spring ai alibaba 学习记录(多模态)
Agent 相当于我们人类的大脑,MCP 相当于我们人类的双手,此时多模态就相当于我们人类的眼睛、嘴巴、耳朵。通过多模态 Agent 可以实现对音频、图像的解析并输出(字节的豆包感觉是做的最好的)。
多模态看似深奥,使用方法本质上是给纯文本聊天换一个实体类对象;之前传给 Agent 是纯文本,这次则是传过去的是文件流。重点还是大模型是否支持多模态。
一、代码对比
1. 多模态的聊天形式 (接收文本 + 文件)
import org.springframework.core.io.Resource;
import org.springframework.util.MimeType;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import org.springframework.ai.chat.client.ChatClient;
@RestController
@RequestMapping("/ai")
public class MultimodalController {
private final ChatClient chatClient;
public MultimodalController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
/**
* 多模态聊天接口
* 【区别点】:使用 POST 请求,通过 @RequestParam 接收文本和 MultipartFile 文件
*/
@PostMapping("/multimodal")
public String multimodalChat(
@RequestParam(value = "prompt", defaultValue = "请描述这张图片") String prompt,
@RequestParam("file") MultipartFile file) throws Exception {
// 1. 动态获取上传文件的类型 (例如 "image/png", "image/jpeg")
MimeType mimeType = MimeType.valueOf(file.getContentType());
// 2. 将 MultipartFile 直接转换为 Spring AI 支持的 Resource 对象
Resource mediaResource = file.getResource();
// 3. 调用模型
return chatClient.prompt()
.user(u -> u
.text(prompt)
.media(mimeType, mediaResource) // 传入文件和类型
)
// 开启 DashScope 的多模态支持
.options(DashScopeChatOptions.builder().multiModel(true).build())
.call()
.content();
}
}
2. 纯文本聊天形式 (仅接收文本)
import org.springframework.web.bind.annotation.*;
import org.springframework.ai.chat.client.ChatClient;
@RestController
@RequestMapping("/ai")
public class TextChatController {
private final ChatClient chatClient;
public TextChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
/**
* 纯文本聊天接口
* 【区别点】:只需要接收文本 prompt,去掉了 MultipartFile
*/
@PostMapping("/text")
public String textChat(
@RequestParam(value = "prompt", defaultValue = "你好") String prompt) {
// 3. 调用模型
return chatClient.prompt()
// 【区别点】:直接传入字符串,不需要使用 u -> u.text().media()
.user(prompt)
// 【区别点】:去掉了开启 DashScope 多模态支持的 .options() 配置
.call()
.content();
}
}
二、核心差
- 入参维度:纯文本往往只接收一个字符串(或者 JSON 中的某个字段);多模态由于涉及二进制文件上传,通常需要结合
@RequestParam和MultipartFile来接收多媒体流。 - 构建维度:Spring AI 的
ChatClient中,纯文本直接.user(String)即可;而多模态需要通过 Lambda 表达式将文本和媒体对象(Resource+MimeType)组装在一起:.user(u -> u.text(...).media(...))。
三、我们需要注意
1. 模型自身的支持限制
并非所有大模型都支持多模态!
在调用前必须确认你当前使用的模型版本。例如 OpenAI 需要 gpt-4o 或 gpt-4-vision-preview;阿里云 DashScope 需要 qwen-vl-max 或 qwen-audio 等。如果把图片传给纯文本模型(如 qwen-turbo),会直接报错。
2. 必须显式开启多模态开关
在使用 Spring AI Alibaba (DashScope) 时,即便你传入了 .media(),如果不显式指定多模态配置,底层可能会解析失败。
必须加上:.options(DashScopeChatOptions.builder().multiModel(true).build())。或者在配置文件中开启multi-model(不建议,毕竟官方给的样例是是硬编码进去的)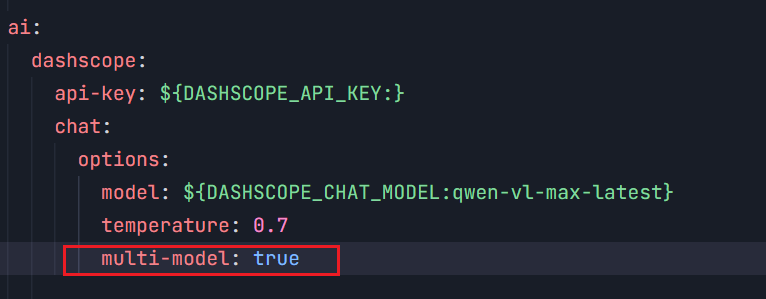
四、深究多模态的使用
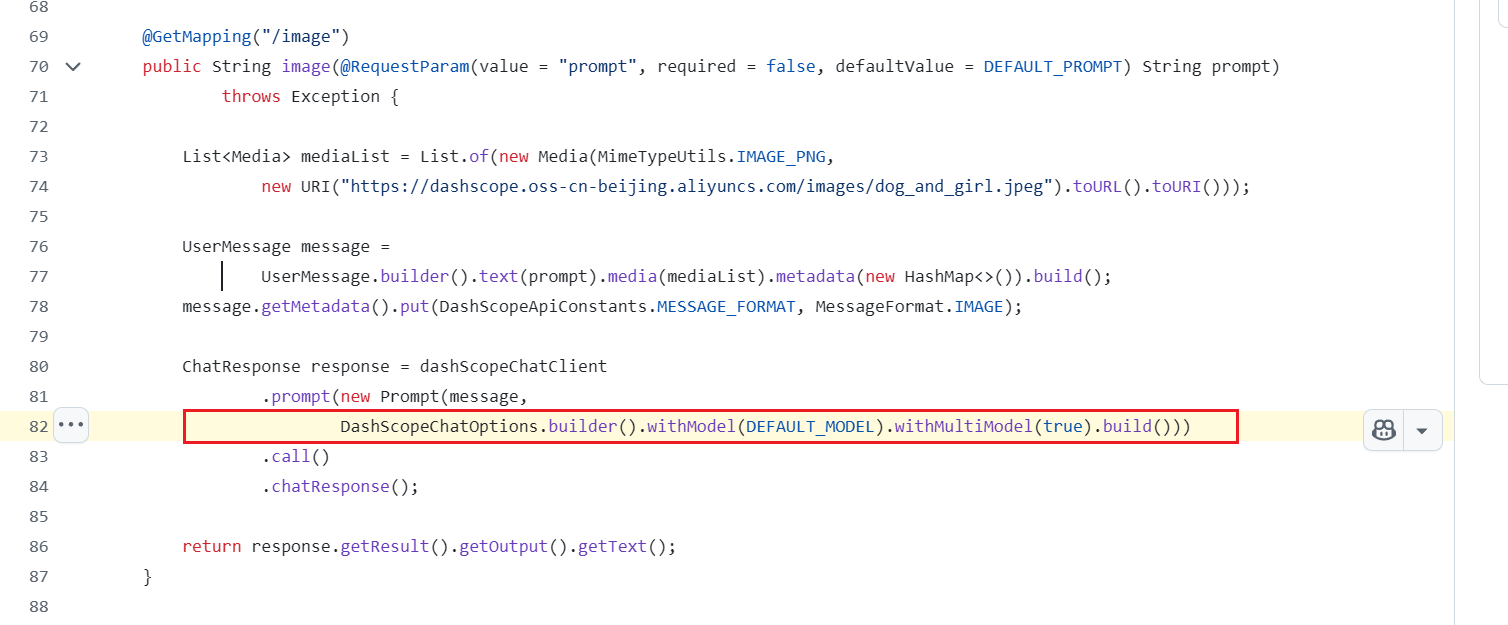
最近我在使用百炼平台发现其底层代码和Spring AI还是有点区别的,我阅读Spring AI官方指导文档发现官方使用多模态并没有涉及:
// 开启 DashScope 的多模态支持
.options(DashScopeChatOptions.builder().multiModel(true).build())
测试了一下发现如果Spring AI Alibaba不添加上面的那段代码则会报
HTTP 400 - {“code”:“InvalidParameter”,“message”:“url error, please check url!”} 。
这里需要我们参考官方样例:
https://github.com/spring-ai-alibaba/examples/blob/c66ffdec789defe4adf86b34bac0084df3b71e92/spring-ai-alibaba-multi-model-example/dashscope-multi-model/src/main/java/com/alibaba/cloud/ai/example/multi/controller/MultiModelController.java#L82
`
这也是我个人认为不建议直接在yml这类配置文件中将multi-model设置为true的原因

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)