准分发。
两种常用路由配置方式
-
按渠道 / 账户路由
:适合拥有多个渠道账户的场景,不同账户对应不同 Agent:
{
"bindings": [
{ "agentId": "home", "match": { "channel": "whatsapp", "accountId": "personal" } },
{ "agentId": "work", "match": { "channel": "whatsapp", "accountId": "biz" } },
{ "agentId": "writing", "match": { "channel": "telegram" } }
]
}
-
按群聊路由
:适合同一个 Bot 对接多个群聊的场景,无需多申请 Bot,不同群聊对应不同 Agent:
{
"bindings": [
{
"agentId": "work",
"match": {
"channel": "telegram",
"peer": { "kind": "group", "id": "-1001234567890" }
}
},
// 兜底规则:未匹配到的Telegram消息交给home Agent
{ "agentId": "home", "match": { "channel": "telegram" } }
]
}
路由匹配的核心规则
-
优先级从高到低
:peer(精确匹配群 / 个人 ID)→ parentPeer(线程继承)→ guildId+roles(Discord 角色)→ guildId/teamId → accountId → 渠道级兜底 → 默认 Agent;
-
AND 语义
:一条规则中若包含多个匹配条件,需所有条件同时命中才会生效;
-
顺序决定优先级
:同一层级的规则,配置文件中写在前面的优先匹配。
实战原则:具体规则在前,兜底规则在后,避免消息被错误分发。
配置完成后,重启 Gateway 并验证路由是否生效:
openclaw gateway restart
openclaw channels status --probe
4.3 多人 DM 必做:配置 dmScope 实现会话隔离
如果你的 OpenClaw 开放了多人 DM(如dmPolicy: "allowlist"添加了多个号码),必须调整 dmScope,这是社区中高频踩坑点。
默认情况下,dmScope: "main",所有人的 DM 共享同一个会话上下文,会导致隐私泄露(如 A 的私聊内容被 B 看到)。dmScope的核心作用是控制 DM 场景下的会话 key 生成逻辑,四种取值对应不同场景,按需选择即可:
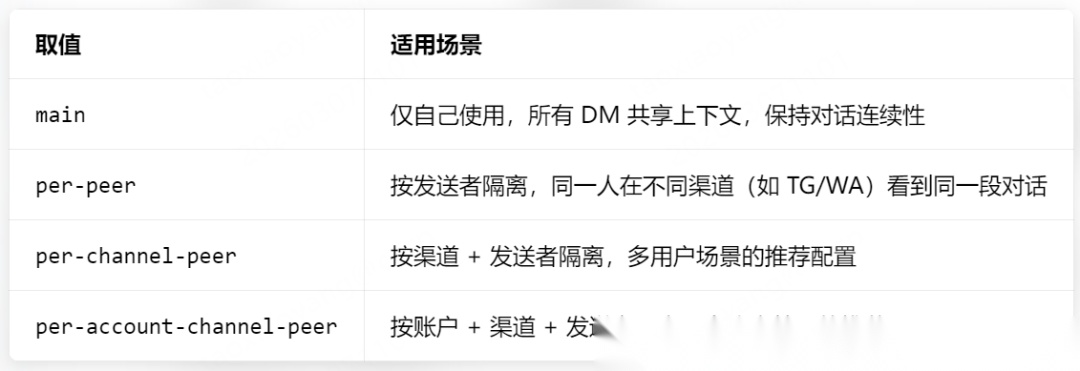
多用户场景下,推荐配置:
{
"session": {
"dmScope": "per-channel-peer"
}
}
若需要让同一用户在不同渠道的会话互通,可通过session.identityLinks合并不同渠道的身份。
五、多 Agent 的三层隔离方案:按需选择
完成 Agent 创建和路由配置后,默认实现的是软隔离—— 多个 Agent 跑在同一个 Gateway 进程中,仅实现 Workspace 和 Sessions 的逻辑隔离。随着使用场景的复杂化(如处理敏感数据、对外提供服务),需要更强的隔离能力,OpenClaw 提供了「软隔离→Docker Sandbox→多 Gateway」三层隔离方案,每一层解决不同的问题,资源消耗和隔离程度逐级提升。
5.1 软隔离:轻量首选,适合个人 / 小团队
隔离程度:约定级(共享 Gateway 进程,无文件系统硬边界)资源消耗:低适用场景:个人使用、小团队协作、信任环境
核心优势
- 配置简单,无需额外依赖,仅通过配置文件就能实现;
- Agent 之间可通过
sessions_send工具互相通信(需启用tools.agentToAgent),实现轻量协作; - 资源消耗低,对宿主机性能无额外要求。
潜在风险
属于「君子协议」式隔离,同一进程内的 Agent 可通过绝对路径访问其他 Agent 的 Workspace,因此不适合处理敏感数据或对外提供服务。
5.2 Docker Sandbox:容器级隔离,防范工具越权
隔离程度:容器级(文件系统 + 进程隔离,工具执行与宿主机隔离)资源消耗:中适用场景:处理敏感数据、防范工具越权操作、开放给外部人员使用
核心认知纠正
Sandbox 并非「把 Gateway 塞进 Docker」,而是Gateway 运行在宿主机,Agent 的工具执行(exec/read/write 等)进入 Docker 容器,即使模型执行了危险操作(如删文件、访问敏感路径),影响范围也仅局限在容器内部,实现「爆炸半径控制」。
最小化启用配置
{
"agents": {
"defaults": {
"sandbox": {
"mode": "non-main", // off-关闭 | non-main-非私人对话进沙箱 | all-全部进沙箱
"scope": "session", // session-每会话一个容器 | agent-每Agent一个容器 | shared-全局一个容器
"workspaceAccess": "none" // none-无访问 | ro-只读 | rw-读写
}
}
}
}
参数解读:
-
mode: non-main是多数场景的默认值,私人对话不进沙箱(保证体验),群聊 / 频道进沙箱(保证安全);
-
scope: session是最强隔离,适合处理敏感数据;
agent适合需要跨会话共享容器状态的场景; -
workspaceAccess: none是最安全配置,沙箱内工具仅能操作容器内部文件。
精细化配置:不同 Agent 不同规则
可给单个 Agent 单独配置 Sandbox,实现「个人 Agent 不限制,外部 Agent 强隔离」:
{
"agents": {
"list": [
{
"id": "personal",
"workspace": "~/.openclaw/workspace-personal",
"sandbox": { "mode": "off" }
},
{
"id": "external",
"workspace": "~/.openclaw/workspace-external",
"sandbox": { "mode": "all", "scope": "agent" },
"tools": {
"allow": ["read", "exec"],
"deny": ["write", "edit", "browser"]
}
}
]
}
}
启用前准备
需先构建沙箱镜像,基础镜像满足核心需求,带常用工具的镜像适合开发场景:
# 构建基础沙箱镜像
scripts/sandbox-setup.sh
# 构建包含curl/jq/python3/git的镜像
scripts/sandbox-common-setup.sh
注意:默认沙箱容器无网络(docker.network: "none"),若需要联网,需显式配置;容器创建后仅执行一次的setupCommand,需提前配置网络和 root 权限。
5.3 多 Gateway:进程级隔离,企业级高可用
隔离程度:进程级(完全独立,Gateway 实例之间无任何共享资源)资源消耗:高适用场景:企业级部署、对外提供多租户服务、需要高可用 / 救援能力
OpenClaw 官方建议:大多数场景一个 Gateway 足够,多 Gateway 仅用于「强隔离 + 高可用」需求,比如搭建「救援 Bot」—— 主 Gateway 挂掉时,可通过救援 Gateway 排查问题。
核心要求:资源完全独立
多个 Gateway 实例的以下资源必须唯一,否则会出现冲突:
-
OPENCLAW_CONFIG_PATH(配置文件路径);
-
OPENCLAW_STATE_DIR(状态目录);
-
agents.defaults.workspace(工作目录);
-
gateway.port(端口,间隔≥20,避免派生端口冲突)。
便捷搭建:使用 profiles
profiles 会自动隔离配置文件和状态目录,是搭建多 Gateway 的最优方式:
# 搭建主Gateway,端口18789
openclaw --profile main onboard
openclaw --profile main gateway --port 18789
# 搭建救援Gateway,端口19789
openclaw --profile rescue onboard
openclaw --profile rescue gateway --port 19789
若需要将 Gateway 安装为后台服务,仅需添加install命令:
openclaw --profile main gateway install
六、上线前必做的安全与验证检查
多 Agent 体系搭建完成后,上线前的检查必不可少,既保证功能正常,也规避安全风险,以下 8 项检查是社区实践总结的「必做项」,缺一不可:
- 用
openclaw doctor检查配置文件格式(需为 JSON5),避免语法错误; - 确认所有 Agent 的 Workspace 和 AgentDir 路径独立,无重复;
- 确认 bindings 规则「具体在前,兜底在后」,无路由冲突;
- 多人 DM 场景已配置
dmScope,推荐per-channel-peer; - 远程访问仅通过 SSH 隧道或 Tailscale VPN,不直接暴露端口:
# SSH隧道示例,本地18789端口映射到远程Gateway端口
ssh -N -L 18789:127.0.0.1:18789 user@gateway-host
- 若启用 Sandbox,已提前构建镜像,网络和权限配置符合需求;
- 若使用多 Gateway,端口间隔≥20,所有资源完全隔离;
- 用
openclaw channels status --probe验证所有渠道连接正常,消息能正常收发。
另外,OpenClaw 的 Gateway 支持配置热重载,默认模式为hybrid—— 可热更新的改动(如 bindings、dmScope)直接生效,需要重启的改动自动触发重启,无需每次手动重启 Gateway。若需要自定义热重载规则,可在配置文件中设置gateway.reload.mode,取值为off(关闭)、hot(仅热更新)、restart(所有改动重启)。
七、多 Agent 落地实践:选型与避坑总结
OpenClaw 的多 Agent 体系是渐进式的,无需一步到位,可根据自身场景从「软隔离」逐步升级到「多 Gateway」,结合行业实践和社区踩坑经验,以下选型指南和实践原则能让你的落地更顺畅。
7.1 快速选型:按场景选方案
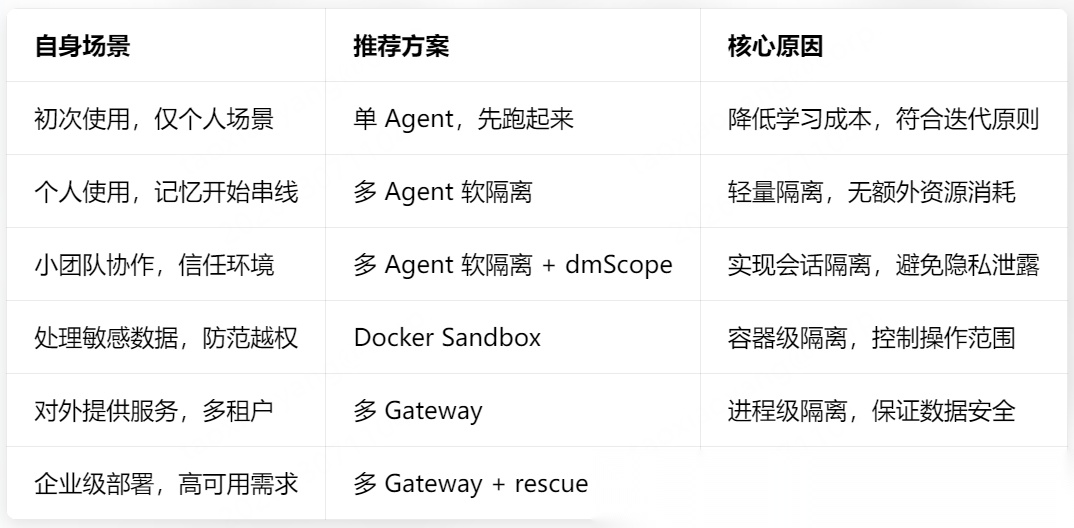
7.2 核心实践原则:避坑关键
-
先单后多,按需拆分
:多 Agent 不是「炫技」,而是解决问题的手段,只有出现记忆串线、prompt 臃肿、会话阻塞三个信号时,才需要拆分;
-
隔离程度与场景匹配
:不要过度隔离,个人场景用软隔离即可,企业级场景再上多 Gateway,避免资源浪费;
-
安全优先,细节为王
:多人 DM 必配 dmScope,远程访问不暴露端口,Sandbox 启用前必建镜像,这些细节是避免踩坑的关键;
-
渐进式迭代,逐步优化
:从「创建 Agent + 配置路由」的基础版,到「加 Sandbox 做隔离」的进阶版,再到「多 Gateway 高可用」的企业版,每一步都有明确的触发条件,不盲目升级。
7.3 行业趋势下的 OpenClaw 多 Agent 价值
从行业来看,多智能体系统是企业 AI 的下一个核心方向,部署多智能体系统的企业平均能实现 30-35% 的生产力提升,76% 的事件响应提速。而 OpenClaw 的多 Agent 体系,将这种「企业级分工」落地到了本地设备,让个人和小团队也能享受专业化分工的红利。
它的核心价值不是「增加 Agent 数量」,而是让 AI 的能力与场景精准匹配—— 写作 Agent 专注文案创作,开发 Agent 聚焦代码编写,生活 Agent 打理日常事务,每个 Agent 都在自己的领域积累记忆、优化能力,最终形成一个高效的 AI 协作团队。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献196条内容
已为社区贡献196条内容

所有评论(0)